Python 类和模块、Python pip 命令、Windows 中打开隐藏文件夹、python中的字符串拼接
Python 类和模块
这里的模块就是包的意思
模块介绍
内置电池(batteries included) -- 可以直接用
基础代码库,覆盖了网络通信、文件处理、数据库接口、图形系统、XML处理
第三方工具包 -- 需要安装才能用
• Pandas:数据处理与分析
• Numpy:科学计算
• Scikit-learn:基于SciPy和Numpy的开源机器学习模块
• Tensorflow:深度学习框架
Python pip 命令
在Python中是通过 pip 命令安装和管理第三方的包
我们可以看一下这个命令在哪里
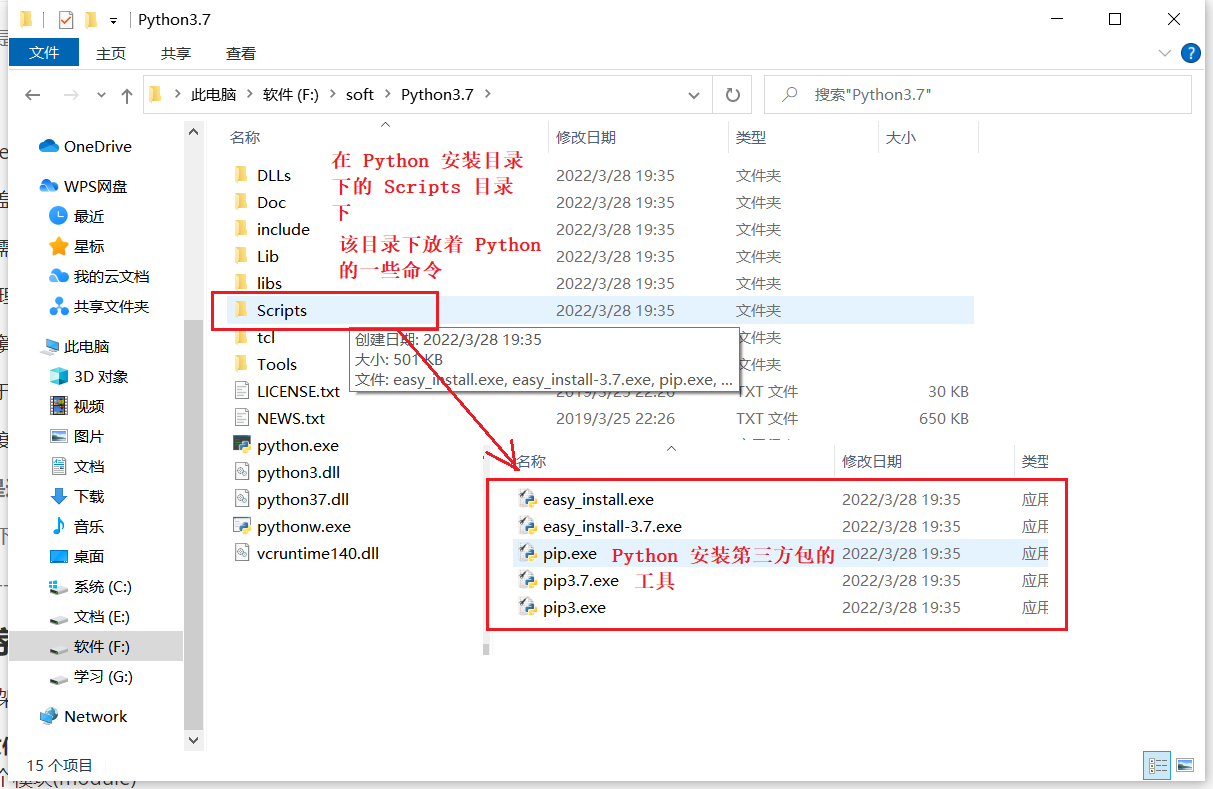
使用 pip 命令安装和管理第三方的包:在DOS命令行窗口中输入 pip install 第三方包名
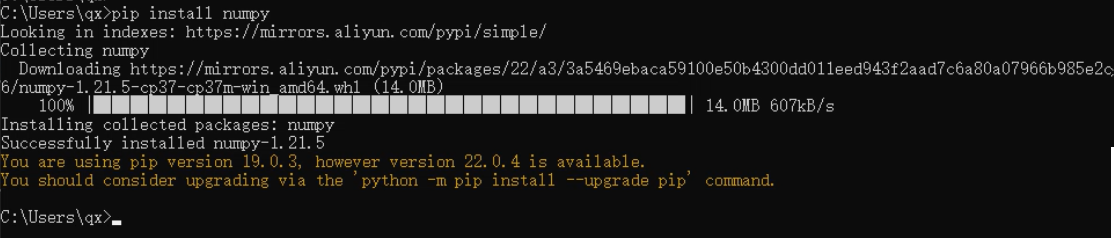
安装完之后 PyCharm 会自动建立索引
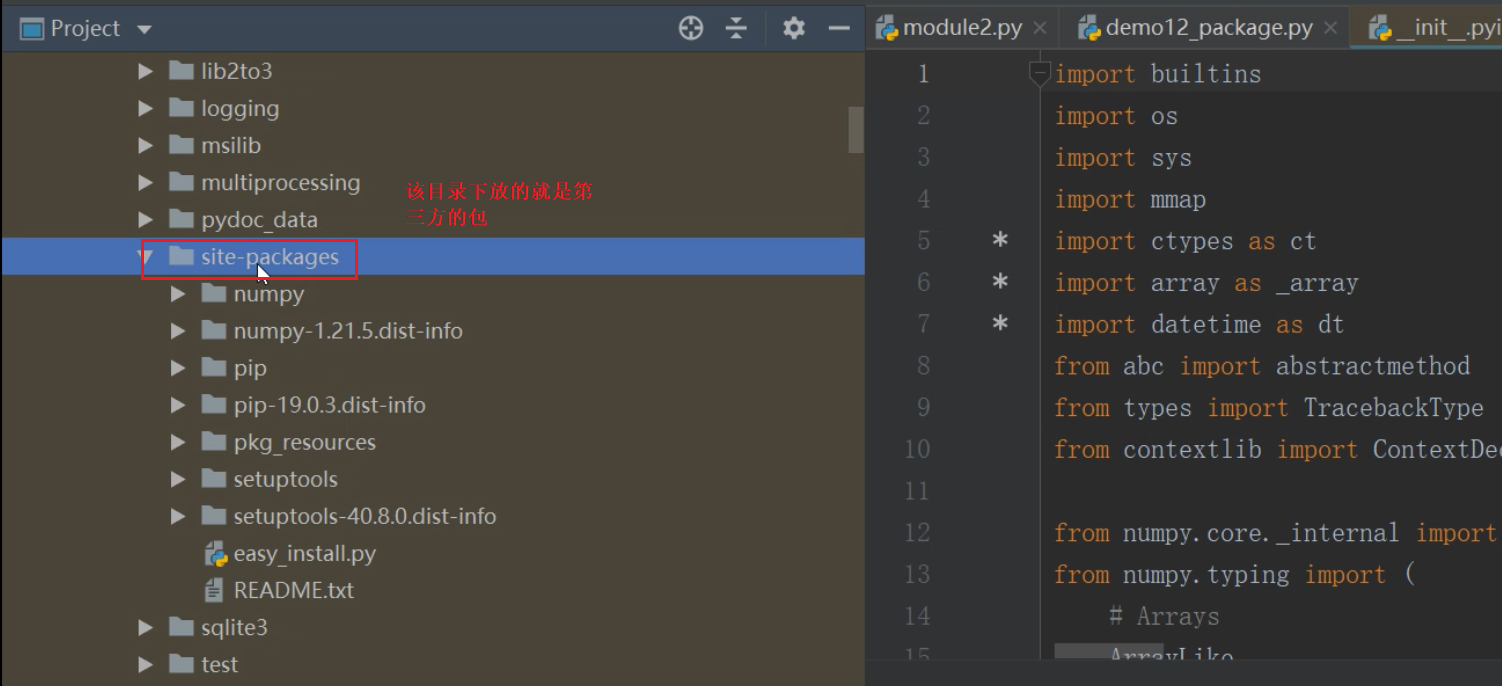
pip 命令换源
不换源的话是从国外下载,很卡很慢
pip 修改 pip 源
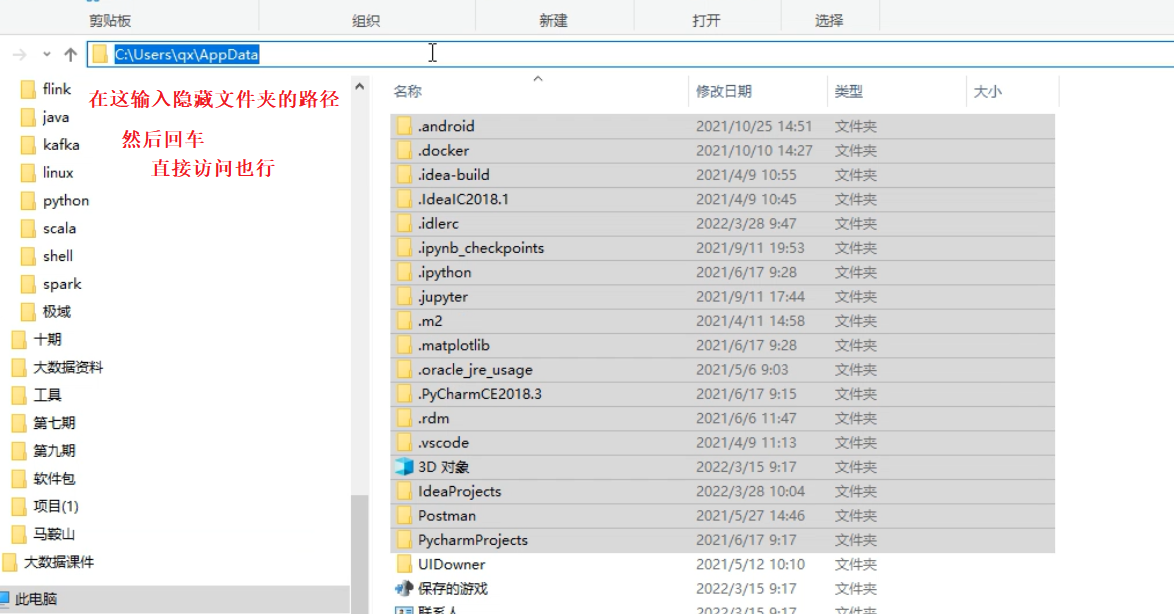
找到系统盘下C:\Users\用户名\AppData\Roaming(APPData可能是隐藏文件,需要将隐藏关闭)
查看在Roaming文件夹下有没有一个pip文件夹,如果没有自己创建一个;
进入pip文件夹,创建一个pip.ini文件;
使用记事本的方式打开pip.ini文件,写入:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
上面是永久修改,这边为临时修改
