CSAPP学习笔记——chapter4 处理器体系结构
CSAPP学习笔记——chapter4 处理器体系结构
这一章相对于其它的章节,是相对来说比较困难的一章;其它章节的一些内容都在计组,计网,操作系统等课程里面已经接触过一些概念,但是有关处理器,我才发现大脑没有先验知识。这一章作者借助一个Y86-64指令集,从指令集的设计,到一个指令具体的执行过程,再到流水线,再到流水线中的数据冒险,结构冒险等,向我们介绍了现代处理器的知识。本篇博文将先回顾一下本章的重要概念,然后再结合这些概念介绍本章的实验部分。
指令集
一个处理器支持的指令以及指令的字节级编码被称为指令集体系结构(Instruction-Set Architecture,ISA)。处理器支持的指令就是对应的汇编语言,而后者则是汇编语言对应的二进制编码。
以书中的Y86-64指令集举例,其支持的指令主要有:
# movq i-->r: 从立即数到寄存器...
irmovq, rrmovq, mrmovq, rmmovq
# Opq
addq, subq, andq, xorq
# 跳转 jXX
jmp, jle, jl, je, jne, jge, jg
# 条件传送 cmovXX
cmovle, cmovl, cmove, cmovne, cmovge, cmovg
call, ret
pushq, popq
# 停止指令的执行
halt
# 寄存器
%rax, %rcx, %rdx
%rbx, %rsp, %rbp
%rsi, %rdi, %r8
%r9, %r10, %r11
%r12, %r13, %r14
其编码格式为:


当一个程序被编译为其对应的汇编代码,然后这些汇编代码又被转换为其对应的二进制代码,这些代码便可以在计算机上执行。
指令的执行过程
一个Y86-64指令的执行过程包括以下几个步骤:
取指:取指就是从内存中取出指令字节,地址为程序计数器PC的值。从指令中取出icode(指令代码)和ifun(指令功能)。还会取出这个指令所使用到的寄存器rA和rB,对于使用立即数的指令还会取出一个常数valC,还会计算下一个指令的地址valP。
译码:译码最多读出两个操作数valA和valB,他们来自寄存器rA和rB。当然也可能来自栈上
执行:ALU根据指令ifun指明的操作,计算内存引用的有效地址,将操作数进行计算,得到的值被称为valE,有些指令还会设置条件码。
访存:访存要么是写数据到内存,要么是从内存中读取数据,这个数据值为valM
写会:将计算结果写回到寄存器文件
更新PC:将PC设置为下一条指令的地址。

这是一个比较经典的例子。取指阶段取出指令对应的功能,寄存器编号,以及计算下一条指令的地址;译码则是取出寄存器中的值,执行阶段将valA和valB进行对应的计算。
再补一个带访存的例子:

其实这样就引出一个问题,一条指令为什么要被分为这些步骤呢,直接抽象的去看,只要知道指令的用法不就可以了?接下来就引出了下一部分的内容,流水线。
流水线
先看一个最基本的例子:
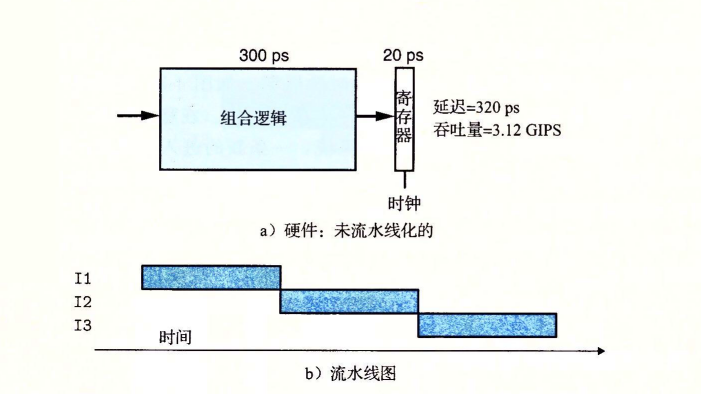
这个硬件的执行逻辑就是执行完一个指令之后,再去执行下一个指令,延迟是320ps,吞吐量是:
但是如果把组合逻辑切分为这样:
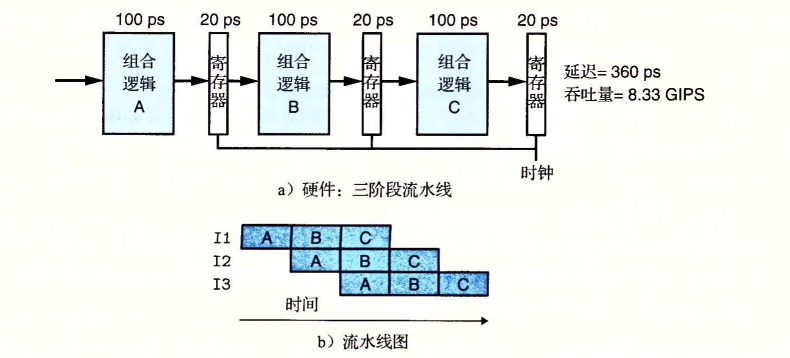
当第一条指令的A阶段执行完毕之后,此时A的执行硬件便空闲了,此时第二条指令的A阶段便可以提前执行,不用等待指令1全部执行完成。以此类推,这就是流水线。
此时虽然增加了延迟(360ps),但换来的确实更大的系统吞吐量,因为此时的时钟周期更短了,由原来的360ps变为了现在的120ps。吞吐量变为8.33GIPS。提高了大约2.67倍,代价是增加了一些硬件,以及延迟的少量增加。再到后面书里介绍了流水线的一些局限性,比如不一致的划分,流水线过深引发的一些问题,这里就不做过多介绍了。
所以这里就解释了上一小节提出的问题,之所以将指令的执行过程进行分段,就是为了实现流水线,提高系统吞吐量。
流水线冒险
流水线化的目的是每个时钟周期都发射一条指令。但是当指令之间存在数据相关,或者控制相关时,就必须通过一些特殊的方式来进行处理,保证得到的行为和ISA定义的模型相符。
| 数据相关 | 控制相关 |
|---|---|
 |
 |
数据冒险
在流水线处理器设计中,数据冒险(Data Hazard)是指一条指令依赖于前一条或几条指令的执行结果时发生的情况。这种依赖关系导致后续指令无法在前一条指令完成之前执行,从而降低了流水线的效率。
数据冒险的类型
当一条指令更新后面指令会读到的那些程序状态时,就有可能出现冒险。对于Y86-64 来说,程序状态包括程序寄存器、程序计数器、内存、条件码寄存器和状态寄存器。让我们来看看在提出的设计中每类状态出现冒险的可能性。
程序寄存器:我们已经认识这种冒险了。出现这种冒险是因为寄存器文件的读写是在不同的阶段进行的,导致不同指令之间可能出现不希望的相互作用。程序计数器:更新和读取程序计数器之间的冲突导致了控制冒险。当我们的取指阶段逻辑在取下一条指令之前,正确预测了程序计数器的新值时,就不会产生冒险。预测错误的分支和 ret 指令需要特殊的处理,会在 4.5.5 节中讨论。
