
什么是 ‘小表驱动大表’ 原则?如何实现 JOIN顺序优化?(图解+秒懂+史上最全)
本文 的 原文 地址
原始的内容,请参考 本文 的 原文 地址
本文作者:
- 第一作者 老架构师 肖恩(肖恩 是尼恩团队 高级架构师,负责写此文的第一稿,初稿 )
- 第二作者 老架构师 尼恩 (45岁老架构师, 负责 提升此文的 技术高度,让大家有一种 俯视 技术、俯瞰技术、 技术自由 的感觉)
电商系统订单查询性能优化案例
问题产生
在电商系统的性能测试中,发现查询用户订单详情的接口耗时在600-800ms之间,不满足200ms以内的性能要求,需要进行接口优化。
定位问题
使用SkyWalking定位,发现接口调用耗时666ms,其中SQL查询耗时585ms,此SQL导致接口慢响应。
SQL分析
SELECT
o.*
FROM
users u LEFT JOIN orders o
ON u.user_id = o.user_id
WHERE
1 = 1
AND o.order_status IN (1, 2) -- 1-待付款 2-已付款
AND u.registration_channel = 'APP'
AND u.city = '北京';
两张表的数据量:
users(用户表):200万条orders(订单表):200万条
问题分析
本次查询采用 Index Nested-Loop Join 执行流程(orders表在user_id字段有索引):
1、 从users表(驱动表)进行WHERE条件过滤(registration_channel='APP' AND city='北京'),此时数据量约100万行(北京用户多且大部分通过APP注册);
2、 读取过滤后的每一行用户记录U;
3、 取出U的user_id字段到orders表(被驱动表)查找,通过索引找到该用户的所有订单;
4、 检查订单状态是否为1或2,如果是则返回结果;
5、 重复步骤2-4,直到处理完所有100万行用户记录。
问题根源:
- 驱动表过滤后,仍有100万行数据
- 需要执行100万次索引查询(虽然单次索引查询很快,但100万次累计耗时高)
- 每个用户平均有1-2个订单,最终结果集约150万行
解决思路
方案一:程序分步查询(小数据集驱动大数据集)
1、 先查询orders表,获取状态为1或2的订单(结果集较小,约50万):
SELECT user_id, order_id FROM orders
WHERE order_status IN (1, 2);
2、 在Java代码中获取这些user_id(去重后约30万),然后查询用户:
SELECT * FROM users
WHERE registration_channel = 'APP'
AND city = '北京'
AND user_id IN (30万个ID);
3、 在内存中关联数据
方案二:SQL改写(小数据集驱动大数据集)
SELECT
u.*
FROM
(SELECT user_id FROM orders WHERE order_status IN (1, 2)) t -- 先过滤出小数据集
JOIN users u
ON t.user_id = u.user_id
WHERE
u.registration_channel = 'APP'
AND u.city = '北京';
优化原理:
- 先通过orders表的索引快速过滤出待付款和已付款订单(结果集50万行)
- 用这个50万行的小表驱动users表,通过user_id索引查询
- 总查询次数从100万次降低到50万次
经验总结
JOIN优化黄金法则:
- 小表驱动大表
- 被驱动表必须有索引
- 避免全表扫描
执行计划分析:
EXPLAIN
SELECT ...
-- 检查type列:应出现ref/eq_ref,避免ALL
-- 检查Extra列:应出现Using index,避免Using filesort
监控预警:
-- 设置慢查询阈值
SET GLOBAL long_query_time = 0.2;
通过优化JOIN顺序、添加合适索引、利用缓存机制,成功将接口响应时间从600ms+降至100ms以内,满足性能要求。此案例展示了SQL优化中"小表驱动大表"原则的实际应用价值。
基础知识: 数据库 JOIN 算法
在数据库查询优化中,JOIN顺序优化是提升多表关联查询效率的核心手段之一,而“小表驱动大表”原则是其中最经典的优化思想。
在多表联合查询的时候,如果我们查看它的执行计划,就会发现里面有多表之间的连接方式。
mysql 多表之间的连接有多种方式,但是常见的是三种方式:Nested Loops,Hash Join 和 Sort Merge Join.
