Netty内存池(史上最全 + 5W字长文)
文章很长,而且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《尼恩Java面试宝典 最新版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
本文宗旨:不断迭代,带大家起底式、穿透式 搞定Netty内存池、对象池
Netty的内存池、 对象池,都太、太、太 TM的NB了,
对象池 通过ThreadLocal无锁机制消除了多线程的竞争, 非常巧妙。
Netty 两池, 非常值得大家去学习,去深入的学习,并且在项目中去使用
后面如果有机会,尼恩带着大家,从架构、设计、实现,带着大家去手写 两大池子: 内存池 + 对象池。
作为基础组件,大家可以在自己的 高并发 、高性能项目中,去使用。
接下来,为大家介绍一下 两池的基本原理
为什么需要池化内存
Netty 作为底层网络框架,为了更高效的网络传输性能,堆外内存(Direct ByteBuffer)的使用是非常高频的。
堆外内存在 JVM 之外,在有效降低 JVM GC 压力的同时,还能提高传输性能。
但它也是一把双刃剑,堆外内存是非常宝贵的资源,申请和释放都是高成本的操作,使用不当还可能造成严重的内存泄露等问题 。
性能问题:创建堆外内存的速度比堆内存慢了10到20倍
那么进行池化管理,多次重用是比较有效的方式。
为了解决这个问题Netty就做了内存池,Netty的内存池是不依赖于JVM本身的GC的。
从申请内存大小的角度讲,申请多大的 Direct ByteBuffer 进行池化又会是一大问题,太大会浪费内存,太小又会出现频繁的扩容和内存复制!!!
所以呢,就需要有一个合适的内存管理算法,解决高效分配内存的同时又解决内存碎片化的问题。
所以一个优秀的内存管理算法必不可少。
一个内存分配器至少需要看关注两个核心目标:
- 高效的内存分配和回收,提升单线程或者多线程场景下的性能
- 提高内存的有效利用率,减少内存碎片,包括内部碎片和外部碎片
可以带着以下问题去看Netty内存池源码:
- 内存池管理算法是怎么做到申请效率,怎么减少内存碎片
- 高负载下内存池不断扩展,如何做到内存回收
- 对象池是如何实现的,这个不是关键路径,可以当成黑盒处理
- 内存池跟对象池作为全局数据,在多线程环境下如何减少锁竞争
- 池化后内存的申请跟释放必然是成对出现的,那么如何做内存泄漏检测,特别是跨线程之间的申请跟释放是如何处理的。
jemalloc
jemalloc是一种优秀的内存管理算法,在这里就不展开去探究了,大家可以自行 google 百度。本文基于netty管理pooled direct memory实现进行讲解,netty对于java heap buffer的管理和对direct memory的管理在实现上基本相同
Netty 作为一款高性能的网络应用程序框架,拥有自己的内存分配。
Netty内存池的思想源于 jemalloc github ,可以说是 jemalloc 的 Java 版本。
本章源码基于 Netty 4.1.0版本,该版本是采用 jemalloc3.x 的算法思想,而 4.1.45 以后的版本则基于 jemalloc4.x 算法进行重构,两者差别还是挺大的。
jemalloc 是由 Jason Evans 在 FreeBSD 项目中引入的新一代内存分配器。它是一个通用的 malloc 实现,侧重于减少内存碎片和提升高并发场景下内存的分配效率,其目标是能够替代 malloc。jemalloc 应用十分广泛,在 Firefox、Redis、Rust、Netty 等出名的产品或者编程语言中都有大量使用。具体细节可以参考 Jason Evans 发表的论文 [《A Scalable Concurrent malloc Implementation for FreeBSD》]。
除了 jemalloc 之外,业界还有一些著名的高性能内存分配器实现,比如 ptmalloc 和 tcmalloc。简单对比如下:
- ptmalloc(per-thread malloc) 基于 glibc 实现的内存分配器,由于是标准实现,兼容性较好。缺点是多线程之间内存无法实现共享,内存开销很大。
- tcmalloc(thread-caching malloc) 是由 Google 开源,最大特点是带有线程缓存,目前在 Chrome、Safari 等产品中有所应用。tcmalloc 为每个线程分配一个局部缓存,可以从线程局部缓冲分配小内存对象,而对于大内存分配则使用自旋锁减少内存竞争,提高内存效率。
jemalloc借鉴 tcmalloc 优秀的设计思路,所以在架构设计方面两者有很多相似之处,同样都包含线程缓存特性。但是 jemalloc 在设计上比 tcmalloc 要复杂。它将内存分配粒度划分为Small、Large、Huge,并记录了很多元数据,所以元数据占用空间高于 tcmalloc。
从上面了解到,他们的核心目标无外乎有两点:
- 高效的内存分配和回收,提升单线程或多线程场景下的性能。
- 减少内存碎片,包括内存碎片和外部碎片。提高内存的有效利用率。
内存碎片
在 Linux 世界,物理内存会被划分成若干个 4KB 大小的内存页(page),这是分配内存大小的最小粒度。
分配和回收都是基于 page 完成的。
page 内产生的碎片称为 内存碎片,page 外产生的碎片称为 外部碎片。
内存碎片产生的原因:
是内存被分割成很小的块,虽然这些块是空闲且地址连续的,但却小到无法使用。
随着内存的分配和释放次数的增加,内存将变得越来越不连续。
最后,整个内存将只剩下碎片,即便有足够的空闲页框可以满足请求,但要分配一个大块的连续页框就无法满足,
外部碎片产生的原因:
外部碎片指的是还没有被分配出去(不属于任何进程),但由于太小了无法分配给申请内存空间的新进程的内存空闲区域。
外部碎片是出于任何已分配区域或页面外部的空闲存储块。
这些存储块的总和可以满足当前申请的长度要求,但是由于它们的地址不连续或其他原因,使得系统无法满足当前申请。
减少内存浪费的核心
所以减少内存浪费的核心就是尽量避免产生内存碎片。
常见的内存分配器算法
常见的内存分配器算法有:
- 动态内存分配
- 伙伴算法
- Slab算法
动态内存分配
全称 Dynamic memory allocation,又称为 堆内存分配,简单 DMA。
简单地说就是想要多少内存空间,操作系统就给你多少。在大部分场景下,只有在程序运行时才知道所需内存空间大小,
提前分配的内存大小空间不好把控,分配太多造成空间浪费,分配太少造成程序崩溃。
DMA 就是从一整块内存中 按需分配,对于已分配的内存会记录元数据,同时还会使用空闲分区维护空闲内存,便于在下次分配时快速查找可用的空闲分区。
常见的有以下三种查找策略:
首次适应算法(first fit)
- 空闲分区按内存地址从低到高的顺序以双向链表形式连接在一起。
- 内存分配每次从低地址开始查找并分配。因此造成低地址使用率较高而高地址使用率很低。同时会产生较多的小内存。
循环首次适应算法(next fit)
- 该算法是 首次适应算法 的变种,主要变化是第二次的分配是从下一个空闲分区开始查找。
- 对于 首次适应算法 ,该算法将内存分配得更加均匀,查找效率有所提升,但是这会导致严重的内存碎片。
最佳适应算法(best fit)
- 空间分区链始终保持从小到大的递增顺序。当内存分配时,从开头开始查找适合的空间内存并分配,当完成分配请求后,空闲分区链重新按分区大小排序。
- 此算法的空间利用率更高,但同样会有难以利用的小空间分区,究其原因是空闲内存块大小不变,并没有针对内存大小做优化分类,除非内存内存大小刚好等于空闲内存块的大小,空间利用率 100%。
- 每次分配完后需要重新排序,因此存在 CPU 消耗。
动态内存分配的问题
动态内存分配的问题:会导致严重的内存碎片
内存碎片就是内存被分割成很小很小的一些块,这些块虽然是空闲的,可是却小到没法使用。
随着申请和释放次数的增长,内存将变得愈来愈不连续。
最后,整个内存将只剩下碎片,即便有足够的空闲页框能够知足请求,但要分配一个大块的连续页框就可能没法满足,因此减小内存浪费的核心就是尽可能避免产生内存碎片。
针对这样的问题,有不少行之有效的解决方法,其中伙伴算法被证实是很是行之有效的一套内存管理方法,所以也被至关多的操做系统所采用。
伙伴算法(Buddy memory allocation)
如何避免外部碎片的方法有两种:
(1)是利用分页单元把一组非连续的空闲页框映射到连续的线性地址区间;
(2)伙伴系统:是记录现存空闲连续页框块情况,以尽量避免为了满足对小块的请求而分割大的连续空闲块。
伙伴内存分配技术是一种内存分配算法,它将内存划分为分区,以最合适的大小满足内存请求。
Buddy memory allocation 于 1963 年 Harry Markowitz 发明。
伙伴算法的原理
伙伴(buddy)算法中,它不像DMA那样,根据需要从被管理内存的空闲分区以随意大小方式进行分配。
而是按照不同的规格,以块为单位进行分配。各个内存块可分可合,但不是任意的分与合。
每一个块都有个朋友,或叫“伙伴”,既可与之分开,又可与之结合。所以,只有伙伴关系的内存块,才能分开和合并。
伙伴算法的原理:
系统中的空闲内存总是按照相邻关系,两两分组,每组中的两个内存块称作伙伴。
伙伴的分配可以是彼此独立的。
但如果两个小伙伴都是空闲的,内核将其合并为一个更大的内存块,作为下一层次上某个内存块的伙伴。
具体先看下一个例子:
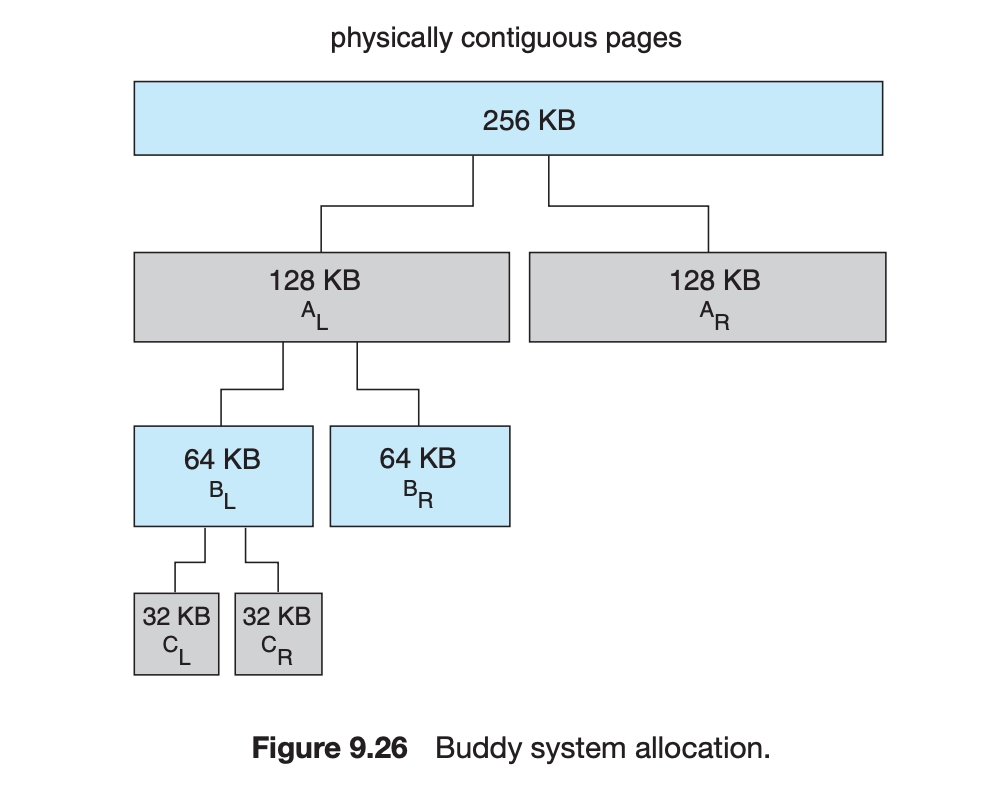
首先,伙伴算法把所有的空闲页面分为10个块组,
每组中块的大小是2的幂次方个页面,例如
- 第0组中块的大小都为1个页面,
- 第1组中块的大小为都为2个页面,
- 第9组中块的大小都为512个页面。
也就是说,每一组中块的大小是相同的,且这同样大小的块形成一个链表(可以解释为hashmap中hash值相同的key的桶 bucket)。
剩下的未分配的内存,我们将其添加到第10个块组中。
并且,除了第0个块组有2个块以外,其余都只有一个块,但是第10个块组可以有多个块。
什么的伙伴块?如何获取?
伙伴块指的是连续的两个块,这两个块大小相等,并且两个块合并后的块可以一直迭代合并为1024页的大块。
这一点可能不太好理解,画了个图:

