希音面试:说说 ClickHouse Group By 执行流程 ?CK 能支持 十亿级数据 实时分析的原理 是什么?
本文 的 原文 地址
原始的内容,请参考 本文 的 原文 地址
尼恩说在前面
在45岁老架构师 尼恩的读者交流群(50+)中,通过 Java+AI双驱架构 帮助很多小伙伴拿到了一线企业如 字节、得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团、蚂蚁、得物的面试资格,遇到很多很重要的面试题:
说说 ClickHouse Group By 执行流程 ?
ClickHouse 支持 高吞吐写入与低延迟查询,可支撑亿级乃至十亿级数据的实时分析,原因是什么?
为啥mysql 不行?
最近有小伙伴在 面试希音,遇到 到了这个的面试题。 小伙伴没有 回答好,到手到 大厂 offer就 这样飞走了。 非常可惜。
小伙伴面试完了之后,来求助尼恩。
那么,遇到 这个问题,该如何才能回答得很漂亮,才能 让面试官刮目相看、口水直流。
所以,尼恩给大家做一下系统化、体系化的梳理,使得大家内力猛增,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
一、ClickHouse 高性能分析型数据库核心解析
1、ClickHouse 概述
ClickHouse 核心优势是高吞吐写入与低延迟查询,可支撑亿级乃至十亿级数据的实时分析需求。
ClickHouse 与其他数据工具的定位差异,可通过以下图 区分:

2、ClickHouse 整体架构
ClickHouse 的架构设计是其性能的核心基础,核心差异在于“存储与计算的关系”和“MPP 并行能力”。
ClickHouse 是面向联机分析处理(OLAP)场景的分布式列式数据库,其核心架构包含两大模块:
- 存储层:负责数据持久化与压缩优化
- 计算层:处理查询执行与分布式计算
ClickHouse 采用MPP(大规模并行处理)架构,各节点对等协作,通过数据分片与副本机制实现水平扩展。
MPP 与传统计算引擎不同,ClickHouse采用存储计算一体化设计,使存储层能针对查询需求进行深度优化。
2.1 架构核心:存储服务于计算
传统大数据引擎(如 Spark)是 “计算 存储 分离 ”模式——计算层需从外部存储(HDFS/S3)读取原始数据,再进行计算;
而 ClickHouse 是 “计算 存储 一体化 ”模式 —— 自带存储层,可在存储阶段为计算做优化(如列存储、预排序),即“存储服务于计算”,大幅减少计算时的 I/O 开销。
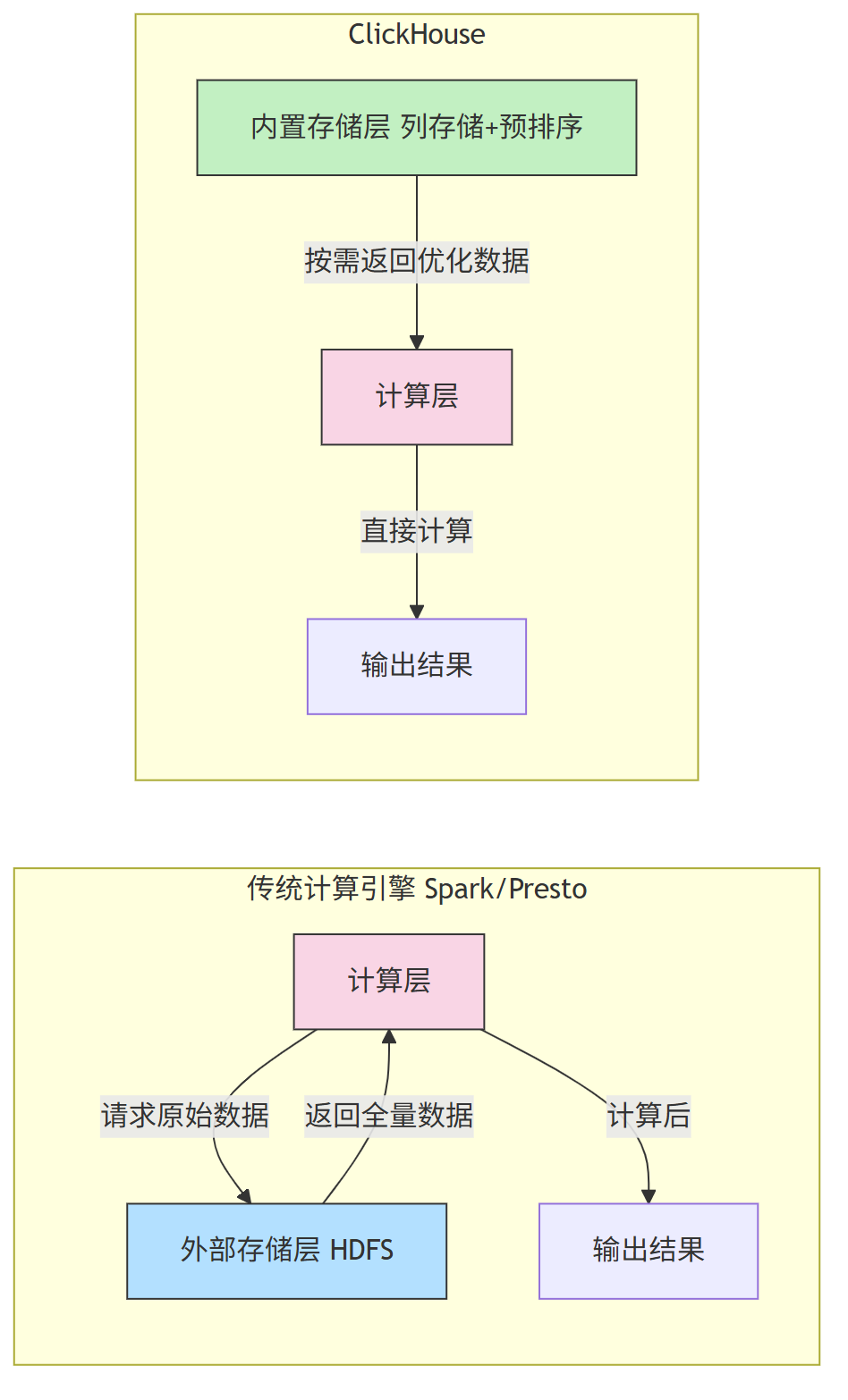
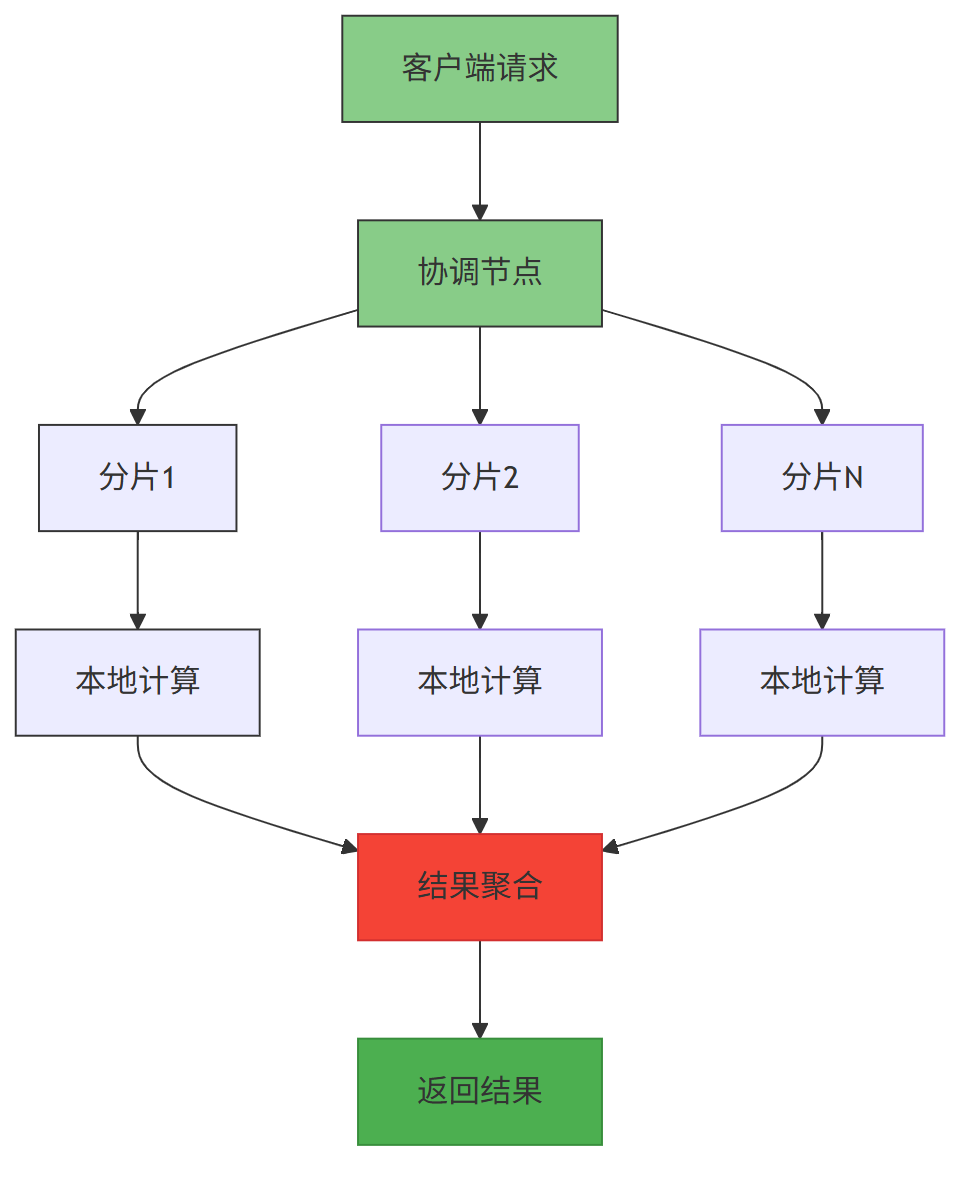
2.2 MPP 架构:并行计算提效
ClickHouse 采用大规模并行处理(MPP) 架构,集群中所有节点对等,无主从之分。
MPP 架构中,查询 任务会被拆分为多个子任务,并行分发到不同节点执行,最后汇总结果,充分利用多核 CPU 与多节点资源。
3、 ClickHouse 核心性能优化特性
ClickHouse 的极速查询能力,源于三大核心优化:
- 列式存储
- 向量化执行
- 数据预排序。
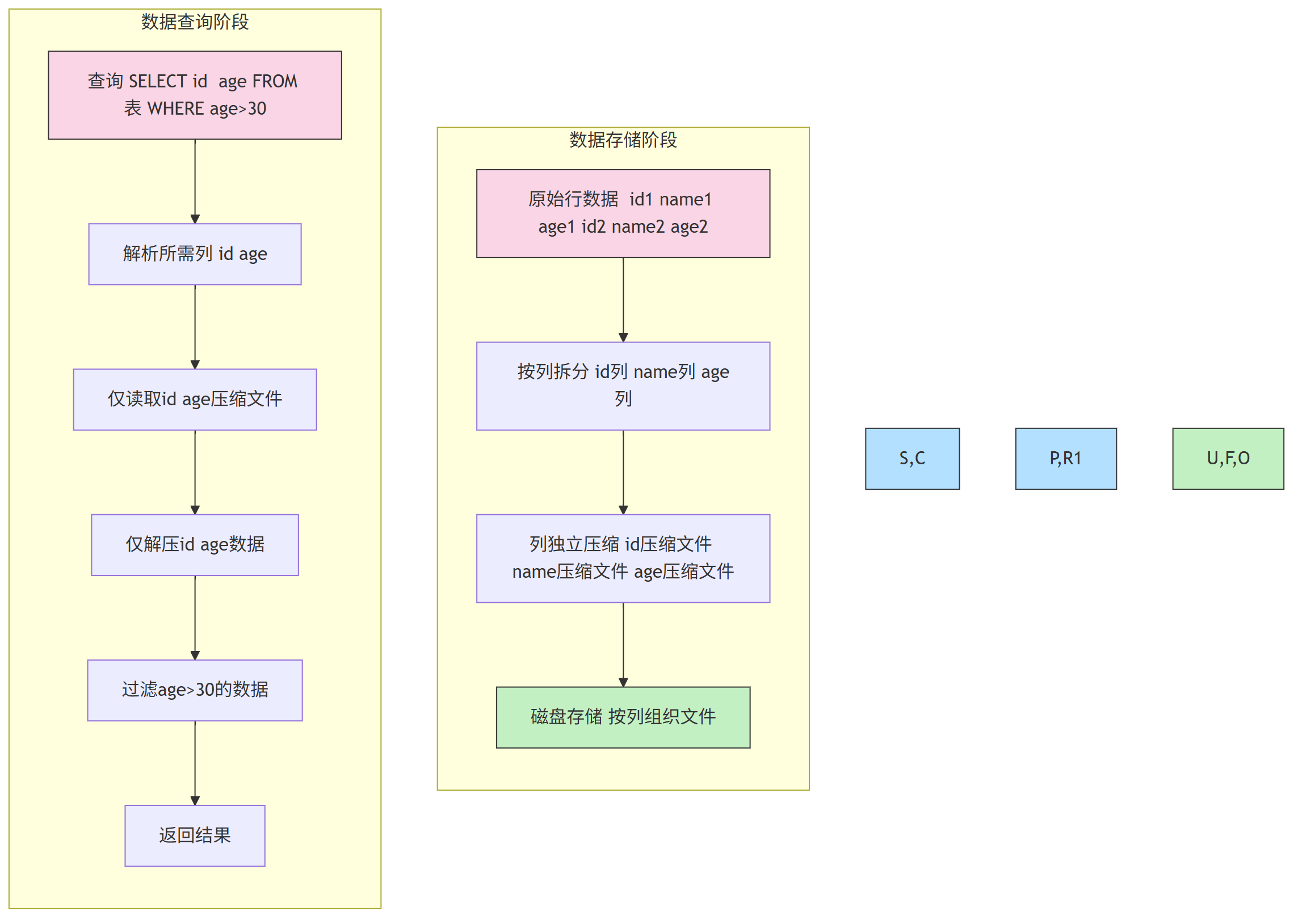
3.1 列式存储:减少无效数据读取
传统行存储按“行”存储数据(一行所有列存在一个文件),查询时需读取整行数据;
而列式存储按“列”拆分存储(每列单独一个文件),查询时仅读取所需列,同时同列数据特征相似,压缩率更高(生产中常达 8:1)。

3.2 向量化执行:提升 CPU 效率
传统计算引擎“单条数据处理”(一次处理 1 条数据,CPU 缓存命中率低);
ClickHouse 采用“批量处理”,将数据分成固定大小的块(如 1024 条),借助 CPU 的 SIMD(单指令多数据) 指令集,1 条指令处理多个数据,大幅提升 CPU 利用率。
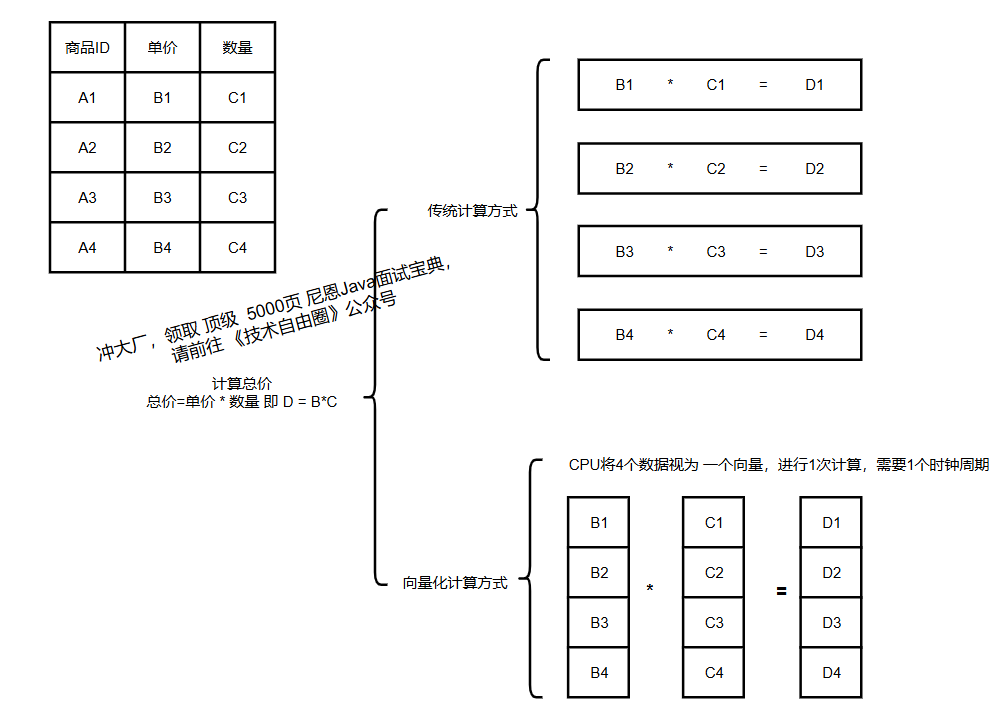
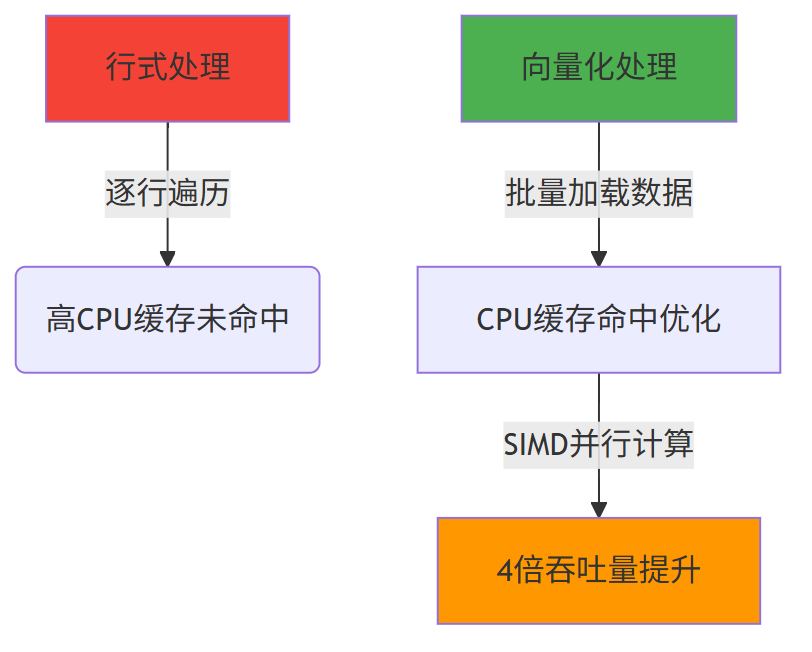
3.3 数据预排序:加速范围查询
ClickHouse 基于类 LSM 算法,数据写入时先在内存排序,刷盘后通过后台 Compaction 合并为有序大分区,确保磁盘数据始终有序。
