InnoDB圣经: 硬核解读 InnoDB 内存架构 和 磁盘架构 (图解+秒懂+史上最全 )
本文 的 原文 地址
原始的内容,请参考 本文 的 原文 地址
尼恩说在前面
在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团、蚂蚁、得物的面试资格,遇到很多很重要的相关面试题:
InnoDB 内存结构 和 磁盘 结构, 你理解吗?
什么是 Doublewrite Buffer ?InnoDB是如何实现 Doublewrite Buffer 的?
比较undo log、redo log和bin log的作用和区别?
最近有小伙伴在面 腾讯,问到了mysql InnoDB 存储引擎 相关的面试题。 小伙伴 没有系统的去梳理和总结,所以支支吾吾的说了几句,面试官不满意,面试挂了。
所以,尼恩给大家做一下系统化、体系化的梳理,使得大家内力猛增,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
当然,这道面试题,以及参考答案,也会收入咱们的 《尼恩Java面试宝典PDF》V175版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请到文末公号【技术自由圈】获取
本文作者:
- 第一作者 老架构师 肖恩(肖恩 是尼恩团队 高级架构师,负责写此文的第一稿,初稿 )
- 第二作者 老架构师 尼恩 (45岁老架构师, 负责 提升此文的 技术高度,让大家有一种 俯视 技术、俯瞰技术、 技术自由 的感觉)
一、InnoDB 存储引擎
1、MySQL体系和InnoDB存储引擎
MySQL的体系结构是分层设计的,包括Server层和 Engin层。
1. 服务层(Server层):处理连接、查询解析、优化、内置函数
2. 存储引擎层(Engin层):负责数据存储/检索(可插拔)
Engin层 是可以拔插设计, 可以 选择不同的 存储引擎。
InnoDB 属于 Engin层 ,是默认的 存储引擎, 负责 "最终数据存储与管理"的核心组件。
MySQL整体架构:
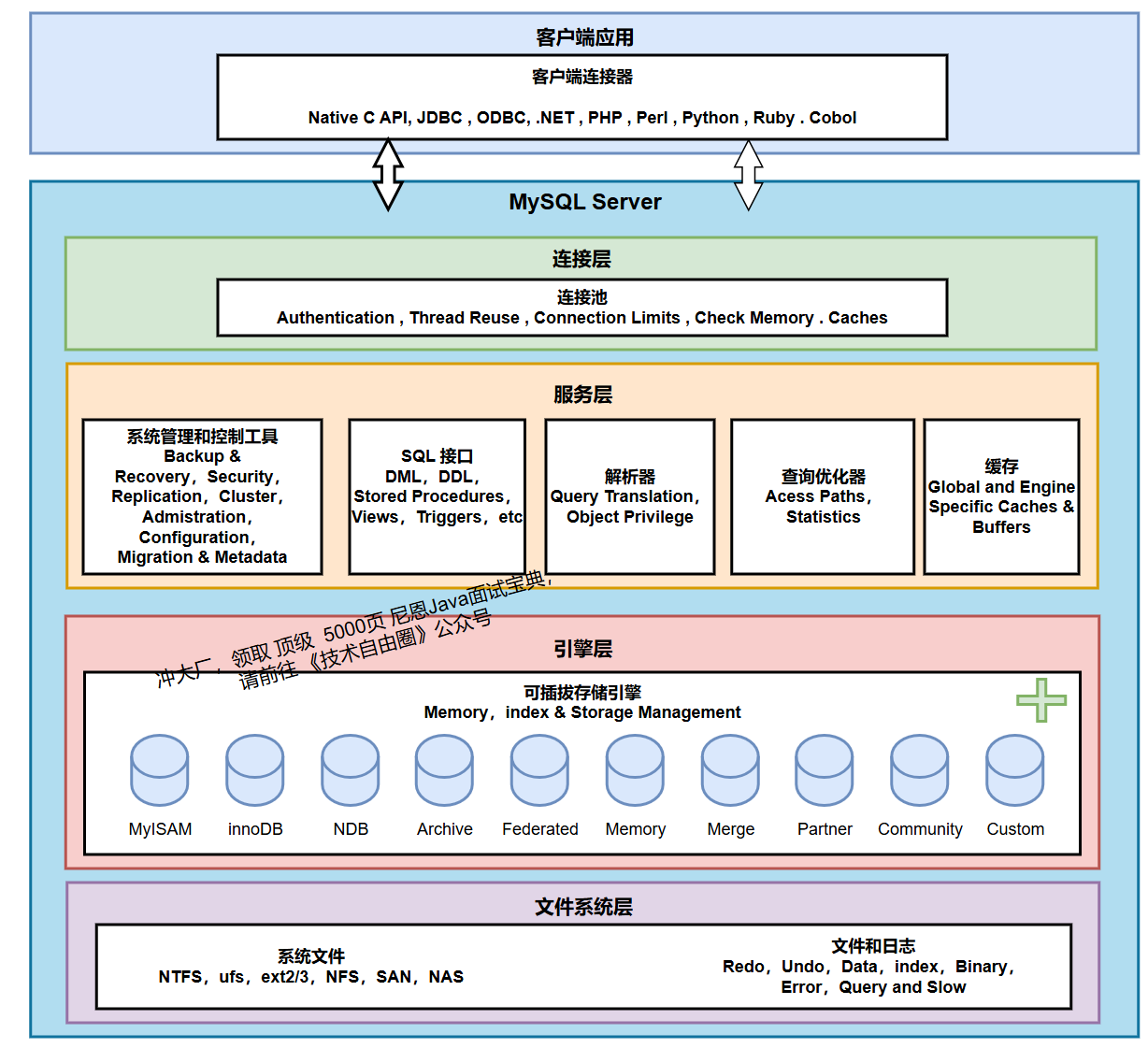
各层作用:
- 连接层:处理客户端接入(如TCP连接),验证密码,管理连接池。
- 服务层:负责SQL的解析、优化(比如选最优索引)、缓存,以及执行存储过程等。
