
pyspark常见使用方法
以日志文件的解析过程为例,其中部分日志文件样例为:
2021-03-09 06:54:21,907 [http-nio-16680-exec-6-43:tUxRo338DAxy6xpj] INFO [m.u.g.s.l.ThreadLocalLogHandler] - request url: /wfbmall-api/homeGoods/queryMemberScoreInfo, finish at 1615244061907, total cost 8 ms.
2021-03-09 04:49:36,302 [http-nio-16680-exec-7-44:MFf7C1xRrxLgib44] INFO [m.u.g.s.l.ThreadLocalLogHandler] - {"code":"200","message":"操作成功","data":{"memberId":2145,"availableScore":0},"transNonce":"ce9b7833-b7d1-4419-bc17-4ff6d77b45c0","transDate":"1615236576302"}
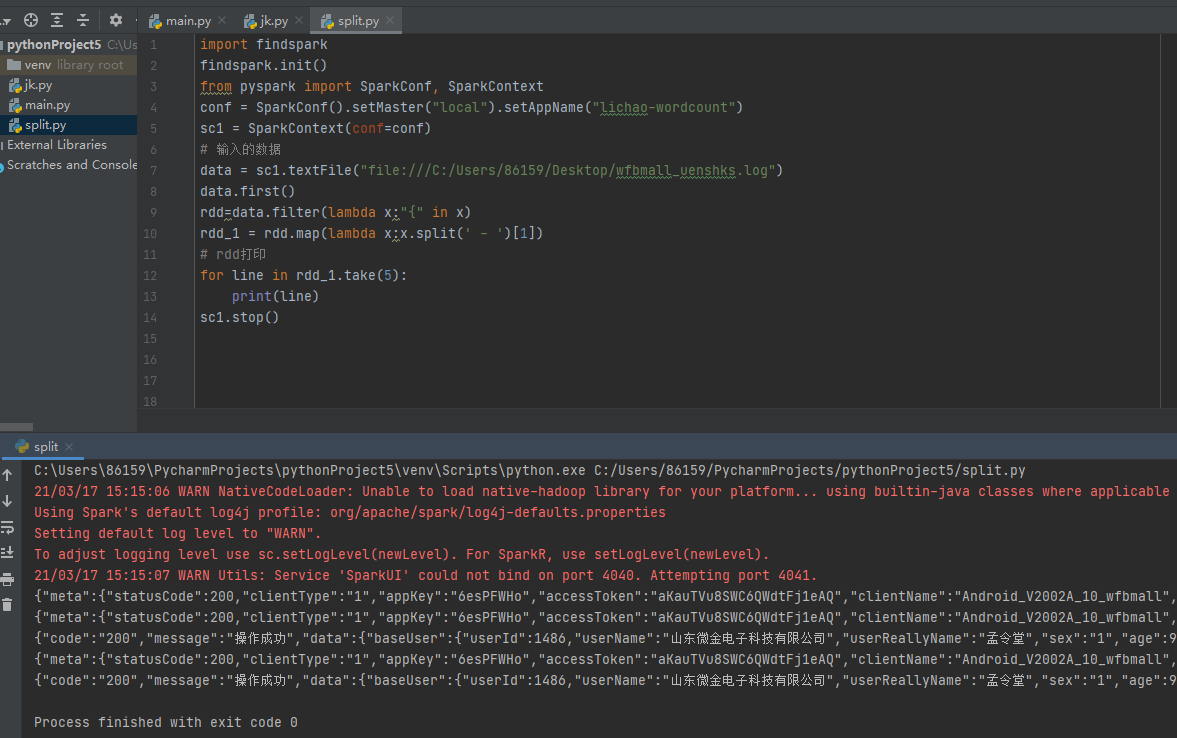
案例一,将日志文件中的json部分提取出来
import findspark
findspark.init()
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("lichao-wordcount")
sc1 = SparkContext(conf=conf)
# 输入的数据
data = sc1.textFile("file:///C:/Users/86159/Desktop/wfbmall_uenshks.log") #读取本地文件
data.first() # 查看文件的首行数据
rdd=data.filter(lambda x:"{" in x) # 过滤出包含大括号“{”的数据,即json文件
rdd_1 = rdd.map(lambda x:x.split(' - ')[1]) # 将包含json行的数据以分隔符进行分割,提取json文件部分
# rdd打印
for line in rdd_1.take(5): #打印前5行数据
print(line)
sc1.stop()
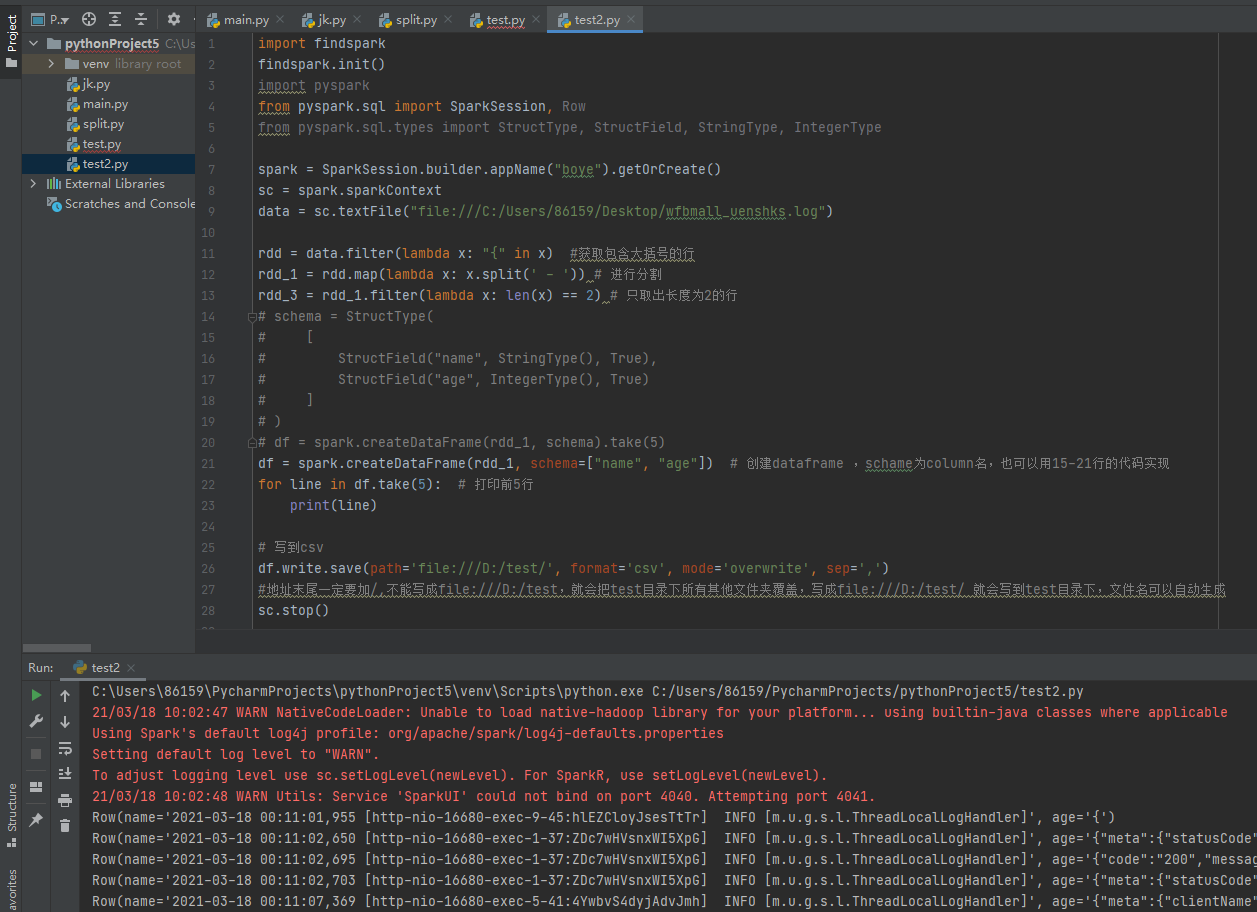