查询时可利用有序性快速定位范围(如“时间>2024-01-01”),减少扫描的数据量。
MergeTree (本地表) 建表语句的 示例
-- 示例:创建 MergeTree 表(核心表引擎,支持预排序)
CREATE TABLE IF NOT EXISTS user_behavior (
user_id UInt64, -- 用户ID(无符号整数)
behavior_type String, -- 行为类型(点击/购买)
create_time DateTime, -- 行为时间
product_id UInt64 -- 商品ID
) ENGINE = MergeTree() -- MergeTree:支持预排序、Compaction
ORDER BY (user_id, create_time) -- 排序键:决定数据存储顺序(核心配置)
PARTITION BY toYYYYMM(create_time) -- 按年月分区(优化时间范围查询)
PRIMARY KEY user_id; -- 主键:需为排序键前缀(此处user_id是排序键首字段)
-- 关键解释:
-- 1. ORDER BY 是预排序的核心,查询常按 user_id+时间范围过滤,有序数据可快速定位
-- 2. PARTITION BY 按时间分区,查询时先定位分区,再扫描分区内数据
4、 ClickHouse 表引擎
表引擎决定了数据的存储方式、查询支持能力、并发控制等
4.1 ClickHouse 提供多种引擎
ClickHouse 提供多种引擎,适配不同场景,常用引擎如下:
| 表引擎类型 | 代表引擎 | 核心用途 | 适用场景 |
|---|---|---|---|
| 核心存储引擎 | MergeTree | 海量结构化数据存储(支持预排序、分区) | 业务核心表(如用户行为、订单表) |
| 分布式引擎 | Distributed | 管理分片集群(不存储数据,仅路由请求) | 分布式查询入口(对外提供统一表名) |
| 内存引擎 | Memory | 内存存储(数据重启丢失) | 临时计算、小表缓存 |
| 日志引擎 | Log | 轻量存储(无索引) | 日志数据(如审计日志、访问日志) |
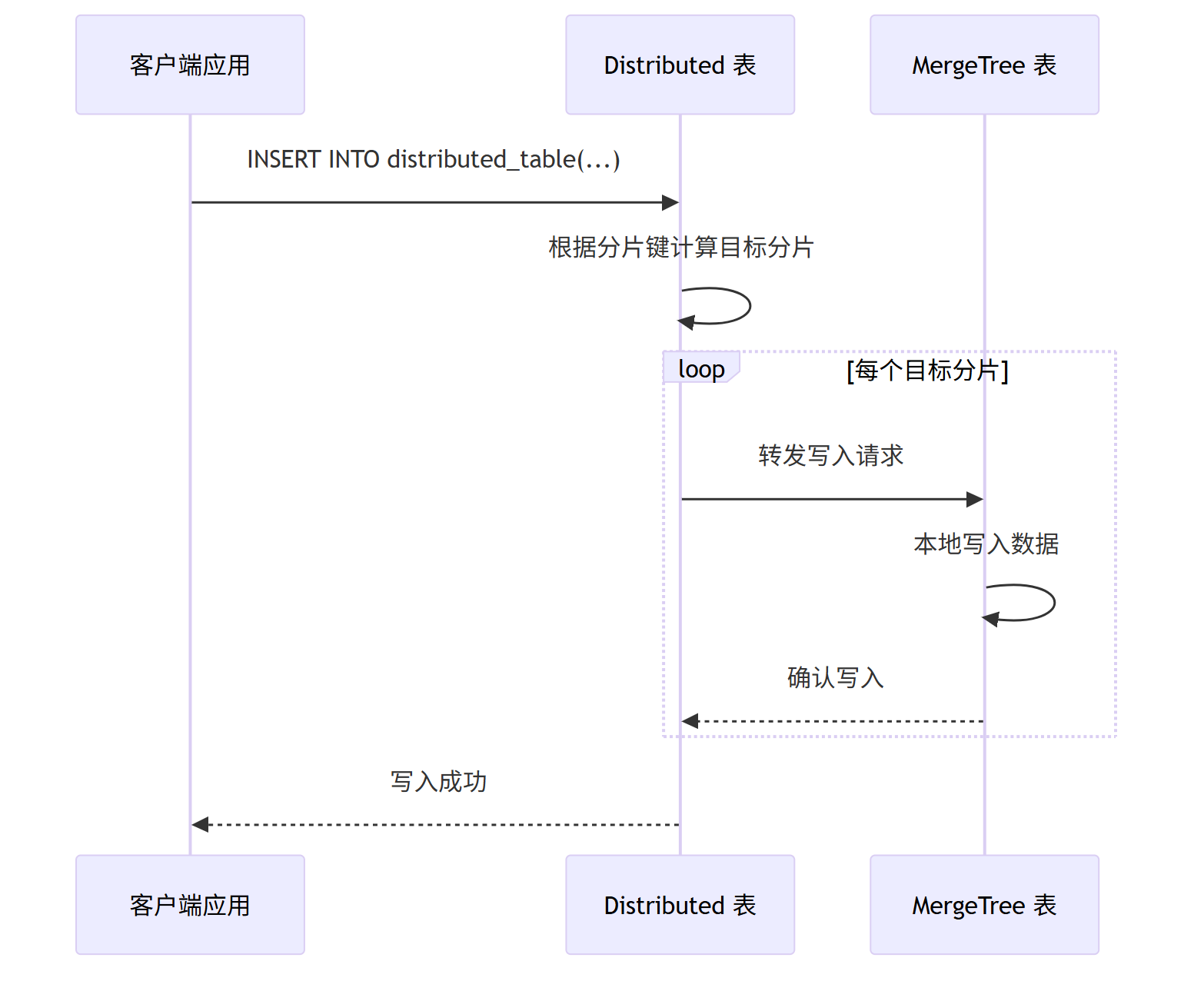
Distributed 关键解释:
- Distributed 表本身不存数据,仅作为“路由入口”
- 写入时:按分片键计算分片ID,路由到对应节点的本地表
- 查询时:向所有分片发送子查询,汇总结果后返回
Distributed 表建表示例(分片管理)
-- 前提:已在 config.xml 配置集群 my_cluster(2个分片,每个分片1个副本)
CREATE TABLE IF NOT EXISTS user_behavior_dist (
user_id UInt64,
behavior_type String,
create_time DateTime,
product_id UInt64
) ENGINE = Distributed(
my_cluster, -- 集群名称(配置文件中定义)
default, -- 数据库名(与本地表一致)
user_behavior, -- 本地表名(每个分片节点上的表)
user_id -- 分片键(按user_id哈希分片,保证数据均匀)
);
4.2 Distributed 与 MergeTree 引擎在 ClickHouse 中的协作关系
在 ClickHouse 的高性能列式数据库架构中,Distributed 引擎和 MergeTree 系列引擎有着密切的协同关系,共同构建了 ClickHouse 的分布式处理能力。
Distributed 与 MergeTree 引擎 对比
| 特性 | Distributed 引擎 | MergeTree 引擎 |
|---|---|---|
| 本质 | 逻辑引擎(无实际存储) | 物理存储引擎 |
| 作用 | 分布式查询与写入协调 | 本地数据存储与处理 |
| 存储 | 不存储实际数据 | 管理本地磁盘数据 |
| 数据分布 | 跨节点/分片 | 分区内有序存储 |
| 依赖关系 | 依赖底层的 MergeTree 表 | 作为 Distributed 表基础 |
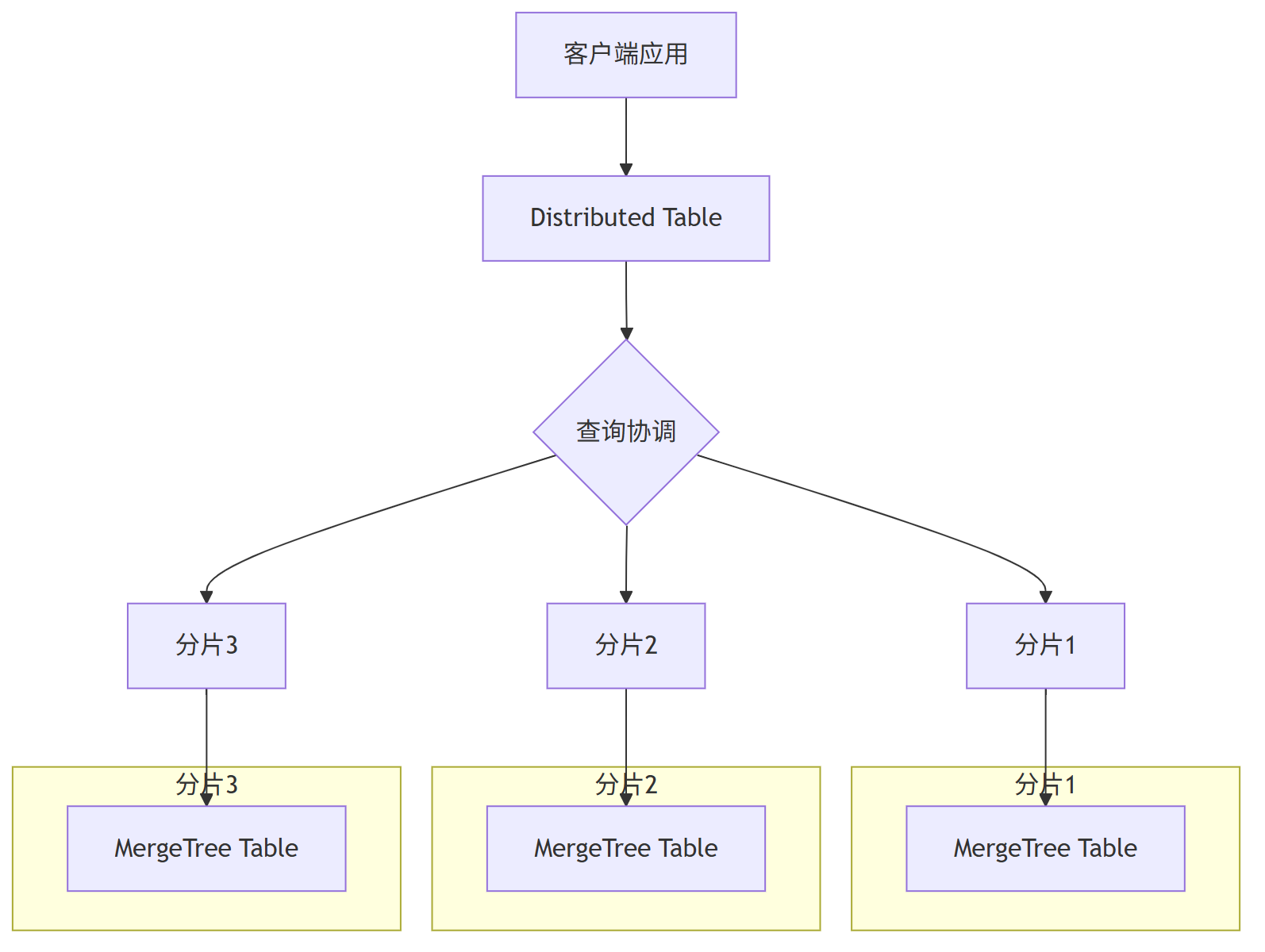
