Druid学习之路 (三)Druid的数据源和段
作者:Syn良子 出处:https://www.cnblogs.com/cssdongl/p/9703204.html 转载请注明出处
Druid的数据源和分段
Druid的数据存储在"DataSource"中,这其实类似于传统的RDBMS中的表.每一个数据源按照时间进行分段,当然你还可以选择其他属性进行分段.每一个时间区间被称为一个"Chunk".(举个列子,一天的时间区间的Chunk,如果你的数据源是按天进行分段的).在一个Chunk内,数据被分成一个或者多个"segments".每个segment是一个单独的文件,它由数以百万的数据行构成.因为segment是组织在时间chunk里的,所以按照时间曲线有助于理解segments,像下面这样的
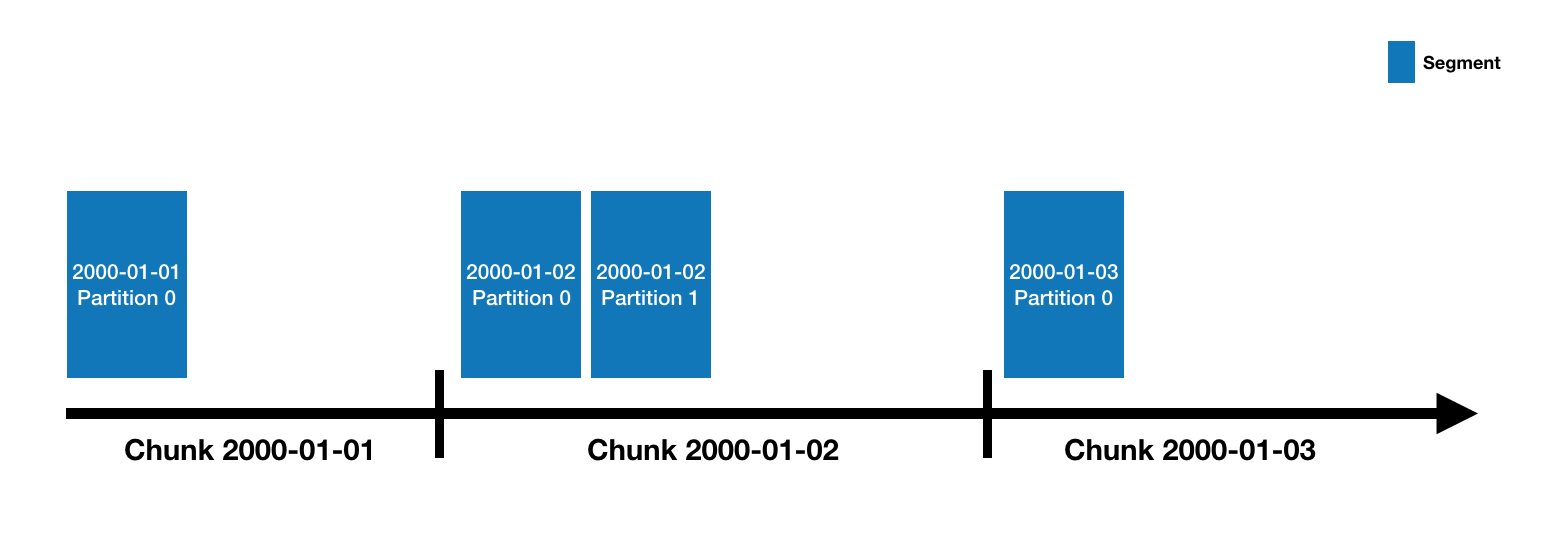
一个数据源刚开始由几个segments一直扩展到几百几千甚至上百万个segments.每个segment的生命周期始于被MiddleManager创建,这个时候segment是可变的没有被提交的.一个segment的构建包含以下列出来的步骤,这种设计是为了满足一个可以支持压缩并可以被快速查询的文件格式
- 转换成列式存储格式
- 利用bitmap建立索引
- 利用多种算法进行压缩
segments会周期性的提交和发布.此时它会被写入deep storage然后状态改为不可变的.随后它会被从MiddleManager移动到Historical进程中去.与此同时关于这个segment的一个条目也会被写入元数据存储.这个条目是描述该segment的元数据,包含segment的schema,大小,以及它在deep storage上的存储位置.所有这些类似的条目都会被Coordinator用来寻找对应的数据是否在集群上是可用状态的.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号