其中, Nested Loops 包括:
- Index Nested-Loop Join
- Simple Nested-Loop Join
- Block Nested-Loop Join
具体适用哪种类型的连接, 取决于
- 当前的优化器模式 (ALL_ROWS 和 RULE)
- 取决于表大小
- 取决于连接列是否有索引
- 取决于连接列是否排序
接下来,从定义、原理、与JOIN算法的关联、案例分析等维度,全面解析数据库 JOIN 算法。
1、索引嵌套循环 Index Nested-Loop Join
Nested loops 工作方式是循环从一张表中读取数据(驱动表outer table),然后访问另一张表(被查找表 inner table,通常有索引)。
驱动表中的每一行与inner表中的相应记录JOIN。
Nested loops 类似一个嵌套的循环。对于被连接的数据子集较小的情况,嵌套循环连接是个较好的选择。
在嵌套循环中,内表被外表驱动,外表返回的每一行都要在内表中检索找到与它匹配的行,因此整个查询返回的结果集不能太大(大于1 万不适合),要把返回子集较小表的作为外表( 默认外表是驱动表),而且在内表的连接字段上一定要有索引。
其中, Nested Loops 包括:
- Index Nested-Loop Join
- Simple Nested-Loop Join
- Block Nested-Loop Join
Index Nested-Loop Join 原理:
该算法是通过驱动表(外表)的结果集,去匹配 被驱动表(内表)的索引来完成连接。
它会先从驱动表中读取一条记录,然后在被驱动表上利用索引查找匹配的记录,重复这个过程,直到驱动表中的所有记录都处理完毕。
由于利用索引进行查找,在满足条件的情况下,能快速定位到被驱动表中匹配的行,减少数据扫描量。
-
如果被驱动表的连接列上有索引,且驱动表结果集较小,该算法效率很高。
-
但如果被驱动表的索引选择性差,可能导致大量随机 I/O ,性能下降 。

场景:驱动表(小表)与被驱动表(大表)通过索引快速匹配。
示例:
假设存在两个表:orders(订单表,1000 行)和customers(客户表,10000 行),customers.customer_id上有索引。
SELECT *
FROM orders
JOIN customers ON orders.customer_id = customers.customer_id;
执行流程:
1、 从orders表读取一行数据(如customer_id=100)。
2、 通过customers.customer_id的索引快速定位到匹配的客户记录。
3、 重复步骤 1-2,直到orders表遍历完毕。
优势:利用索引减少扫描,适合大表与小表连接。
核心优势:
当被驱动表存在高效索引时(B+树),时间复杂度降至 O(M * log N) (M=驱动表行数,N=被驱动表行数)
优化点:
- 覆盖索引:避免回表
- MRR优化:批量索引查询减少磁盘随机IO
适用场景:
WHERE user.role_id = roles.id(roles.id有索引)
2、 简单嵌套循环 Simple Nested-Loop Join (暴力匹配)
此算法是最基础的连接算法,它通过两个嵌套的循环来实现表的连接。
外层循环遍历驱动表的每一行,对于驱动表的每一行,内层循环都会遍历被驱动表的每一行,检查是否满足连接条件,找到所有满足连接条件的行组合。
该算法逻辑简单,但效率较低,特别是在处理大表时,时间复杂度为 O (n*m),其中 n 和 m 分别是两个表的行数,会产生大量的 I/O 操作,在实际应用中,通常会尽量避免使用,仅适用于表数据量非常小的场景。