4.3 Distributed 与 MergeTree 引擎协作机制说明
Distributed 和 MergeTree 引擎在 ClickHouse 中各司其职:
- •MergeTree 引擎提供高性能本地存储和处理, 作为物理存储基础,每个分片上有独立的MergeTree实例
- •Distributed 引擎实现透明分布式访问层, 提供 分布式访问入口
- •协作关系:Distributed 表是逻辑入口,MergeTree 表是物理基础
4.3.1. 数据写入流程
4.3.2. 查询处理流程
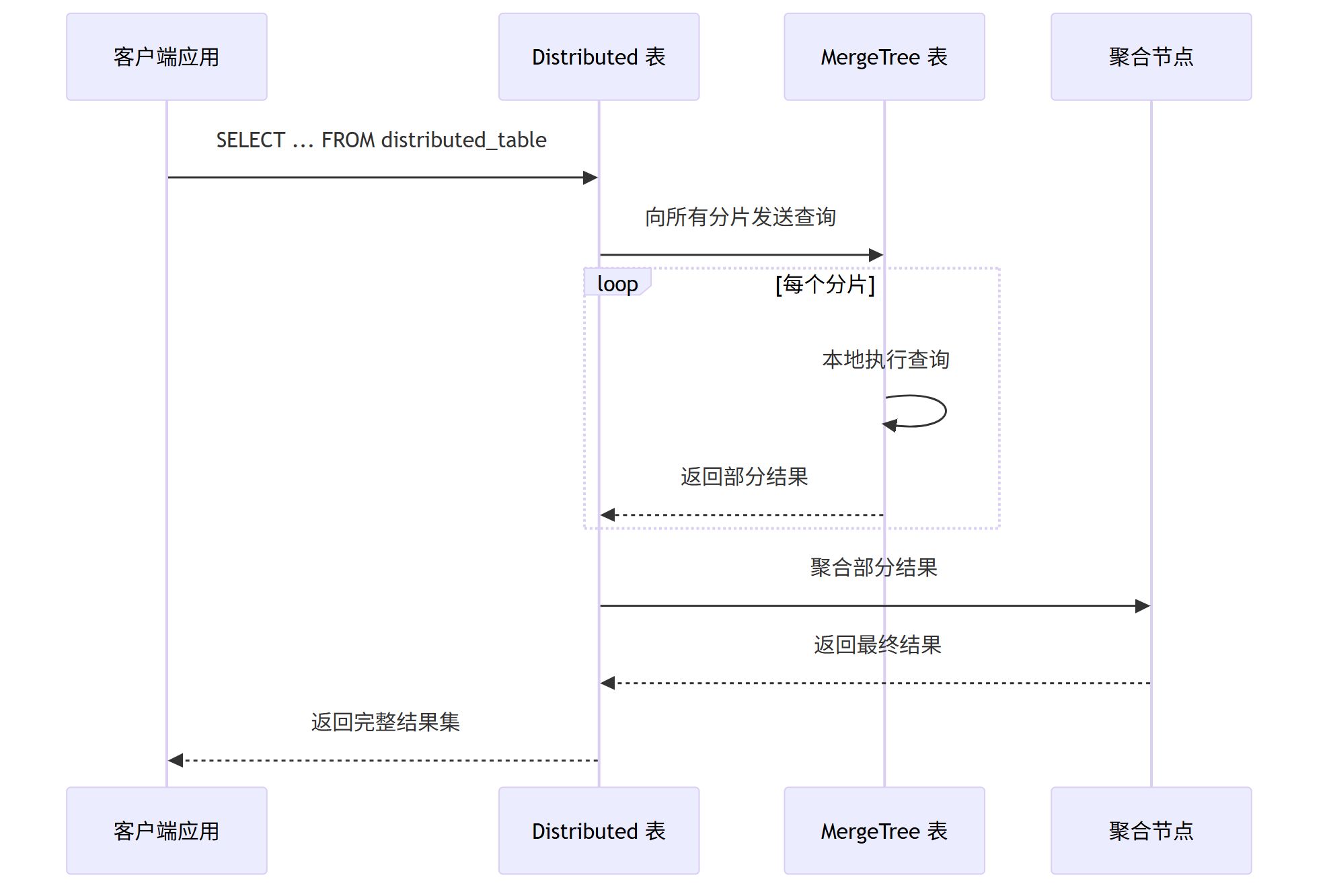
4.3.3. 实际应用场景
-- 创建本地存储表
CREATE TABLE events_local ON CLUSTER main_cluster
(
event_date Date,
event_type String,
user_id UInt64,
value Float64
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/events_local', '{replica}')
PARTITION BY toYYYYMM(event_date)
ORDER BY (event_date, event_type);
-- 创建分布式访问表
CREATE TABLE events_distributed AS events_local
ENGINE = Distributed('main_cluster', 'default', 'events_local', rand());
5、 ClickHouse 数据类型
ClickHouse 支持 100+ 数据类型,设计上兼顾“存储效率”与“计算性能”,核心类型分类及实践如下:
核心数据类型表
| 类型分类 | 具体类型 | 用途说明 | 示例 |
|---|---|---|---|
| 基本数值类型 | UInt8/UInt64 | 无符号整数(存储ID、计数,节省空间) | user_id UInt64 |
| Int8/Int64 | 有符号整数(存储带正负的数值) | score Int32 | |
| Decimal(P,S) | 高精度小数(金额、汇率,避免浮点误差) | amount Decimal(18,2) | |
| 日期时间类型 | Date | 日期(YYYY-MM-DD,仅占2字节) | create_date Date |
| DateTime64(N) | 带精度的时间(N为小数位数,如毫秒) | pay_time DateTime64(3) | |
| 复杂类型 | Array(T) | 同类型数组(存储多值,如商品分类) | tags Array(String) |
| Nested(k1 T1, k2 T2) | 嵌套结构(类似JSON数组对象) | addr Nested(street String, city String) | |
| 优化类型 | LowCardinality(T) | 低基数优化(值数量<1万,如状态) | status LowCardinality(String) |
| Nullable(T) | 支持空值(需额外存储空标记,慎用) | email Nullable(String) |
复杂类型使用示例
-- 示例:含复杂类型的商品表
CREATE TABLE IF NOT EXISTS product_info (
product_id UInt64,
name String,
category Array(String), -- 数组:商品所属多个分类
price Decimal(18,2),
status LowCardinality(String), -- 低基数:状态仅“在售/下架/预售”
update_time DateTime64(3),
remark Nullable(String) -- 可空:备注可能为空
) ENGINE = MergeTree()
ORDER BY product_id;
-- 插入数据(数组用[],空值用NULL)
INSERT INTO product_info VALUES (
1001,
"5G手机",
["电子设备", "手机", "5G"], -- 数组值
3999.00,
"在售", -- 低基数值