- 存储引擎层:这是MySQL的"数据管家",通过统一接口与服务层交互。InnoDB是其中功能最完善的(支持事务、行锁等),直接对接磁盘文件。
- 文件系统层:最终存储数据的物理文件(如
.ibd数据文件、日志文件等)。
关键点:可拔插架构中,有一套规范的I/O操作接口,InnoDB通过标准接口嵌入MySQL,处理所有数据I/O操作
2、Inno DB总体架构
InnoDB 存储引擎目前也是应用最广泛的存储引擎。 从 MySQL 5.5 版本开始作为表的默认存储引擎。
InnoDB 存储引擎 最早由 Innobase Oy 公司开发(属第三方存储引擎)。
InnoDB 存储引擎 是第一个完整支持 ACID 事务的 MySQL 存储引擎,特点是行锁设计、支持 MVCC、支持外键、提供一致性非锁定读,非常适合 OLTP 场景的应用使用。
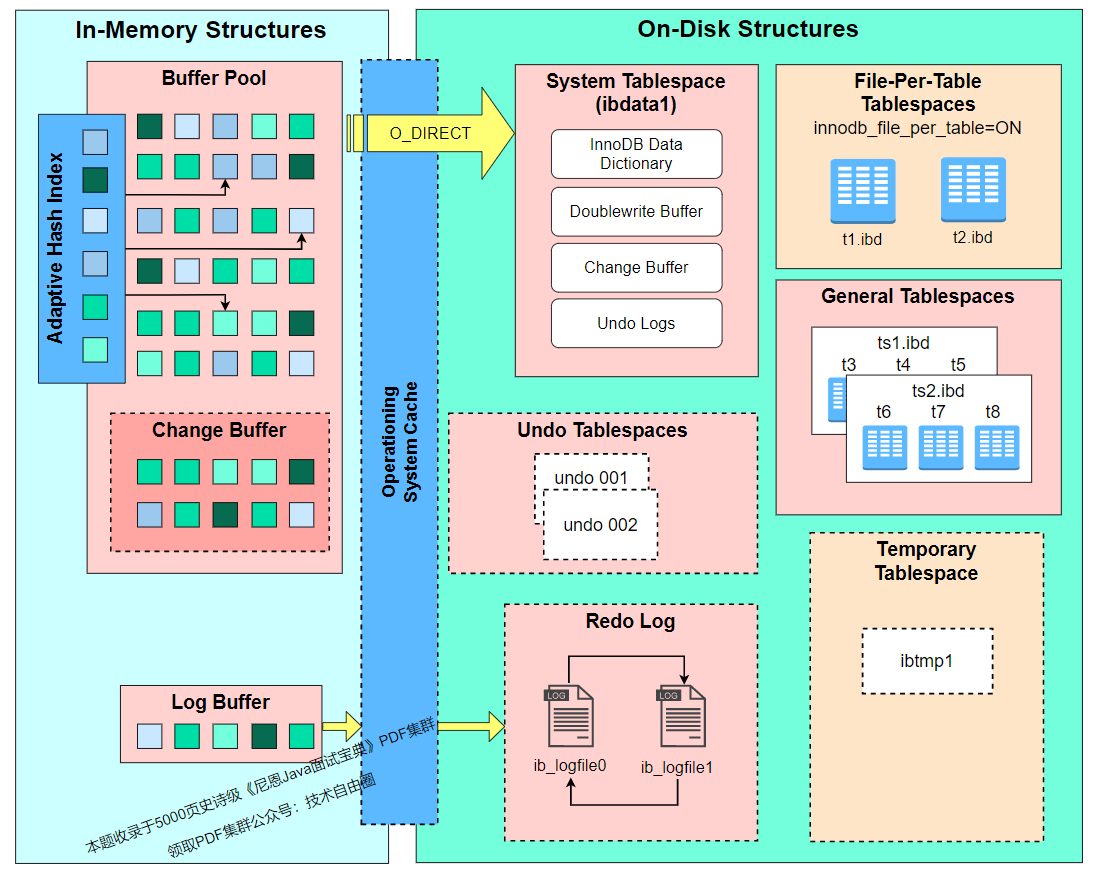
InnoDB 存储引擎架构包含内存结构和磁盘结构两大部分
MySQL 8.0 版本,总体架构图如下:
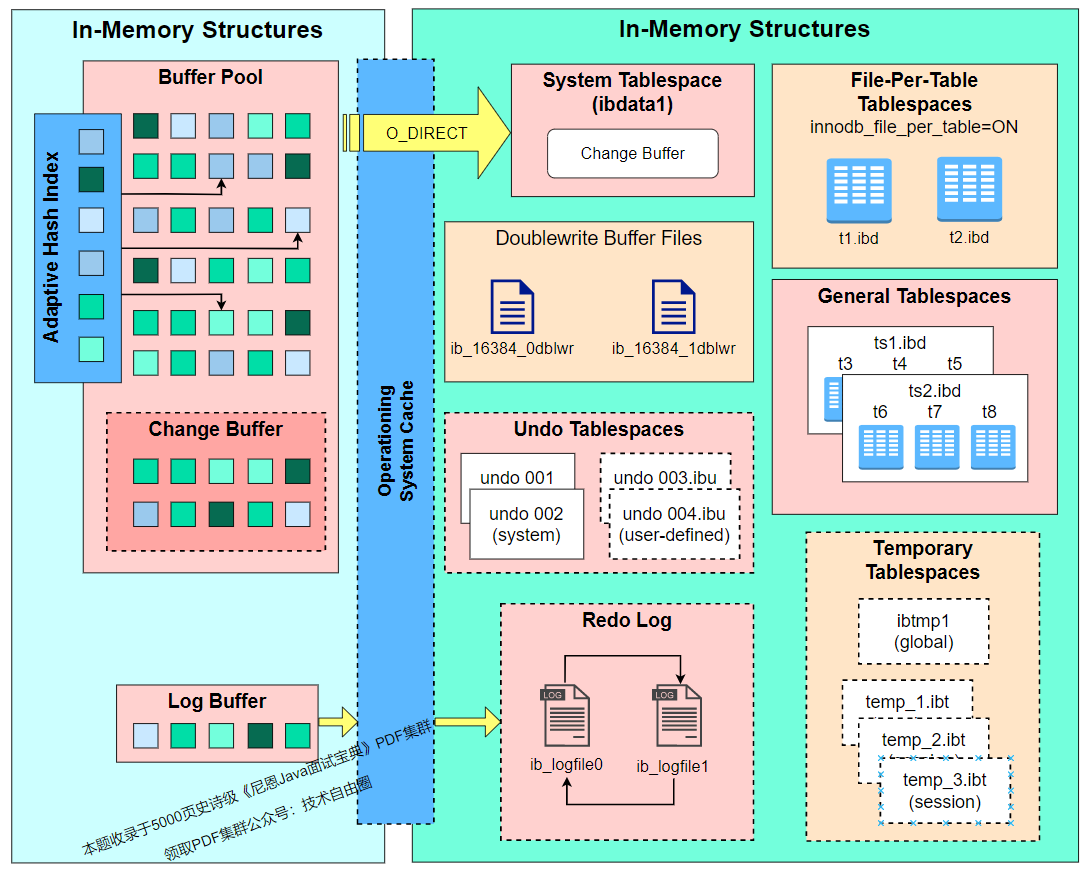
MySQL 5.5 版本,总体架构图如下:
3、Inno DB数据读写流程
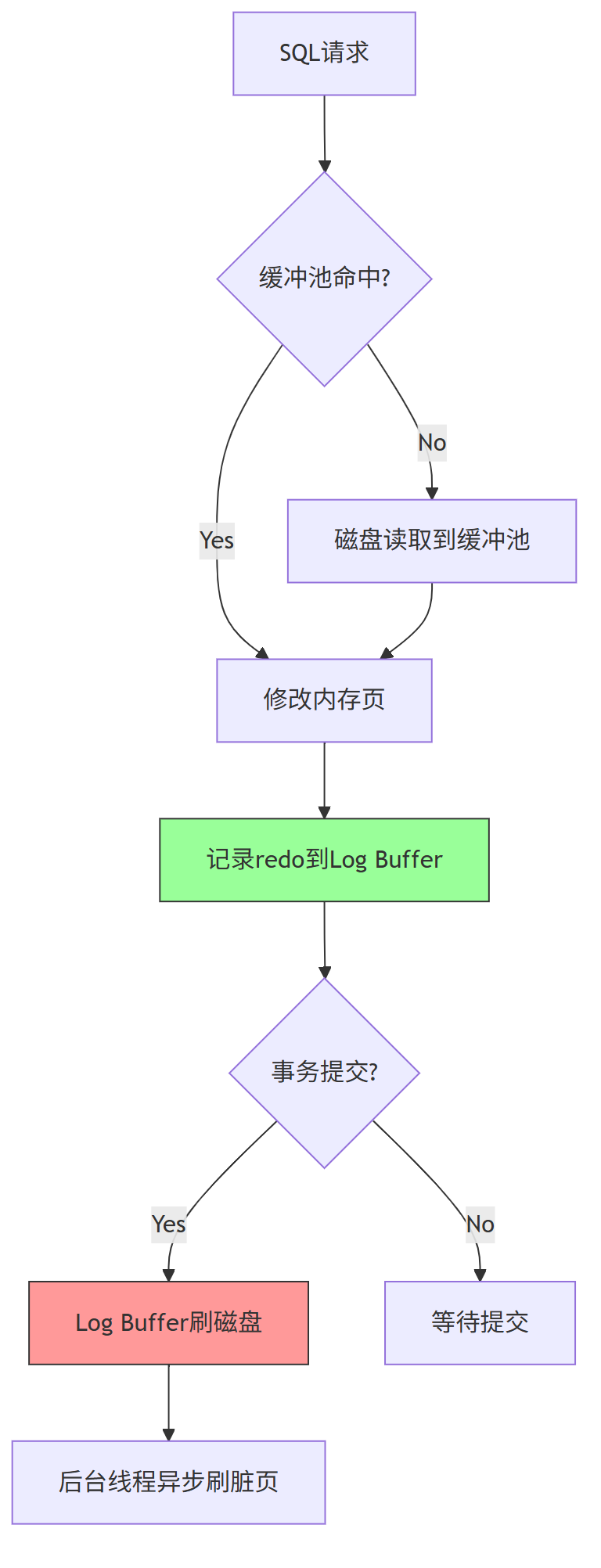
关键步骤:
1)读路径:优先检查缓冲池,未命中时从.ibd(也就是各种表空间)加载
2)写路径:
- 先写redo log(顺序I/O)
- 异步写入数据文件(随机I/O)
SHOW ENGINE INNODB STATUS\G -- 查看刷脏进度
3)崩溃恢复:通过redo log重做未落盘操作
二、InnoDB内存架构
InnoDB的内存就像"高速缓存区",减少磁盘IO,提升速度。
主要组件如下:
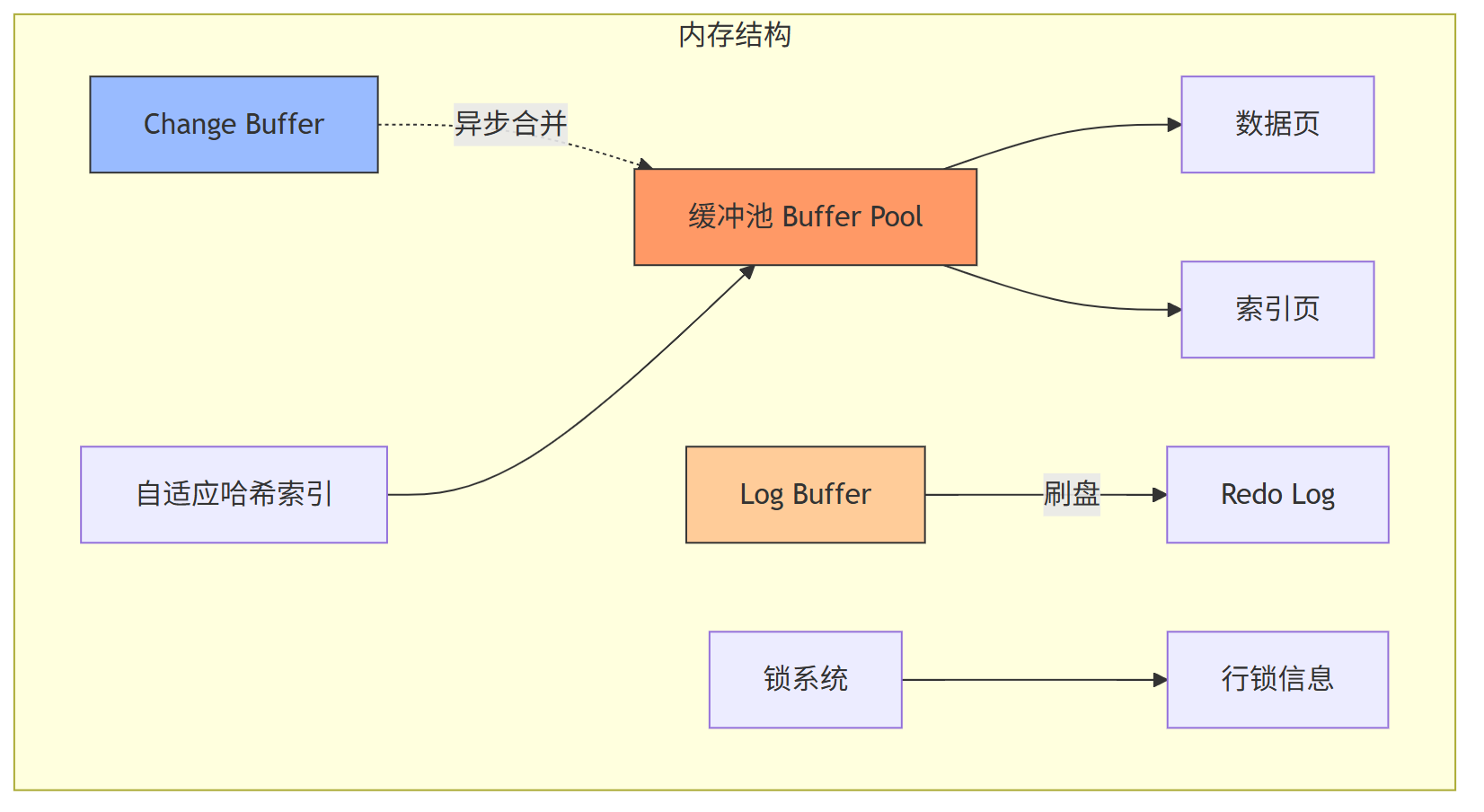
核心组件:
(1) Buffer Pool 数据热区枢纽:
预分配连续内存缓存数据页,通过LRU算法管理热数据,将随机I/O转为内存操作。
(2) Log Buffer 写操作高速通道:
暂存事务中的redo日志,innodb_flush_log_at_trx_commit控制刷盘策略,平衡性能与安全。
(3) Change Buffer 非聚簇索引加速器:
缓存非唯一索引的DML操作(INSERT/UPDATE/DELETE),后台异步合并到磁盘索引结构。
(4) 自适应哈希索引 智能路径优化器:
