[转] mysql字符集设置 转自: https://www.cnblogs.com/JMLiu/p/8313204.html
Mysql中各种与字符编码集(character_set)有关的变量含义
mysql涉及到各种字符集,在此做一个总结。
字符集的设置是通过环境变量来设置的,环境变量和linux中的环境变量是一个意思。mysql的环境变量分为两种:session和global。session变量是仅在这次会话红中有效,在mysql中,一次会话可以理解为当前连接(除非reload,否则,一次会话就只有一次连接)。global环境变量则是确定了下一个新建立的session的变量值。使用show variables可以查看session值,如果要查看global的环境变量,则用show golbal variables语句。设置session环境变量用set variablename=value,设置global环境变量用set global variablename=value。
环境变量可以在服务启动后用set来设置,有些(主要是和数据库服务器有关的)也可以在启动服务时用命令行参数指定,还可以在配置文件中设置(my.cnf)。
mysql提供了四个等级的默认字符集以及比较规则,分别是服务器、数据库、表、列级别的。文档原话是:There are default settings for character sets and collations at four levels: server, database, table, and column. The description in the following sections may appear complex, but it has been found in practice that multiple-level defaulting leads to natural and obvious results.
一个字符集(character set)对应了一个默认的字符排序码规则(collation),当改变了一个等级的默认编码集时,与它同等级的默认字符排序规则也会变成该字符集对应的字符排序规则。
除了有这四个等级的默认字符编码和排序规则,还可以指定具体某一段字符的编码以及他的排序规则,指定字符编码是直接在他前面加上_utf8就可以了,指定排序规则在后面加上collate<排序规则>,如下这样: SELECT _utf8'abc' COLLATE utf8_danish_ci; 注意,如果有转义字符,那么转义字符是不会收字符串指定编码集影像的,而是和character_set_connection一致,如下:
1 mysql> SET NAMES latin1;
2 mysql> SELECT HEX('à\n'), HEX(_sjis'à\n');
返回的结果中\n仍然是换行符,因为\用的是latin1的字符集,在latin1中,它是换行符,而_sijis字符集中,\不是转移字符,而是6E。
结果:
+------------+-----------------+
| HEX('à\n') | HEX(_sjis'à\n') |
+------------+-----------------+
| E00A | E00A |
+------------+-----------------+
如果要查看所有的字符集,用show character set语句,查看所有的collation,用show collation语句。
字符集的设定不仅影响着存储,还会影响客户端和数据库服务器的通信,关于数据编码,mqsql中涉及到下面几个问题:
1、客户端发过来的数据使用什么字符集编码的?
2、接收到数据之后,应该用什么编码格式编码之后再将数据插入到mysql server中?
3、执行查询之后,查询出来的结果应该用什么编码集编码之后再返回?
4、数据库的各种表的数据,应该用什么字符集编码,以及它们用什么排序?
5.查询语句的字符串比较时,应该在哪一个标准里面来比较,比如:'Mueller' = 'Müller'是为真还是假?
6.数据库的各种元数据,包括表名、数据库名、密码、用户名、以及comment等,用什么字符集表示?
针对这四个问题,mysql就提供了不同的环境变量来进行跟踪,这些变量为:
|
变量名 |
含义 |
|
character_set_server |
默认的内部操作字符集 |
|
character_set_client |
客户端来源数据使用的字符集,也就是客户端发过来的查询语句使用的什么字符集 |
|
character_set_connection |
MySQL接受到用户查询后,按照character_set_client将其转化为character_set_connection设定的字符集。 |
|
character_set_results |
查询结果编码的字符集 |
|
character_set_database |
当前选中数据库的默认字符集 |
|
character_set_system |
系统元数据(字段名等)字符集 |
|
collation_connection |
执行字符比较时采用的编码规则 |
在mysql中,可以为数据库指定默认的字符编码,成为该数据库中每个新建表的默认字符编码集,但是对于已经建立的表则不受影响。在新建一个表时,也可以使用DEFUALT CHARACTER SET=xxx来指定表的字符编码。
在数据库的查询(select update insert)操作中,涉及到的字符编码有character_set_client, character_set_connnection, character_set_result三个变量,这是三个变量是需要建立连接之后进行设置的.
