MapReduce(分布式计算)_01
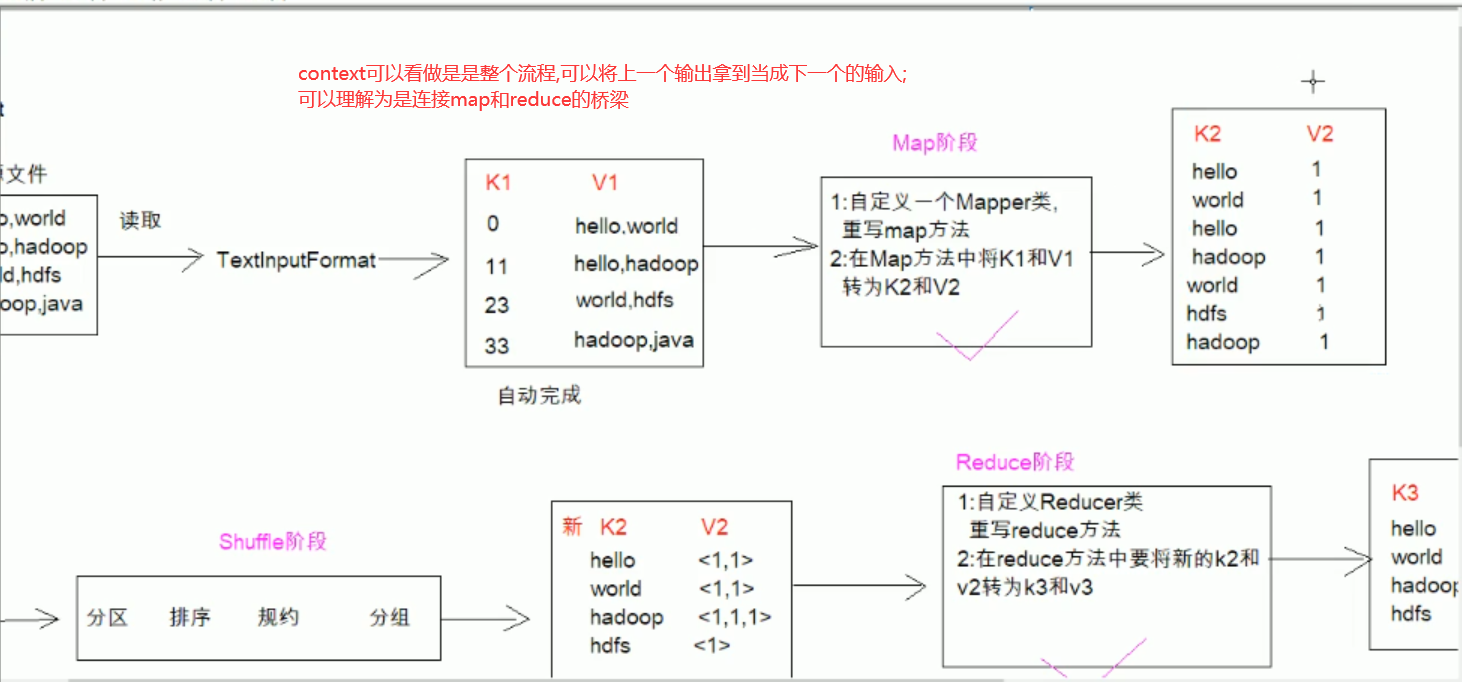
13-MapReduce排序-流程分析1-MapReduce介绍
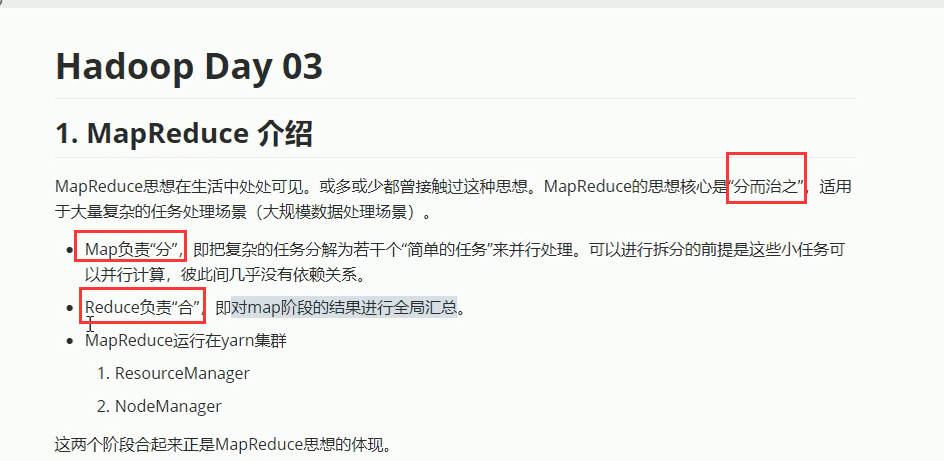

===========================================================================================================================
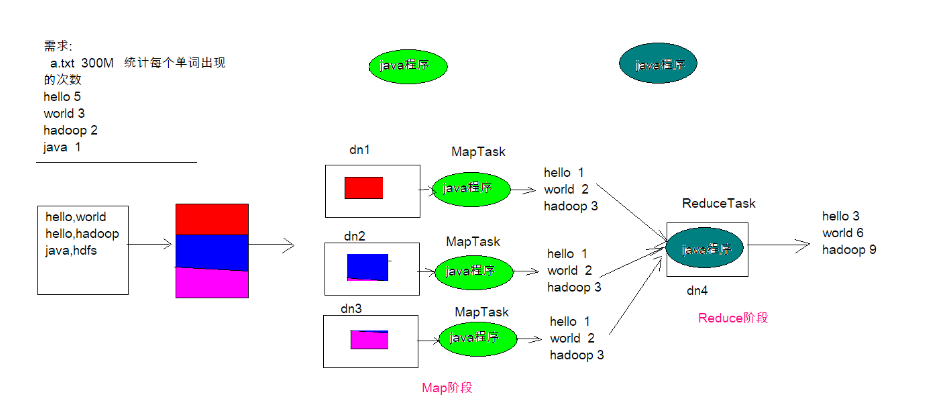
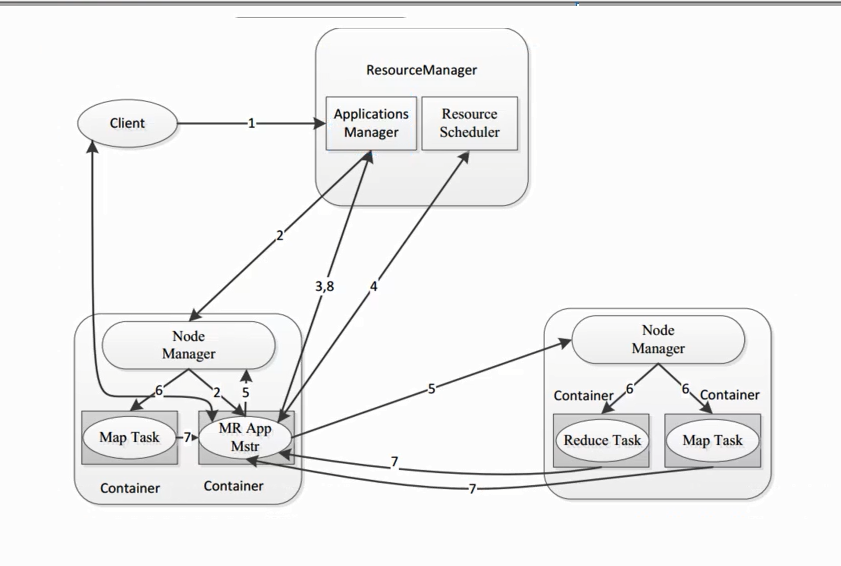
2-MapReduce的构思和框架结构

===============================================================================================================
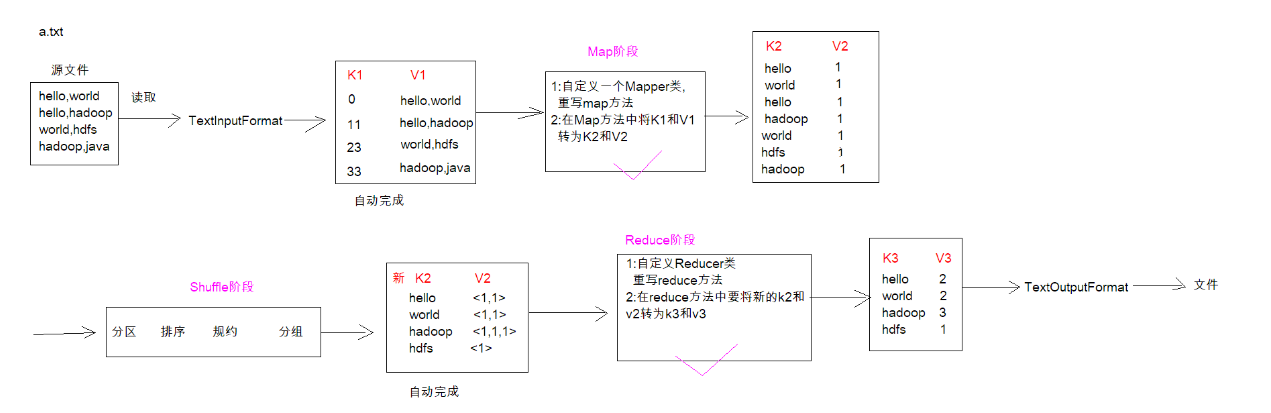
3-MapReduce的编程规范

===================================================================================================================
4-MapReduce案例-wordcount-步骤分析
======================================================================================================================
5-MapReduce案例-wordcount-准备工作


=========================================================================================================================
6-MapReduce案例-wordcount-Map阶段代码





WordCountMapper.java
package com.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* Mapper的泛型:
* KEYIN:k1的类型 有偏移量 LongWritable
* VALUEIN:v1的类型 一行的文本数据 Text
* KEYOUT:k2的类型 每个单词 Text
* VALUEOUT:v2的类型 固定值1 LongWritable
*
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
/**
* map方法是将k1和v1转为k2和v2
* key:是k1
* value:是v1
* context:表示MapReduce上下文对象
*/
/**
* k1 v1
* 0 hello,world
* 11 hello,hadoop
