



伪分布式集群、Linux 查看历史命令
目录
伪分布式集群
Linux 查看历史命令
historyLinux查看进程运行的状态
top---- 也能查看集群资源
为了节省计算机的资源,我们将之前分布式的集群,改为伪分布式
伪分布式:即在一个节点上做分布式,可以节省资源
拍摄快照
在改伪分布式之前可以给我们的集群拍个快照,方便之后如果想要用回分布式集群,可以通过快照恢复
因为我们集群中的东西基本上大多都在master中,所以选择将master改为伪分布式的
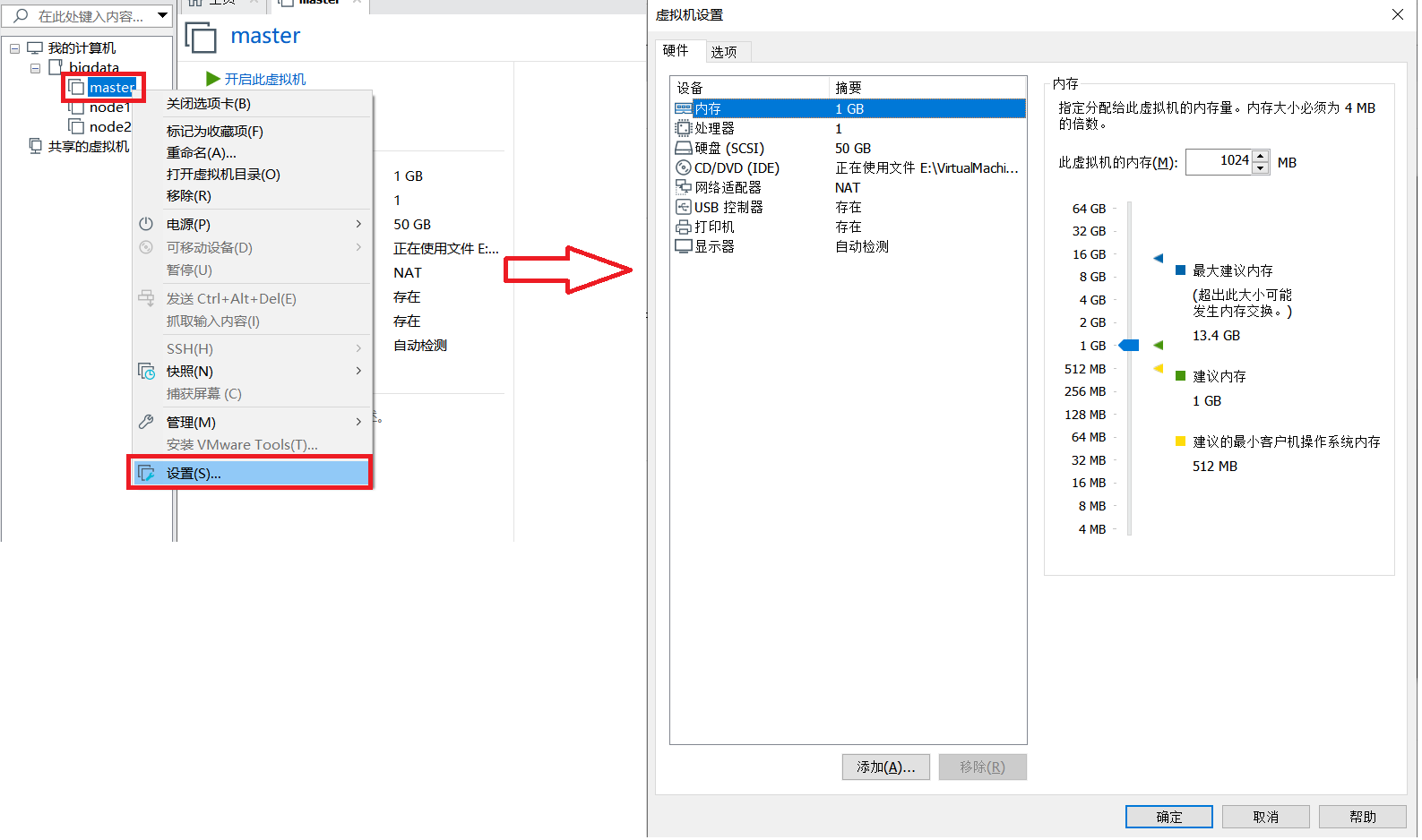
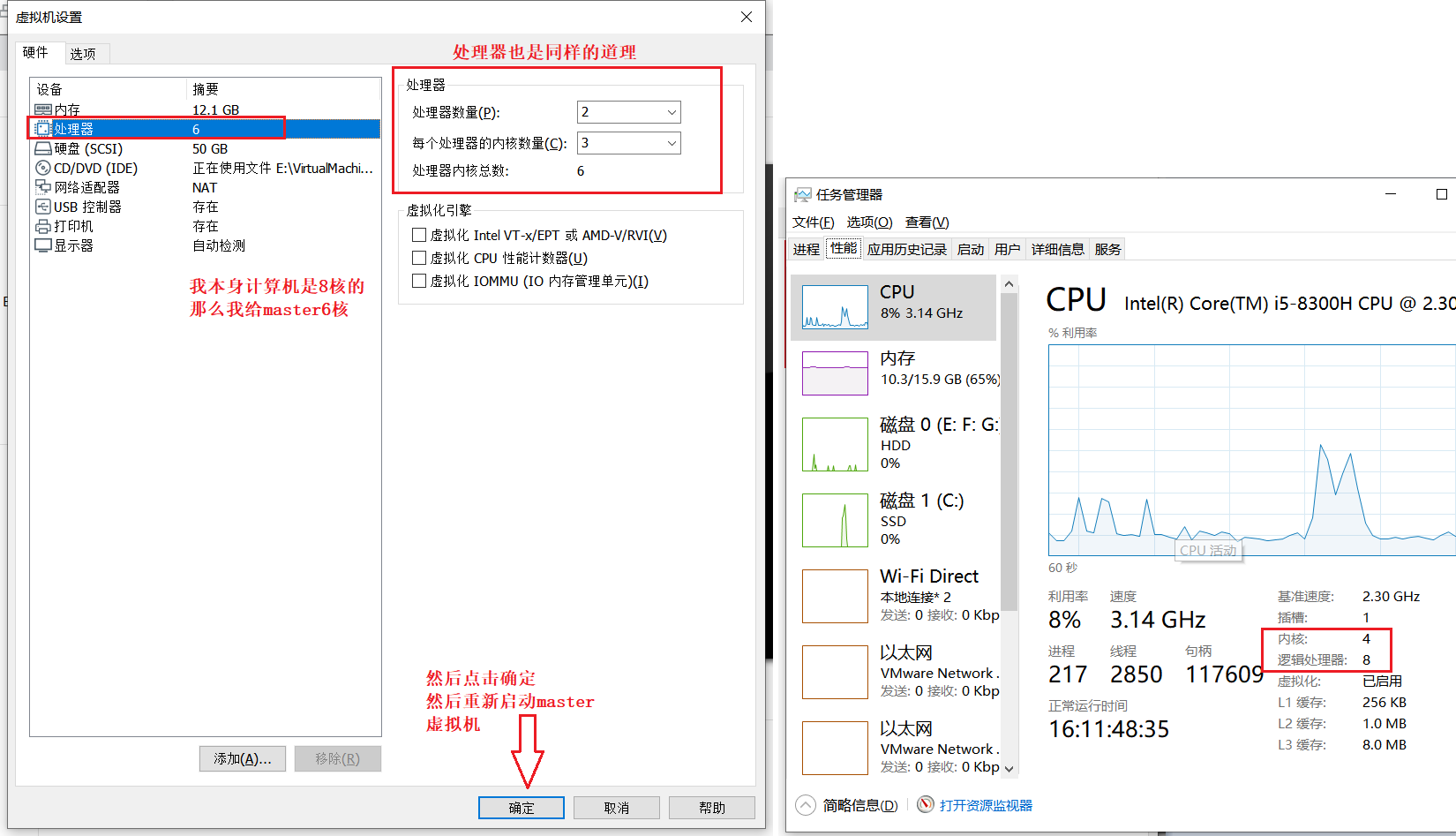
为 master 增加计算资源
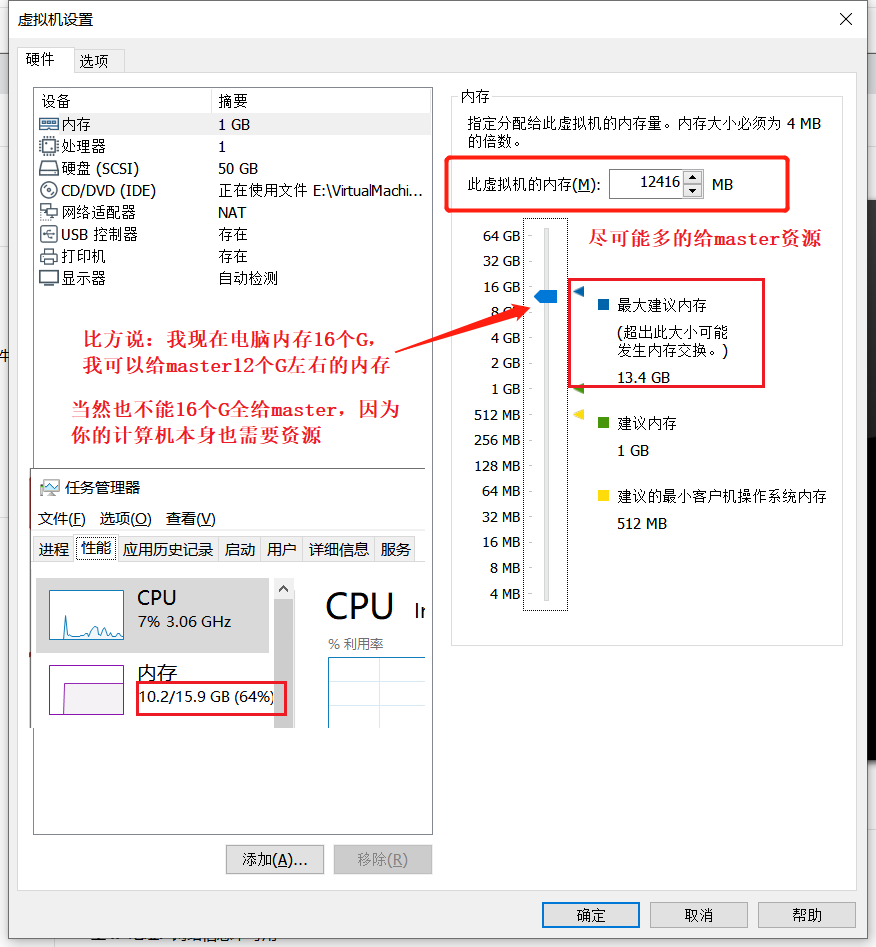
那么给 master 多少计算资源好呢?
尽可能多的给
在给master分配资源之前,需要先将master关机
为master分配好资源之后,我们就可以开始伪分布式的修改了(将之前所有的东西从hadoop开始改一遍配置文件)
将 hadoop 改为伪分布式
1、修改 slaves 文件
cd /usr/local/soft/hadoop-2.7.6/etc/hadoop/
vim slaves
将slaves里面的node1和node2删除,增加master
2、删除hadoop tmp目录
rm -rf /usr/local/soft/hadoop-2.7.6/tmp/