1、针对第一个问题,使用character_set_client环境变量来回答:
character_set_client ,这是用户告诉服务器,客户端发过来的SQL语句是用的什么字符集,要和客户端发出去的字节流采用的编码集一致,如果是shell,那么就是和shell的编码集一致,中文windows的cmd就是gbk。但是对于使用_utf8'xxx'标记的字符,则用标记的字符集解码。
2、针对第二个问题,使用character_set_connetion环境变量来回答:
character_set_connection ,MySQL server 接收到用户查询后,按照character_set_client将其转化为character_set_connection设定的字符集,一般就是所操作的表对应的编码集。
3、针对第三个问题,使用character_set_result环境变量来回答:
character_set_results , MySQL将存储的数据转换成character_set_results中设定的字符集发送给用户,客户端获取到的结果就是以这种形式编码的。
4.针对第四个问题,使用上面提到的四个等级的默认字符集以及排序规则,即character_set_server、character_set_database以及建立表时的DEFAULT CHARACTER SET=xxx和指定字段时的DEFAULT CHARACTER SET=xxx来回答:
character_set_server决定了服务器的默认编码,character_set_database决定了新建数据库的默认字符集,而数据库的字符集又决定了新建表的默认字符集,而表的字符集又决定了字段的默认字符集,如果没有通过DEFAULT CHARACTER SET=xxx来改变表的字符集,则新表就使用character_set_database指定的字符集。
5.针对第五个问题,使用collation_connection来回答:
collation_connection变量制定了比较的规则。collation_connection的值得形式如下:字符集_语言_ci(大小不写敏感) 或字符集_语言_cs(大小写敏感),像中文这样的,没有大小写,所以只能是ci,比如set collatioin_connection=gbk_chinese_ci。就是设置成中文字典的排序规则。除了按具体语言排序,还可以按照二进制的位置排序,比如utf8_bin。
character_set_connection和collatioin_connection是一体的,设置了character_set_connection之后,collation_connection会跟着变成对应的默认排序规则,反之亦然。如果要显示的设置排序规则,可以用 SET NAMES'charset_name' COLLATE 'collation_name' 。
但是如果查询语句的字符串和表的字段比较,则collation_connection不适用,因为表的字段有它自己的字符排序规则,而它自己的排序规则优先级高于collation_connection。
6.针对第六个问题,使用character_set_system来回答:
character_set_system表示元数据的字符集,默认就是utf8,而且不要去更改它,否则,因为类似于用户名密码这种东西,可能用各种奇葩的字符去表示,只有utf8能够容纳它们。如果变成了别的字符集,那么用户名和密码就不能用你想要的字符去表示了。需要注意的是,这个character_set_system也好,character_set_dababase、character_set_server也好,都指标是在数据库内部的保存格式,而不是返回到客户端的编码格式,返回到客户端的结果都会转化为character_set_results指定的字符集之后再返回,官方文档原话是“Storage of metadata using Unicode does not mean that the server returns headers of columns and the results of DESCRIBE functions in the character_set_systemcharacter set by default. When you use SELECT column1 FROM t, the name column1 itself is returned from the server to the client in the character set determined by the value of the character_set_results system variable, which has a default value of latin1.”。
另外,如果要临时设置返回值的编码,可以用set names charset_name'来临时改变character_set_results以及其他相关变量的值为charset_name。set names 'charset_name'等价于下面三条语句的结合:
1 SET character_set_client = charset_name; 2 SET character_set_results = charset_name; 3 SET character_set_connection = charset_name;
SET CHARACTER SET和 SET NAMES 很像,但是是把 character_set_connection 和 collation_connection 分别设置为 character_set_database 和collation_database一样,SET CHARACTER SET 等同于以下三条语句的结合。charset_name
1 SET character_set_client = charset_name; 2 SET character_set_results = charset_name; 3 SET collation_connection = @@collation_database;
所以,set character set 'charset_name'要更常用。
顺便提一句,mysql的错误日志意识utf8格式产生的,但是如果把它输出到客户端,它就会转场character_set_results的编码格式再传到客户端(所有传到客户端的东西都会转码成character_set_results的)。
还可以加入启动参数skip-character-set-client-handshake来使客户端的编码和数据库保持一致。
通常,客户端的字符集可以通过操作系统来获取,从而使得字符集的分配和客户端一致。
参考:1、Connection Character Sets and Collations
3、What are character sets and collations
5、Mysql中的排序规则utf8_unicode_ci、utf8_general_ci的区别总结
//// 文章2, 这个更有用.....
