


Flink 流表的 join、开启 MySQL binlog
目录
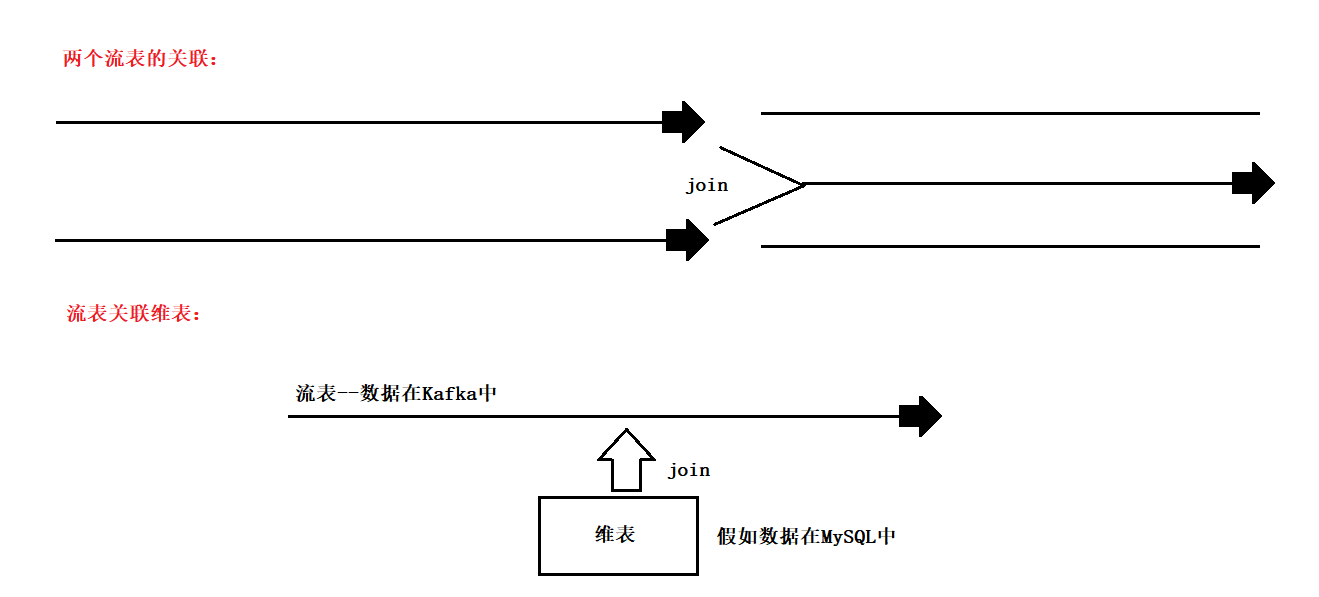
Flink 流表的 join
1、Regular Joins
常规联接
常规联接是最通用的联接类型,其中任何新记录或对联接输入任一侧的更改都是可见的,并且会影响整个联接结果。例如,如果左侧有一条新记录,则该记录将与右侧的所有先前和将来的记录合并。
但是,此操作具有重要含义:它需要将连接输入的两端永久保持在 Flink 状态。因此,如果一个或两个输入表持续增长,则资源使用量也将无限增长。
两边表的数据都会以flink状态的形式保存起来,如果表持续增长,会导致flink状态放不下,会出问题
Flink SQL shell 示例
CREATE TABLE student_join (
id String,
name String,
age int,
gender STRING,
clazz STRING
) WITH (
'connector' = 'kafka',
'topic' = 'student_join',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'asdasdasd',
'format' = 'csv',
'scan.startup.mode' = 'latest-offset'
)
CREATE TABLE score_join (
s_id String,
c_id String,
sco int
) WITH (
'connector' = 'kafka',
'topic' = 'score_join',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'asdasdasd',
'format' = 'csv',
'scan.startup.mode' = 'latest-offset'
)
select a.id,a.name,b.c_id,b.sco
from student_join a
inner join
score_join b
on a.id=b.s_id
select a.id,a.name,b.c_id,b.sco from
student_join a
left join
score_join b on a.id=b.s_id
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic student_join
1500100001,施笑槐,22,女,文科六班
1500100002,吕金鹏,24,男,文科六班
1500100003,单乐蕊,22,女,理科六班
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic score_join
1500100001,1000001,98
1500100001,1000002,5
1500100001,1000003,137
1500100001,1000004,29
1500100001,1000005,85
1500100001,1000006,52
1500100002,1000001,139
1500100002,1000002,102
2、Interval Joins
间隔连接
与常规联接操作相比,这种联接仅支持具有 time 属性的仅追加表。由于时间属性是准单调递增的,Flink 可以从其状态中删除旧值,而不会影响结果的正确性。
不会保留大量的状态
Flink SQL shell 示例
CREATE TABLE student_Interval_join (
id String,
name String,
age int,
gender STRING,
clazz STRING,
ts TIMESTAMP(3),
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'student_join',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'asdasdasd',
'format' = 'csv',
'scan.startup.mode' = 'latest-offset'
)
CREATE TABLE score_Interval_join (
s_id String,
c_id String,
sco int,
ts TIMESTAMP(3),
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'score_join',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'asdasdasd',
'format' = 'csv',
'scan.startup.mode' = 'latest-offset'
)
select a.id,a.name,b.c_id,b.sco from
student_Interval_join a , score_Interval_join b
WHERE a.id=b.s_id
and a.ts BETWEEN b.ts - INTERVAL '5' SECOND AND b.ts