自动检测高频等值查询路径,在内存中构建哈希索引,突破B+树检索深度限制。
(5) undo 日志缓冲:
InnoDB 内存中临时存放 undo 日志的区域,用于事务回滚和多版本控制,最终会刷新到磁盘的 Undo 表空间。
2.1、Buffer Pool
2.1.1 什么是 Buffer Pool?
简单说,Buffer Pool 是 InnoDB 存储引擎里一块内存区域,专门用来缓存表数据和索引数据。
就像我们平时把常用的文件放在桌面方便拿取,MySQL 也会把频繁访问的数据存到 Buffer Pool 里,避免每次都去读写磁盘(磁盘速度比内存慢太多),以此提高查询效率。
它是 InnoDB 性能的“核心加速器”,大部分时候,我们查数据、改数据,都是和 Buffer Pool 打交道,而不是直接操作磁盘。
Buffer Pool缓存磁盘数据页(16KB/页)。
通过减少磁盘 I/O 提升性能,使用 LRU 算法 + 冷热分离管理数据页。
2.1.2 数据读取流程
SELECT * FROM table WHERE id=1; -- 直接返回内存数据

关键步骤说明:
-
缓存命中(哈希表检索):直接返回内存数据
-
缓存未命中:
(1) 从 free_list获取空闲页
- 若空 → 触发 LRU 淘汰冷区尾部页
- 若为脏页 → 异步刷盘
- 从磁盘加载数据到空闲页
2.1.3 冷热数据迁移机制
冷热数据迁移是 MySQL 的 内存优化策略,通过将 Buffer Pool 中的内存页分为热区(高频访问)和冷区(低频访问),从而实现:
-
保护热点数据:高频访问页不被异常挤出
-
隔离临时访问:全表扫描等操作不污染热区
-
智能淘汰:优先释放低频使用的内存
1)LRU冷热分区结构
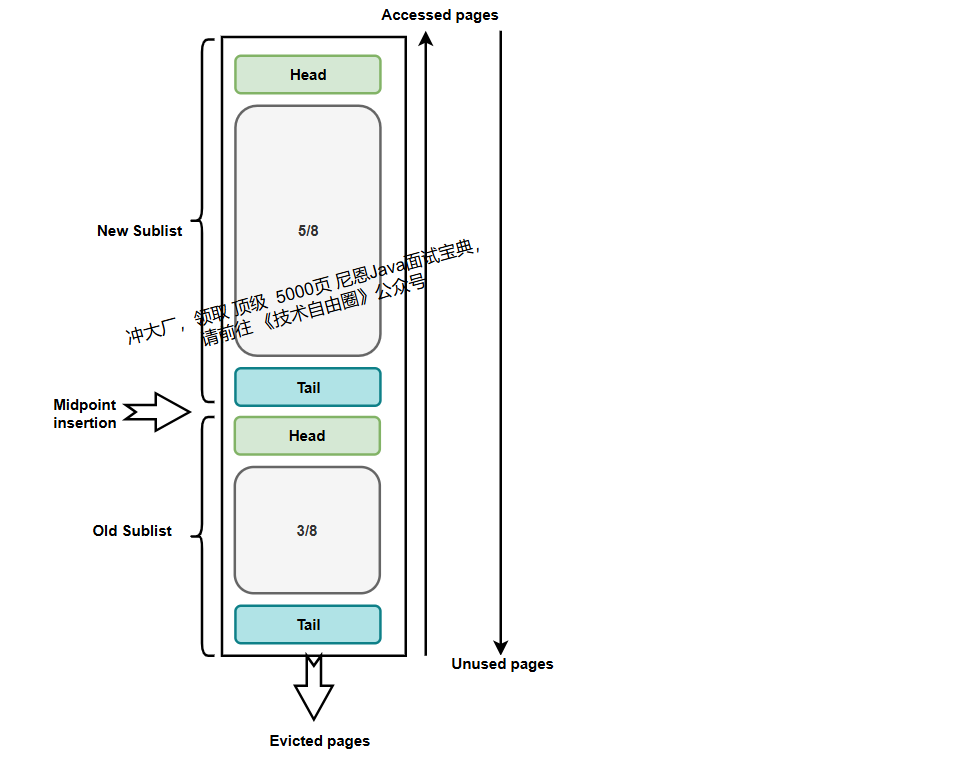
| 位置 | 特征 | 流动规则 |
|---|---|---|
| 热区头部 | 最近高频访问页 | 持续访问则保留 |
| 冷区头部 | 新加载页/降级页 | 二次访问可升热区 |
| 冷区尾部 | 待淘汰页 | 内存不足时立即释放 |
关键控制参数
-- 冷区占比 (默认37%)
SET GLOBAL innodb_old_blocks_pct = 37;
-- 冷区页停留最短时间 (默认1000ms)
SET GLOBAL innodb_old_blocks_time = 1000;
2)基本流程
