



Flink Connectors、假如遇到报错显示不能使用该字段名、Flink 处理 json 数据、解决maven项目依赖包冲突的问题
目录
Flink Connectors
通过 Flink SQL 读 Kafka 写 MySQL
package com.shujia.flink.table
//只写SQL的情况下
//这边就不需要将最后面的改为 _ 了
//若是涉及到算子的时候需要改
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.EnvironmentSettings
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
object Demo3FLinkSqlOnKafka {
def main(args: Array[String]): Unit = {
//创建 flink 环境
val bsEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
bsEnv.setParallelism(1)
//设置 table 环境的一些参数
val bsSettings: EnvironmentSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner() //使用blink计划器
.inStreamingMode() //流模式
.build()
// 创建flink table 环境
val bsTableEnv: StreamTableEnvironment = StreamTableEnvironment.create(bsEnv, bsSettings)
/*
mary,2022-03-25 10:30:05,/home
mary,2022-03-25 10:30:06,/admin
mary,2022-03-25 10:30:07,/login
mary,2022-03-25 10:30:08,/home
mary,2022-03-25 11:00:05,/admin
mary,2022-03-25 11:30:05,/admin
mary,2022-03-25 12:00:05,/admin
mary,2022-03-25 12:10:05,/admin
mary,2022-03-25 12:20:05,/admin
mary,2022-03-25 13:00:05,/admin
*/
/**
* 读取kafka中的数据 -- 创建source表
* 具体的CSV的参数可以参见官网
*/
bsTableEnv.executeSql(
"""
|CREATE TABLE clicks (
| `user` STRING, //假如遇到报错显示不能使用该字段名,可以在字段名上加上反引号 ``
| cTime TIMESTAMP(3),
| url STRING,
| -- 声明 user_action_time 是事件时间属性,并且用 延迟 5 秒的策略来生成 watermark
| WATERMARK FOR cTime AS cTime - INTERVAL '5' SECOND -- 设置水位线
|) WITH (
| 'connector' = 'kafka',
| 'topic' = 'clicks1',
| 'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
| 'properties.group.id' = 'asdasd',
| 'format' = 'csv',
| 'csv.field-delimiter' = ',' ,
| 'csv.ignore-parse-errors' = 'true', // 忽略脏数据
| 'scan.startup.mode' = 'earliest-offset'
|)
|
""".stripMargin)
/**
* 如果想简单看一下表中数据,可以通过 Print SQL 连接器
* 通过SQL的方式创建print表
* LIKE: 引用原表的字段创建新的表
*/
bsTableEnv.executeSql(
"""
|CREATE TABLE print_table WITH ('connector' = 'print')
|LIKE clicks (EXCLUDING ALL)
|
""".stripMargin)
/**
* 打印结果
*
*/
/* bsTableEnv.executeSql(
"""
|insert into print_table
|select * from clicks
|
""".stripMargin)*/
/**
* 统计用户访问网页的次数
*
*/
//创建print表
bsTableEnv.executeSql(
"""
|CREATE TABLE count_print (
| `user` STRING,
| c BIGINT
|)
|WITH ('connector' = 'print')
|
""".stripMargin)
/* bsTableEnv.executeSql(
"""
|insert into count_print
|select `user`,count(url) as c from clicks group by `user`
|
""".stripMargin)*/
/**
* 每隔一小时统计用户访问网页的次数
*
*/
bsTableEnv.executeSql(
"""
|CREATE TABLE window_print (
| `user` STRING,
| win_end TIMESTAMP(3),
| c BIGINT
|)
|WITH ('connector' = 'print')
|
""".stripMargin)
/**
* 将结果保存到mysql
* 需要先在mysql中创建表
*
*/
bsTableEnv.executeSql(
"""
|CREATE TABLE mysql_sink (
| `user` STRING,
| win_end TIMESTAMP(3),
| c BIGINT,
| PRIMARY KEY (`user`,win_end) NOT ENFORCED
|) WITH (
| 'connector' = 'jdbc',
| 'url' = 'jdbc:mysql://master:3306/bigdata',
| 'table-name' = 'window_count',
| 'username' = 'root',
| 'password' = '123456'
|)
|
""".stripMargin)
bsTableEnv.executeSql(
"""
|insert into mysql_sink
|select
|`user`,
|TUMBLE_END(cTime, INTERVAL '1' HOURS) as win_end, -- 窗口结束时间
|count(url) as c
|from
|clicks group by
|`user`,
|TUMBLE(cTime, INTERVAL '1' HOURS) -- 一个小时一个窗口,事件时间的滚动窗口
|
""".stripMargin)
}
}
通过 Flink SQL 读 FileSystem
Flink 处理 json 数据需要导入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>1.11.2</version>
</dependency>
程序示例
package com.shujia.flink.table
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.EnvironmentSettings
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