pip的源有很多(可以去百度找),这里使用的是清华大学的源
在DOS命令行中使用 -i 指定一个参数即可
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy
卸载包
pip uninstall 第三方包名
然后可以装一下下面两个包 -- 做数据处理的工具
pip install numpy
pip install pandas
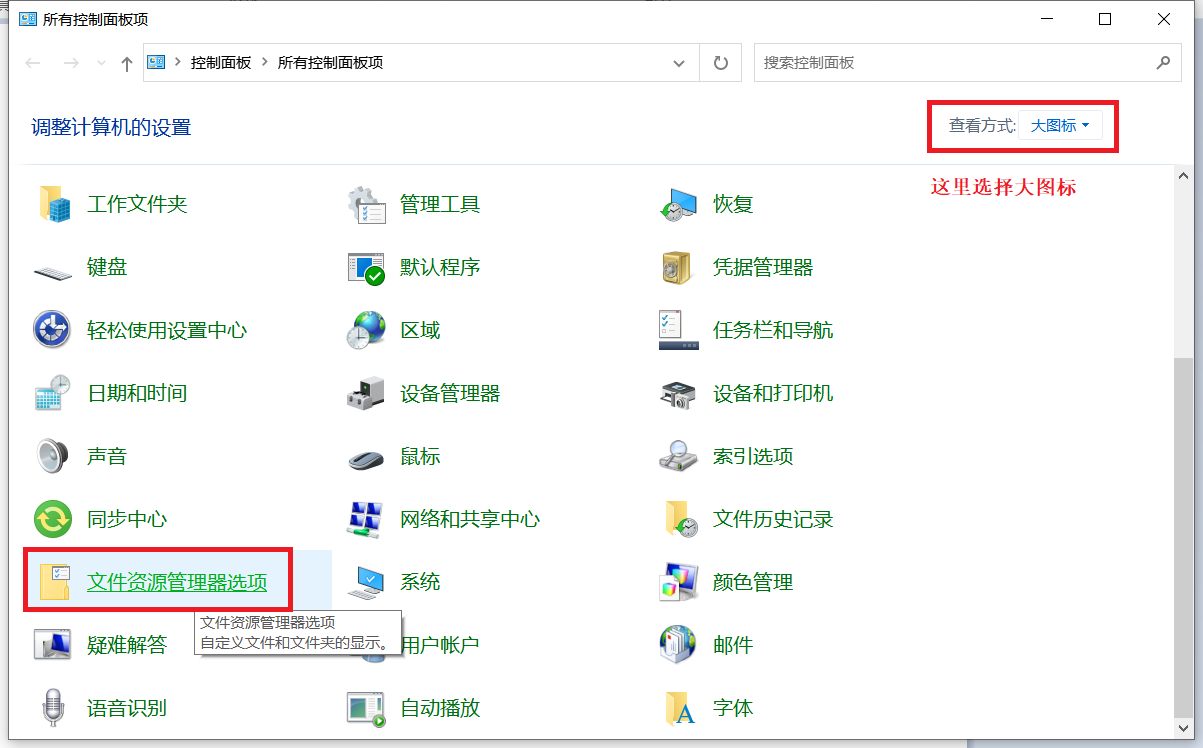
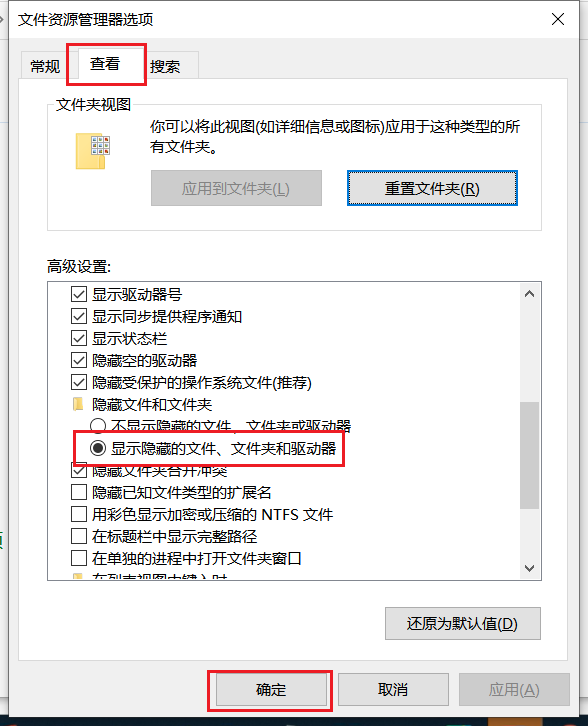
Windows 中打开隐藏文件夹
方式一:
方式二:
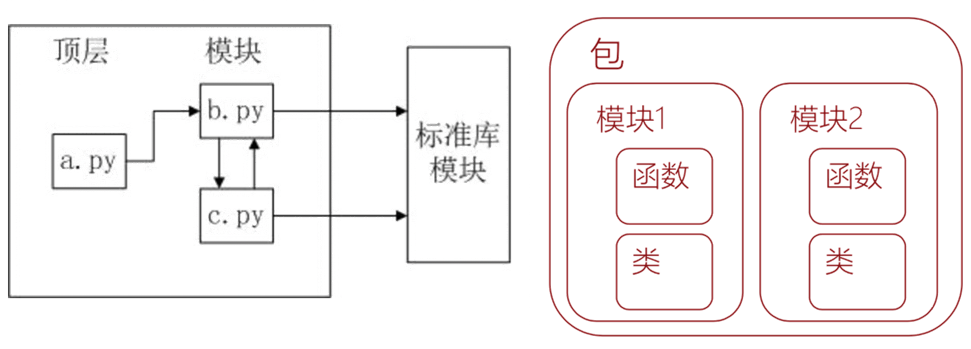
Python程序的架构
Python程序的构架指:将一个程序分割为源代码文件的集合以及将这些部分连接在一起的方法
Python源代码文件: *.py
一个py文件是一个模块(module)
多个模块可以组成一个包(package)
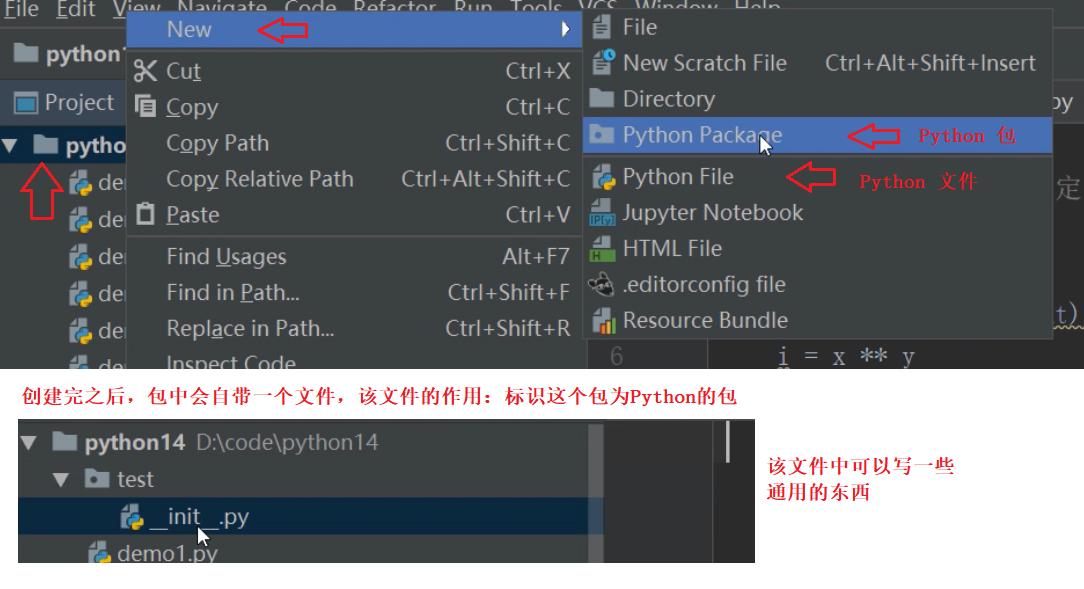
在IDEA中创建Python包
模块的执行环境
模块的执行环境:模块包含变量、函数、 类以及其他的模块(如果导入的话), 而函数也有自己的本地变量
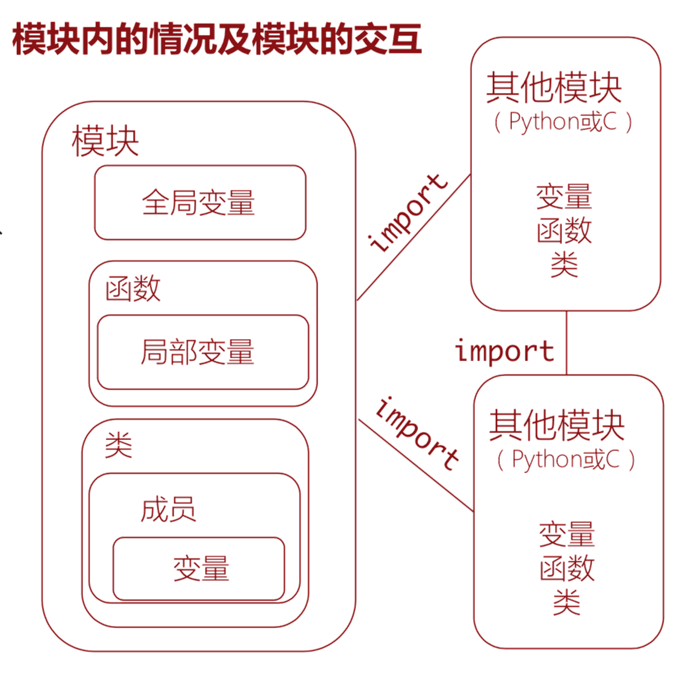
模块的作用
模块是Python中的最高级别组织单元,它将程序代码和数据封装起来以便重用
模块的三个角色:
-
代码重用
-
系统命名空间的划分(模块可理解为变量名 的封装,即模块就是命名空间)
-
实现共享服务和数据
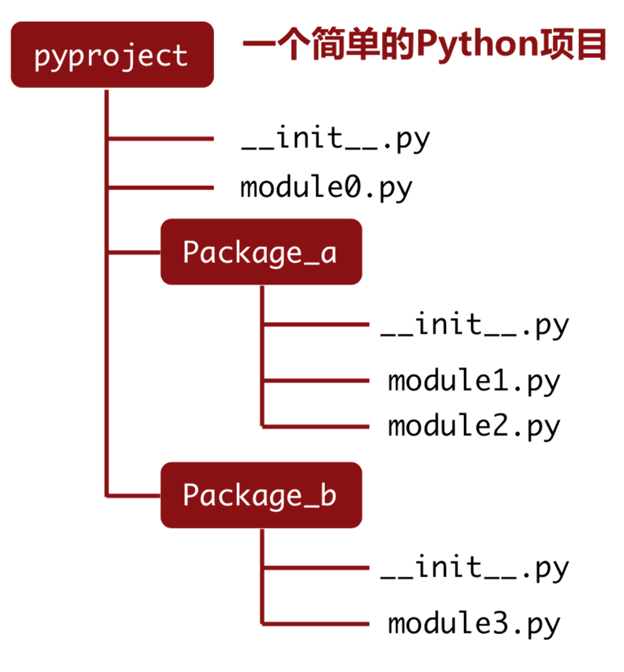
模块的导入