内存:对数据内存的读和写都发生在访存阶段。在一条读内存的指令到达这个阶段之前,前面所有要写内存的指令都已经完成这个阶段了。另外,在访存阶段中写数据的指令和在取指阶段中读指令之间也有冲突,因为指令和数据内存访问的是同一个地址空间。只有包含自我修改代码的程序才会发生这种情况,在这样的程序中,指令写内存的一部分,过后会从中取出指令。有些系统有复杂的机制来检测和避免这种冒险,而有些系统只是简单地强制要求程序不应该使用自我修改代码。为了简便,假设程序不能修改自身,因此我们不需要采取特殊的措施,根据在程序执行过程中对数据内存的修改来修改指令内存。
条件码寄存器:在执行阶段中,整数操作会写这些寄存器。条件传送指令会在执行阶段以及条件转移会在访存阶段读这些寄存器。在条件传送或转移到达执行阶段之前,前面所有的整数操作都已经完成这个阶段了。所以不会发生冒险。
状态寄存器:指令流经流水线的时候,会影响程序状态。我们采用流水线中的每条指令都与一个状态码相关联的机制,使得当异常发生时,处理器能够有条理地停止,就像在 4.5.6节中会讲到的那样。这些分析表明我们只需要处理寄存器数据冒险、控制冒险,以及确保能够正确处理。
异常:当设计一个复杂系统时,这样的分类分析是很重要的。这样做可以确认出系统实现中可能的困难,还可以指导生成用于检查系统正确性的测试程序。
避免数据冒险的措施:
- 数据转发/前递(Data Forwarding/By passing):这是减少或消除RAW冒险最常用的方法。在这种技术中,一旦前一条指令计算出结果(即使还没有写回寄存器),这个结果就直接从执行单元传递给后续需要这个结果的指令,而不是等待数据写回寄存器后再被读取,这个需要额外的硬件和控制逻辑。
- 流水线暂停(Pipeline Stalling/Pipeline Bubbling):当无法通过数据转发解决冒险时,流水线可以暂停一条或多条指令的执行,直到所需的数据变得可用。这通过插入“气泡”(NOP指令)实现,相当于在流水线中引入空白周期。
- 指令重排(Instruction Reordering):编译器或处理器可以在保持程序语义不变的前提下重新安排指令的执行顺序,以减少数据冒险。
- 寄存器重命名(Register Renaming):这种技术通过将指令中的寄存器重新映射到另一组物理寄存器来消除WAR和WAW冒险。这样,即使逻辑寄存器相同,指令也可以操作不同的物理寄存器,从而避免了数据冒险。
- 乱序执行(Out-of-Order Execution):现代处理器可以以乱序的方式执行指令,只要数据依赖得到满足。这样,即使某些指令由于数据冒险而延迟,处理器也可以执行其他不依赖于这些数据的指令,从而提高效率。
书里主要介绍了前两种。
控制冒险
当处理器无法根据处于取指阶段的当前指令来确定下一条指令的地址时,就会出现控制冒险。如同在前面讨论过的,在我们的流水线化处理器中,控制冒险只会发生在ret 指令和跳转指令。而且,后一种情况只有在条件跳转方向预测错误时才会造成麻烦。
这里回顾一下分支预测的知识,为了保证每个周期都能发射一条指令,因此处理器在遇到jmp指令时,不会暂停,而是会去预测下一个指令,如果是valC的话,那就是默认跳转(总是选择分支);如果是valP的话,那就是默认不跳转(从不选择)。
除了总是选择分支和从不选择分支这两种预测策略,此外还有一些别的分支预测策略,比如正向不选择(forward not-taken),当分支地址比下一条地址低的时候就选择分支,否则就不选择分支。这种策略基于一种观察:在某些程序或编程模式中,正向跳转(向前跳转到较低的地址)通常用于循环的实现,而循环往往会执行多次。因此,预测这种正向跳转为Taken可能会提高分支预测的准确性。相反,反向跳转(向后跳转到较高的地址)或顺序执行通常出现在顺序代码执行或函数的结尾处的条件判断中,这些分支较可能不被执行(Not-Taken)。
如果分支预测失败,流水线就会取出预测分支的指令,但是这样很浪费很多的周期,因此一个好的分支预测策略是重要的。
实验
PartA
实验的A部分主要考察对汇编语言的掌握,作者提供了三个C程序,我们需要充当编译器的角色,把它们翻译成对应的汇编代码。
/*
* Architecture Lab: Part A
*
* High level specs for the functions that the students will rewrite
* in Y86-64 assembly language
*/
/* $begin examples */
/* linked list element */
typedef struct ELE {
long val;
struct ELE *next;
} *list_ptr;
/* sum_list - Sum the elements of a linked list */
long sum_list(list_ptr ls)
{
long val = 0;
while (ls) {
val += ls->val;
ls = ls->next;
}
return val;
}
/* rsum_list - Recursive version of sum_list */
long rsum_list(list_ptr ls)
{
if (!ls)