now64(3), -- 当前毫秒时间
NULL -- 空值
);
-- 关键解释:
-- 1. LowCardinality:将“在售”编码为0、“下架”为1,存储时用编码值,减少空间
-- 2. Array:查询时用 HAS 关键字(如 category HAS '5G')快速过滤
6、 分片与副本策略
在 ClickHouse 中,为了提升查询性能及增加数据容错性,分别在水平方向和垂直方向上划分为分片(shard)及副本(replica)。
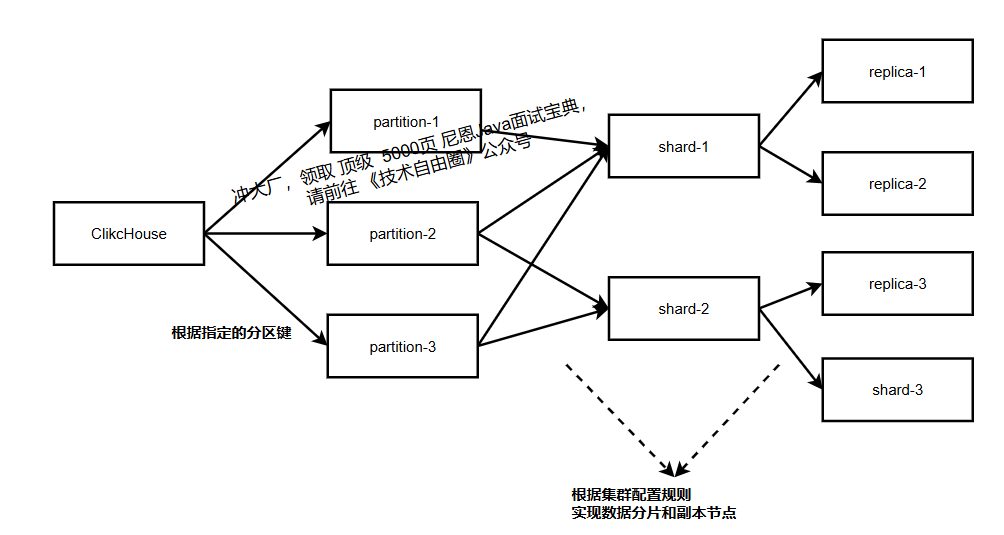
在分布式模式下,ClickHouse 会将数据在水平方向上分为多个分片(shard),并且分布到不同节点上,不同分片间的数据不同。
分片(shard) 的目的主要是为了提升查询性能,方便多线程及分布式查询。
在分布式查询时,按照分片数量拆分成若干个对本地表的子查询,然后依次查询每个分片的数据,再合并汇总返回。
6.1 分片:水平拆分数据
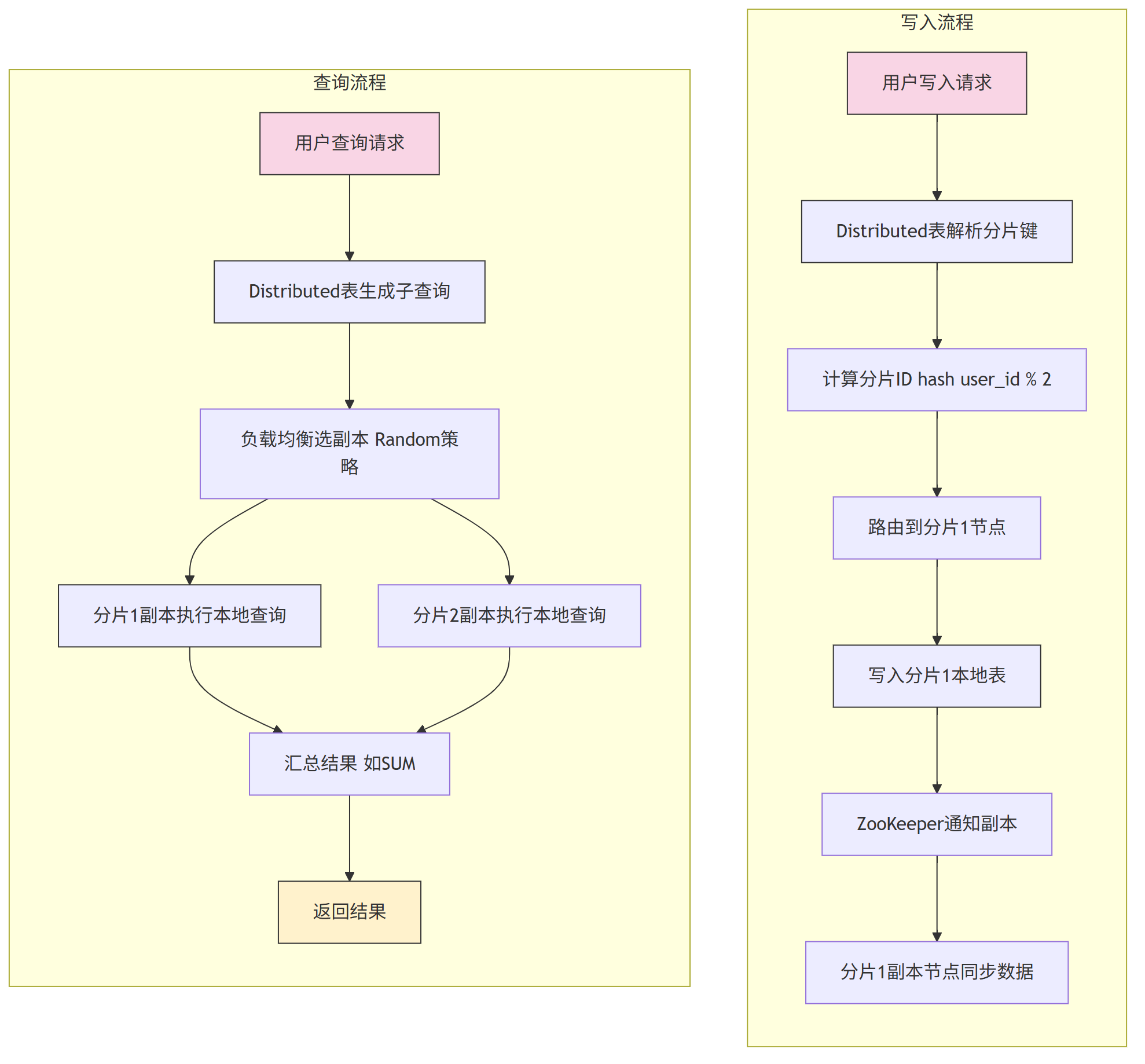
将数据按“分片键”拆分为多个部分(分片),分布到不同节点,查询时并行处理各分片数据,提升效率。分片键选择需满足“数据均匀分布”(如 user_id、order_id)。
分片策略:
- 哈希分片:按分片键哈希值分配(如
user_id % 分片数,最常用); - 随机分片:按随机数分配(数据均匀,但同一用户数据可能跨分片);
- 范围分片:按分片键范围分配(如时间范围,适合按时间查询的场景)。
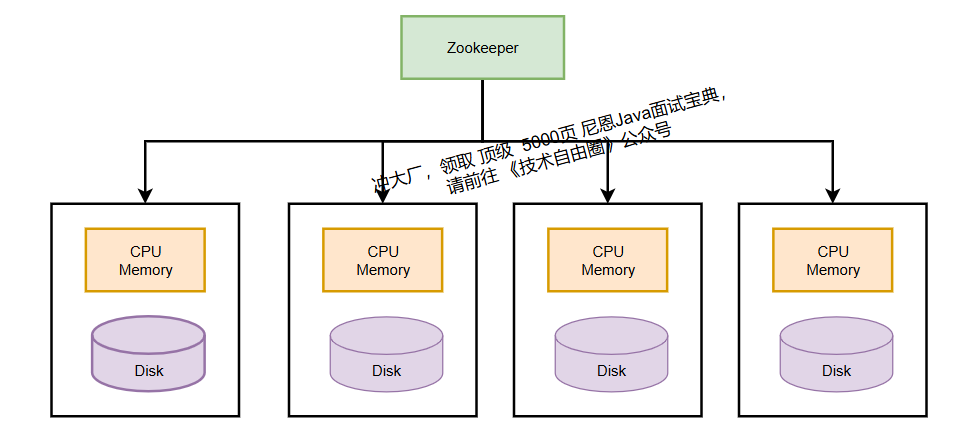
6.2 副本:垂直冗余数据
同一分片的数据在多个节点存储副本,借助 ZooKeeper 实现副本同步(写入一个副本后,自动同步到其他副本),避免单点故障。
副本选择策略(负载均衡)
查询时,ClickHouse 按 load_balancing 参数选择副本,常用策略:
- Random(默认):优先选择错误数最少的副本,再随机;
- Round Robin:循环选择副本,避免单点压力;
- Nearest hostname:选择主机名最相似的副本(减少网络延迟)。
6.3 分片与副本整体流程
7、ClickHouse 索引设计
索引是加速查询的关键,ClickHouse 主要支持稀疏索引(主键索引) 和跳数索引,避免传统稠密索引的高存储开销。
7.1 稀疏索引(主键索引)
ClickHouse 将数据按“颗粒(默认 8192 行)”划分,仅为每个颗粒的首行存储主键值(存于 primary.idx),并通过标记文件(.mrk)记录颗粒的磁盘物理地址。查询时先通过索引定位颗粒,再读取颗粒数据,大幅减少扫描范围。


查询流程:
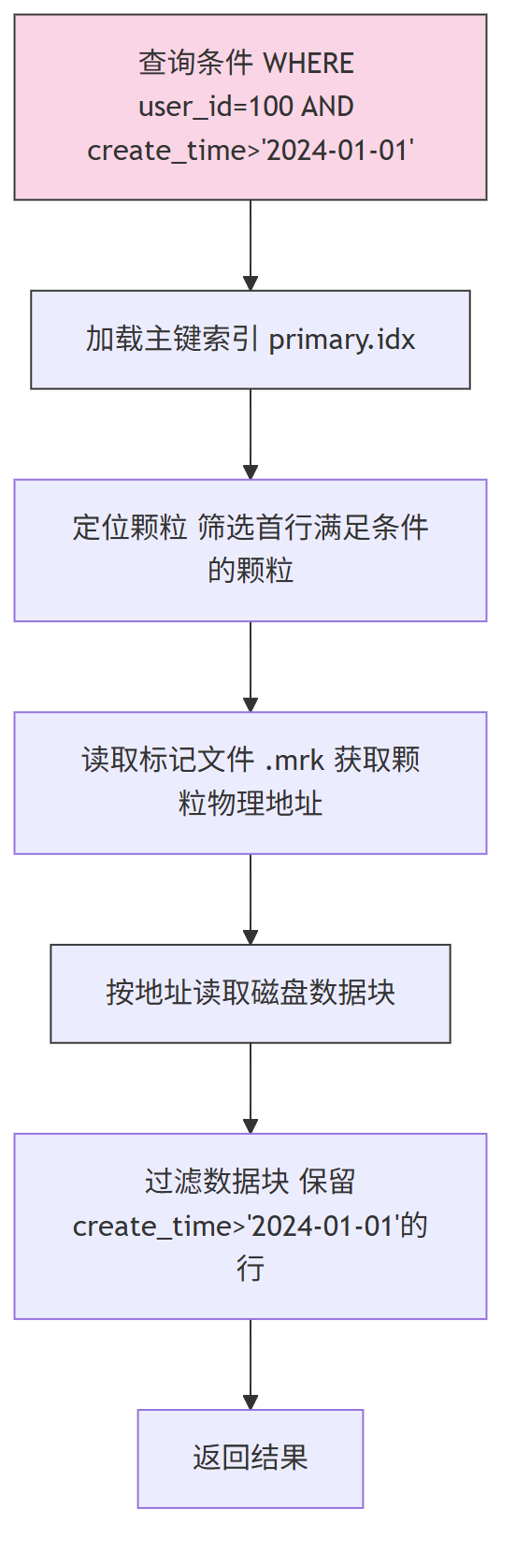
7.2 跳数索引(辅助索引)
当查询条件不命中主键时,跳数索引可进一步跳过无匹配数据的块,常用类型:
- minmax 索引:存储每个块的字段最值(适合范围查询,如时间范围);
- 布隆过滤器索引:快速判断块是否包含目标值(适合等值查询,如
category='5G'); - set 索引:存储块内所有 distinct 值(适合枚举值查询)。
跳数索引创建示例:
-- 示例1:为时间字段创建minmax索引(优化范围查询)
ALTER TABLE user_behavior
ADD INDEX idx_create_time create_time TYPE minmax GRANULARITY 8192;
-- GRANULARITY 8192:每8192行生成一个索引条目
-- 示例2:为数组字段创建布隆过滤器索引(优化等值查询)
ALTER TABLE product_info
ADD INDEX idx_category category TYPE bloom_filter(0.01) GRANULARITY 4096;
-- bloom_filter(0.01):误判率1%,平衡空间与精度
-- 关键解释:
-- 1. 跳数索引需手动创建,默认不开启
-- 2. 选择合适的GRANULARITY:值越小,索引越细,但存储开销越大
7.2 比喻说明
想象一下,ClickHouse 的表就是一本超厚的百科全书(比如《中国大百科全书》)。
1.主键索引(Primary Index)是啥?
