a、b都有索引,WHERE a=1 ORDER BY b 出现 filesort ,为什么?(秒懂+图解)
本文 的 原文 地址
原始的内容,请参考 本文 的 原文 地址
一个 暗藏玄机 的 高难度 面试题
在45岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的面试题。
去年, 一个 28岁小伙 凭着 尼恩给他 定制的 那个 牛逼轰轰的 绝世简历, 拿到了 一个 35K*14薪的高薪机会,逆天改命。
今年,开始 冲击更高的机会, 在面试大厂过程中, 碰到 一个 暗藏玄机 的 高难度 面试题
面试官问: where a=1 order by b 语句中, a、b 都有单列索引, 为什么会有filesort,
小伙伴没有准备好,面试挂了。
所以,这里尼恩给 把 手写AQS 大家做一下系统化、体系化的梳理,使得大家可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”。
出现 filesort的 原因:
虽然where条件使用了a索引,但排序的b列是另一个索引,而这两个索引是独立的,
在获取满足a=1的行之后,这些行在磁盘上的存储顺序与b的顺序无关,所以需要额外的排序操作(filesort)来满足order by b。
当执行where a=1 order by b时,虽然 a 和 b 分别有单列索引,但可能出现 filesort 的原因如下:
-
MySQL 在处理该查询时,会先利用 a 列的索引快速筛选出
a=1的记录。 -
但单列索引 a 只能优化查询的筛选过程,无法提供这些记录在 b 列上的有序性。
-
数据库需要对筛选出的结果按照 b 列排序。MySQL 就会触发 filesort 操作,在内存或磁盘上对结果集进行排序。
为什么优化器不能使用索引b来避免排序?