return 0;
else {
long val = ls->val;
long rest = rsum_list(ls->next);
return val + rest;
}
}
/* copy_block - Copy src to dest and return xor checksum of src */
long copy_block(long *src, long *dest, long len)
{
long result = 0;
while (len > 0) {
long val = *src++;
*dest++ = val;
result ^= val;
len--;
}
return result;
}
/* $end examples */
sum_list.ys
# sum_list - Sum the elements of a linked list
# author: xwang
# Execution begins at address 0
.pos 0
irmovq stack, %rsp # Set up stack pointer
call main # Execute main program
halt # Terminate program
# Sample linked list
.align 8
ele1:
.quad 0x00a
.quad ele2
ele2:
.quad 0x0b0
.quad ele3
ele3:
.quad 0xc00
.quad 0
main:
// 这里主要复制参数
irmovq ele1, %rdi
call sum_list
ret
# long sum_list(list_ptr ls)
sum_list:
irmovq $0, %rax
jmp test
loop:
mrmovq (%rdi), %r8
addq %r8, %rax
mrmovq 8(%rdi), %rdi
test:
andq %rdi, %rdi
jne loop
ret
# Stack starts here and grows to lower addresses
.pos 0x200
stack:
rsum_list.ys
这个考察的是对链表求和的递归实现
# sum_list - Sum the elements of a linked list
# author: xwang
# Execution begins at address 0
.pos 0
irmovq stack, %rsp # Set up stack pointer
call main # Execute main program
halt # Terminate program
# Sample linked list
.align 8
ele1:
.quad 0x00a
.quad ele2
ele2:
.quad 0x0b0
.quad ele3
ele3:
.quad 0xc00
.quad 0
main:
// 这里主要复制参数
irmovq ele1, %rdi
call rsum_list
ret
# long sum_list(list_ptr ls)
rsum_list:
andq %rdi, %rdi
je return
mrmovq (%rdi), %rbx
mrmovq 8(%rdi), %rdi
pushq %rbx
call rsum_list
popq %rbx
addq %rbx, %rax
ret
return:
irmovq $0, %rax
ret
# Stack starts here and grows to lower addresses
.pos 0x200
stack:
copy_block.ys
# copy - Sum the elements of a linked list
# author: xwang
# Execution begins at address 0
.pos 0
irmovq stack, %rsp # Set up stack pointer
call main # Execute main program
halt # Terminate program
.align 8
# Source block
src:
.quad 0x00a
.quad 0x0b0
.quad 0xc00
# Destination block
dest:
.quad 0x111
.quad 0x222
.quad 0x333
main:
// 这里主要复制参数
irmovq src, %rdi
irmovq dest, %rsi
irmovq $3, %rdx
call copy
ret
# long copy(list_ptr ls)
copy:
irmovq $0, %rax
irmovq $8, %r8
irmovq $1, %r9
andq %rdx, %rdx
jmp test
loop:
mrmovq (%rdi), %r10
rmmovq %r10, (%rsi)
addq %r8, %rdi
addq %r8, %rsi
xorq %r10, %rax
subq %r9, %rdx
test:
jne loop