* ------------------------------------------
* k2 v2
* hello 1
* world 1
* hadoop 1
*/
@Override
protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException {
Text text=new Text();
LongWritable writable = new LongWritable();
//1.对每一行数据进行字符串拆分
String line = value.toString();
String[] split = line.split(",");
//2.遍历数组,获取一个单词
//靠context来连接
for (String word : split) {
text.set(word);
writable.set(1);
context.write(text,writable);
}
}
}
============================================================================================================
7-MapReduce案例-wordcount-Reduce阶段代码
WordCountReducer.java
package com.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* KEYIN:k2 Text 每个单词
* VALUE:v2 LongWritable 集合中泛型的类型
* KEYOUT:k3 Text 每个单词
* VALUEOUT LongWritable 每个单词出现的次数
*/
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
/**
* reduce方法的作用是将k2和v2转为k3和v3
* key:k2
* value:集合
* context:MapReduce的上下文对象
*/
/**
* 新 k2 v2
* hello <1,1>
* world <1,1>
* hadoop <1,1,1>
* -----------------------------
* k3 v3(遍历集合相加)
* hello 2
* world 2
* hadoop 3
*/
@Override
protected void reduce(Text key, Iterable<LongWritable> values,
Context context) throws IOException, InterruptedException {
long count=0;
//1.遍历values集合
for (LongWritable value : values) {
//2.将集合中的值相加
count+=value.get();
}
//3:将k3和v3写入上下文中
context.write(key, new LongWritable(count));
}
}