这是因为a、b 两个单列索引是相互独立的,a 列索引的叶子节点存储的是行指针,无法直接关联到 b 列的索引顺序,所以即使 b 有索引,数据库也无法高效地利用它来避免排序操作。
所以,同时使用两个索引(一个用于where,一个用于order by)是不行的,除非有索引覆盖了(a,b)两列(即联合索引)。
单列索引 场景 ,数据库只能选择一个索引(通常选择where条件中的索引a,因为它可以过滤行),然后再对结果进行排序。
解决方案:创建联合索引(a, b),保障 索引覆盖+前置匹配
这样,查询时可以通过索引a定位到a=1的记录,并且由于b是索引中的下一列,这些记录在索引中已经是按b排序的,因此可以直接按顺序返回数据,避免了filesort。
但是,尼恩提示:
-
这里要告诉面试官, 题目中没有出现select列, 如果select的列不在联合索引中,则 还有可能需要回表。
-
如果希望避免回表,可以使用覆盖索引(即索引包含查询所需的所有select 列)。
接下来,尼恩带着大家 来 深挖 底层知识 和原理。
方案1:默认使用 索引A 忽略索引B
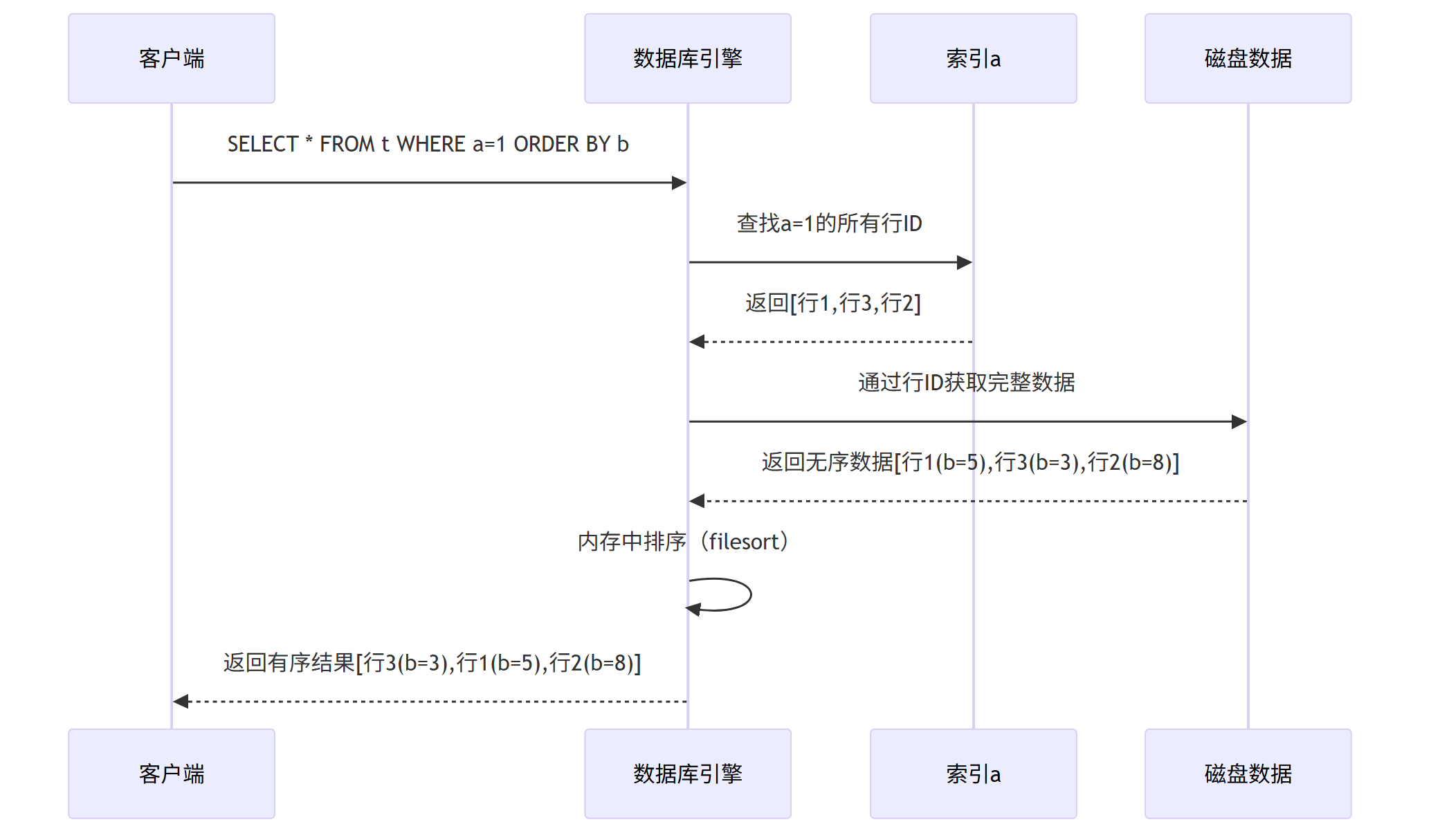
默认情况下,当 a和 b都是单列索引时, 如果 WHERE条件筛选率高时(如 a=1命中少于 20%的行),优化器会选择 "过滤 → 排序" 的查询路径, 并且使用 a 的索引进行过滤。
具体步骤:
第一步过滤:
使用a索引,找到所有a=1的记录的行ID(假设是InnoDB,则通过二级索引a找到主键)
第2步回表:
通过主键回表,查找完整行数据。
第3步filesort:
此时,这些行在物理存储顺序上(按主键排列)与b列的顺序可能不一致,所以为了按b排序,需要将这些行收集起来进行排序(filesort)。
执行过程详解
这是因为两个单列索引是相互独立的,a 列索引的叶子节点存储的是行指针,无法直接关联到 b 列的索引顺序,所以即使 b 有索引,数据库也无法高效地利用它来避免排序操作。
这里不用 索引b了。
为啥不用索引b呢?