ret
# Stack starts here and grows to lower addresses
.pos 0x200
stack:
PartB
这里我们需要在seq_full的基础上,添加一个 iaddq V,rb将一个立即数加到指定的寄存器。

结合指令的执行过程那部分的介绍,可以得知iaddq的指令执行过程如下:

-
fetch stage
# 判断指令是否合法,需要添加上IIADDQ bool instr_valid = icode in { INOP, IHALT, IRRMOVQ, IIRMOVQ, IRMMOVQ, IMRMOVQ, IOPQ, IJXX, ICALL, IRET, IPUSHQ, IPOPQ, IIADDQ }; # Does fetched instruction require a regid byte? IIADDQ需要 bool need_regids = icode in { IRRMOVQ, IOPQ, IPUSHQ, IPOPQ, IIRMOVQ, IRMMOVQ, IMRMOVQ, IIADDQ}; # Does fetched instruction require a constant word? IIADDQ需要 bool need_valC = icode in { IIRMOVQ, IRMMOVQ, IMRMOVQ, IJXX, ICALL, IIADDQ}; -
Decode Stage and Write back stage
## What register should be used as the B source? 产生valB,结合iaddq的执行过程可知其为寄存器rB word srcB = [ icode in { IOPQ, IRMMOVQ, IMRMOVQ, IIADDQ } : rB; icode in { IPUSHQ, IPOPQ, ICALL, IRET } : RRSP; 1 : RNONE; # Don't need register ]; ## What register should be used as the E destination? 指定valE写回的地方,iaddq是寄存器rB word dstE = [ icode in { IRRMOVQ } && Cnd : rB; icode in { IIRMOVQ, IOPQ, IIADDQ} : rB; icode in { IPUSHQ, IPOPQ, ICALL, IRET } : RRSP; 1 : RNONE; # Don't write any register ]; -
Execute Stage
## Select input A to ALU 传到ALU执行单元的第一个数字是立即数valC word aluA = [ icode in { IRRMOVQ, IOPQ} : valA; icode in { IIRMOVQ, IRMMOVQ, IMRMOVQ, IIADDQ } : valC; icode in { ICALL, IPUSHQ } : -8; icode in { IRET, IPOPQ } : 8; # Other instructions don't need ALU ]; ## Select input B to ALU 传到ALU执行单元的第二个数字是来自寄存器rB的值valB word aluA = [ word aluB = [ icode in { IRMMOVQ, IMRMOVQ, IOPQ, ICALL, IPUSHQ, IRET, IPOPQ, IIADDQ } : valB; icode in { IRRMOVQ, IIRMOVQ } : 0; # Other instructions don't need ALU ]; ## Should the condition codes be updated? bool set_cc = icode in { IOPQ, IIADDQ }; 执行完这个要设置条件码 -
memory stage
iaddq没有访存阶段,无需修改 -
PC update
这里不使用跳转,所以默认是下一条指令valP,因此不需要修改。
测试
这里介绍一下测试的过程
-
编译
make VERSION=full -
在一个程序上测试
./ssim -g ../y86-code/asumi.yo -
运行一个标准检查程序