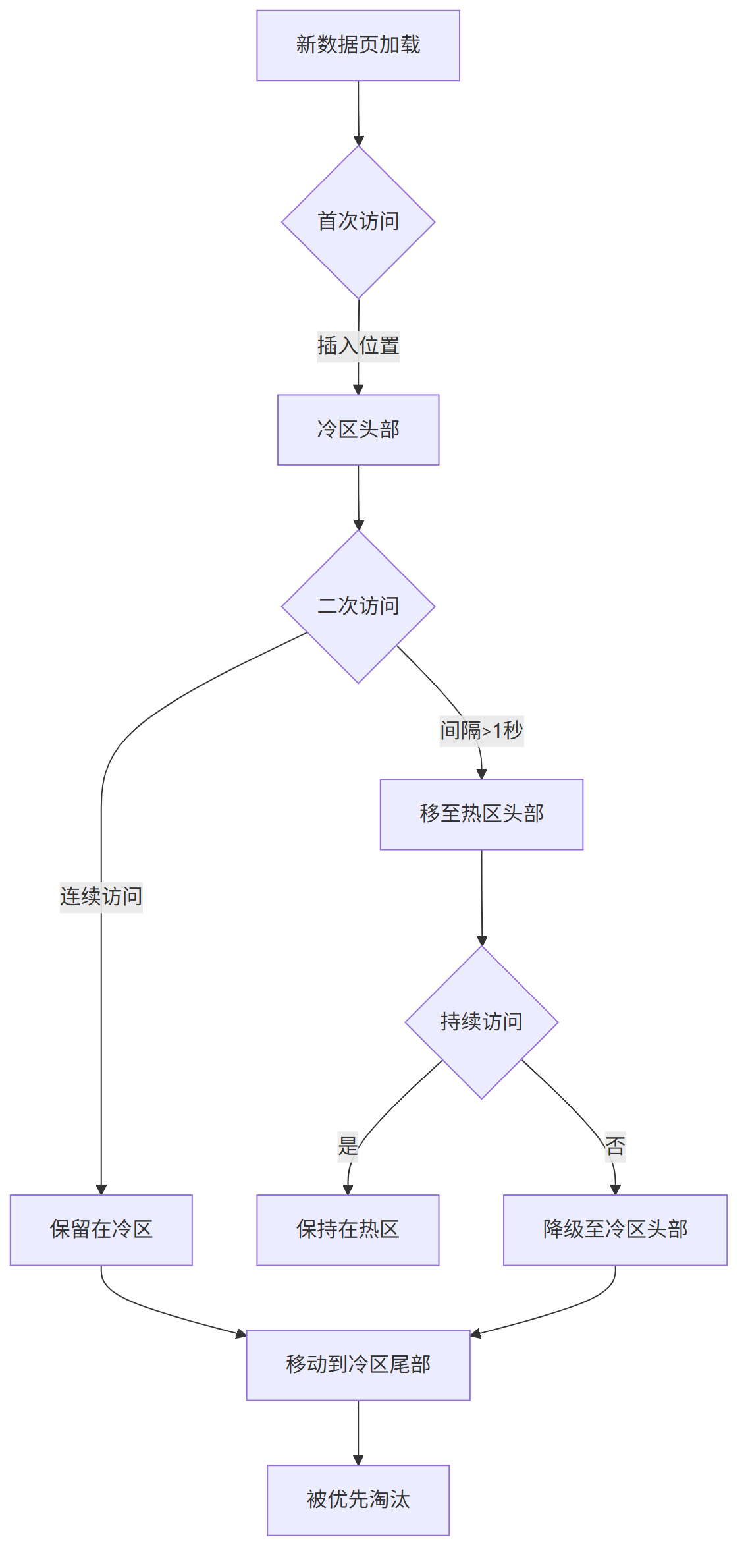
3)冷热区规则:
-
首次加载:插入 冷区头部
-
二次访问:移至 热区头部
-
冷→热迁移条件:
- 第二次访问该数据页
- 距首次加载时间 >
innodb_old_blocks_time - 访问间隔需超过过滤阈值
-
热→冷降级条件:
- 连续未访问时间 > 热区保护期
- 热区空间不足时尾部页降级
- 访问频率跌出热区保持阈值
4)淘汰规则:
if page in lru_cold and not recently_used: # 冷区尾部
evict_page(page)
elif page in lru_hot and not accessed_in_time: # 热区未访问
move_to_cold_head(page) # 降级至冷区
5)案例分析
场景: 10GB全表扫描
SELECT * FROM 10GB_table; -- 数千万页级扫描
保护机制:
(1) 所有新页插入冷区头部
(2) 1秒内连续访问不触发升温
(3) 扫描结束自动从冷区尾部淘汰
(4) 热区100%不受影响
6)与传统LRU对比优势
| 机制 | 传统LRU | MySQL冷热迁移 |
|---|---|---|
| 新页插入位置 | 直接放头部 | 冷区头部 |
| 全表扫描影响 | 立即污染热点区 | 完全隔离在冷区 |
| 淘汰策略 | 纯按访问时间 | 冷区优先+频率加权 |
| 二次机会 | 无 | 热区降级页回冷区头部 |
本质价值:通过物理隔离和延时升温机制,解决了传统LRU算法的“缓存污染”问题,使有限的Buffer Pool空间始终服务于真正的热点数据。
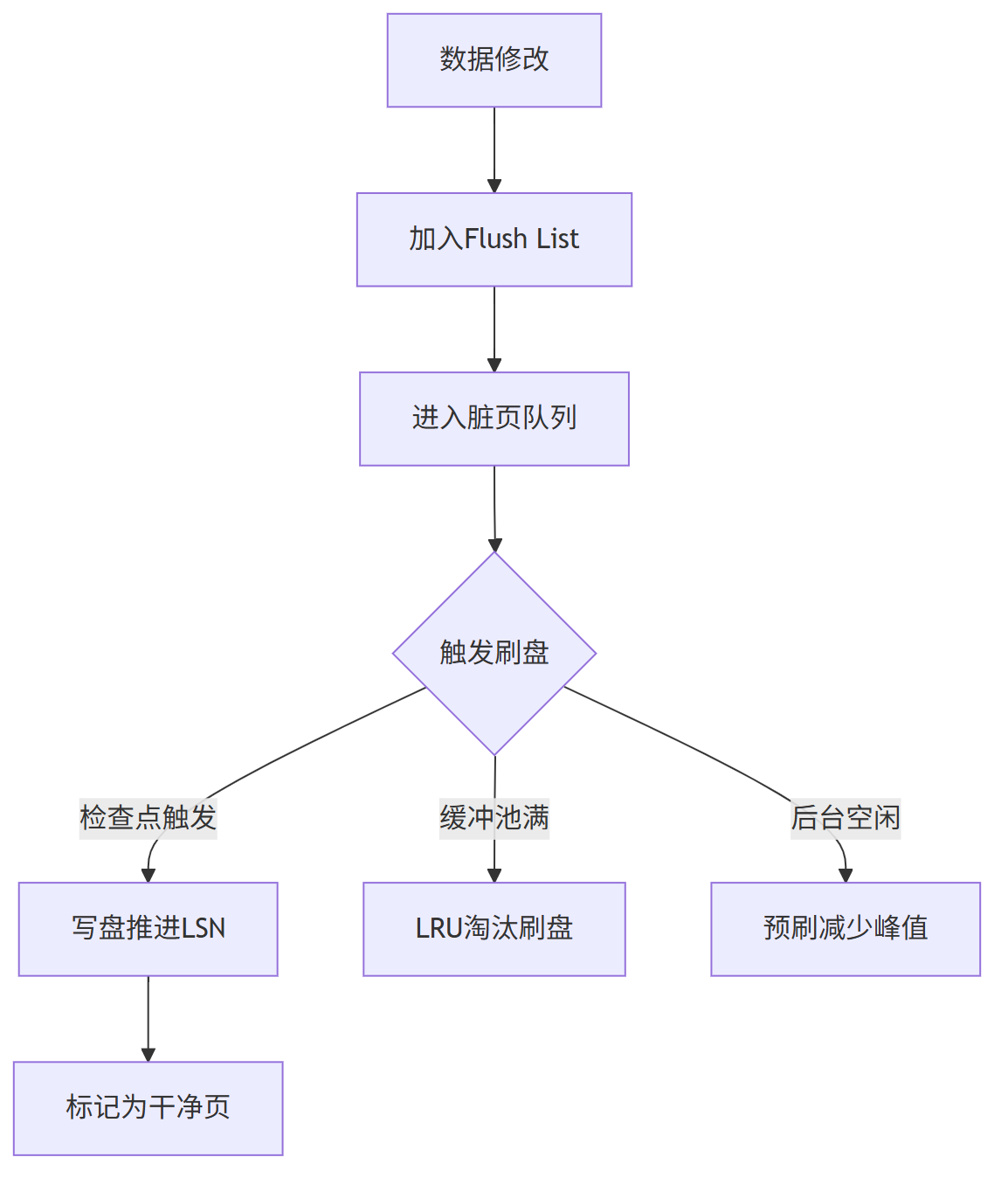
2.1.4 脏页刷盘机制
什么是 “脏页”?
当我们修改数据时,先改 Buffer Pool 里的缓存(内存),这时候缓存和磁盘数据就不一致了,这部分缓存叫“脏页”。
脏页怎么来的?
事务修改数据时,InnoDB 会先从磁盘加载目标数据页到 Buffer Pool(如果不在内存中),修改内存页后,会:
(1) 标记该页为“脏页”(dirty page);
(2) 记录修改操作到 Redo Log(保证崩溃后能恢复);
(3) 不立即写回磁盘(磁盘 IO 太慢,影响性能)。

脏页刷盘用到mysql的checkpoint机制。
Checkpoint机制
什么是checkpoint机制呢?
