

白话 Pulsar Bookkeeper 的存储模型

最近我们的 Pulsar 存储有很长一段时间数据一直得不到回收,但消息确实已经是 ACK 了,理论上应该是会被回收的,随着时间流逝不但没回收还一直再涨,最后在没找到原因的情况下就只有一直不停的扩容。
最后磁盘是得到了回收,过程先不表,之后再讨论。
为了防止类似的问题再次发生,我们希望可以监控到磁盘维度,能够列出各个日志文件的大小以及创建时间。
这时就需要对 Pulsar 的存储模型有一定的了解,也就有了这篇文章。
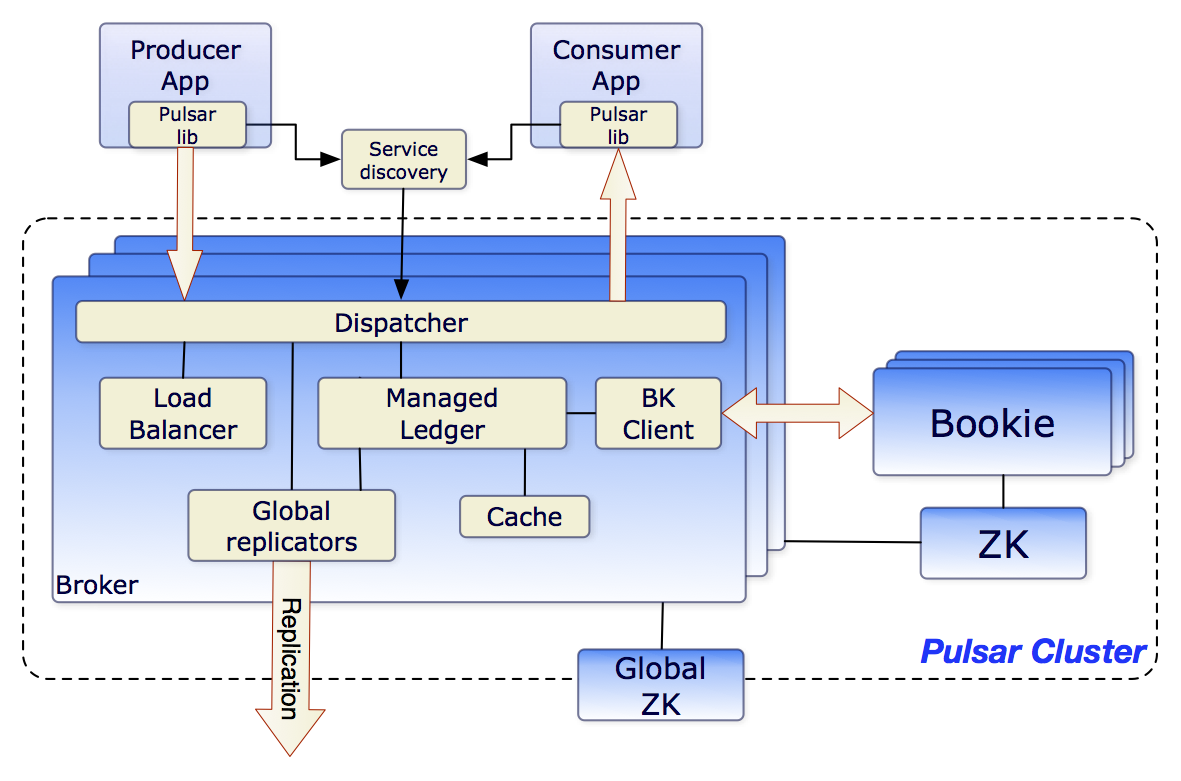
讲到 Pulsar 的存储模型,本质上就是 Bookkeeper 的存储模型。
Pulsar 所有的消息读写都是通过 Bookkeeper 实现的。
Bookkeeper是一个可扩展、可容错、低延迟的日志存储数据库,基于 Append Only 模型。(数据只能追加不能修改)
