


Python Pandas 数据分析
Python Pandas 数据分析
Pandas 的底层也是 Numpy 实现的
Python科学计算生态圈
Python在科学计算方面有很多不断改良的库,结合其在通用编程方面的强大实力, 使其在数据处理、交互探索性计算以及数据可视化方面深受广大编程者的喜爱
Python有着一个强大的科学计算生态圈, 已经完全可以媲美MATLAB、R等特定编程语言/工具

Numpy
NumPy是Python科学计算基础包,提供了以下功能(仅列举了几条)
快速高效的多维数组对象ndarray
用于对数组执行元素级计算以及直接对数组执行数学运算的函数
用于读写硬盘上基于数组的数据集的工具
线性代数运算、傅里叶变换以及随机数生成
用于集成由C、C++、Fortran等语言编写的代码的工具
对于数值型数据,NumPy数组在存储和处理数据时要比内置的Python数据结构 高效得多
Pandas
pandas提供了使我们能够快速便捷地处理结构化数据的大量数据结构和函数
pandas兼具NumPy高性能的数组计算功能以及电子表格和关系型数据库灵活的数据处理功能
对于金融行业的用户,pandas提供了大量适合于金融数据的高性能时间序列功能和工具
学统计的人会对R语言比较熟悉,R提供的data.frame对象功能仅仅是pandas的DataFrame所提供的功能的一个子集
pandas含有使数据分析工作变得更快更简单的高级数据结构和操 作工具,它是基于Numpy构建的,有很多操作是类似的
约定本小节编写程序之前默认运行了import pandas as pd和 from pandas import Series,DataFrame
DataFrame -- 类似 spark-sql 中的 DataFrame
Series -- 这是列的一个单例
Pandas-Series
Series是一种类似于一维数组的对象,由数据(各种NumPy数据 类型)以及与之相关的数据标签(即索引)组成
可以通过字典构建Series对象,Series对象的索引也是可以修改的