===================================================================================================
8-MapReduce案例-wordcount-JobMain代码 (主程序类的编写)
MapReduce主程序的固定模板

//创建一个任务对象
Job job = Job.getInstance(super.getConf(),"mapreduce_wordcount");

JobMain.class
package com.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobMain extends Configured implements Tool{
@Override
public int run(String[] arg0) throws Exception {
//创建一个任务对象
Job job = Job.getInstance(super.getConf(),"mapreduce_wordcount");
//打包在集群运行时,需要做一个配置
job.setJarByClass(JobMain.class);
//设置任务对象
//第一步:设置读取文件的类:K1和V1(读取原文件TextInputFormat)
job.setInputFormatClass(TextInputFormat.class);
//设置从哪里读
TextInputFormat.addInputPath(job,new Path("hdfs://http://192.168.187.100:50070/wordcount"));
//第二步:设置Mapper类
job.setMapperClass(WordCountMapper.class);
//设置Map阶段的输出类型: k2和v2的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//进入Shuffle阶段,采取默认分区,默认排序,默认规约,默认分组
//第三,四,五,六步,采取默认分区,默认排序,默认规约,默认分组
//第七步:设置Reducer类
job.setReducerClass(WordCountReducer.class);
//设置reduce阶段的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//第八步: 设置输出类
job.setOutputFormatClass(TextOutputFormat.class);
//设置输出的路径
//注意:wordcount_out这个文件夹一定不能存在
TextOutputFormat.setOutputPath(job, new Path("hdfs://http://192.168.187.100:50070/wordcount_out"));
boolean b= job.waitForCompletion(true);//固定写法;一旦任务提交,处于等待任务完成状态
return b?0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//启动一个任务
//返回值0:执行成功