假设我们寻找1号块的伙伴块,如果是2号块的话,当1,2号块合并后,是无法继续与0号块 合并的,此时0号块就变成了不可合并状态,所以1号块的伙伴块应该是0号而不是2号。
寻找到伙伴块的方法是这样的:
当块大小为n时,寻找到的伙伴块必须满足,合并后的大块的左边(低内存)区域的大小应该是合并大块的k倍,即2nk的大小(k为非负整数)。
怎么进行快分配?
当需要分配一个内存大小为n时,需要分配一个内存块,块的大小为m,且m满足: m/2 < n and m>=n.
通过这个限制条件,我们可以获得要分配的块的大小,并且到对应的块组寻找有没有空闲块,如果有的话就把这个块分配出来,如果没有的话就把继续寻找到上一级块组,如果上一级有的话,就将这个空闲块拆分为两个并且分配一个块出来,另一个块归入下一级块组中。
如果上一级也没有空闲块的话,就继续向上一级寻找,递归寻找到合适的块。
怎么进行块释放?
类似于块分配的逆向操作,回收一个块时会首先检测其伙伴块是否空闲,如果空闲的话,回收块会与伙伴块合并为更大的块,并且在上一级块组中寻找伙伴块合并,递归进行此操作,直到无法再次合并为止。
伙伴算法的一个简单例子
假设,一个最初由256KB的物理内存。假设申请21KB的内存,内核需分片过程如下:
内核将256KB的内存进行分割,变成两个128KB的内存块,AL和AR,这两个内存块称为伙伴。
随后他发现128KB也远大于21KB,于是他继续分割为两个64KB的内存块,发现64KB 也不是满足需求的最小的内存块,于是他继续分割为两个32KB的。
32KB再往下就是16KB,就不满足需求了,所以32KB是它满足需求的最下的内存块了,所以他就分割出来的CL 或者CR 分配给需求方。
当需求方用完了,需要进行归还:
然后他把32KB的内存还回来,它的另一个伙伴如果没被占用,那么他们地址连续,就合并成一个64KB的内存块,以此类推,进行合并。
注意:
这里的所有的分割都是进行二分来分割,所有内存块的大小都是2的幂次方。
伙伴算法的秘诀:
把内存块存放在比链接表更先进的数据结构中。这些结构常常是桶型、树型和堆型的组合或变种。一般来说,由于所选数据结构的不同,而各伙伴分配程序的工作方式是相差很大。
由于有各种各样的具有已知特性的数据结构可供使用,所以伙伴分配程序得到广泛应用。
伙伴分配程序编写起来常常很复杂,其性能可能各不相同。
linux内核中伙伴算法
Linux内核内存管理的一项重要工作就是如何在频繁申请释放内存的情况下,避免碎片的产生。
Linux采用伙伴系统解决外部碎片的问题,采用slab解决内部碎片的问题。
Linux2.6为每一个管理区使用不一样的伙伴系统,内核空间分为三种区,DMA,NORMAL,HIGHMEM,对于每一种区,都有对应的伙伴算法。
linux内核中,伙伴算法把所有的空闲页框分组成 11 个块链表,每一个块链表分别包含大小为1、2、4、8、16、32、64、128、256、512 和 1024 个连续的页框。
最大内存请求大小为 4MB,该内存是连续的。伙伴算法即大小相同、地址连续。
11个块链表中:
-
第0个块链表包含大小为2^0个连续的页框,
-
第1个块链表中,每一个链表元素包含2个页框大小的连续地址空间
-
….
-
第10个块链表中,每一个链表元素表明4M的连续地址空间。
每一个链表中元素的个数在系统初始化时决定,在执行过程当中,动态变化。
#ifndef CONFIG_FORCE_MAX_ZONEORDER
#define MAX_ORDER 11
#else
#define MAX_ORDER CONFIG_FORCE_MAX_ZONEORDER
#endif
#define MAX_ORDER_NR_PAGES (1 << (MAX_ORDER - 1))
struct free_area {
struct list_head free_list[MIGRATE_TYPES];//空闲块双向链表
unsigned long nr_free;//空闲块的数目
};
struct zone{
....
struct free_area free_area[MAX_ORDER];
....
};
zone从上到下的每一个元素的类型为free_area,free_area内部都是都保存一个free_list链表,
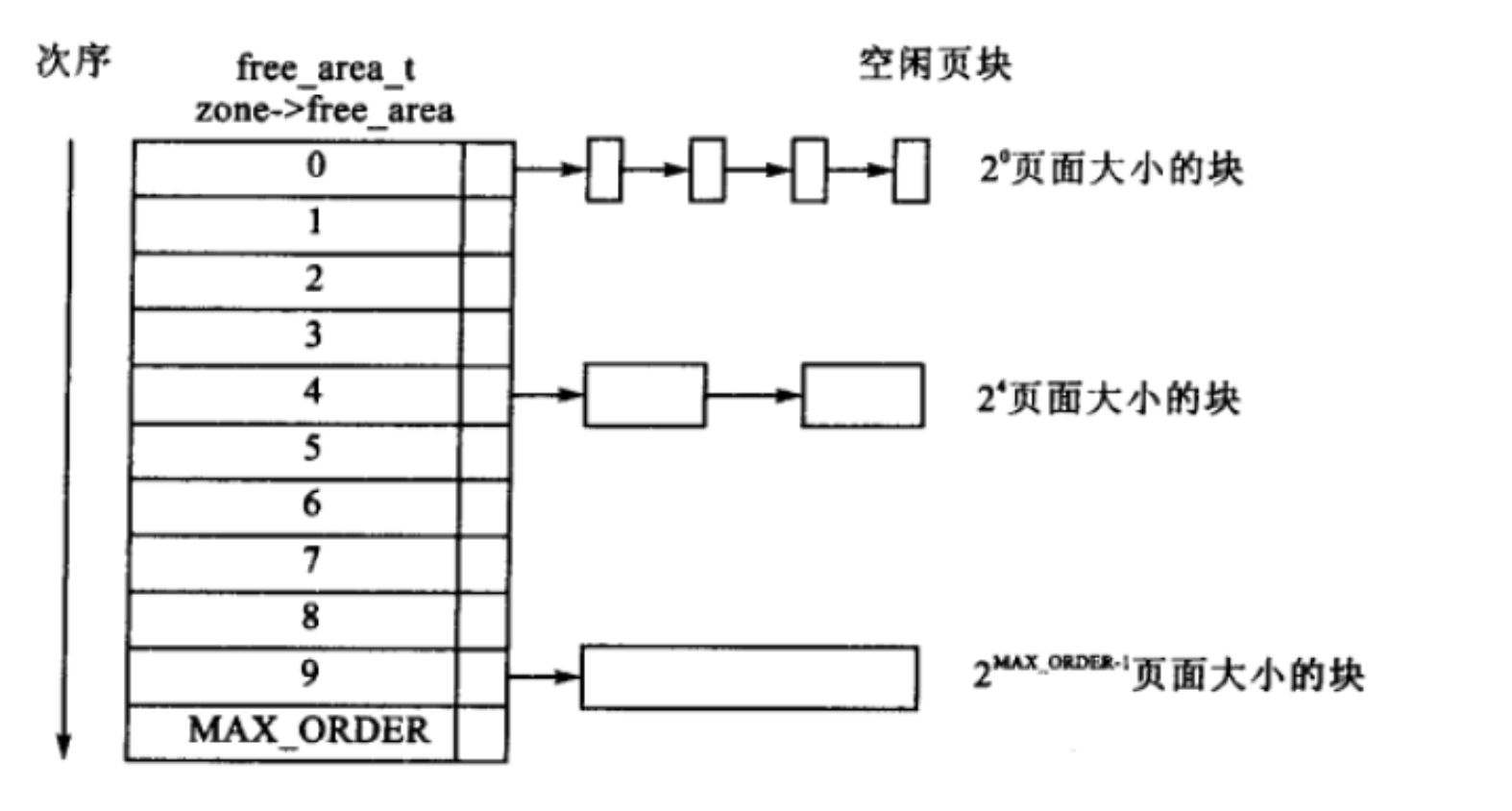
struct free_area free_area[MAX_ORDER] #MAX_ORDER 默认值为11,分别存放着11个组
free_area数组中第K个free_area元素,它标识所有大小为2^k的空闲块,所有空闲快由free_list指向的双向循环链表组织起来。
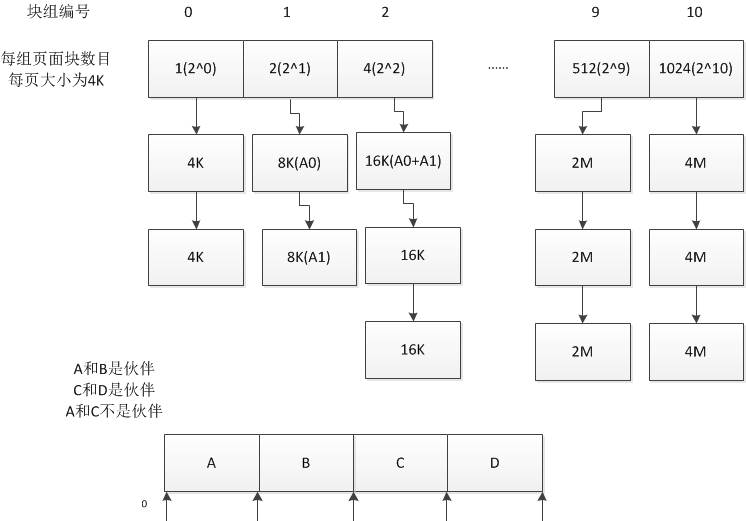
换一个角度的图
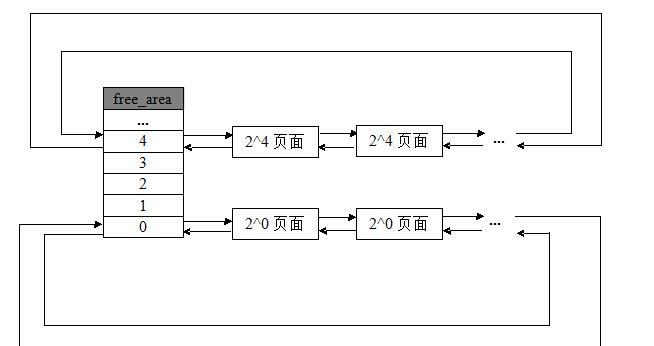
伙伴算法每次只能分配2的幂次个页框的空间,每页大小通常为4K
例如:一次分配1页,2页,4页,8页,…,1024页(2^10)等等,所以,伙伴算法最多一次可以分配4M(1024*4K)的内存空间
MAX_ORDER默认值为11,分别存放着11个组,free_area结构体里面又标注了该组别空闲内存块的情况。
zone的成员:nr_free和zone_mem_map数组
其中的nr_free,它指定了对应空间剩余块的个数。
zone的 zone_mem_map数组
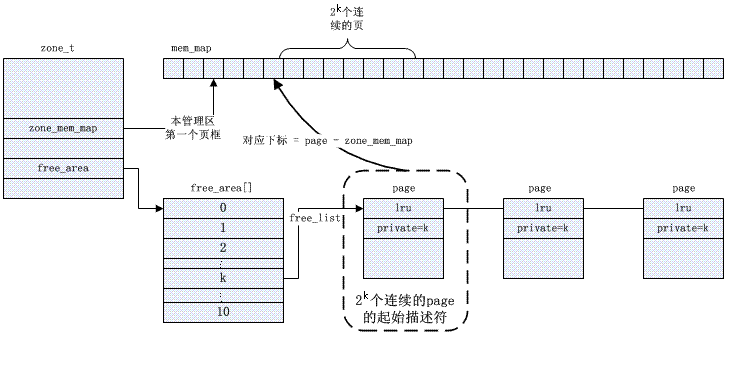
伙伴位图mem_map
伙伴关系: 两个内存块,大小相同,地址连续,同属于一个大块区域。(第0块和第1块是伙伴,第2块和第3块是伙伴,但第1块和第2块不是伙伴)
伙伴位图:用一位描述伙伴块的状态位码,称之为伙伴位码。
伙伴位码:用一位描述伙伴块的状态位码,称之为伙伴位码。
比如,bit0为第0块和第1块的伙伴位码,若是bit0为1,表示这两块至少有一块已经分配出去,若是bit0为0,说明两块都空闲或者两块都被使用。如果bit0为1,表示这两块至少有一块已经分配出去,如果bit0为0,说明两块都空闲,还没分配。
整个过程当中,位图扮演了重要的角色
Linux内核伙伴算法中每一个order 的位图都表示全部的空闲块,位图的某位对应于两个伙伴块,
为1就表示其中一块忙,为0表示两块都闲或都在使用。
系统每次分配和回收伙伴块时都要对它们的伙伴位跟1进行异或运算。
所谓异或是指刚开始时,两个伙伴块都空闲,它们的伙伴位为0:
-
若是其中一块被使用,异或后得1;
-
若是另外一块也被使用,异或后得0;
-
若是前面一块回收了异或后得1;
-
若是另外一块也回收了异或后得0。
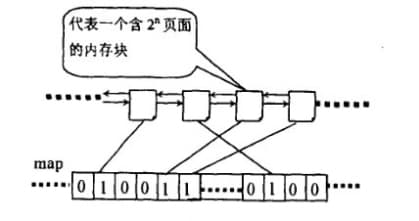
如图所示,位图的某一位对应两个互为伙伴的块,为1表示其中一块已经分配出去了,为0表示两块都空闲或都已被使用。
伙伴中不管是分配/还是释放,都只是相对的位图进行异或操做。
分配内存时对位图的是为释放过程服务,释放过程根据位图判断伙伴是否存在:
-
若是对相应位的异或操做,得1,说明之前为0,两块都是busy,没有伙伴能够合并,
-
若是异或操做得0,说明之前是1,说明只有一块是busy,一块是 idle(/free),busy的是自己,就进行合并
并且,继续按这种方式合并伙伴,直到不能合并为止。
位图的主要用途是在回收算法中指示是否能够和伙伴块合并,分配时只要搜索空闲链表就足够了。但是,分配的同时还要对相应位异或一下,这是为回收算法服务。
Buddy算法的分配原理:
假如系统需要4(2^2)个页面大小的内存块,该算法就到free_area[2]中查找,
如果free_area[2]链表中有空闲块,就直接从中摘下并分配出去。
如果没有,算法将顺着数组向上查找free_area[3], 如果free_area[3]中有空闲块,则将其从链表中摘下,分成等大小的两部分,前四个页面作为一个块插入free_area[2],后一部分4个页面分配出去
free_area[3]中也没有,就再向上查找,如果free_area[4]中有,就将这16(2^4)个页面等分成两份,前一半挂到free_area[3]的链表头部,后一半的8个页等分成两等分,前一半挂free_area[2]的链表中,后一半分配出去。
假如free_area[4]也没有,则重复上面的过程,直到到达free_area数组的最后,如果还没有则放弃分配。
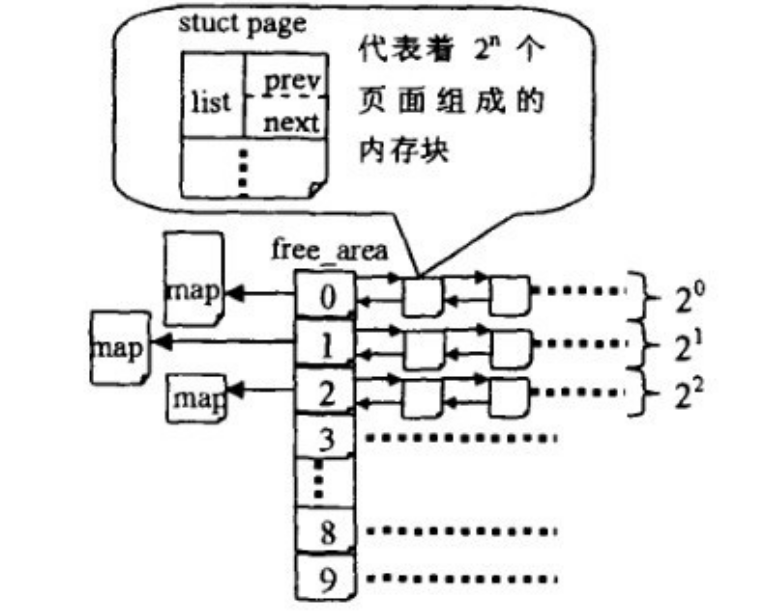
Buddy算法分配的例子
假设在初始阶段,全是大小为2^9大小的块( MAX_ORDER为10),序号依次为0, 512, 1024等等,而且全部area的map位都为0(实际上操做系统代码要占一部分空间,但这里只是举例),
如今要分配一个2^3大小的页面块,有如下动做:
- 从order为3的area的空闲链表开始搜索,没找到就向高一级area搜索,依次类推,按照假设条件,会一直搜索到order为9的area,找到了序号为0的
2^9页块。 - 把序号为0的
2^9页块从order为9的area的空闲链表中摘除, 并对该area的 mem_map第0位( 0 >>(1+9) )异或一下得1。
说明:
把序号为n的页面块插入order为i的area时,需要对该area的map位(n>>(1+order))跟1异或,更新map值
所以,这里对area的map第0(序号右移(1+order)的结果)位跟1异或一
- 把序号为0的
2^9页块拆分成两个序号分别为0和256的2^8页块,前者放入order为8的area的空闲链表中,并对该area的第0位( 0>>(1+8) )异或一下得1。
说明:
拆分后两个快,第一个的偏移量还是0,第二个伙伴的偏移量序号为 2^8 ,=256
- 把序号为256的
2^8页块拆分成两个序号分别为256和384的2^7页块,前者放入order为7的area的空闲链表中,并对该area的第1位( 256>>(1+7) )异或一下得1。
说明:
拆分后两个快,第一个的偏移量还是256,第二个伙伴的偏移量为256 +
2^7(第二个偏移量128) =384
- 把序号为384的
2^7页块拆分成两个序号分别为384和448的2^6页块,前者放入order为6的area的空闲链表中,并对该area的第3位( 384>>(1+6) )异或一下得1。 - 把序号为448的
2^6页块拆分成两个序号分别为448和480的2^5页块,前者放入order为5的area的空闲链表中,并对该area的第7位( 448>>(1+5) )异或一下得1。 - 把序号为480的
2^5页块拆分成两个序号分别为480和496的2^4页块,前者放入order为4的area的空闲链表中,并对该area的第15位( 480>>(1+4) )异或一下得1。 - 把序号为496的
2^4页块拆分成两个序号分别为496和504的2^3页块,前者放入order为3的area的空闲链表中,并对该area的第31位( 496>>(1+3) )异或一下得1。 - 序号为504的
2^3页块就是所求的块。
把序号为n的页面块插入order为i的area时,须要对该area的map位(n>>(1+order))跟1异或,更新map值
Buddy算法的释放原理:
内存的释放是分配的逆过程,也可以看作是伙伴的合并过程。
当释放一个块时,先在其对应的链表中考查是否有伙伴存在,如果没有伙伴块,就直接把要释放的块挂入链表头;
如果有,则从链表中摘下伙伴,合并成一个大块,然后继续考察合并后的块在更大一级链表中是否有伙伴存在,直到不能合并或者已经合并到了最大的块。
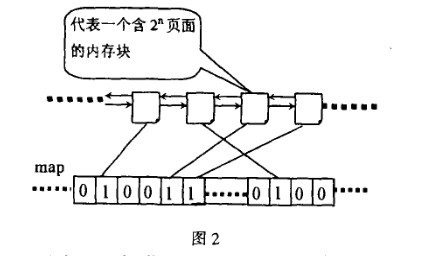
整个过程中,位图扮演了重要的角色,如图2所示,位图的某一位对应两个互为伙伴的块,为1表示其中一块已经分配出去了,为0表示两块都空闲。
伙伴中无论是分配还是释放都只是相对的位图进行异或操作。
分配内存时对位图的是为释放过程服务,释放过程根据位图判断伙伴是否存在,如果对相应位的异或操作得1,则没有伙伴可以合并,如果异或操作得0,就进行合并,并且继续按这种方式合并伙伴,直到不能合并为止。
Buddy算法回收的例子
map下标 如何计算:页块的序号>>(1+order)
回收的页面块假设序号为n,页面的规模为order,在map的第i位,i= n>>(1+order)
假设序号为4,order规模为0,在map的第2位,因为 4>>1+0= 2
假设序号为5,order规模为0,在map的第2位,因为 5>>1+0= 2
回收的页面块假设序号为n,回收时,取得map中的的该area中的map[n>>(1+order)],将该map值跟1异或,若结果为0(大家都idle),则序号n的页面块可跟其伙伴块合并,不然不能合并。
回收的页块若能与伙伴块合并,插入上一级的area中,则视合并块为之前已被占用,
然后根据该area中其伙伴块的状态(已被回收或者被占用)判断其map位是1(伙伴忙,自己咸)还是0(伙伴忙,自己忙),再让map位跟1异或一下,结果为0则再合并,结果为1则不再合并。
假设回收序号为4,order规模为0的内存块:
1.当回收序号为4的1页块时,先找到order为0(规模最小)的area,把该页面块加入到该area的空闲链表中,
而后判断其伙伴块(序号为5的页块)的状态,读该area的map的第2(下标为2 序号右移1+order的结果)位( 4>>(1+order) ),
假设伙伴块被占,则该位为0(回收4块前,四、5块都忙),现跟1异或一下得1,并再也不向上合并。
2.当回收序号为5的1页块时,同理,先找到order为0的area,把该页面块加入到该area的空闲链表中,而后判断其伙伴块(序号为4的1页块)的状态,
读该area的map的第2位(5>>(1+order) ),这时该位为1(回收4块前,四忙、5不忙),现跟1异或一下得0,并向上合并,
把序号为4的1页块和序号为5的1页块从该area的空闲链表中摘除,合并成序号为4的2页块,并放到order为1的area的空闲链表中。
同理,此时又要判断合并后的块的伙伴块(序号为6的2页块)的状态,读该area(order为1的area,不是其它!)的map的第1位((4>>(1+order) ),
假设伙伴块在此以前已被回收,则该位为1,现异或一下得0,并向上合并,把序号为4的2页块和序号为6的2页块从order为1的area的空闲链表中摘除,合并成序号为4的4页块,并放到order为2的area的空闲链表中。
而后再判断其伙伴块状态,如此反复。
伙伴(buddy)算法的问题
伙伴算法管理的是原始内存,比如最原始的物理内存(Java中的堆外),或者说一大块连续的 堆内存。
申请时,伙伴算法会给程序分配一个较大的内存空间,即保证所有大块内存都能得到满足。
很明显分配比需求还大的内存空间,会产生内部碎片。
所以伙伴算法虽然能够完全避免外部碎片的产生,但这恰恰是以产生内部碎片为代价的。
缺点:
虽然伙伴算法有效减少了外部碎片,但最小粒度还是 page(4K),因此有可能造成非常严重的内部碎片,最严重带来 50% 的内存碎片。
Slab 算法
伙伴 算法 在小内存场景下并不适用,因为每次都会分配一个 page,导致非常严重的内部碎片。
而 Slab 算法 则是在 伙伴算法 的基础上对小内存分配场景做了专门的优化:
提供调整缓存机制 存储内核对象,当内核需要再次分配内存时,基本上可以通过缓存中获取。
Linux 底层采用 Slab 算法 进行小内存分配。
Linux采用伙伴系统解决外部碎片的问题,采用slab解决内部碎片的问题。
slab 分配器的基本原理:
按照预定固定的大小,将分配的内存分割成特定长度的块,以完全解决内存碎片问题。
具体来说:
slab 分配器将分配的内存分割成各种尺寸的块,并把相同尺寸的块分成组。
另外分配到的内存用完之后,不会释放,而是返回到对应的组,重复利用。