InnoDB改数据先在内存瞎折腾(Buffer Pool),不立马写到磁盘——怕慢。
但这么搞有俩问题:
-
万一崩了,内存里的改动丢了咋办?
-
Redo Log 总不能无限存吧?
Checkpoint 就是来解决这俩问题的。
说白了,它就是个「标记点」,告诉系统:“在我这时间点之前,所有内存里改了还没写到磁盘的脏页,都已经安全落地了”。
checkpoint标记点以后的修改,崩溃恢复交给redo log处理
Checkpoint的核心作用:
-
缩短恢复时间:崩溃恢复时只需要从最近的checkpoint开始重做日志
-
脏页刷盘:定期清理缓冲池中的脏页
-
日志空间回收:标记哪些redo log可以被覆盖重用
Checkpoint 有哪几种?啥时候会触发(也就是啥时候进行脏页刷盘)?
1)Sharp Checkpoint(彻底型)
就一种情况会触发:数据库正常关闭(shutdown)。
这时候会把所有脏页全刷到磁盘,Checkpoint 直接怼到 Redo Log 的末尾。下次启动不用恢复,因为啥都落盘了。简单粗暴,但耗时——生产库大的话,关一次可能等半天。
2)Fuzzy Checkpoint(模糊型)
数据库正常运行时用的,不刷所有脏页,只挑一部分刷,避免阻塞业务。细分为 4 种:
- Master Thread Checkpoint:
主线程自己偷偷干的,每秒或每 10 秒(默认1S)刷一点脏页(数量很少),不影响性能。比如每秒刷 10 个页,慢悠悠的。
- FLUSH_LRU_LIST Checkpoint:
Buffer Pool 有个 LRU 链表(最近最少用),淘汰旧页时,发现是脏页,就得先刷盘再扔。不然扔了就丢数据了。
- Async/Sync Flush Checkpoint:
这是急活儿!Redo Log 快写满时(write pos 快追上 Checkpoint 了),必须赶紧刷脏页推进 Checkpoint,给新日志腾地方。
要是还剩点空间,异步刷(不卡事务);
要是快满了,同步刷(卡着新事务,直到腾出新空间)。
- Dirty Page too much Checkpoint:
当脏页占 Buffer Pool 的比例超过 innodb_max_dirty_pages_pct(默认 75%),就触发刷盘,把比例压下去。避免脏页太多,万一崩了恢复慢。
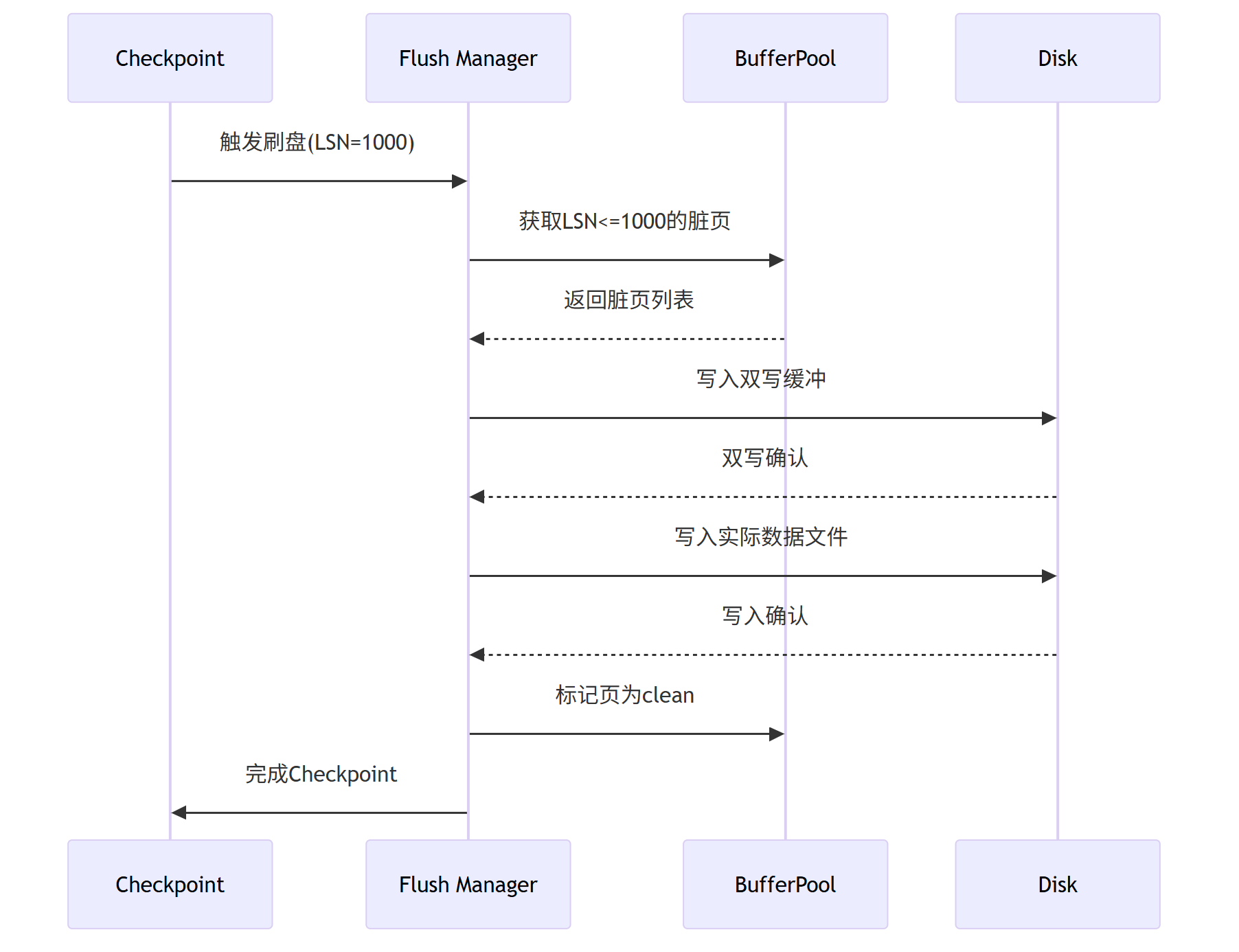
核心流程图
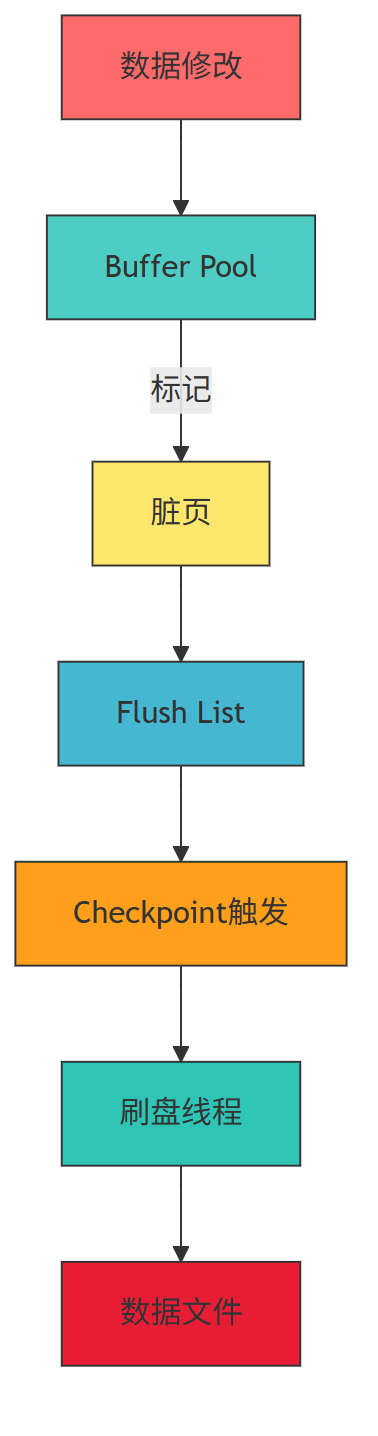
脏页生命周期:
2.1.5 性能调优实战
关键配置参数
| 参数 | 说明 | 推荐值 |
|---|---|---|
innodb_buffer_pool_size |
总内存大小 | 物理内存的50%-80% |
innodb_old_blocks_pct |
冷区内存占比 | 默认37% |
innodb_lru_scan_depth |
每次扫描深度 | 默认1024 |
预热技巧(重启后加载):
SELECT pg.space_id, pg.page_no
FROM information_schema.innodb_buffer_page AS pg;
监控命令:
SHOW ENGINE INNODB STATUS;
-- Buffer Pool命中率 = (1 - disk_reads / logical_reads) * 100%
核心价值:将随机磁盘 I/O 转换为内存访问,加速高频数据操作。理解冷热分离与异步刷盘机制是调优关键。
2.2、Change Buffer
2.2.1 什么是 Change Buffer
简单说,Change Buffer 是 InnoDB 里一块专门缓存非唯一二级索引修改的内存区域。
作用:当你改数据时,如果要改的索引页不在内存里(Buffer Pool),不用立刻去磁盘找这个页,先把修改记在 Change Buffer 里,等以后有机会再一起处理。
打个比方: 这就像 网购时,快递员不会每到一个包裹就立刻送上门,而是攒一批顺路送——减少跑腿次数,效率自然高。
为什么 Change Buffer 能提升性能?