int run = ToolRunner.run(configuration, new JobMain(), args);
System.out.println(run);
}
}
=============================================================================================
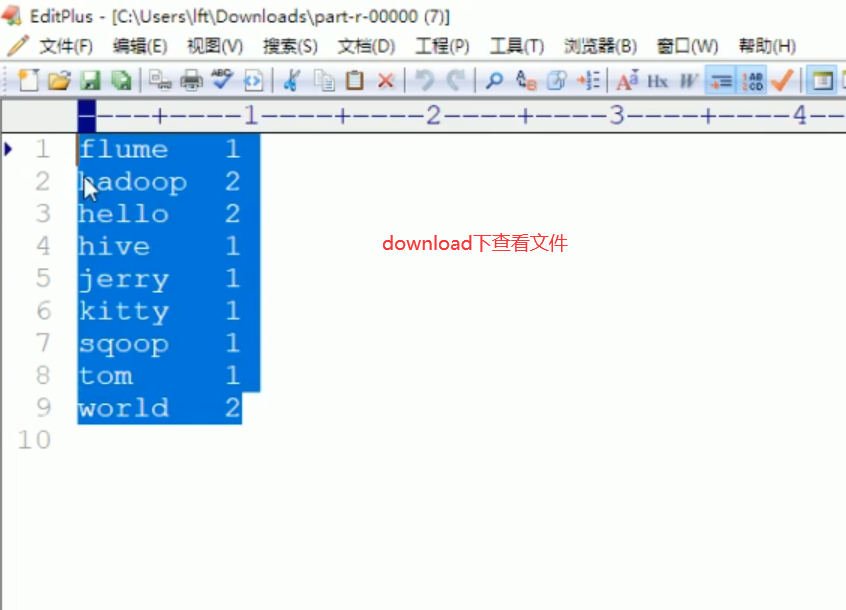
9-MapReduce案例-wordcount-集群运行
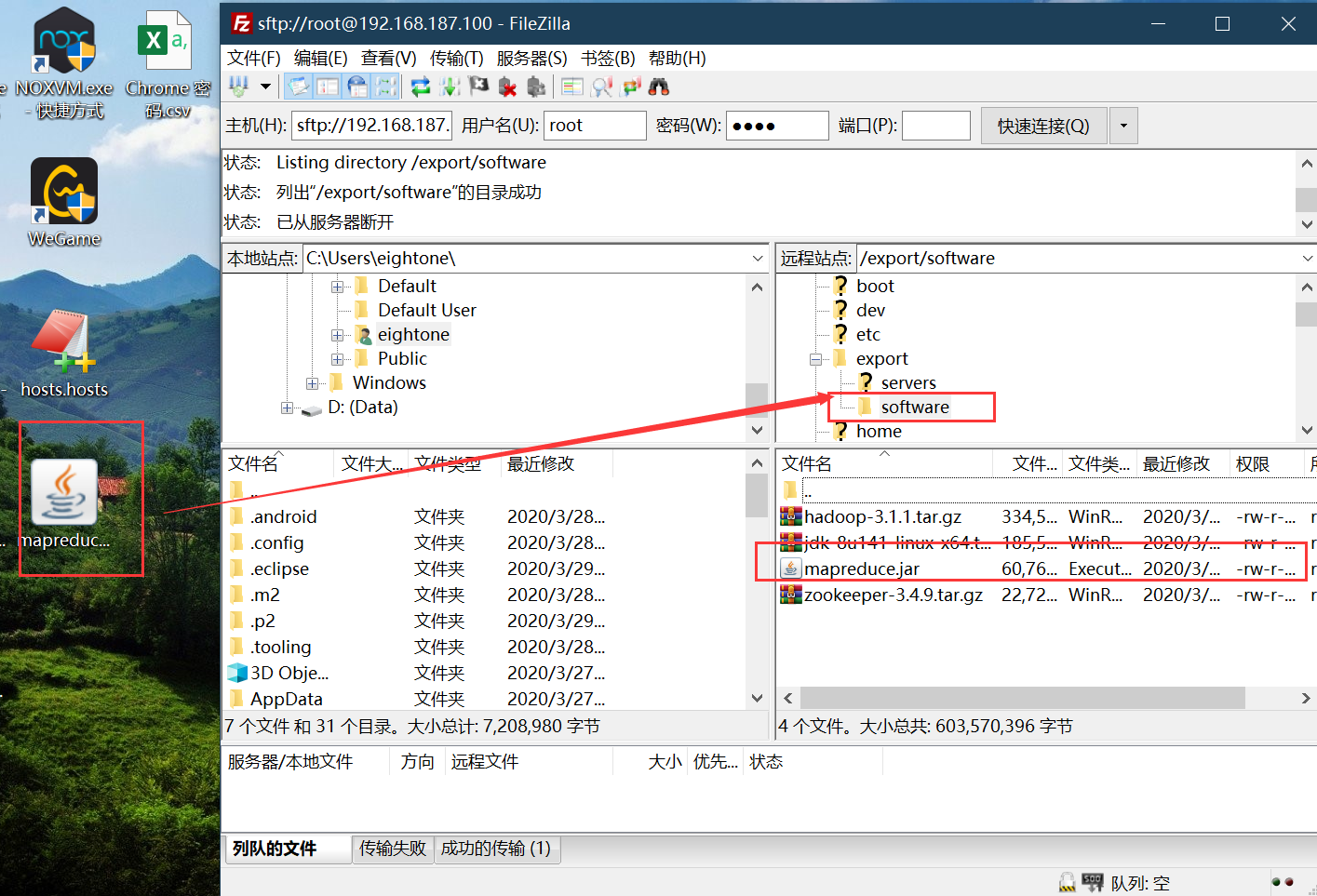

运行成功: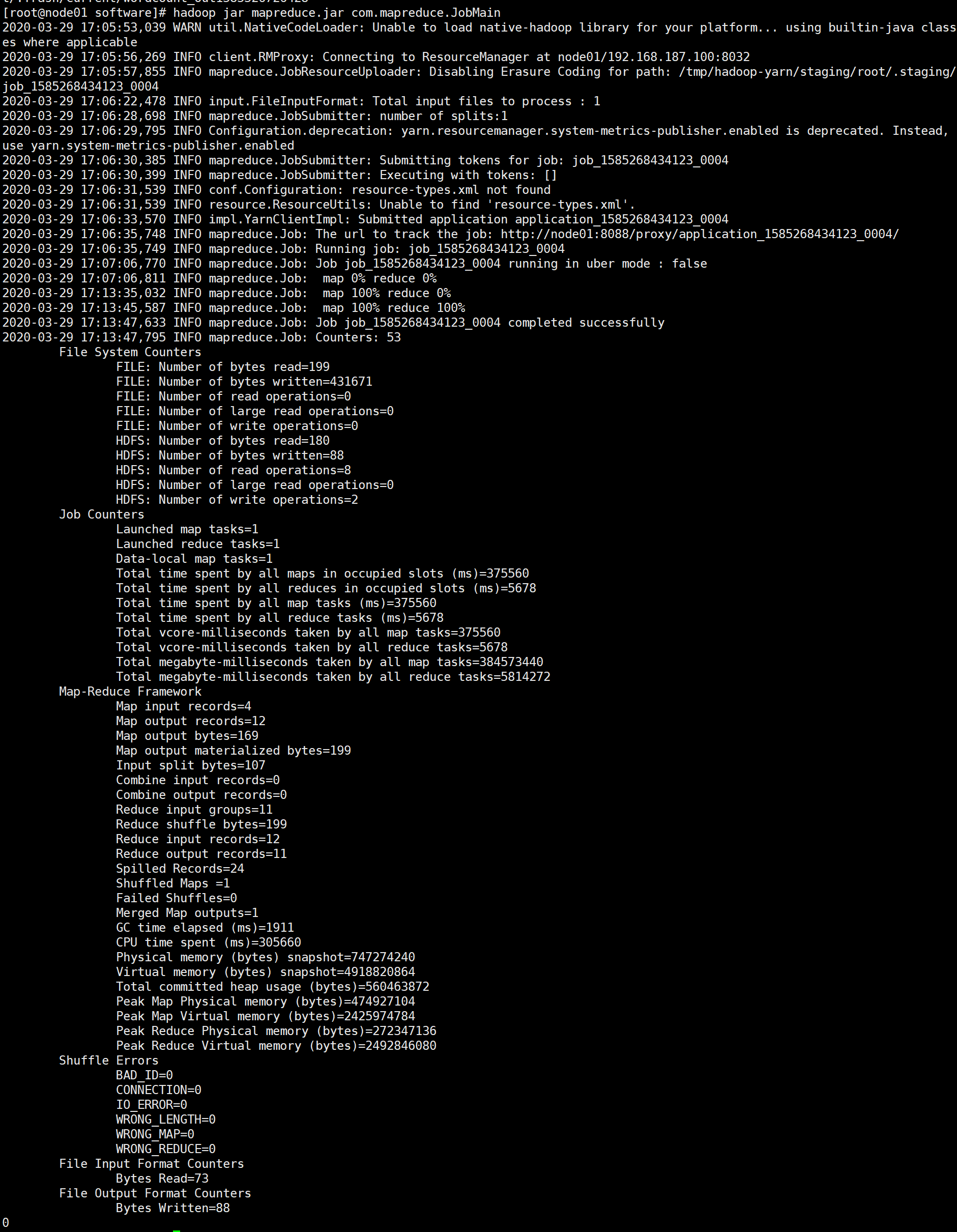

======================================================================================================================
10-MapReduce分区-原理


===========================================================================================================
11-MapReduce分区-代码实现
PartitonerOwn.java
package com.mapreduce;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class PartitonerOwn extends Partitioner<Text,LongWritable>{
/**
* text:表示k2
* longWritable:表示v2
* i:reduce个数
*/
@Override
public int getPartition(Text text, LongWritable longWritable, int i) {
//如果单词的长度>=5,进入第一个分区-->第一个reduceTask-->reduce编号为0
if(text.toString().length()>=5) {
return 0;
}else {
return 1;
}
}
}
------------------------------------------------------------------------------------------------------------------------------------------------------------
JobMain.java
package com.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobMain extends Configured implements Tool{
@Override
public int run(String[] arg0) throws Exception {
//创建一个任务对象
Job job = Job.getInstance(super.getConf(),"mapreduce_wordcount");