> cd ../y86-code; make testssim ../seq/ssim -t asum.yo > asum.seq ../seq/ssim -t asumr.yo > asumr.seq ../seq/ssim -t cjr.yo > cjr.seq ../seq/ssim -t j-cc.yo > j-cc.seq ../seq/ssim -t poptest.yo > poptest.seq ../seq/ssim -t pushquestion.yo > pushquestion.seq ../seq/ssim -t pushtest.yo > pushtest.seq ../seq/ssim -t prog1.yo > prog1.seq ../seq/ssim -t prog2.yo > prog2.seq ../seq/ssim -t prog3.yo > prog3.seq ../seq/ssim -t prog4.yo > prog4.seq ../seq/ssim -t prog5.yo > prog5.seq ../seq/ssim -t prog6.yo > prog6.seq ../seq/ssim -t prog7.yo > prog7.seq ../seq/ssim -t prog8.yo > prog8.seq ../seq/ssim -t ret-hazard.yo > ret-hazard.seq grep "ISA Check" *.seq asum.seq:ISA Check Succeeds asumr.seq:ISA Check Succeeds cjr.seq:ISA Check Succeeds j-cc.seq:ISA Check Succeeds poptest.seq:ISA Check Succeeds prog1.seq:ISA Check Succeeds prog2.seq:ISA Check Succeeds prog3.seq:ISA Check Succeeds prog4.seq:ISA Check Succeeds prog5.seq:ISA Check Succeeds prog6.seq:ISA Check Succeeds prog7.seq:ISA Check Succeeds prog8.seq:ISA Check Succeeds pushquestion.seq:ISA Check Succeeds pushtest.seq:ISA Check Succeeds ret-hazard.seq:ISA Check Succeeds rm asum.seq asumr.seq cjr.seq j-cc.seq poptest.seq pushquestion.seq pushtest.seq prog1.seq prog2.seq prog3.seq prog4.seq prog5.seq prog6.seq prog7.seq prog8.seq ret-hazard.seq -
回归测试
# 这个命令测试除了iaddq之外的其它所有指令 > (cd ../ptest; make SIM=../seq/ssim) ./optest.pl -s ../seq/ssim Simulating with ../seq/ssim All 49 ISA Checks Succeed ./jtest.pl -s ../seq/ssim Simulating with ../seq/ssim All 64 ISA Checks Succeed ./ctest.pl -s ../seq/ssim Simulating with ../seq/ssim All 22 ISA Checks Succeed ./htest.pl -s ../seq/ssim Simulating with ../seq/ssim All 600 ISA Checks Succeed # 这个指令测试保护iaddq的所有指令 > cd ../ptest; make SIM=../seq/ssim TFLAGS=-i ./optest.pl -s ../seq/ssim -i Simulating with ../seq/ssim All 58 ISA Checks Succeed ./jtest.pl -s ../seq/ssim -i Simulating with ../seq/ssim All 96 ISA Checks Succeed ./ctest.pl -s ../seq/ssim -i Simulating with ../seq/ssim All 22 ISA Checks Succeed ./htest.pl -s ../seq/ssim -i Simulating with ../seq/ssim All 756 ISA Checks Succeed
PartC
这一步部分我们的目标是修改 pipe-full.hcl和nocopy.ys使得这个函数每元素周期数尽可能小,也就是尽可能快。
*/
word_t ncopy(word_t *src, word_t *dst, word_t len)
{
word_t count = 0;
word_t val;
while (len > 0) {
val = *src++;
*dst++ = val;
if (val > 0)
count++;
len--;
}
return count;
}
/* $end ncopy */
默认情况
# 这个是nocpy.ys的默认情况,我们先使用作者提供的 ./benchmark.pl 测一下速度
##################################################################
# You can modify this portion
# Loop header
xorq %rax,%rax # count = 0;
andq %rdx,%rdx # len <= 0?
