Redis集群 - 图解 - 秒懂(史上最全)
文章很长,而且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《尼恩Java面试宝典 最新版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
Redis集群 - 图解 - 秒懂(史上最全)
说明:
本文,以史上最为清晰的笔法,介绍清楚了Redis集群。
看完本文,涉及到Redis集群的架构类面试题目,按照本文的思路去回答,一定是120分。
Redis的架构模式分类
-
单节点模式
-
主从模式
-
哨兵模式
-
集群模式
单节点模式

特点:简单
问题:
1、内存容量有限 2、处理能力有限 3、无法高可用。
主从模式
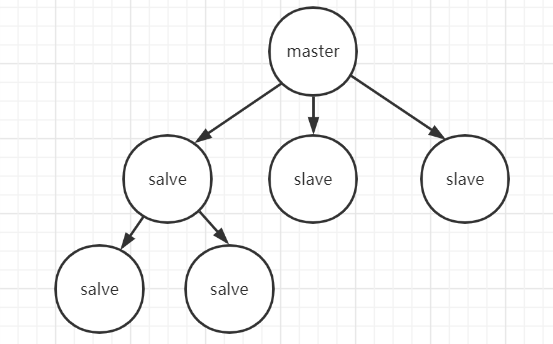
Redis 的复制(replication)功能允许用户根据一个 Redis 服务器来创建任意多个该服务器的复制品,其中被复制的服务器为主服务器(master),而通过复制创建出来的服务器复制品则为从服务器(slave)。 只要主从服务器之间的网络连接正常,主从服务器两者会具有相同的数据,主服务器就会一直将发生在自己身上的数据更新同步 给从服务器,从而一直保证主从服务器的数据相同。
特点:
1、master/slave 角色
2、master/slave 数据相同
3、降低 master 读压力, 读取工作转交从库
哨兵模式
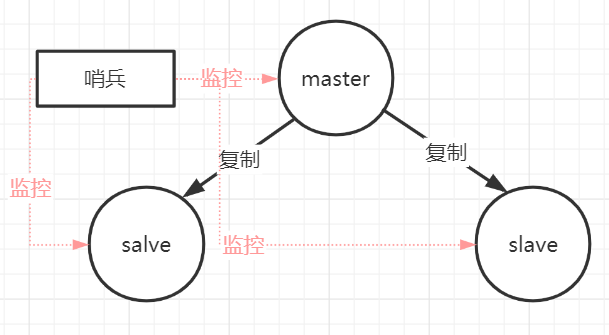
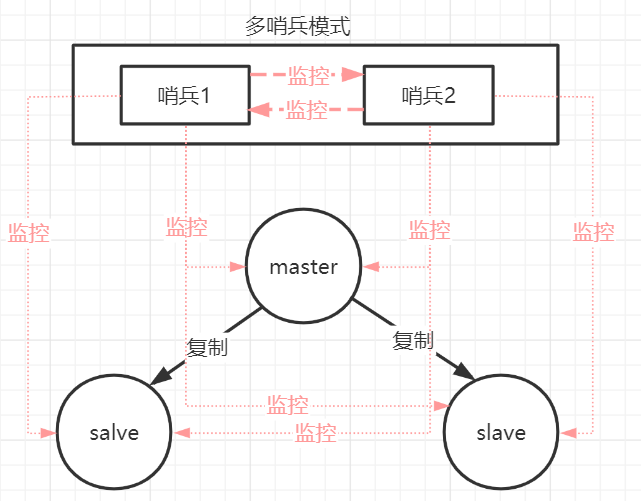
哨兵本身也有单点故障的问题,可以使用多个哨兵进行监控,哨兵不仅会监控redis集群,哨兵之间也会相互监控。每一个哨兵都是一个独立的进程,作为进程,它会独立运行。
Redis sentinel 是一个分布式系统中监控 redis 主从服务器,并在主服务器下线时自动进行故障转移。
Redis sentinel 其中三个特性:
- 监控(Monitoring):
Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
- 提醒(Notification):
当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic failover):
当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作。
特点:
-
1、保证高可用
-
2、监控各个节点
-
3、自动故障迁移
缺点:
主从模式,切换需要时间丢数据
没有解决 master 写的压力
集群模式
集群模式方案主要包括以下几个:
- 客户端分片
- 代理分片
- 服务端分片
- 代理模式和服务端分片相结合的模式
代理分片包括:
-
Codis
-
Twemproxy
服务端分片包括:
- Redis Cluster
它们还可以用是否中心化来划分,其中客户端分片、Redis Cluster属于无中心化的集群方案,Codis、Tweproxy属于中心化的集群方案。
是否中心化是指客户端访问多个Redis节点时,是直接访问还是通过一个中间层Proxy来进行操作,直接访问的就属于无中心化的方案,通过中间层Proxy访问的就属于中心化的方案,它们有各自的优劣,下面分别来介绍。
集群的必要性
所谓的集群,就是通过添加服务器的数量,提供相同的服务,从而让服务器达到一个稳定、高效的状态。
问题:我们已经部署好了redis,并且能启动一个redis,实现数据的读写,为什么还要学习redis集群?
答:
(1)单个redis存在不稳定性。当redis服务宕机了,就没有可用的服务了。
(2)单个redis的读写能力是有限的。
总结:redis集群是为了强化redis的读写能力。
如何学习redis集群
说明:
(1)redis集群中,每一个redis称之为一个节点。
(2)redis集群中,有两种类型的节点:主节点(master)、从节点(slave)。
(3)redis集群,是基于redis主从复制实现。
所以,学习redis集群,就是从学习redis主从模式开始的。
而学习主从模式,需要从redis主从复制开始。
redis主从复制
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点。
默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
主从复制的使用场景
主从复制的作用
主从复制的作用主要包括:
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
主从(master-slave)架构涉及到主从复制
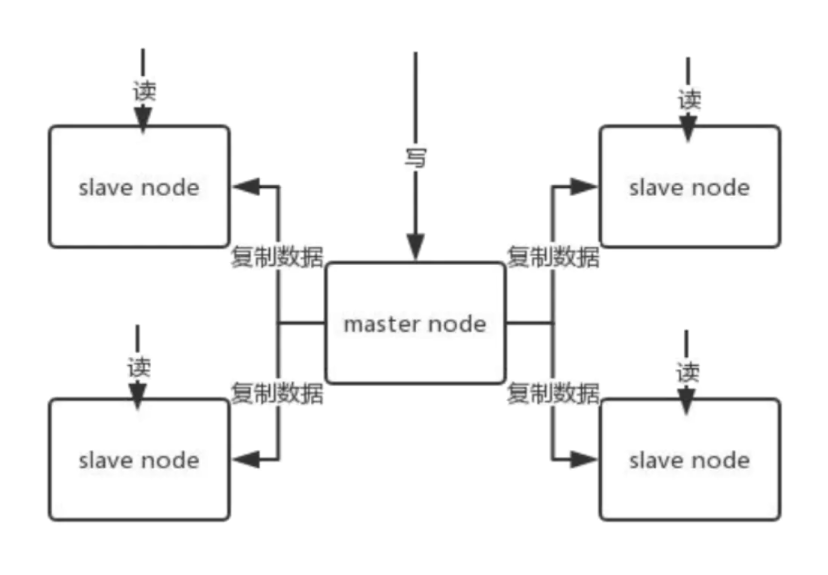
单机的 redis,能够承载的 QPS 大概就在上万到几万不等。对于缓存来说,一般都是用来支撑读高并发的。
因此架构做成主从(master-slave)架构,一主多从,主负责写,并且将数据复制到其它的 slave 节点,从节点负责读。所有的读请求全部走从节点。这样也可以很轻松实现水平扩容,支撑读高并发。
为了更直观的理解主从复制,在介绍其内部原理之前,先说明我们需要如何操作才能开启主从复制。
建立复制
需要注意,主从复制的开启,完全是在从节点发起的;不需要我们在主节点做任何事情。
从节点开启主从复制,有3种方式:
(1)配置文件
在从服务器的配置文件中加入:slaveof
(2)启动命令
redis-server启动命令后加入 --slaveof
(3)客户端命令
Redis服务器启动后,直接通过客户端执行命令:slaveof
上述3种方式是等效的,下面以客户端命令的方式为例,看一下当执行了slaveof后,Redis主节点和从节点的变化。
主从复制实例
准备工作:启动两个节点
方便起见,实验所使用的主从节点是在一台机器上的不同Redis实例,其中主节点监听6379端口,从节点监听6380端口;从节点监听的端口号可以在配置文件中修改:

启动后可以看到:

两个Redis节点启动后(分别称为6379节点和6380节点),默认都是主节点。
建立复制关系
此时在6380节点执行slaveof命令,使之变为从节点:

观察效果
下面验证一下,在主从复制建立后,主节点的数据会复制到从节点中。
(1)首先在从节点查询一个不存在的key:

(2)然后在主节点中增加这个key:

(3)此时在从节点中再次查询这个key,会发现主节点的操作已经同步至从节点:

(4)然后在主节点删除这个key:

(5)此时在从节点中再次查询这个key,会发现主节点的操作已经同步至从节点:

断开复制
通过slaveof
从节点执行slaveof no one后,打印日志如下所示;可以看出断开复制后,从节点又变回为主节点。

主节点打印日志如下:

核心原理: 主从复制的核心原理
上面一节中,介绍了如何操作可以建立主从关系;本小节将介绍主从复制的实现原理。
1 当启动一个 slave node 的时候,它会发送一个 PSYNC 命令给 master node。
2 如果这是 slave node 初次连接到 master node,那么会触发一次 full resynchronization 全量复制。
此时 master 会启动一个后台线程,开始生成一份 RDB 快照文件,同时还会将从客户端 client 新收到的所有写命令缓存在内存中。RDB 文件生成完毕后, master 会将这个 RDB 发送给 slave,
slave接收到RDB , 会先写入本地磁盘,然后再从本地磁盘加载到内存中,
3 接着 master 会将内存中缓存的写命令发送到 slave,slave 也会同步这些数据。
如果slave node跟 master node 有网络故障,断开了连接,会自动重连,连接之后 master node 仅会复制给 slave 部分缺少的数据。
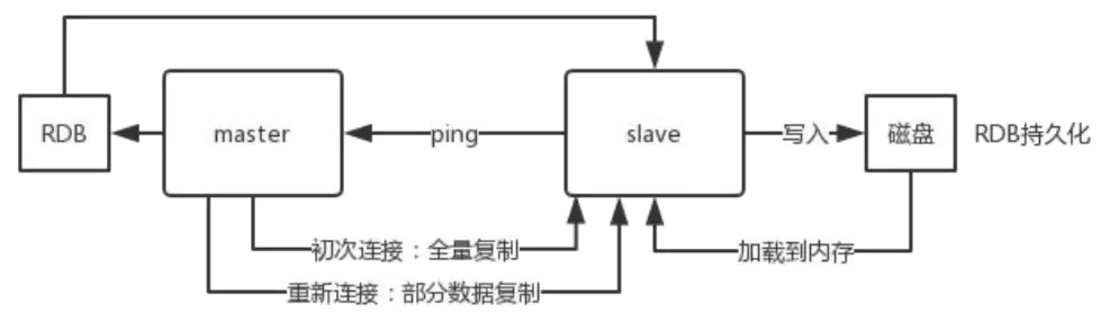
主从复制过程大体可以分为3个阶段:
- 连接建立阶段(即准备阶段)
- 数据同步阶段
- 命令传播阶段;
下面分别进行介绍。
连接建立阶段
该阶段的主要作用是在主从节点之间建立连接,为数据同步做好准备。
步骤1:保存主节点信息
从节点服务器内部维护了两个字段,即masterhost和masterport字段,用于存储主节点的ip和port信息。
需要注意的是,slaveof是异步命令,从节点完成主节点ip和port的保存后,向发送slaveof命令的客户端直接返回OK,实际的复制操作在这之后才开始进行。
这个过程中,可以看到从节点打印日志如下:

步骤2:建立socket连接
从节点每秒1次调用复制定时函数replicationCron(),如果发现了有主节点可以连接,便会根据主节点的ip和port,创建socket连接。
如果连接成功,则:
- 从节点:
为该socket建立一个专门处理复制工作的文件事件处理器,负责后续的复制工作,如接收RDB文件、接收命令传播等。
- 主节点:
接收到从节点的socket连接后(即accept之后),为该socket创建相应的客户端状态,并将从节点看做是连接到主节点的一个客户端,后面的步骤会以从节点向主节点发送命令请求的形式来进行。
这个过程中,从节点打印日志如下:

步骤3:发送ping命令
从节点成为主节点的客户端之后,发送ping命令进行首次请求,目的是:检查socket连接是否可用,以及主节点当前是否能够处理请求。
从节点发送ping命令后,可能出现3种情况:
(1)返回pong:说明socket连接正常,且主节点当前可以处理请求,复制过程继续。
(2)超时:一定时间后从节点仍未收到主节点的回复,说明socket连接不可用,则从节点断开socket连接,并重连。
(3)返回pong以外的结果:如果主节点返回其他结果,如正在处理超时运行的脚本,说明主节点当前无法处理命令,则从节点断开socket连接,并重连。
在主节点返回pong情况下,从节点打印日志如下:

步骤4:身份验证
如果从节点中设置了masterauth选项,则从节点需要向主节点进行身份验证;没有设置该选项,则不需要验证。从节点进行身份验证是通过向主节点发送auth命令进行的,auth命令的参数即为配置文件中的masterauth的值。
如果主节点设置密码的状态,与从节点masterauth的状态一致(一致是指都存在,且密码相同,或者都不存在),则身份验证通过,复制过程继续;如果不一致,则从节点断开socket连接,并重连。
步骤5:发送从节点端口信息
身份验证之后,从节点会向主节点发送其监听的端口号(前述例子中为6380),主节点将该信息保存到该从节点对应的客户端的slave_listening_port字段中;该端口信息除了在主节点中执行info Replication时显示以外,没有其他作用。
数据同步阶段
主从节点之间的连接建立以后,便可以开始进行数据同步,该阶段可以理解为从节点数据的初始化。
具体执行的方式是:从节点向主节点发送psync命令(Redis2.8以前是sync命令),开始同步。
数据同步阶段是主从复制最核心的阶段,根据主从节点当前状态的不同,可以分为全量复制和部分复制。
在Redis2.8以前,从节点向主节点发送sync命令请求同步数据,此时的同步方式是全量复制;
在Redis2.8及以后,从节点可以发送psync命令请求同步数据,此时根据主从节点当前状态的不同,同步方式可能是全量复制或部分复制。后文介绍以Redis2.8及以后版本为例。
- 全量复制:用于初次复制或其他无法进行部分复制的情况,将主节点中的所有数据都发送给从节点,是一个非常重型的操作。
- 部分复制:用于网络中断等情况后的复制,只将中断期间主节点执行的写命令发送给从节点,与全量复制相比更加高效。需要注意的是,如果网络中断时间过长,导致主节点没有能够完整地保存中断期间执行的写命令,则无法进行部分复制,仍使用全量复制。
全量复制
Redis通过psync命令进行全量复制的过程如下:
(1)从节点判断无法进行部分复制,向主节点发送全量复制的请求;或从节点发送部分复制的请求,但主节点判断无法进行部分复制;具体判断过程需要在讲述了部分复制原理后再介绍。
(2)主节点收到全量复制的命令后,执行bgsave,在后台生成RDB文件,并使用一个缓冲区(称为复制缓冲区)记录从现在开始执行的所有写命令
(3)主节点的bgsave执行完成后,将RDB文件发送给从节点;从节点首先清除自己的旧数据,然后载入接收的RDB文件,将数据库状态更新至主节点执行bgsave时的数据库状态
(4)主节点将前述复制缓冲区中的所有写命令发送给从节点,从节点执行这些写命令,将数据库状态更新至主节点的最新状态
(5)如果从节点开启了AOF,则会触发bgrewriteaof的执行,从而保证AOF文件更新至主节点的最新状态
下面是执行全量复制时,主从节点打印的日志;可以看出日志内容与上述步骤是完全对应的。
主节点的打印日志如下:

从节点打印日志如下图所示:

其中,有几点需要注意:从节点接收了来自主节点的89260个字节的数据;从节点在载入主节点的数据之前要先将老数据清除;从节点在同步完数据后,调用了bgrewriteaof。
通过全量复制的过程可以看出,全量复制是非常重型的操作:
(1)主节点通过bgsave命令fork子进程进行RDB持久化,该过程是非常消耗CPU、内存(页表复制)、硬盘IO的;
(2)主节点通过网络将RDB文件发送给从节点,对主从节点的带宽都会带来很大的消耗
(3)从节点清空老数据、载入新RDB文件的过程是阻塞的,无法响应客户端的命令;如果从节点执行bgrewriteaof,也会带来额外的消耗
部分复制
由于全量复制在主节点数据量较大时效率太低,因此Redis2.8开始提供部分复制,用于处理网络中断时的数据同步。
部分复制的实现,依赖于三个重要的概念:
(1)复制偏移量
主节点和从节点分别维护一个复制偏移量(offset),代表的是主节点向从节点传递的字节数;主节点每次向从节点传播N个字节数据时,主节点的offset增加N;从节点每次收到主节点传来的N个字节数据时,从节点的offset增加N。
offset用于判断主从节点的数据库状态是否一致:如果二者offset相同,则一致;如果offset不同,则不一致,此时可以根据两个offset找出从节点缺少的那部分数据。例如,如果主节点的offset是1000,而从节点的offset是500,那么部分复制就需要将offset为501-1000的数据传递给从节点。而offset为501-1000的数据存储的位置,就是下面要介绍的复制积压缓冲区。
(2)复制积压缓冲区
复制积压缓冲区是由主节点维护的、固定长度的、先进先出(FIFO)队列,默认大小1MB;当主节点开始有从节点时创建,其作用是备份主节点最近发送给从节点的数据。注意,无论主节点有一个还是多个从节点,都只需要一个复制积压缓冲区。
在命令传播阶段,主节点除了将写命令发送给从节点,还会发送一份给复制积压缓冲区,作为写命令的备份;除了存储写命令,复制积压缓冲区中还存储了其中的每个字节对应的复制偏移量(offset)。由于复制积压缓冲区定长且是先进先出,所以它保存的是主节点最近执行的写命令;时间较早的写命令会被挤出缓冲区。
由于该缓冲区长度固定且有限,因此可以备份的写命令也有限,当主从节点offset的差距过大超过缓冲区长度时,将无法执行部分复制,只能执行全量复制。反过来说,为了提高网络中断时部分复制执行的概率,可以根据需要增大复制积压缓冲区的大小(通过配置repl-backlog-size);例如如果网络中断的平均时间是60s,而主节点平均每秒产生的写命令(特定协议格式)所占的字节数为100KB,则复制积压缓冲区的平均需求为6MB,保险起见,可以设置为12MB,来保证绝大多数断线情况都可以使用部分复制。
从节点将offset发送给主节点后,主节点根据offset和缓冲区大小决定能否执行部分复制:
- 如果offset偏移量之后的数据,仍然都在复制积压缓冲区里,则执行部分复制;
- 如果offset偏移量之后的数据已不在复制积压缓冲区中(数据已被挤出),则执行全量复制。
(3)服务器运行ID(runid)
每个Redis节点(无论主从),在启动时都会自动生成一个随机ID(每次启动都不一样),由40个随机的十六进制字符组成;runid用来唯一识别一个Redis节点。通过info Server命令,可以查看节点的runid:

主从节点初次复制时,主节点将自己的runid发送给从节点,从节点将这个runid保存起来;当断线重连时,从节点会将这个runid发送给主节点;主节点根据runid判断能否进行部分复制:
- 如果从节点保存的runid与主节点现在的runid相同,说明主从节点之前同步过,主节点会继续尝试使用部分复制(到底能不能部分复制还要看offset和复制积压缓冲区的情况);
- 如果从节点保存的runid与主节点现在的runid不同,说明从节点在断线前同步的Redis节点并不是当前的主节点,只能进行全量复制。
psync命令的执行
在了解了复制偏移量、复制积压缓冲区、节点运行id之后,本节将介绍psync命令的参数和返回值,从而说明psync命令执行过程中,主从节点是如何确定使用全量复制还是部分复制的。
psync命令的执行过程可以参见下图(图片来源:《Redis设计与实现》):
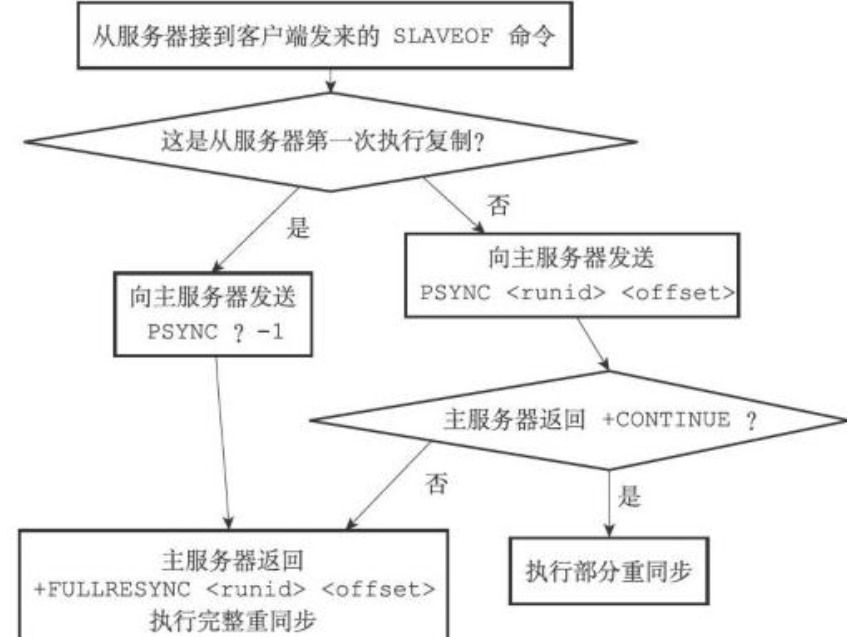
(1)首先,从节点根据当前状态,决定如何调用psync命令:
- 如果从节点之前未执行过slaveof或最近执行了slaveof no one,则从节点发送命令为psync ? -1,向主节点请求全量复制;
- 如果从节点之前执行了slaveof,则发送命令为psync
,其中runid为上次复制的主节点的runid,offset为上次复制截止时从节点保存的复制偏移量。
(2)主节点根据收到的psync命令,及当前服务器状态,决定执行全量复制还是部分复制:
- 如果主节点版本低于Redis2.8,则返回-ERR回复,此时从节点重新发送sync命令执行全量复制;
- 如果主节点版本够新,且runid与从节点发送的runid相同,且从节点发送的offset之后的数据在复制积压缓冲区中都存在,则回复+CONTINUE,表示将进行部分复制,从节点等待主节点发送其缺少的数据即可;
- 如果主节点版本够新,但是runid与从节点发送的runid不同,或从节点发送的offset之后的数据已不在复制积压缓冲区中(在队列中被挤出了),则回复+FULLRESYNC
,表示要进行全量复制,其中runid表示主节点当前的runid,offset表示主节点当前的offset,从节点保存这两个值,以备使用。
命令传播阶段
数据同步阶段完成后,主从节点进入命令传播阶段;在这个阶段主节点将自己执行的写命令发送给从节点,从节点接收命令并执行,从而保证主从节点数据的一致性。
在命令传播阶段,除了发送写命令,主从节点还维持着心跳机制:PING和REPLCONF ACK。
redis主从模式
redis主从模式架构
在软件架构中,master-slave(主从模式)是使用比较多的一种架构方式;
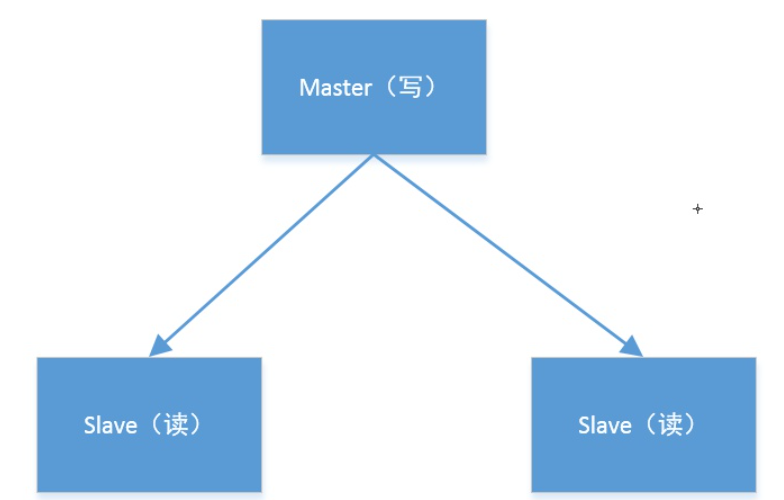
主(master)和 从(slave)部署在不同的服务器上,当主节点服务器写入数据时会同步到从节点的服务器上,一般主节点负责写入数据,从节点负责读取数据
所以,适用于读写分离的高并发场景:客户端可以通过主写入,通过从读取。
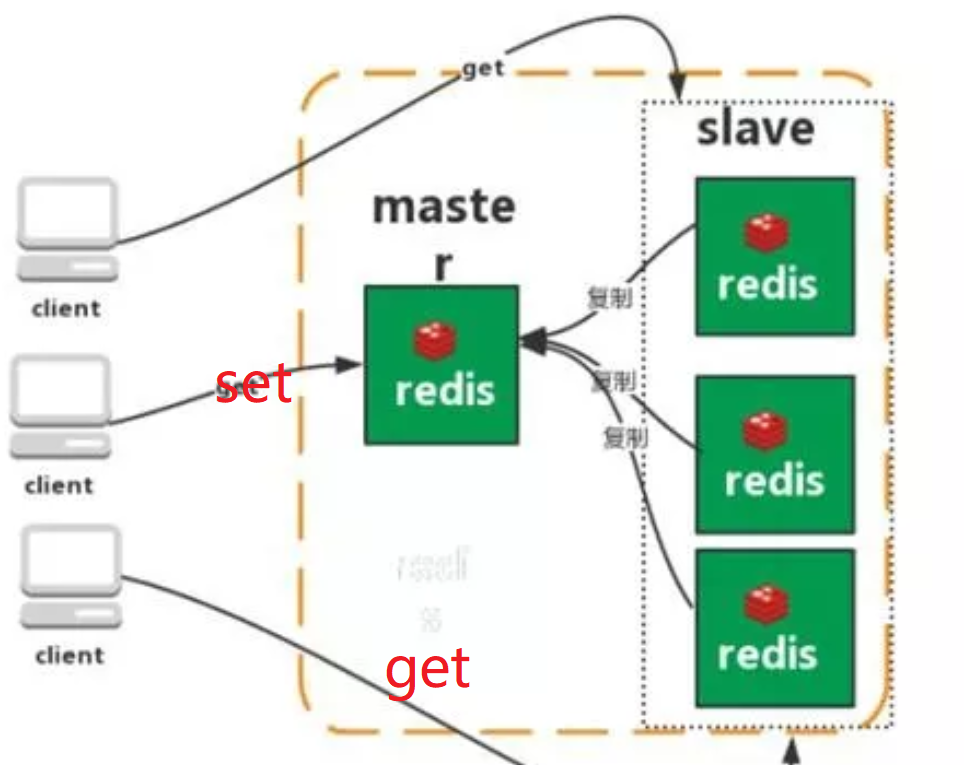
主从集群的搭建
单机配置一主多从
- 主服务器通过默认的redis.conf启动redis-server
- 复制主服务器的redis.conf为两个新的文件redis_slave1.conf和redis_slave2.conf
- 分别添加如下配置
# 端口
# 或者port 6381
port 6382
# AOF和快照文件文件夹
# dir /usr/local/var/db/redis_slave1/
dir /usr/local/var/db/redis_slave2/
# 从节点要跟随的主节点
slaveof 127.0.0.1 6379
# 如果设置了密码,就要设置
masterauth master-password
- 从服务器分别通过redis_slave1.conf和redis_slave2.conf启动
集群的运行结果(部分)
# 主节点
32314:M 13 Feb 2019 18:19:34.807 * Replica 127.0.0.1:6381 asks for synchronization
32314:M 13 Feb 2019 18:19:34.807 * Full resync requested by replica 127.0.0.1:6381
32314:M 13 Feb 2019 18:19:34.807 * Starting BGSAVE for SYNC with target: disk
32314:M 13 Feb 2019 18:19:34.807 * Background saving started by pid 33175
33175:C 13 Feb 2019 18:19:34.808 * DB saved on disk
32314:M 13 Feb 2019 18:19:34.838 * Background saving terminated with success
32314:M 13 Feb 2019 18:19:34.839 * Synchronization with replica 127.0.0.1:6381 succeeded
32314:M 13 Feb 2019 18:22:01.275 * Replica 127.0.0.1:6382 asks for synchronization
32314:M 13 Feb 2019 18:22:01.275 * Full resync requested by replica 127.0.0.1:6382
32314:M 13 Feb 2019 18:22:01.275 * Starting BGSAVE for SYNC with target: disk
32314:M 13 Feb 2019 18:22:01.276 * Background saving started by pid 33436
33436:C 13 Feb 2019 18:22:01.277 * DB saved on disk
32314:M 13 Feb 2019 18:22:01.359 * Background saving terminated with success
32314:M 13 Feb 2019 18:22:01.360 * Synchronization with replica 127.0.0.1:6382 succeeded
# 从节点
33174:S 13 Feb 2019 18:19:34.806 * MASTER <-> REPLICA sync started
33174:S 13 Feb 2019 18:19:34.806 * Non blocking connect for SYNC fired the event.
33174:S 13 Feb 2019 18:19:34.807 * Master replied to PING, replication can continue...
33174:S 13 Feb 2019 18:19:34.807 * Partial resynchronization not possible (no cached master)
33174:S 13 Feb 2019 18:19:34.807 * Full resync from master: deb0cb0abde947bba19c5224a3664e27c90a6b65:0
33174:S 13 Feb 2019 18:19:34.839 * MASTER <-> REPLICA sync: receiving 175 bytes from master
33174:S 13 Feb 2019 18:19:34.839 * MASTER <-> REPLICA sync: Flushing old data
33174:S 13 Feb 2019 18:19:34.839 * MASTER <-> REPLICA sync: Loading DB in memory
33174:S 13 Feb 2019 18:19:34.839 * MASTER <-> REPLICA sync: Finished with success
33174:S 13 Feb 2019 18:19:34.839 * Background append only file rewriting started by pid 33176
33174:S 13 Feb 2019 18:19:34.863 * AOF rewrite child asks to stop sending diffs.
33176:C 13 Feb 2019 18:19:34.863 * Parent agreed to stop sending diffs. Finalizing AOF...
33176:C 13 Feb 2019 18:19:34.863 * Concatenating 0.00 MB of AOF diff received from parent.
33176:C 13 Feb 2019 18:19:34.863 * SYNC append only file rewrite performed
33174:S 13 Feb 2019 18:19:34.909 * Background AOF rewrite terminated with success
33174:S 13 Feb 2019 18:19:34.910 * Residual parent diff successfully flushed to the rewritten AOF (0.00 MB)
33174:S 13 Feb 2019 18:19:34.910 * Background AOF rewrite finished successfully
不同机器上配置一主多从
如果redis-server在不同的机器上,只需要以下两个配置即可
# 从节点要跟随的主节点
slaveof 127.0.0.1 6379
# 如果设置了密码,就要设置
masterauth master-password
通过命令设置从服务器
- 可以通过向运行中的从服务器发送SLAVEOF命令来将其设置为从服务器。
- 如果用户使用的是 SLAVEOF配置选项,那么Redis在启动时首先会载入当前可用的任何快照文件或者AOF文件,然后连接主服务器并执行上述的复制过程。如果用户使用的是SLAVEOF命令,那么Redis会立即尝试连接主服务器,并在连接成功之后,开始上述复制过程。
优点
读写分离,提高效率
数据热备份,提供多个副本
问题:
- master无法保证高可用
主节点故障,集群则无法进行工作,可用性比较低,从节点升主节点需要人工手动干预
- 没有解决 master 写的压力
单点容易造成性能低下,主节点的写受到限制(只有一个主节点)
- 主节点的存储能力受到限制
只有一个主节点
- 全量同步可能会造成毫秒或者秒级的卡顿现象
redission访问redis集群
redission作为redis 官方推荐的java客户端。 redission使用netty4.x作为网络层。 redission使用异步io方式操作
redission的读写操作源码分析
从一个读、写操作的代码作为分析代码,如下:
//创建redis客户端
Redisson redisson =(Redisson) Redisson.create();
//创建RBucket对象
RBucket<String> bucket = redisson.getBucket("key1");
//设置对象
bucket.set("someValue");
//获取结果
String bucketObject = bucket.get();
System.out.println("bucketObject:"+bucketObject);
下面详细介绍Redission提供的RBucket 接口和RedissonBucket类。
RBucket 接口
/**
* Any object holder
* @author Nikita Koksharov
*/
public interface RBucket<V> extends RExpirable, RBucketAsync<V>
{
V get();
void set(V value);
void set(V value, long timeToLive, TimeUnit timeUnit);
}
RBucket提供set()和sget()方法用于保存和获取对象。
RedissonBucket 实现类
RedissonBucket 是对RBucket对象的实现。
RedissonBucket实现set()和get()同步方法和异步方法。
public class RedissonBucket<V> extends RedissonExpirable implements RBucket<V> {
protected RedissonBucket(CommandAsyncExecutor connectionManager, String name) {
super(connectionManager, name);
}
protected RedissonBucket(Codec codec, CommandAsyncExecutor connectionManager, String name)
{
super(codec, connectionManager, name);
}
@Override
public V get() {
return get(getAsync());
}
protected final <V> V get(RFuture<V> future) {
return commandExecutor.get(future);
}
@Override
public Future<V> getAsync() {
return commandExecutor.readAsync(getName(), codec, RedisCommands.GET, getName());
}
@Override
public void set(V value) {
get(setAsync(value));
}
@Override
public Future<Void> setAsync(V value) {
return commandExecutor.writeAsync(getName(), codec, RedisCommands.SET, getName(), value);
}
@Override
public void set(V value, long timeToLive, TimeUnit timeUnit) {
get(setAsync(value, timeToLive, timeUnit));
}
@Override
public Future<Void> setAsync(V value, long timeToLive, TimeUnit timeUnit) {
return commandExecutor.writeAsync(getName(), codec, RedisCommands.SETEX, getName(), timeUnit.toSeconds(timeToLive), value);
}
}
RedissonBucket 对象又继承了基类RedissonExpirable,RedissonExpirable继承了基类RedissionObject对象。
abstract class RedissonExpirable extends RedissonObject implements RExpirable {
RedissonExpirable(CommandAsyncExecutor connectionManager, String name) {
super(connectionManager, name);
}
RedissonExpirable(Codec codec, CommandAsyncExecutor connectionManager, String name) {
super(codec, connectionManager, name);
}
@Override
public boolean expire(long timeToLive, TimeUnit timeUnit) {
return commandExecutor.get(expireAsync(timeToLive, timeUnit));
}
...
}
//RedissonExpirable继承了基类RedissionObject对象。
abstract class RedissonObject implements RObject
{
final CommandAsyncExecutor commandExecutor; //连接池
private final String name;//作为键
final Codec codec; //编码解码器
}
在RedissionObject 包含name 作为键,codec 作为编码解码器,commandExecutor 用来执行操作的连接池。
Redisstion的类型
对于Redisson的任何操作,都需要获取到操作句柄类RedissonObject,RedissonObject根据不同的数据类型有不同的RedissonObject实现类,RedissonObject的类继承关系图如下:
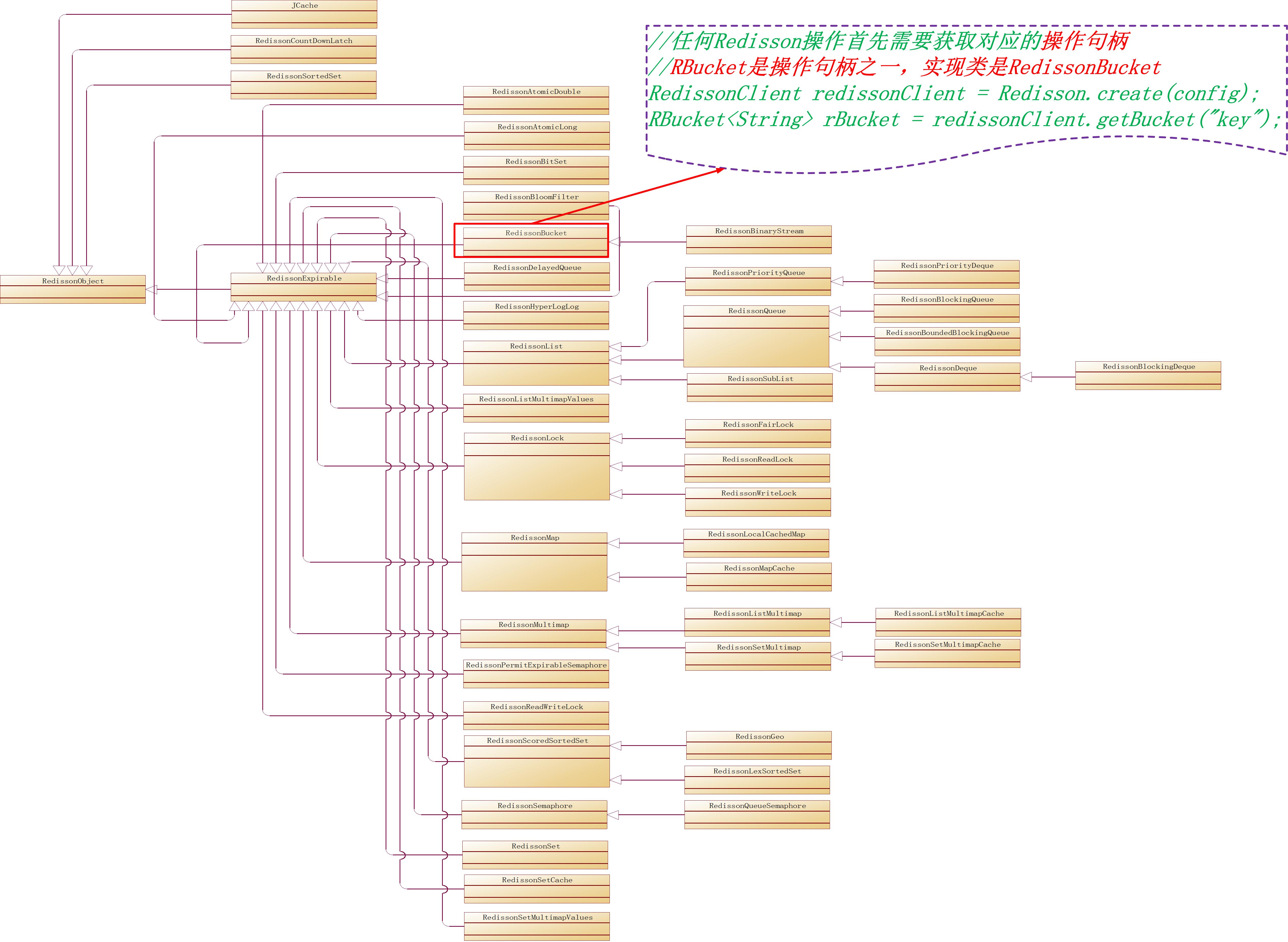
例如想设置redis服务端的key=key的值value=123,你需要查询Redis命令和Redisson对象匹配列表,找到如下对应关系:

然后我们就知道调用代码这么写:
Config config = new Config();// 创建配置
config.useMasterSlaveServers() // 指定使用主从部署方式
.setMasterAddress("redis://192.168.29.24:6379") // 设置redis主节点
.addSlaveAddress("redis://192.168.29.24:7000") // 设置redis从节点
.addSlaveAddress("redis://192.168.29.24:7001"); // 设置redis从节点
RedissonClient redisson = Redisson.create(config);// 创建客户端(发现这一操作非常耗时,基本在2秒-4秒左右)
//任何Redisson操作首先需要获取对应的操作句柄
//RBucket是操作句柄之一,实现类是RedissonBucket
RBucket<String> rBucket = redissonClient.getBucket("key");
//通过操作句柄rBucket进行读操作
rBucket.get();
//通过操作句柄rBucket进行写操作
rBucket.set("123");
至于其它的redis命令对应的redisson操作对象,都可以官网的Redis命令和Redisson对象匹配列表 查到。
解密:redission的set()方法流程
RedissionBucket执行set()方法
当RedissionBucket执行set()方法时,这将是Redission整个流程的核心。
- RedissonBucket 执行set()方法,并通过get(RFuture
future)方法获取RFuture异步任务的返回值
public class RedissonBucket<V> extends RedissonExpirable implements RBucket<V>
{
@Override
public void set(V value) {
get(setAsync(value));
}
}
- setAsync(value)异步写入的方法
真正执行set操作,调用commandExecutor 来完成,参数为主要封装redis的键值,命令以及所需要的参数
public class RedissonBucket<V> extends RedissonExpirable implements RBucket<V>
{
@Override
public Future<Void> setAsync(V value) {
return commandExecutor.writeAsync(getName(), codec, RedisCommands.SET, getName(), value);
}
}
- CommandAsyncService 线程池的 writeAsync 异步写入
CommandAsyncService 首先通过netty框架创建一个promise接口,并且返回。
public class CommandAsyncService implements CommandAsyncExecutor
{
public <T, R> Future<R> writeAsync(String key, Codec codec, RedisCommand<T> command, Object ... params)
{
//通过netty创建一个Promise接口并且返回
Promise<R> mainPromise = connectionManager.newPromise();
NodeSource source = getNodeSource(key);
async(false, source, codec, command, params, mainPromise, 0);
return mainPromise;
}
}
在此,RBucket 执行一个set操作,由netty创建一个promise对象,并且RBucket通过get()同步方法获取promise完成时的结果。
前面的异步转同步的方法:
protected final
return commandExecutor.get(future);
}
- CommandAsyncService 线程池的同步get方法
public class CommandAsyncService implements CommandAsyncExecutor
{
@Override
public <V> V get(RFuture<V> future) {
try {
future.await();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
if (future.isSuccess()) {
return future.getNow();
}
throw convertException(future);
}
}
在Redission引擎中,核心流程处理在于
CommandAsyncService.async() 创建异步任务
这个关键方法。CommandAsyncService.async()方法内部,一直在优化和改变。不过代码,一直朝着更加清晰的地方发展,这更加有利于我们的学习。
protected <V, R> void async(final boolean readOnlyMode,
final NodeSource source,
final Codec codec,
final RedisCommand<V> command,
final Object[] params,
final Promise<R> mainPromise,
final int attempt)
{
RedisExecutor<V, R> executor =
new RedisExecutor<>(readOnlyMode, source,
codec, command, params, mainPromise,
ignoreRedirect, connectionManager, objectBuilder);
executor.execute();
}
RedisExecutor 命令执行器
public RedisExecutor(boolean readOnlyMode, NodeSource source,
Codec codec, RedisCommand<V> command,
Object[] params, RPromise<R> mainPromise, boolean ignoreRedirect,
ConnectionManager connectionManager, RedissonObjectBuilder objectBuilder) {
super();
this.readOnlyMode = readOnlyMode;
this.source = source;
this.codec = codec;
this.command = command;
this.params = params;
this.mainPromise = mainPromise;
this.ignoreRedirect = ignoreRedirect;
this.connectionManager = connectionManager;
this.objectBuilder = objectBuilder;
this.attempts = connectionManager.getConfig().getRetryAttempts();
this.retryInterval = connectionManager.getConfig().getRetryInterval();
this.responseTimeout = connectionManager.getConfig().getTimeout();
}
命令执行方法
public void execute() {
if (mainPromise.isCancelled()) {
free();
return;
}
if (!connectionManager.getShutdownLatch().acquire()) {
free();
mainPromise.tryFailure(new RedissonShutdownException("Redisson is shutdown"));
return;
}
codec = getCodec(codec);
//获取连接
RFuture<RedisConnection> connectionFuture = getConnection();
RPromise<R> attemptPromise = new RedissonPromise<R>();
mainPromiseListener = (r, e) -> {
if (mainPromise.isCancelled() && connectionFuture.cancel(false)) {
log.debug("Connection obtaining canceled for {}", command);
timeout.cancel();
if (attemptPromise.cancel(false)) {
free();
}
}
};
if (attempt == 0) {
mainPromise.onComplete((r, e) -> {
if (this.mainPromiseListener != null) {
this.mainPromiseListener.accept(r, e);
}
});
}
scheduleRetryTimeout(connectionFuture, attemptPromise);
connectionFuture.onComplete((connection, e) -> {
if (connectionFuture.isCancelled()) {
connectionManager.getShutdownLatch().release();
return;
}
if (!connectionFuture.isSuccess()) {
connectionManager.getShutdownLatch().release();
exception = convertException(connectionFuture);
return;
}
if (attemptPromise.isDone() || mainPromise.isDone()) {
releaseConnection(attemptPromise, connectionFuture);
return;
}
sendCommand(attemptPromise, connection);
writeFuture.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture future) throws Exception {
checkWriteFuture(writeFuture, attemptPromise, connection);
}
});
releaseConnection(attemptPromise, connectionFuture);
});
attemptPromise.onComplete((r, e) -> {
checkAttemptPromise(attemptPromise, connectionFuture);
});
}
在RedisExecutor.execute()方法内部,获取一个连接
//获取连接
RFuture<RedisConnection> connectionFuture = getConnection();
获取一个连接 后,这里也使用了异步方式, 对connectionFuture 进行监听。
当connectFuture完成时,然后进行写操作。然后sendCommand 发送命令。
connectionFuture.onComplete((connection, e) -> {
if (connectionFuture.isCancelled()) {
connectionManager.getShutdownLatch().release();
return;
}
if (!connectionFuture.isSuccess()) {
connectionManager.getShutdownLatch().release();
exception = convertException(connectionFuture);
return;
}
if (attemptPromise.isDone() || mainPromise.isDone()) {
releaseConnection(attemptPromise, connectionFuture);
return;
}
sendCommand(attemptPromise, connection);
writeFuture.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture future) throws Exception {
checkWriteFuture(writeFuture, attemptPromise, connection);
}
});
releaseConnection(attemptPromise, connectionFuture);
});
当Redission接受到Redis服务器消息时,会取出发送时的信息。这个时候会设置attempPromise完成时通知,在attempPromise监听器中会通知MainPromise.这个时候MainPromise就会获取到通知。
protected void completeResponse(CommandData<Object, Object> data, Object result, Channel channel) {
if (data != null
&& !data.getPromise().trySuccess(result)
&& data.cause() instanceof RedisTimeoutException) {
log.warn("response has been skipped due to timeout! channel: {}, command: {}", channel, LogHelper.toString(data));
}
}
Redssion的处理流水线
@Override
protected void initChannel(Channel ch) throws Exception {
initSsl(config, ch);
if (type == Type.PLAIN) {
ch.pipeline().addLast(new RedisConnectionHandler(redisClient));
} else {
ch.pipeline().addLast(new RedisPubSubConnectionHandler(redisClient));
}
ch.pipeline().addLast(
connectionWatchdog,
CommandEncoder.INSTANCE,
CommandBatchEncoder.INSTANCE,
new CommandsQueue());
if (pingConnectionHandler != null) {
ch.pipeline().addLast(pingConnectionHandler);
}
if (type == Type.PLAIN) {
ch.pipeline().addLast(new CommandDecoder(config.getExecutor(), config.isDecodeInExecutor()));
} else {
ch.pipeline().addLast(new CommandPubSubDecoder(config.getExecutor(), config.isKeepPubSubOrder(), config.isDecodeInExecutor()));
}
}
redission命令发送处理器
public class CommandsQueue extends ChannelDuplexHandler {
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
if (msg instanceof QueueCommand) {
QueueCommand data = (QueueCommand) msg;
QueueCommandHolder holder = queue.peek();
if (holder != null && holder.getCommand() == data) {
super.write(ctx, msg, promise);
} else {
queue.add(new QueueCommandHolder(data, promise));
sendData(ctx.channel());
}
} else {
super.write(ctx, msg, promise);
}
}
private void sendData(Channel ch) {
QueueCommandHolder command = queue.peek();
if (command != null && command.trySend()) {
QueueCommand data = command.getCommand();
List<CommandData<Object, Object>> pubSubOps = data.getPubSubOperations();
if (!pubSubOps.isEmpty()) {
for (CommandData<Object, Object> cd : pubSubOps) {
for (Object channel : cd.getParams()) {
ch.pipeline().get(CommandPubSubDecoder.class).addPubSubCommand((ChannelName) channel, cd);
}
}
} else {
ch.attr(CURRENT_COMMAND).set(data);
}
command.getChannelPromise().addListener(listener);
ch.writeAndFlush(data, command.getChannelPromise());
}
}
}
NioSocketChannel 执行最终的写操作
public class NioSocketChannel extends AbstractNioByteChannel implements io.netty.channel.socket.SocketChannel {
@Override
protected void doWrite(ChannelOutboundBuffer in) throws Exception {
SocketChannel ch = javaChannel();
int writeSpinCount = config().getWriteSpinCount();
do {
if (in.isEmpty()) {
// All written so clear OP_WRITE
clearOpWrite();
// Directly return here so incompleteWrite(...) is not called.
return;
}
// Ensure the pending writes are made of ByteBufs only.
int maxBytesPerGatheringWrite = ((NioSocketChannelConfig) config).getMaxBytesPerGatheringWrite();
ByteBuffer[] nioBuffers = in.nioBuffers(1024, maxBytesPerGatheringWrite);
int nioBufferCnt = in.nioBufferCount();
// Always us nioBuffers() to workaround data-corruption.
// See https://github.com/netty/netty/issues/2761
switch (nioBufferCnt) {
case 0:
// We have something else beside ByteBuffers to write so fallback to normal writes.
writeSpinCount -= doWrite0(in);
break;
case 1: {
// Only one ByteBuf so use non-gathering write
// Zero length buffers are not added to nioBuffers by ChannelOutboundBuffer, so there is no need
// to check if the total size of all the buffers is non-zero.
ByteBuffer buffer = nioBuffers[0];
int attemptedBytes = buffer.remaining();
final int localWrittenBytes = ch.write(buffer);
if (localWrittenBytes <= 0) {
incompleteWrite(true);
return;
}
adjustMaxBytesPerGatheringWrite(attemptedBytes, localWrittenBytes, maxBytesPerGatheringWrite);
in.removeBytes(localWrittenBytes);
--writeSpinCount;
break;
}
default: {