//打包在集群运行时,需要做一个配置
job.setJarByClass(JobMain.class);
//设置任务对象
//第一步:设置读取文件的类:K1和V1(读取原文件TextInputFormat)
job.setInputFormatClass(TextInputFormat.class);
//设置从哪里读
TextInputFormat.addInputPath(job,new Path("hdfs://node01:8020/wordcount"));
//第二步:设置Mapper类
job.setMapperClass(WordCountMapper.class);
//设置Map阶段的输出类型: k2和v2的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//进入Shuffle阶段,采取默认分区,默认排序,默认规约,默认分组
//第三,四,五,六步,采取默认分区,默认排序,默认规约,默认分组
//设置我们的分区类
job.setPartitionerClass(PartitonerOwn.class);
//第七步:设置Reducer类
job.setReducerClass(WordCountReducer.class);
//设置reduce阶段的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置reduce的个数
job.setNumReduceTasks(2);
//第八步: 设置输出类
job.setOutputFormatClass(TextOutputFormat.class);
//设置输出的路径
//注意:wordcount_out这个文件夹一定不能存在
TextOutputFormat.setOutputPath(job, new Path("hdfs://node01:8020/wordcount_out"));
boolean b= job.waitForCompletion(true);//固定写法;一旦任务提交,处于等待任务完成状态
return b?0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//启动一个任务
//返回值0:执行成功
int run = ToolRunner.run(configuration, new JobMain(), args);
System.out.println(run);
}
}
------------------------------------------------------------------------------------------------------------------------------------------------------------
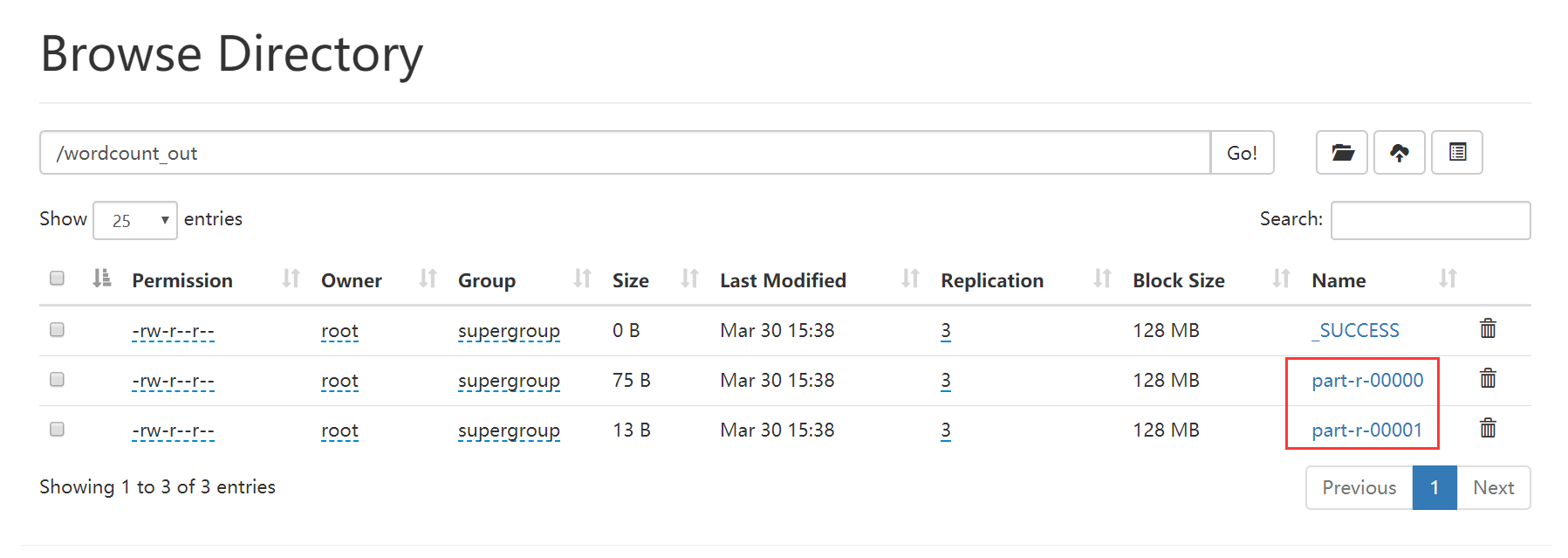
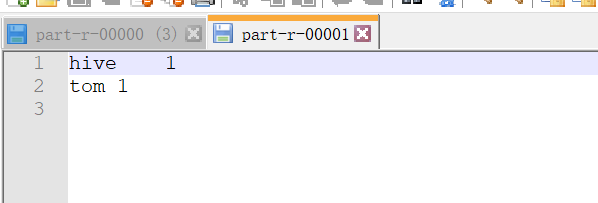
修改代码之后,重新打成jar包,上传到服务器,执行代码jar包