Pandas-Dataframe
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)
DataFrame既有行索引也有列索引,可以看做由Series组成的字典
最常用的构建方法是直接传入一个由等长列表或NumPy数组组成的字典
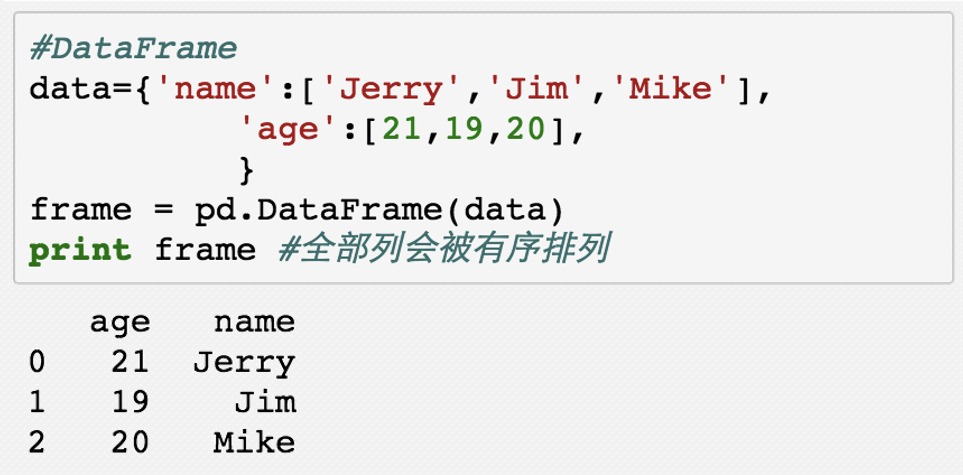
# 需要先安装 pandas
import pandas as pd
# 构建一个序列,指定数据和索引
series = pd.Series(data=[1, 2, 3, 4, 5, 6], index=["a", "b", "c", "d", "e", "f"])
print(series)
# 修改索引
series.index = [0, 1, 2, 3, 4, 5]
print(series)
# 通过字典构建
# 这是字典简写的一种方式,=前为key,=后为value
di = dict(a=1, b=2, c=3)
print(di)
pd_series = pd.Series(di)
print(pd_series)
# 构建DataFrame
users = {
"name": ["张三", "李四", "王五"],
"age": [23, 24, 25]
}
print(users)
df = pd.DataFrame(users)
print(df)
Pandas-Drop
丢弃指定轴上的项: drop方法返回一个在 指定轴上删除了指定值的新对象
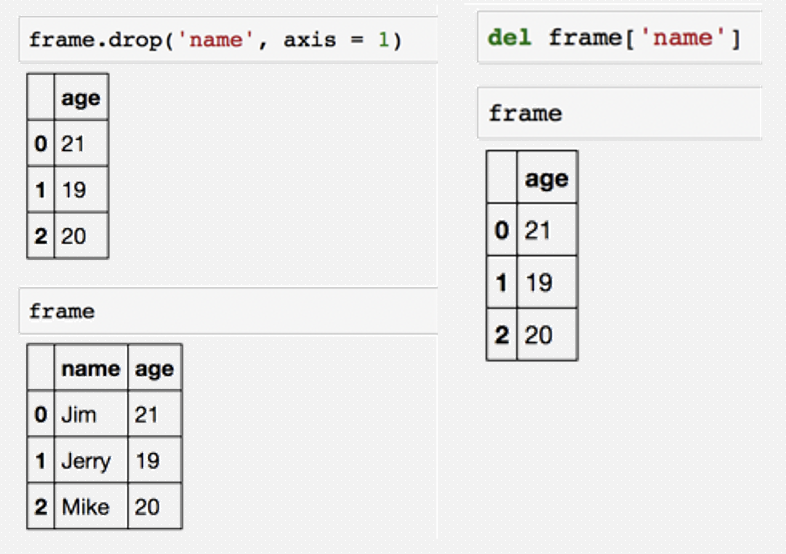
# 导入Pandas包
import pandas as pd
# 构建序列
series = pd.Series(data=[1,2,3,4],index=[0,1,2,3])
print(series)
# 构建DF
df = pd.DataFrame(data={"name":["张三","李四","王五"],"age":[23,24,25]})
# 选择列,df的一个列是一个Series
print(df["name"])