- 它就是书最前面的 总目录。这个目录很稀疏,不会告诉你“苹果”在第几页,只会告诉你“A字母开头的条目”从第1页开始,“B字母开头的条目”从第50页开始……
- 在 ClickHouse 里,这就是稀疏索引。它通过主键帮你快速定位到数据块(Granule),
mark文件就像精确的页码,帮你翻到那一章。
2.那“跳数索引”又是干嘛的?
- 现在,你想在这本百科全书里找所有 “产地是新疆的水果”。
- 用总目录(主键索引)你只能找到“水果”这个大类在哪(比如在“S”字母 section),但你还是得把“水果”这一整章几十页全部读完,才能找出哪些水果的产地是新疆。这很慢。
- 跳数索引,就像是有人在书页边上贴了各种各样的便利贴,或者给书做了很多专项小目录。
- 比如,有人做了一份 “产地索引” 的小册子,上面写着:•
产地:新疆-> 出现在第15页、第28页、第33页•产地:海南-> 出现在第22页、第40页 - 有了这个“产地索引”(也就是跳数索引),你就不用去读“水果”章节的所有几十页了。你直接翻到第15、28、33页看一眼,就能找到所有新疆水果。你跳过了大量根本不相关的书页!
8、ClickHouse 计算引擎
ClickHouse 计算引擎的核心是“将 SQL 转化为可执行计划, 然后 并行执行”
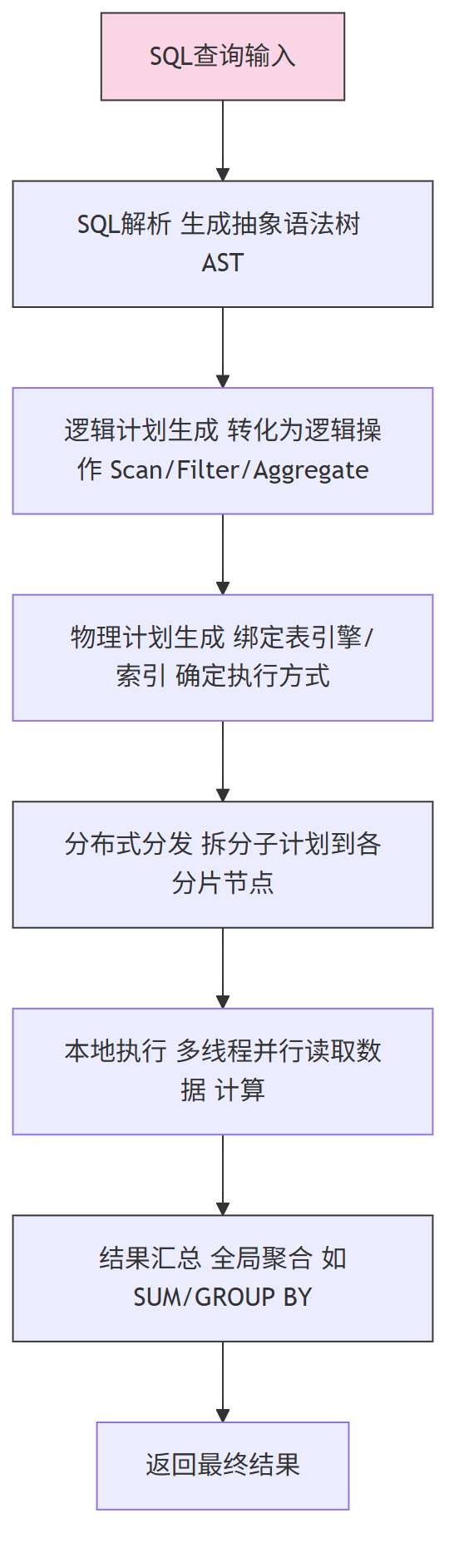
从功能和整体架构上讲,ClickHouse 的计算引擎与 其他数据库(如mysql )的计算引擎并没有很大的不同。
功能都是将可描述的结构化查询语言(SQL)转化翻译为可以执行的物理计划以及执行计算并获得计算结果,而整体架构都有包含 SQL 解析、翻译解释、计算执行等部分。
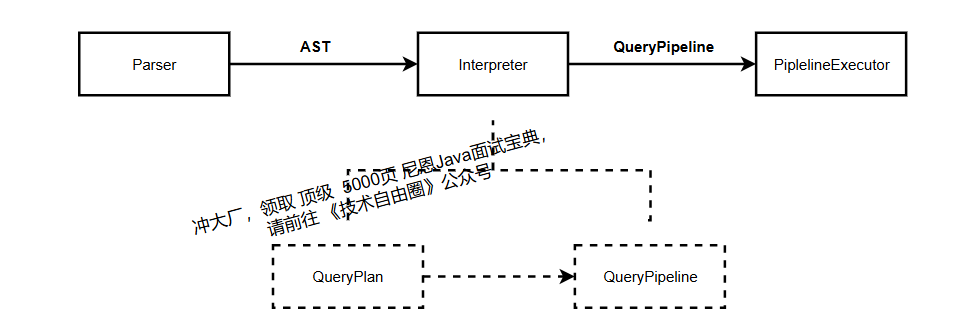
计算引擎核心流程
从实现方面,ClickHouse 同样采用了多线程及分布式查询,成为其高性能和高扩展性的关键。
通过线程级并行的方式提升性能,利用多核 CPU 的计算能力;
通过采用分布式架构,支持分片和副本,通过将数据分布到多个节点实现存储和计算的扩展。
二、ClickHouse聚合算子实现原理
在ClickHouse中,聚合是最核心的算子之一,也是优化最多的部分。
聚合 底层实现融合了算法设计、数据结构优化和硬件特性利用,最终实现了对海量数据的高效聚合。
在 ClickHouse 中,聚合操作所使用的 Hashmap 中的 Key,本质上, 就是由 GROUP BY 子句计算出的值(分组键)。
ClickHouse的聚合实现是“算法设计+硬件特性+场景适配”的结合体,每个优化都针对具体痛点。
理解这些细节,不仅能更好地使用ClickHouse,也能为其他大数据引擎的优化提供思路。
2.1、聚合算法核心架构:从两阶段到并行化
ClickHouse的聚合逻辑核心围绕三个要素展开:HashMap(存储中间结果)、并行计算(提升效率)、两阶段聚合(减少数据传输)。
理解这三个要素,是掌握聚合实现的基础。
2.1.1 聚合流程 的 两个 基础 阶段
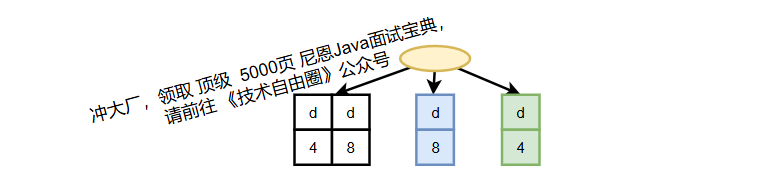
常规聚合过程分为pre-aggregate(初步聚合) 和final-aggregate(最终聚合) 两个阶段:
- pre-aggregate:多个线程(T1、T2、T3)各自处理部分数据,用HashMap存储本地中间结果(如每个线程计算自己负责的数据的sum/count);
- final-aggregate:单线程合并所有线程的中间结果,得到最终聚合结果。
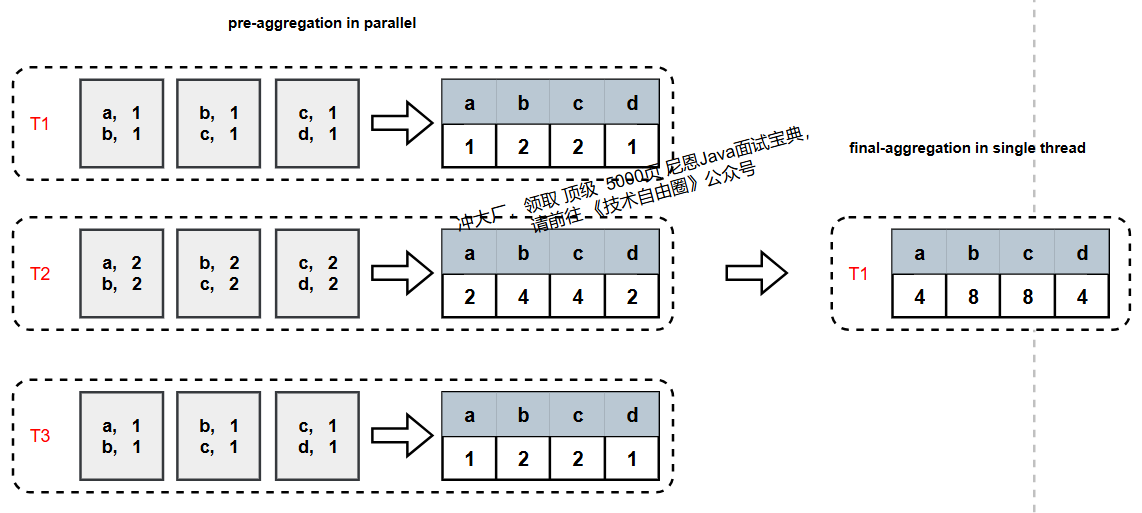
存在的问题:
如果pre-aggregate后数据量几乎没减少(比如聚合key基数极高),final-aggregate会因单线程处理大量数据而成为瓶颈,严重影响效率。
2.1.2 并行优化:Two-level HashMap的引入
为解决final-aggregate单线程瓶颈,ClickHouse引入Two-level HashMap(二级哈希表),实现final-aggregate的并行化。
2.1.2.1 Two-level HashMap结构