导入从本质上讲,就是在一个文件中载入另一个文件,并且能够读取那个文件的内容。一个模块内的内容通过这样的方法其属性(object,attribute)能够被外界使用
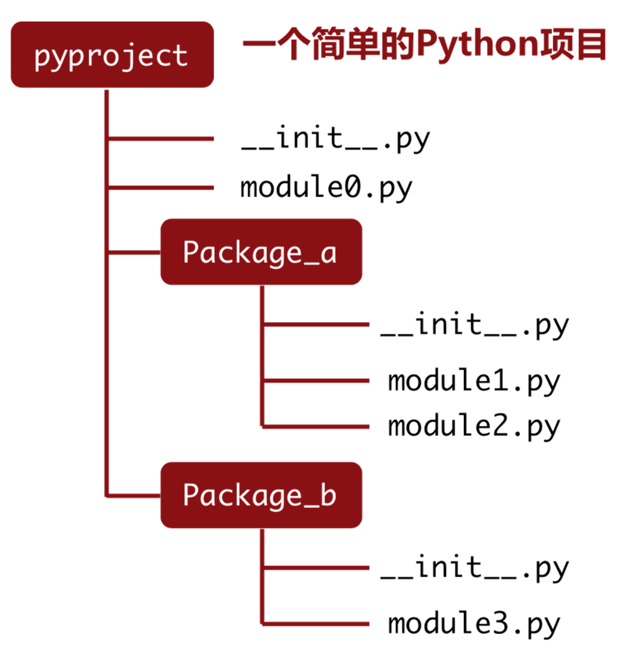
模块导入方式

导入整个模块
模块的方式非常简单,在"import"后加上"模块名称"就可以了

通过这一句,计算机就在指定的位置找到了"numpy.py"文件,并准备好该文件 拥有的之后会用到的函数和属性。在导入"numpy"后,我们就可以通过点符号 "."连接模块名称和函数名,使用该模块中的函数和属性。

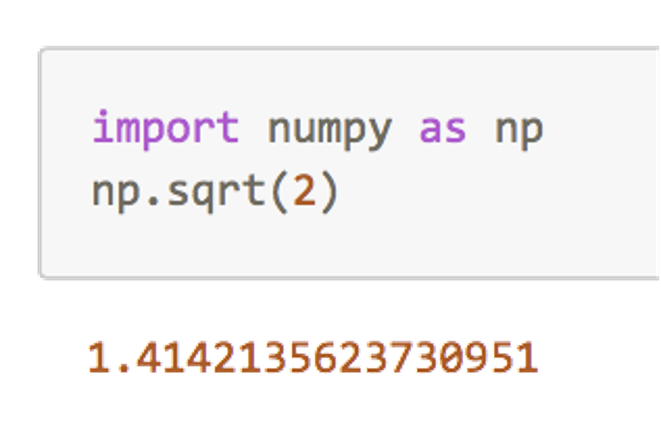
别名
指定的方式是采用"import 模块名称 as 别名"。我们可以将"numpy"简记为 "np",并且在调用时,直接使用"np"就可以:
只导入某个对象
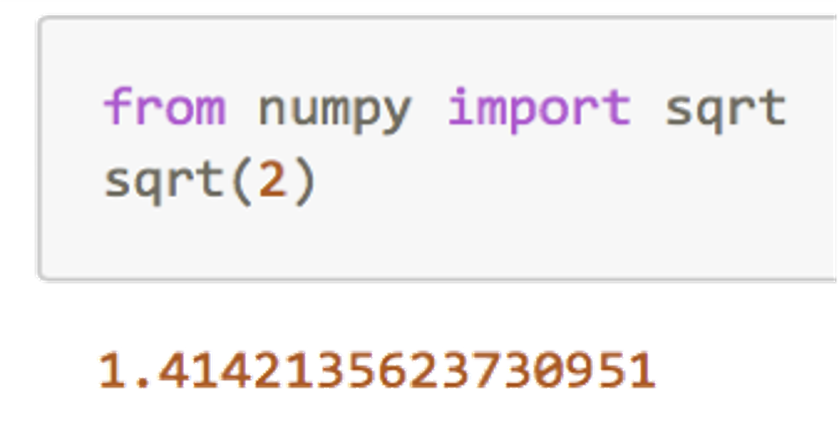
此过程的实现方式是“from 模块名称 import 函数名称",但是要注意我们 只拿到了某个具体的工具,而没有拿到整个工具箱
引入其它的包或者模块代码示例
# test 包中的 _init_.py 文件
# 在包被引用的时候会第一个执行
print("__init__.py")
# 将需要批量导入的模块放在里面
__all__ = ["module1", "module2"]
# test 包中的 module1.py
print("module1.py")
def fun1(x, y):
return x * y
a = 100
# test 包中的 module2.py
def fun2(x, y):
return x ** y
