


Scrapy 使用时出现的问题及解决、Python中的线程休眠、在Python中使用正则表达式
目录
Scrapy 使用时出现的问题及解决
Scrapy | A Fast and Powerful Scraping and Web Crawling Framework -- Scrapy 官网
将来如果使用到 Scrapy 可以回去看视频 或者 去看官网的使用文档
缺少网站"君子协议"的文件
假如通过 scrapy crawl 爬虫名称 命令运行 Scrapy 的时候,出现警告如下图所示

那是因为每个网站都有这样的一个文件 -- 君子协议
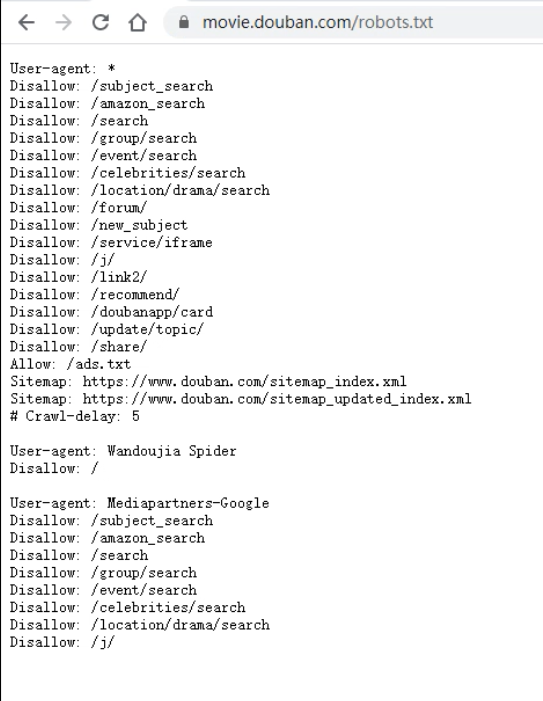
这个文件的作用是:文件中所列出的东西,可以在法律的范围内随便爬取,文件中没有列出的东西就不要随便爬了
当然你也可以不遵循这个文件,所以称之为君子协议
那么我们使用 Scrapy 时不指定"君子协议"该怎么办呢?
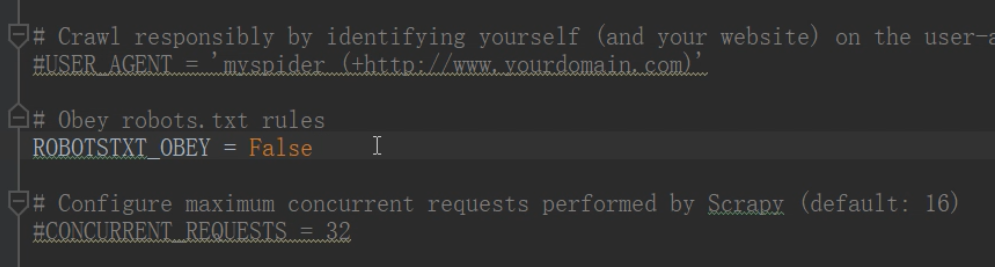
需要在 Scrapy 项目下的 settings.py 的文件中
修改下面的设置
# Obey robots.txt rules
ROBOTSTXT_OBET = False # 表示不遵循君子协议
如图所示:
缺少请求头
假如通过 scrapy crawl 爬虫名称 命令运行 Scrapy 的时候,出现警告如下图所示