强调: Linux采用伙伴系统解决外部碎片的问题,采用slab解决内部碎片的问题。
jemalloc 算法
jemalloc 是基于 buddy+Slab 而来,比buddy+ Slab 更加复杂。
Slab 提升小内存分配场景下的速度和效率,jemalloc 通过 Arena 和 Thread Cache 在多线程场景下也有出色的内存分配效率。
Arena 是分而治之思想的体现,与其让一个人管理全部内存,到不如将任务派发给多个人,每个人独立管理,互不干涉(线程竞争)。
Thread Cache 是 tcmalloc 的核心思想,jemalloc 也把它借鉴过来。
通过Thread Cache机制, 每个线程有自己的内存管理器,分配在这个线程内完成,就不需要和其他线程竞争。
相关文档
- Facebook Engineering post: This article was written in 2011 and corresponds to jemalloc 2.1.0.
- jemalloc(3) manual page: The manual page for the latest release fully describes the API and options supported by jemalloc, and includes a brief summary of its internals.
Netty 底层的内存分配是采用 jemalloc 算法思想。
Netty内存规格
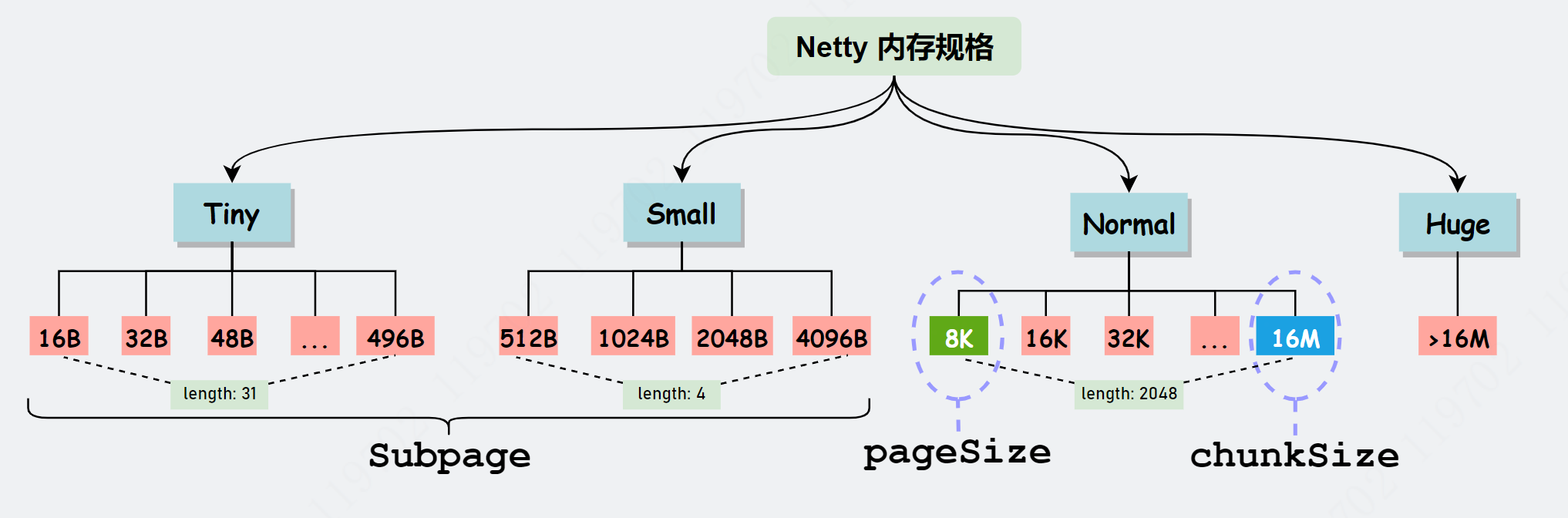
Netty 对内存大小划分为:Tiny、Small、Normal 和 Huge 四类。
Huge 类型
Netty 默认向操作系统申请的内存大小为 16MB,对于大于 16MB 的内存定义为 Huge 类型,
Netty 对 Huge 类型的处理方式为:
大型内存不做缓存、不做池化,直接以 Unpool 的形式分配内存,用完后回收。
Tiny、Small、Normal类型
对于 16MB 及更小的内存,分类为:Tiny、Small、Normal,也有对应的枚举 SizeClass 进行描述。
// io.netty.buffer.PoolArena.SizeClass
enum SizeClass {
Tiny,
Small,
Normal
}
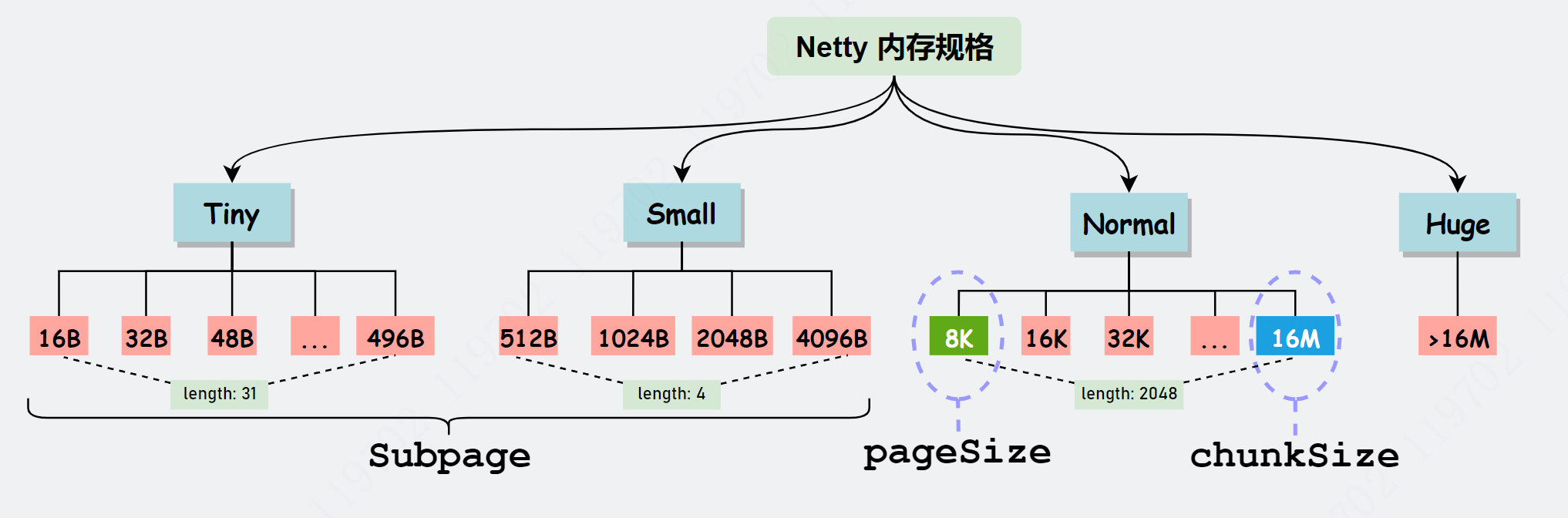
不过 Netty 定义了一套更细粒度的内存分配单位:Chunk、Page、Subpage,方便内存的管理。
注意:为了方便管理, Netty 在每个区域内又定义了更细粒度的内存分配单位,分别是 Chunk、Page 和 Subpage。
Chunk
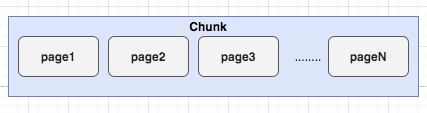
Chunk 即上述提及的 Netty 向操作系统申请内存的单位,默认是 16MB。后续所有的内存分配也都是基于 Chunk 完成。
Chunk 是 Page 的集合。
一个 Chunk(16MB),由 2048 个 Page (8KB)组成。
netty 内存向系统或者JVM堆申请是大块的内存,单位是chunk块, 不是一点一点申请,而是一大块一大块的申请,然后再内部高效率的二次分配
一个chunk 的大小是16MB, 实际上每个chunk, 都以双向链表的形式保存在一个chunkList 中,
而多个chunkList, 同样也是双向链表进行关联的, 大概结构如下所示:
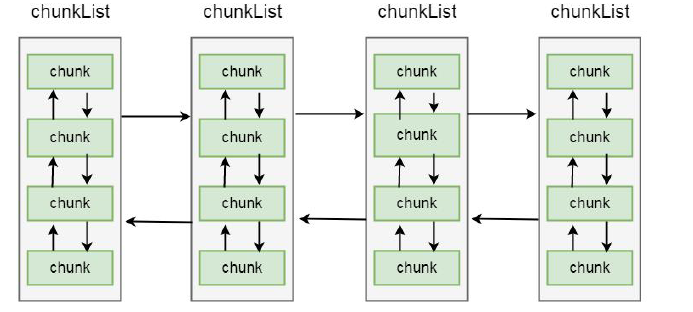
这样, 在内存分配时, chunkList 中, 是根据chunk 的内存使用率归到一个chunkList 中,
会根据百分比找到相应的chunkList, 在chunkList 中选择一个chunk 进行内存分配。
Page
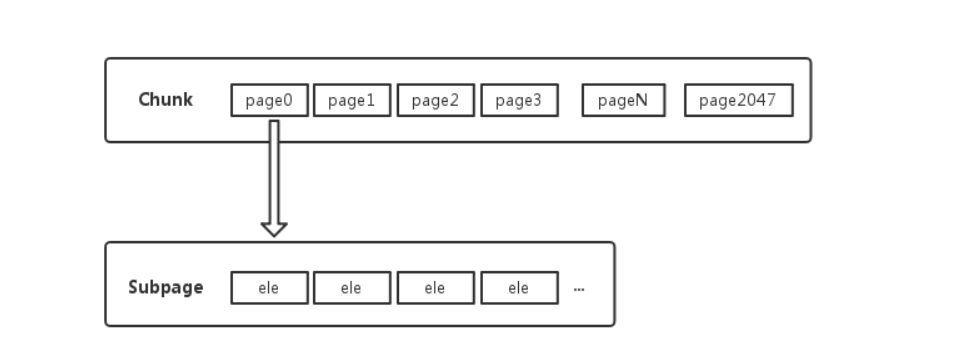
Page 是 Chunk 用于管理内存的基本单位。
Page 的默认大小为 8KB,若欲申请 16KB,则需申请连续的两块空闲 Page。

SubPage
很多场景下, 为缓冲区分配8KB 的内存也是一种浪费, 比如只需要分配2KB 的缓冲区, 如果使用8KB 会造成6KB 的浪费,
这种情况, netty 又会将page 切分成多个subpage,
SubPage 是 Page 下的管理单位。
每个subpage 大小要根据分配的缓冲区大小而指定, 比如要分配2KB 的内存, 就会将一个page 切分成4 个subpage, 每个subpage 的大小为2KB, 如下图:

对于底层应用,KB 级的内存已属于大内存的范畴,更多的是 B 级的小内存,直接使用Page 进行内存的分配,无疑是非常浪费的。
所以对 Page 进行了切割划分,划分后的便是 SubPage,Tiny 和 Small 类型的内存使用的分配单位都是 SubPage。
切割划分的算法原则是:
如首次申请 512 B 的内存,则先申请一块 Page 内存,然后将 8 KB 的 Page 按照 512B 均分为 16 块,每一块可以认为是一个 SubPage,然后将第一块 SubPage 内存地址返回给申请方。
同时下一次申请 512B 内存,则在 16 块中分配第二块。
其他非 512B 的内存申请,则另外申请一个 Page 进行均等切分和分配。
所以,对于 SubPage 没有固定的大小,和 Tiny、Small 中某个具体大小的内存申请有关。
问题:为什么只有上面穷举出来的内存大小,没有19B、21B、3KB这样规格?
是因为 netty 中会把申请内存大小进行了标准化,向上取整到最接近的上图中所列举出的大小,以便于管理。
内存规格化
Netty 需要对用户申请的内存大小进行 规格化 处理,目的是方便后续计算和内存分配。
通过内存规格化,将 31B 规格化为 32B,将 15MB 规格化 16MB。
Netty 和内存规格化涉及三个核心算法:
- 一是找到离分配内存最近且大于分配内存的 2 值。获取最接近 2^n 的数
- 二是找到离分配内存最近且大于分配内存的16 倍的值。
- 三是通过掩码判断是否大于某个数。
获取最接近 2^n 的数(非常重要的算法)
对于small和normal ,规格化成获取最接近 2^n 的数,便于计算和管理。
注意:Netty 通过大量的位运算来提升性能,但代码的可读性不太好。
下面的算法,获取最接近 2^n 的数(非常重要的算法),jvm源码里边都用到了。



上面一连串的位移计算,看得眼花缭乱。
这个算法的核心:是找到最接近 2的幂 且 大于用户申请规模的值。这个算法很重要,很多核心源码用到。
这个算法的思路: 把二进制 0100 0000 0001(1025) 变成 0111 1111 1111 +1 (2048)。
记初始值为 i,原始值的二进制最高位为 1 的序号记为 n,具体执行过程描述如下:
-
先执行 i-1 操作,目的是解决当值为 2时也能得到本身,而非 2。
-
再执行 i |= i>>>1 运算,目的是赋值第 n-1 位的值为 1。
假设为1的最高位n,也就是第 n 位位置确定为 1,那么无符号右移一位后第 n-1 也为 1。
再与原值进行 | 运算后更新第 n-1 的值。
此时,原值的第 n、n-1 都确定为 1,那么接下来就可以无符号右移两倍,让n-2、n-3 赋值为 1。
由于 int 类型有 32 位,所以只需要进行 5 次运算,每次分别无符号右移1、2、4、8、16 就可让小于 i 的所有位都赋值为 1。
测试用例:获取最接近 2^n 的数
由于源码可读性太差,代码的可读性不太好。特意写了用例




完整演示与介绍,请参考40岁老架构师尼恩的视频:《彻底穿透netty架构与源码》
获取最近的下一个16的倍数值
对于tiny类型,规格化其实思路很简单:
先把低四位的值抹去(变成0),再加上
16就得到了目标值。

测试用例执行结果

完整演示与介绍,请参考40岁老架构师尼恩的视频:《彻底穿透netty架构与源码》
Netty 内存池分配整体思路
设计思路
Netty采用了jemalloc的思想,这是FreeBSD实现的一种并发malloc的算法。
jemalloc依赖多个Arena来分配内存,运行中的应用都有固定数量的多个Arena,默认的数量与处理器的个数有关。
系统中有多个Arena的原因是由于各个线程进行内存分配时竞争不可避免,这可能会极大的影响内存分配的效率,为了缓解高并发时的线程竞争,Netty允许使用者创建多个分配器(Arena)来分离锁,提高内存分配效率。
线程首次分配/回收内存时,首先会为其分配一个固定的Arena。
线程选择Arena时使用round-robin的方式,也就是顺序轮流选取。
每个线程各种保存Arena和缓存池信息,这样可以减少竞争并提高访问效率。
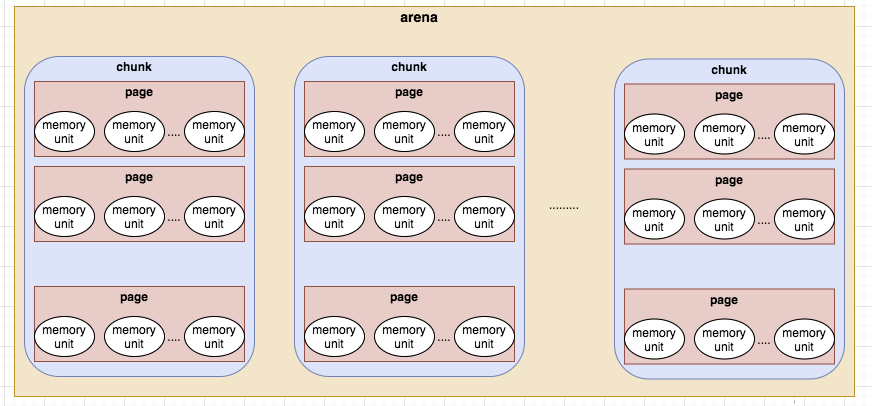
Arena将内存分为很多Chunk进行管理,Chunk内部保存Page,以页为单位申请。
下图展示了netty基于jemalloc实现的内存划分逻辑
内存池结构
Netty中将内存池分为五种不同的形态从大到小依次是:
-
PoolArena,
-
PoolChunkList,
-
PoolChunk,
-
PoolPage,
-
PoolSubPage.
首先,Netty 会向 操作系统 申请一整块 连续内存,称为 chunk(数据块),除非申请 Huge 级别大小的内存,
否则一般大小为 16MB,使用 io.netty.buffer.PoolChunk 对象包装。
具体长这样子:
Netty将chunk进一步拆分为多个page,每个 page 默认大小为 8KB,
因此每个 chunk 包含 2048 个 page。为了对小内存进行精细化管理,减少内存碎片,提高内存使用率,
Netty 对 page 进一步拆分若干 subpage,subpage 的大小是动态变化的,最小为 16Byte。
- 计算: 当请求内存分配时,将所需要内存大小进行内存规格化,获得规格化的内存请求值。根据值确认准确的树的高度。
- 搜索: 在内存映射数据中,进行空闲内存序列的搜索。
- 标记: 分组被标记为全部已使用,且通过循环更新其父节点标记信息。父节点的标记值取两个子节点标记值的最小的一个。
当然,上面说的只是整体思路。还要分类型进行细化。