# 引入其它的包或者模块
# 引入模块,需要取别名 -- 导入包下面的单个模块
# import test.module1 as m1
# print(m1.fun1(10, 20))
# 导入模块下所有的东西
# python中导入模块实际上就是将模块的代码全部执行一遍
# from test.module1 import *
# from test.module1 import fun1
#
# print(fun1(10, 20))
#
# print(a)
# 导入包下面所有的模块, 需要在 __init__ 文件中增加 __all__
from test import *
print(module1.fun1(10, 2))
print(module2.fun2(10, 2))
# 直接导入整个包 , 需要在 __init__ 文件中增加 __all__
import test
import test as t # 直接导入整个包时,也可以取别名
print(t.module1.fun1(10, 2))
import sys
# python 搜索包的位置
for p in sys.path:
print(p)
代码中的类和对象
__init__(): 相当于 java 中的构造函数self : 相当于 java 中的 this
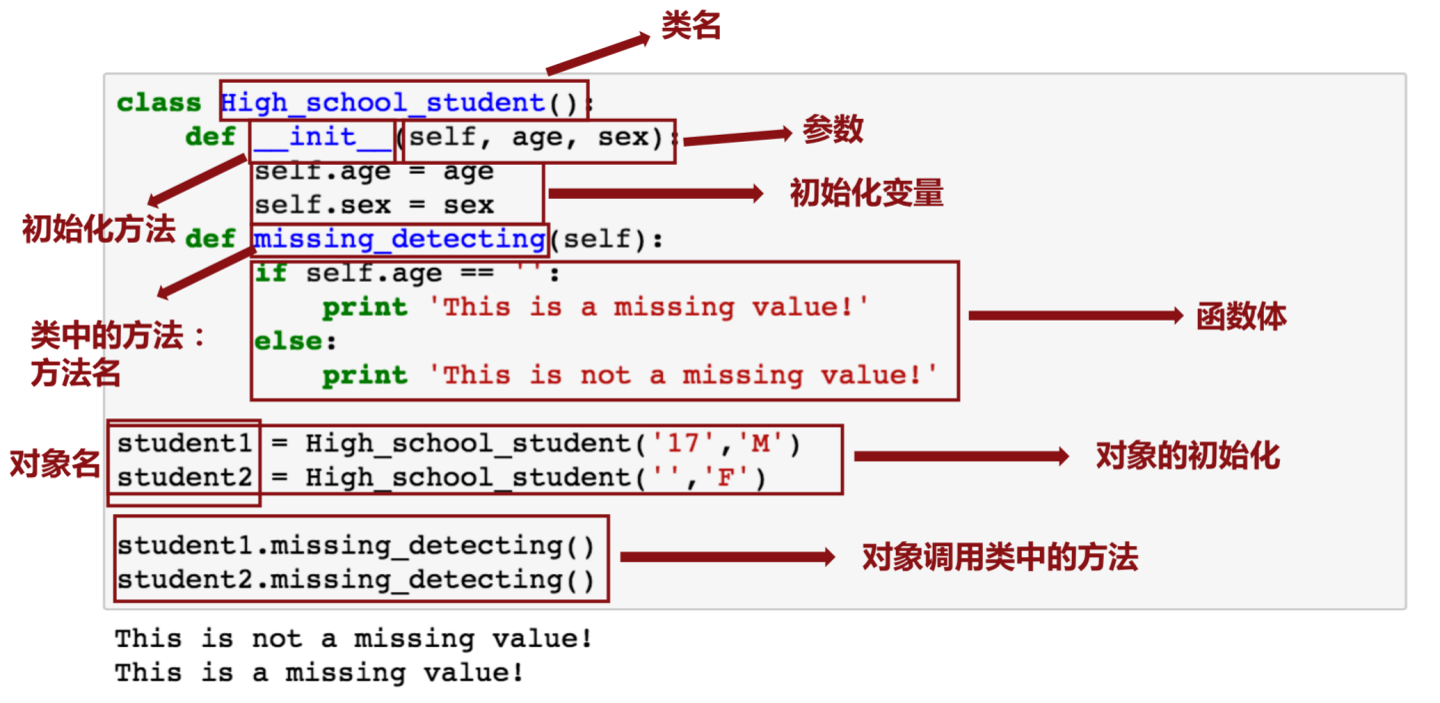
类的创建
用 class 类名 即可以创建一个类
在类名的程序块中可以定义这个类的属性、方法等等

创建实例
创建相应的实例
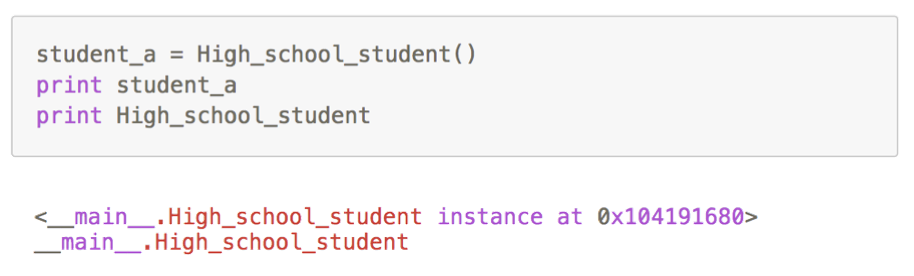
查看实例属性
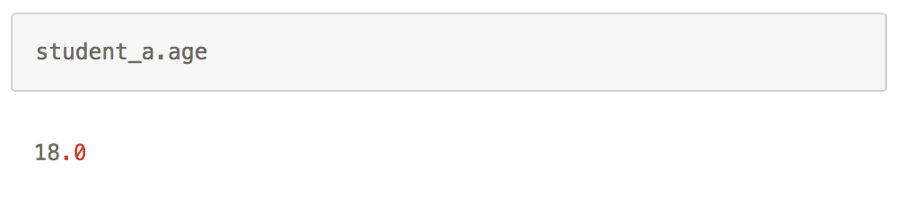
初始化方法__init__方法
__init__是一种特殊的方法,使得实例一开始就拥有类模板所具有的属性
self参数是类中函数定义时必须使用的参数,并且永远是第一个参数,该参数表示创建的实例本身