# 删除列,返回新的df
# axis=1 -- 列,axis=0 -- 行
df.drop("name",axis=1)
print(df)
# 删除源df的列
del df["name"]
Pandas-索引,选取,过滤
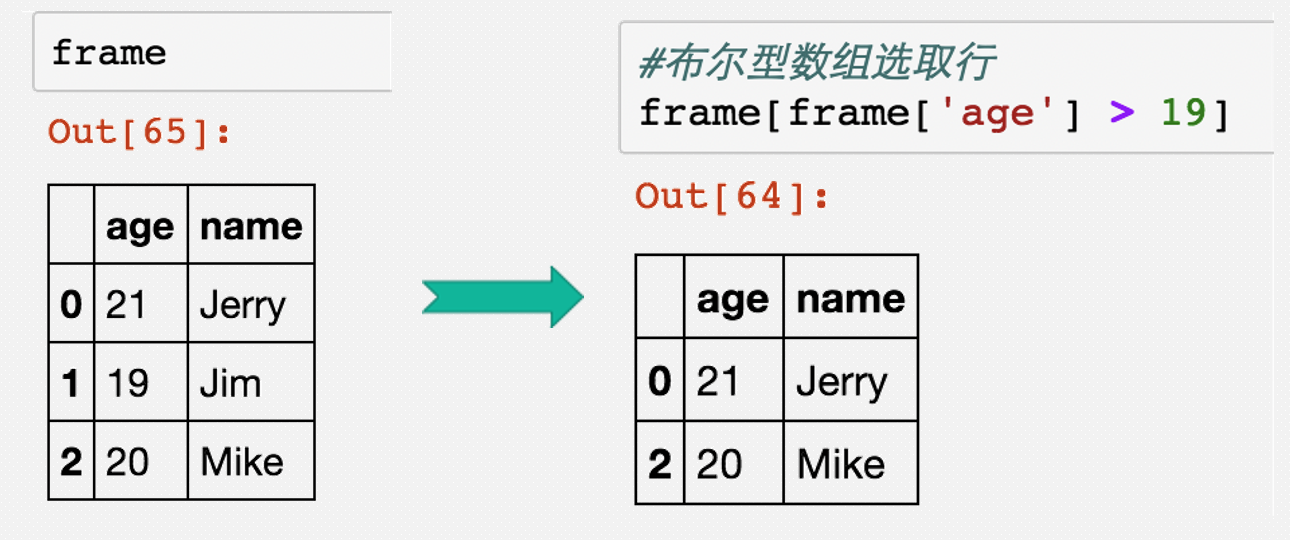
# 导入Pandas包
import pandas as pd
# 构建DF
df = pd.DataFrame(data={"name":["张三","李四","王五"],"age":[23,24,25]})
# 布尔索引,true 的位置保留,false的位置过滤
print(df[df["are"] > 23 ])
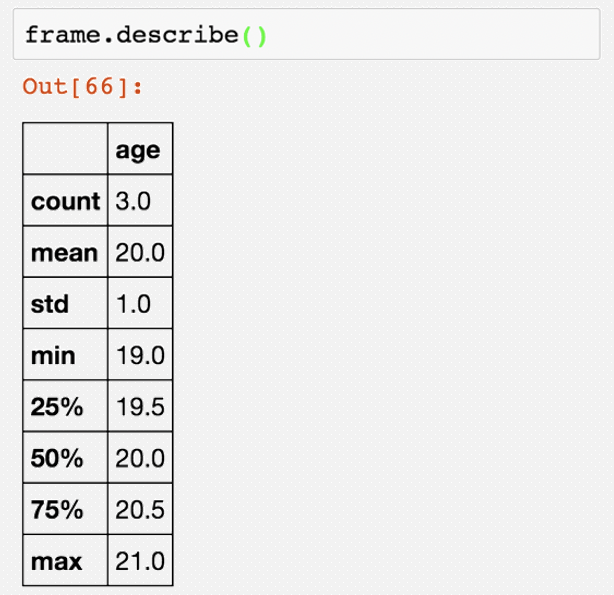
Pandas-汇总计算和描述统计
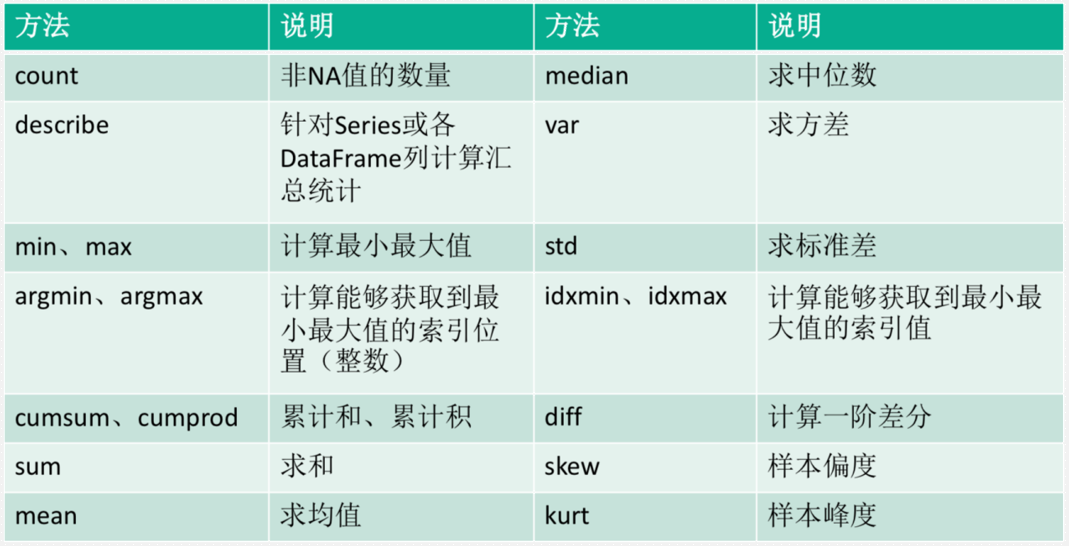
Pandas-汇总
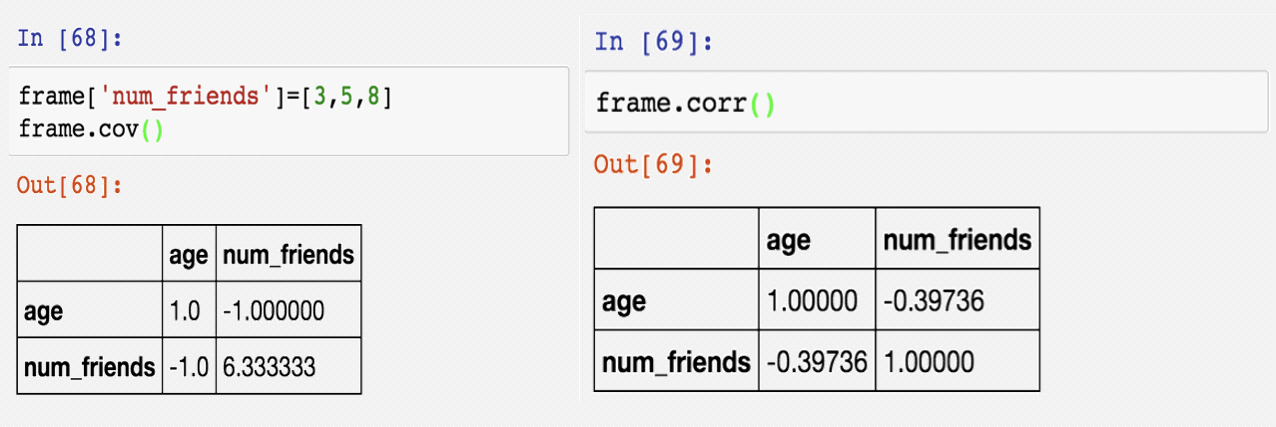
Pandas-描述统计
# 导入Pandas包
import pandas as pd
# 读取CSV格式的数据
student = pd.read_csv("students.txt", #路径
header=None, #没有用做列名的行号
names=["id","name","age","gender","clazz"], #列名
encoding="utf-8", #编码
sep=",") #分割方式
# 对读取的数据做分组统计
# count() -- 将所有的列都进行统计,所以在前面先拿出id,对id进行统计
student.groupby(by="clazz")["id"].count()
# 计算班级的平均年龄
student.groupby(by="clazz")["age"].mean()
# 对表中可以计算的列,进行统计分析(都给你算一遍)
student.describe()
# 计算年龄最小值
min_age = student["age"}.min()
# 保存数据
# 可以to很多格式
min_age.to_csv("min_age.txt",header=None,sep=",")