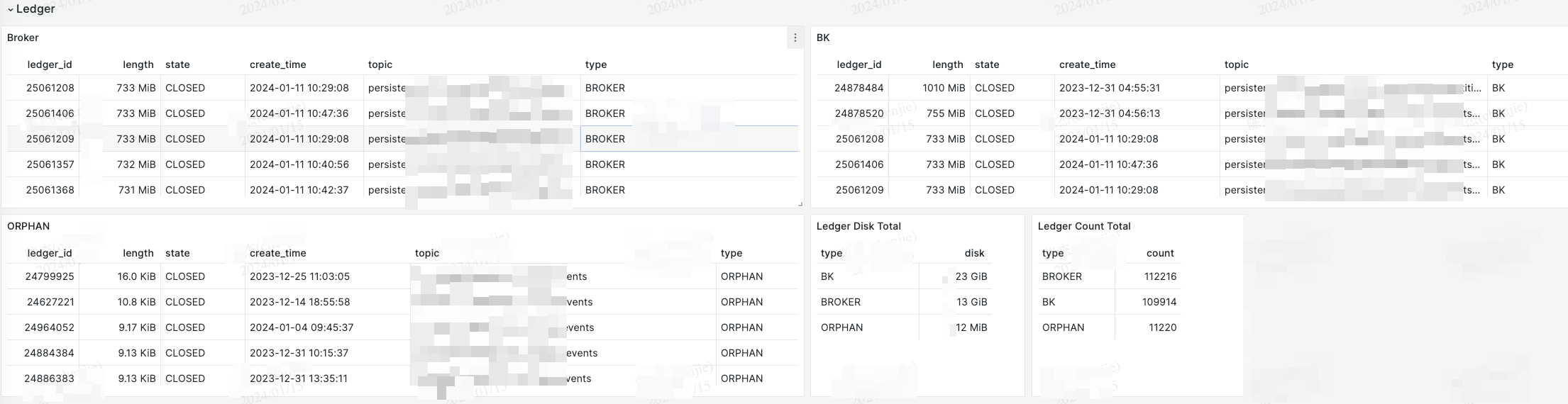
这里我利用 Pulsar 和 Bookkeeper 的 Admin API 列出了 Broker 和 BK 中 Ledger 分别占用的磁盘空间。
关于这个如何获取和计算的,后续也准备提交给社区。
背景
但和我们实际 kubernetes 中的磁盘占用量依然对不上,所以就想看看在 BK 中实际的存储日志和 Ledger 到底差在哪里。
知道 Ledger 就可以通过 Ledger 的元数据中找到对应的 topic,从而判断哪些 topic 的数据导致统计不能匹配。
Bookkeeper 有提提供一个Admin API 可以返回当前 BK 所使用了哪些日志文件的接口:
https://bookkeeper.apache.org/docs/admin/http#endpoint-apiv1bookielist_disk_filefile_typetype