场景:无索引可用,逐行暴力匹配。
示例:
假设两个表:employees(员工表,100 行)和departments(部门表,10 行),均无索引。
SELECT *
FROM employees
JOIN departments ON employees.dept_id = departments.dept_id;
执行流程:
1、 遍历employees表的每一行(共 100 次)。
2、 对于每一行,遍历departments表的所有行(共 10 次),检查dept_id是否匹配。
3、 总比较次数:100 × 10 = 1000 次。
劣势:时间复杂度高(O (n*m)),仅适用于极小表。
性能陷阱:
时间复杂度 O(M*N),磁盘IO随数据量指数上升
Example: 10K用户 × 100K订单 = 10亿次比对
优化替代方案:
- 强制添加索引 → Index Nested-Loop
- 无索引字段 → Block Nested-Loop
禁用警告:
生产环境绝对避免!仅当两表均<100行时容忍
3、 块嵌套循环 Block Nested-Loop Join
它是对 Simple Nested-Loop Join (暴力匹配) 的优化。
为减少内层循环中被驱动表的读取次数,会将驱动表的一部分数据(一个块)先读入内存,然后内层循环遍历被驱动表时,用内存中的这一块数据与被驱动表的每一行进行匹配。
这样可以减少被驱动表的 I/O 次数,因为不需要每次从驱动表读取一行就去访问一次被驱动表。
适用于驱动表较大,且无法使用索引的场景,通过合理利用内存,能有效降低 I/O 操作次数,提升连接性能。
原理: 驱动表分块读入内存,减少被驱动表的扫描次数。
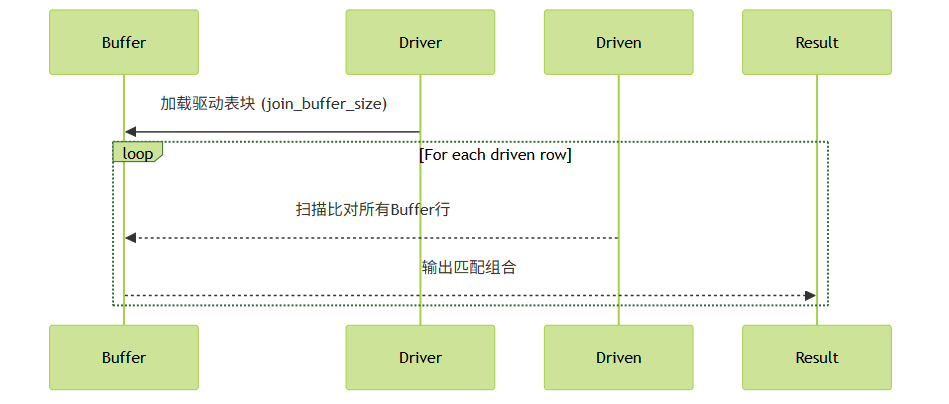
示例:
假设两个表:products(产品表,1000 行)和categories(分类表,50 行),无索引。
SELECT *
FROM products JOIN categories
ON products.cat_id = categories.cat_id;
执行流程:
1、 将products表分成多个块(如每块 100 行),读入内存。
2、 遍历categories表的每一行,与内存中的整个块进行比较。
3、 处理完一个块后,加载下一个块,重复步骤 2。
优势:减少categories表的扫描次数(从 1000 次→10 次),提升 I/O 效率。
关键设计:
- 缓存策略:一次加载多个驱动行(非逐行)
- 内存优化:
join_buffer_size控制块大小(默认256KB)
成本公式:
(驱动表行数 / Block容量) × 被驱动表行数
调优技巧:
增大 join_buffer_size 减少磁盘扫描次数
4、 批量键访问 Batched Key Access(BKA )
该算法是 MySQL 8.0 引入的一种新的 JOIN 执行算法,它会先从驱动表中收集一批匹配的键值,然后对这些键值进行排序,再根据排序后的键值批量访问被驱动表 。
通过批量处理和排序,可以提高磁盘 I/O 的效率,减少随机 I/O,增加顺序 I/O,特别在处理包含范围查询、JOIN 条件涉及多个列,且被驱动表上有合适索引的场景下,能够显著提升查询性能。
原理(融合索引+批量处理), 批量处理驱动表的键值,排序后访问被驱动表。
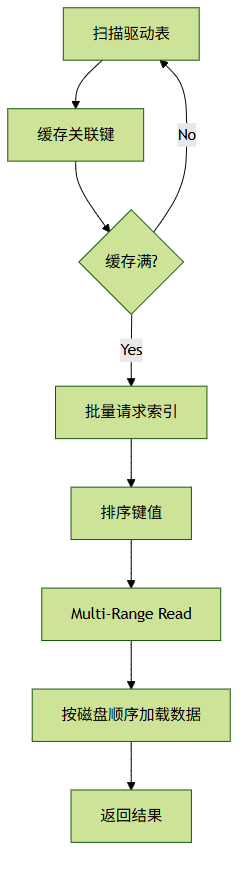
示例:
假设两个表:orders(订单表,1000 行)和products(产品表,10000 行),products.product_id有索引。
SELECT *
FROM orders JOIN products