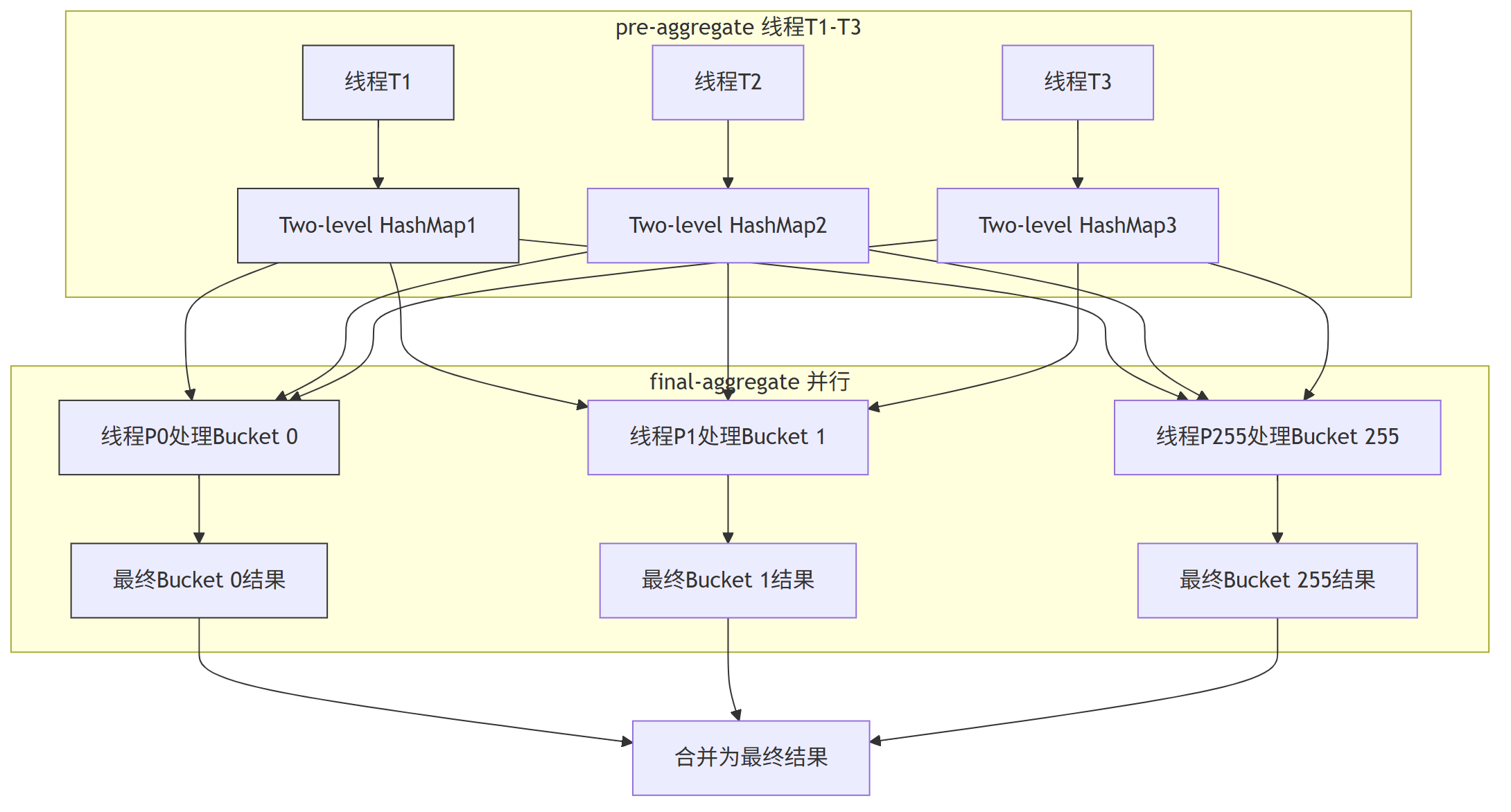
与常规HashMap不同,Two-level HashMap分为两层:
- 第一层:固定数量的Bucket(默认256个),每个Bucket是一个独立的子HashMap;
- 第二层:子HashMap内部用开放地址法处理冲突。
数据先通过哈希映射到第一层Bucket,再进入子HashMap处理,天然支持按Bucket拆分并行处理。
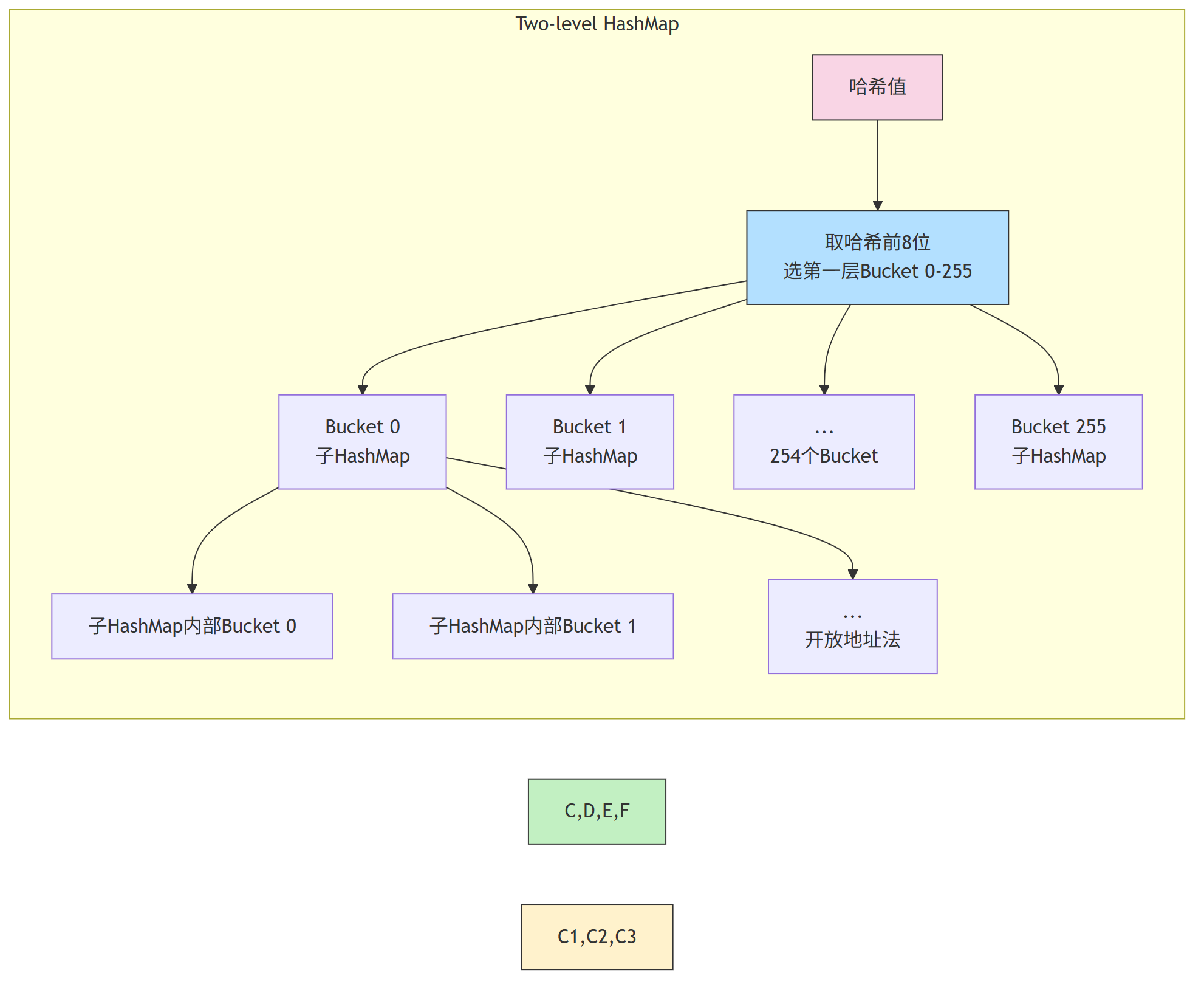
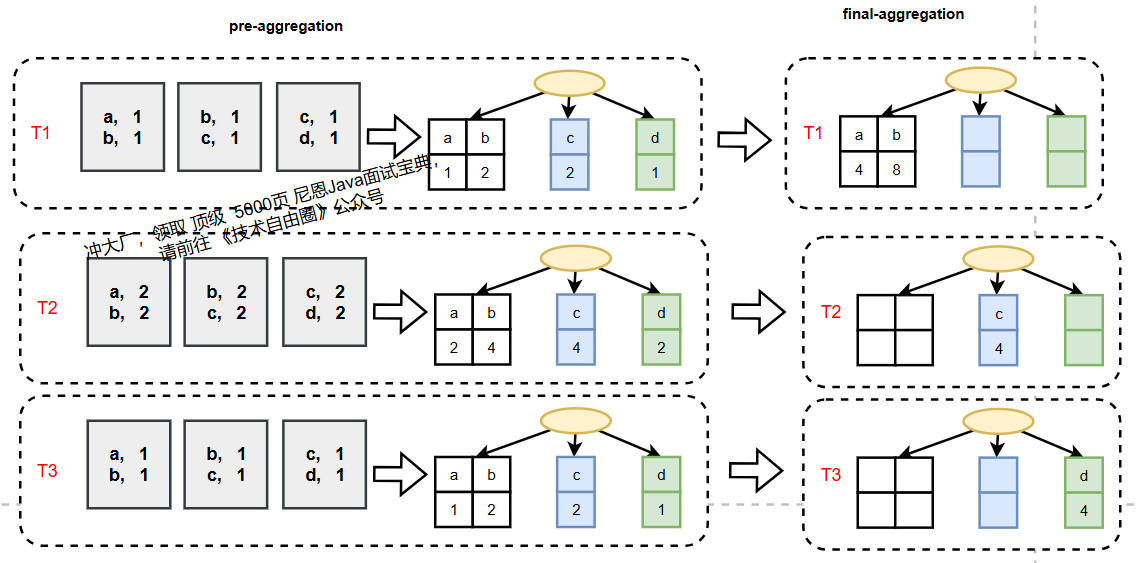
2.1.2.2 并行化的final-aggregate流程
引入Two-level HashMap后,final-aggregate可按第一层Bucket拆分任务,
每一个线程可以独立的 处理一个Bucket的子HashMap,避免并发冲突,实现并行合并:
2.1.3 聚合算法的自适应选择
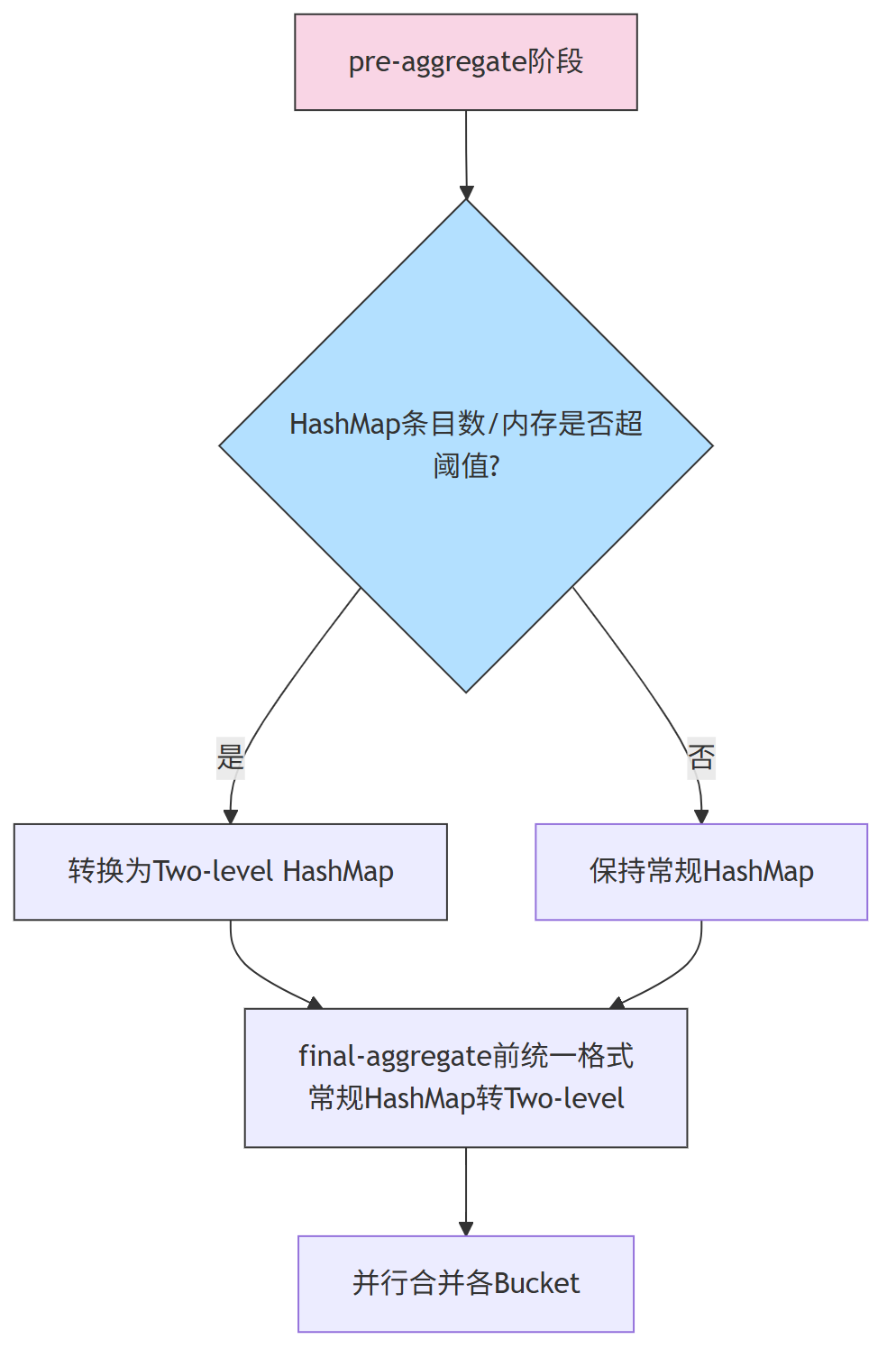
ClickHouse提供了一种运行时自适应的方式,在运行时选择选择聚合算法以及是否使用Two-level HashMap。
具体的策略是当pre-aggregate过程中,HashMap中的数据超过一定阈值,将其转换成Two-level HashMap。
参考参数:
group_by_two_level_threshold:HashMap中条目数超过该阈值时,转换为Two-level HashMap;group_by_two_level_threshold_bytes:HashMap占用内存超过该阈值时,转换为Two-level HashMap。
每个pre-aggregate线程独立选择是否是用Two-level HashMap的,那么在进行第二次聚合的时候输入可能既有常规HashMap也有Two-level Hashmap,对于这种情况会在final-aggregate前先将常规HashMap转换成Two-level的。整体的算法如下图所示:
转换逻辑如下:
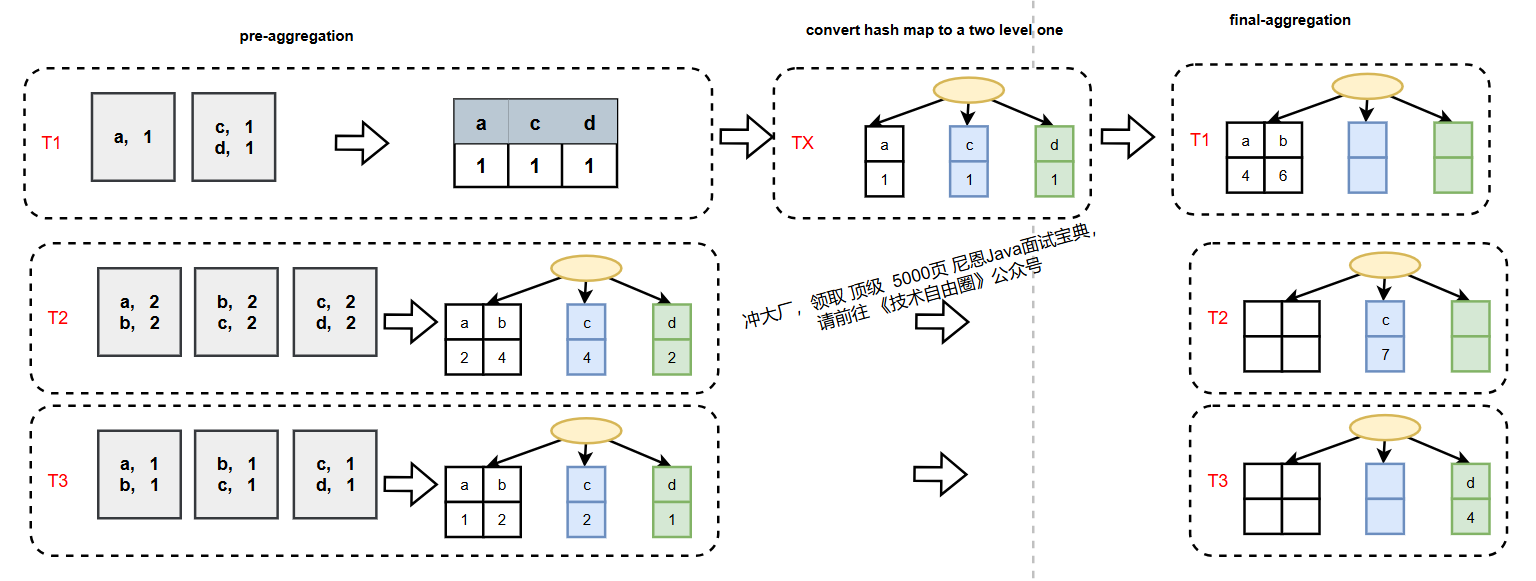
潜在优化点:目前HashMap到Two-level的转换是单线程执行,若改为并行转换可进一步提升效率。
2.2、HashMap的构建与聚合执行
ClickHouse的计算引擎基于列式存储,数据以Block(由多列组成的二维表)为单位流转。
聚合过程本质是将Block数据写入HashMap并执行聚合计算,分为“构建HashMap”和“执行聚合”两步。
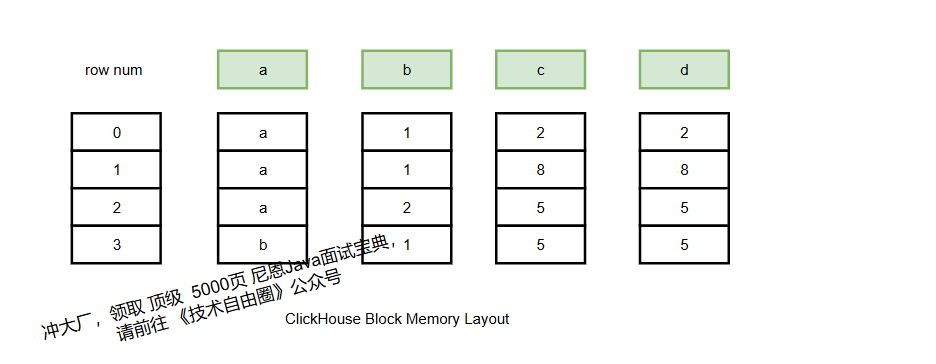
2.2.1 构建HashMap:初始化聚合状态
构建阶段 de 目标 :为所有聚合key分配内存,并初始化聚合函数的状态对象(如sum的初始值0、uniqExact的空HashSet)。
关键流程:
(1) 遍历Block中的每行数据,判断聚合key是否已在HashMap中;
(2) 若不存在,通过 Arena 分配聚合函数状态所需内存, Arena 就是内存池 ;
(3) 初始化状态对象(如sum函数初始化为0);
(4) 记录每行对应的状态对象内存地址,便于后续快速访问。
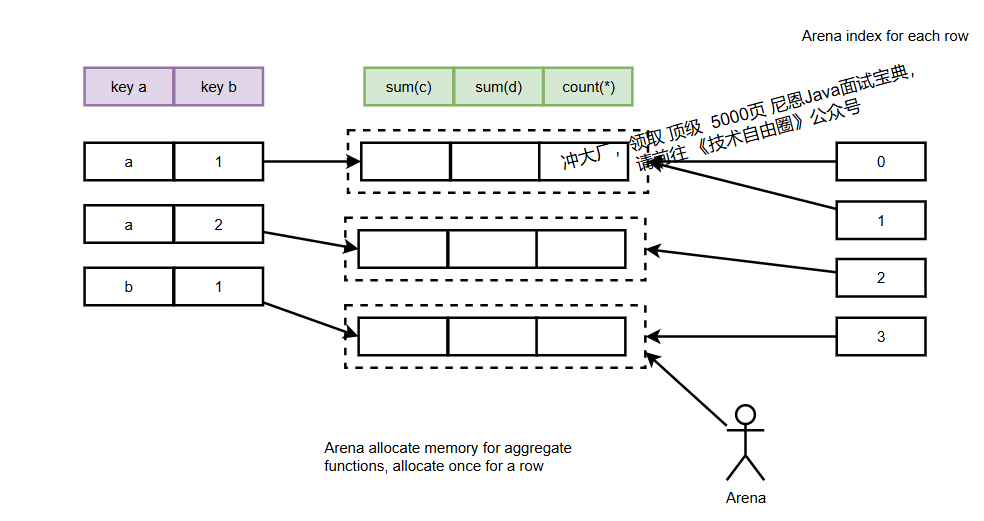
关键代码解析(内存分配与状态初始化):
/// 1. 为所有聚合函数状态分配内存
/// total_size_of_aggregate_states:所有聚合函数状态的总内存大小
/// aggregates_pool:Arena内存池(统一管理内存,便于监控和释放)
/// place:分配到的连续内存块起始地址
AggregateDataPtr place = result.aggregates_pool->alignedAlloc(
total_size_of_aggregate_states, // 总大小
align_aggregate_states // 内存对齐要求
);
/// 2. 初始化每个聚合函数的状态对象
/// offsets_of_aggregate_states:每个聚合函数在总内存中的偏移量