==============================================================================================================
12-MapReduce排序-概述

==============================================================================================================
13-MapReduce排序-流程分析
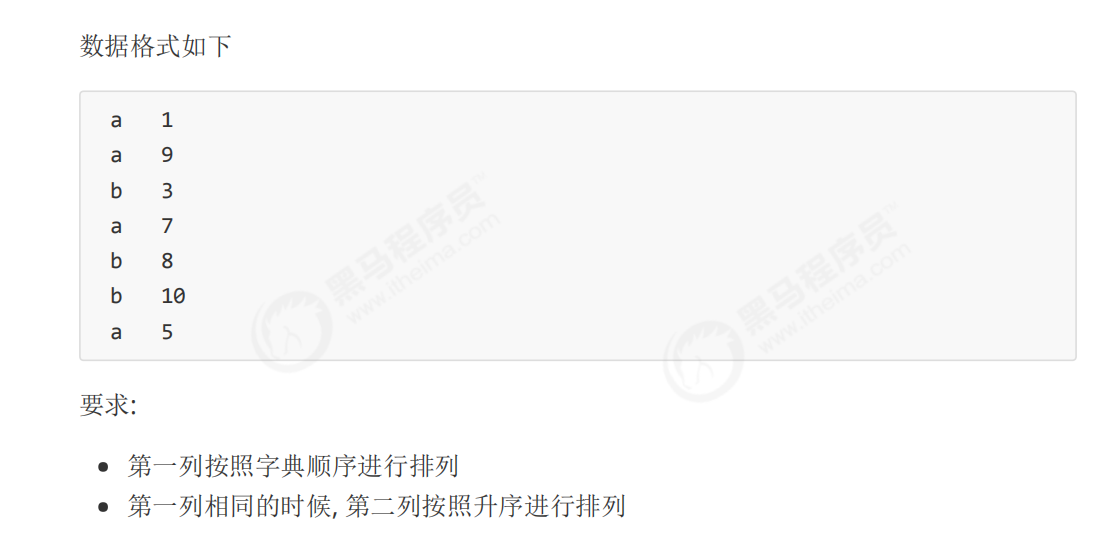
注意:k1为每一行的偏移量


================================================================================================================
14-MapReduce排序-实现比较器和序列化代码
PairWritable.java
package com.mapreduce_sort;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class PairWritable implements WritableComparable<PairWritable>{
private String first;
private int second;
public String getFirst() {
return first;
}
public void setFirst(String first) {
this.first = first;
}
public int getSecond() {
return second;
}
public void setSecond(int second) {
this.second = second;
}
@Override
public String toString() {
return first+'\t'+second;
}
//实现反序列化
@Override
public void readFields(DataInput dataInput) throws IOException {
this.first=dataInput.readUTF();
this.second=dataInput.readInt();
}
//实现序列化(将对象变成字节流)
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(first);
dataOutput.writeInt(second);
}
//实现排序规则
@Override
public int compareTo(PairWritable other) {
//先比较first,如果first相同,则比较second
int result=this.first.compareTo(other.first);//abc abb 先a比较;后比较b;最后发现c的ASCII值大于b
if (result==0) {
return this.second-other.second;