jle Done # if so, goto Done:
Loop:
mrmovq (%rdi), %r10 # read val from src...
rmmovq %r10, (%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle Npos # if so, goto Npos:
iaddq $1, %rax # count++
Npos:
irmovq $1, %r10
subq %r10, %rdx # len--
irmovq $8, %r10
addq %r10, %rdi # src++
addq %r10, %rsi # dst++
andq %rdx,%rdx # len > 0?
jg Loop # if so, goto Loop:
##################################################################
ncopy
0 13
1 29 29.00
2 45 22.50
3 57 19.00
4 73 18.25
5 85 17.00
6 101 16.83
7 113 16.14
8 129 16.12
9 141 15.67
...
60 857 14.28
61 869 14.25
62 885 14.27
63 897 14.24
64 913 14.27
Average CPE 15.18
Score 0.0/60.0
这个时候还是比较慢的,而且没有分数
使用iaddq
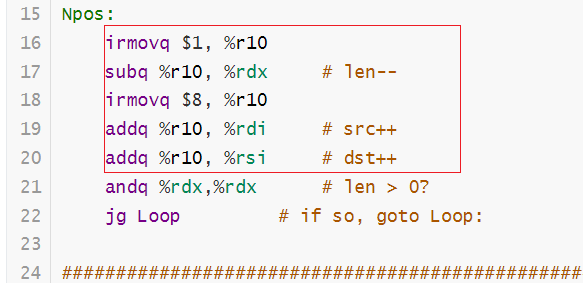
第一个想到的是使用iaddq指令,这样可以减少这部分的操作。添加指令的方法和PartB是一样的,需要修改pipe-full.hcl
##################################################################
# You can modify this portion
# Loop header
xorq %rax,%rax # count = 0;
andq %rdx,%rdx # len <= 0?
jle Done # if so, goto Done:
Loop:
mrmovq (%rdi), %r10 # read val from src...
rmmovq %r10, (%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle Npos # if so, goto Npos:
iaddq $1, %rax # count++
Npos:
iaddq $8, %rdi # src++
iaddq $8, %rsi # dst++
iaddq $-1, %rdx # len--
jg Loop # if so, goto Loop:
##################################################################
ncopy
0 13
1 26 26.00
2 38 19.00
3 47 15.67
4 59 14.75
5 68 13.60
6 80 13.33
7 89 12.71
8 101 12.62
9 110 12.22
10 122 12.20
11 131 11.91
12 143 11.92
...
60 647 10.78
61 656 10.75
62 668 10.77
63 677 10.75
64 689 10.77
Average CPE 11.70
Score 0.0/60.0
可以看到此时的CPE减少了15.18-11.70=3.48,效果还是有的。但是还没有分数。
循环展开
下一步就是循环展开了,循环展开在第五章有更加详细的介绍。他的主要好处是提高指令的并行度和减少循环控制的开销。
这部分代码同时做了两点优化:
-
原先的代码逻辑在处理剩余值时,当剩余为8时会进入1*1循环,修改边界判断条件使得其也能循环展开。
-
我测试之后发现6路展开要优于8路展开,因此将原先的展开修改为6路
# You can modify this portion
# Loop header
andq %rdx,%rdx # len <= 0?