1. 过滤与排序的分离
WHERE a=1→ 过滤任务 → 使用索引a高效完成ORDER BY b→ 排序任务 → 索引b无法利用
2. 单列索引的局限性
| 索引类型 | 过滤条件 | 排序支持 |
|---|---|---|
索引 a |
✅ 高效筛选 a=1 |
❌ 无法提供 b顺序 |
索引 b |
❌ 无法处理 a=1 |
✅ 自带排序效果 |
方案二:强制使用 索引 b
假设:我们 强制使用 索引 b
EXPLAIN SELECT * FROM t FORCE INDEX(idx_b) WHERE a=1 ORDER BY b;
- 索引
b本身有序 → ✅ 满足排序 - 但索引
b无法快速定位a=1→ ❌ 需全表扫描 - 最终:排序省去了,过滤更慢了
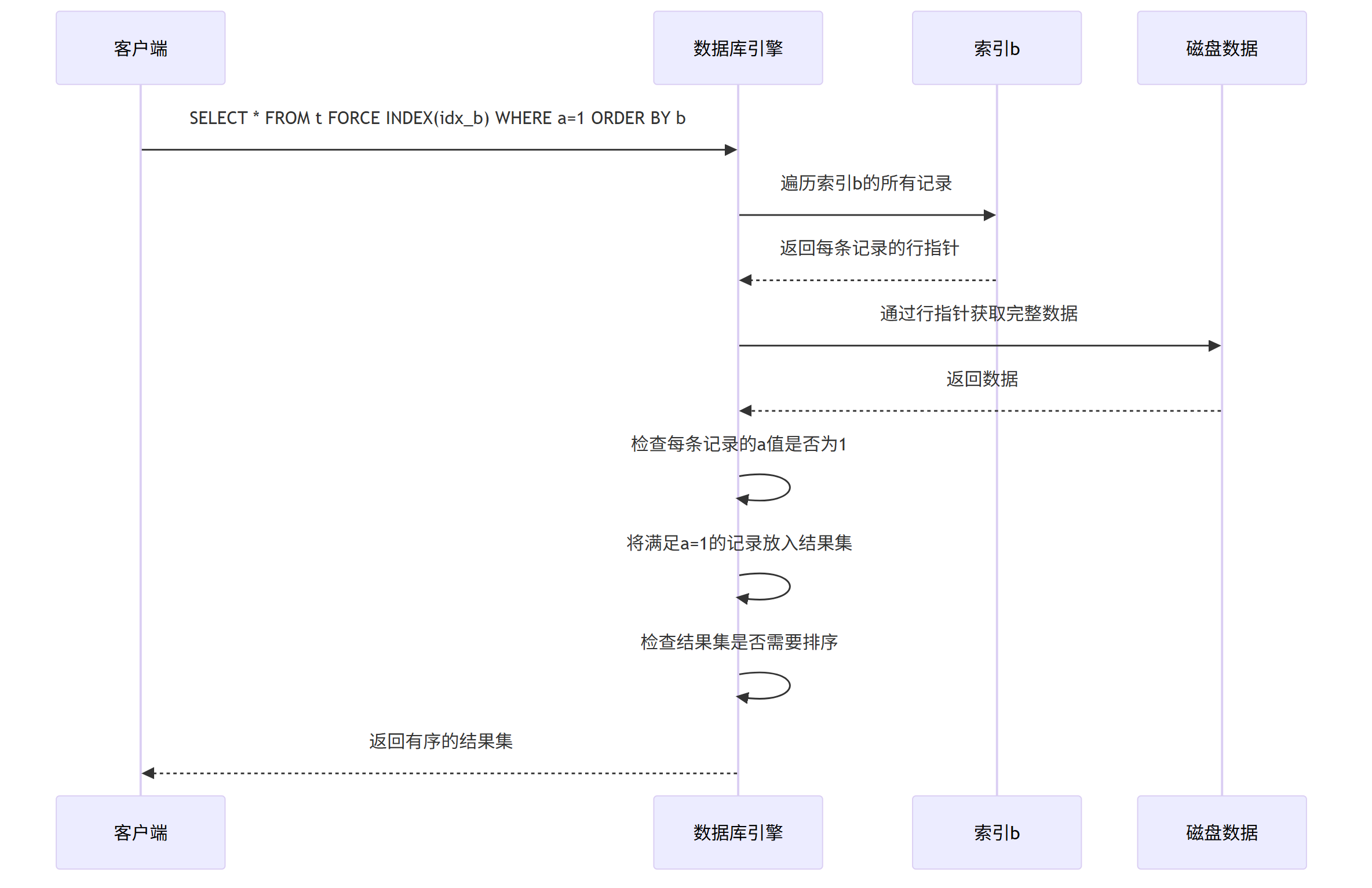
假设a和b都是单列索引,MySQL的执行顺序如下:
1. 强制使用索引b:
由于使用了FORCE INDEX(idx_b),MySQL会优先使用索引b。
2. 执行顺序:
先执行全表扫描:由于索引b无法直接用于过滤条件a=1,MySQL需要遍历索引b的所有记录,通过行指针获取完整的行数据,然后逐行检查a值是否为1。