Huge 分配逻辑概述
Normal 级别分配的大小范围是 [16M, 无限大) 。
大内存分配比其他类型的内存分配稍微简单一点,操作的内存单元是 PoolChunk,它的容量大小是用户申请的容量(可满足内存对齐要求)。
Netty 对 Huge 对象的内存块采用非池化管理策略,在每次请求分配内存时单独创建特殊的非池化 PoolChunk 对象,当对象内存释放时整个 PoolChunk 内存也会被释放。
大内存的分配逻辑是在 io.netty.buffer.PoolArena#allocateHuge 完成。
Normal 分配逻辑
Normal 级别分配的大小范围是 [4097B, 16M) 。
核心思想是将 PoolChunk 拆分成 2048 个 page ,这是 Normal 分配的最小单位。
每个 page 等大(pageSize=8KB),并在逻辑上通过一棵满二叉树管理这些 page 对象。
我们申请的内存本质是组合若干个 page 。Normal 的分配核心逻辑是在 PoolChunk#allocateRun(int) 完成。
Small 分配逻辑
Small 级别分配的大小范围是 (496B, 4096B] 。
核心是把一个 page 拆分若干个 Subpage,PoolSubpage 就是这些若干个 Subpage 的化身,有效解决小内存场景造成内存碎片的问题。
一个 page 大小为 8192B,有且只有四种大小: 512B、1024B、2048B 和 4096B,以 2 倍递增。
当申请的内存大小在 496B~4096B 范围内时,就能确定这四种中的一种。
当进行内存分配时,先在树的最底层找到一个空闲的 page,拆分成若干个 subpage,并构造一个 PoolSubpage 进行管理。
选择第一个 subpage 用于此次申请,标记为已使用,并将 PoolSubpage 放置在 PoolSubpage[] smallSubpagePools 数组所对应的链表中。
等下次申请等大容量内存时就可从 PoolSubpage[] 直接分配从链表中分配内存。
Tiny 分配逻辑
Tiny 级别分配的大小范围是 (0B, 496B] 。
分配逻辑与 Small 类似,
先找到空闲的 Page 然后将其拆分若干个 Subpage 并构造一个 PoolSubpage 对它们进行管理。
随后选择第一个 subpage 用于此次申请,并将对象 PoolSubpage 放置在 PoolSubpage[] tinySubpagePools 数组所对应的链表中。等待下次分配时使用。
区别在于如何定义若干个?
Tiny 给出的定义逻辑是获取最接近 16*N 的且大于规格值的大小。
比如申请内存大小为 31B,找到最接近的下一个 16*1 的倍数且大于 31 的值是 32,
因此,就把 Page 拆分成 8192/32=256 个 subpage,这里的若干个就是根据规格值确定的,它是可变的值。
PoolArena
上面讲述了针对不同级别 Netty 是如何完成内存分配的。
arena是jemalloc中的概念,它是一个内存管理单元,线程在arena中去分配和释放内存,
PoolArena的高并发设计
为了减少线程成间的竞争,很自然会提供多个PoolArena。
和G1垃圾回收器、Redis分段锁一样,这里用了分治模式,
系统正常会存在多个arena,每个线程会被绑定一个arena,PoolArena是线程共享的对象,每个线程只会绑定一个 PoolArena,线程和 PoolArena 是多对一的关系。
同一个arena可以被多个线程共享,arena和thread之间的关系如下图
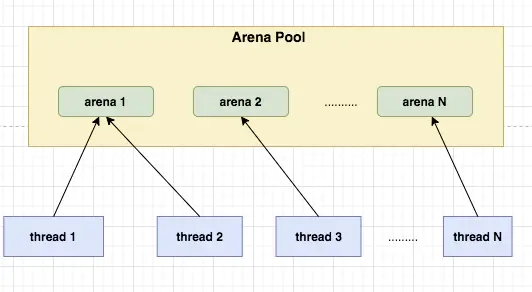
PoolArena 是进行池化内存分配的核心类,采用固定数量的多个 Arena 进行内存分配,默认与 CPU 核心数量有关,
当某个线程首次申请内存分配时,会通过轮询(Round-Robin) 方式得到一个 PoolArena,在该线程的整个生命周期内只和这个 Arena 打交道,
PoolArena 是分治思想的体现,其目标是,解决在多线程场景下的高并发问题。
PoolArena的核心成员
PoolArena 提供 DirectArena 和 HeapArena 子类,这是因为底层容器类型不同所以需要子类区分。但核心逻辑是在 PoolArena 完成的。
PoolArena 的数据结构大致(除去监测指标数据)可分为两大类:
-
存储 PoolChunk 的 6 个 PoolChunkList
-
存储 PoolSubpage 的 2 个数组。
PoolArena 构造器初始化也做了很多重要的工作,包含串联 PoolChunkList 以及初始化 PoolSubpage[] 。
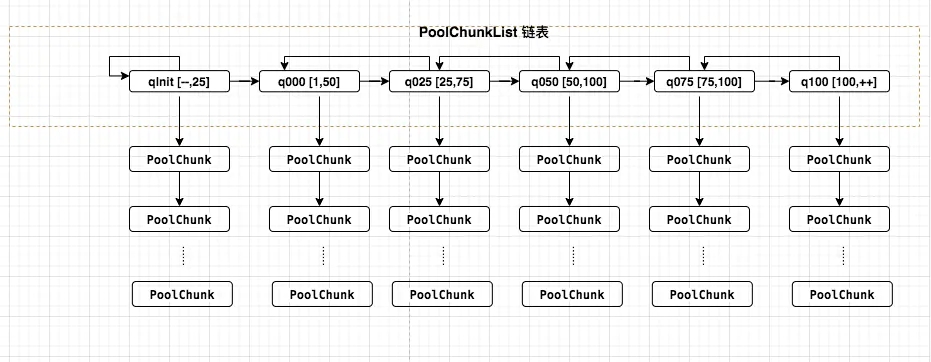
存储 PoolChunk 的 6 个 PoolChunkList
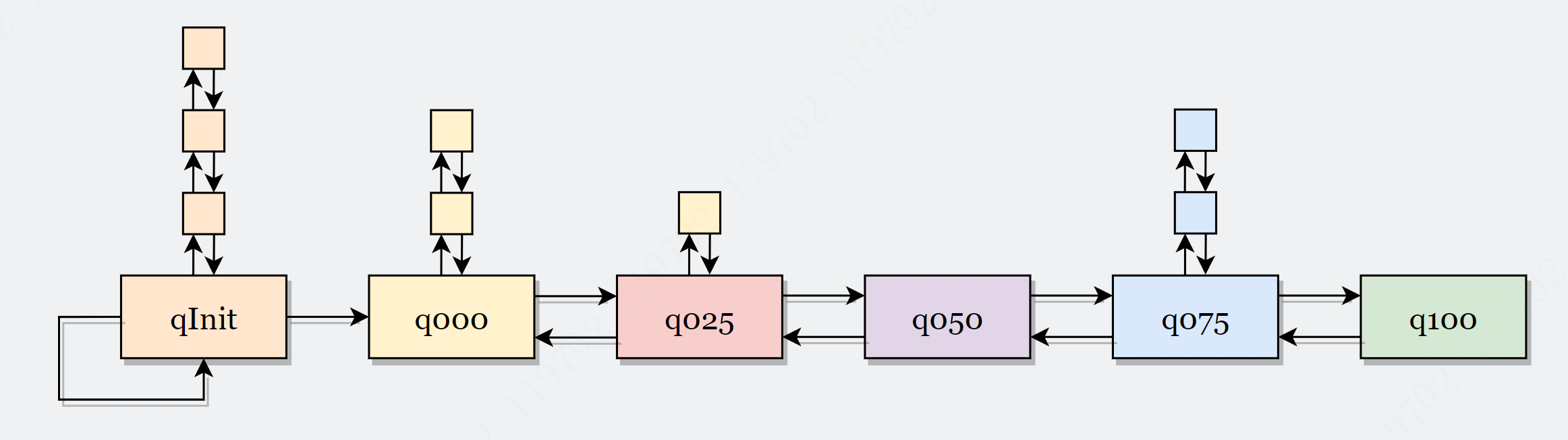
q000、q025、q050、q075、q100 表示最低内存使用率。如下图所示
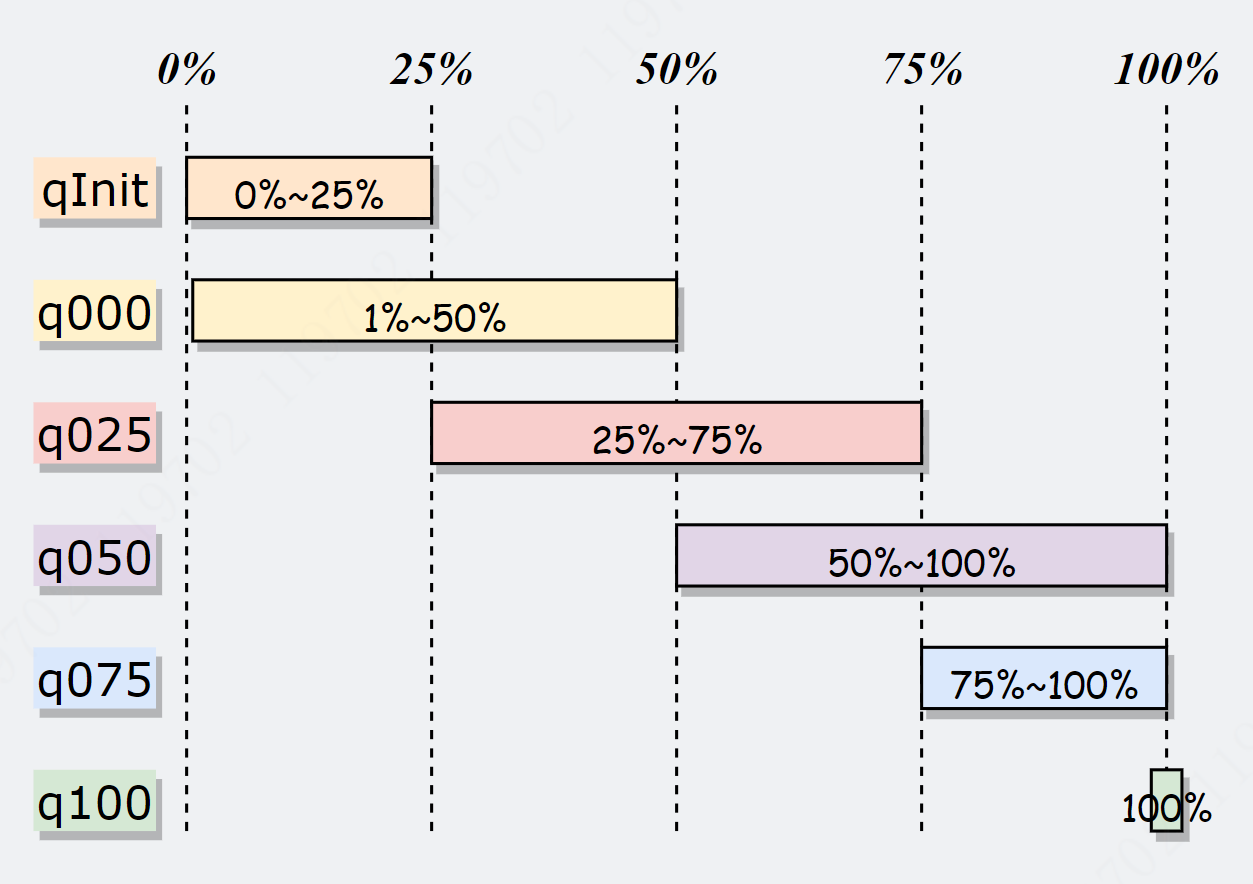
任意 PoolChunkList 都有内存使用率的上下限:
-
minUsag
-
maxUsage。
如果使用率超过 maxUsage,那么 PoolChunk 会从当前 PoolChunkList 移除,并移动到下一个PoolChunkList 。
同理,如果使用率小于 minUsage,那么 PoolChunk 会从当前 PoolChunkList 移除,并移动到前一个PoolChunkList。
每个 PoolChunkList 的上下限都有交叉重叠的部分,为什么呢?
因为 PoolChunk 需要在 PoolChunkList 不断移动,如果临界值恰好衔接的,则会导致 PoolChunk 在两个 PoolChunkList 不断移动,造成性能损耗。
PoolChunkList 适用于 Chunk 场景下的内存分配,PoolArena 初始化 6 个 PoolChunkList 并按上图首尾相连,形成双向链表,但是, q000 这个 PoolChunkList 是没有前向节点
q000 这个 PoolChunkList 是没有前向节点,为什么呢?
因为当其余 PoolChunkList 没有合适的 PoolChunk 可以分配内存时,会创建一个新的 PoolChunk 放入 pInit 中,然后根据用户申请内存大小分配内存。
而在 p000 中的 PoolChunk ,如果因为内存归还的原因,使用率下降到 0%,则不需要放入 pInit,而是直接执行销毁方法,将整个内存块的内存释放掉。
这样,内存池中的内存就有生成/销毁等完成生命周期流程,避免了在没有使用情况下还占用内存。
存储 PoolSubpage 的 2 个数组
PoolSubpage 是对某一个 page 的化身,page毕竟太粗,
如果申请1Byte的空间就分配一个页是不是太浪费空间,对,这确实很浪费,
在Netty中Page还会被细化为subpage,
用于专门处理小于8k的空间申请,那是subpage。
于是, Page 还可以按 elemSize 拆分成若干个 subpage,
在 PoolArena 使用 PoolSubpage[] 数组来存储 PoolSubpage 对象,
两个PoolSubpage[] 数组如下图所示:
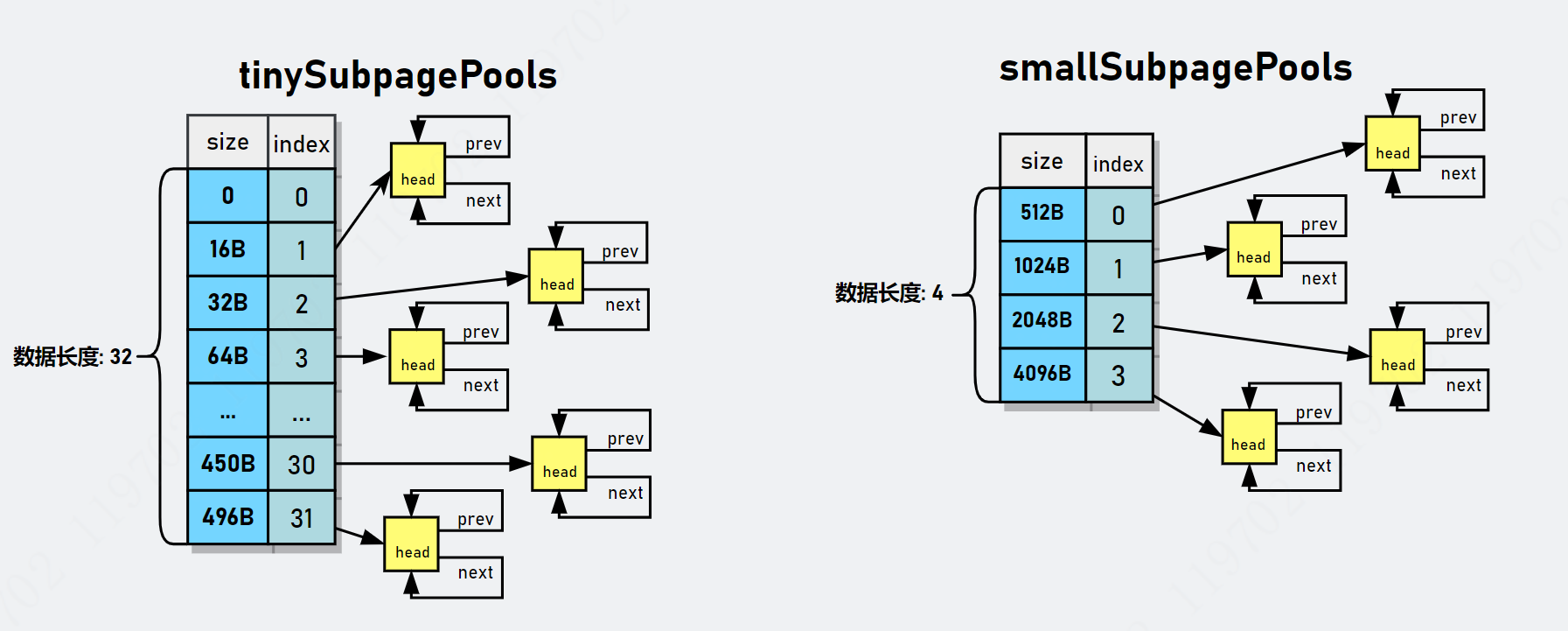
smallSupbagePools 数组
对于 Small类型的subpage, 它拥有四种不同大小的规格,因此 smallSupbagePools 的数组长度为 4,
smallSubpagePools[0] 表示 elemSize=512B 的 PoolSubpage 对象的链表,
smallSubpagePols[1] 表示 elemSize=1024B 的 PoolSubpages 对象的链表。
smallSubpagePols[2] 表示 elemSize=2048B 的 PoolSubpages 对象的链表。
smallSubpagePols[3] 表示 elemSize=4096B 的 PoolSubpages 对象的链表。
tinySubpagePools 数组
tinySubpagePools 原理一样,只不过划分的粒度(步长)比较小,
tinySubpagePools 数组的元素划分,不是以2的幂的步长划分的,而是以倍数来的,以 16 的倍数递增。
从16B-496B,总共可分为 32 类,因此 tinySubpagePools 数组长度为 32。
PoolSubpage[] 数组与HashMap的对比
这两个PoolSubpage[] 数组用来存储 PoolSubpage 对象且按 PoolSubpage#elemSize 确定索引的位置 index,最后将它们构造双向链表。
每个PoolSubpage[] 数组都对应一组双向链表。
每个PoolSubpage[] 数组下标所对应的 size 容量不一样,按 PoolSubpage#elemSize 确定索引的位置 index
PoolSubpage数组的结构,非常类似于一个简单的HashMap,简单的HashMap集合的三个基本存储概念
| 名称 | 说明 |
|---|---|
| table | 存储所有节点数据的数组 |
| slot | 哈希槽。即table[i]这个位置 |
| bucket | 哈希桶。table[i]上所有元素形成的表或数的集合 |
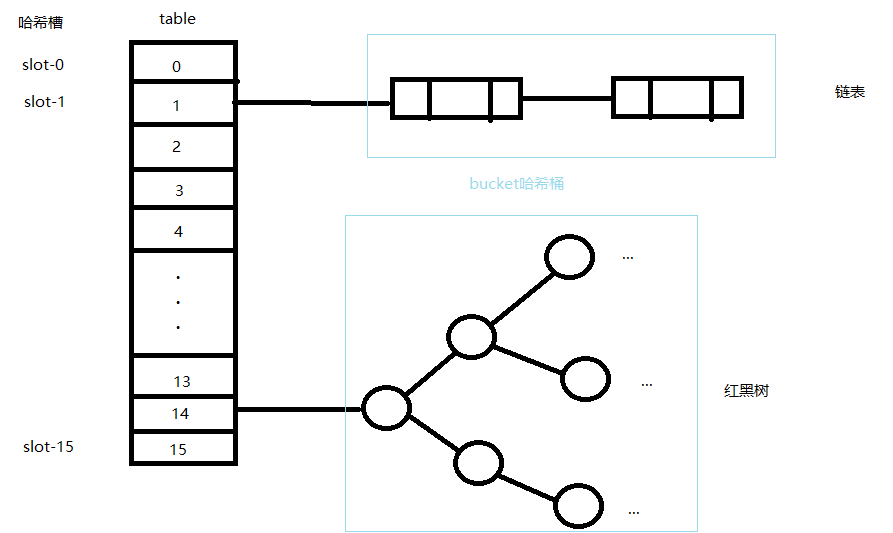
PoolSubpage#elemSize 可以理解为hashmap的key,这是这里不进行hash运算,而是根据elemSize 的规模去确定 slot 槽位
PoolSubpage[] 的一个元素PoolSubpage,可以理解为hashmap的bucket,这是这里不链表,而是双向链表
PoolArena的具体实现
PoolArena是功能的门面,通过PoolArena提供接口供上层使用,屏蔽底层实现细节。
Netty默认会生成2×CPU个PoolArena跟IO线程数一致。
然后第一次使用的时候会找一个使用线程最少的PoolArena
private <T> PoolArena<T> leastUsedArena(PoolArena<T>[] arenas) {
if (arenas == null || arenas.length == 0) {
return null;
}
PoolArena<T> minArena = arenas[0];
for (int i = 1; i < arenas.length; i++) {
PoolArena<T> arena = arenas[i];
if (arena.numThreadCaches.get() < minArena.numThreadCaches.get()) {
minArena = arena;
}
}
return minArena;
}
现在我们看下PoolArena的属性,比较多,
//maxOrder默认是11
private final int maxOrder;
//内存页的大小,默认是8k
final int pageSize;
//默认是13,表示的是8192等于2的13次方
final int pageShifts;
// 默认是16M
final int chunkSize;
//这个等于~(pageSize-1),用于判断申请的内存是不是大于或者等于一个page
//申请内存reqCapacity&subpageOverflowMask如果等于0那么表示申请的内
//存小于一个page的大小,如果不等于0那么表示申请的内存大于或者一个page的大小
final int subpageOverflowMask;
//它等于pageShift - 9,默认等4
final int numSmallSubpagePools;
final int directMemoryCacheAlignment;
final int directMemoryCacheAlignmentMask;
//tiny类型内存PoolSubpage数组,数组长度是32,从index=1开始使用
private final PoolSubpage<T>[] tinySubpagePools;
//small类型内存PoolSubpage数组,数组长度在默认情况下是4
private final PoolSubpage<T>[] smallSubpagePools;
//PoolChunkList代表链表中的节点,
//每个PoolChunkList存放内存使用量在相同范围内的chunks,
//比如q075存放的是使用量达到了75%以上的chunk
private final PoolChunkList<T> q050;
private final PoolChunkList<T> q025;
private final PoolChunkList<T> q000;
private final PoolChunkList<T> qInit;
private final PoolChunkList<T> q075;
private final PoolChunkList<T> q100;
private final List<PoolChunkListMetric> chunkListMetrics;
//下面都是一些记录性质的属性
// Metrics for allocations and deallocations
private long allocationsNormal;
// We need to use the LongCounter here as this is not guarded via synchronized block.
private final LongCounter allocationsTiny = PlatformDependent.newLongCounter();
private final LongCounter allocationsSmall = PlatformDependent.newLongCounter();
private final LongCounter allocationsHuge = PlatformDependent.newLongCounter();
private final LongCounter activeBytesHuge = PlatformDependent.newLongCounter();
private long deallocationsTiny;
private long deallocationsSmall;
private long deallocationsNormal;
// We need to use the LongCounter here as this is not guarded via synchronized block.
private final LongCounter deallocationsHuge = PlatformDependent.newLongCounter();
// Number of thread caches backed by this arena.
final AtomicInteger numThreadCaches = new AtomicInteger();
是由多个PoolChunkList和两个SubPagePools(一个是tinySubPagePool,一个是smallSubPagePool)组成的。
看下tinySubpagePools和smallSubpagePools数组的初始化, 以tinySubpagePools为例

private PoolSubpage<T>[] newSubpagePoolArray(int size) {
return new PoolSubpage[size];
}
构造一个 newSubpagePoolArray方法中,创建了一个PoolSubpage 对象数组,里边没有初始化任何元素
接下来,是初始化每一个元素,或者说,初始化每一个slot槽位,
具体的做法是:每一个槽位构造出一个头部对象,类型为 PoolSubpage
private PoolSubpage<T> newSubpagePoolHead(int pageSize) {
PoolSubpage<T> head = new PoolSubpage<T>(pageSize);
head.prev = head;
head.next = head;
return head;
}
PoolSubpage是双向链表节点型的对象,默认head和next都指向自己
所以初始化后的SubpagePools长这样