数据文件操作-文件读取
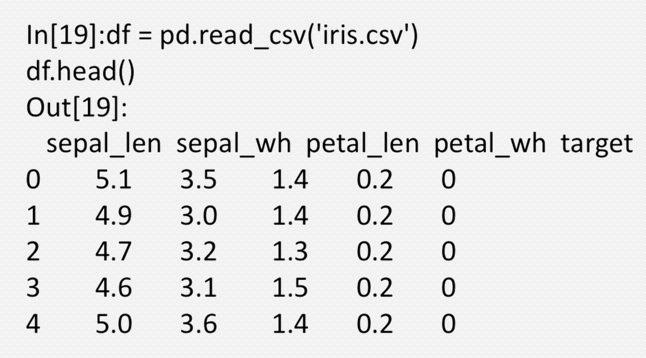
pandas提供了一些用于将表格型数据读取为DataFrame对象的函数,常用的函数为read_csv和read_table
函数的选项可以划分为几个大类
索引:将一个或多个列当做返回的DataFrame处理,以及是否从文件、用户获取列名
类型推断和数据转换:包括用户定义值的转换、缺失值标记列表等
日期解析:包括组合功能,比如将分散在多个列中的日期时间信息组合起来
迭代:支持对大文件进行逐块迭代
不规整数据问题:跳过一些行、页脚、注释或其他一些不重要的东西
文件读取
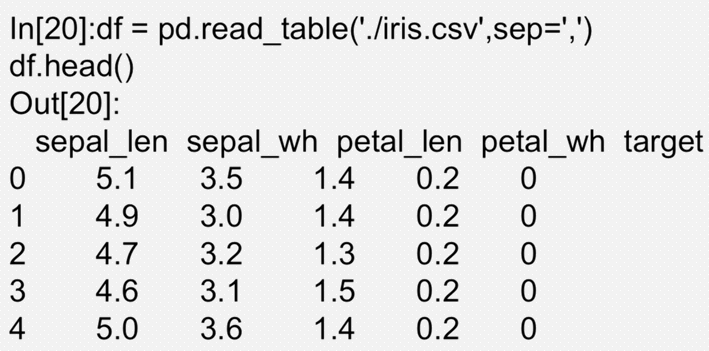
Pandas提供了一些用于将表格型数据读取位DataFrame对象的函数。其中最常用 的为read_csv和read_table。read_csv 从文件、URL、文件型对象中加载带分隔符 的数据。默认分隔符为逗号。read_table从文件、URL、文件型对象中加载带分隔 符的数据。默认分隔符为制表符(“\t”)
使用read_table从文件、URL、文件型对象中加载带分隔符的数据。 默认分隔符为制表符(“\t”)
read_csv/read_table常用参数介绍:
path :表示文件系统位置、URL、文件型对象的字符串
sep/delimiter:用于对行中个字段进行拆分的字符序列或正则表达式
header:用做列名的行号。默认为0(第一行),若无header行,设为None
names:用于结果的列名列表,结合header=None
skiprows: 需要忽略的行数
na_values:一组用于替换NA的值
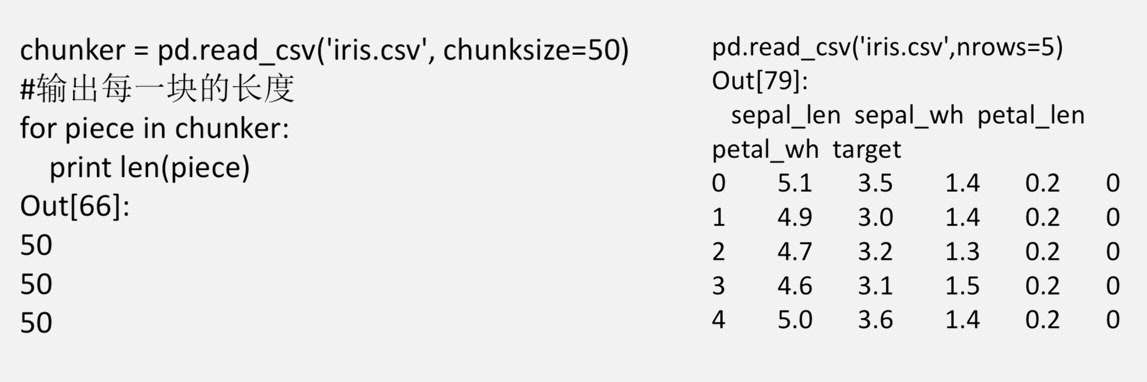
nrows:需要读取的行数(从文件开始处算起)
verbose:打印各种解析器信息,比如“非数值列中缺失值的数量”
encoding:用于unicode的文本格式编码。例如,“utf-8”表示用UTF-8 编码的文本
在处理不规则文件时,skiprows可以帮助跳过文件中的若干行。