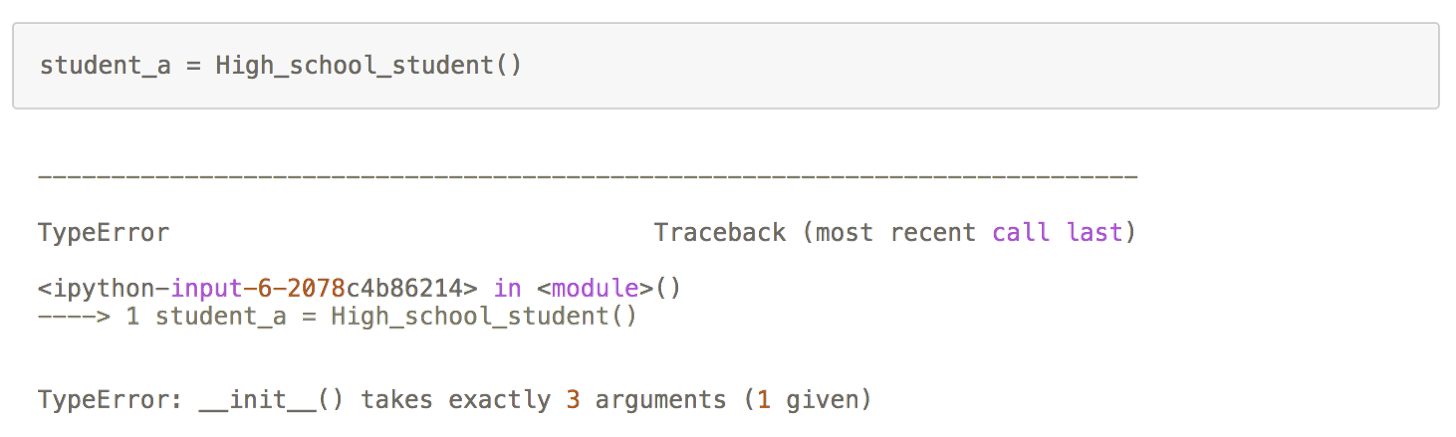
正确的初始化对象
一旦__init__存在除了"self"之外的参数,那么在创建实例 "student_a"时,我们就需要传入相应的参数值(不过"self"不需要传入数值,Python解释器会自动将实例变量传入)
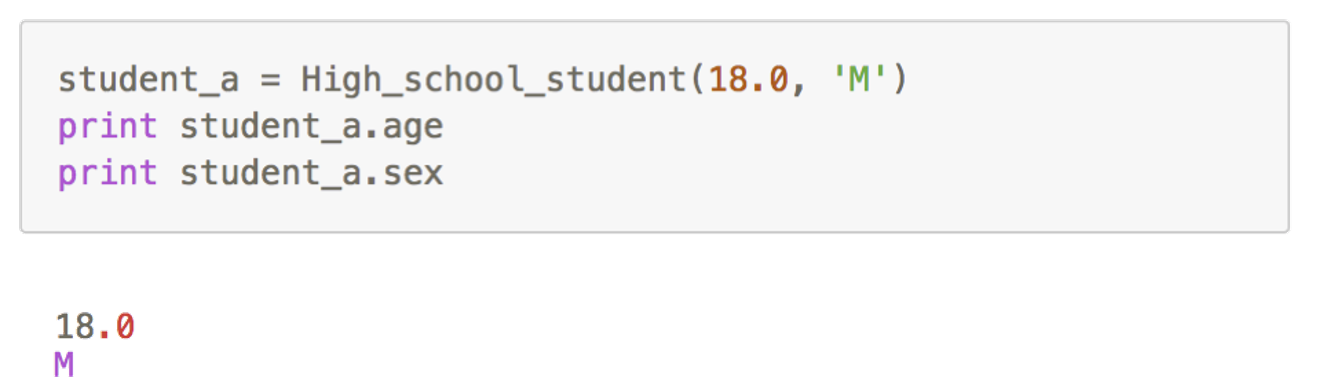
• 如果我们传入了两个参数—— 18 与 M,则我们可以成功创建一个高中生对象,这个高中生的年龄是18,性别是M
• 我们可以不断创建拥有不同年龄与性别的高中生对象实例
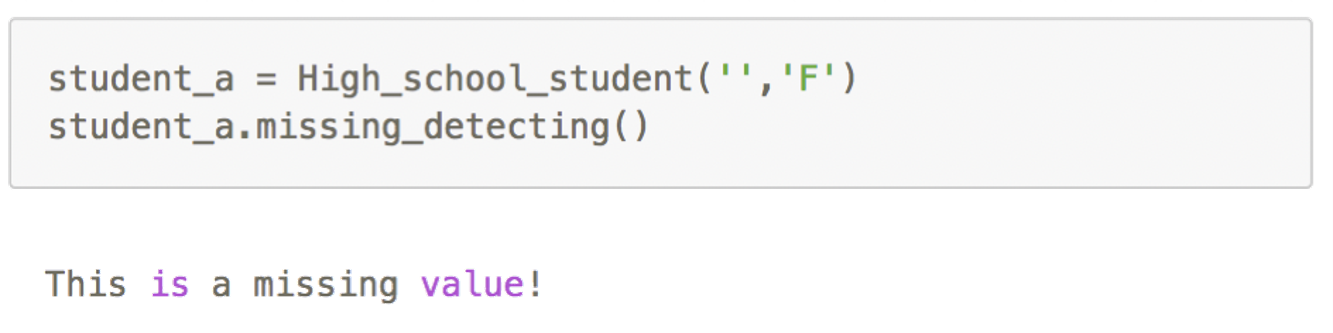
自定义检测缺失值的方法
检测实例对象中的 age 属性是否为缺省值,自定义相应的 missing_detecting 方法

使用自定义的类方法
类中的方法的第一个参数必须为 self 。下面我们首先创建实例 student_a ,然 后调用"missing_detecting"方法:
__init__方法中导入数据
在每一次创建实例的时候,自动导入数据,并且定义与数据有关的变量

成员的私有化
面向对象的语言一般都对对象有一些统一的要求。例如封装性。
封装性的意思是指,一个对象的成员属性要得到一定程度的保护。例如,要对一个 对象的成员属性进行修改或访问,就必须通过对象允许的方法来进行(例如要求输 入密码以确认拥有此权限等)。这样可以保护对象,使程序不易出错。
C++与Java语言中,严格地实现了对象的封装性。
对象的封装性
例如在上面的 High_school_student 类中,虽然数据已经被封装在类里面,但 是我们还是可以通过外部访问其中的变量。我们可以在外部对 age 进行修改:
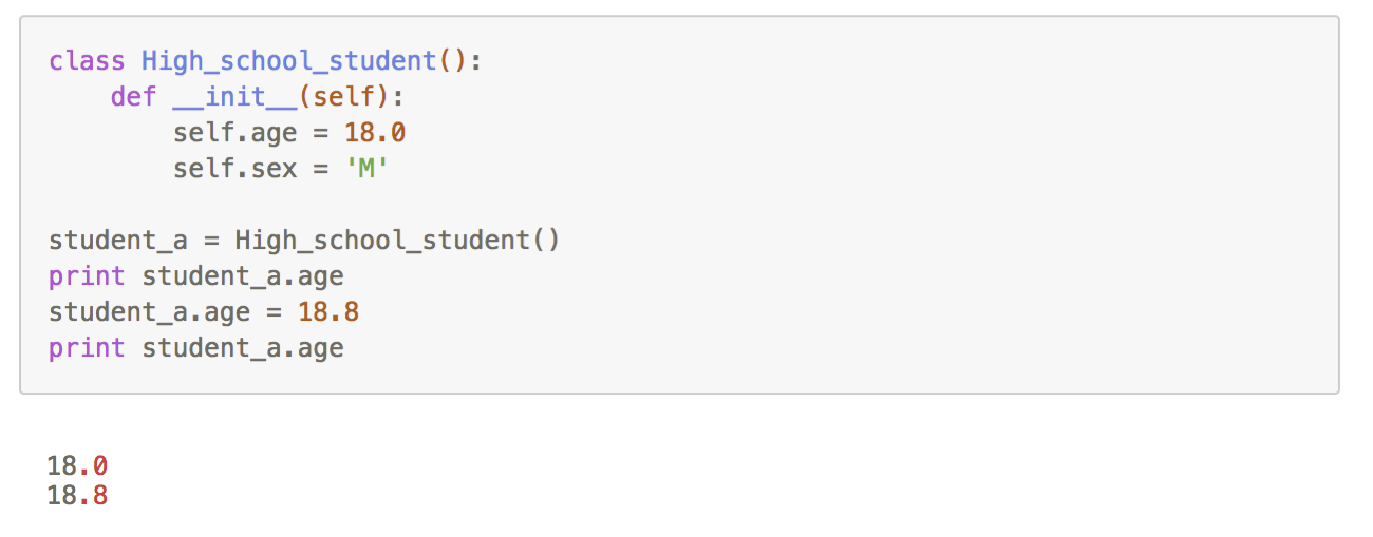