原文:http://blog.csdn.net/woslx/article/details/49685111
utf-8编码可能2个字节、3个字节、4个字节的字符,但是MySQL的utf8编码只支持3字节的数据,而移动端的表情数据是4个字节的字符。如果直接往采用utf-8编码的数据库中插入表情数据,Java程序中将报SQL异常:
java.sql.SQLException: Incorrect string value: ‘\xF0\x9F\x92\x94’ for column ‘name’ at row 1
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1073)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3593)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3525)
at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:1986)
at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2140)
at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2620)
at com.mysql.jdbc.StatementImpl.executeUpdate(StatementImpl.java:1662)
at com.mysql.jdbc.StatementImpl.executeUpdate(StatementImpl.java:1581)
可以对4字节的字符进行编码存储,然后取出来的时候,再进行解码。但是这样做会使得任何使用该字符的地方都要进行编码与解码。
utf8mb4编码是utf8编码的超集,兼容utf8,并且能存储4字节的表情字符。
采用utf8mb4编码的好处是:存储与获取数据的时候,不用再考虑表情字符的编码与解码问题。
更改数据库的编码为utf8mb4:
1. MySQL的版本
utf8mb4的最低mysql版本支持版本为5.5.3+,若不是,请升级到较新版本。
2. MySQL驱动
5.1.34可用,最低不能低于5.1.13
3.修改MySQL配置文件
修改mysql配置文件my.cnf(windows为my.ini)
my.cnf一般在etc/mysql/my.cnf位置。找到后请在以下三部分里添加如下内容:
[client]
default-character-set = utf8mb4
[mysql]
default-character-set = utf8mb4
[mysqld]
character-set-client-handshake = FALSE
character-set-server = utf8mb4
collation-server = utf8mb4_unicode_ci #utf8mb4_gengeral_ci 对于中、英文来说, 排序速度更快. 但对法文、俄文等可能会出现排序不准确额现象
init_connect='SET NAMES utf8mb4'
4. 重启数据库,检查变量
SHOW VARIABLES WHERE Variable_name LIKE 'character_set_%' OR Variable_name LIKE 'collation%';
| Variable_name | Value |
|---|---|
| character_set_client | utf8mb4 |
| character_set_connection | utf8mb4 |
| character_set_database | utf8mb4 |
| character_set_filesystem | binary |
| character_set_results | utf8mb4 |
| character_set_server | utf8mb4 |