3、重新初始化hadoop
hadoop namenode -format
4、启动hadoop
start-all.sh
5、验证
http://master:8088
http://master:50070
这样就好了,我们可以通过 jps 看一下,主从节点的进程都在 master 中
将 Zookeeper 改为伪分布式
1、修改 zoo.cfg 文件
cd /usr/local/soft/zookeeper-3.4.6/conf
vim zoo.cfg
修改如下图所示

2、删除version文件
rm -rf /usr/local/soft/zookeeper-3.4.6/data/version-2/
3、启动zk
zkServer.sh start
4、验证
zkServer.sh status
将 hive 改为伪分布式
hive本身就是单节点的,由于hadoop被重置了,hive表的数据都丢失了
1、启动hvie的元数据服务
不启动的话,hive 不能用
nohup hive --service metastore >> metastore.log 2>&1 &
将 HBase 改为伪分布式
1、修改 regionservers 文件
cd /usr/local/soft/hbase-1.4.6/conf
vim regionservers
将 regionservers 里面的node1和node2删除,增加master
2、启动 HBase
start-hbase.sh
将 kafka 改为伪分布式
Kafka 是去中心化的架构
1、删除data目录
rm -rf /usr/local/soft/kafka_2.11-1.0.0/data/
2、启动kafka
kafka-server-start.sh -daemon /usr/local/soft/kafka_2.11-1.0.0/config/server.properties
3、测试
kafka-console-producer.sh --broker-list master:9092 --topic test_topic1
kafka-console-consumer.sh --bootstrap-server master:9092 --from-beginning --topic test_topic1
将 canal 改为伪分布式
1、修改canal.properties配置文件
cd /usr/local/soft/canal/conf
vim canal.properties
修改以下配置:
canal.zkServers = master:2181
canal.mq.servers = master:9092
2、启动 canal
# 需要先启动Kafka
cd /usr/local/soft/canal/bin
./startup.sh -- 启动


 浙公网安备 33010602011771号
浙公网安备 33010602011771号