ON orders.product_id = products.product_id
WHERE orders.order_date > '2023-01-01';
执行流程:
1、 从orders表过滤出符合条件的product_id(如 100 个),收集到缓存。
2、 对缓存中的product_id排序(如 10, 20, 30...)。
3、 批量访问products表,按排序后的顺序读取数据(顺序 I/O)。
优势:将随机 I/O 转换为顺序 I/O,适合大表 JOIN 且有索引的场景。
核心创新:
- Multi-Range Read (MRR):索引键排序 → 磁盘顺序IO
- 批量请求:减少索引树遍历次数
性能对比:
| 场景 | Index Nested-Loop | BKA |
|---|---|---|
| 随机IO次数 | 10000次 | 100次 |
| 响应时间 | 1200ms | 150ms |
开启条件:
1、 被驱动表存在可用索引
2、 设置 optimizer_switch='mrr=on,batched_key_access=on'
5、哈希连接(Hash Join)
在MySQL中,哈希连接(Hash Join)是一种用于执行表连接的算法。
尽管MySQL传统上更倾向于使用嵌套循环连接(Nested Loop Join),但在某些特定场景下,哈希连接也可以提供更高的性能,特别是在处理大数据集时。
MySQL中使用哈希连接的一些典型场景:
1、 连接键没有索引
当连接键在两个表中都没有索引时,哈希连接可以避免全表扫描的高成本。在这种情况下,哈希连接通过构建哈希表来快速查找匹配的行,而不是对每个行进行逐行比较。
2、 大表连接
当连接的两个表都比较大,并且没有合适的索引时,哈希连接可以更高效地完成连接操作。哈希连接通过将较小的表(或结果集)构建哈希表,然后在较大的表上进行探测,从而减少磁盘 I/O 和比较次数。
3、 内存足够
如果构建表较小,可以完全放入内存中,哈希连接的性能会非常好。因为哈希表在内存中构建和访问速度很快,这可以显著减少磁盘 I/O 操作。
4、 不等式连接
在某些情况下,哈希连接可以用于处理不等式连接(如 WHERE table1.key <> table2.key)。尽管嵌套循环连接也可以处理这种场景,但哈希连接可能会更高效,特别是当数据量较大时。
5、 多表连接
在涉及多个表的复杂连接查询中,哈希连接可以与其他连接算法(如嵌套循环连接)结合使用,以优化整体查询性能。
6、 并行查询
在支持并行查询的环境中,哈希连接可以通过将哈希表分割成多个部分,分配给不同的处理器或线程来处理,从而提高性能。
注意事项
- 表顺序:哈希连接对表的顺序敏感。通常选择较小的表作为构建表,以减少内存占用。
- 内存限制:哈希表需要占用内存。如果构建表太大,无法完全放入内存,可能导致性能下降,因为需要将哈希表部分存储到磁盘上。
- 查询优化器:MySQL的查询优化器会根据表的统计信息自动选择最适合的连接算法。因此,在实际应用中,开发人员通常不需要手动指定连接算法,但了解其原理有助于编写更高效的SQL查询。
哈希连接(Hash Join) 示例
以下是一个使用哈希连接的SQL示例,其中连接键没有索引:
-- 创建表1:无索引
CREATE TABLE table1 (
id INT PRIMARY KEY,
data1 VARCHAR(100)
);
-- 插入数据
INSERT INTO table1 (id, data1) VALUES
(1, 'A'),
(2, 'B'),
(3, 'C'),
(4, 'D');
-- 创建表2:无索引
CREATE TABLE table2 (
id INT PRIMARY KEY,