案例二,将rdd转化为DataFrame,并保存为csv文件
import findspark
findspark.init()
import pyspark
from pyspark.sql import SparkSession, Row
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
spark = SparkSession.builder.appName("boye").getOrCreate()
sc = spark.sparkContext
data = sc.textFile("file:///C:/Users/86159/Desktop/wfbmall_uenshks.log")
rdd = data.filter(lambda x: "{" in x) #获取包含大括号的行
rdd_1 = rdd.map(lambda x: x.split(' - ')) # 进行分割
rdd_3 = rdd_1.filter(lambda x: len(x) == 2) # 只取出长度为2的行
# schema = StructType(
# [
# StructField("name", StringType(), True),
# StructField("age", IntegerType(), True)
# ]
# )
# df = spark.createDataFrame(rdd_1, schema).take(5)
df = spark.createDataFrame(rdd_1, schema=["name", "age"]) # 创建dataframe ,schame为column名,也可以用15-21行的代码实现
for line in df.take(5): # 打印前5行
print(line)
# 写到csv
df.write.save(path='file:///D:/test/', format='csv', mode='overwrite', sep=',')
#地址末尾一定要加/,不能写成file:///D:/test,就会把test目录下所有其他文件夹覆盖,写成file:///D:/test/ 就会写到test目录下,文件名可以自动生成
sc.stop()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号