for (size_t j = 0; j < aggregate_functions.size(); ++j)
{
// 为第j个聚合函数创建状态对象(如sum创建AggregateFunctionSumData<Int64>)
aggregate_functions[j]->create(place + offsets_of_aggregate_states[j]);
}
为什么用Arena而不是new?
聚合可能消耗大量内存,Arena可集中管理内存,便于监控总占用量、限制单查询内存使用,或在内存不足时将状态 spill 到磁盘。
Arena 是什么?
Netty 源码中也用到了 Arena ,具体请参考 尼恩的 Netty对象池、内存池视频。
简单说,Arena 是一个预分配的大块连续内存(内存池)。当聚合需要为新的分组键分配内存(存储键值或聚合状态)时,不再频繁调用系统的
new或malloc,而是从 Arena 中“划出”一小段连续空间使用。
2.2.2 执行聚合:更新状态对象
构建完HashMap后,需根据每行数据更新对应的聚合函数状态(如sum累加、count递增)。
由于状态对象分散在不同内存地址,无法通过SIMD指令批量处理,但可针对特殊场景优化。
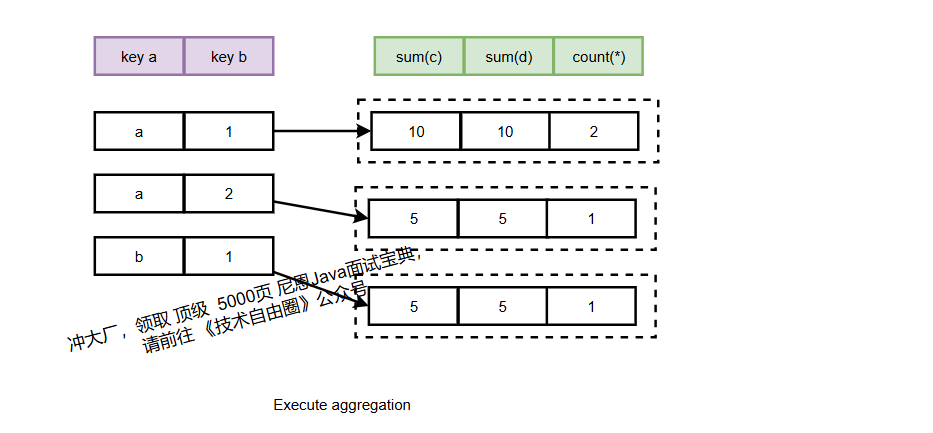
常规聚合执行代码:
/// 为一个聚合函数批量处理多行数据
void IAggregateFunctionHelper::addBatch(
size_t row_begin, // 起始行
size_t row_end, // 结束行
AggregateDataPtr * places, // 每行对应的状态对象地址
size_t place_offset, // 状态对象在内存块中的偏移
const IColumn ** columns, // 输入列数据
Arena * arena, // 内存池(可能用于动态分配,如HashSet扩容)
ssize_t if_argument_pos // 条件列位置(可选)
) const override
{
// 遍历行,更新对应状态
for (size_t i = row_begin; i < row_end; ++i)
if (places[i]) // 若状态对象存在(已初始化)
// 调用具体聚合函数的add方法(如sum累加)
static_cast<const Derived *>(this)->add(
places[i] + place_offset, // 状态对象地址
columns, // 输入数据列
i, // 当前行号
arena
);
}
特殊优化:常量key的SIMD加速
若所有聚合key相同(结果只有一条),可通过SIMD指令批量处理:
/// Sum函数针对常量key的批量处理(用SIMD加速)
template <typename Value>
void NO_INLINE AggregateFunctionSumData::addMany(
const Value * __restrict ptr, // 输入数据指针(__restrict避免指针别名,优化编译)
size_t start,
size_t end
)
{
#if USE_MULTITARGET_CODE
// 根据CPU支持的指令集选择最优实现
if (isArchSupported(TargetArch::AVX512BW))
{
addManyImplAVX512BW(ptr, start, end); // 用AVX512BW指令
return;
}
else if (isArchSupported(TargetArch::AVX2))
{
addManyImplAVX2(ptr, start, end); // 用AVX2指令
return;
}
// ... 其他指令集(SSE42等)
#endif
// 无SIMD支持时的普通实现
addManyImpl(ptr, start, end);
}
JIT优化:新版本默认开启compile_aggregate_expressions参数,通过即时编译(JIT)生成聚合代码,减少函数调用开销,进一步提升效率。