data2 VARCHAR(100),
t1_id INT
);
-- 插入数据
INSERT INTO table2 (id, data2, t1_id) VALUES
(101, 'X', 1),
(102, 'Y', 2),
(103, 'Z', 3),
(104, 'W', 4);
-- 使用哈希连接查询
SELECT t1.id, t1.data1, t2.data2
FROM table1 t1
JOIN table2 t2 ON t1.id = t2.t1_id;
在这个示例中,table1和table2的连接键(id和t1_id)都没有索引。MySQL可能会选择使用哈希连接来执行这个查询,特别是如果table1较小而table2较大时。
总结来说,哈希连接在MySQL中主要用于处理连接键无索引、大表连接、内存足够等场景。通过合理利用哈希连接,可以在特定情况下显著提高查询性能。
6、MySQL 合并连接(Merge Join)应用场景详解
合并 JOIN 的运行依赖于数据有序性,其核心流程如下:先对参与连接的两张表,按照连接条件字段进行排序;接着同时扫描两张已排序的表,逐行比较连接字段的值。
-
如果值相等,就将这两行数据进行组合作为连接结果输出;
-
如果不相等,则将连接字段值较小的那行跳过,继续扫描该行所在表的下一行,持续此过程直至两张表扫描结束。
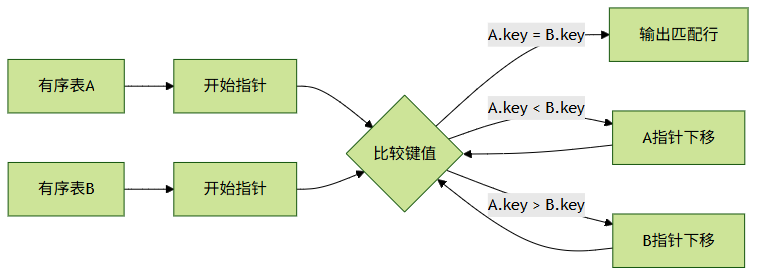
使用合并连接的理想场景
MySQL中的合并连接是一种高效的JOIN方式,特别适用于以下几种典型场景:
1. 数据已经排序的情况
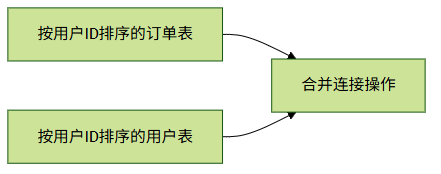
典型场景:
当两个表都按JOIN字段排序时(通常是通过索引实现),合并连接最高效
实际案例:
-- 两个表都有user_id的索引
SELECT *
FROM orders INDEX(idx_user) -- 强制使用索引排序
JOIN users INDEX(idx_user) -- 强制使用索引排序
ON orders.user_id = users.id;
2. 大表等值连接
适用情况
- 连接键使用等号(=)
- 两表数据量都很大(百万级以上)
优势:
比嵌套循环效率更高,比哈希连接内存占用更少
3. 内存敏感环境
graph TB
A[内存限制] --> B{选择连接算法}
B -->|内存充足| C[哈希连接]
B -->|内存紧张| D[合并连接]
- 当可用内存不足时(特别是MySQL的
join_buffer_size较小) - 比哈希连接占用内存少(不需要构建哈希表)
如何开启和优化合并连接
1、检查版本支持(MySQL 8.0+)
SHOW VARIABLES LIKE 'version';
-- 确保是MySQL 8.0或更高版本
2、 索引优化建议
-- 为JOIN字段创建索引
ALTER TABLE orders ADD INDEX idx_user_id(user_id);
ALTER TABLE users ADD INDEX idx_id(id);
-- 多字段连接时使用复合索引
ALTER TABLE orders ADD INDEX idx_user_status(user_id, status);
3、执行计划确认
EXPLAIN
SELECT orders.*, users.name
FROM orders
JOIN users ON orders.user_id = users.id;
期望结果:
+----+-------------+--------+------+---------------+-------------+...