}
return result;
}
}
----------------------------------------------------------------------------------------------------------------------------------------------------------------
package com.mapreduce_sort;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class SortMapper extends Mapper<LongWritable, Text, PairWritable, Text>{
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
//1.对每一行数据进行拆分,然后封装到PairWritable对象中,作为A2
String[] split = value.toString().split("\t");
PairWritable pairWritable = new PairWritable();
pairWritable.setFirst(split[0]);
pairWritable.setSecond(Integer.parseInt(split[1].trim()));
//2.将k2和v2写入上下文中
context.write(pairWritable, value);
}
}
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
SortReducer.java
package com.mapreduce_sort;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class SortReducer extends Reducer<PairWritable,Text, PairWritable, NullWritable>{
/**
* a 1 <a 1,a 1>
* a 1
*
*/
@Override
protected void reduce(PairWritable key, Iterable<Text> values,Context context)throws IOException, InterruptedException {
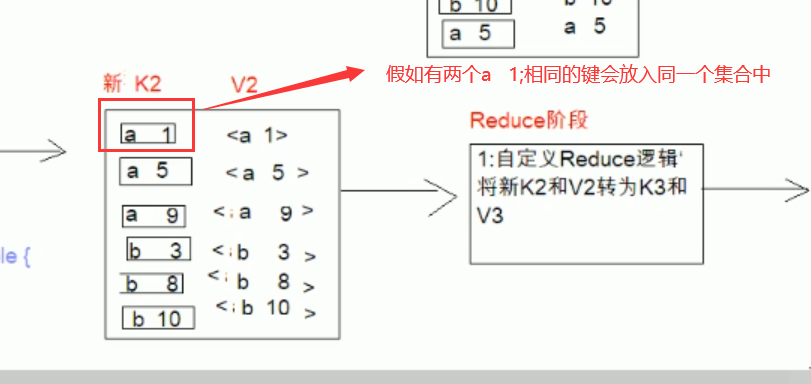
//处理有两个a 1
for (Text value : values) {
//NullWritable.get();.get()表示获取空对象
context.write(key, NullWritable.get());
}
}
}
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
JobMain.java
package com.mapreduce_sort;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobMain extends Configured implements Tool{