object Demo4FileSource {
def main(args: Array[String]): Unit = {
//创建flink 环境
val bsEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
bsEnv.setParallelism(1)
//设置table 环境的一些参数
val bsSettings: EnvironmentSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner() //使用blink计划器
.inStreamingMode() //流模式
.build()
// 创建flink table 环境
val bsTableEnv: StreamTableEnvironment = StreamTableEnvironment.create(bsEnv, bsSettings)
/**
* 创建读取文件的表 -- 有界流
* 也可以创建分区表 -- 具体去官网找参数,这里没有涉及到分区
* json格式的数据Flink会自动解析
*/
bsTableEnv.executeSql(
"""
|CREATE TABLE student (
| id STRING,
| name STRING,
| age INT,
| gender STRING,
| clazz STRING
|) WITH (
| 'connector' = 'filesystem',
| 'path' = 'data/students.json',
| 'format' = 'json'
|)
""".stripMargin)
//创建print表
bsTableEnv.executeSql(
"""
|CREATE TABLE print_table WITH ('connector' = 'print')
|LIKE student (EXCLUDING ALL)
|
""".stripMargin)
//向print表中插入数据
bsTableEnv.executeSql(
"""
|insert into print_table
|select * from student
|
""".stripMargin)
}
}
通过 Flink SQL 读 MySQL
package com.shujia.flink.table
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.EnvironmentSettings
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
object Demo5MysqlSource {
def main(args: Array[String]): Unit = {
//创建flink 环境
val bsEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
bsEnv.setParallelism(1)
//设置table 环境的一些参数
val bsSettings: EnvironmentSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner() //使用blink计划器
.inStreamingMode() //流模式
.build()
// 创建flink table 环境
val bsTableEnv: StreamTableEnvironment = StreamTableEnvironment.create(bsEnv, bsSettings)
//读MySQL的时候不需要加主键,写MySQL的时候才需要
bsTableEnv.executeSql(
"""
|CREATE TABLE student (
| id STRING,
| name STRING,
| age INT,
| gender STRING,
| clazz STRING
|) WITH (
| 'connector' = 'jdbc',
| 'url' = 'jdbc:mysql://master:3306/bigdata',
| 'table-name' = 'student',
| 'username' = 'root',
| 'password' = '123456'
|)
""".stripMargin)
bsTableEnv.executeSql(
"""
|CREATE TABLE print_table WITH ('connector' = 'print')
|LIKE student (EXCLUDING ALL)
|
""".stripMargin)
bsTableEnv.executeSql(
"""
|insert into print_table
|select * from student
|
""".stripMargin)
}
}
通过 Flink SQL 读写 HBase
Flink 读写 HBase 需要导入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hbase_2.11</artifactId>
<version>1.11.2</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.4.6</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- or... -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>1.4.6</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
程序示例
解决maven项目依赖包冲突的问题
package com.shujia.flink.table
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.EnvironmentSettings
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
object Demo6FlinkOnHbase {
def main(args: Array[String]): Unit = {
//创建flink 环境
val bsEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置table 环境的一些参数
val bsSettings: EnvironmentSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner() //使用blink计划器
.inStreamingMode() //流模式
.build()
// 创建 flink table 环境
val bsTableEnv: StreamTableEnvironment = StreamTableEnvironment.create(bsEnv, bsSettings)
/**
* 创建读取文件的表 -- 有界流
*
*/
bsTableEnv.executeSql(
"""
|CREATE TABLE student (
| id STRING,
| name STRING,
| age INT,
| gender STRING,
| clazz STRING
|) WITH (
| 'connector' = 'filesystem',
| 'path' = 'data/students.json',
| 'format' = 'json'
|)
|
""".stripMargin)
/**
* 将数据保存到hbasez中
*
* 这个表即可以读,也可以写,双向的
*
* 需要先在hbase中创建表
*