从返回的结果可以看出,落到具体的磁盘上只有一个文件名称,是无法知道具体和哪些 Ledger 进行关联的,也就无法知道具体的 topic 了。
此时只能大胆假设,应该每个文件和具体的消息 ID 有一个映射关系,也就是索引。
所以需要搞清楚这个索引是如何运行的。
存储模型
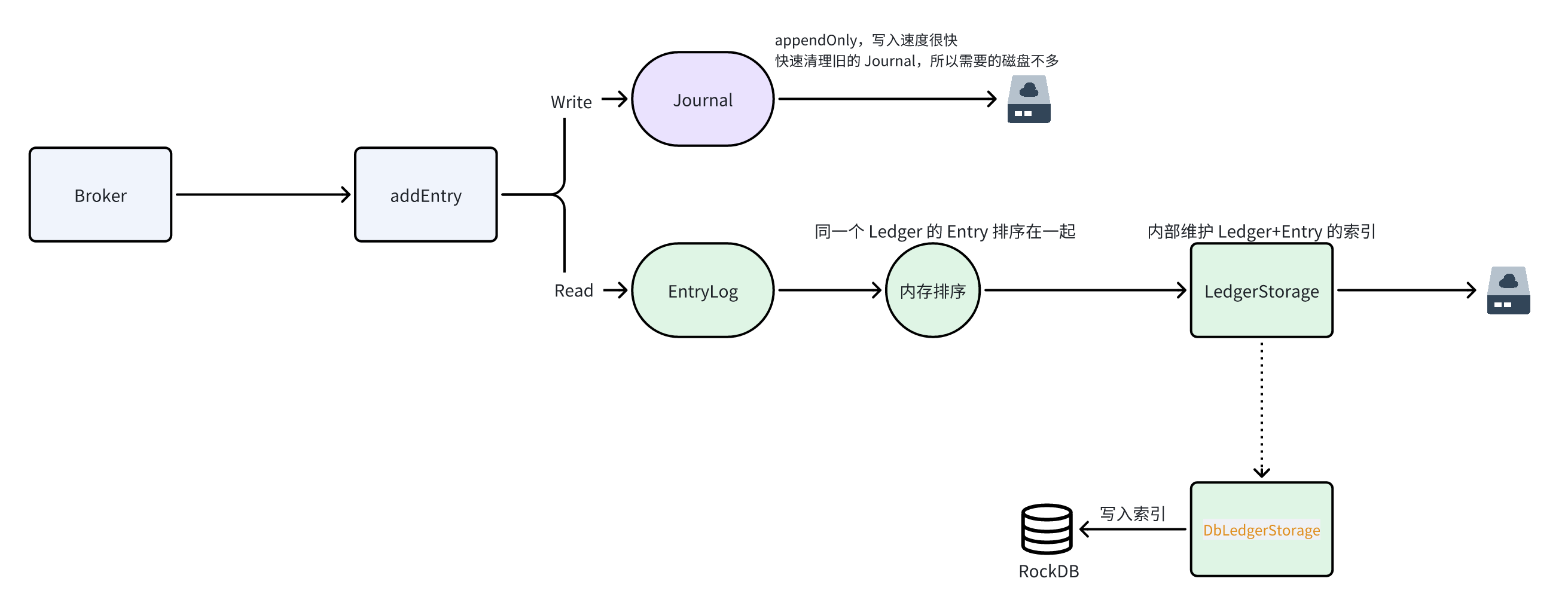
我查阅了一些网上的文章和源码大概梳理了一个存储流程:
- BK 收到写入请求,数据会异步写入到
Journal/Entrylog - Journal 直接顺序写入,并且会快速清除已经写入的数据,所以需要的磁盘空间不多(所以从监控中其实可以看到 Journal 的磁盘占有率是很低的)。
- 考虑到会随机读消息,EntryLog 在写入前进行排序,保证落盘的数据中同一个 Ledger 的数据尽量挨在一起,充分利用 PageCache.