私有化
如果我们希望某些内部属性不被外部访问,我们可以在属性名称前加上两个下划线"__" 表示将该属性成员私有化,该成员在内部可以被访问,但是在外部是不能够访问的。
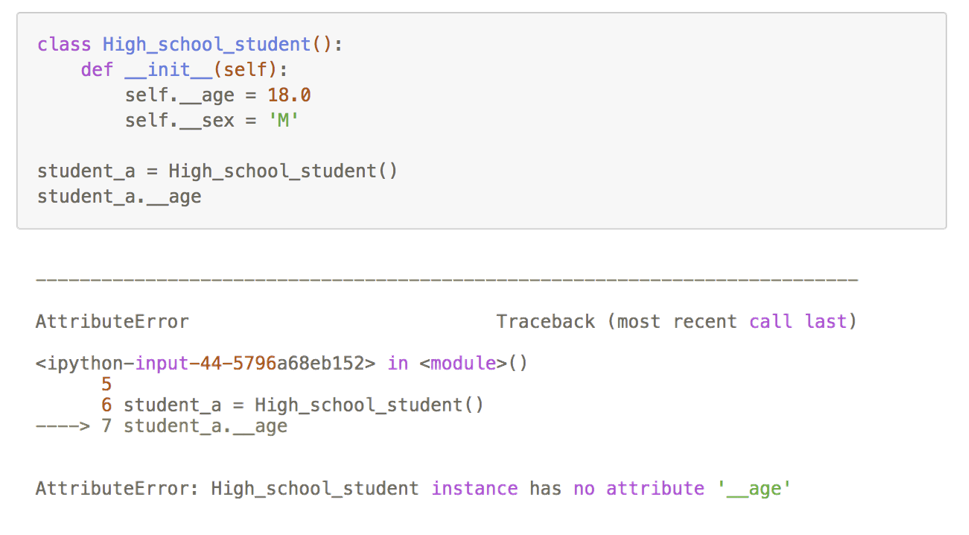
成员私有化不仅包括属性的私有化,也包括了方法的私有化,在方法名称前加上 __ 也可以使得函数只能被内部访问,不能够被外部访问:
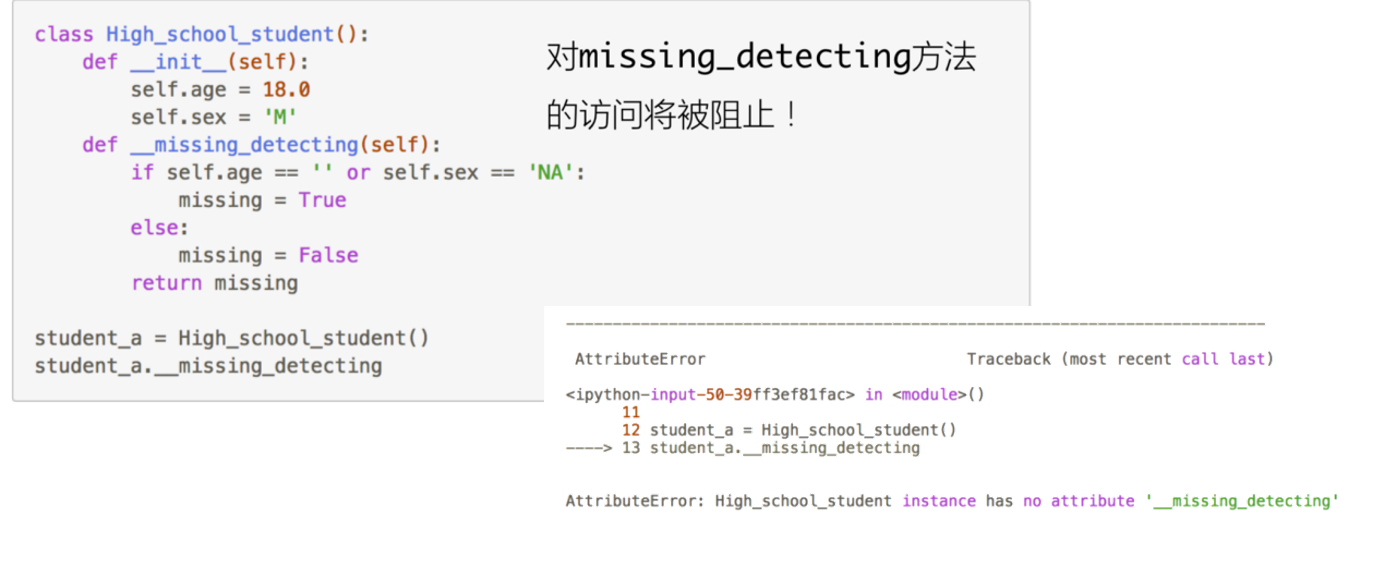
# 定义类
class Student():
# 初始化函数,相当于构造函数
# self 相当于java中的this
# id: str, name: str, age: int, gender: str, clazz: str = "一班" -- 构造函数的参数
# clazz: str = "一班" -- 参数的默认值,如果该参数不是最后一个参数,则给定默认值的时候,其后面的参数也需要给定默认值
def __init__(self, id: str, name: str, age: int, gender: str, clazz: str = "一班"):
print("初始化")
# 给成员变量赋值, 赋值即定义
self.id = id
# 成员变量的私有化,不能在外面访问
self.__name = name
self.age = age
self.gender = gender
self.clazz = clazz
# 普通方法
def print(self):
# 在类的内部调用私有化方法
str = self.__mk_str()
print(str)
# 方法私有化
def __mk_str(self):