可以在读取文件时处理数据中的缺失值,要用到参数na_values。

na_values可以接受一组表示缺失值的字符串,用字典将列的特定值指定为NaN。

在处理较大文件时,有两种方式:通过nrows指定读取的行; 通过设置chunksize,逐块读取
数据文件操作——写出数据
使用to_csv写出数据到文件,默认会写出行和列的标签, 可以设置 index和header选项进行选择。

文件读写小结


处理缺失数据
pandas使用浮点值NaN(Not a Number)表示浮点和非浮点数组 中的 缺失数据,它只是一个便于被检测出来的标记而已;Python 内置的None值也会被当做NA处理

处理缺失值
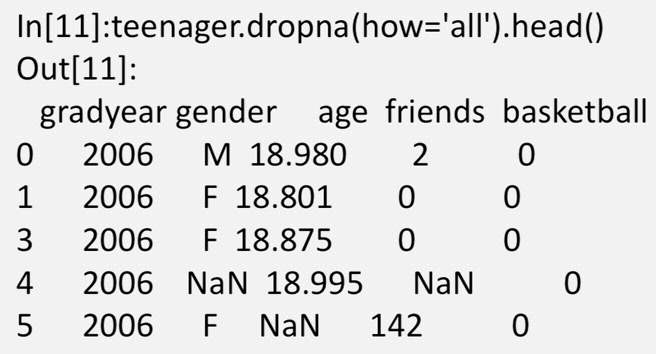
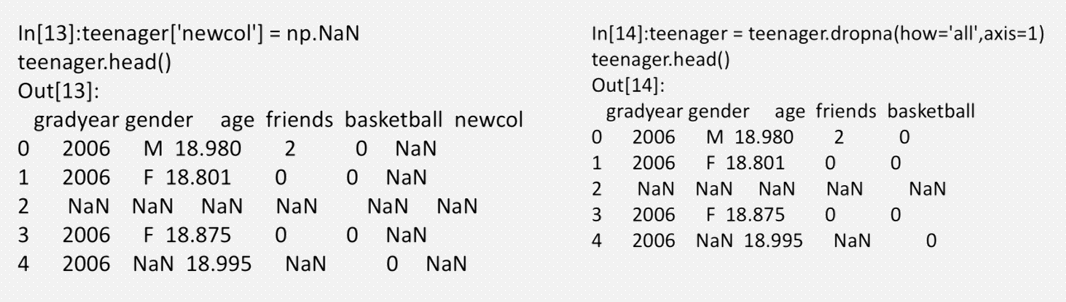
对于DataFrame对象,dropna默认丢弃任何含有缺失值的行, how='all' 只丢弃全为NA的那些行,axis=1指定丢弃列