三、HashMap类型选择策略
HashMap是聚合的核心数据结构,ClickHouse针对不同场景设计了30+种HashMap及哈希函数组合,核心思路是“特例化优化”——根据聚合key的类型和数量选择最优实现。
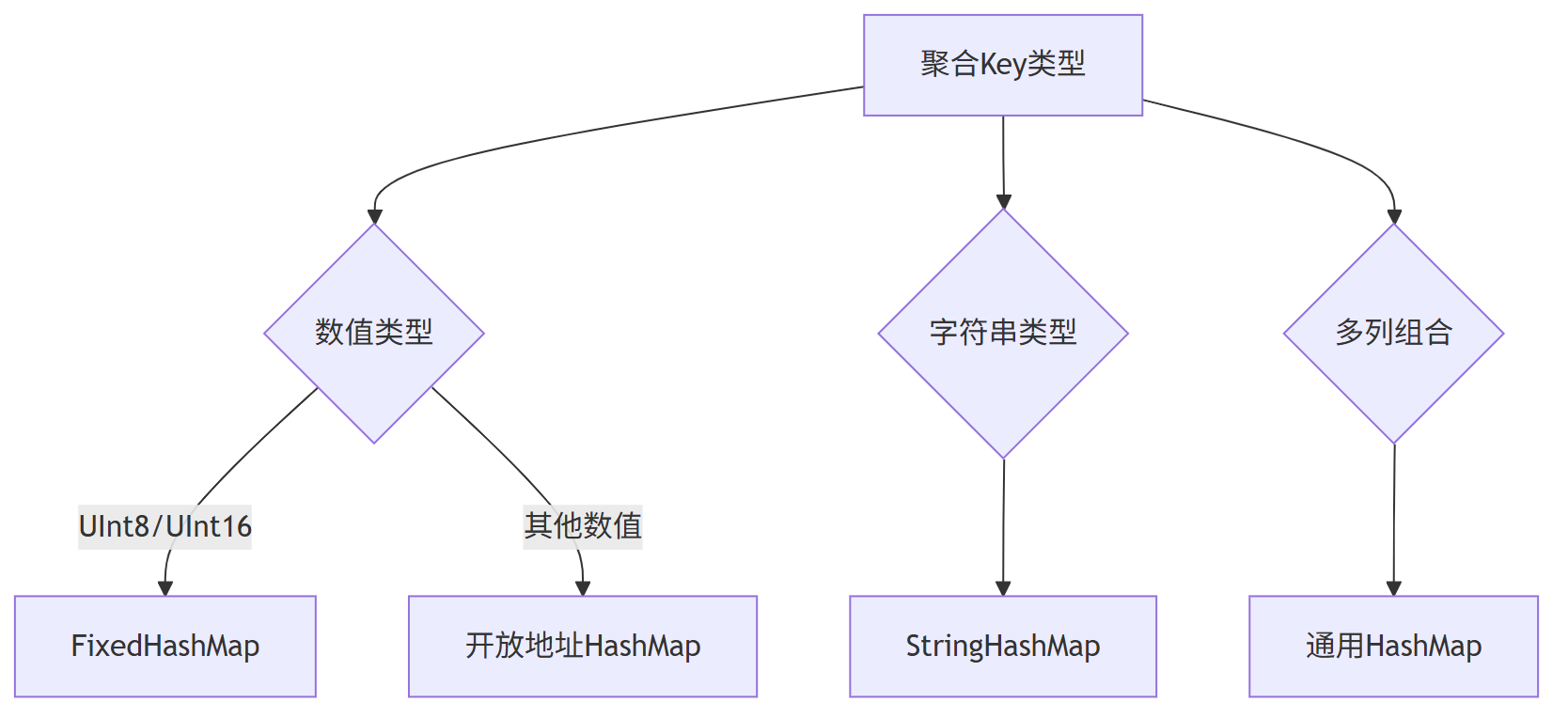
智能数据结构选择(临界点优化)
| 分组键特征 | 选用数据结构 | 性能临界点 |
|---|---|---|
UInt8 小范围(<256) |
FixedHashMap(数组) |
无哈希计算 O(1) |
| 普通整型/字符串 | HashMapWithSavedHash |
基数 < 1000万 |
| 海量基数(>1000万) | TwoLevelHashMap |
桶分治 + 并行 |
| 超长字符串 | StringHashMap |
短字符串内联存储 |
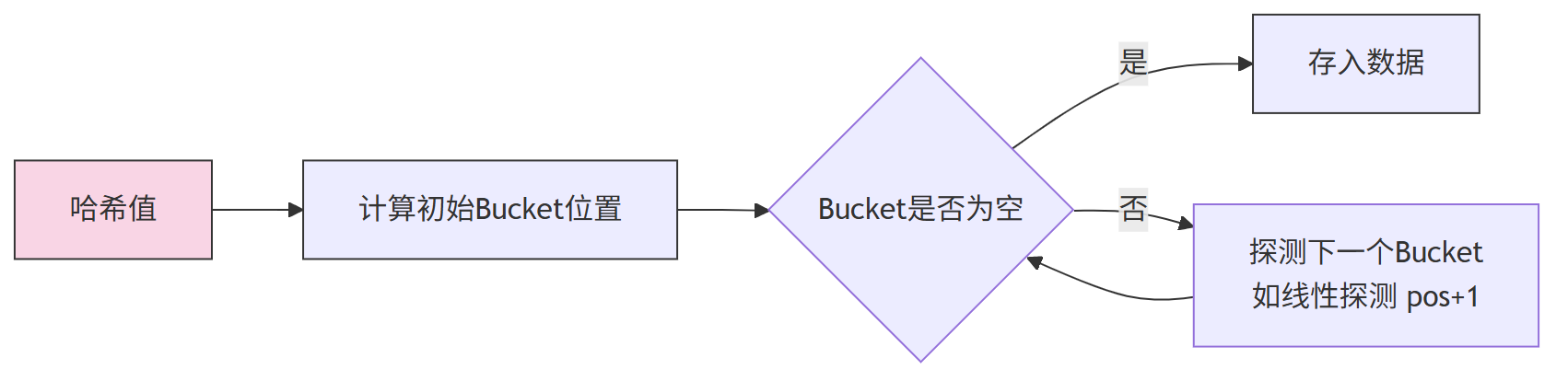
3.1 基础结构:开放地址法HashMap
ClickHouse采用开放地址法实现HashMap(而非Java标准库的拉链法),原因如下:
- 缓存友好:数据存储连续,CPU缓存命中率更高;
- 无内存碎片:插入时无需动态分配链表节点,减少内存碎片;
- 实现简单:避免链表遍历,合并HashMap时效率更高。

3.2 按场景优化的HashMap类型
3.2.1 FixedHashMap:适用于低基数整数key
当聚合key是UInt8(0-255)或UInt16(0-65535)时,直接用key值作为索引,无需哈希计算:
- 内存结构:固定大小的数组(如UInt8对应256个槽位);
- 优势:无哈希冲突、无需resize、查询O(1)。


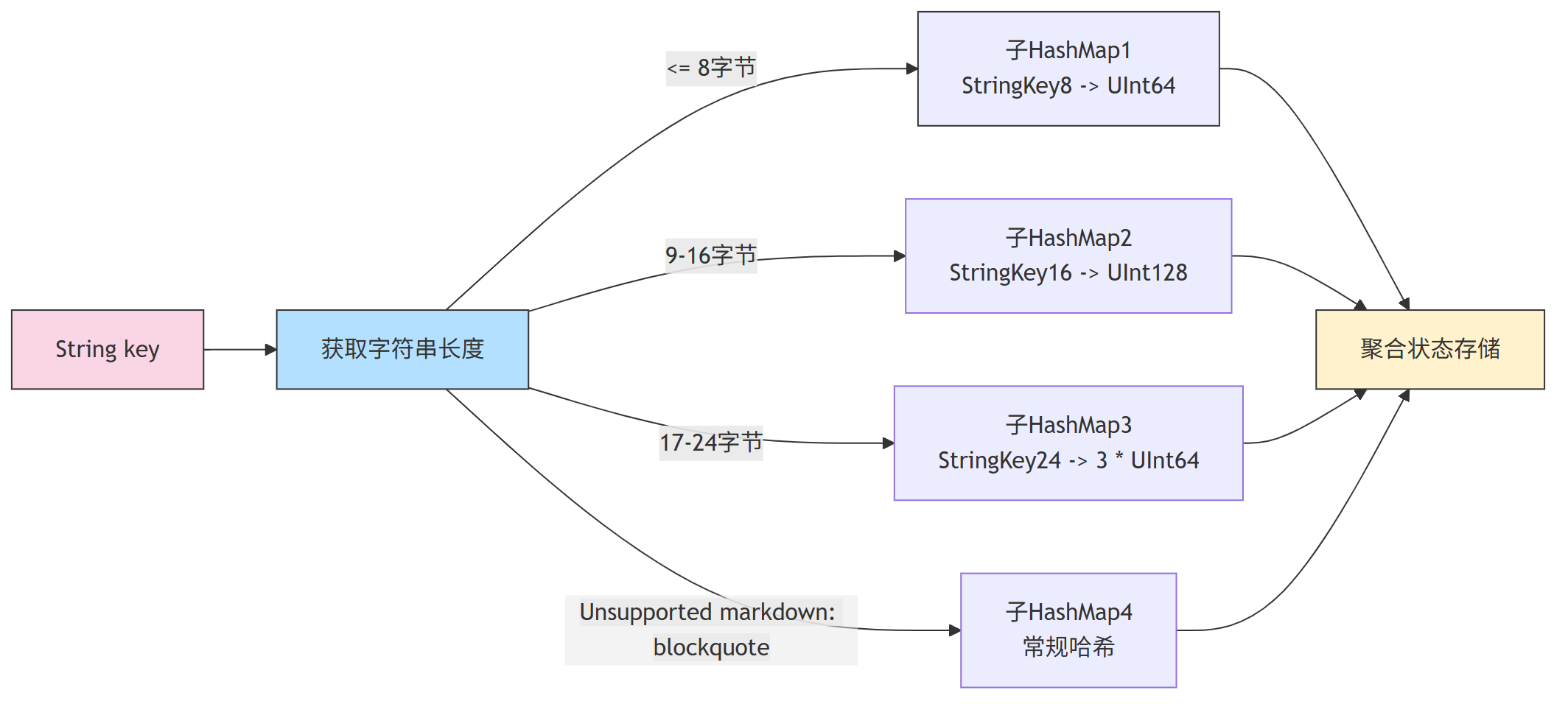
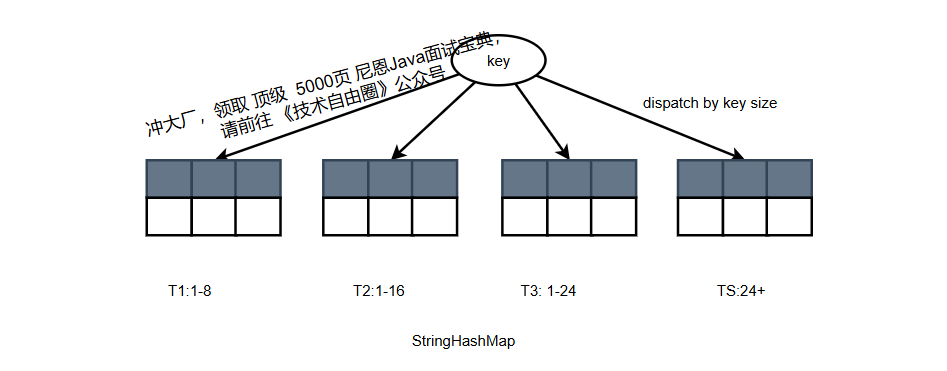
3.2.2 StringHashMap:适用于字符串key
字符串key长度可变,StringHashMap内置多个子HashMap,按字符串长度路由:
- 短字符串(≤8字节):用UInt64存储,哈希函数基于SSE42的
_mm_crc32_u64(硬件加速); - 中长字符串(≤24字节):拆分后用多个UInt64处理;
- 长字符串:用常规哈希函数。
哈希函数示例(SSE42加速):
struct StringHashTableHash
{
#if defined(__SSE4_2__)
// 处理8字节字符串key(StringKey8本质是UInt64)
size_t ALWAYS_INLINE operator()(StringKey8 key) const
{
size_t res = -1ULL; // 初始值
res = _mm_crc32_u64(res, key); // 用硬件CRC32指令计算哈希
return res;
}
// 处理16字节字符串key(拆分为两个UInt64)
size_t ALWAYS_INLINE operator()(StringKey16 key) const
{
size_t res = -1ULL;
res = _mm_crc32_u64(res, key.items[0]); // 第一部分
res = _mm_crc32_u64(res, key.items[1]); // 第二部分
return res;
}
// ... 其他长度处理
#endif
};
3.2.3 TwoLevelHashMap:支持并行聚合
如前文所述,TwoLevelHashMap含256个固定子HashMap,通过哈希值前8位选择子HashMap,剩余位用于子HashMap内部定位。
其变种TwoLevelHashMapWithSavedHash会缓存哈希值,合并时无需重复计算,进一步提速。

四、ClickHouse Group By 执行流程
由于平台篇幅限制, 剩下的内容(5000字+),请参参见原文地址

 浙公网安备 33010602011771号
浙公网安备 33010602011771号