这时我们就需要手动编写发起请求的代码
在我们写的爬虫的逻辑代码中
# 需要爬取的页面
start_url = 'https://movie.douban.com/top250?start=%7Bpage%7D&filter='
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36"
}
# 手动编写发起请求的代码 -- 增加请求头
# yield -- 返回数据,类似于return
def start_requests(self):
yield scrapy.Request(url=self.start_url, headers=self.head)
在IDEA命令行中执行运行爬虫的命令
当然如果觉得在DOS命令行中执行 scrapy crawl 爬虫名称 命令,很难看,在IDEA的命令行中也能执行,但是必须要在爬虫项目的位置下
当然使用爬虫的时候,最难的并不是指定爬取域的范围,而是对返回的数据解析的过程
在IDEA中右键运行 Scrapy 项目
需要在项目下的 __init__.py 文件中,添加如下代码
from scrapy import cmdline
# 执行cmd脚本
cmdline.execute("scrapy crawl DouBanSpider".split(" "))
然后就可以在项目下的文件中直接右键运行 Scrapy 项目
效果和 DOS 命令行中一样
如何快速确定需要爬取的数据的xpath路径
在Python中使用正则表达式
# 需要先导入一个正则的包
import re
# pattern : 正则 -- 格式: r"表达式"
# string : 被查询的字符串
re.findall(pattern, string, flags) -- 查询
re.finditer()
处理数据时的常用方法
text() : 取出标签内容,返回一个 SelectorList 对象
extract() : 返回一个列表,里面是提取的内容
strip() : 去除字符串两边的空格及制表符
",".join() : 将列表中的元素通过 , 拼接成字符串
apply() : 相当于 spark 中的 map(),apply()中传入 lambda 表达式
value_counts() : 统计 value 的数量
to_dict() : 将序列转换成一个字典
items() : 将字典转换成一个序列
如何在浏览器开发者工具中复制页面响应
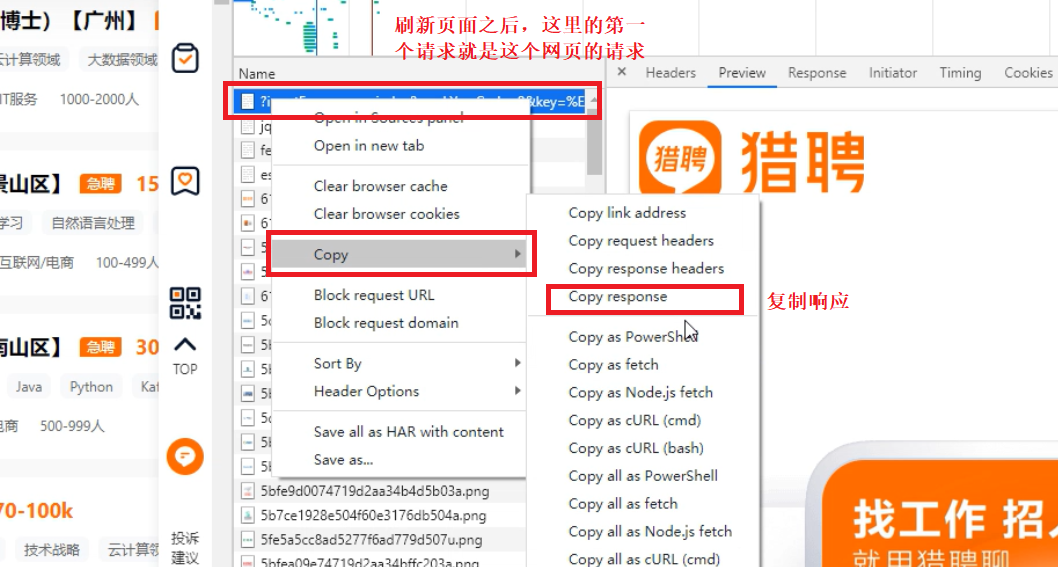
这里的响应和我们通过爬虫代码拿到的响应是一样的
如果网页有多页,如何爬取多页内容
观察网页的URL地址我们发现,同一个网页中的多页的地址是有规律的
URL 中的 ? 后面的参数通过 & 分割
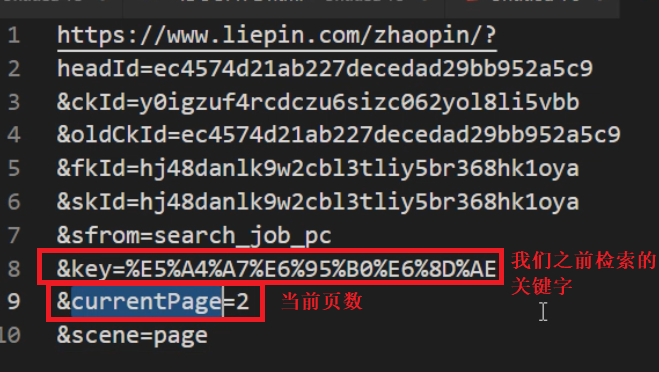
那么我们 指定爬取域的范围 的爬虫代码可以这样写:
# 在指定的 URL 中 通过 {} 来充当占位符
base_url = "https://www.liepin.com/zhaopin/?headId=ec4574d21ab227decedad29bb952a5c9&ckId=y0igzuf4rcdczu6sizc062yol8li5vbb&oldCkId=ec4574d21ab227decedad29bb952a5c9&fkId=hj48danlk9w2cbl3tliy5br368hk1oya&skId=hj48danlk9w2cbl3tliy5br368hk1oya&sfrom=search_job_pc&key={}¤tPage={}&scene=page"
# 手动编写发起请求的代码
def start_requests(self):
# 检索关键字列表
words = ["大数据", "hadoop", "spark", "flink", "数据处理", "数据开发"]
for word in words:
# 循环获取多个页面
# range() -- 快速构建一个列表
for page in range(100):
# .format() -- 对上面的占位符进行按顺序的赋值
# parse.quote() -- 将字符串转换成URL中的编码格式,使用此方法需要导一个包 from urllib import parse
url = self.base_url.format(parse.quote(word), page)
# 返回请求结果
yield scrapy.Request(url=url)
Python中的线程休眠
可以用于防止爬虫爬的太快,被封掉
当然 Python 爬虫 - Scrapy 的 反反爬虫相关机制 中也提到了另一种方法
import time
time.sleep(seconds)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号