# python中的字符串拼接
# "%s\t%s\t%d\t%s\t%s" -- 相当于字符串拼接格式,%s:相当于被拼接的字符串
# (self.id, self.__name, self.age, self.gender, self.clazz) -- 这里的值一一对应到前面的 %s 或 %d
# %s -- 对应字符串,%d -- 对应数字
str = "%s\t%s\t%d\t%s\t%s" % (self.id, self.__name, self.age, self.gender, self.clazz)
return str
# 创建类的对象
student1 = Student("001", "张三", 23, "男", "一班")
# 调用对象的方法
student1.print()
# 修改属性的值
student1.age = 24
student1.print()
# 获取属性的值
print(student1.age)
# clazz给定默认值之后
student2 = Student("002", "李四", 22, "男")
student2.print()
python中的字符串拼接
类的继承
与封装性一样,继承性是面向对象程序设计的另一种重要的属性。
类的继承好比孩子与父母之间的继承关系一样,孩子拥有父母所拥有的许多 特性。在编程语言中,如果一个新的类继承另外一个类,那么这个新的类成 为子类(Subclass),被子类继承的类称为父类
我们可以把更加一般、范围大的类的属性在父类定义,把更加具体、范围小 的特点在子类定义。
定义子类
在定义好High_school_student后,可以定义两个子类Male_student与 female_student继承它
pass 关键字:占位的意思,如果一个类中没有代码,也不能空着,需要通过 pass 关键字占个位置,不然代码会报错
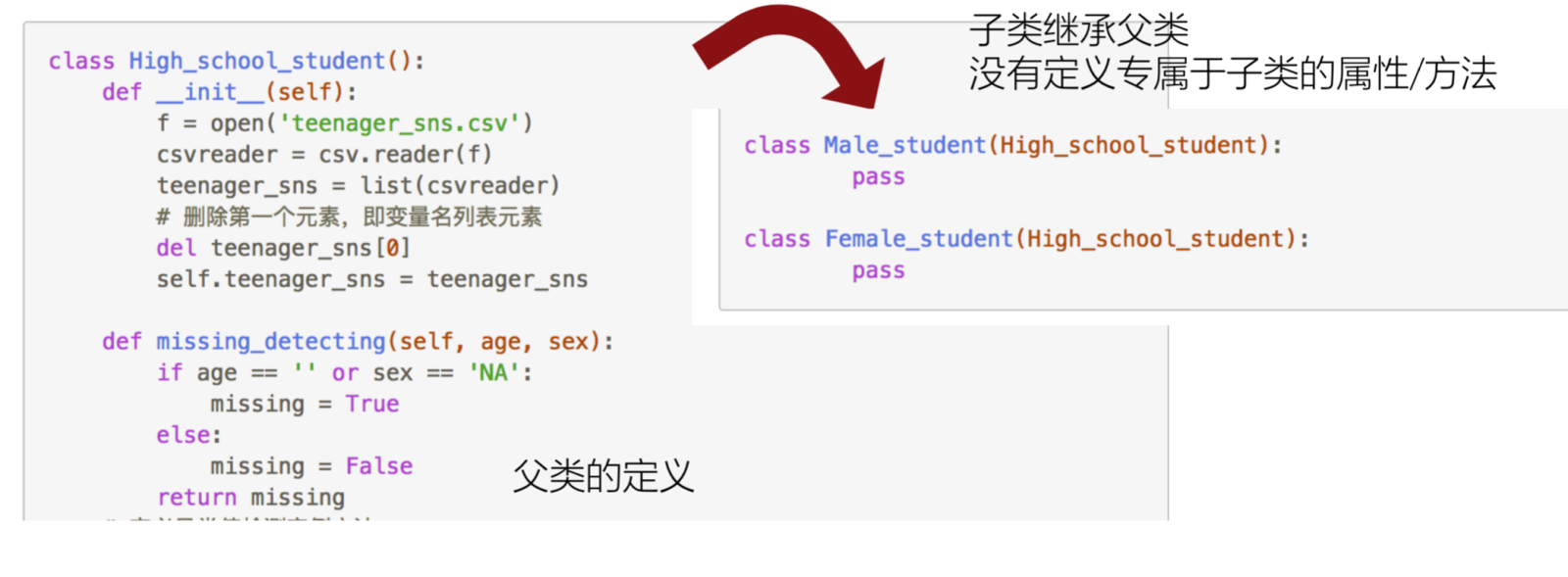