再执行排序:虽然索引b本身是有序的,但全表扫描后,只有满足a=1的记录才会被放入结果集。如果结果集较大,MySQL可能需要对这些记录进行排序(filesort)。
当强制使用索引 b(idx_b)时,查询流程如下:
EXPLAIN SELECT * FROM t FORCE INDEX(idx_b) WHERE a=1 ORDER BY b;
1.索引 b的结构
索引 b仅存储列 b的值 + 主键(聚簇索引的指针)。索引 b 没有列 a的数据,因此无法直接通过索引 b判断 a=1的条件。
2.执行流程
-
步骤 1:扫描整个索引 b
引擎按索引
b的顺序遍历所有叶子节点(因为索引天然有序)。 -
步骤 2:逐行回表查询
对于索引
b中的每条记录,通过主键回表到聚簇索引中查找整行数据(包括列a)。 -
步骤 3:过滤数据
检查回表后的行是否满足
a=1。如果满足,保留;否则丢弃。 -
步骤 4:返回结果
满足条件的行已按索引
b的顺序排列(省去了ORDER BY b的排序)。
3.本质是全表扫描
- 由于索引
b未包含a,必须扫描 所有索引 b记录 + 回表所有行,实际效果等价于全表扫描。 - 即使通过索引
b避免了排序,回表操作(随机 I/O)的成本远高于索引扫描,整体性能更差。
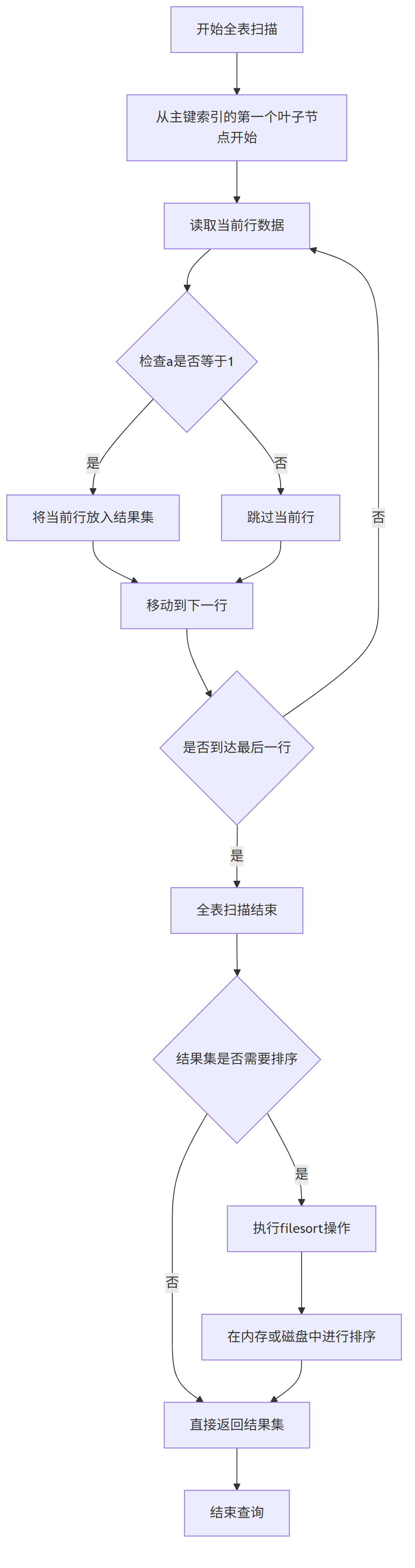
什么是 全表扫描?