看下smallSubpagePools数组的初始化, 和tinySubpagePools类似,只是数组的大小不同

Netty的池化内存分配流程
在深入PoolSubpage之前,有必要先说下netty的内存分配流程实现。
netty向jvm或者堆外内存每次申请的内存以chunk为基本单位,
每个chunk的默认大小是16M,在netty内部每个chunk又被分成若干个page,默认情况下每个page的大小为8k,所以在默认情况下一个chunk包含2048个page
应用程序向netty申请内存的时候分成两四情况:
1)如果申请的内存大于一个chunk的尺寸,规模为huge,那么netty就会直接向JVM或者操作系统申请相应大小的内存。
2)如果申请的内存小于chunk的尺寸,但是规模为normal,默认情况下也就是小于16M,那么netty就会以page为单位去分配一个run系列的page给应用程序
比如申请10K的内存,那么netty会选择一个chunk中的2个page分配给应用程序,
如果申请的内存小于一个page的大小,那么就直接分配一个page给应用程序
3)如果申请的内存小于normal的尺寸,但是规模为small,则先去 smallSubpagePools 中查找,如果没有,则找一个page劈成n个同等规模的Subpage,然后进行分配,剩余的Subpage插入smallSubpagePools 具体的slot中。
4)如果申请的内存小于normal的尺寸,但是规模为tiny,则先去 tinySubpagePools 中查找,如果没有,则找一个page劈成n个同等规格的Subpage,然后进行分配,剩余的Subpage插入tinySubpagePools 具体的slot中。
第2、3、4步中,如果没有空闲的page,则申请一个chunk,分配成page后,再申请一个page
PoolChunk
Netty一次向系统申请16M的连续内存空间,这块内存通过PoolChunk对象包装,
为了更细粒度的管理它,进一步细分成页,默认一个页8k(pageSize=8k),为的把这16M内存分成了2048个页。
页作为Netty的最基本的单位 ,所有的内存分配首先必须申请一块空闲页。
几个比较重要的术语
在介绍PoolChunk代码之前先介绍几个比较重要的术语。
- page:page是PoolChunk的分配的最小单位,默认的1个page的大小为8kB
- run:表示的是一个page的集合
- handle:句柄,用于表示poolChunk中一块内存的位置,大小,使用情况等信息,
page页与page run
Page 是 Chunk 用于管理内存的基本单位。
Page 的默认大小为 8KB,若欲申请 16KB,则需申请连续的两块空闲 Page。
如果内部分配的不只是8k,比如 8193个字节,规格化后,会变成 2个page,
这个两个page组成一个序列,或者说一串,叫做page run。
handle:内存句柄
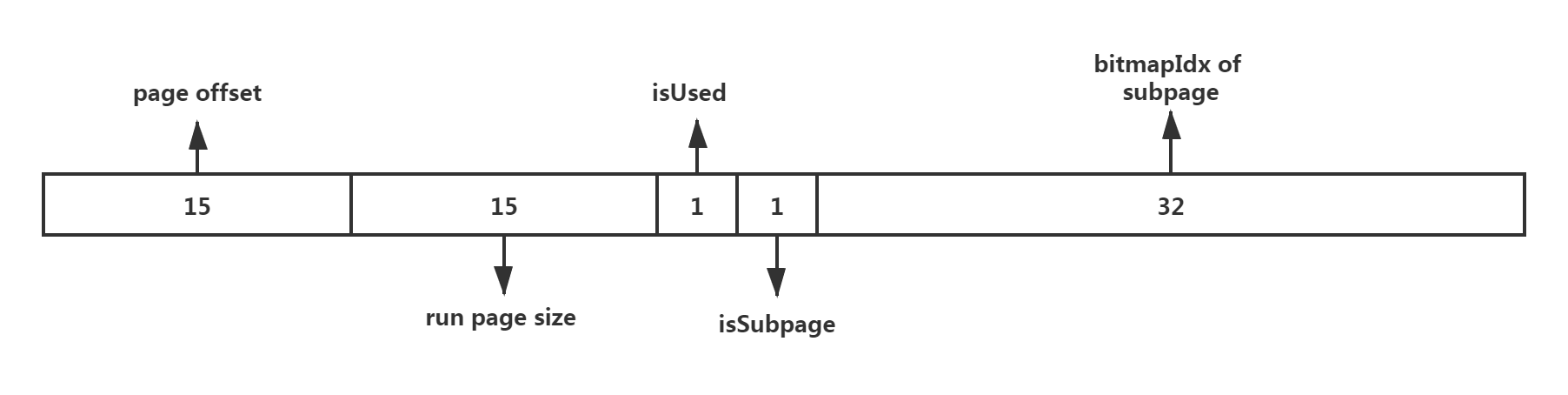
一个handle 是一个long占8个字节,其由低位的4个字节和高位的4个字节组成,
toHandle(bitmapIdx);

memoryMapIdx:
低位的4个字节表示当前page(8K)在PoolChunk(16M)中memoryMap映射数组中的下标索引;
bitmapIdx:
高位的4个字节则表示当前需要分配的内存PoolSubPage在page 8KB内存中的位图索引。
场景一:
对于大于8KB的内存分配,不涉及PoolSubPage结构,因而高位四个字节的位图索引为0, 而低位的4个字节page序列在chunk中的位置索引;
场景二:
对于低于8KB的内存分配,其会使用一个PoolSubPage来表示整个8KB内存,因而需要一个位图索引来表示subpage在page中的位图索引。
从形象上理解,这个是两个俄罗斯套娃
完整演示与介绍,请参考40岁老架构师尼恩的视频:《彻底穿透netty架构与源码》
PoolPage
Page的大小默认是8192字节,也可以设置系统变量io.netty.allocator.pageSize来改变页的大小。
自定义页大小有如下限制:
- 1.必须大于4096字节;
- 2.必须是2的整次数幂。
如果管理一个chunk的Page
一个chunk的Page需要通过某种数据结构跟算法管理起来。
大家可以设想一下,最简单的方式:是采用数组或位图管理
如上图1表示已申请,0表示空闲。这样申请一个Page的复杂度为O(n)。
netty分配给应用程序的内存都是以page(默认8K)为单位进行分配,同时根据申请量每次分配个page,
换言之netty不可能一次分配3个page或者5个page,如果申请3x8192的内存默认netty会分配4个page,如果申请5x8192的内存,默认netty会分配8个page。
一个chunk默认的大小是16M,在PoolChunk中这16M的内存在逻辑上被划分成2048个page。
为了高效的实现page的分配,netty使用一棵树完全二叉树来管理这16M的内存,这棵完全二叉树的深度为12,
从第0层开始,第11层有2048个叶子节点,每个叶子节点代表一个page,

注意:这颗完全二叉树中的非叶子节代表的内存容量等于其子节点的容量和
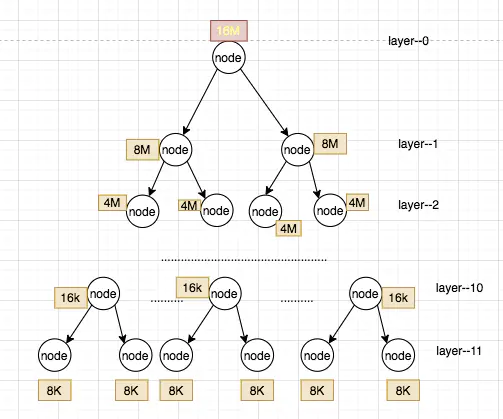
这里,构造了一棵 满二叉树(Compelte balanced binary) 从而加快搜索速度。棵树看起来看是这样的(括号中的表示每个节点的大小)
- depth=0 1 node (chunkSize)
- depth=1 2 nodes (chunkSize/2)
- …
- depth=d 2^d nodes (chunkSize/2^d)
- …
- depth=maxOrder 2^maxOrder nodes (chunkSize/2^{maxOrder} = pageSize)
当 depth=maxOrder 时,节点是由 page 组成。
fbt树memoryMap 和 depthMap
PoolChunk 用两个成员 memoryMap(内存映射) 和 depthMap (深度映射) 就是代表的这颗二叉树,是两颗fbt树,满二叉树
默认 memoryMap和depthMap数组长度为4096
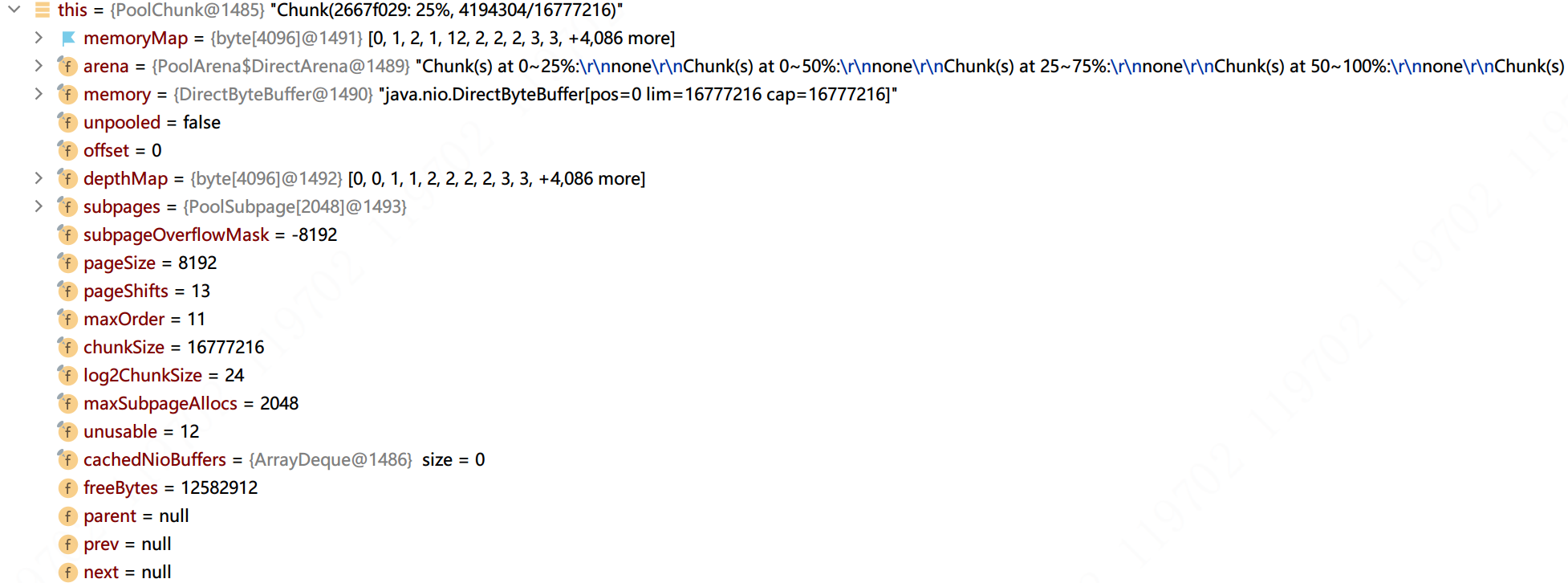
final class PoolChunk<T> implements PoolChunkMetric {
private static final int INTEGER_SIZE_MINUS_ONE = Integer.SIZE - 1;
final PoolArena<T> arena;
final T memory;
final boolean unpooled;
final int offset;
private final byte[] memoryMap; //表示完全二叉树,共有4096个节点
private final byte[] depthMap; //表示节点的层高,共有4096个
...
一个完全二叉树可以用大小为4096的数组表示,数组元素的值含义为:
private final byte[] memoryMap; //表示完全二叉树,共有4096个
private final byte[] depthMap; //表示节点的层高,共有4096个
但是这棵完全二叉树只有4095个节点,netty选择从数组的index=1开始去表示这棵完全二叉树。
那么memoryMap和depthMap有什么区别呢?
- memoryMap[i] = depthMap[i]= depth: 表示该节点下面的所有叶子节点都可用,这是初始状态
- memoryMap[i] = depthMap[i] + 1:表示该节点下面有一部分叶子节点被使用,但还有一部分叶子节点可用
- memoryMap[i] = maxOrder + 1 = 12:表示该节点下面的所有叶子节点不可用
memoryMap 是会随着page的分配和回收动态的修改每个节点的值,
depthMap中的元素一旦初始化之后就不会被修改了,将来需要查看某个节点初始状态的值( 节点的depth深度)就可以通过depthMap查找。
满二叉树的初始化
我们看下memoryMap和depthMap初始化代码

Netty采用完全二叉树进行管理,树中每个叶子节点表示一个Page,即树高为12,


特点:
中间节点表示页节点的持有者,叶子节点为 page,page 处于第11层,树的层数从0开始。
高度为 11 的节点(2048 - 4095)即为 Page 节点,代表 8 KB ;
高度为 10 的节点(1024 - 2047)均拥有 2 个 Page 节点,代表16 KB;
高度为 1 的节点(2、3)均拥有 1024 个 Page 节点,代表 8 MB;
高度为 0 的节点(1)拥有 2048 个 Page 节点,代表 16 MB,即一个满 Chunk 的大小。
memoryMap搜索算法
memoryMap 类型是 byte[],用来记录树的分配情况。
id索引的元素 初始值,为对应节点所在的树的深度。搜索空闲page时,用id索引,在 memoryMap 满二叉树上搜索:
-
memoryMap[id] = depth_of_id=> 代表该节点: 空闲/完全未分配。这里,可以把depth_of_id 理解为规模,可以分配出 >= depth_of_id 级别的内存,
比如 id为10, depth_of_id 为10,可以分配出 10(16k)、11(8k) 级规模的内存
-
memoryMap[id] > depth_of_id=> 代表该节点: 至少有一个子节点已经被分配了,但其他子节点仍然可分配。这里,可以把depth_of_id 理解为规模,可以分配出 > depth_of_id 级别的内存,
比如 id为10, depth_of_id 为11 ,可以分配出 11(8k) 级规模的内存, 10(16k)级的分配不了了,已经有一个子节点已经分配完了
-
memoryMap[id] = maxOrder + 1=> 代表该节点: 当前节点已经完成分配了,即当前节点处于不可用状态。比如 id为10, depth_of_id 为12,不可以分配出 10(16k)、11(8k) 级规模的内存,两个子树,都分配完了
规格化处理
所有用户申请内存的大小都按PoolArena#normalizecapacity 方法法进行规格化处理。
这确保了当我们请求大小 >= pageSize 的内存段时,规格化容量等于下一个最近的2的次幂。
页的申请跟释放
有了上面的数据结构,那么页的申请跟释放就非常简单了,
页的申请,只需要从根节点一路遍历找到可用的节点即可,复杂度为O(lgn)。
代码为:
#PoolChunk
//根据申请空间大小,选择申请方法
long allocate(int normCapacity) {
if ((normCapacity & subpageOverflowMask) != 0) { // >= pageSize
return allocateRun(normCapacity); //大于1页
} else {
return allocateSubpage(normCapacity);
}
}
allocate方法是PoolChunk真正实现page分配的地方,PoolChunk对于page的分配分成两种情况:
-
单次内存申请量标准化之后大于或者等于一个page,对应的分配方法是allocateRun
-
单次内存申请量标准化之后小于一个page,对应的分配方法是allocateSubpage
两大场景,具体如下:
- 场景一:大于或者等于一个page,
对应的分配方法是allocateRun,返回的就是memoryMap 内存映射的索引值,也就是数组的下标,
- 场景一:小于一个page
对应的分配方法是allocateSubpage, 之后会返回一个handle 句柄,handle 是一个64位的标记,记载着很多内存地址信息,
allocateRun分配page run
接下来看看allocateRun(页面系列):allocateRun是分配多个page操作,找到最接近当前需要分配的size的内存块
allocateRun首先计算 内存块在 fbt上的深度
举个例子,当分配的内存大于2^13B(8196B)时,可以通过内存值计算对应的深度:int d=11-(log2(normCapacity)-13)。
其中,normCapacity为分配的内存大小,它大于或等于8KB且为8KB的整数倍。
例如,申请大小为16KB的内存,d=11-(14-13)=10,表示只能在小于或等于10层上寻找还未被分配的节点。

深度d到底怎么算的?
int d = maxOrder - (log2(normCapacity) - pageShifts)
首先我们看下(log2(normCapacity) - pageShifts),在这里的normCapacity至少是8k,取了log2后至少是13.
两个例子:
如果 normCapacity是8k, 取了log2后刚好是13,那么(log2(normCapacity) - pageShifts) 结果就是0, 于是 d=maxOrder=11。意思就是说定位要了深度11,也就是最大深度
如果是16k呢?那结果就是11-(14-13)=10,深度是10。
计算深度时,首先要计算内存块size的对数,这里用位运算,
来计算 2的对数,效率比数学运算高多了

再通过allocateNode找到一个最合适的节点: 沿着平衡二叉树,从根节点开始,寻找一个合适的节点。
如果无法分配,返回-1。
allocateNode
allocateNode就是要在平衡二叉树中要找到一个可以满足normCapacity的节点,这里边有个要点:
内存映射 memoryMap[id]存放的是,该id能分配的最小深度,这个最小深度,实际上代表的能分配的最大容量。
Netty采用了前序遍历算法:
-
从根节点开始,第二层为左右节点,先看左边节点内存是否够分配,
-
若不够,则选择其兄弟节点(右节点);
-
若当前左节点够分配,则需要继续向下一层层地查找,直到找到层级最接近d(分配的内存在二叉树中对应的层级)的节点。



测试用例:allocateNode的执行过程
allocateNode找到一个可以满足normCapacity的节点,测试用例的结果如下




完整演示与介绍,请参考40岁老架构师尼恩的视频:《彻底穿透netty架构与源码》
updateParentsAlloc更新父节点的深度值
一个子节点分配之后,同时要更新父节点,一直到根节点,‘
具体的修改逻辑为:
不断迭代,找父节点,
将父节点的深度值就改成子节点里最小的那个,

updateParentsAlloc更新父节点的深度值,测试用例的结果如下

完整演示与介绍,请参考40岁老架构师尼恩的视频:《彻底穿透netty架构与源码》
通过memoryMap的index找偏移量
内存映射memoryMap的下标的作用:
通过内存映射memoryMap的下标可以找到其偏移量。然后初始化PooledBytebuf实例