子类继承父类属性及实例化方法
子类 Male_student 的实例 male_student 继承了父类的初始化属性 self.teenager_sns

同样的,子类也继承 missing_detecting 和 outlier_detecting 两个 实例方法:
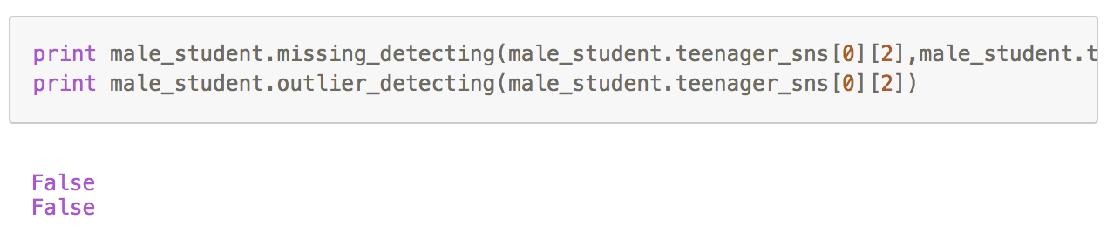
比如,我们试试在子类中也定义一个 missing_detecting 方法:

然后试试创建子类实例并调用 missing_detecting 方法:

可以看出这里我们用的是子类的missing_detecting,而 不是父类的missing_detecting!
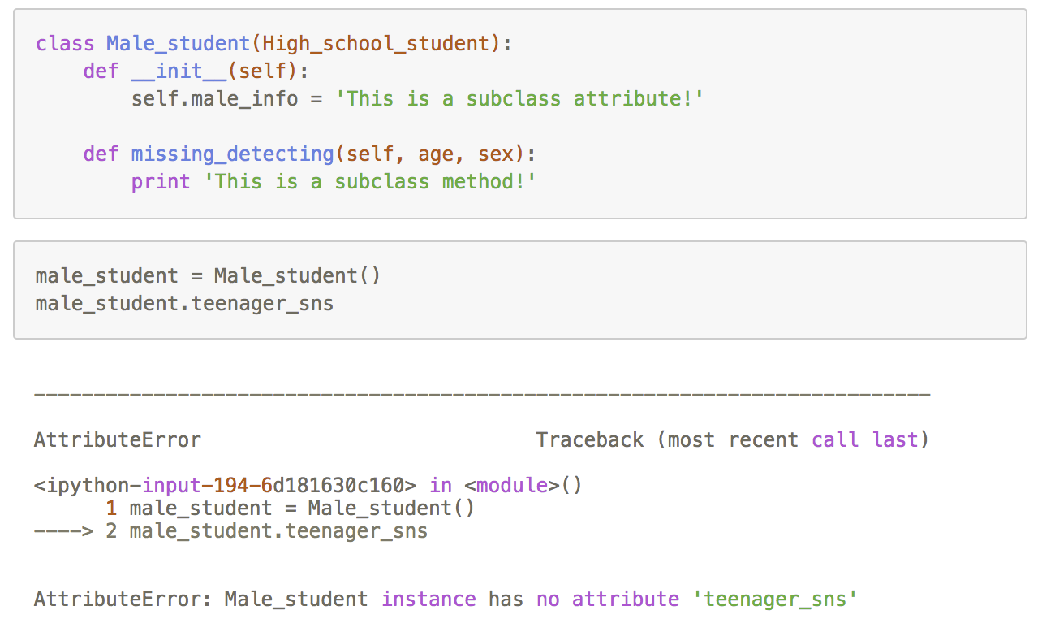
子类中定义__init__方法
如果不注意继承性的这个特点,有可能导致错误!
class Person():
def __init__(self, name, age):
self.name = name
self.age = age
def print(self):
print("Person", self.name, self.age)
# 继承父类,会将父类所有的东西都继承过来
class Student(Person):
# 如果这个类中什么都不写,需要用 pass 占个位置,不然会报错
# pass
# 重写父类的方法
def print(self):
print("Student", self.name, self.age)
# 父类的引用指向子类的对象 -- 多态
student: Person = Student("张三", 23)
student.print()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号