// Zero length buffers are not added to nioBuffers by ChannelOutboundBuffer, so there is no need
// to check if the total size of all the buffers is non-zero.
// We limit the max amount to int above so cast is safe
long attemptedBytes = in.nioBufferSize();
final long localWrittenBytes = ch.write(nioBuffers, 0, nioBufferCnt);
if (localWrittenBytes <= 0) {
incompleteWrite(true);
return;
}
// Casting to int is safe because we limit the total amount of data in the nioBuffers to int above.
adjustMaxBytesPerGatheringWrite((int) attemptedBytes, (int) localWrittenBytes,
maxBytesPerGatheringWrite);
in.removeBytes(localWrittenBytes);
--writeSpinCount;
break;
}
}
} while (writeSpinCount > 0);
incompleteWrite(writeSpinCount < 0);
}
ChannelOutboundBuffer回调Promise的接口
ChannelOutboundBuffer写完之后,回调Promise的接口。
Future 有两种模式:将来式和回调式。而回调式会出现回调地狱的问题,由此衍生出了 Promise 模式来解决这个问题。这才是 Future 模式和 Promise 模式的相关性。
public final class ChannelOutboundBuffer {
/**
* Removes the fully written entries and update the reader index of the partially written entry.
* This operation assumes all messages in this buffer is {@link ByteBuf}.
*/
public void removeBytes(long writtenBytes) {
for (;;) {
Object msg = current();
if (!(msg instanceof ByteBuf)) {
assert writtenBytes == 0;
break;
}
final ByteBuf buf = (ByteBuf) msg;
final int readerIndex = buf.readerIndex();
final int readableBytes = buf.writerIndex() - readerIndex;
if (readableBytes <= writtenBytes) {
if (writtenBytes != 0) {
progress(readableBytes);
writtenBytes -= readableBytes;
}
remove();
} else { // readableBytes > writtenBytes
if (writtenBytes != 0) {
buf.readerIndex(readerIndex + (int) writtenBytes);
progress(writtenBytes);
}
break;
}
}
clearNioBuffers();
}
/**
* Will remove the current message, mark its {@link ChannelPromise} as success and return {@code true}. If no
* flushed message exists at the time this method is called it will return {@code false} to signal that no more
* messages are ready to be handled.
*/
public boolean remove() {
Entry e = flushedEntry;
if (e == null) {
clearNioBuffers();
return false;
}
Object msg = e.msg;
ChannelPromise promise = e.promise;
int size = e.pendingSize;
removeEntry(e);
if (!e.cancelled) {
// only release message, notify and decrement if it was not canceled before.
ReferenceCountUtil.safeRelease(msg);
safeSuccess(promise);
decrementPendingOutboundBytes(size, false, true);
}
// recycle the entry
e.recycle();
return true;
}
回到写完后的异步回调接口
RedisExecutor 发送命令sendCommand
public class RedisExecutor<V, R> {
protected void sendCommand(RPromise<R> attemptPromise, RedisConnection connection) {
if (source.getRedirect() == Redirect.ASK) {
List<CommandData<?, ?>> list = new ArrayList<CommandData<?, ?>>(2);
RPromise<Void> promise = new RedissonPromise<Void>();
list.add(new CommandData<Void, Void>(promise, codec, RedisCommands.ASKING, new Object[]{}));
list.add(new CommandData<V, R>(attemptPromise, codec, command, params));
RPromise<Void> main = new RedissonPromise<Void>();
writeFuture = connection.send(new CommandsData(main, list, false));
} else {
if (log.isDebugEnabled()) {
log.debug("acquired connection for command {} and params {} from slot {} using node {}... {}",
command, LogHelper.toString(params), source, connection.getRedisClient().getAddr(), connection);
}
writeFuture = connection.send(new CommandData<V, R>(attemptPromise, codec, command, params));
}
}
来自于 AbstractChannelHandlerContext 的异步回调:
abstract class AbstractChannelHandlerContext implements ChannelHandlerContext, ResourceLeakHint {
@Override
public ChannelFuture writeAndFlush(Object msg) {
return writeAndFlush(msg, newPromise());
}
}
RedisExecutor启动超时重试定时器
public class RedisExecutor<V, R> {
public void execute() {
writeFuture.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture future) throws Exception {
checkWriteFuture(writeFuture, attemptPromise, connection);
}
});
}
private void checkWriteFuture(ChannelFuture future, RPromise<R> attemptPromise, RedisConnection connection) {
if (future.isCancelled() || attemptPromise.isDone()) {
return;
}
if (!future.isSuccess()) {
exception = new WriteRedisConnectionException(
"Unable to send command! Node source: " + source + ", connection: " + connection +
", command: " + LogHelper.toString(command, params)
+ " after " + attempt + " retry attempts", future.cause());
if (attempt == attempts) {
if (!attemptPromise.tryFailure(exception)) {
log.error(exception.getMessage());
}
}
return;
}
timeout.cancel();
scheduleResponseTimeout(attemptPromise, connection);
}
private void scheduleResponseTimeout(RPromise<R> attemptPromise, RedisConnection connection) {
long timeoutTime = responseTimeout;
if (command != null
&& (RedisCommands.BLOCKING_COMMAND_NAMES.contains(command.getName())
|| RedisCommands.BLOCKING_COMMANDS.contains(command))) {
Long popTimeout = null;
if (RedisCommands.BLOCKING_COMMANDS.contains(command)) {
boolean found = false;
for (Object param : params) {
if (found) {
popTimeout = Long.valueOf(param.toString()) / 1000;
break;
}
if ("BLOCK".equals(param)) {
found = true;
}
}
} else {
popTimeout = Long.valueOf(params[params.length - 1].toString());
}
handleBlockingOperations(attemptPromise, connection, popTimeout);
if (popTimeout == 0) {
return;
}
timeoutTime += popTimeout * 1000;
// add 1 second due to issue https://github.com/antirez/redis/issues/874
timeoutTime += 1000;
}
long timeoutAmount = timeoutTime;
TimerTask timeoutTask = new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
if (attempt < attempts) {
if (!attemptPromise.cancel(false)) {
return;
}
attempt++;
if (log.isDebugEnabled()) {
log.debug("attempt {} for command {} and params {}",
attempt, command, LogHelper.toString(params));
}
mainPromiseListener = null;
execute();
return;
}
attemptPromise.tryFailure(
new RedisResponseTimeoutException("Redis server response timeout (" + timeoutAmount + " ms) occured"
+ " after " + attempts + " retry attempts. Command: "
+ LogHelper.toString(command, params) + ", channel: " + connection.getChannel()));
}
};
timeout = connectionManager.newTimeout(timeoutTask, timeoutTime, TimeUnit.MILLISECONDS);
}
CommandDecoder 命令解码器
public class CommandDecoder extends ReplayingDecoder<State> {
@Override
protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
QueueCommand data = ctx.channel().attr(CommandsQueue.CURRENT_COMMAND).get();
if (state() == null) {
state(new State());
}
if (data == null) {
while (in.writerIndex() > in.readerIndex()) {
int endIndex = skipCommand(in);
try {
decode(ctx, in, data);
} catch (Exception e) {
in.readerIndex(endIndex);
throw e;
}
}
} else {
int endIndex = 0;
if (!(data instanceof CommandsData)) {
endIndex = skipCommand(in);
}
try {
decode(ctx, in, data);
} catch (Exception e) {
if (!(data instanceof CommandsData)) {
in.readerIndex(endIndex);
}
throw e;
}
}
}
private void decode(ChannelHandlerContext ctx, ByteBuf in, QueueCommand data) throws Exception {
decodeCommand(ctx.channel(), in, data);
}
protected void decodeCommand(Channel channel, ByteBuf in, QueueCommand data) throws Exception {
if (data instanceof CommandData) {
CommandData<Object, Object> cmd = (CommandData<Object, Object>) data;
try {
decode(in, cmd, null, channel, false, null);
sendNext(channel, data);
} catch (Exception e) {
cmd.tryFailure(e);
sendNext(channel);
throw e;
}
}
}
protected void decode(ByteBuf in, CommandData<Object, Object> data, List<Object> parts, Channel channel, boolean skipConvertor, List<CommandData<?, ?>> commandsData) throws IOException {
int code = in.readByte();
if (code == '+') {
String result = readString(in);
handleResult(data, parts, result, skipConvertor, channel);
} else if (code == '-') {
String error = readString(in);
} else if (code == ':') {
Long result = readLong(in);
handleResult(data, parts, result, false, channel);
} else if (code == '$') {
} else {
String dataStr = in.toString(0, in.writerIndex(), CharsetUtil.UTF_8);
throw new IllegalStateException("Can't decode replay: " + dataStr);
}
}
private void handleResult(CommandData<Object, Object> data, List<Object> parts, Object result, boolean skipConvertor, Channel channel) {
if (data != null && !skipConvertor) {
result = data.getCommand().getConvertor().convert(result);
}
if (parts != null) {
parts.add(result);
} else {
completeResponse(data, result, channel);
}
}
protected void completeResponse(CommandData<Object, Object> data, Object result, Channel channel) {
if (data != null
&& !data.getPromise().trySuccess(result)
&& data.cause() instanceof RedisTimeoutException) {
log.warn("response has been skipped due to timeout! channel: {}, command: {}", channel, LogHelper.toString(data));
}
}
回到最初的mainPromise 回调
public class CommandAsyncService implements CommandAsyncExecutor
{
public <T, R> Future<R> writeAsync(String key, Codec codec, RedisCommand<T> command, Object ... params)
{
//通过netty创建一个Promise接口并且返回
Promise<R> mainPromise = connectionManager.newPromise();
NodeSource source = getNodeSource(key);
async(false, source, codec, command, params, mainPromise, 0);
return mainPromise;
}
}
public class RedissonPromise<T> extends CompletableFuture<T> implements RPromise<T> {
private final Promise<T> promise = ImmediateEventExecutor.INSTANCE.newPromise();
@Override
public boolean trySuccess(T result) {
if (promise.trySuccess(result)) {
complete(result);
return true;
}
return false;
}
}
取消重试定时器
mainPromiseListener = (r, e) -> {
if (mainPromise.isCancelled() && connectionFuture.cancel(false)) {
log.debug("Connection obtaining canceled for {}", command);
timeout.cancel();
if (attemptPromise.cancel(false)) {
free();
}
}
};
同步,异步,阻塞,非阻塞实战
同步,异步,阻塞,非阻塞的理解需要花费很大的精力,从 IO 模型和内核进行深入地理解,才能分清区别。在日常开发中往往没必要过于纠结到底是何种调用,但得对调用的特性有所了解,比如是否占用主线程的时间片,出现异常怎么捕获,超时怎么解决等等
Future 和 Promise的区别