弹性伸缩
前面的算法原理部分介绍了Netty如何实现内存块的申请和释放,单个chunk比较容量有限,
如何管理多个chunk,构建成能够弹性伸缩内存池?
PoolChunk管理
为了解决单个PoolChunk容量有限的问题,Netty将多个PoolChunk组成链表一起管理,
然后用PoolChunkList对象持有链表的head, 将所有PoolChunk组成一个链表的话,进行遍历查找管理效率较低,
因此Netty设计了PoolArena对象(arena中文是舞台、场所),实现对多个PoolChunkList、PoolSubpage的分组管理调度,线程安全控制、提供内存分配、释放的服务
PoolChunkList
上面讨论了PoolChunk的内存分配算法,但是PoolChunk只有16M,
这远远不够用,所以会很很多很多PoolChunk,这些PoolChunk组成一个链表,然后用PoolChunkList持有这个链表.
#PoolChunkList
private PoolChunk<T> head;
#PoolChunk
PoolChunk<T> prev;
PoolChunk<T> next;
它有6个PoolChunkList,所以将PoolChunk按内存使用率分类组成6个PoolChunkList,
同时每个PoolChunkList还把各自串起来,形成一个PoolChunkList链表。
注意:
- q000没有前驱节点,所以一旦PoolChunk使用率为0,就从PoolChunkList中移除,释放掉这部分空间,避免在高峰的时候申请过内存一直缓存到池中。
- 各个PoolChunkList的区间是交叉的、重叠的,这是故意的,因为如果重叠,而是介于一个临界值的话,PoolChunk会在前后PoolChunkList不停的来回移动。
PoolArena内部持有6个PoolChunkList,各个PoolChunkList持有的PoolChunk的使用率区间不同:
// 容纳使用率 (0,25%) 的PoolChunk
private final PoolChunkList qInit;
// [1%,50%)
private final PoolChunkList q000;
// [25%, 75%)
private final PoolChunkList q025;
// [50%, 100%)
private final PoolChunkList q050;
// [75%, 100%)
private final PoolChunkList q075;
// 100%
private final PoolChunkList q100;
6个PoolChunkList对象组成双向链表,
当PoolChunk内存分配、释放,导致使用率变化,需要判断PoolChunk是否超过所在PoolChunkList的限定使用率范围,
如果超出了,需要沿着6个PoolChunkList的双向链表找到新的合适PoolChunkList,成为新的head
同样的,当新建PoolChunk并分配完内存,该PoolChunk也需要按照上面逻辑放入合适的PoolChunkList中
分配归一化内存normCapacity(大小范围在[pageSize, chunkSize]) 具体处理如下:
按顺序依次访问q050、q025、q000、qInit、q075,遍历PoolChunkList内PoolChunk链表判断是否有PoolChunk能分配内存
如果上面5个PoolChunkList有任意一个PoolChunk内存分配成功,PoolChunk使用率发生变更,重新检查并放入合适的PoolChunkList中,结束
否则新建一个PoolChunk,分配内存,放入合适的PoolChunkList中(PoolChunkList扩容)
note:可以看到分配内存依次优先在q050 - q025 - q000 - qInit - q075的PoolChunkList的内分配,
这样做的好处是,使分配后各个区间内存使用率更多处于[75,100)的区间范围内,提高PoolChunk内存使用率的同时也兼顾效率,减少在PoolChunkList中PoolChunk的遍历
当PoolChunk内存释放,同样PoolChunk使用率发生变更,重新检查并放入合适的PoolChunkList中,如果释放后PoolChunk内存使用率为0,则从PoolChunkList中移除,释放掉这部分空间,避免在高峰的时候申请过内存一直缓存在池中(PoolChunkList缩容)

支撑百万级并发,Netty如何实现高性能内存管理
PoolChunkList的额定使用率区间存在交叉,这样设计是因为如果基于一个临界值的话,当PoolChunk内存申请释放后的内存使用率在临界值上下徘徊的话,会导致在PoolChunkList链表前后来回移动
PoolSubpage管理
PoolArena内部持有2个PoolSubpage数组,分别存储tiny和small规格类型的PoolSubpage:
// 数组长度32,实际使用域从index = 1开始,对应31种tiny规格PoolSubpage
private final PoolSubpage[] tinySubpagePools;
// 数组长度4,对应4种small规格PoolSubpage
private final PoolSubpage[] smallSubpagePools;
相同规格大小(elemSize)的PoolSubpage组成链表,不同规格的PoolSubpage链表的head则分别保存在tinySubpagePools 或者 smallSubpagePools数组中,如下图:

支撑百万级并发,Netty如何实现高性能内存管理
当需要分配小内存对象到PoolSubpage中时,根据归一化后的大小,计算出需要访问的PoolSubpage链表在tinySubpagePools和smallSubpagePools数组的下标,访问链表中的PoolSubpage的申请内存分配,
如果访问到的PoolSubpage链表节点数为0,则创建新的PoolSubpage分配内存然后加入链表
PoolSubpage链表存储的PoolSubpage都是已分配部分内存,当内存全部分配完或者内存全部释放完的PoolSubpage会移出链表,减少不必要的链表节点;
当PoolSubpage内存全部分配完后再释放部分内存,会重新将加入链表
PoolArean内存池弹性伸缩可用下图总结:

PoolChunkList源码分析
下面是PoolChunkList中属性定义
//PoolChunkList所属的arena
private final PoolArena<T> arena;
private final int minUsage; //最小使用率
private final int maxUsage; //最大使用率
private final int maxCapacity; //属于本PoolChunkList管理的chunk最大可被申请的内存量
//同类chunk链表头指针
private PoolChunk<T> head;
private final int freeMinThreshold;
private final int freeMaxThreshold;
// This is only update once when create the linked like list of PoolChunkList in PoolArena constructor.
// 指向PoolChunkList链表中的前一个节点
private PoolChunkList<T> prevList;
private final PoolChunkList<T> nextList;
那么netty到底是如何给不同的chunk进行分类的呢?
其实是通过设定两个参数实现的,minUsage和maxUsage,
在netty中chunk按照剩余可用内存的大小被分成了6类,下面是这六类在PoolArena中的定义
//[100,) 每个PoolChunk使用率100%
q100 = new PoolChunkList<T>(this, null, 100, Integer.MAX_VALUE, chunkSize);
//[75,100) 每个PoolChunk使用率75-100%
q075 = new PoolChunkList<T>(this, q100, 75, 100, chunkSize);
//[50,100)
q050 = new PoolChunkList<T>(this, q075, 50, 100, chunkSize);
//[25,75)
q025 = new PoolChunkList<T>(this, q050, 25, 75, chunkSize);
//[1,50)
q000 = new PoolChunkList<T>(this, q025, 1, 50, chunkSize);
qInit = new PoolChunkList<T>(this, q000, Integer.MIN_VALUE, 25, chunkSize);
同时申请空间,使用哪一个PoolChunkList也是有先后顺序的,
先从 q050 使用率的列表开始
#PoolArena
allocateNormal(...){
if (q050.allocate(...) || q025.allocate(...) ||
q000.allocate(...) || qInit.allocate(...) ||
q075.allocate(...)) {
return;
}
PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize);
...
qInit.add(c);
}
如果Chunk的使用率超过设置的maxUsage,则移到下一个PoolChunkList中
#PoolChunkList
boolean allocate(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
if (head == null || normCapacity > maxCapacity) {
return false;
}
for (PoolChunk<T> cur = head;;) {
long handle = cur.allocate(normCapacity);
if (handle < 0) {
cur = cur.next;
if (cur == null) {
return false;
}
} else {
cur.initBuf(buf, handle, reqCapacity);
if (cur.usage() >= maxUsage) {
remove(cur);
nextList.add(cur); //移到下一个PoolChunkList中
}
return true;
}
}
}
freeMinThreshold、freeMaxThreshold两个属性
PoolChunk在使用过程中,还会受到freeMinThreshold、freeMaxThreshold两个属性的影响。
freeMinThreshold和freeMaxThreshold会分别根据maxUsage和minUsage计算出来,公式如下:
freeMinThreshold = (maxUsage == 100) ? 0 :
(int) (chunkSize * (100.0 - maxUsage + 0.99999999) / 100L);
freeMaxThreshold = (minUsage == 100) ? 0 :
(int) (chunkSize * (100.0 - minUsage + 0.99999999) / 100L);
在arena中minUsage和maxUsage被设置了不同大小的值
我们就拿q025来举例子看下,
q025对应的PoolChunkList,
minUsage = 25,maxUsage = 75,
根据这两个值可以算出:
- freeMinThreshold约定于4.16M
- freeMaxThreshold约等于12.16M。
PoolChunk在使用过程中是会结合freeMinThreshold与 freeMaxThreshold动态变化的:
-
当一个chunk分配出去一些内存后,如果这个chunk在这次分配之后剩余的可用内存小于freeMinThreshold,那么这个chunk就不再属于这个chunkList管理了,那么他就会被沿着PoolChunkList链表向下继续查找适合存放它的PoolChunkList。
-
当向一个chunk中释放内存后,如果释放之后这个chunk的可用内存大于freeMaxThreshold,那么就需要沿着PoolChunkList链表向头部方向去寻找适合管理这个chunk的PoolChunkList。
下图给出了不同PoolChunkList管理的chunk的内存范围

最终,PoolChunk会在不同PoolChunkList中变化。
这样设计的目的:
考虑到随着内存的申请与释放,PoolChunk的内存碎片也会相应的升高,
使用率越高的PoolChunk, 其申请一块连续空间(分配一块连续的内存空间)失败的概率也会大大的提高。
PoolSubpage
页还要分为子页,为啥呢?
由于一个页(page)的大小就达到了10^13(8192字节),通常, 一次申请分配内存,没有这么大,可能很小。
当我们申请的内存小于一个chunk的大小,netty会以page为单位返回结果给申请者,一个page默认是8K,
如果我们申请的内存量是32B,netty返回了一个page,这不是很浪费吗,
对你,这确实很浪费,
于是,Netty将页(page)划分成更小的片段——SubPage
实际上,除了小对象直接分配一个page会造成浪费之外,小对象在page中进行平衡树的标记又额外消耗更多空间,
因此Netty的实现是:先PoolChunk中申请空闲page,同一个page分为相同大小规格的小内存进行存储

小对象内存管理
当请求对象的大小reqCapacity = 496,规格化计算后方式是向上取最近的16的倍数,
例如15规整为15、40规整为48、490规整为496,
规格化后的大小(normalizedCapacity)小于pageSize的小对象可分为2类:
-
微型对象(tiny):规格化为16的整倍数,如16、32、48、…、496,一共31种规格
-
小型对象(small):规格化为2的幂的,有512、1024、2048、4096,一共4种规格
有两种类型的PoolSubpage:
1)申请内存小于512的tiny类型的PoolSubpage
2)申请内存在512到4096之间的small类型的PoolSubpage
所以,Subpage按大小分有两大类,36种情况:
-
Tiny:小于512B的情况,最小空间为16,对齐大小为16,区间为[16,512),所以共有32种情况。
简单的说:Tiny类型的内存,分配规格按照 16的倍数 关系增长
-
Small:大于等于512的情况,总共有四种,512,1024,2048,4096。
简单的说:Small类型的内存,分配规格按照 2的幂次方 关系增长
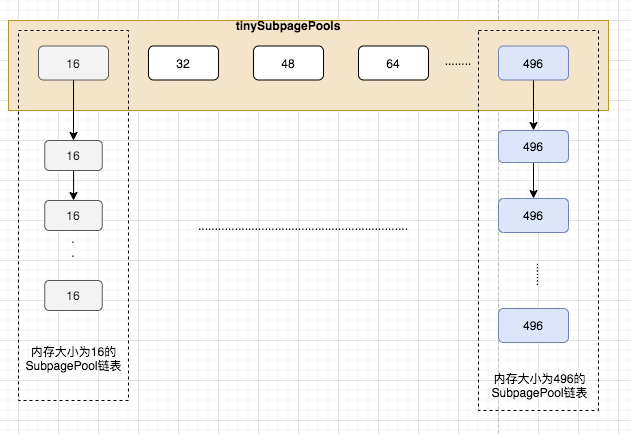
tinySubpagePools
tiny是按照16的倍数分块,最大分到496,tinySubpagePools数组长度是32,
其中index=0的位置是不使用的,
数组的第一个元素指向的是内存被按照以16B为基本单位进行划分的pages,第32个元素指向的是内存被按照以496B为基本单位进行划分的pages。
smallSubpagePools
small类型从512开始后面的数是前面的2倍直到4096,所以smallSubpagePools的大小是4,
第1个元素指向的是内存被按照以512B为基本单位进行划分的pages,
第2个元素指向的是内存被按照以1024B为基本单位进行划分的pages,
第3个元素指向的是内存被按照以2048B为基本单位进行划分的pages,
最后一个元素指向的是内存被按照以4096B为基本单位进行划分的pages

问题: 规格化后,是不是存在内存的浪费呢?
例如1025byte规格化为2048byte, 浪费了 1023个byte
8193byte规格化为16384byte,8191个byte
这样是不是造成了一些浪费?
可以理解为是一种取舍,通过规格化处理,使池化内存分配大小规格化,大大方便内存申请和内存、内存复用,提高效率
PoolSubpage的作用:
对申请到的page按照实际申请量的大小,对这个page再进行分割,从而做到内存的合理利用和减少内存碎片化。
PoolSubpage的属性
PoolSubpage是由PoolChunk的page生成的,page可以生成多种PoolSubpage ,
但是,一 个 page 只 能 生 成 其 中 一 种 PoolSubpage 。
这些page用PoolSubpage对象进行封装,PoolSubpage内部有记录这些小内存的重要成员:
- 内存规格大小(elemSize)、
- 可用内存数量(numAvail)和
- 各个小内存的使用情况,通过long[]类型的bitmap相应bit值0或1,来记录内存是否已使用
通过bitmap,PoolSubpage中直接采用位图管理空闲空间(因为不存在申请k个连续的空间),所以申请释放非常简单。
#PoolSubpage(数据结构)
final PoolChunk<T> chunk; //对应的chunk
private final int memoryMapIdx; //chunk中那一页,页的大小,肯定大于等于4096,默认为 8k
private final int pageSize; //subpage页大小
private final long[] bitmap; //位图,使用bitmap来记录每个内存单元的使用情况。
int elemSize; //单元大小
private int maxNumElems; //总共有多少个单位
private int bitmapLength; //位图大小,maxNumElems >>> 6,一个long有64bit
private int nextAvail; //下一个可用的单位
private int numAvail; //还有多少个可用单位;
elemSize单元大小
PoolSubpage 会被分成n个小的element单元:
- 单元的大小为 elementSize,
- n为pageSize/elementSize个
bitmap单元位图
这里bitmap是个位图,使用bitmap来记录每个内存单元element的使用情况.
位图的每一个位置,0表示element可用,1表示element不可用.
相关的索引
nextAvail 记录下一个可用内存单元的位置,初始状态为0,
numAvail 记录可用的内存块的数量,还有多少个可用单位;
PoolSubpage的分配步骤和源码分析
平衡二叉树第十一层的叶子节点最小也是8KB,那比如要分配128B的缓存,直接分给8KB显然是不合适的,
Tiny是小于512Byte,Small介于512B~8KB,Tiny和Small统称Subpage,Subpage的内存分配,包含Tiny和Small的内存分配,
所以 ,Subpage的内存分配应该是整个netty最为复杂的部分了。
PoolSubpage将chunk中的一个page再次划分,分成相同大小的N份,这里暂且叫Element,经过对每个Element的标记与清理标记来进行内存的分配与释放。
subpage分配的整体流程
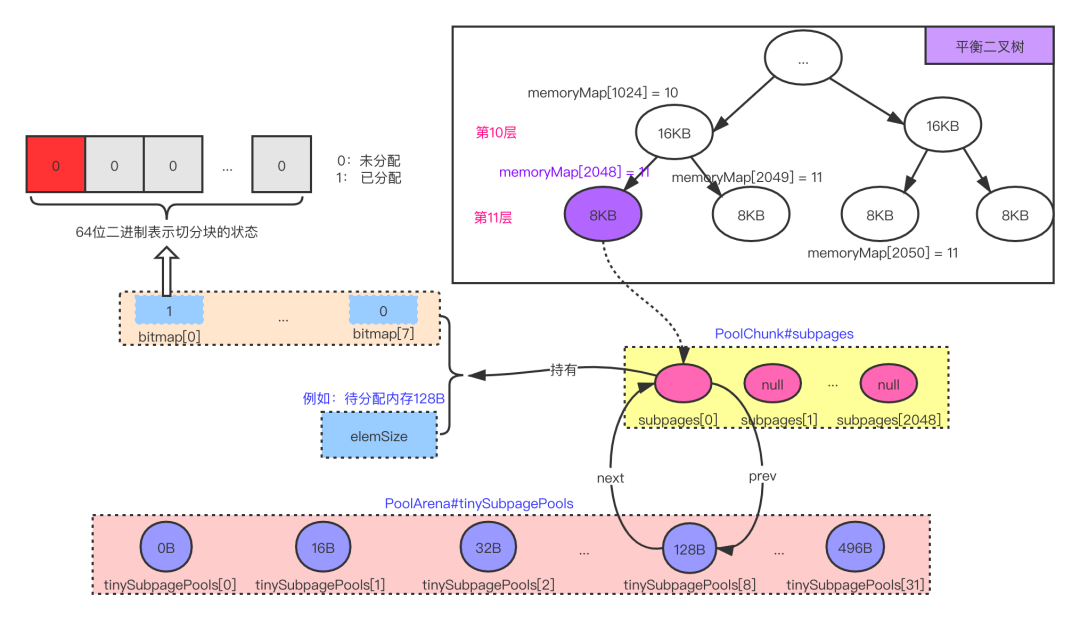
步骤:
-
在PoolChunk的二叉树上找到匹配的节点,由于小于8KB,因此只匹配一个page节点,
-
然后按照申请规模进行切割, 切割之后创建 subpage,
-
创建完成后,分配一个 element,然后返回其 handle , 两个int(32位)的索引 bitmapIdx 和 memoryMapIdx,合并成一个long类型
以分配128B为例, 先从平衡二叉树的第11层, 选一个未分配的叶子节点Page (大小为8KB),
假设,选中的为第一个page,memoryMap[2048], 对该Page进行切割,假如要分配128B,整体会切割为64块
因为:8192/128=64
PoolSubpage的构造
inal class PoolSubpage<T> {
private final int memoryMapIdx; // 当前page在chunk中的id
private final int runOffset; // 当前page在chunk.memory的偏移量
private final int pageSize; // page大小
private final long[] bitmap; // 这个bitmap的实现和BitSet相同,经过对每个二进制位的标记来修改一段内存的占用状态
PoolSubpage<T> prev; // 前一个节点,这里要配合PoolArena看,后面再说
PoolSubpage<T> next;
boolean doNotDestroy; // 表示该page在使用中,不能被清除
int elemSize; // 该page切分后每一段的大小
private int maxNumElems; // 该page包含的段数量
private int bitmapLength; // bitmap须要用到的长度
private int nextAvail; // 下一个可用的位置
private int numAvail; // 可用的段数量
PoolSubpage(PoolChunk<T> chunk, int memoryMapIdx, int runOffset, int pageSize, int elemSize) {
this.chunk = chunk;
this.memoryMapIdx = memoryMapIdx;
this.runOffset = runOffset;
this.pageSize = pageSize;
// 这里为何是16,64两个数字呢,
// elemSize是通过normCapacity处理的数字,最小值为16;
// 因此一个page最多可能被分成pageSize/16段内存,而一个long有64个位,固能够表示64个内存段的状态;
// 所以最多须要pageSize/16/64个long ,才能保证全部段的状态均可以管理
bitmap = new long[pageSize >>> 10]; // pageSize / 16(2^4) / 64 (2^6)
init(elemSize);
}
这个构造方法只是做了一些简单的属性初始化工作。
难点的地方,是初始bitmap,
bitmap用bit位来记录每个subpage的使用情况,每个bit对应一个subpage,0表示subpage空闲,1表示subpage已经被分配出去。
一个subpage的大小是elemSize,最小的elemSize=16,
那么一个page最多可分割成subpage的数量maxSubpageCount=pageSize/16=pageSize >> 4。
bitmap是个long型的数字,每个long数据有64位,因此bitmap的最大长度只需要maxBitmapLength = maxSubpageCount / 64 = pageSize / 16 / 64
所以,bitmap= new long[pageSize >>> 10] 就够用了。
PoolSubpage的初始化
init方法的作用是根据elemSize计算出有效的bitmap长度bitmapLength,
然后把bitmapLength范围内存的bit值都初始化为0,
将本身加入到chunk.arena的对应规模的slot的列表中。

chunk在分配page时,若是是8K如下的段则交给subpage管理,
然而chunk并无将subpage暴露给外部,subpage只好自谋生路,在初始化或重新分配时将本身加入到chunk.arena的pool中,
经过arena进行后续的管理(包括复用subpage上的其余element)
PoolChunk#allocateSubpage分配subpage