全表扫描是指对主键索引(聚簇索引)进行顺序扫描(因为主键索引包含了整行数据)。
流程如下:
(1) 从主键索引的第一个叶子节点开始(按顺序读取)。
(2) 读取每一行数据。
(3) 检查该行数据是否满足条件a=1。如果满足,则将其放入结果集中。
(4) 继续扫描直到最后一行。
全表扫描后,如果结果集太大 ,如果不使用索引,那么就需要对结果集进行排序(filesort)。
也就是说,全表扫描后,如果结果集太大 ,我们需要在内存(或者磁盘)中进行一次排序操作(filesort)。
方案一和方案二 的 代价比较
方案一: 默认 使用 索引 a
EXPLAIN SELECT * FROM t WHERE a=1 ORDER BY b;
WHERE a=1→ 过滤任务 → 使用索引a高效完成ORDER BY b→ 排序任务 → 索引b无法利用 , 直接 filesort
方案二:假设 我们 强制使用 索引 b
EXPLAIN SELECT * FROM t FORCE INDEX(idx_b) WHERE a=1 ORDER BY b;
- 索引
b本身有序 → ✅ 满足排序 - 但索引
b无法快速定位a=1→ ❌ 需全表扫描 - 最终:排序省去了,过滤更慢了
| 方案 | 过滤代价 | 排序代价 | 总代价 |
|---|---|---|---|
使用索引 a |
低(索引扫描) | 高(内存排序) | 中 |
使用索引 b |
高(全表扫描) | 低(免排序) | 高 |
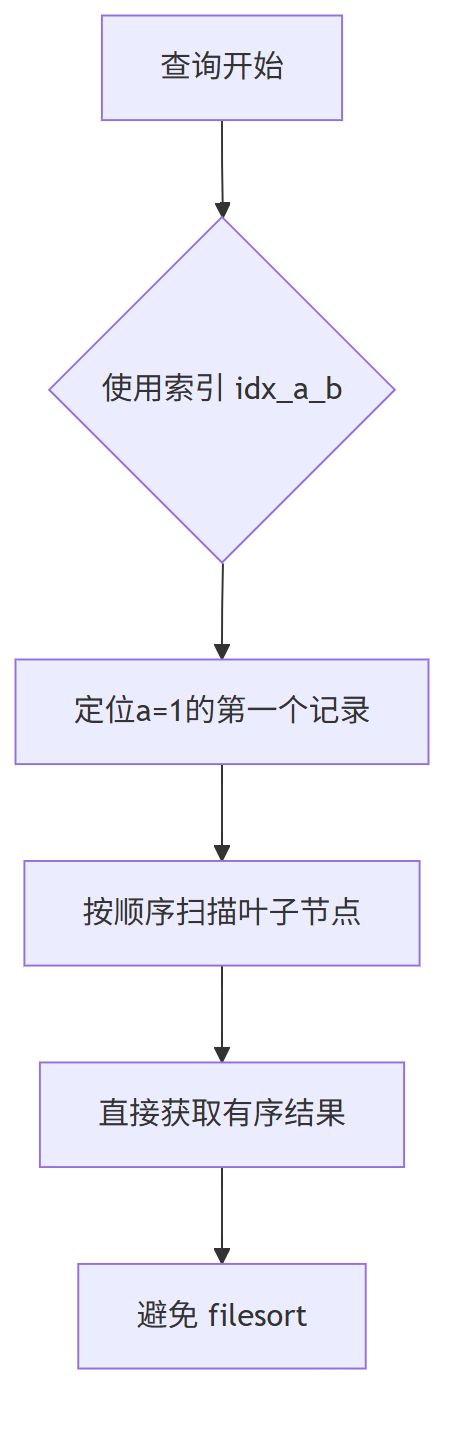
方案三:创建联合索引
-- 创建覆盖过滤+排序的联合索引
CREATE INDEX idx_a_b ON your_table(a, b);
优化后执行流程:
联合索引 (a, b)的结构:
索引结构:
+--------+--------+-------+
| a值 | b值 | 行指针 |
+--------+--------+-------+
| 1 | 3 | ->行3 |
| 1 | 5 | ->行1 |
| 1 | 8 | ->行2 |
| 2 | 4 | ... |
+--------+--------+-------+
联合索引的执行优势:
1. 过滤高效:直接定位 a=1的索引范围
2. 免排序:同一个 a分组内,b自然有序
3 覆盖索引(可选):若仅需 a,b列可避免回表
方案一、方案二、方案三 比较
由于平台 篇幅限制, 此处省略 1000字+
原始的内容,请参考 本文 的 原文 地址

 浙公网安备 33010602011771号
浙公网安备 33010602011771号