核心是减少磁盘 IO:
- 对非唯一二级索引的高频修改(比如批量插入),不用每次都读磁盘页,先在内存里“记账”;
- 合并时一次性处理多个修改,把零散的磁盘操作变成集中操作。
反过来想:如果没有 Change Buffer,每插一条数据就要读一次磁盘索引页(如果不在内存),1000条就是1000次磁盘IO,慢得让人着急。
Change Buffer本质定位:Change Buffer(写缓冲)是 InnoDB 加速 非唯一二级索引变更 的杀手锏。
Change Buffer核心价值:将索引更新由随机写转为顺序写,解决二级索引写入瓶颈。
不是所有索引修改都能用Change Buffer,有两个前提:
(1) 必须是二级索引(非主键索引);
(2) 这个索引不是唯一的(因为唯一索引要检查唯一性,必须访问磁盘页确认,绕不开)。
像普通的 INSERT、UPDATE、DELETE 操作,只要符合上面两个条件,就可能用到 Change Buffer。
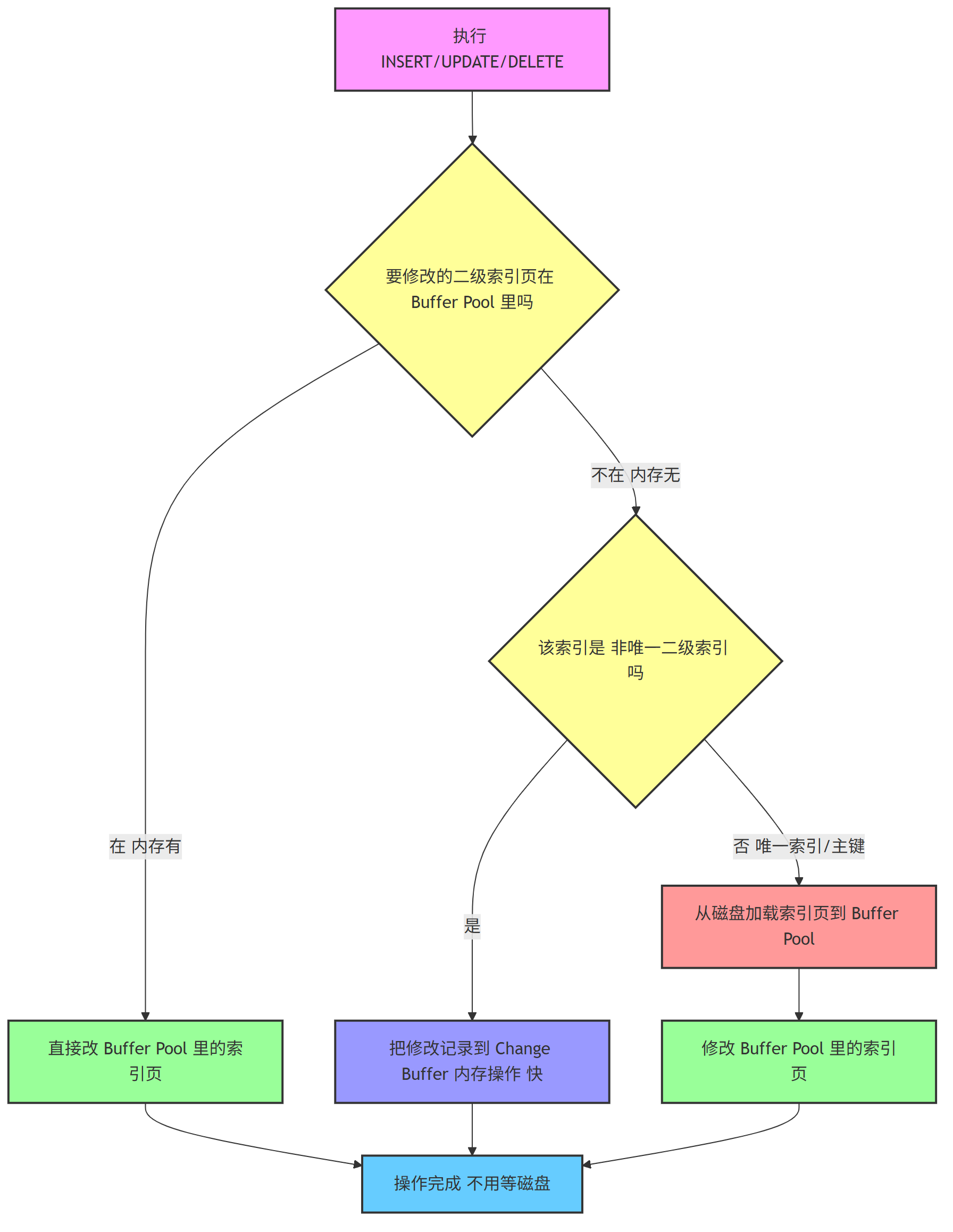
Change Buffer 运作全流程:
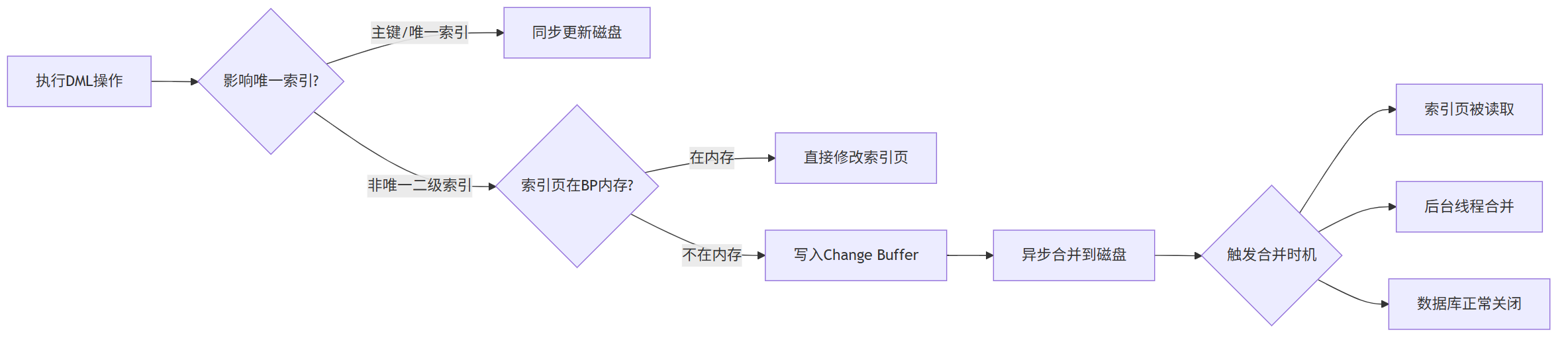
2.2.2 合并触发场景
存在 Change Buffer 里的修改,终究要写到磁盘的索引页上,这个过程叫“合并”(merge)
-- 手动强制合并命令
ALTER TABLE tbl_name FORCE CHANGE BUFFER MERGE;
2.2.3 性能调优实战
关键控制参数
-- 最大内存占比 (默认25%)
SET GLOBAL innodb_change_buffer_max_size=30;
-- 合并操作类型配置
SET GLOBAL innodb_change_buffering='all'; -- 支持insert/delete/purge
状态监控命令
SHOW ENGINE INNODB STATUS\G
---BUFFER POOL AND MEMORY
Ibuf: size 7549, free list len 3980, seg size 11530,
merged operations:
insert 5934234, delete mark 387703, delete 7392
与传统方案对比
| 特性 | 无Change Buffer | Change Buffer启用 |
|---|---|---|
| 二级索引更新 | 每次触发磁盘随机写 | 批量顺序写 |
| 索引页不在内存时 | 先读磁盘 → 更新 → 写回 | 内存记录 → 延迟合并 |
| 写性能 | 100TPS | 10000+ TPS |
| 适用场景 | 唯一索引更新 | 非唯一索引批量写入 |
设计哲学:
用内存换磁盘随机I/O,牺牲数据落地实时性换取吞吐量跃升。
在账单记录、时序数据场景可带来10倍+写入性能提升,但对交易核心表需谨慎评估数据一致性要求。
2.2.4 Change Buffer 总结
Change Buffer 就是 InnoDB 为非唯一二级索引修改设计的“内存暂存区”:
(1) 先把修改记在内存,避免频繁访问磁盘;
(2) 等合适的时机(比如查询该索引时)再批量合并到磁盘;
(3) 核心价值:把零散的磁盘操作变成集中操作,大幅提升写性能。
理解它,就能更好地优化那些带非唯一二级索引的表的写入性能了。
2.3、Log Buffer
2.3.1 什么是Log Buffer
Log Buffer(日志缓冲区)是 InnoDB 的 事务日志高速通道,在内存中缓冲 redo log 数据,通过批量合并写盘机制将随机I/O转化为顺序I/O,实现事务提交的瞬时响应。