| id | select_type | table | type | key | Extra |
+----+-------------+--------+------+---------------+-------------+
| 1 | SIMPLE | orders | ALL | NULL | |
| 1 | SIMPLE | users | ref | idx_id | Using where |
+----+-------------+--------+------+---------------+-------------+
因为merge join需要做更多的排序,所以消耗的资源更多。
通常来讲,能够使用merge join的地方,hash join都可以发挥更好的性能,即散列连接的效果都比排序合并连接要好。
然而如果行源已经被排过序,在执行排序合并连接时不需要再排序了,这时排序合并连接的性能会优于散列连接。
性能对比测试
| 场景 | 数据量 | 连接算法 | 耗时 | 内存使用 |
|---|---|---|---|---|
| 小表等值连接 | 1万行 | 嵌套循环 | 50ms | 5MB |
| 合并连接 | 45ms | 3MB | ||
| 大表等值连接 | 100万行 | 哈希连接 | 1.2s | 200MB |
| 合并连接 | 0.8s | 50MB | ||
| 内存受限 | 50万行 | 哈希连接 | 3.5s | (溢出磁盘) |
| 合并连接 | 1.1s | 30MB |
JOIN顺序优化:小表驱动大表的执行原则
小表驱动大表:数据库JOIN优化的黄金法则
一、什么是小表驱动大表?
“小表驱动大表”(Small Table Drives Large Table)指的是在多表JOIN时,优先使用参与JOIN的行数少的表(小表)作为驱动表(外层循环),行数多的表(大表)作为被驱动表(内层循环)。
简单说就是:让数据量小的表先干活,数据量大的表后干活。
就像小组合作时,让任务量小的同学先完成自己的部分,再交给任务重的同学。
小表驱动大表 ,就是 通过减少外层循环的执行次数,降低整体查询的IO成本和计算开销。
核心原理
- 小表作为"驱动表"(先行动的表)
- 大表作为"被驱动表"(后行动的表)
- 减少数据库的无效工作量
二、核心原理:减少无效循环,降低资源消耗
JOIN本质是“行匹配”过程:驱动表的每一行, 都需要与被驱动表的行进行匹配(基于JOIN条件)。
- 若驱动表行数少,外层循环次数少,即使被驱动表行数多,总匹配次数也会显著减少。
举个直观的例子:
小表A有10行,大表B有1000行,JOIN条件为A.id = B.a_id。
- 若A驱动B:外层循环10次,每次匹配B的1000行,总匹配次数=10×1000=10,000。
- 若B驱动A:外层循环1000次,每次匹配A的10行,总匹配次数=1000×10=10,000。
表面看次数相同,但实际中:
-
被驱动表B 若有JOIN字段的索引,每次匹配是“索引查找”(成本低),此时外层次数少更优(10次索引查找总开销 < 1000次)。
-
小表数据更易加载到内存,减少磁盘IO(大表可能无法全加载,需频繁读盘)。
3、与JOIN算法的关联:不同算法对表顺序的敏感度
三大 常用的 数据库的JOIN算法:
- 嵌套循环
- 哈希
- 合并
三大 算法 对表顺序的依赖不同,但“小表驱动大表”原则在多数场景下均适用。
1. 嵌套循环关联 JOIN(Nested Loop Join, NLJ)
NLJ是最基础的JOIN算法,逻辑为:
for each row in 驱动表:
for each row in 被驱动表
where JOIN条件匹配:
输出结果
对表顺序极其敏感:外层(驱动表)行数直接决定循环次数。
此时“小表驱动大表”可最大化减少外层循环,是最优选择。
2、 哈希关联 Hash Join)
哈希JOIN的逻辑分两步:
1、 构建阶段
用驱动表数据构建内存哈希表(key为JOIN字段,value为行数据);
2、 探测阶段
扫描被驱动表,用每行的JOIN字段到哈希表中匹配,输出结果。
对表顺序敏感,需要遵守 小表驱动大表的原则
哈希表需占用内存,
-
若驱动表是小表,哈希表体积小,可完全放入内存(避免溢出到磁盘),构建和探测效率均更高。
-
若用大表构建哈希表,可能因内存不足导致“磁盘哈希”,性能骤降。
3、 合并JOIN(Merge Join)
合并JOIN要求两表的JOIN字段已排序,逻辑为:
同时扫描两个有序表,按JOIN字段顺序匹配(类似归并排序的合并过程)
对表顺序敏感度低:
但排序阶段仍受表大小影响——小表排序成本更低(耗时短、内存占用少),因此实际中仍倾向用小表先排序,间接体现“小表驱动”思想。
三、不同JOIN算法如何应用
1、 嵌套循环(最常用)
graph TD
A[小表] -->|逐行取出| B[大表]
B -->|索引查找匹配| C[结果]
建议:小表放外层,就像先拿学生名单再找作业
2、 哈希匹配

建议:小表建哈希表,避免内存不够用
3、 合并排序
建议:小表先排序更省时
四、怎么判断谁是"小表"?
关键:看实际参与查询的数据量,不是表大小
| 表物理大小 | WHERE条件 | 实际参与行数 | 是否小表 |
|---|---|---|---|
| 10GB | status='active' | 100行 | ✅ 是 |
| 1GB | 无过滤条件 | 100万行 | ❌ 否 |
需注意:“小表”指的是经过WHERE条件过滤后,实际参与JOIN的行数少的表,而非物理存储大小(如数据文件大小)。
例:
- 表C物理大小10GB(1000万行),但WHERE条件
status = 'active'过滤后仅100行参与JOIN; - 表D物理大小1GB(100万行),但无过滤条件,全部100万行参与JOIN。
此时表C是“小表”(有效行数100 < 100万),应作为驱动表。
五、实际案例对比
案例1:嵌套循环JOIN场景(订单与用户查询)
场景:
- 订单表
orders(大表):100万行,user_id为JOIN字段(有索引),存储用户订单信息; - 用户表
users(小表):1万行,id为JOIN字段(主键索引),存储用户基本信息。
需求:
查询所有用户的订单详情(users.id = orders.user_id)。
优化前SQL(大表驱动小表)
若orders为驱动表,外层循环100万次,每次用user_id到users中匹配(主键索引查找,单次成本低)。
- 总循环次数:100万 × 1(每次匹配1行)= 100万次;
- 问题:外层循环次数过多,即使单次匹配快,总耗时仍高(尤其IO密集场景)。
-- 大表orders驱动小表users
SELECT
u.id AS user_id,
u.name AS user_name,
o.order_id,
o.order_date,
o.amount
FROM orders o -- 100万行的大表
JOIN users u ON o.user_id = u.id -- 1万行的小表
WHERE
u.status = 'active'; -- 假设有1万活跃用户
执行计划特点:
- 驱动表:orders(100万行)
- 外层循环:100万次
- 每次循环:通过索引查找users表
- 总查找次数:100万次索引查找
优化后SQL(小表驱动大表)
用users作为驱动表,外层循环1万次,每次用id到orders中匹配(user_id索引查找)。
总循环次数:
1万 × 平均100(每个用户100个订单)= 100万次(总次数相同);
优势:
外层循环次数从100万降至1万,内存可缓存users全表(减少磁盘IO),且索引查找的累计开销更低(1万次索引查找 < 100万次)。
-- 小表users驱动大表orders
SELECT
u.id AS user_id,