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic student_join
1500100001,施笑槐,22,女,文科六班,"2020-09-17 15:12:20"
1500100002,吕金鹏,24,男,文科六班,"2020-09-17 15:12:20"
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic score_join
1500100001,1000001,98,"2020-09-17 15:12:22"
1500100002,1000002,5,"2020-09-17 15:12:10"
3、流表和维表关联
Flink SQL shell 示例
-- 维表在数据 mysql 中 无法发现维表更新,维表更新了flink不知道
CREATE TABLE student_mysql (
id String,
name String,
age int,
gender STRING,
clazz STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://master:3306/bigdata?useUnicode=true&characterEncoding=utf-8&useSSL=false',
'table-name' = 'student',
'username' = 'root',
'password'= '123456'
)
-- 流表数据在kafka中
CREATE TABLE score_join1 (
s_id String,
c_id String,
sco int
) WITH (
'connector' = 'kafka',
'topic' = 'score_join',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'asdasdasd',
'format' = 'csv',
'scan.startup.mode' = 'latest-offset'
);
select a.id,a.name,b.c_id,b.sco from
score_join1 b
left join student_mysql a
on a.id=b.s_id
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic score_join
1500100001,1000001,98
1500100002,1000002,5
1500100001,1000003,137
1500100004,1000004,29
---使用mysqlcdc关联维表
-- 可以实时发现维表更新
需要将 flink-sql-connector-mysql-cdc-1.1.0 上传到 flink 的lib目录下
需要重启yarn-session,flink-sql-client
mysql cdc
1、先进行全量表读取
2、再通过监控 mysql 的 binlog 日志实时读取新的数据 (binlog默认没有开启)
CREATE TABLE student_mysql_cdc (
id String,
name String,
age int,
gender STRING,
clazz STRING
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'master',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'bigdata',
'table-name' = 'student'
)
select a.id,a.name,b.c_id,b.sco from
score_join1 b left join student_mysql_cdc a
on a.id=b.s_id
kafka-console-producer.sh --broker-list master:9092 --topic score_join
1500100001,1000001,98
1500100001,1000002,5
1500100001,1000003,137
1500100001,1000004,29
1500100001,1000005,85
1500100001,1000006,52
1500100002,1000001,139
1500100002,1000002,102
1500100003,1000002,102
1500100006,1000002,102
1,1000002,102
2,1000002,102
开启 MySQL binlog
修改my.cnf
vim /etc/my.cnf
在[mysqld]下增加几行配置,如下
[mysqld]
# 打开binlog
log-bin=mysql-bin
# 选择ROW(行)模式
binlog-format=ROW
# 配置MySQL replaction需要定义,不要和canal的slaveId重复
server_id=1
改了配置文件之后,重启MySQL,使用命令查看是否打开binlog模式:
service mysqld restart
show variables like 'log_bin';


 浙公网安备 33010602011771号
浙公网安备 33010602011771号