简单聊聊Storm的流分组策略
简单聊聊Storm的流分组策略
首先我要强调的是,Storm的分组策略对结果有着直接的影响,不同的分组的结果一定是不一样的。其次,不同的分组策略对资源的利用也是有着非常大的不同,本文主要讲一讲localOrShuffle这个分组对资源利用的重大改善。最后,不同的分组对项目的逻辑也起着至关重要的决定,比如在写数据的时候不同的分组策略会导致死锁。
简单理解数据流分组
拓扑定义的一部分就是为每个Bolt指定输入的数据流,而数据流分组则定义了在Bolt的task之间如何分配数据流。
目前的Storm1.1.0版本内置了8种流分组策略,除此之外你也可以通过实现 CustomStreamGrouping接口来实现自定义的流分组策略。下面将结合具体的需求场景来具体的聊聊这些内置的分组策略:
Shuffle grouping:
随机分组:随机的将tuple分发给bolt的各个task,每个bolt实例接收到相同数量的tuple。
Fields grouping:
按字段分组:根据指定的字段的值进行分组,举个栗子,流按照“user-id”进行分组,那么具有相同的“user-id”的tuple会发到同一个task,而具有不同“user-id”值的tuple可能会发到不同的task上。这种情况常常用在单词计数,而实际情况是很少用到,因为如果某个字段的某个值太多,就会导致task不均衡的问题。
Partial Key grouping:
部分字段分组:流由分组中指定的字段分区,如“字段”分组,但是在两个下游Bolt之间进行负载平衡,当输入数据歪斜时,可以更好地利用资源。本论文 提供了一个很好的解释,说明它的工作原理以及它提供的优点。有了这个分组就完全可以不用Fields grouping了。
All grouping:
全复制分组:将所有的tuple都复制之后再分发给Bolt所有的task,每一个订阅数据流的task都会接收到一份相同的完全的tuple的拷贝。
Global grouping:
全局分组:这种分组会将所有的tuple都发到一个taskid最小的task上。由于所有的tuple都发到唯一一个task上,势必在数据量大的时候会造成资源不够用的情况。
None grouping:
不分组:不指定分组就表示你不关心数据流如何分组。目前来说不分组和随机分组效果是一样的,但是最终,Storm可能会使用与其订阅的bolt或spout在相同进程的bolt来执行这些tuple。这可能是节省资源最好的一种方式吧,但是目前并未实现。
Direct grouping:
指向分组:这是一种特殊的分组策略。以这种方式分组的流意味着将由元组的生成者决定消费者的哪个task能接收该元组。指向分组只能在已经声明为指向数据流的数据流中声明。tuple的发射必须使用emitDirect种的一种方法。Bolt可以通过使用TopologyContext或通过在OutputCollector(返回元组发送到的taskID)中跟踪emit方法的输出来获取其消费者的taskID。
Local or shuffle grouping:
本地或随机分组:和随机分组类似,但是如果目标Bolt在同一个工作进程中有一个或多个任务,那么元组将被随机分配到那些进程内task。简而言之就是如果发送者和接受者在同一个worker则会减少网络传输,从而提高整个拓扑的性能。有了此分组就完全可以不用shuffle grouping了。
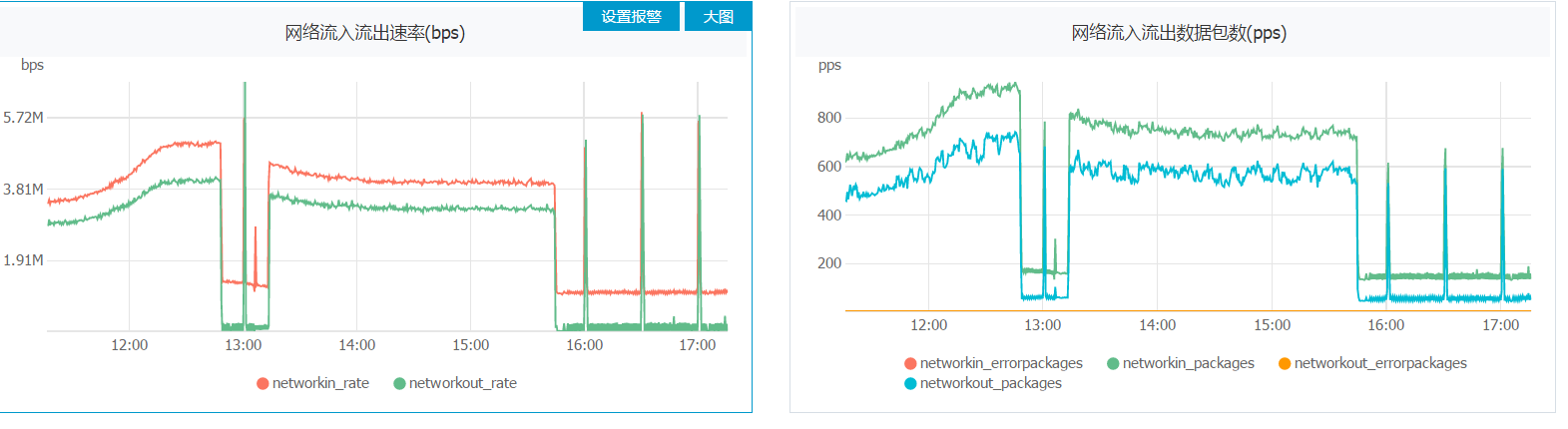
本地或随机分组对于并发度大的拓扑简直是神器好吧,发一张图让你们见识见识。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号