| character_set_system | utf8 |
| collation_connection | utf8mb4_unicode_ci |
| collation_database | utf8mb4_unicode_ci |
| collation_server | utf8mb4_unicode_ci |
collation_connection 、collation_database 、collation_server是什么没关系。
但必须保证
| 系统变量 | 描述 |
|---|---|
| character_set_client | (客户端来源数据使用的字符集) |
| character_set_connection | (连接层字符集) |
| character_set_database | (当前选中数据库的默认字符集) |
| character_set_results | (查询结果字符集) |
| character_set_server | (默认的内部操作字符集) |
这几个变量必须是utf8mb4。
5. 数据库连接的配置
数据库连接参数中:
characterEncoding=utf8会被自动识别为utf8mb4,也可以不加这个参数,会自动检测。
而autoReconnect=true是必须加上的。
6. 将数据库和已经建好的表也转换成utf8mb4
更改数据库编码:ALTER DATABASE caitu99 CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
更改表编码:ALTER TABLE TABLE_NAME CONVERT TO CHARACTER SET utf8mb4 COLLATEutf8mb4_general_ci;
如有必要,还可以更改列的编码
///文章三 修改mysql字符集
mysql设置数据库编码及字段为utf8mb4

 4916
4916  收藏 6
收藏 6最近做微信小程序的过程中,数据库内需要存储微信昵称,而微信昵称经常是有特殊字符的,因此数据库需要使用utf8mb4编码。方法如下:
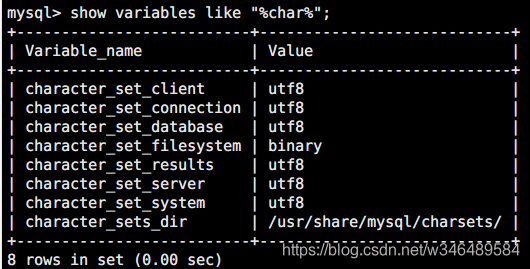
1、进入mysql,输入 show variables like "%char%"; 查看当前数据库编码:
2、在mysql的配置文件 /etc/my.cnf 中,新增以下内容:
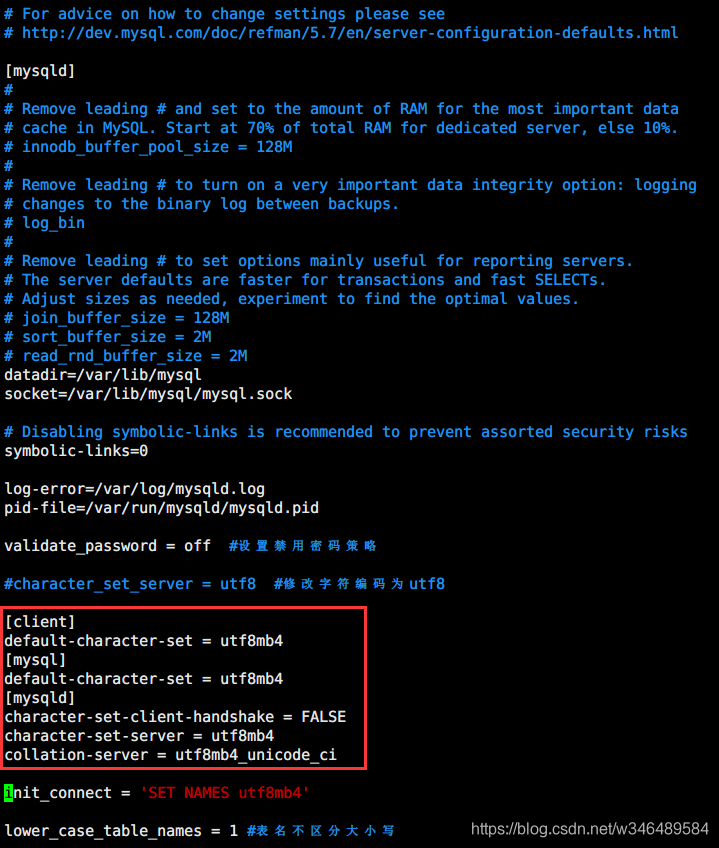
-
[client]
-
default-character-set = utf8mb4
-
[mysql]
-
default-character-set = utf8mb4
-
[mysqld]
-
character-set-client-handshake = FALSE
-
character-set-server = utf8mb4
-
collation-server = utf8mb4_unicode_ci
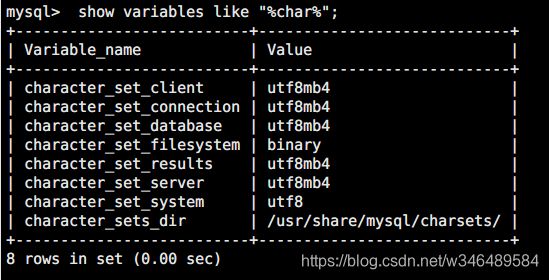
3、重启mysql,再次查看数据库编码,发现已经改变:
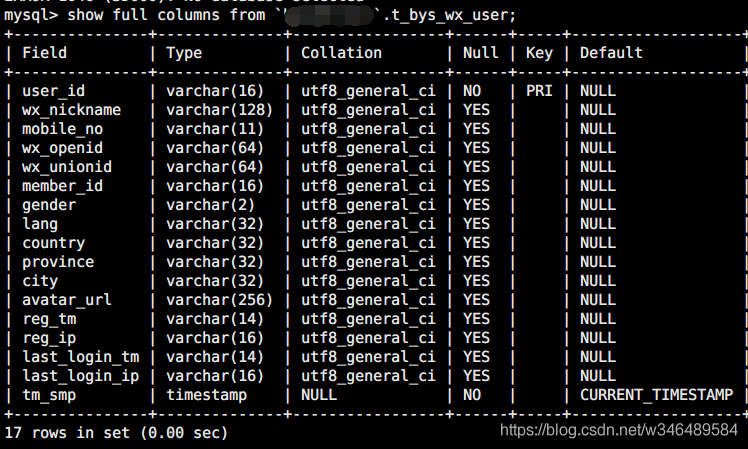
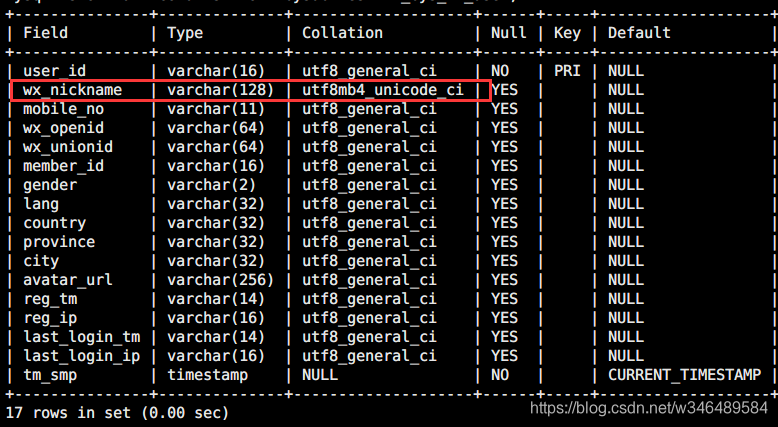
4、输入 show full columns from `db_name`.table_name; 查看当前表的字段信息:
5、输入sql命令,修改字段编码为utf8mb4:
ALTER TABLE `db_name`.table_name MODIFY `wx_nickname` VARCHAR(128) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
6、再次查看,可以发现字段编码已经被成功改变了:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号