简单说,Log Buffer 就是 InnoDB 存 redo log 的一块内存缓冲区。redo log 是保证数据安全的关键(比如断电时恢复数据),但直接写磁盘太慢,所以先放内存里攒一攒,凑够一批再写磁盘,这就是 Log Buffer 的作用。
打个比方:就像你写日记,不会写一个字就立刻存档,而是写满一页再存——减少存档次数,效率更高。
基本流程图:
当你执行增删改操作时,redo log 的产生和存储流程是这样的:
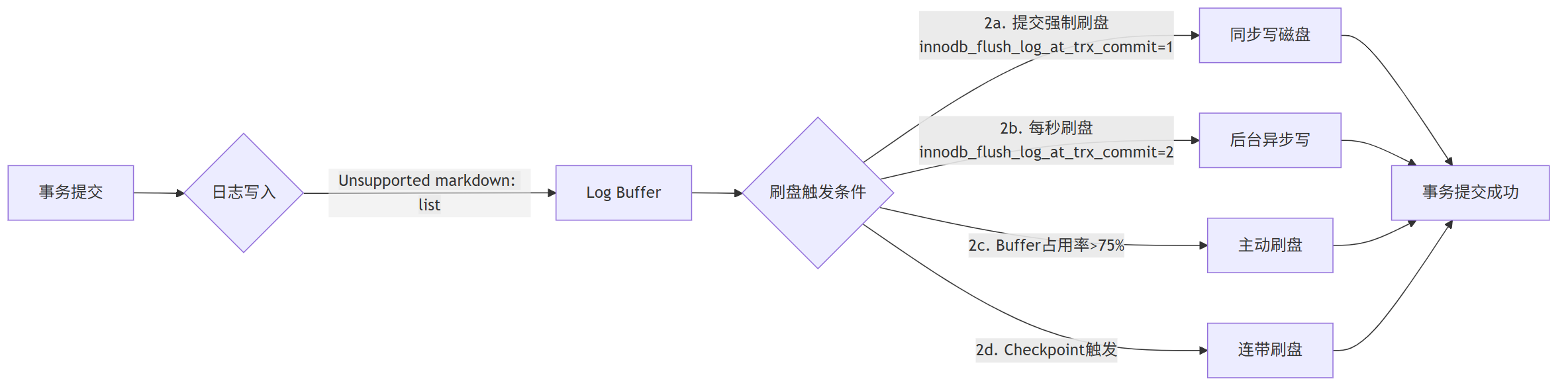
比如你连续执行10条 UPDATE,InnoDB 不会每条都写磁盘,而是先把这10条的 redo log 都放 Log Buffer 里,等满足条件了再一次性刷到磁盘,大大减少磁盘 IO 次数。
什么时候会把 Log Buffer 刷到磁盘?
| 触发条件 | 刷盘模式 | 数据安全性 | 性能影响 |
|---|---|---|---|
innodb_flush_log_at_trx_commit=1 |
事务提交同步刷 | 最高(ACID) | 高延迟 |
innodb_flush_log_at_trx_commit=2 |
每秒后台异步刷 | 中等(OS崩溃丢数据) | 低延迟 |
| Buffer使用率 > 75% | 强制刷盘 | 防溢出 | 可控 |
| Checkpoint推进 | 连带刷盘 | 保证恢复点 | 周期影响 |
Checkpoint的执行是InnoDB存储引擎的核心机制,其触发基于四大条件:
- 时间周期:秒级/分钟级定时触发
- 空间阈值:日志空间 >75% 或脏页比例 >阈值
- 事件驱动:关闭、备份等特殊操作
- 负载压力:高并发写入时的自适应触发
Checkpoint执行时完成的关键工作:
- 确定最小安全LSN位置
- 批量刷新Redo日志到磁盘
- 按顺序写入脏数据页
- 原子更新检查点元数据
- 回收日志和数据页资源
2.3.2 性能调优实战
关键控制参数
-- 缓冲区大小 (默认16MB,建议1-4GB)
SET GLOBAL innodb_log_buffer_size = 268435456; -- 256MB
-- 刷盘策略 (1=全持久化, 2=高性能模式)
SET GLOBAL innodb_flush_log_at_trx_commit = 2;
-- 刷盘间隔 (默认1秒)
SET GLOBAL innodb_flush_log_at_timeout = 2;
状态监控命令:
SHOW ENGINE INNODB STATUS\G
LOG
Log sequence number 182701152 // 当前LSN
Log flushed up to 182701152 // 刷盘LSN
Pages flushed up to 182701152 // 页刷盘LSN
Last checkpoint at 182701092 // 检查点LSN
系统崩溃恢复逻辑:
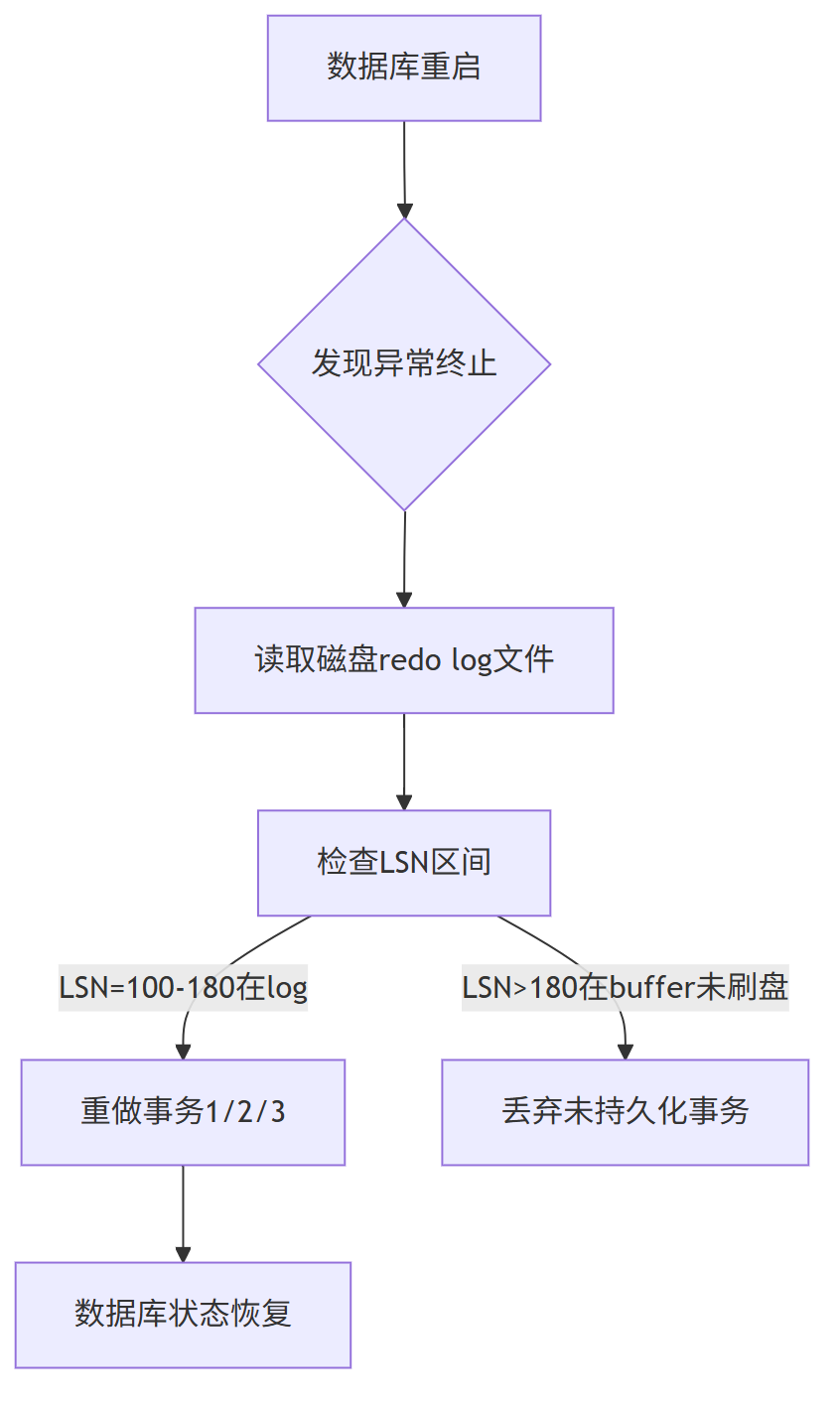
2.3.3 Log Buffer 总结
核心是减少磁盘 IO 次数:
- 内存写速度比磁盘快1000倍以上,先放内存能让事务执行更快;
- 批量刷盘把多次小 IO 变成一次大 IO,效率更高。
但记住:Log Buffer 只是“暂存”,最终还是要刷到磁盘才能保证数据安全,这就是为什么有各种刷盘策略的平衡。
(1) 先存内存,减少磁盘 IO,让事务跑得更快;
(2) 靠定时、满了、事务提交这三个时机刷到磁盘,兼顾性能和安全;
(3) 大小和刷盘策略可以调,根据业务的“速度需求”和“安全需求”平衡。
理解它,就能更好地配置 MySQL,在数据安全和写入性能之间找到合适的平衡点。
2.4、Adaptive Hash Index(自适应哈希索引)
2.4.1 什么是自适应哈希索引(AHI)?