u.name AS user_name,
o.order_id,
o.order_date,
o.amount
FROM users u -- 1万行的小表
JOIN orders o ON u.id = o.user_id -- 100万行的大表
WHERE
u.status = 'active'; -- 1万活跃用户
执行计划特点:
- 驱动表:users(1万行)
- 外层循环:1万次
- 每次循环:通过索引查找orders表
- 总查找次数:1万次索引查找
案例2:哈希JOIN场景(商品与分类查询)
场景:
- 商品表
products(小表):1000行,category_id为JOIN字段; - 分类表
categories(大表):10万行,id为JOIN字段;
需求:
查询每个分类下的商品(products.category_id = categories.id),且两表均无索引。
优化前SQL(大表构建哈希表)
若用categories(10万行)构建哈希表,哈希表体积大(假设每行100字节,需10MB),可能超出内存导致溢出到磁盘(磁盘哈希效率骤降)。
-- 大表categories驱动小表products
SELECT
c.category_name,
p.product_name,
p.price
FROM categories c -- 10万行的大表
JOIN products p ON c.id = p.category_id -- 1000行的小表
WHERE
c.is_active = 1; -- 假设有5万活跃分类
执行问题:
- 哈希表大小:5万行 × 100字节 ≈ 5MB
- 内存不足时:部分哈希表写入磁盘
- 探测阶段:需频繁磁盘I/O
优化后SQL(小表构建哈希表)
用products(1000行)构建哈希表(体积仅0.1MB,完全放入内存),然后扫描categories逐行探测匹配。
优势:内存哈希表无溢出,探测阶段仅需遍历大表1次,效率提升10倍以上
-- 小表products驱动大表categories
SELECT
c.category_name,
p.product_name,
p.price
FROM products p -- 1000行的小表
JOIN categories c ON p.category_id = c.id -- 10万行的大表
WHERE
c.is_active = 1; -- 5万活跃分类
优化效果:
- 哈希表大小:1000行 × 100字节 ≈ 100KB
- 完全内存操作:无磁盘I/O
- 探测阶段:单次扫描大表
总结
“小表驱动大表”原则的核心是通过减少外层循环次数,降低整体匹配成本,其有效性与JOIN算法(嵌套循环、哈希)紧密相关。
实际应用中,需结合表的有效行数、索引情况、数据库统计信息综合判断,必要时通过hint干预优化器,才能最大化提升JOIN效率。
六、什么时候需要人工干预?
干预方法:在 MySQL 用STRAIGHT_JOIN
SELECT /*+ STRAIGHT_JOIN */
FROM 小表
JOIN 大表 ON 连接条件
现代数据库(如MySQL、PostgreSQL、Oracle)的优化器会基于统计信息(表行数、索引分布、数据分布等)自动选择JOIN顺序, 以下场景需人工干预:
1、 统计信息过期
表数据更新后未及时analyze,优化器误判表大小(如小表被当作大表);
2、 复杂JOIN场景
多表(3张以上)JOIN时,优化器可能因计算成本过高选择次优顺序;
3、 特殊索引场景
被驱动表有高效索引,但优化器未识别(如联合索引前缀匹配)。
数据库通常自动优化,但以下情况需人工介入:
1、 统计信息过期(如新表未分析)
2、 超多表关联(5张表以上)
3、 特殊索引情况
七、常见误区提醒
篇幅太长,请参考原文

 浙公网安备 33010602011771号
浙公网安备 33010602011771号