@Override
public int run(String[] arg0) throws Exception {
//创建一个任务对象
Job job = Job.getInstance(super.getConf(),"mapreduce_sort");
//打包在集群运行时,需要做一个配置
job.setJarByClass(JobMain.class);
//设置任务对象
//第一步:设置读取文件的类:K1和V1(读取原文件TextInputFormat)
job.setInputFormatClass(TextInputFormat.class);
//设置从哪里读
TextInputFormat.addInputPath(job,new Path("hdfs://node01:8020/input/sort"));
//第二步:设置Mapper类
job.setMapperClass(SortMapper.class);
//设置Map阶段的输出类型: k2和v2的类型
job.setMapOutputKeyClass(PairWritable.class);
job.setMapOutputValueClass(Text.class);
//进入Shuffle阶段,采取默认分区,默认排序,默认规约,默认分组
//第三,四,五,六步,采取默认分区,默认排序,默认规约,默认分组
//第七步:设置Reducer类
job.setReducerClass(SortReducer.class);
//设置reduce阶段的输出类型
job.setOutputKeyClass(PairWritable.class);
job.setOutputValueClass(NullWritable.class);
//第八步: 设置输出类
job.setOutputFormatClass(TextOutputFormat.class);
//设置输出的路径
//注意:wordcount_out这个文件夹一定不能存在
TextOutputFormat.setOutputPath(job, new Path("hdfs://node01:8020/sort_out"));
boolean b= job.waitForCompletion(true);//固定写法;一旦任务提交,处于等待任务完成状态
return b?0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//启动一个任务
int run=ToolRunner.run(configuration, new JobMain(),args);
//任务退出
System.exit(run);
}
}
=====================================================================================================================
16-MapReduce排序-集群运行





 浙公网安备 33010602011771号
浙公网安备 33010602011771号