- 最终数据的索引通过
LedgerId+EntryId生成索引信息存放到RockDB中(Pulsar的场景使用的是DbLedgerStorage实现)。 - 读取数据时先从获取索引,然后再从磁盘读取数据。
- 利用
Journal和EntryLog实现消息的读写分离。
简单来说 BK 在存储数据的时候会进行双写,Journal 目录用于存放写的数据,对消息顺序没有要求,写完后就可以清除了。
而 Entry 目录主要用于后续消费消息进行读取使用,大部分场景都是顺序读,毕竟我们消费消息的时候很少会回溯,所以需要充分利用磁盘的 PageCache,将顺序的消息尽量的存储在一起。
同一个日志文件中可能会存放多个 Ledger 的消息,这些数据如果不排序直接写入就会导致乱序,而消费时大概率是顺序的,但具体到磁盘的表现就是随机读了,这样读取效率较低。
所以我们使用 Helm 部署 Bookkeeper 的时候需要分别指定 journal 和 ledgers 的目录
volumes:
# use a persistent volume or emptyDir
persistence: true
journal:
name: journal
size: 20Gi
local_storage: false
multiVolumes:
- name: journal0
size: 10Gi
# storageClassName: existent-storage-class
mountPath: /pulsar/data/bookkeeper/journal0
- name: journal1
size: 10Gi
# storageClassName: existent-storage-class
mountPath: /pulsar/data/bookkeeper/journal1
ledgers:
name: ledgers
size: 50Gi
local_storage: false
storageClassName: sc
# storageClass:
# ... useMultiVolumes: false
multiVolumes:
- name: ledgers0
size: 1000Gi
# storageClassName: existent-storage-class
mountPath: /pulsar/data/bookkeeper/ledgers0
- name: ledgers1
size: 1000Gi
# storageClassName: existent-storage-class
mountPath: /pulsar/data/bookkeeper/ledgers1
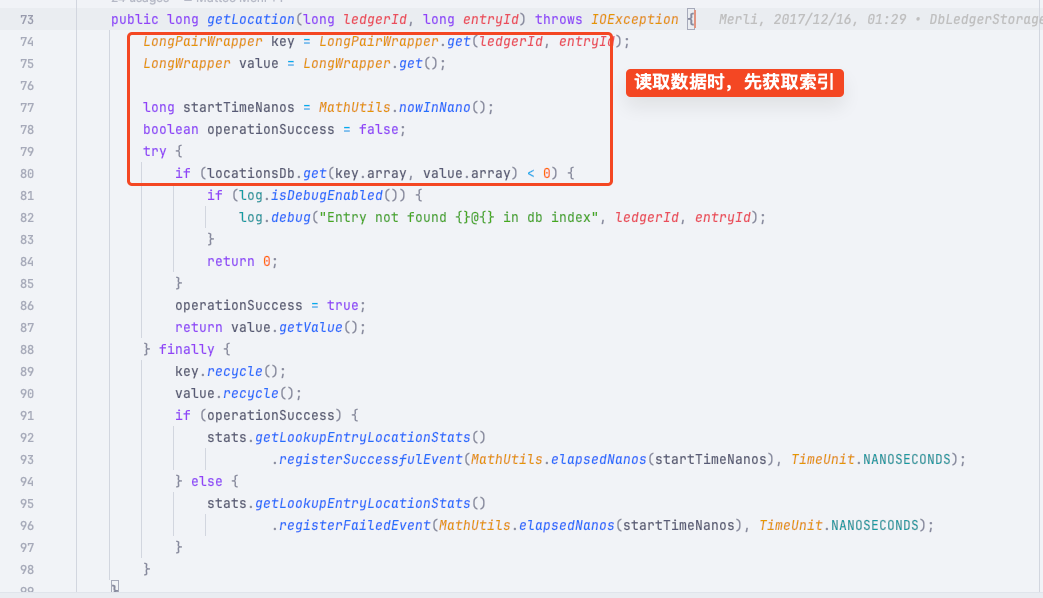
每次在写入和读取数据的时候都需要通过消息 ID 也就是 ledgerId 和 entryId 来获取索引信息。
也印证了之前索引的猜测。
所以借助于 BK 读写分离的特性,我们还可以单独优化存储。
比如写入 Journal 的磁盘因为是顺序写入,所以即便是普通的 HDD 硬盘速度也很快。
大部分场景下都是读大于写,所以我们可以单独为 Ledger 分配高性能 SSD 磁盘,按需使用。
因为在最底层的日志文件中无法直接通过 ledgerId 得知占用磁盘的大小,所以我们实际的磁盘占用率对不上的问题依然没有得到解决,这个问题我还会持续跟进,有新的进展再继续同步。
作者: crossoverJie

欢迎关注博主公众号与我交流。
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出, 如有问题, 可邮件(crossoverJie#gmail.com)咨询。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号