jle Done # 如果一开始输入的len就<=0,直接结束
jmp test
Loop6x6:
#取地址
mrmovq 0(%rdi), %r8
mrmovq 8(%rdi), %r9
mrmovq 16(%rdi), %r10
mrmovq 24(%rdi), %r11
mrmovq 32(%rdi), %r12
mrmovq 40(%rdi), %r13
#赋值
rmmovq %r8, 0(%rsi)
rmmovq %r9, 8(%rsi)
rmmovq %r10, 16(%rsi)
rmmovq %r11, 24(%rsi)
rmmovq %r12, 32(%rsi)
rmmovq %r13, 40(%rsi)
#判断是否可以count+1
judge0:
andq %r8, %r8
jle judge1
iaddq $1, %rax
judge1:
andq %r9, %r9
jle judge2
iaddq $1, %rax
judge2:
andq %r10, %r10
jle judge3
iaddq $1, %rax
judge3:
andq %r11, %r11
jle judge4
iaddq $1, %rax
judge4:
andq %r12, %r12
jle judge5
iaddq $1, %rax
judge5:
andq %r13, %r13
jle step6x6
iaddq $1, %rax
step6x6:
iaddq $48,%rdi
iaddq $48,%rsi
test:
#这里需要判断长度是否6
iaddq $-6, %rdx
jge Loop6x6 #有则6x6循环拓展
iaddq $6, %rdx #要把减去的6加回去才能循环
jle Done
Loop1x1:
mrmovq (%rdi), %r10 # read val from src
rmmovq %r10, (%rsi) # and store it to dst
andq %r10, %r10 # val <= 0? 这里已经是guarded-do了
jle Npos1x1 # if so, goto Npos:
iaddq $1, %rax # count++
Npos1x1:
iaddq $8, %rdi # src++
iaddq $8, %rsi # dst++
iaddq $-1, %rdx # len--
jg Loop1x1 # if so, goto Loop:
ncopy
0 12
1 34 34.00
2 46 23.00
3 55 18.33
4 67 16.75
5 76 15.20
6 58 9.67
...
60 391 6.52
61 404 6.62
62 416 6.71
63 425 6.75
64 437 6.83
Average CPE 8.65
Score 37.1/60.0
可以看到循环展开提升还是很大的。11.70-8.68=3.05。
修改分支预测策略
注意到pipe_full.hcl中的IJXX分支预测策略是总是不选择的,这里我修改为总是选择,也就是下一条指令f_valP,试了一下结果很好。
# Predict next value of PC
word f_predPC = [
f_icode in { ICALL , IJXX} : f_valC;
1 : f_valP;
];
修改为:
# Predict next value of PC
word f_predPC = [
f_icode in { ICALL } : f_valC;
1 : f_valP;
];
- f_valP 通常表示下一条顺序执行的指令的地址,即程序计数器(PC)递增到下一条指令的位置。
- f_valC 通常表示分支或跳转指令的目标地址,即在跳转或调用指令中指定的目标地址。
因此,根据代码逻辑:
如果 f_icode 是 ICALL(调用指令)或 IJXX(跳转指令),则预测的下一个程序计数器(f_predPC)的值是 f_valC。
对于其他所有指令,预测的下一个程序计数器(f_predPC)的值是 f_valP。
./benchmark.pl
ncopy
0 69
1 75 75.00
2 77 38.50
3 71 23.67
4 75 18.75
5 71 14.20
6 71 11.83
7 69 9.86
8 71 8.88
9 67 7.44
...
59 69 1.17
60 71 1.18
61 73 1.20
62 65 1.05
63 69 1.10
64 73 1.14
Average CPE 5.34
Score 60.0/60.0
在实践中,最佳的分支预测策略往往是动态的,即根据程序的运行时行为来适应性地调整。现代处理器中的分支预测单元通常会使用更复杂的算法(如基于历史的分支预测器,包括局部分支预测器、全局分支预测器和两级分支预测器等)来动态地预测每个分支的行为,以达到更高的预测准确率。因此,对于特定的程序或代码段,简单的静态预测策略(如总是选择或总是不选择)可能表现出不同的效果。
分支预测其实还涉及更多的内容,这里的学习如果以后用到了,再去深入研究吧。
通过这个实验我大概的感觉对于一个程序的优化,分支预测的收益是最高的,然后其它比如转发技术和循环展开收益次之。
Summary
本篇博文讨论了处理器体系结构中的指令集和流水线相关的知识,书中还结合着硬件电路去介绍了指令各个执行阶段的细节,由于时间原因,电路这部分我是略读的;最后的实验在软件层面帮助我巩固了汇编,指令集,以及优化程序的相关知识。
Refer
本文来自博客园,作者:CuriosityWang,转载请注明原文链接:https://www.cnblogs.com/curiositywang/p/17998020

 浙公网安备 33010602011771号
浙公网安备 33010602011771号