-
PoolSubpage
head = arena.findSubpagePoolHead(normCapacity); 找到当前规格内存normCapacity在subpagePools数组中索引,进而获取该索引内head节点。
例如:normCapacity=32属于tiny规格,32 / 16 = 2,即取tinySubpagePools[2]中head节点
-
int id = allocateNode(d); 进行page分配,上面已经分析过
-
获取PoolChunk中subpages数组中subpage(一般情况下为null),创建一个subpage并放到subpages中
-
subpage.allocate();
在subpage上进行分配
PoolSubpage#allocate分配Element
下面看看subpage是如何进行内部的内存分配的:

final int bitmapIdx = getNextAvail();
找到当前page中可分配内存段的bitmapIdx
bitmap[q] |= 1L << r;
通过bitmapIdx定位到具体分配了哪个段,并把代表该段的索引置为1表示不可用,
bitmapIdx 32位int类型高26位表示在bitmap数组中位置索引,低6位表示64位long类型内位数索引(2^6 = 64);
toHandle(bitmapIdx);
把两个int(32位)的索引 bitmapIdx 和 memoryMapIdx,合并成一个long类型返回
可以想一下如何把两个不同类型索引或两个int类型值同时返回?
netty这里把两个int(32位)的索引 bitmapIdx 和 memoryMapIdx,合并成一个long类型,
加 0x4000000000000000L 是为了让高32位不全是0
getNextAvail



-
bitmap: 8个long类型组成的位图数组;bitmapLength:bitmap的有效长度,不一定是8,例如16B时需要8个long,bitmapLength=8;32B时只需要4个long,bitmapLength=4
-
遍历bitmap中每一个long类型,判断long是不是全1,不是的话就说明该long类型表示的位图中还有未分配的段
-
有可用段时通过findNextAvail0(i, bits);找到索引直接返回
PoolSubpage#free
// 释放指定element
boolean free(int bitmapIdx) {
if (elemSize == 0) {
return true;
}
// 下面这几句转换成咱们常见的BitSet,其实就是bitSet.set(q, false)
int q = bitmapIdx >>> 6;
int r = bitmapIdx & 63;
assert (bitmap[q] >>> r & 1) != 0;
bitmap[q] ^= 1L << r;
// 将这个index设置为可用, 下次分配时会直接分配这个位置的内存
setNextAvail(bitmapIdx);
// numAvail=0说明以前已经从arena的pool中移除了,如今变回可用,则再次交给arena管理
if (numAvail ++ == 0) {
addToPool();
return true;
}
if (numAvail != maxNumElems) {
return true;
} else {
// 注意这里的特殊处理,若是arena的pool中没有可用的subpage,则保留,不然将其从pool中移除。
// 这样尽量的保证arena分配小内存时能直接从pool中取,而不用再到chunk中去获取。
// Subpage not in use (numAvail == maxNumElems)
if (prev == next) {
// Do not remove if this subpage is the only one left in the pool.
return true;
}
// Remove this subpage from the pool if there are other subpages left in the pool.
doNotDestroy = false;
removeFromPool();
return false;
}
}
handle:bitmapIdx 和 memoryMapIdx
一个handle 是一个long占8个字节,其由低位的4个字节和高位的4个字节组成,
toHandle(bitmapIdx);
memoryMapIdx:
低位的4个字节表示当前page(8K)在PoolChunk(16M)中memoryMap映射数组中的下标索引;
bitmapIdx:
高位的4个字节则表示当前需要分配的内存PoolSubPage在page 8KB内存中的位图索引。
场景一:
对于大于8KB的内存分配,不涉及PoolSubPage结构,因而高位四个字节的位图索引为0, 而低位的4个字节page序列在chunk中的位置索引;
场景二:
对于低于8KB的内存分配,其会使用一个PoolSubPage来表示整个8KB内存,因而需要一个位图索引来表示subpage在page中的位图索引。
从形象上理解,这个是两个俄罗斯套娃
完整演示与介绍,请参考40岁老架构师尼恩的视频:《彻底穿透netty架构与源码》
PoolArena大管家/管理器
PoolArena是内存管理的大管家/管理器。
它内部有一个PoolChunkList组成的链表(上文已经介绍过了,链表是按PoolChunkList所管理的使用率划分)。
此外,它还有两个PoolSubpage的数组,PoolSubpage[] tinySubpagePools 和 PoolSubpage[] smallSubpagePools。
默认情况下,tinySubpagePools的长度为31,即存放16,32,48...496这31种规格的PoolSubpage(不同规格的PoolSubpage存放在对应的数组下标中,相同规格的PoolSubpage在同一个数组下标中形成链表)。
默认情况下,smallSubpagePools的长度为4,存放512,1024,2048,4096这四种规格的PoolSubpage。
PoolArena会根据所申请的内存大小决定是找PoolChunk还是找对应规格的PoolSubpage来分配。
值得注意的是,PoolArena在分配内存时,是会存在竞争的,
因此在关键的地方,PoolArena会通过sychronize来保证线程的安全。
另外,Netty对这种竞争做了一定程度的优化,它会分配多个PoolArena,让线程尽量使用不同的PoolArena,减少出现竞争的情况。
PooledByteBufAllocator
内存分配的入口是 【PooledByteBufAllocator #newDirectBuffer()】。
PooledByteBufAllocator的结构
PooledByteBufAllocator该类,也就是内存分配的 起始类, 其内部定义了很多 默认变量值 用于接下来的内存分配整个流程。
PooledByteBufAllocator的结构图如下:

从上图 可看到有三个核心的类:
1.PoolArena(DirectArena, HeapArena都继承于该类) : 可以把他想象成内存大管家
2.PoolThreadCache: 线程本地内存缓存池
3.InternalThreadLocalMap: 目前把他当成 ThreadLocalMap 就行
在讲解源码前,请 思考一个问题 :
从图中可看到 不管是 DirectArena 还是 HeapArena,他们都有多个,且各自组成了数组 分别是directArenas 和 heapArenas。
前面说了PoolArena , 我们目前可以看成是一个内存大管家, 当业务来申请内存时,需要从PoolArena 这块大内存中 截取一块来使用就行。
但是 为什么要有多个PoolArena呢 ?
解答:
首先我们假设就只有一个PoolArena, 众所周知 现在的 CPU 一般都是多核的, 此时有多个业务(多线程) 同时从Netty中 申请内存(从大内存中偏移出多个小内存)来使用,
而本质上是多核CPU来操作这同一块大内存 进行读写。
但是 由于 操作系统的读写内存屏障 存在, 会导致多个线程的读写并不能做到真正的并行。
因此Netty用了多个PoolArena 来减轻这种不能并行的行为,从而提升效率。
PooledByteBufAllocator的核心属性
用户程序申请内存通过PooledByteBufAllocator类提供的buffer去操作,下面是这个类定义的属性
//heap类型arena的个数,数量计算方法同下
private static final int DEFAULT_NUM_HEAP_ARENA;
//direct类型arena个数,默认为min(cpu_processors * 2,maxDirectMemory/16M/2/3),正
//常情况下如果不设置很小的Xmx或者很小的-XX:MaxDirectMemorySize,
//arena的数量就等于计算机processor个数的2倍,
private static final int DEFAULT_NUM_DIRECT_ARENA;
//内存页的大小,默认为8k(这个内存页可以类比操作系统内存管理中的内存页)
private static final int DEFAULT_PAGE_SIZE;’
//默认是11,因为一个chunk默认是16M = 2^11 * 2^13(8192)
private static final int DEFAULT_MAX_ORDER; // 8192 << 11 = 16 MiB per chunk
//缓存tiny类型的内存的个数,默认是512
private static final int DEFAULT_TINY_CACHE_SIZE;
//缓存small类型的内存的个数,默认是256
private static final int DEFAULT_SMALL_CACHE_SIZE;
//缓存normal类型的内存的个数,默认是64
private static final int DEFAULT_NORMAL_CACHE_SIZE;
//最大可以被缓存的内存值,默认为32K,当申请的内存超过32K,那么这块内存就不会被放入缓存池了
private static final int DEFAULT_MAX_CACHED_BUFFER_CAPACITY;
//cache经过多少次回收之后,被清理一次,默认是8192
private static final int DEFAULT_CACHE_TRIM_INTERVAL;
private static final long DEFAULT_CACHE_TRIM_INTERVAL_MILLIS;
//是不是所有的线程都是要cache,默认true,
private static final boolean DEFAULT_USE_CACHE_FOR_ALL_THREADS;
private static final int DEFAULT_DIRECT_MEMORY_CACHE_ALIGNMENT;
// Use 1023 by default as we use an ArrayDeque as backing storage which will then allocate an internal array
// of 1024 elements. Otherwise we would allocate 2048 and only use 1024 which is wasteful.
static final int DEFAULT_MAX_CACHED_BYTEBUFFERS_PER_CHUNK;
//-------------------------------------------下半部分的属性---------------------------------------
//heap类型的arena数组
private final PoolArena<byte[]>[] heapArenas;
//direct memory 类型的arena数组
private final PoolArena<ByteBuffer>[] directArenas;
//对应上面的DEFAULT_TINY_CACHE_SIZE;
private final int tinyCacheSize;
private final int smallCacheSize;
private final int normalCacheSize;
private final List<PoolArenaMetric> heapArenaMetrics;
private final List<PoolArenaMetric> directArenaMetrics;
//这是个FastThreadLocal,记录是每个线程自己的内存缓存信息
private final PoolThreadLocalCache threadCache;
//每个PageChunk代表的内存大小,默认是16M,这个可以类比操作系统内存管理中段的概念
private final int chunkSize;
创建heap和direct memory类型的Arena
在初始化PooledByteBufAllocator的时候会创建heap和direct memory类型的Arena,
/**
*
* @param preferDirect 是否申请直接内存 默认一般都是true
* @param nHeapArena heapArena的个数 假设 cpu*2
* @param nDirectArena directArena的个数 假设 cpu*2
* @param pageSize 页的大小 默认8KB (8192)
* @param maxOrder chunk中完全平衡二叉树的深度 11
* @param smallCacheSize smallMemoryRegionCache的队列长度 256
* @param normalCacheSize normalMemoryRegionCache的队列长度 64
* @param useCacheForAllThreads 是否所有的线程都使用PoolThreadCache true
* @param directMemoryCacheAlignment 对齐填充 0
*/
public PooledByteBufAllocator(boolean preferDirect, int nHeapArena, int nDirectArena, int pageSize, int maxOrder, int smallCacheSize, int normalCacheSize,
boolean useCacheForAllThreads, int directMemoryCacheAlignment) {
// directByDefault = true
super(preferDirect);
// 目前理解成 threadLocal 每个线程中有自己的 PoolThreadLocalCache缓存
threadCache = new PoolThreadLocalCache(useCacheForAllThreads);
// 赋值 smallCacheSize=256 normalCacheSize=64
this.smallCacheSize = smallCacheSize;
this.normalCacheSize = normalCacheSize;
// 计算chunkSize 8KB<<11 = 16mb (16,777,216)
chunkSize = validateAndCalculateChunkSize(pageSize, maxOrder);
// pageSize=8KB(8192)
//pageShifts表示 1 左移多少位是 8192 = 13
int pageShifts = validateAndCalculatePageShifts(pageSize, directMemoryCacheAlignment);
// 生成 heapArenas 数组
if (nHeapArena > 0) {
heapArenas = newArenaArray(nHeapArena);
List<PoolArenaMetric> metrics = new ArrayList<PoolArenaMetric>(heapArenas.length);
for (int i = 0; i < heapArenas.length; i ++) {
PoolArena.HeapArena arena = new PoolArena.HeapArena(this,
pageSize, pageShifts, chunkSize,
directMemoryCacheAlignment);
heapArenas[i] = arena;
metrics.add(arena);
}
heapArenaMetrics = Collections.unmodifiableList(metrics);
} else {
heapArenas = null;
heapArenaMetrics = Collections.emptyList();
}
// netty默认情况下都会使用 直接内存,因此我们在整个Netty中关心直接内存相关就可以了,而且直接内存与堆内存逻辑并无太多差异。
// 生成 directArena数组
if (nDirectArena > 0) {
// 假设平台CPU 个数是8, 这里会创建 cpu(8)*2 = 16个长度的 directArenas数组。
directArenas = newArenaArray(nDirectArena);
// 这是个内存池图表
//如果想要监测 内存池详情 可使用该对象(关于内存分配逻辑不用关心Metric相关对象)
List<PoolArenaMetric> metrics = new ArrayList<PoolArenaMetric>(directArenas.length);
// for循环最终创建了 16个 directArena 对象,并且 将这些DirectArena对象放入到数组内
for (int i = 0; i < directArenas.length; i ++) {
// 参数1:allocator 对象
// 参数2:pageSize 8k
// 参数3:pageShift 13 1<<13 可推出pageSize的值
// 参数4:chunkSize: 16mb
// 参数5:directMemoryCacheAlignment 对齐填充 0
PoolArena.DirectArena arena = new PoolArena.DirectArena(
this, pageSize, pageShifts, chunkSize, directMemoryCacheAlignment);
directArenas[i] = arena;
metrics.add(arena);
}
directArenaMetrics = Collections.unmodifiableList(metrics);
} else {
directArenas = null;
directArenaMetrics = Collections.emptyList();
}
metric = new PooledByteBufAllocatorMetric(this);
}
分配直接内存入口
/**
* 申请分配直接内存 入口
* @param initialCapacity 业务需求内存大小
* @param maxCapacity 内存最大限制
* @return ByteBuf netty中内存对象
*/
@Override
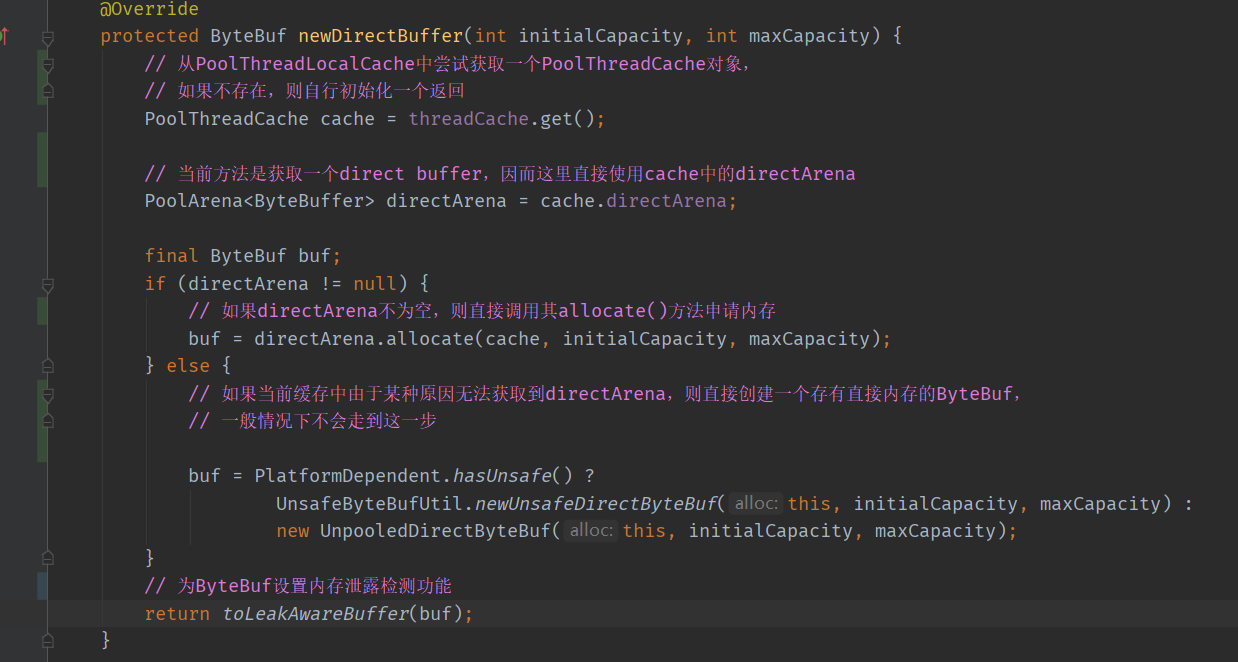
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
// 若当前线程没有PoolThreadCache 则创建一份 PoolThreadCache
// 若当前线程有 则直接获取
PoolThreadCache cache = threadCache.get();
// 拿到当前线程cache中绑定的directArena
PoolArena<ByteBuffer> directArena = cache.directArena;
final ByteBuf buf;
// 这个条件正常逻辑 都会成立
if (directArena != null) {
//这是咱们的核心入口 ******
// 参数1: cache 当前线程相关的PoolThreadCache对象
// 参数2:initialCapactiy 业务层需要的内存容量
// 参数3:maxCapacity 最大内存大小
buf = directArena.allocate(cache, initialCapacity, maxCapacity);
} else {
// 一般不会走到这里,不用看
buf = PlatformDependent.hasUnsafe() ?
UnsafeByteBufUtil.newUnsafeDirectByteBuf(this, initialCapacity, maxCapacity) :
new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
return toLeakAwareBuffer(buf);
}
缓存架构
回顾一下有关内存分配几个非常重要的概念,分别是arena、chunk、page、subpage。
接下来我们看一下什么是arena:
在每个线程去申请内存的时候,他首先会通过ThreadLocal 这种方式去获得当前线程的PoolThreadCache对象,