* 需要导入flink-connector-hbase的依赖和hbase-client(或者hbase-common)的依赖
* 但是导完依赖之后IDEA就不会打印日志了,因为出现了日志冲突
* Class path contains multiple SLF4J bindings -- 类路径包含多个SLF4J绑定
* 也就是说在Maven中有多个SLF4J的包,导致出现了冲突
* 解决方案如下
*/
bsTableEnv.executeSql(
"""
|
|CREATE TABLE student_hbase (
| id STRING,
| info ROW<name STRING, age INT , gender STRING, clazz STRING>,
| PRIMARY KEY (id) NOT ENFORCED
|) WITH (
| 'connector' = 'hbase-1.4',
| 'table-name' = 'student',
| 'zookeeper.quorum' = 'master:2181,node1:2181,node2:2181'
|)
|
""".stripMargin)
//将数据写入hbase
/*bsTableEnv.executeSql(
"""
|insert into student_hbase
|
|select id, ROW(name,age,gender,clazz) as info from student
|
""".stripMargin)*/
/**
*
* 读取hbase中的数据 -- 有界流
*
*/
bsTableEnv.executeSql(
"""
|CREATE TABLE print_table (
|clazz STRING,
|c BIGINT
|)
|WITH ('connector' = 'print')
|
""".stripMargin)
bsTableEnv.executeSql(
"""
|insert into print_table
|select info.clazz as clazz, count(1) as c from
|student_hbase
|group by info.clazz
|
""".stripMargin)
}
}
解决 maven 项目依赖包冲突的问题
背景:在 maven 项目中导入依赖的时候,依赖包中会附加很多包进来,有的时候这些附加导入的包,之前就存在了,即在 Maven 中同一个包不止一个,所以会产生依赖包冲突的问题,例如上面所示
在 maven 项目中导入依赖的时候,假设导入A依赖(包含B-1.5版本),又导入C依赖(包含B-1.0版本),这时就会发生依赖冲突
解决:
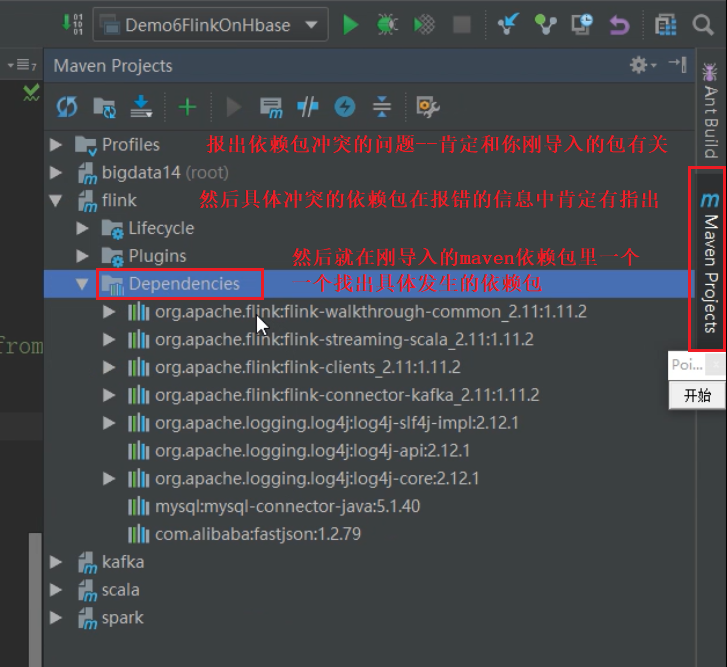
1、找出冲突的包
首先报出依赖包冲突的错误,肯定和刚导入的依赖包有关
然后具体冲突的依赖包在报错的信息中肯定有指出
2、排除冲突的包
在导入依赖的代码中,通过 <exclusions><exclusion>……</exclusion>……</exclusions> 来将导入依赖中具体发送冲突的包排除掉
格式如下:
<dependency>
<groupId>……</groupId>
<artifactId>……</artifactId>
<version>……</version>
<exclusions>
<exclusion>
<groupId>……</groupId>
<artifactId>……</artifactId>
</exclusion>
<exclusion>
<groupId>……</groupId>
<artifactId>……</artifactId>
</exclusion>
</exclusions>
</dependency>
DataGen and BlackHole
DataGen
DataGen 连接器允许按数据生成规则进行读取。
DataGen 连接器可以使用计算列语法。 这使您可以灵活地生成记录。
DataGen 连接器是内置的。
注意 不支持复杂类型: Array,Map,Row。 请用计算列构造这些类型。
DataGen 是用来做测试的,是帮助我们生成测试数据的工具,可以随机生成指定类型的数据,常用于我们做测试时没有数据
BlackHole
类似于回收站,放进去就没了
BlackHole 连接器允许接收所有输入记录。它被设计用于:
- 高性能测试。
- UDF 输出,而不是实质性 sink。
就像类 Unix 操作系统上的 /dev/null。
BlackHole 连接器是内置的。
代码示例
package com.shujia.flink.table
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.EnvironmentSettings
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
object Demo7DataGen {
def main(args: Array[String]): Unit = {
//创建flink 环境
val bsEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置table 环境的一些参数
val bsSettings: EnvironmentSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner() //使用blink计划器
.inStreamingMode() //流模式
.build()
// 创建 flink table 环境
val bsTableEnv: StreamTableEnvironment = StreamTableEnvironment.create(bsEnv, bsSettings)
/**
* datagen: 随机生成数据的工具
* 水位线字段不能被 LIKE 继承过去
*/
bsTableEnv.executeSql(
"""
|CREATE TABLE datagen (
| f_sequence INT,
| f_random INT,
| f_random_str STRING
|) WITH (
| 'connector' = 'datagen',
| 'rows-per-second'='5',
| 'fields.f_sequence.kind'='sequence',
| 'fields.f_sequence.start'='1',
| 'fields.f_sequence.end'='1000',
| 'fields.f_random.min'='1',
| 'fields.f_random.max'='1000',
| 'fields.f_random_str.length'='10'
|)
""".stripMargin)
//水位线字段不能被 LIKE 继承过去
bsTableEnv.executeSql(
"""
|CREATE TABLE print_table WITH ('connector' = 'print')
|LIKE datagen (EXCLUDING ALL)
""".stripMargin)
//创建BlackHole表
bsTableEnv.executeSql(
"""
|CREATE TABLE blackhole_table WITH ('connector' = 'blackhole')
|LIKE datagen (EXCLUDING ALL)
|
""".stripMargin)
bsTableEnv.executeSql(
"""
|insert into blackhole_table
|select * from datagen
|
""".stripMargin)
}
}


 浙公网安备 33010602011771号
浙公网安备 33010602011771号