丢弃数据中全部为缺失值的行。
丢弃数据中全部为缺失值的列。
处理缺失数据
使用fillna方法可以填充缺失数据,并且可以增加不同的选项

使用字典和method方式填充,method=‘ffill’或‘bfill’(前向或后向填 充),limit可以调节最大填充数量

数据标准化
Pandas中并没有提供直接进行数据标准化的方式,可以使用scikit-learn中 preprocessing的方法进行数据的标准化操作。
标准化有两种处理方式:Z-score标准化和min-max标准化。在一些机器 学习算法中(如,支持向量机的RBF核,线性模型中的L1和L2正则化), 算法要求输入的数据特征均值为0,并且方差在相同数量级。这一操作可 以调用preprocessing的scale方法和StandardScaler类实现。
在线性模型的计算过程中,要求输入数据特征在同一个数量级上,为了实 现这一操作,可以调用preprocessing的MinMaxScaler方法。

preprocessing模块提供了StandardScaler工具类,包含名为Transformer 的API,可以在训练集上计算均值和标准差,并且能够在之后将同样的转 换应用于测试集。

preprocessing中提供了MinMaxScalar方法对数据进行[0,1]标准化

数据库风格的DataFrame合并
数据集的合并或连接运算通过一个或多个键将行连接起来 pandas中主要使用merge函数

默认情况下merge会将重叠列的列名当做键,可以显示地用left_on和right_on指定; 连接的时候产生的是行的笛卡尔积,如下面合并结果所示有4个“b”行。

默认情况下,merge做的是“inner”连接,结果中的键是交集,其他方式 还有“left”、“right”以及“outer”

# 导入Pandas包
import pandas as pd
……前面有两个表student,score
# 表关联
join = pd.merge(student,score,how="inner",left_on="id",right_on="stu_id")
# 取前面一部分显示
join.head()
# 取尾部显示
join.tail()
# 当然表关联之后也能进行分组统计
# 按多个字段进行分组
# reset_index() -- 重新生成索引,然后可以进行再次计算
# reset_index():用于在做统计之后,想要看到原始数据,可以通过reset_index()重置
join.groupby(by=["id","clazz"])["sco"].sum().reset_index().groupby(by="clazz")["sco"].mean()
轴向连接
使用concat函数可以将不同的Series或DataFrame进行轴向连接; 传入axis=1可以在列上进行轴向连接

对DataFrame进行轴 向连接也是同样的效 果,有时候行索引是 没有意义的,可以传 入ignore_index=True

数据组合
对数据集进行分组并对各组应用一个函数,这是数据分析过程中的一 个重要环节。在数据集准备好之后,通常的任务就是计算分组统计或 生成透视表。
Pandas提供了一个灵活高效的groupby功能,它使你能以一种自然的 方式对数据集进行切片、切块、摘要等操作。
对数据分组并对各组应用一个函数,是数据分析工作的一个主要环节。 Pandas中对象可以在行(axis=0)或列(axis=1)上进行分组,然后将 一个函数应用(apply)到个分组并产生一个新值。最后所有这些函数 的执行结果会被合并(combine)到最终结果对象中。
下面的例子按照sex进行分组,并计算tip列的平均值。

一次传入多个数组,通过两个键对进行分组,得到的Series具有一个 层次化索引

利用agg()使用自定义聚合函数,一次传入多个聚合函数。

数据处理小结



 浙公网安备 33010602011771号
浙公网安备 33010602011771号