然后调用他的allocate方法去申请内存,他一共分为两部分,
-
一个是cache,在申请内存的时候首先会尝试从缓存中获取,
-
另外一个就是arena,如果从缓存中获取不到对应的内存,那么就要通过arena从内存池中获取。
本地线程存储
虽然提供了多个PoolArena减少线程间的竞争,但是难免还是会存在锁竞争,所以需要利用ThreaLocal进一步优化,把已申请的内存放入到ThreaLocal自然就没有竞争了。
大体思路是:
- 在ThreadLocal里面放一个PoolThreadCache对象
- 然后释放的内存都放入到PoolThreadCache里面,下次申请先从PoolThreadCache获取。
但是,如果thread1申请了一块内存,然后传到thread2在线程释放,这个Netty在内存holder对象里面会引用PoolThreadCache,所以还是会释放到thread1里。
PoolThreadCache
PoolThreadCache是Netty内存管理中能够实现高效内存申请和释放的一个重要原因,
Netty会为每一个线程都维护一个PoolThreadCache对象,
当进行内存申请时,首先会尝试从PoolThreadCache中申请,如果无法从中申请到,则会尝试从Netty的公共内存池中申请。
PoolThreadCache数据结构
PoolThreadCache的数据结构与PoolArena的主要属性结构非常相似,但细微位置有很大的不同。
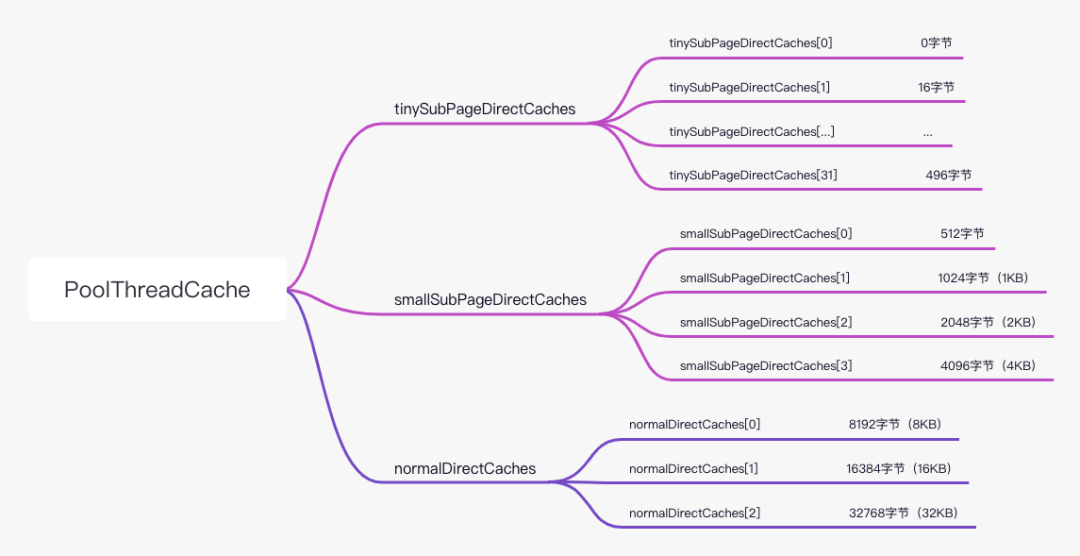
在PoolThreadCache中,其维护了三个数组(我们以直接内存的缓存方式为例进行讲解),

这三个数组分别保存了tiny,small和normal类型的缓存数据,
不同于PoolArena的使用PoolSubpage和PoolChunk进行不同规格的内存的维护,这里不同规格的内存,三个数组都是使用MemoryRegionCache类型
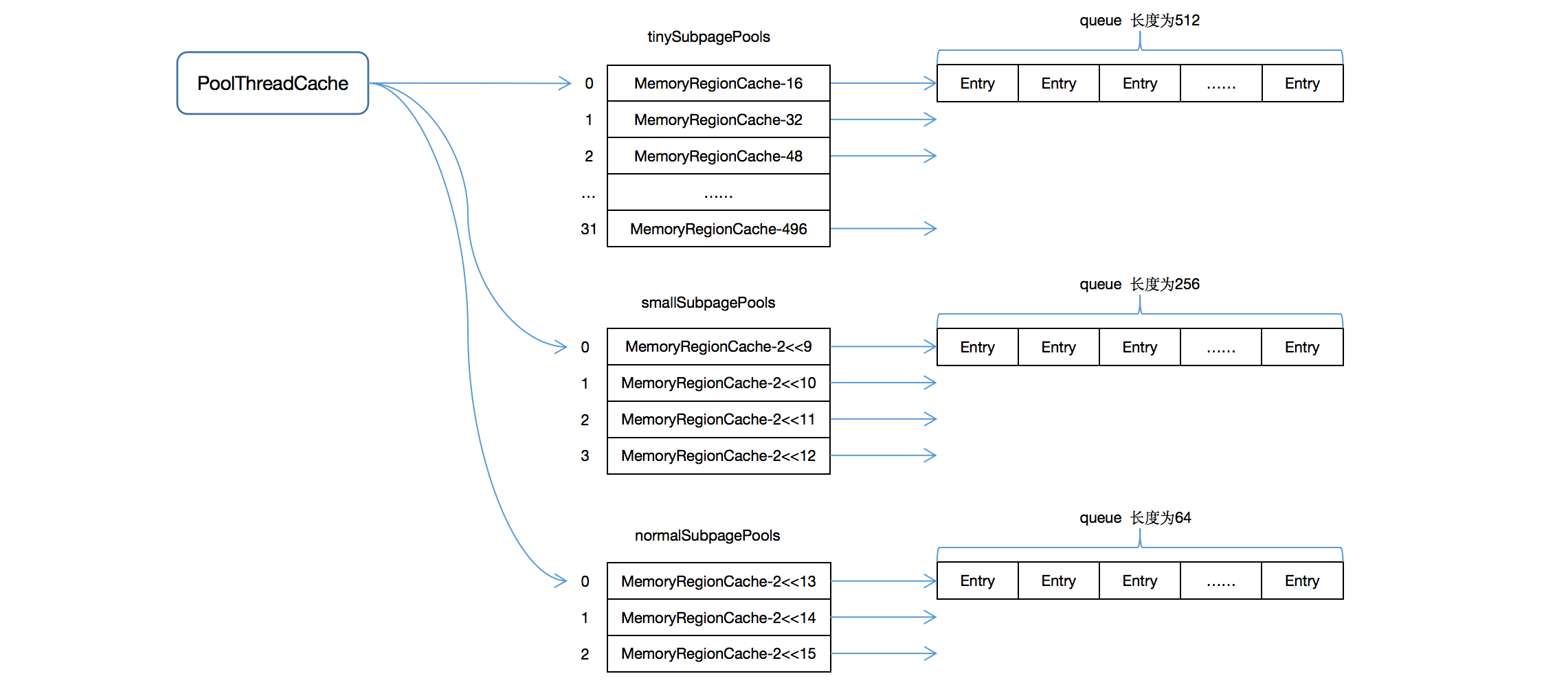
每个元素的桶(内部结构为队列)的长度,是一个有界队列,不同规格的桶,长度不一样:
- 对于tiny类型的缓存,该队列的长度为512,
- 对于small类型的缓存,该队列的长度为256,
- 对于normal类型的缓存,该队列的长度为64。
在进行内存释放的时候,如果一种规格的队列桶已经满了,那么就会将该内存块释放回PoolArena中。
MemoryRegionCache
cache数组中的一个元素,类型为MemoryRegionCache,主要成为为队列 bucket,和内存的规格

队列桶中的元素统一使用的是Entry这种数据结构,该结构的主要属性如下:

PoolThreadCache中维护每一个内存块最终都是使用的一个Entry对象来进行的,
-
缓存Entry最重要的属性是chunk和handle,
-
chunk记录了当前内存块所在的PoolChunk对象,
一个handle 是一个long占8个字节,其由低位的4个字节和高位的4个字节组成,
低位的4个字节表示当前page(8K)在PoolChunk(16M)中memoryMap映射数组中的下标索引;
而高位的4个字节则表示当前需要分配的内存在PoolSubPage所代表的8KB内存中的位图索引。
对于大于8KB的内存分配,不涉及PoolSubPage结构,因而高位四个字节的位图索引为0, 而低位的4个字节page序列在chunk中的位置索引;
对于低于8KB的内存分配,其会使用一个PoolSubPage来表示整个8KB内存,因而需要一个位图索引来表示subpage在page中的位图索引。
PoolThreadCache的初始化
对于PoolThreadCache的初始化,其初始化过程是与PoolThreadLocalCache所绑定的。
PoolThreadLocalCache的作用与Java中的ThreadLocal的作用非常类似,核心方法大致如下:
-
initialValue()方法,用于在无法从PoolThreadLocalCache中获取数据时,通过调用该方法初始化一个。
-
get()方法,用于在无法从PoolThreadLocalCache中获取数据时
-
remove()方法,分别用于从PoolThreadLocalCache中将当前绑定的数据给清除。
首先看看获取PoolThreadCache初始化的入口代码:
如下是PoolThreadLocalCache.initialValue()方法的源码
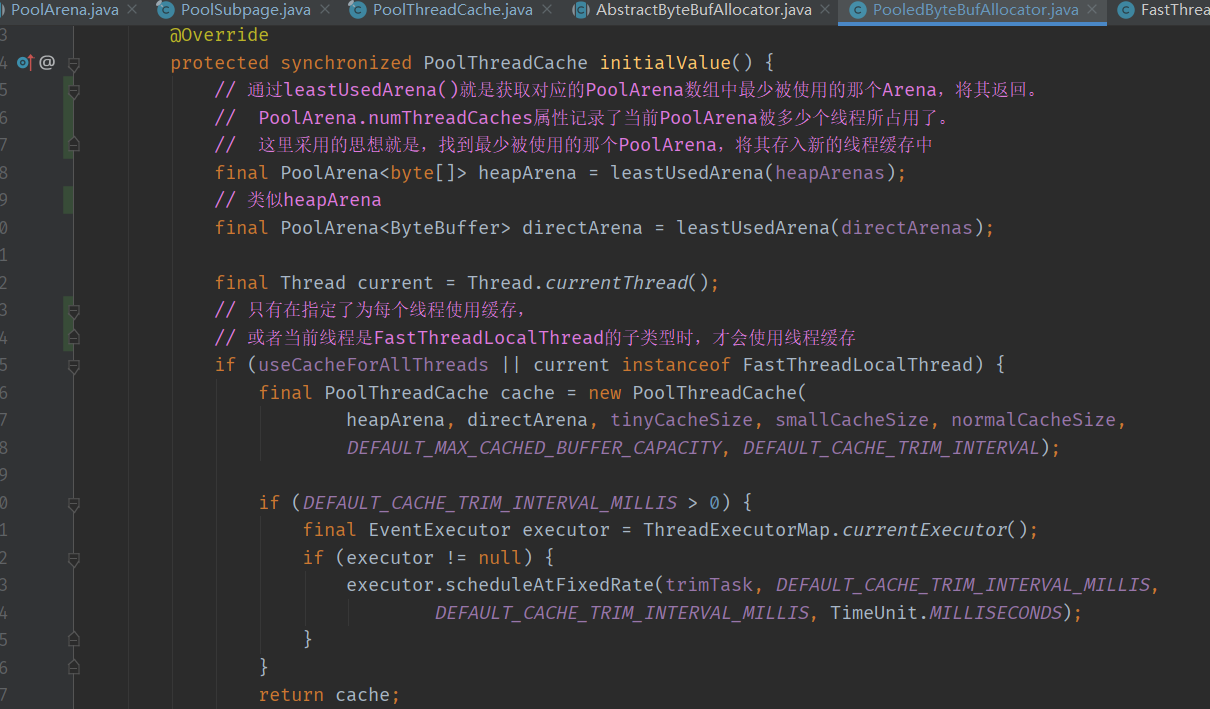

首先会根据PoolArena的属性numThreadCaches查找PoolArena数组中被最少线程占用的那个arena,
然后将其封装到一个新建的PoolThreadCache中, 并且返回

获得PoolThreadCache后,再通过PoolThreadCache获取PoolArena,再调用 PoolArena#allocate方法



大致的步骤:
-
PoolThreadCache是将其分为tiny,small和normal三种不同的方法来调用的,首先根据规格化后的内容规模,去计算不同类型的slot槽位
-
在对应的内存数组中,相对应的slot槽位找到MemoryRegionCache对象之后,通过调用allocate()方法来申请内存,
-
申请完之后还会检查当前缓存申请次数是否达到了8192次,达到了则对缓存中使用的内存块进行检测,将较少使用的内存块返还给PoolArena。
根据规模计算不同类型的slot槽位

拿到槽位后,获取不同类型的 MemoryRegionCache对象


MemoryRegionCache.allocate()
下面我们继续看一下MemoryRegionCache.allocate()方法是如何申请内存的:

MemoryRegionCache 是从队列中取entry,如果取到了,则使用该内存块初始化一个ByteBuf对象。
PoolThreadCache会对其内存块使用次数进行计数,这么做的目是什么呢?
主要是目前已经线程隔离了,防止一个线程占用太多的资源,其他线程抢不到内存。
所以,如果一个ThreadPoolCache所缓存的内存块使用次数较少,那么就可以将其释放到PoolArena中,以便于其他线程可以申请使用。
PoolThreadCache会在其内存总的申请次数达到8192时,遍历其所有的MemoryRegionCache,然后调用其trim()方法进行内存释放,
MemoryRegionCache#trim()
如下是该方法的源码:



内存释放
还要补充5000字
对象池
只要知道一个PoolChunk里面的页索引,申请到的空间容量,如果是小内存还需要知道页内索引, 就可以定位到这块内存了。
这些信息, 都保存到PooledByteBuf对象
protected PoolChunk<T> chunk;
protected long handle; //索引
protected T memory; //chunk.memory
protected int offset; //偏移量
protected int length;
int maxLength;
PoolThreadCache cache;
所以再申请完内存后,还需要创建这么个对象来保存这些信息。
在Netty中会有一个轻量级的对象池(Recycler)来保存PooledByteBuf对象。
这里用了ThreadLocal来减少锁的争用,所以同样的会出现不通线程之间申请与释放的问题。
在这个地方Netty的处理方式为:它为每个线程维持一个对象队列,同时又有一个全局的队列来保存释放的对象。
当线程从自身的队列拿不到对象时,会从全局队列中转移一部分对象到自身队列中去。
内存释放
Netty中使用引用计数机制来管理资源,
ByteBuf实现了ReferenceCounted接口,当实例化ByteBuf对象时,引用计数加1。
当应用代码保持一个对象引用时,会调用retain方法将计数增加1,对象使用完毕进行释放,调用release将计数器减1.
当引用计数变为0时,对象将释放所有的资源,返回内存池。
内存泄露检测
内存泄露检测的原理是利用虚引用,当一个对象只被虚引用指向时,
在GC的时候会被自动放到了一个ReferenceQueue里面,每次去申请内存的时候最后都会根据检测策略去ReferenceQueue里面判断释放有泄露的对象。
#AbstractByteBufAllocator
protected static ByteBuf toLeakAwareBuffer(ByteBuf buf) {
ResourceLeakTracker<ByteBuf> leak;
switch (ResourceLeakDetector.getLevel()) {
case SIMPLE:
leak = AbstractByteBuf.leakDetector.track(buf);
if (leak != null) {
buf = new SimpleLeakAwareByteBuf(buf, leak);
}
break;
case ADVANCED:
case PARANOID:
leak = AbstractByteBuf.leakDetector.track(buf);
if (leak != null) {
buf = new AdvancedLeakAwareByteBuf(buf, leak);
}
break;
default:
break;
}
return buf;
}
netty支持下面四种级别,使用-Dio.netty.leakDetectionLevel=advanced可以调节等级。
- 禁用(DISABLED) - 完全禁止泄露检测,省点消耗。
- 简单(SIMPLE) - 默认等级,告诉我们取样的1%的ByteBuf是否发生了泄露,但总共一次只打印一次,看不到就没有了。
- 高级(ADVANCED) - 告诉我们取样的1%的ByteBuf发生泄露的地方。每种类型的泄漏(创建的地方与访问路径一致)只打印一次。对性能有影响。
- 偏执(PARANOID) - 跟高级选项类似,但此选项检测所有ByteBuf,而不仅仅是取样的那1%。对性能有绝大的影响。
Handler中的内存处理机制
Netty中有handler链,消息是由本Handler传到下一个Handler。
所以Netty引入了一个规则,谁是最后使用者,谁负责释放。
根据谁最后使用谁负责释放的原则,每个Handler对消息可能有三种处理方式
-
对原消息不做处理,调用 ctx.fireChannelRead(msg)把原消息往下传,那不用做什么释放。
-
将原消息转化为新的消息并调用 ctx.fireChannelRead(newMsg)往下传,那必须把原消息release掉。
-
如果已经不再调用ctx.fireChannelRead(msg)传递任何消息,那更要把原消息release掉。
假设每一个Handler都把消息往下传,Handler并也不知道谁是启动Netty时所设定的Handler链的最后一员,
所以Netty在Handler链的最末补了一个TailHandler,如果此时消息仍然是ReferenceCounted类型就会被release掉。
未完待续
完整演示与介绍,请参考40岁老架构师尼恩的视频:《彻底穿透netty架构与源码》
参考文献
https://blog.csdn.net/qq_41652863/article/details/99095769#PoolArena
http://anyteam.me/netty-memory-allocation-PoolArena/
http://www.programmersought.com/article/9322400832/
https://www.jianshu.com/p/4856bd30dd56
https://juejin.im/post/5d4f6d74f265da03e83b5e07
https://www.jianshu.com/p/550704d5a628
https://blog.csdn.net/ClarenceZero/article/details/112971237
https://juejin.cn/post/6922783552580878349
https://blog.csdn.net/m0_64383449/article/details/121707936
https://blog.csdn.net/ClarenceZero/article/details/112971237
https://blog.csdn.net/cq_pf/article/details/107794567
https://blog.csdn.net/wangwei19871103/article/details/104341612
https://people.freebsd.org/~jasone/jemalloc/bsdcan2006/jemalloc.pdf
https://juejin.cn/post/6922783552580878349
https://blog.csdn.net/wangwei19871103/article/details/104341612
https://blog.csdn.net/wangwei19871103/article/details/104341612
http://blog.ouyangsihai.cn/zhi-cheng-bai-wan-ji-bing-fa-netty-ru-he-shi-xian-gao-xing-neng-nei-cun-guan-li.html
https://www.cnblogs.com/wuzhenzhao/p/11290533.html
http://www.javashuo.com/article/p-vtghkove-ez.html
https://blog.csdn.net/gaoliang1719/article/details/115649976
https://www.jianshu.com/p/a97724153d88
https://blog.csdn.net/helloworld_ptt/article/details/115599230
http://www.shangmayuan.com/a/2b8575b1f6754fae8e6b7d86.html
https://zhuanlan.zhihu.com/p/321780626
https://blog.csdn.net/helloworld_ptt/article/details/115599230
https://blog.csdn.net/helloworld_ptt/article/details/115599230
http://www.shangmayuan.com/a/2b8575b1f6754fae8e6b7d86.html
https://www.cnblogs.com/s686zhou/p/15701801.html
https://my.oschina.net/zhangxufeng/blog/3040834
https://my.oschina.net/zhangxufeng/blog/3030653
https://zhuanlan.zhihu.com/p/115521554

 浙公网安备 33010602011771号
浙公网安备 33010602011771号