自适应哈希索引(AHI)是 InnoDB 的动态索引加速器,自动将高频访问的 B+树 路径转换为哈希索引。
自适应哈希索引(AHI) 核心目标:将索引检索复杂度从 O(log n) 降至 O(1),针对热点数据查询实现毫秒级响应。
简单说,AHI 是 InnoDB 自己偷偷搞的“加速工具”——它会盯着那些被频繁查询的索引,悄悄在内存里建哈希索引,帮你把某些查询速度提得更快。
哈希索引的特点是“等值查询贼快”(比如 WHERE id = 123),但维护起来麻烦,还不适合范围查询(比如 WHERE id > 100)。
InnoDB 就想出个招:不麻烦人手动建,自己观察哪些查询频繁,符合哈希索引的脾气,就自动建,这就是“自适应”的意思。
1)运作流程:
不是随便什么查询都会触发 AHI,得满足几个条件:
- 必须是等值查询(比如
=、IN、<=>); - 同一索引页(B+树里的一个叶子节点)被频繁访问,且查询模式固定(比如总是查
WHERE col = ?); - 访问次数达到阈值(InnoDB 内部判断,不用我们管)。
举个例子:一张表有索引 idx_name,如果经常执行 SELECT * FROM t WHERE name = '张三' 这类查询,InnoDB 发现这个索引页被反复查,就会给这个页建个 AHI。
比如你第一次查 name = '张三',没 AHI,走 B+树查;查多了,InnoDB 建了 AHI,下次再查,直接通过哈希值定位到数据,不用再遍历 B+树的层级,速度能快好几倍。
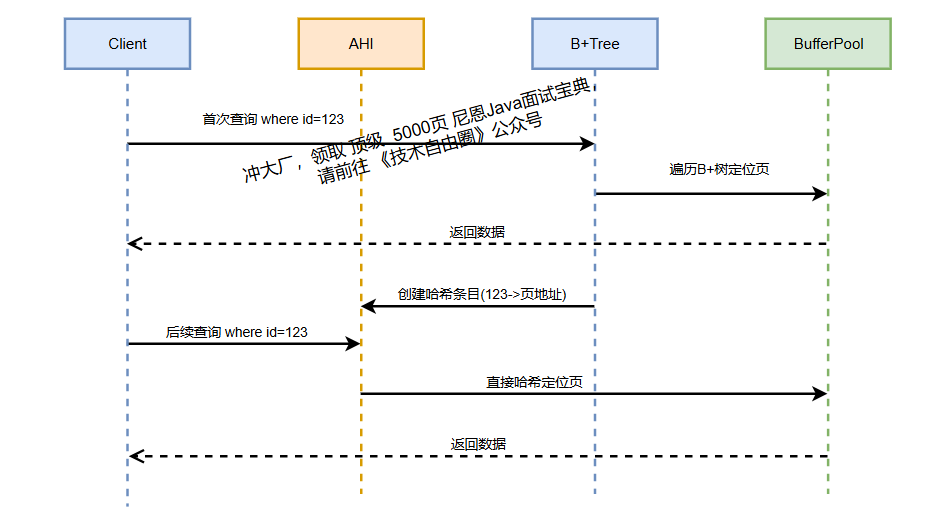
2)AHI 会自动“清理”吗?
会的。InnoDB 不只是建,还会盯着 AHI 的使用情况:
- 如果某个 AHI 建完后很少被用到,会自动删掉,腾内存;
- 当索引结构变化(比如删数据、改索引),对应的 AHI 也会跟着更新或删除,不用手动维护。
这也是“自适应”的体现——只留有用的,没用的自动清。
3)AHI 适合什么场景?
最适合“大量等值查询”的场景,比如:
- 电商商品详情页(频繁查
WHERE goods_id = ?); - 用户中心(频繁查
WHERE user_id = ?)。
这些场景下,AHI 能把查询从“遍历 B+树”变成“哈希直接定位”,性能提升明显。
但如果是范围查询多(比如 WHERE price > 100),AHI 几乎没用,因为哈希索引不支持范围查找,这时甚至可能浪费内存。
4)AHI 总结:
AHI 就是 InnoDB 自带的“智能加速插件”:
(1) 自动观察频繁的等值查询,悄悄建哈希索引;
(2) 加速查询时直接定位数据,跳过 B+树遍历;
(3) 没用的 AHI 自动删,不麻烦人维护;
(4) 适合等值查询多的场景,范围查询多可以关掉。
理解它,就能更好地判断要不要留着这个“加速工具”,让数据库跑更快。
2.4.2 性能调优实战
适用场景:
| 场景类型 | 加速效果 | 典型案例 |
|---|---|---|
| 主键点查询 | 8-10倍 | 用户ID查询 |
| 短连接查询 | 5-7倍 | 微服务API请求 |
| 排序索引访问 | 3-5倍 | 分页顺序查询 |
| 大范围扫描 | 无提升 | 全表扫描 |
控制参数:
-- 全局开关 (默认ON)
SET GLOBAL innodb_adaptive_hash_index = OFF;
-- 分区数设置 (默认8,解决锁竞争)
SET GLOBAL innodb_adaptive_hash_index_parts = 16;
-- 实时状态监控
SHOW GLOBAL STATUS LIKE 'Innodb_ahi%';
输出关键指标:
+-----------------------------------+-------+
| Variable_name | Value |
+-----------------------------------+-------+
| Innodb_ahi_searches | 38245 | # AHI查询次数
| Innodb_ahi_inserts | 1298 | # AHI新增条目
| Innodb_ahi_contention | 83 | # 哈希冲突次数
+-----------------------------------+-------+
与B+树索引对比:
| 维度 | B+Tree | AHI |
|---|---|---|
| 索引类型 | 持久化结构 | 内存临时结构 |
| 构建方式 | 显示创建 | 自动按需生成 |
| 检索复杂度 | O(log n) | O(1) |
| 适用操作 | 范围/精确/排序 | 仅精确查询 |
| 内存占用 | 固定 | 动态增长(最大BPOOL 1/32) |
| 更新代价 | 中 | 高(需重建) |
| 最佳场景 | 通用业务 | 超高频点查询 |
核心价值:对热点主键查询实现零层检索(直接内存定位),在交易系统核心表(如订单号查询)可提升10倍吞吐量。但高并发写入场景可能因重建开销导致20%性能下降,需通过
innodb_adaptive_hash_index_parts缓解锁冲突。
三、InnoDB 磁盘架构

核心组件:
(1) Redo Log(重做日志)
崩溃恢复的保险丝:顺序记录所有物理数据变更,实例崩溃时通过重放保证ACID持久性,物理文件为ib_logfile0/1的循环写入。
(2) Undo Log(回滚日志)
事务回滚的时光机:存储数据修改前的原始镜像,支撑事务回滚和MVCC多版本读,MySQL 8.0后独立存储在undo_001等专用表空间。
(3) 系统表空间(System Tablespace)
引擎核心仓库:默认存储数据字典、双写缓冲、Change Buffer等元数据,主文件ibdata1持续增长且不可收缩。
(4) 独立表空间(File-Per-Table Tablespace)
表专属数据容器:每个InnoDB表独立的.ibd文件存储表数据+索引,通过innodb_file_per_table=ON启用,支持空间回收。
(5) 通用表空间(General Tablespace)
多表共享存储池:用户创建的跨表存储空间(CREATE TABLESPACE),可将多个表集中存储于自定义.ibd文件中。
(6) 撤销表空间(Undo Tablespaces)
回滚日志专用住宅:MySQL 8.0+默认将undo log从系统表空间剥离,存储在独立的undo_001/002文件,避免ibdata1膨胀。
(7) 临时表空间(Temporary Tablespaces)
瞬时数据沙盒:存储临时表及排序操作的磁盘中间数据,主文件ibtmp1随服务启动动态创建,重启自动清理。
3.1、Redo Log
由于平台 篇幅限制, 此处省略 5000字+
原始的内容,请参考 本文 的 原文 地址

 浙公网安备 33010602011771号
浙公网安备 33010602011771号