Future 的结果由异步计算的结果确定。请注意,必须使用Callable或Runnable初始化FutureTask(经典的Future),没有无参数构造函数,并且Future和FutureTask都是从外部只读的(FutureTask的set方法受保护)。该值将从内部设置为计算结果。
Promise和 Future 是非常相似的概念,不同之处在于,Future 是针对尚不存在的结果的只读容器,而 Promise 可以被写入(通常只能写入一次)。
Promise 的结果可以由你(或实际上任何人)随时设置,因为它具有公共设置方法。你向客户代码发送一个 Promise,并在以后根据需要执行。
在Java 8中,Promise最终被称为CompletableFuture,它的javadoc解释了:可以明确完成(设置其值和状态)并可以用作CompletionStage的Future,它支持在完成时触发的相关功能和操作。
在Java 8中,可以创建CompletableFuture和SettableFuture,而无需执行任何任务,并且可以随时设置它们的值。注意,CompletableFuture不是“纯粹的”Promise,可以使用诸如FutureTask之类的任务对其进行初始化,并且它最有用的功能是与处理链的步骤无关。
连接的获取
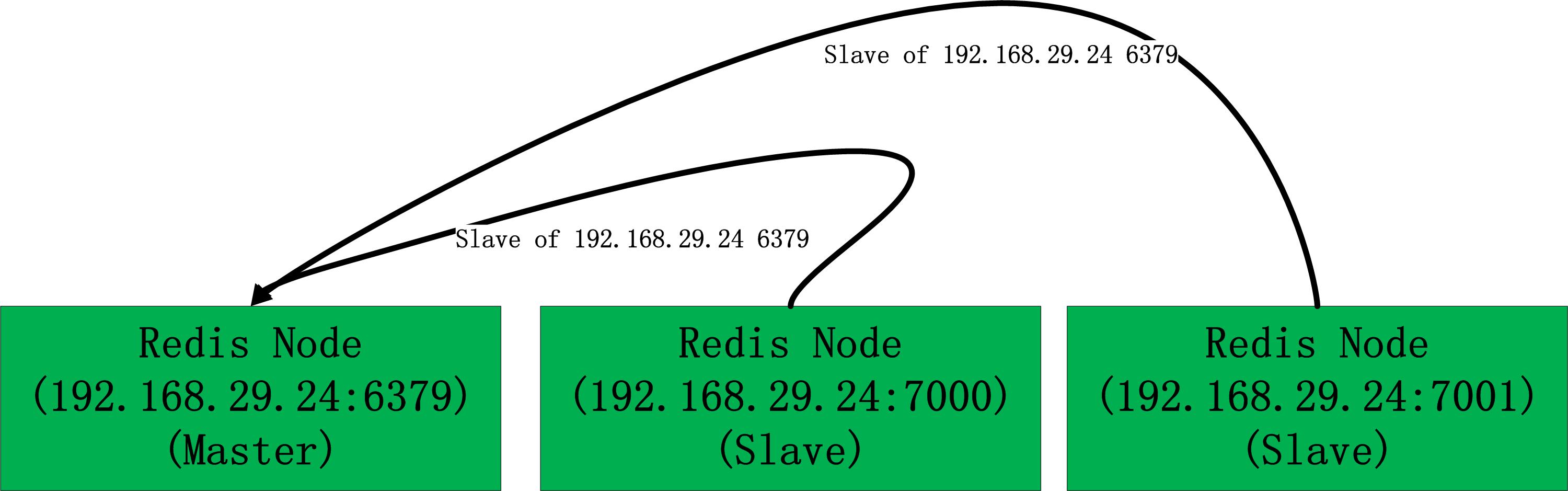
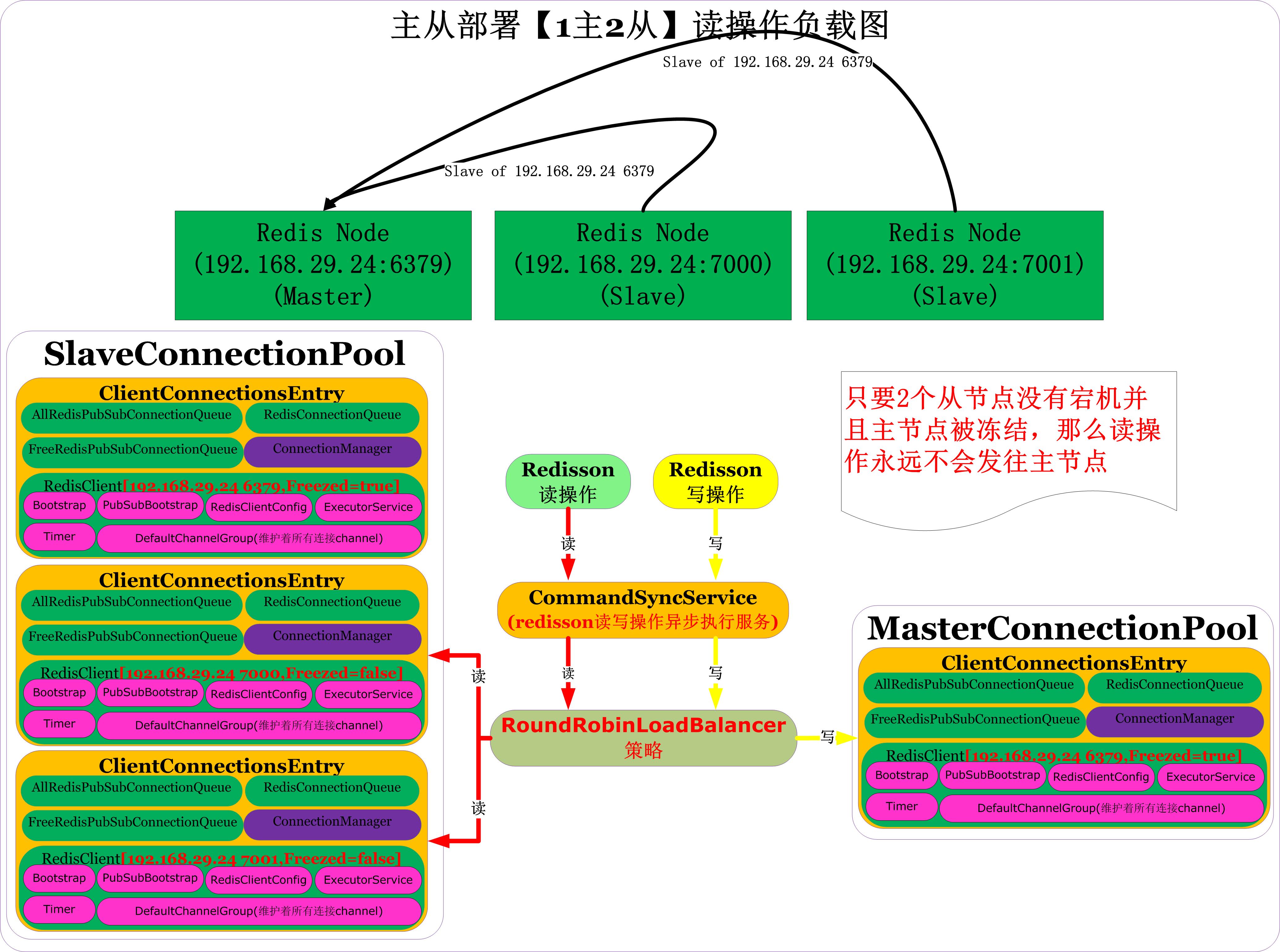
RedissonClient一主两从部署时连接池组成
对如下图的主从部署(1主2从):
 redisson纯java操作代码如下:
redisson纯java操作代码如下:
Config config = new Config();// 创建配置
config.useMasterSlaveServers() // 指定使用主从部署方式
//.setReadMode(ReadMode.SLAVE) 默认值SLAVE,读操作只在从节点进行
//.setSubscriptionMode(SubscriptionMode.SLAVE) 默认值SLAVE,订阅操作只在从节点进行
//.setMasterConnectionMinimumIdleSize(10) 默认值10,针对每个master节点初始化10个连接
//.setMasterConnectionPoolSize(64) 默认值64,针对每个master节点初始化10个连接,最大可以扩展至64个连接
//.setSlaveConnectionMinimumIdleSize(10) 默认值10,针对每个slave节点初始化10个连接
//.setSlaveConnectionPoolSize(64) 默认值,针对每个slave节点初始化10个连接,最大可以扩展至64个连接
//.setSubscriptionConnectionMinimumIdleSize(1) 默认值1,在SubscriptionMode=SLAVE时候,针对每个slave节点初始化1个连接
//.setSubscriptionConnectionPoolSize(50) 默认值50,在SubscriptionMode=SLAVE时候,针对每个slave节点初始化1个连接,最大可以扩展至50个连接
.setMasterAddress("redis://192.168.29.24:6379") // 设置redis主节点
.addSlaveAddress("redis://192.168.29.24:7000") // 设置redis从节点
.addSlaveAddress("redis://192.168.29.24:7001"); // 设置redis从节点
RedissonClient redisson = Redisson.create(config);// 创建客户端(发现这一操作非常耗时,基本在2秒-4秒左右)
上面代码执行完毕后,如果在redis服务端所在服务器执行以下linux命令:
#6379上建立了10个连接
netstat -ant |grep 6379|grep ESTABLISHED
#7000上建立了11个连接
netstat -ant |grep 7000|grep ESTABLISHED
#7001上建立了11个连接
netstat -ant |grep 7001|grep ESTABLISHED
你会发现redisson连接到redis服务端总计建立了32个连接,其中masterpool占据10个连接,slavepool占据20个连接,另外pubSubConnectionPool占据2个连接
连接池中池化对象分布
连接池中池化对象分布如下图:
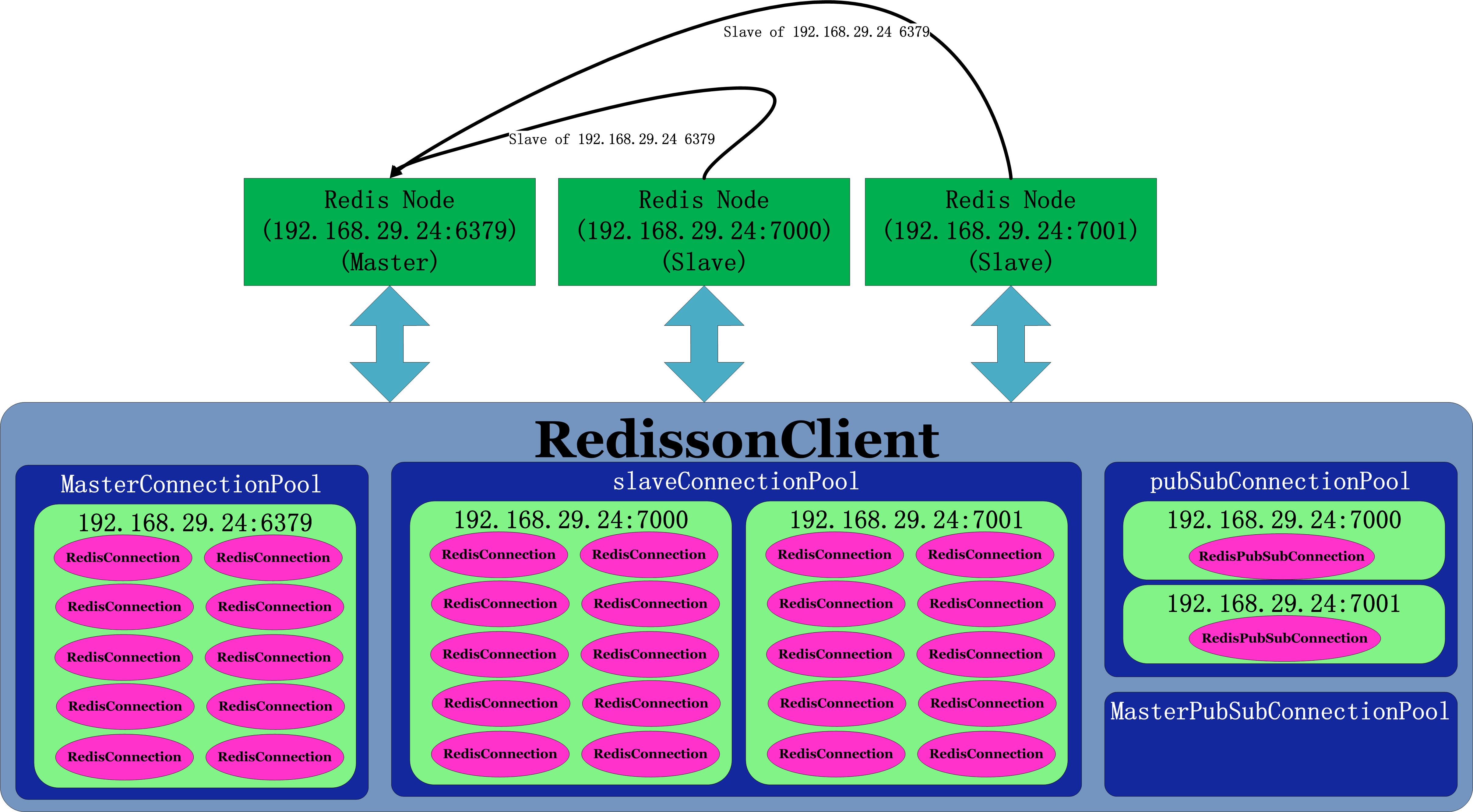
从上图可以看出,连接池是针对每个IP端口都有一个独立的池,连接池也按照主从进行划分,具体如下:
-
MasterConnectionPool:
默认针对每个不同的IP+port组合,初始化10个对象,最大可扩展至64个,因为只有一个master,所以上图创建了10个连接;
-
MasterPubSubConnectionPool:
默认针对每个不同的IP+port组合,初始化1个对象,最大可扩展至50个,因为默认SubscriptionMode=SubscriptionMode.SLAVE,所以master上不会创建连接池,所以上图MasterPubSubConnectionPool里没有创建任何连接;
-
SlaveConnectionPool:
默认针对每个不同的IP+port组合,初始化10个对象,最大可扩展至64个,因为有两个slave,每个slave上图创建了10个连接,总计创建了20个连接;
-
PubSubConnectionPool:
默认针对每个不同的IP+port组合,初始化1个对象,最大可扩展至50个,因为有两个slave,每个slave上图创建了1个连接,总计创建了2个连接。
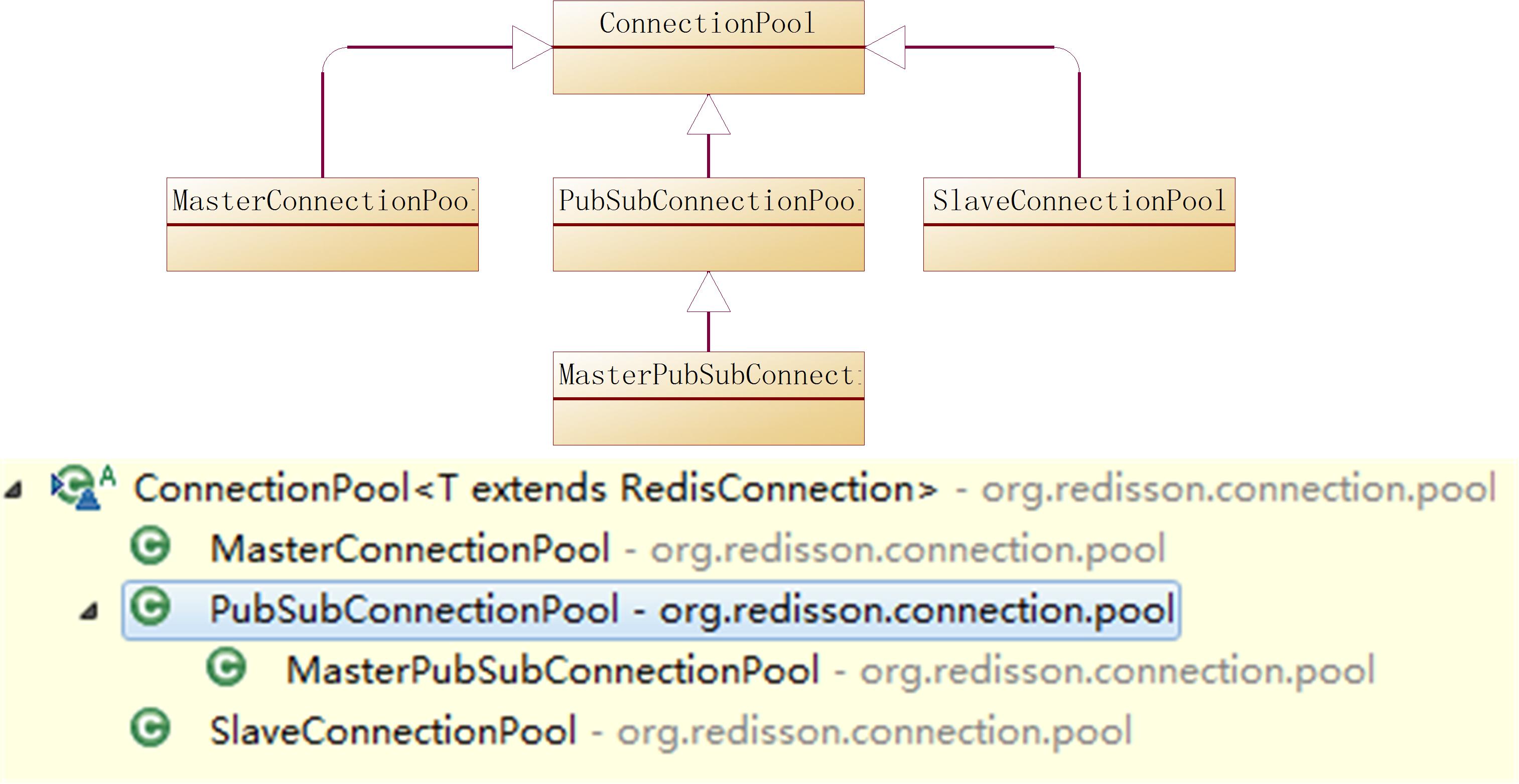
Redisson的4类连接池
这里我们来详细介绍下Redisson的连接池实现类,Redisson里有4种连接池,它们是
-
MasterConnectionPool、
-
MasterPubSubConnectionPool、
-
SlaveConnectionPool
-
PubSubConnectionPool,
Redisson里有4种连接池,它们的父类都是ConnectionPool,其类继承关系图如下:
通过上图我们了解了ConnectionPool类的继承关系图
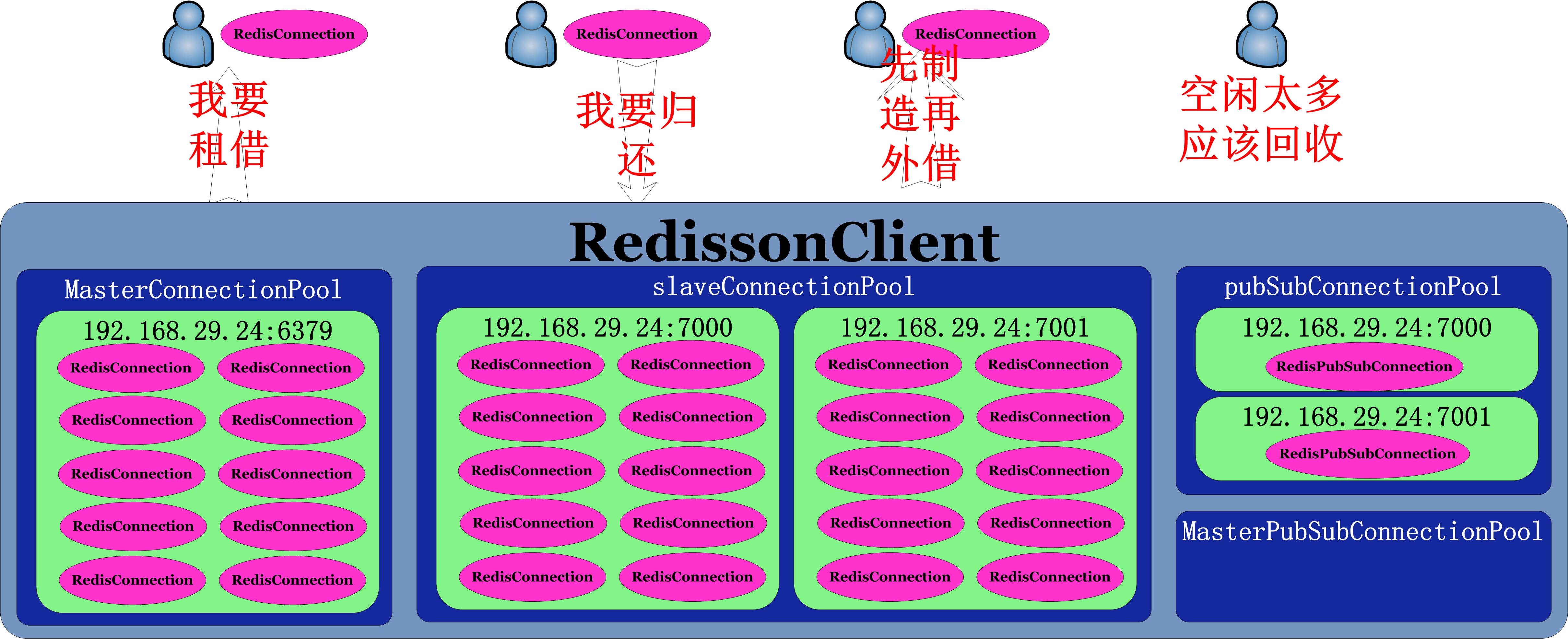
用一张图来解释ConnectionPool干了些啥,如下图:
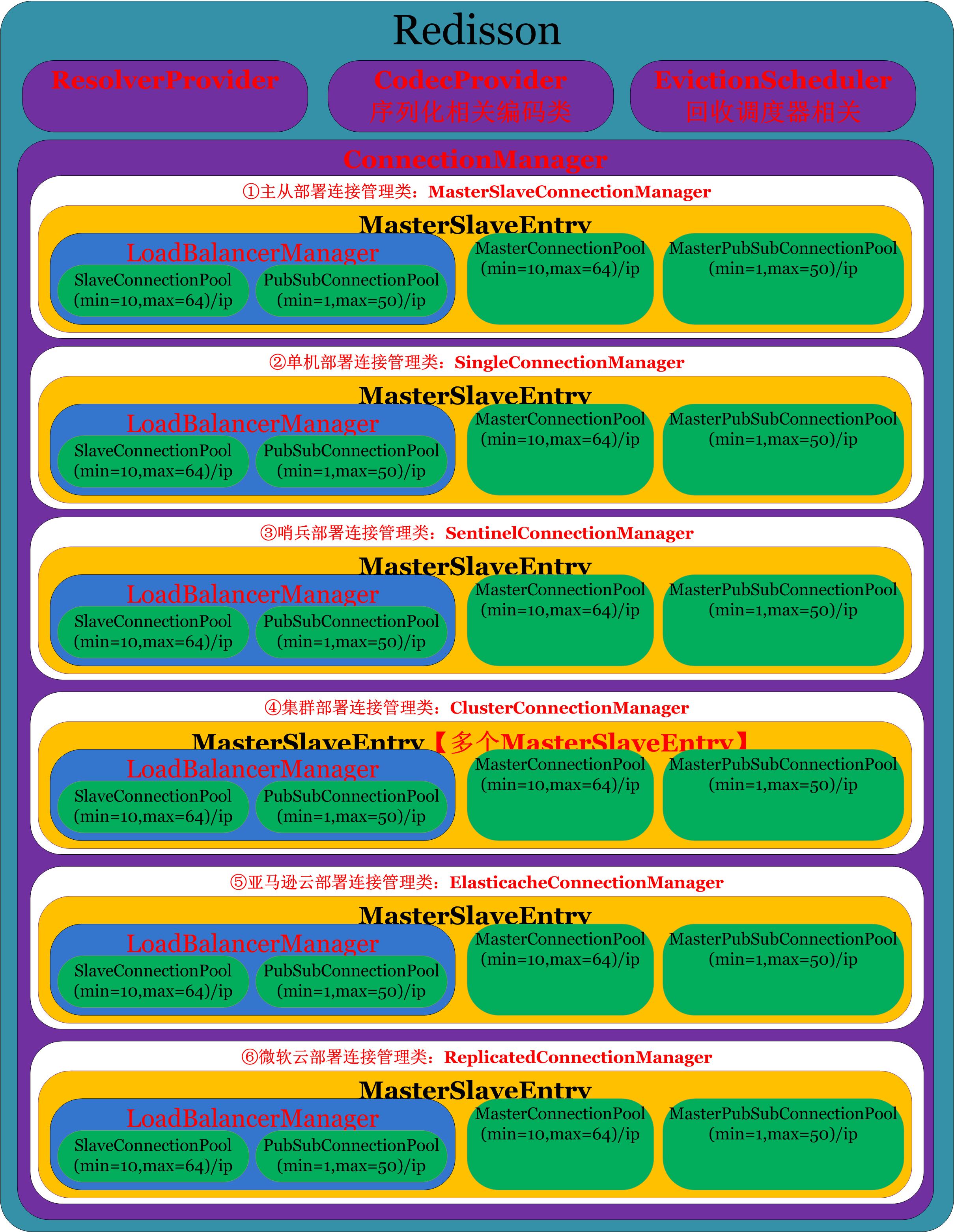
都到这里了,不介意再送一张图了解各种部署方式下的连接池分布了,如下图:
ConnectionPool类的组成
通过上图我们了解了ConnectionPool类的继承关系图,再来一张图来了解下ConnectionPool.java类的组成,如下:
好了,再来图就有点啰嗦了,注释ConnectionPool.java代码如下:
abstract class ConnectionPool<T extends RedisConnection> {
private final Logger log = LoggerFactory.getLogger(getClass());
//维持着连接池对应的redis节点信息
//比如1主2从部署MasterConnectionPool里的entries只有一个主节点(192.168.29.24 6379)
//比如1主2从部署MasterPubSubConnectionPool里的entries为空,因为SubscriptionMode=SubscriptionMode.SLAVE
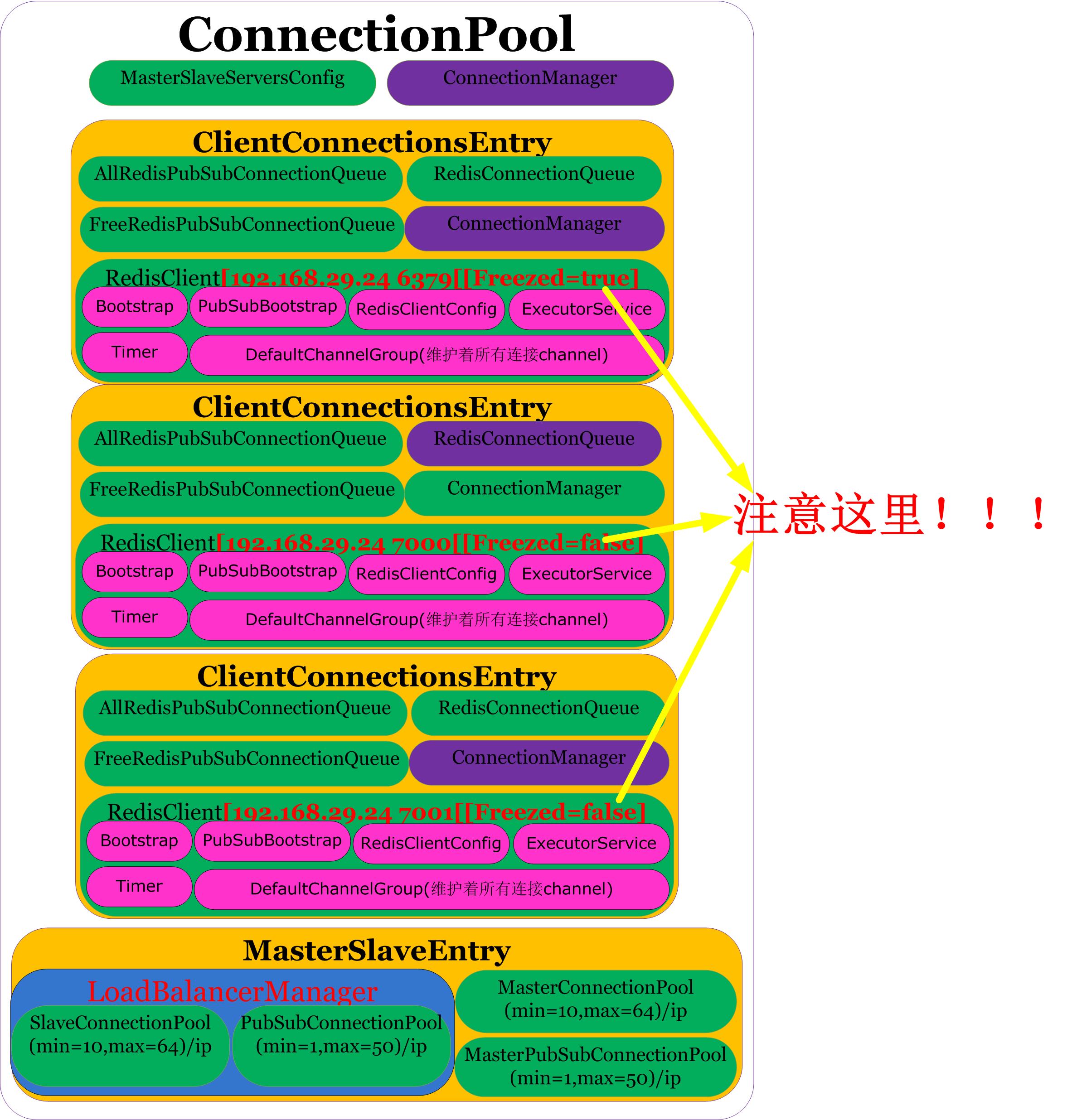
//比如1主2从部署SlaveConnectionPool里的entries有3个节点(192.168.29.24 6379,192.168.29.24 7000,192.168.29.24 7001,但是注意192.168.29.24 6379冻结属性freezed=true不会参与读操作除非2个从节点全部宕机才参与读操作)
//比如1主2从部署PubSubConnectionPool里的entries有2个节点(192.168.29.24 7000,192.168.29.24 7001),因为SubscriptionMode=SubscriptionMode.SLAVE,主节点不会加入
protected final List<ClientConnectionsEntry> entries = new CopyOnWriteArrayList<ClientConnectionsEntry>();
//持有者RedissonClient的组件ConnectionManager
final ConnectionManager connectionManager;
//持有者RedissonClient的组件ConnectionManager里的MasterSlaveServersConfig
final MasterSlaveServersConfig config;
//持有者RedissonClient的组件ConnectionManager里的MasterSlaveEntry
final MasterSlaveEntry masterSlaveEntry;
//构造函数
public ConnectionPool(MasterSlaveServersConfig config, ConnectionManager connectionManager, MasterSlaveEntry masterSlaveEntry) {
this.config = config;
this.masterSlaveEntry = masterSlaveEntry;
this.connectionManager = connectionManager;
}
//连接池中需要增加对象时候调用此方法
public RFuture<Void> add(final ClientConnectionsEntry entry) {
final RPromise<Void> promise = connectionManager.newPromise();
promise.addListener(new FutureListener<Void>() {
@Override
public void operationComplete(Future<Void> future) throws Exception {
entries.add(entry);
}
});
initConnections(entry, promise, true);
return promise;
}
//初始化连接池中最小连接数
private void initConnections(final ClientConnectionsEntry entry, final RPromise<Void> initPromise, boolean checkFreezed) {
final int minimumIdleSize = getMinimumIdleSize(entry);
if (minimumIdleSize == 0 || (checkFreezed && entry.isFreezed())) {
initPromise.trySuccess(null);
return;
}
final AtomicInteger initializedConnections = new AtomicInteger(minimumIdleSize);
int startAmount = Math.min(50, minimumIdleSize);
final AtomicInteger requests = new AtomicInteger(startAmount);
for (int i = 0; i < startAmount; i++) {
createConnection(checkFreezed, requests, entry, initPromise, minimumIdleSize, initializedConnections);
}
}
//创建连接对象到连接池中
private void createConnection(final boolean checkFreezed, final AtomicInteger requests, final ClientConnectionsEntry entry, final RPromise<Void> initPromise,
final int minimumIdleSize, final AtomicInteger initializedConnections) {
if ((checkFreezed && entry.isFreezed()) || !tryAcquireConnection(entry)) {
int totalInitializedConnections = minimumIdleSize - initializedConnections.get();
Throwable cause = new RedisConnectionException(
"Unable to init enough connections amount! Only " + totalInitializedConnections + " from " + minimumIdleSize + " were initialized. Server: "
+ entry.getClient().getAddr());
initPromise.tryFailure(cause);
return;
}
acquireConnection(entry, new Runnable() {
@Override
public void run() {
RPromise<T> promise = connectionManager.newPromise();
createConnection(entry, promise);
promise.addListener(new FutureListener<T>() {
@Override
public void operationComplete(Future<T> future) throws Exception {
if (future.isSuccess()) {
T conn = future.getNow();
releaseConnection(entry, conn);
}
releaseConnection(entry);
if (!future.isSuccess()) {
int totalInitializedConnections = minimumIdleSize - initializedConnections.get();
String errorMsg;
if (totalInitializedConnections == 0) {
errorMsg = "Unable to connect to Redis server: " + entry.getClient().getAddr();
} else {
errorMsg = "Unable to init enough connections amount! Only " + totalInitializedConnections
+ " from " + minimumIdleSize + " were initialized. Redis server: " + entry.getClient().getAddr();
}
Throwable cause = new RedisConnectionException(errorMsg, future.cause());
initPromise.tryFailure(cause);
return;
}
int value = initializedConnections.decrementAndGet();
if (value == 0) {
log.info("{} connections initialized for {}", minimumIdleSize, entry.getClient().getAddr());
if (!initPromise.trySuccess(null)) {
throw new IllegalStateException();
}
} else if (value > 0 && !initPromise.isDone()) {
if (requests.incrementAndGet() <= minimumIdleSize) {
createConnection(checkFreezed, requests, entry, initPromise, minimumIdleSize, initializedConnections);
}
}
}
});
}
});
}
//连接池中租借出连接对象
public RFuture<T> get(RedisCommand<?> command) {
for (int j = entries.size() - 1; j >= 0; j--) {
final ClientConnectionsEntry entry = getEntry();
if (!entry.isFreezed()
&& tryAcquireConnection(entry)) {
return acquireConnection(command, entry);
}
}
List<InetSocketAddress> failedAttempts = new LinkedList<InetSocketAddress>();
List<InetSocketAddress> freezed = new LinkedList<InetSocketAddress>();
for (ClientConnectionsEntry entry : entries) {
if (entry.isFreezed()) {
freezed.add(entry.getClient().getAddr());
} else {
failedAttempts.add(entry.getClient().getAddr());
}
}
StringBuilder errorMsg = new StringBuilder(getClass().getSimpleName() + " no available Redis entries. ");
if (!freezed.isEmpty()) {
errorMsg.append(" Disconnected hosts: " + freezed);
}
if (!failedAttempts.isEmpty()) {
errorMsg.append(" Hosts disconnected due to `failedAttempts` limit reached: " + failedAttempts);
}
RedisConnectionException exception = new RedisConnectionException(errorMsg.toString());
return connectionManager.newFailedFuture(exception);
}
//连接池中租借出连接对象执行操作RedisCommand
public RFuture<T> get(RedisCommand<?> command, ClientConnectionsEntry entry) {
if ((!entry.isFreezed() || entry.getFreezeReason() == FreezeReason.SYSTEM) &&
tryAcquireConnection(entry)) {
return acquireConnection(command, entry);
}
RedisConnectionException exception = new RedisConnectionException(
"Can't aquire connection to " + entry);
return connectionManager.newFailedFuture(exception);
}
//通过向redis服务端发送PING看是否返回PONG来检测连接
private void ping(RedisConnection c, final FutureListener<String> pingListener) {
RFuture<String> f = c.async(RedisCommands.PING);
f.addListener(pingListener);
}
//归还连接对象到连接池
public void returnConnection(ClientConnectionsEntry entry, T connection) {
if (entry.isFreezed()) {
connection.closeAsync();
} else {
releaseConnection(entry, connection);
}
releaseConnection(entry);
}
//释放连接池中连接对象
protected void releaseConnection(ClientConnectionsEntry entry) {
entry.releaseConnection();
}
//释放连接池中连接对象
protected void releaseConnection(ClientConnectionsEntry entry, T conn) {
entry.releaseConnection(conn);
}
}
Redisson初始化connectionManager
那么这些连接池是在哪里初始化的?如何初始化的?读操作和写操作如何获取连接的?
Redisson接口
RedissonClient.java是一个接口类,它的实现类是Redisson.java,对于Redisson.java的介绍先以一张Redisson的4大组件关系图开始,如下图:

对Redisson.java的代码注释如下:
/**
* 根据配置Config创建redisson操作类RedissonClient
* @param config for Redisson
* @return Redisson instance
*/
public static RedissonClient create(Config config) {
//调用构造方法
Redisson redisson = new Redisson(config);
if (config.isRedissonReferenceEnabled()) {
redisson.enableRedissonReferenceSupport();
}
return redisson;
}
/**
* Redisson构造方法
* @param config for Redisson
* @return Redisson instance
*/
protected Redisson(Config config) {
//赋值变量config
this.config = config;
//产生一份对于传入config的备份
Config configCopy = new Config(config);
//根据配置config的类型(主从模式、单机模式、哨兵模式、集群模式、亚马逊云模式、微软云模式)而进行不同的初始化
connectionManager = ConfigSupport.createConnectionManager(configCopy);
//连接池对象回收调度器
evictionScheduler = new EvictionScheduler(connectionManager.getCommandExecutor());
//Redisson的对象编码类
codecProvider = configCopy.getCodecProvider();
//Redisson的ResolverProvider,默认为org.redisson.liveobject.provider.DefaultResolverProvider
resolverProvider = configCopy.getResolverProvider();
}
其中与连接池相关的就是ConnectionManager.
ConnectionManager的初始化转交工具类ConfigSupport.java进行,ConfigSupport.java会根据部署方式(主从模式、单机模式、哨兵模式、集群模式、亚马逊云模式、微软云模式)的不同而分别进行。
ConfigSupport.java
这里现将ConfigSupport.java创建ConnectionManager的核心代码注释如下:
/**
* 据配置config的类型(主从模式、单机模式、哨兵模式、集群模式、亚马逊云模式、微软云模式)而进行不同的初始化
* @param configCopy for Redisson
* @return ConnectionManager instance
*/
public static ConnectionManager createConnectionManager(Config configCopy) {
if (configCopy.getMasterSlaveServersConfig() != null) {//配置configCopy类型为主从模式
validate(configCopy.getMasterSlaveServersConfig());
return new MasterSlaveConnectionManager(configCopy.getMasterSlaveServersConfig(), configCopy);
} else if (configCopy.getSingleServerConfig() != null) {//配置configCopy类型为单机模式
validate(configCopy.getSingleServerConfig());
return new SingleConnectionManager(configCopy.getSingleServerConfig(), configCopy);
} else if (configCopy.getSentinelServersConfig() != null) {//配置configCopy类型为哨兵模式
validate(configCopy.getSentinelServersConfig());
return new SentinelConnectionManager(configCopy.getSentinelServersConfig(), configCopy);
} else if (configCopy.getClusterServersConfig() != null) {//配置configCopy类型为集群模式
validate(configCopy.getClusterServersConfig());
return new ClusterConnectionManager(configCopy.getClusterServersConfig(), configCopy);
} else if (configCopy.getElasticacheServersConfig() != null) {//配置configCopy类型为亚马逊云模式
validate(configCopy.getElasticacheServersConfig());
return new ElasticacheConnectionManager(configCopy.getElasticacheServersConfig(), configCopy);
} else if (configCopy.getReplicatedServersConfig() != null) {//配置configCopy类型为微软云模式
validate(configCopy.getReplicatedServersConfig());
return new ReplicatedConnectionManager(configCopy.getReplicatedServersConfig(), configCopy);
} else if (configCopy.getConnectionManager() != null) {//直接返回configCopy自带的默认ConnectionManager
return configCopy.getConnectionManager();
}else {
throw new IllegalArgumentException("server(s) address(es) not defined!");
}
}
上面可以看到根据传入的配置Config.java的不同,会分别创建不同的ConnectionManager的实现类。
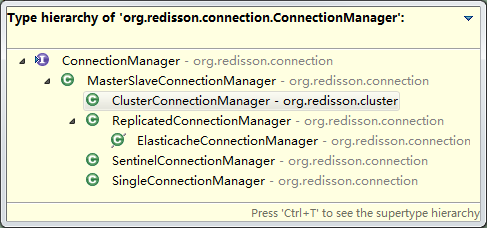
ConnectionManager的6个实现类
这里开始介绍ConnectionManager,ConnectionManager.java是一个接口类,它有6个实现类,分别对应着不同的部署模式(主从模式、单机模式、哨兵模式、集群模式、亚马逊云模式、微软云模式)
如下如所示:
MasterSlaveConnectionManager.java
这里以主从部署方式进行讲解,先通过一张图了解MasterSlaveConnectionManager的组成:
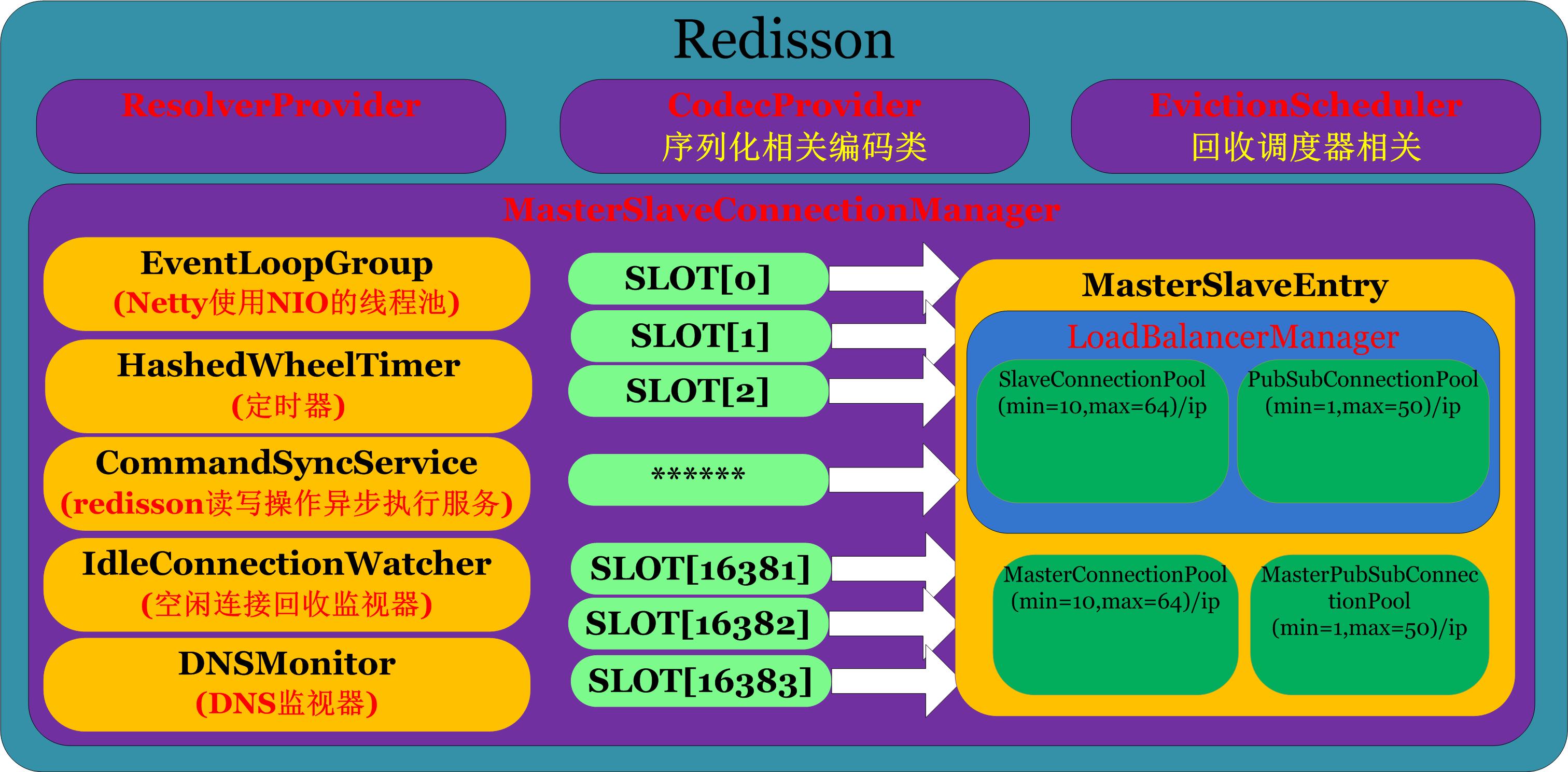
上图中最终要的组件要数MasterSlaveEntry,在后面即将进行介绍,这里注释
MasterSlaveConnectionManager.java的核心代码如下:
/**
* MasterSlaveConnectionManager的构造方法
* @param cfg for MasterSlaveServersConfig
* @param config for Config
*/
public MasterSlaveConnectionManager(MasterSlaveServersConfig cfg, Config config) {
//调用构造方法
this(config);
//
initTimer(cfg);
this.config = cfg;
//初始化MasterSlaveEntry
initSingleEntry();
}
/**
* MasterSlaveConnectionManager的构造方法
* @param cfg for Config
*/
public MasterSlaveConnectionManager(Config cfg) {
//读取redisson的jar中的文件META-INF/MANIFEST.MF,打印出Bundle-Version对应的Redisson版本信息
Version.logVersion();
//EPOLL是linux的多路复用IO模型的增强版本,这里如果启用EPOLL,就让redisson底层netty使用EPOLL的方式,否则配置netty里的NIO非阻塞方式
if (cfg.isUseLinuxNativeEpoll()) {
if (cfg.getEventLoopGroup() == null) {
//使用linux IO非阻塞模型EPOLL
this.group = new EpollEventLoopGroup(cfg.getNettyThreads(), new DefaultThreadFactory("redisson-netty"));
} else {
this.group = cfg.getEventLoopGroup();
}
this.socketChannelClass = EpollSocketChannel.class;
} else {
if (cfg.getEventLoopGroup() == null) {
//使用linux IO非阻塞模型NIO
this.group = new NioEventLoopGroup(cfg.getNettyThreads(), new DefaultThreadFactory("redisson-netty"));
} else {
this.group = cfg.getEventLoopGroup();
}
this.socketChannelClass = NioSocketChannel.class;
}
if (cfg.getExecutor() == null) {
//线程池大小,对于2U 2CPU 8cores/cpu,意思是有2块板子,每个板子上8个物理CPU,那么总计物理CPU个数为16
//对于linux有个超线程概念,意思是每个物理CPU可以虚拟出2个逻辑CPU,那么总计逻辑CPU个数为32
//这里Runtime.getRuntime().availableProcessors()取的是逻辑CPU的个数,所以这里线程池大小会是64
int threads = Runtime.getRuntime().availableProcessors() * 2;
if (cfg.getThreads() != 0) {
threads = cfg.getThreads();
}
executor = Executors.newFixedThreadPool(threads, new DefaultThreadFactory("redisson"));
} else {
executor = cfg.getExecutor();
}
this.cfg = cfg;
this.codec = cfg.getCodec();
//一个可以获取异步执行任务返回值的回调对象,本质是对于java的Future的实现,监控MasterSlaveConnectionManager的shutdown进行一些必要的处理
this.shutdownPromise = newPromise();
//一个持有MasterSlaveConnectionManager的异步执行服务
this.commandExecutor = new CommandSyncService(this);
}
/**
* 初始化定时调度器
* @param config for MasterSlaveServersConfig
*/
protected void initTimer(MasterSlaveServersConfig config) {
//读取超时时间配置信息
int[] timeouts = new int[]{config.getRetryInterval(), config.getTimeout(), config.getReconnectionTimeout()};
Arrays.sort(timeouts);
int minTimeout = timeouts[0];
//设置默认超时时间
if (minTimeout % 100 != 0) {
minTimeout = (minTimeout % 100) / 2;
} else if (minTimeout == 100) {
minTimeout = 50;
} else {
minTimeout = 100;
}
//创建定时调度器
timer = new HashedWheelTimer(Executors.defaultThreadFactory(), minTimeout, TimeUnit.MILLISECONDS, 1024);
// to avoid assertion error during timer.stop invocation
try {
Field leakField = HashedWheelTimer.class.getDeclaredField("leak");
leakField.setAccessible(true);
leakField.set(timer, null);
} catch (Exception e) {
throw new IllegalStateException(e);
}
//检测MasterSlaveConnectionManager的空闲连接的监视器IdleConnectionWatcher,会清理不用的空闲的池中连接对象
connectionWatcher = new IdleConnectionWatcher(this, config);
}
/**
* 创建MasterSlaveConnectionManager的MasterSlaveEntry
*/
protected void initSingleEntry() {
try {
//主从模式下0~16383加入到集合slots
HashSet<ClusterSlotRange> slots = new HashSet<ClusterSlotRange>();
slots.add(singleSlotRange);
MasterSlaveEntry entry;
if (config.checkSkipSlavesInit()) {//ReadMode不为MASTER并且SubscriptionMode不为MASTER才执行
entry = new SingleEntry(slots, this, config);
RFuture<Void> f = entry.setupMasterEntry(config.getMasterAddress());
f.syncUninterruptibly();
} else {//默认主从部署ReadMode=SLAVE,SubscriptionMode=SLAVE,这里会执行
entry = createMasterSlaveEntry(config, slots);
}
//将每个分片0~16383都指向创建的MasterSlaveEntry
for (int slot = singleSlotRange.getStartSlot(); slot < singleSlotRange.getEndSlot() + 1; slot++) {
addEntry(slot, entry);
}
//DNS相关
if (config.getDnsMonitoringInterval() != -1) {
dnsMonitor = new DNSMonitor(this, Collections.singleton(config.getMasterAddress()),
config.getSlaveAddresses(), config.getDnsMonitoringInterval());
dnsMonitor.start();
}
} catch (RuntimeException e) {
stopThreads();
throw e;
}
}
/**
* MasterSlaveEntry的构造方法
* @param config for MasterSlaveServersConfig
* @param slots for HashSet<ClusterSlotRange>
* @return MasterSlaveEntry
*/
protected MasterSlaveEntry createMasterSlaveEntry(MasterSlaveServersConfig config, HashSet<ClusterSlotRange> slots) {
//创建MasterSlaveEntry
MasterSlaveEntry entry = new MasterSlaveEntry(slots, this, config);
//从节点连接池SlaveConnectionPool和PubSubConnectionPool的默认的最小连接数初始化
List<RFuture<Void>> fs = entry.initSlaveBalancer(java.util.Collections.<URI>emptySet());
for (RFuture<Void> future : fs) {
future.syncUninterruptibly();
}
主节点连接池MasterConnectionPool和MasterPubSubConnectionPool的默认的最小连接数初始化
RFuture<Void> f = entry.setupMasterEntry(config.getMasterAddress());
f.syncUninterruptibly();
return entry;
}
上面个人觉得有两处代码值得我们特别关注,特别说明如下:
- entry.initSlaveBalancer:从节点连接池SlaveConnectionPool和PubSubConnectionPool的默认的最小连接数初始化。
- entry.setupMasterEntry:主节点连接池MasterConnectionPool和MasterPubSubConnectionPool的默认的最小连接数初始化。
MasterSlaveEntry.java
用一张图来解释MasterSlaveEntry的组件如下:

MasterSlaveEntry.java里正是我们一直在寻找着的四个连接池
-
MasterConnectionPool、
-
MasterPubSubConnectionPool、
-
SlaveConnectionPool和
-
PubSubConnectionPool,
MasterSlaveEntry.java的核心代码如下:
/**
* MasterSlaveEntry的构造方法
* @param slotRanges for Set<ClusterSlotRange>
* @param connectionManager for ConnectionManager
* @param config for MasterSlaveServersConfig
*/
public MasterSlaveEntry(Set<ClusterSlotRange> slotRanges, ConnectionManager connectionManager, MasterSlaveServersConfig config) {
//主从模式下0~16383加入到集合slots
for (ClusterSlotRange clusterSlotRange : slotRanges) {
for (int i = clusterSlotRange.getStartSlot(); i < clusterSlotRange.getEndSlot() + 1; i++) {
slots.add(i);
}
}
//赋值MasterSlaveConnectionManager给connectionManager
this.connectionManager = connectionManager;
//赋值config
this.config = config;
//创建LoadBalancerManager
//其实LoadBalancerManager里持有者从节点的SlaveConnectionPool和PubSubConnectionPool
//并且此时连接池里还没有初始化默认的最小连接数
slaveBalancer = new LoadBalancerManager(config, connectionManager, this);
//创建主节点连接池MasterConnectionPool,此时连接池里还没有初始化默认的最小连接数
writeConnectionHolder = new MasterConnectionPool(config, connectionManager, this);
//创建主节点连接池MasterPubSubConnectionPool,此时连接池里还没有初始化默认的最小连接数
pubSubConnectionHolder = new MasterPubSubConnectionPool(config, connectionManager, this);
}
/**
* 从节点连接池SlaveConnectionPool和PubSubConnectionPool的默认的最小连接数初始化
* @param disconnectedNodes for Collection<URI>
* @return List<RFuture<Void>>
*/
public List<RFuture<Void>> initSlaveBalancer(Collection<URI> disconnectedNodes) {
//这里freezeMasterAsSlave=true
boolean freezeMasterAsSlave = !config.getSlaveAddresses().isEmpty() && !config.checkSkipSlavesInit() && disconnectedNodes.size() < config.getSlaveAddresses().size();
List<RFuture<Void>> result = new LinkedList<RFuture<Void>>();
//把主节点当作从节点处理,因为默认ReadMode=ReadMode.SLAVE,所以这里不会添加针对该节点的连接池
RFuture<Void> f = addSlave(config.getMasterAddress(), freezeMasterAsSlave, NodeType.MASTER);
result.add(f);
//读取从节点的地址信息,然后针对每个从节点地址创建SlaveConnectionPool和PubSubConnectionPool
//SlaveConnectionPool【初始化10个RedisConnection,最大可以扩展至64个】
//PubSubConnectionPool【初始化1个RedisPubSubConnection,最大可以扩展至50个】
for (URI address : config.getSlaveAddresses()) {
f = addSlave(address, disconnectedNodes.contains(address), NodeType.SLAVE);
result.add(f);
}
return result;
}
/**
* 从节点连接池SlaveConnectionPool和PubSubConnectionPool的默认的最小连接数初始化
* @param address for URI
* @param freezed for boolean
* @param nodeType for NodeType
* @return RFuture<Void>
*/
private RFuture<Void> addSlave(URI address, boolean freezed, NodeType nodeType) {
//创建到从节点的连接RedisClient
RedisClient client = connectionManager.createClient(NodeType.SLAVE, address);
ClientConnectionsEntry entry = new ClientConnectionsEntry(client,
this.config.getSlaveConnectionMinimumIdleSize(),
this.config.getSlaveConnectionPoolSize(),
this.config.getSubscriptionConnectionMinimumIdleSize(),
this.config.getSubscriptionConnectionPoolSize(), connectionManager, nodeType);
//默认只有主节点当作从节点是会设置freezed=true
if (freezed) {
synchronized (entry) {
entry.setFreezed(freezed);
entry.setFreezeReason(FreezeReason.SYSTEM);
}
}
//调用slaveBalancer来对从节点连接池SlaveConnectionPool和PubSubConnectionPool的默认的最小连接数初始化
return slaveBalancer.add(entry);
}
/**
* 主节点连接池MasterConnectionPool和MasterPubSubConnectionPool的默认的最小连接数初始化
* @param address for URI
* @return RFuture<Void>
*/
public RFuture<Void> setupMasterEntry(URI address) {
//创建到主节点的连接RedisClient
RedisClient client = connectionManager.createClient(NodeType.MASTER, address);
masterEntry = new ClientConnectionsEntry(
client,
config.getMasterConnectionMinimumIdleSize(),
config.getMasterConnectionPoolSize(),
config.getSubscriptionConnectionMinimumIdleSize(),
config.getSubscriptionConnectionPoolSize(),
connectionManager,
NodeType.MASTER);
//如果配置的SubscriptionMode=SubscriptionMode.MASTER就初始化MasterPubSubConnectionPool
//默认SubscriptionMode=SubscriptionMode.SLAVE,MasterPubSubConnectionPool这里不会初始化最小连接数
if (config.getSubscriptionMode() == SubscriptionMode.MASTER) {
//MasterPubSubConnectionPool【初始化1个RedisPubSubConnection,最大可以扩展至50个】
RFuture<Void> f = writeConnectionHolder.add(masterEntry);
RFuture<Void> s = pubSubConnectionHolder.add(masterEntry);
return CountListener.create(s, f);
}
//调用MasterConnectionPool使得连接池MasterConnectionPool里的对象最小个数为10个
//MasterConnectionPool【初始化10个RedisConnection,最大可以扩展至64个】
return writeConnectionHolder.add(masterEntry);
}
上面代码个人觉得有四个地方值得我们特别关注,它们是一个连接池创建对象的入口,列表如下:
- writeConnectionHolder.add(masterEntry):其实writeConnectionHolder的类型就是MasterConnectionPool,这里是连接池MasterConnectionPool里添加对象
- pubSubConnectionHolder.add(masterEntry):其实pubSubConnectionHolder的类型是MasterPubSubConnectionPool,这里是连接池MasterPubSubConnectionPool添加对象
- slaveConnectionPool.add(entry):这里是连接池SlaveConnectionPool里添加对象
- pubSubConnectionPool.add(entry):这里是连接池PubSubConnectionPool里添加对象
LoadBalancerManager.java
图解LoadBalancerManager.java的内部组成如下:

LoadBalancerManager.java里面有着从节点相关的两个重要的连接池SlaveConnectionPool和PubSubConnectionPool,这里注释LoadBalancerManager.java的核心代码如下:
/**
* LoadBalancerManager的构造方法
* @param config for MasterSlaveServersConfig
* @param connectionManager for ConnectionManager
* @param entry for MasterSlaveEntry
*/
public LoadBalancerManager(MasterSlaveServersConfig config, ConnectionManager connectionManager, MasterSlaveEntry entry) {
//赋值connectionManager
this.connectionManager = connectionManager;
//创建连接池SlaveConnectionPool
slaveConnectionPool = new SlaveConnectionPool(config, connectionManager, entry);
//创建连接池PubSubConnectionPool
pubSubConnectionPool = new PubSubConnectionPool(config, connectionManager, entry);
}
/**
* LoadBalancerManager的连接池SlaveConnectionPool和PubSubConnectionPool里池化对象添加方法,也即池中需要对象时,调用此方法添加
* @param entry for ClientConnectionsEntry
* @return RFuture<Void>
*/
public RFuture<Void> add(final ClientConnectionsEntry entry) {
final RPromise<Void> result = connectionManager.newPromise();
//创建一个回调监听器,在池中对象创建失败时,进行2次尝试
FutureListener<Void> listener = new FutureListener<Void>() {
AtomicInteger counter = new AtomicInteger(2);
@Override
public void operationComplete(Future<Void> future) throws Exception {
if (!future.isSuccess()) {
result.tryFailure(future.cause());
return;
}
if (counter.decrementAndGet() == 0) {
String addr = entry.getClient().getIpAddr();
ip2Entry.put(addr, entry);
result.trySuccess(null);
}
}
};
//调用slaveConnectionPool添加RedisConnection对象到池中
RFuture<Void> slaveFuture = slaveConnectionPool.add(entry);
slaveFuture.addListener(listener);
//调用pubSubConnectionPool添加RedisPubSubConnection对象到池中
RFuture<Void> pubSubFuture = pubSubConnectionPool.add(entry);
pubSubFuture.addListener(listener);
return result;
}
至此,我们已经了解了开篇提到的四个连接池是在哪里创建的。
连接池的初始化
ConnectionPool.java里获取读写操作的连接,是遍历ConnectionPool里维持的ClientConnectionsEntry列表,找到一非冻结的ClientConnectionsEntry;
然后调用ClientConnectionsEntry里的freeConnectionsCounter尝试将值减1,如果成功,说明连接池中可以获取到连接,那么就从ClientConnectionsEntry里获取一个连接出来,如果拿不到连接,会调用ClientConnectionsEntry创建一个新连接放置到连接池中,并返回此连接
回顾一下 ClientConnectionsEntry的组成图:
上面的代码说明如果 ClientConnectionsEntry里的 freeConnections有空闲连接,那么直接返回该连接,如果没有那么调用 RedisClient.connectAsync创建一个新的连接
/**
* 真正从连接池中获取连接
* @param entry for ClientConnectionsEntry
* @param promise for RPromise<T>
*/
private void connectTo(ClientConnectionsEntry entry, RPromise<T> promise) {
if (promise.isDone()) {
releaseConnection(entry);
return;
}
//从连接池中取出一个连接
T conn = poll(entry);
if (conn != null) {
if (!conn.isActive()) {
promiseFailure(entry, promise, conn);
return;
}
connectedSuccessful(entry, promise, conn);
return;
}
//如果仍然获取不到连接,可能连接池中连接对象都被租借了,这里开始创建一个新的连接对象放到连接池中
createConnection(entry, promise);
}
/**
* 从连接池中获取连接
* @param entry for ClientConnectionsEntry
* @return T
*/
protected T poll(ClientConnectionsEntry entry) {
return (T) entry.pollConnection();
}
/**
* 调用ClientConnectionsEntry创建一个连接放置到连接池中并返回此连接
* @param entry for ClientConnectionsEntry
* @param promise for RPromise<T>
*/
private void createConnection(final ClientConnectionsEntry entry, final RPromise<T> promise) {
//调用ClientConnectionsEntry创建一个连接放置到连接池中并返回此连接
RFuture<T> connFuture = connect(entry);
connFuture.addListener(new FutureListener<T>() {
@Override
public void operationComplete(Future<T> future) throws Exception {
if (!future.isSuccess()) {
promiseFailure(entry, promise, future.cause());
return;
}
T conn = future.getNow();
if (!conn.isActive()) {
promiseFailure(entry, promise, conn);
return;
}
connectedSuccessful(entry, promise, conn);
}
});
}
从freeConnections里获取一个连接并返回给读写操作使用
/**
* ClientConnectionsEntry里从freeConnections里获取一个连接并返回给读写操作使用
*/
public RedisConnection pollConnection() {
return freeConnections.poll();
}
新创建一个连接对象返回给读写操作使用
/**
* ClientConnectionsEntry里新创建一个连接对象返回给读写操作使用
*/
public RFuture<RedisConnection> connect() {
//调用RedisClient利用netty连接redis服务端,将返回的netty的outboundchannel包装成RedisConnection并返回
RFuture<RedisConnection> future = client.connectAsync();
future.addListener(new FutureListener<RedisConnection>() {
@Override
public void operationComplete(Future<RedisConnection> future) throws Exception {
if (!future.isSuccess()) {
return;
}
RedisConnection conn = future.getNow();
onConnect(conn);
log.debug("new connection created: {}", conn);
}
});
return future;
}
RedisClient管理Netty连接
使用java里的网络编程框架Netty连接redis服务端 RedisClient.java
package org.redisson.client;
...
/**
* 使用java里的网络编程框架Netty连接redis服务端
* 作者: Nikita Koksharov
*/
public class RedisClient {
private final Bootstrap bootstrap;//Netty的工具类Bootstrap,用于连接建立等作用
private final Bootstrap pubSubBootstrap;//Netty的工具类Bootstrap,用于连接建立等作用
private final InetSocketAddress addr;//socket连接的地址
//channels是netty提供的一个全局对象,里面记录着当前socket连接上的所有处于可用状态的连接channel
//channels会自动监测里面的channel,当channel断开时,会主动踢出该channel,永远保留当前可用的channel列表
private final ChannelGroup channels = new DefaultChannelGroup(GlobalEventExecutor.INSTANCE);
private ExecutorService executor;//REACOTR模型的java异步执行线程池
private final long commandTimeout;//超时时间
private Timer timer;//定时器
private boolean hasOwnGroup;
private RedisClientConfig config;//redis连接配置信息
//构造方法
public static RedisClient create(RedisClientConfig config) {
if (config.getTimer() == null) {
config.setTimer(new HashedWheelTimer());
}
return new RedisClient(config);
}
//构造方法
private RedisClient(RedisClientConfig config) {
this.config = config;
this.executor = config.getExecutor();
this.timer = config.getTimer();
addr = new InetSocketAddress(config.getAddress().getHost(), config.getAddress().getPort());
bootstrap = createBootstrap(config, Type.PLAIN);
pubSubBootstrap = createBootstrap(config, Type.PUBSUB);
this.commandTimeout = config.getCommandTimeout();
}
//java的网路编程框架Netty工具类Bootstrap初始化
private Bootstrap createBootstrap(RedisClientConfig config, Type type) {
Bootstrap bootstrap = new Bootstrap()
.channel(config.getSocketChannelClass())
.group(config.getGroup())
.remoteAddress(addr);
//注册netty相关socket数据处理RedisChannelInitializer
bootstrap.handler(new RedisChannelInitializer(bootstrap, config, this, channels, type));
//设置超时时间
bootstrap.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, config.getConnectTimeout());
return bootstrap;
}
//构造方法
@Deprecated
public RedisClient(String address) {
this(URIBuilder.create(address));
}
//构造方法
@Deprecated
public RedisClient(URI address) {
this(new HashedWheelTimer(), Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors() * 2), new NioEventLoopGroup(), address);
hasOwnGroup = true;
}
//构造方法
@Deprecated
public RedisClient(Timer timer, ExecutorService executor, EventLoopGroup group, URI address) {
this(timer, executor, group, address.getHost(), address.getPort());
}
//构造方法
@Deprecated
public RedisClient(String host, int port) {
this(new HashedWheelTimer(), Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors() * 2), new NioEventLoopGroup(), NioSocketChannel.class, host, port, 10000, 10000);
hasOwnGroup = true;
}
//构造方法
@Deprecated
public RedisClient(Timer timer, ExecutorService executor, EventLoopGroup group, String host, int port) {
this(timer, executor, group, NioSocketChannel.class, host, port, 10000, 10000);
}
//构造方法
@Deprecated
public RedisClient(String host, int port, int connectTimeout, int commandTimeout) {
this(new HashedWheelTimer(), Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors() * 2), new NioEventLoopGroup(), NioSocketChannel.class, host, port, connectTimeout, commandTimeout);
}
//构造方法
@Deprecated
public RedisClient(final Timer timer, ExecutorService executor, EventLoopGroup group, Class<? extends SocketChannel> socketChannelClass, String host, int port,
int connectTimeout, int commandTimeout) {
RedisClientConfig config = new RedisClientConfig();
config.setTimer(timer).setExecutor(executor).setGroup(group).setSocketChannelClass(socketChannelClass)
.setAddress(host, port).setConnectTimeout(connectTimeout).setCommandTimeout(commandTimeout);
this.config = config;
this.executor = config.getExecutor();
this.timer = config.getTimer();
addr = new InetSocketAddress(config.getAddress().getHost(), config.getAddress().getPort());
//java的网路编程框架Netty工具类Bootstrap初始化
bootstrap = createBootstrap(config, Type.PLAIN);
pubSubBootstrap = createBootstrap(config, Type.PUBSUB);
this.commandTimeout = config.getCommandTimeout();
}
//获取连接的IP地址
public String getIpAddr() {
return addr.getAddress().getHostAddress() + ":" + addr.getPort();
}
//获取socket连接的地址
public InetSocketAddress getAddr() {
return addr;
}
//获取超时时间
public long getCommandTimeout() {
return commandTimeout;
}
//获取netty的线程池
public EventLoopGroup getEventLoopGroup() {
return bootstrap.config().group();
}
//获取redis连接配置
public RedisClientConfig getConfig() {
return config;
}
//获取连接RedisConnection
public RedisConnection connect() {
try {
return connectAsync().syncUninterruptibly().getNow();
} catch (Exception e) {
throw new RedisConnectionException("Unable to connect to: " + addr, e);
}
}
//启动netty去连接redis服务端,设置java的Future尝试将netty连接上的OutBoundChannel包装成RedisConnection并返回RedisConnection
public RFuture<RedisConnection> connectAsync() {
final RPromise<RedisConnection> f = new RedissonPromise<RedisConnection>();
//netty连接redis服务端
ChannelFuture channelFuture = bootstrap.connect();
channelFuture.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(final ChannelFuture future) throws Exception {
if (future.isSuccess()) {
//将netty连接上的OutBoundChannel包装成RedisConnection并返回RedisConnection
final RedisConnection c = RedisConnection.getFrom(future.channel());
c.getConnectionPromise().addListener(new FutureListener<RedisConnection>() {
@Override
public void operationComplete(final Future<RedisConnection> future) throws Exception {
bootstrap.config().group().execute(new Runnable() {
@Override
public void run() {
if (future.isSuccess()) {
if (!f.trySuccess(c)) {
c.closeAsync();
}
} else {
f.tryFailure(future.cause());
c.closeAsync();
}
}
});
}
});
} else {
bootstrap.config().group().execute(new Runnable() {
public void run() {
f.tryFailure(future.cause());
}
});
}
}
});
return f;
}
//获取订阅相关连接RedisPubSubConnection
public RedisPubSubConnection connectPubSub() {
try {
return connectPubSubAsync().syncUninterruptibly().getNow();
} catch (Exception e) {
throw new RedisConnectionException("Unable to connect to: " + addr, e);
}
}
//启动netty去连接redis服务端,设置java的Future尝试将netty连接上的OutBoundChannel包装成RedisPubSubConnection并返回RedisPubSubConnection
public RFuture<RedisPubSubConnection> connectPubSubAsync() {
final RPromise<RedisPubSubConnection> f = new RedissonPromise<RedisPubSubConnection>();
//netty连接redis服务端
ChannelFuture channelFuture = pubSubBootstrap.connect();
channelFuture.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(final ChannelFuture future) throws Exception {
if (future.isSuccess()) {
//将netty连接上的OutBoundChannel包装成RedisPubSubConnection并返回RedisPubSubConnection
final RedisPubSubConnection c = RedisPubSubConnection.getFrom(future.channel());
c.<RedisPubSubConnection>getConnectionPromise().addListener(new FutureListener<RedisPubSubConnection>() {
@Override
public void operationComplete(final Future<RedisPubSubConnection> future) throws Exception {
bootstrap.config().group().execute(new Runnable() {
@Override
public void run() {
if (future.isSuccess()) {
if (!f.trySuccess(c)) {
c.closeAsync();
}
} else {
f.tryFailure(future.cause());
c.closeAsync();
}
}
});
}
});
} else {
bootstrap.config().group().execute(new Runnable() {
public void run() {
f.tryFailure(future.cause());
}
});
}
}
});
return f;
}
//关闭netty网络连接
public void shutdown() {
shutdownAsync().syncUninterruptibly();
if (hasOwnGroup) {
timer.stop();
executor.shutdown();
try {
executor.awaitTermination(15, TimeUnit.SECONDS);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
bootstrap.config().group().shutdownGracefully();
}
}
//异步关闭netty网络连接
public ChannelGroupFuture shutdownAsync() {
for (Channel channel : channels) {
RedisConnection connection = RedisConnection.getFrom(channel);
if (connection != null) {
connection.setClosed(true);
}
}
return channels.close();
}
@Override
public String toString() {
return "[addr=" + addr + "]";
}
}
读写负载流程图
ConnectionPool.java里获取读写操作的连接,是遍历ConnectionPool里维持的ClientConnectionsEntry列表,找到一非冻结的ClientConnectionsEntry,然后调用ClientConnectionsEntry里的freeConnectionsCounter尝试将值减1,如果成功,说明连接池中可以获取到连接,那么就从ClientConnectionsEntry里获取一个连接出来,如果拿不到连接,会调用ClientConnectionsEntry创建一个新连接放置到连接池中,并返回此连接,
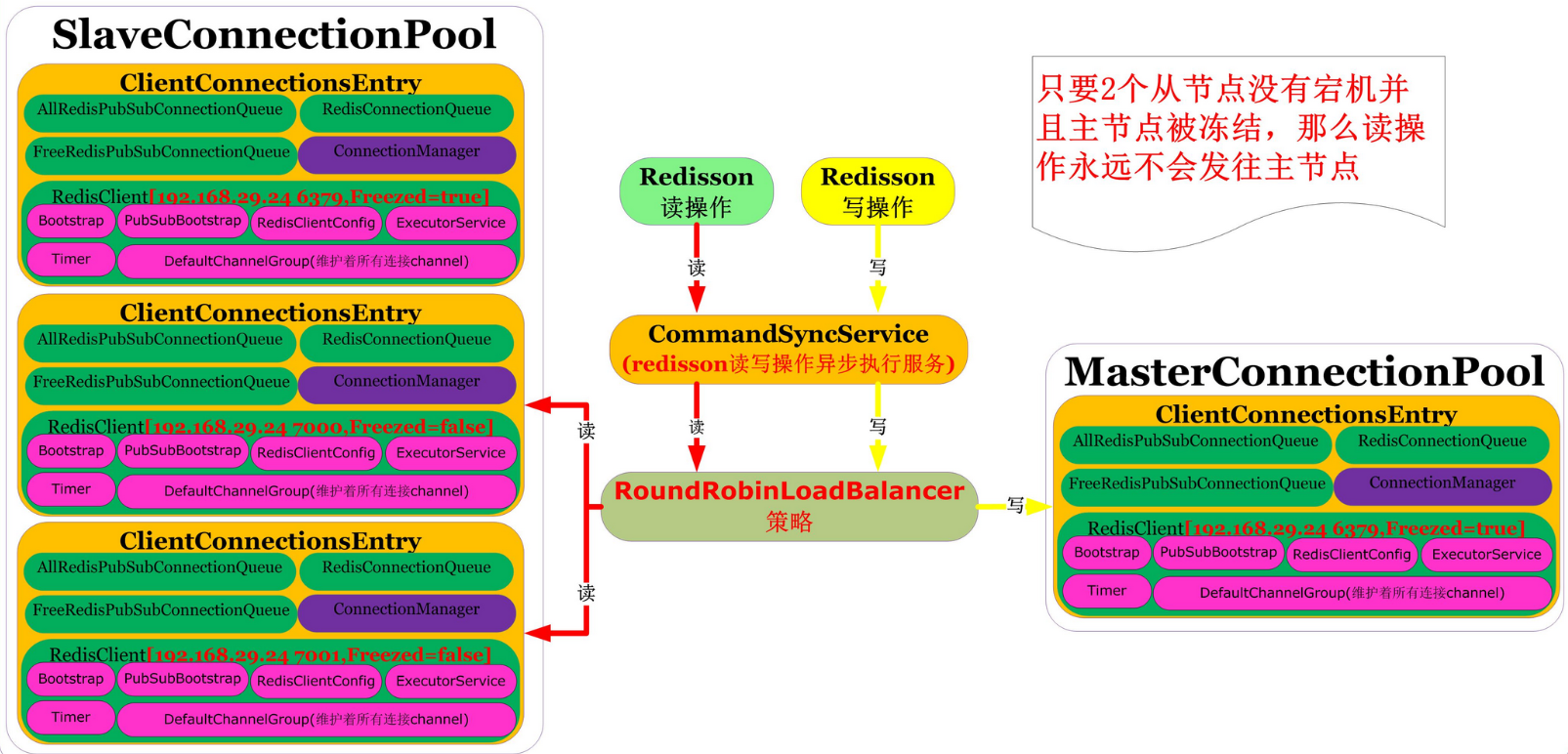
CommandAsyncExecutor 开始获取连接
读写操作首先都需要获取到一个连接对象,在上面的分析中我们知道读写操作都是通过CommandAsyncExecutor.java里的如下代码获取连接对象:
protected RFuture<RedisConnection> getConnection() {
//开始从connectionManager获取池中的连接
//这里采用异步方式,创建一个RFuture对象,等待池中连接,一旦获得连接,然后进行读和写操作
final RFuture<RedisConnection> connectionFuture;
if (readOnlyMode) {
//对于读操作默认readOnlyMode=true,这里会执行
connectionFuture = connectionManager.connectionReadOp(source, command);
} else {
//对于写操作默认readOnlyMode=false,这里会执行
connectionFuture = connectionManager.connectionWriteOp(source, command);
}
}
上面:
- 读操作(readOnlyMode=true)调用了 connectionManager.connectionReadOp从连接池获取连接对象,
- 写操作(readOnlyMode=false)调用了connectionManager.connectionWriteOp从连接池获取连接对象,
从connectionManager获取连接
我们继续跟进 connectionManager关于connectionReadOp和connectionWriteOp
/**
* 读操作通过ConnectionManager从连接池获取连接对象
* @param source for NodeSource
* @param command for RedisCommand<?>
* @return RFuture<RedisConnection>
*/
public RFuture<RedisConnection> connectionReadOp(NodeSource source, RedisCommand<?> command) {
//这里之前分析过source=NodeSource【slot=null,addr=null,redirect=null,entry=MasterSlaveEntry】
MasterSlaveEntry entry = source.getEntry();
if (entry == null && source.getSlot() != null) {//这里不会执行source里slot=null
entry = getEntry(source.getSlot());
}
if (source.getAddr() != null) {//这里不会执行source里addr=null
entry = getEntry(source.getAddr());
if (entry == null) {
for (MasterSlaveEntry e : getEntrySet()) {
if (e.hasSlave(source.getAddr())) {
entry = e;
break;
}
}
}
if (entry == null) {
RedisNodeNotFoundException ex = new RedisNodeNotFoundException("Node: " + source.getAddr() + " for slot: " + source.getSlot() + " hasn't been discovered yet");
return RedissonPromise.newFailedFuture(ex);
}
return entry.connectionReadOp(command, source.getAddr());
}
if (entry == null) {//这里不会执行source里entry不等于null
RedisNodeNotFoundException ex = new RedisNodeNotFoundException("Node: " + source.getAddr() + " for slot: " + source.getSlot() + " hasn't been discovered yet");
return RedissonPromise.newFailedFuture(ex);
}
//MasterSlaveEntry里从连接池获取连接对象
return entry.connectionReadOp(command);
}
/**
* 写操作通过ConnectionManager从连接池获取连接对象
* @param source for NodeSource
* @param command for RedisCommand<?>
* @return RFuture<RedisConnection>
*/
public RFuture<RedisConnection> connectionWriteOp(NodeSource source, RedisCommand<?> command) {
//这里之前分析过source=NodeSource【slot=null,addr=null,redirect=null,entry=MasterSlaveEntry】
MasterSlaveEntry entry = source.getEntry();
if (entry == null) {
entry = getEntry(source);
}
if (entry == null) {//这里不会执行source里entry不等于null
RedisNodeNotFoundException ex = new RedisNodeNotFoundException("Node: " + source.getAddr() + " for slot: " + source.getSlot() + " hasn't been discovered yet");
return RedissonPromise.newFailedFuture(ex);
}
//MasterSlaveEntry里从连接池获取连接对象
return entry.connectionWriteOp(command);
}
上面调用 ConnectionManager从连接池获取连接对象,但是 ConnectionManager却将获取连接操作转交 MasterSlaveEntry处理
回顾一下ConnectionManager 的组成:
从ConnectionPool获取连接
最终的获取连接对象都转交到了从连接池 ConnectionPool
ConnectionPool.java里获取读写操作的连接,是遍历ConnectionPool里维持的ClientConnectionsEntry列表,找到一非冻结的ClientConnectionsEntry,
然后,ClientConnectionsEntry里的freeConnectionsCounter尝试将值减1,
如果成功,说明连接池中可以获取到连接,那么就从ClientConnectionsEntry里获取一个连接出来,如果拿不到连接,会调用ClientConnectionsEntry创建一个新连接放置到连接池中,并返回此连接
/**
* 读写操作从ConnectionPool.java连接池里获取连接对象
* @param command for RedisCommand<?>
* @return RFuture<T>
*/
public RFuture<T> get(RedisCommand<?> command) {
List<ClientConnectionsEntry> entriesCopy = new LinkedList<ClientConnectionsEntry>(entries);
for (Iterator<ClientConnectionsEntry> iterator = entriesCopy.iterator(); iterator.hasNext();) {
//ClientConnectionsEntry里对应的redis节点为非冻结节点,也即freezed=false
ClientConnectionsEntry entry = iterator.next();
if (!((!entry.isFreezed() || entry.isMasterForRead())
&& tryAcquireConnection(entry))) {
iterator.remove();
}
}
while (!entriesCopy.isEmpty()) {
//遍历entriesCopy列表
//遍历的算法默认为RoundRobinLoadBalancer
ClientConnectionsEntry entry = config.getLoadBalancer().getEntry(entriesCopy);
return acquireConnection(command, entry);
}
//记录失败节点信息
List<InetSocketAddress> failed = new LinkedList<InetSocketAddress>();
//记录冻结的节点信息
List<InetSocketAddress> freezed = new LinkedList<InetSocketAddress>();
for (ClientConnectionsEntry entry : entries) {
if (entry.isFailed()) {
failed.add(entry.getClient().getAddr());
} else if (entry.isFreezed()) {
freezed.add(entry.getClient().getAddr());
}
}
StringBuilder errorMsg = new StringBuilder(getClass().getSimpleName() + " no available Redis entries. ");
if (!freezed.isEmpty()) {
errorMsg.append(" Disconnected hosts: " + freezed);
}
if (!failed.isEmpty()) {
errorMsg.append(" Hosts disconnected due to errors during `failedSlaveCheckInterval`: " + failed);
}
RedisConnectionException exception = new RedisConnectionException(errorMsg.toString());
return RedissonPromise.newFailedFuture(exception);
}
/**
* 读写操作从ConnectionPool.java连接池里获取连接对象
* @param command for RedisCommand<?>
* @param entry for ClientConnectionsEntry
* @return RFuture<T>
*/
private RFuture<T> acquireConnection(RedisCommand<?> command, final ClientConnectionsEntry entry) {
//创建一个异步结果获取RPromise
final RPromise<T> result = connectionManager.newPromise();
//获取连接前首先将ClientConnectionsEntry里的空闲连接信号freeConnectionsCounter值减1
//该操作成功后将调用这里的回调函数AcquireCallback<T>
AcquireCallback<T> callback = new AcquireCallback<T>() {
@Override
public void run() {
result.removeListener(this);
//freeConnectionsCounter值减1成功,说明获取可以获取到连接
//这里才是真正获取连接的操作
connectTo(entry, result);
}
@Override
public void operationComplete(Future<T> future) throws Exception {
entry.removeConnection(this);
}
};
//异步结果获取RPromise绑定到上面的回调函数callback
result.addListener(callback);
//尝试将ClientConnectionsEntry里的空闲连接信号freeConnectionsCounter值减1,如果成功就调用callback从连接池获取连接
acquireConnection(entry, callback);
//返回异步结果获取RPromise
return result;
}
/**
* 真正从连接池中获取连接
* @param entry for ClientConnectionsEntry
* @param promise for RPromise<T>
*/
private void connectTo(ClientConnectionsEntry entry, RPromise<T> promise) {
if (promise.isDone()) {
releaseConnection(entry);
return;
}
//从连接池中取出一个连接
T conn = poll(entry);
if (conn != null) {
if (!conn.isActive()) {
promiseFailure(entry, promise, conn);
return;
}
connectedSuccessful(entry, promise, conn);
return;
}
//如果仍然获取不到连接,可能连接池中连接对象都被租借了,这里开始创建一个新的连接对象放到连接池中
createConnection(entry, promise);
}
/**
* 从连接池中获取连接
* @param entry for ClientConnectionsEntry
* @return T
*/
protected T poll(ClientConnectionsEntry entry) {
return (T) entry.pollConnection();
}
/**
* 调用ClientConnectionsEntry创建一个连接放置到连接池中并返回此连接
* @param entry for ClientConnectionsEntry
* @param promise for RPromise<T>
*/
private void createConnection(final ClientConnectionsEntry entry, final RPromise<T> promise) {
//调用ClientConnectionsEntry创建一个连接放置到连接池中并返回此连接
RFuture<T> connFuture = connect(entry);
connFuture.addListener(new FutureListener<T>() {
@Override
public void operationComplete(Future<T> future) throws Exception {
if (!future.isSuccess()) {
promiseFailure(entry, promise, future.cause());
return;
}
T conn = future.getNow();
if (!conn.isActive()) {
promiseFailure(entry, promise, conn);
return;
}
connectedSuccessful(entry, promise, conn);
}
});
}
冻结判断条件
每个ConnectionPool持有的ClientConnectionsEntry对象冻结判断条件
一个节点被判断为冻结,必须同时满足以下条件:
- 该节点有slave节点,并且slave从节点个数大于0;
- 设置的配置ReadMode为false并且SubscriptionMode不为MASTER;
- 该节点的从节点至少有一个存活着,也即如果有从节点宕机,宕机的从节点的个数小于该节点总的从节点个数
主从模式的缺陷
问题:
主从模式下,当主节点宕机了,整个集群就没有可写的节点了。
解决方案:
由于从节点上备份了主节点的所有数据,那在主节点宕机的情况下,如果能够将从节点变成一个主节点,是不是就可以解决这个问题了呢?是的,这个就是Sentinel哨兵的作用。
总之,当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。哨兵模式就是为了解决此类问题而产生的。
Sentinel(哨兵)模式
Sentinel(哨兵)是用于监控redis集群中Master状态的工具,是Redis 的高可用性解决方案,sentinel哨兵模式已经被集成在redis2.4之后的版本中。sentinel系统可以监视一个或者多个redis master服务,以及这些master服务的所有slave;当某个master服务下线时,自动将该master下的slave升级为master服务替代已下线的master服务继续处理请求。
哨兵的任务
Redis 的 Sentinel 系统用于管理多个 Redis 服务器(instance), 该系统执行以下三个任务:
监控(Monitoring):
Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
提醒(Notification):
当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
自动故障迁移(Automatic failover):
当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会进行选举,将其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
监控(Monitoring)
(1)Sentinel可以监控任意多个Master和该Master下的Slaves。(即多个主从模式)
(2)同一个哨兵下的、不同主从模型,彼此之间相互独立。
(3)Sentinel会不断检查Master和Slaves是否正常。
自动故障切换(Automatic failover)
Sentinel网络
监控同一个Master的Sentinel会自动连接,组成一个分布式的Sentinel网络,互相通信并交换彼此关于被监视服务器的信息。
下图中,三个监控s1的Sentinel,自动组成Sentinel网络结构。
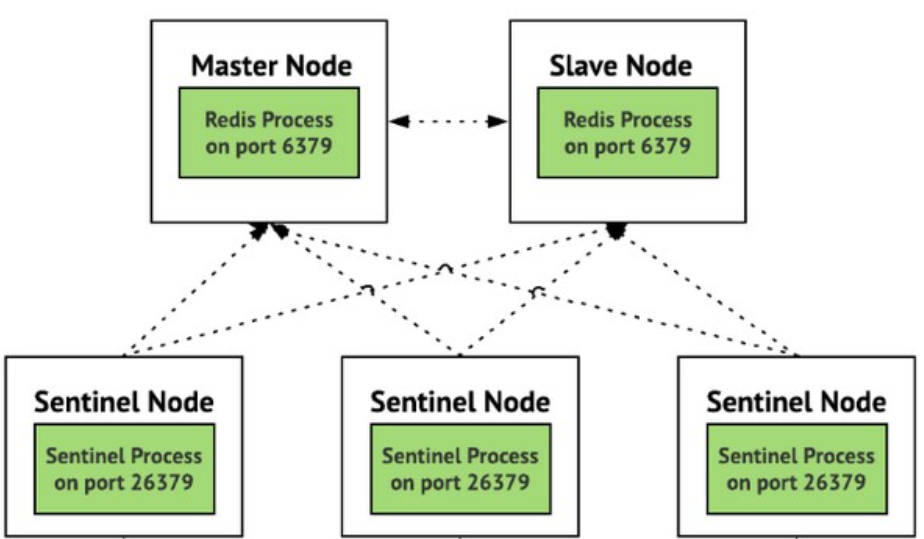
当一个集群中的master失效之后,sentinel可以选举出一个新的master用于自动接替master的工作,集群中的其他redis服务器自动指向新的master同步数据。
一般建议sentinel采取奇数台,防止某一台sentinel无法连接到master导致误切换。
疑问:为什么要使用sentinel网络呢?
答:当只有一个sentinel的时候,如果这个sentinel挂掉了,那么就无法实现自动故障切换了。在sentinel网络中,只要还有一个sentinel活着,就可以实现故障切换。
有关sentinel的几个要点:
-
sentinel本身是监督者的身份,没有存储功能。在整个体系中一个sentinel者或一群sentinels与主从服务架构体系是监督与被监督的关系。
-
作为一个sentinel在整个架构体系中有就可能有如下三种交互:sentinel与主服务器、sentinel与从服务器、sentinel与其他sentinel。
-
既然是交互,交互所需要的基本内容对于这三种场景还是一样的,首先要构建这样的一个交互网络无可避免,需要节点的注册与发现、节点之间的通信连接、节点保活、节点之间的通信协议等。
-
因为角色不同所以在这个架构体系中承担的功能也不一样。所以交互的内容也不一样。
在理解了以上几点之后,我们一步步从构建sentinel网络体系到这整个体系结构是如何来保证其高可用性来分析。
故障切换的过程
(1) 判定客观下线
假如有三个哨兵和一主两从的节点,下面是一主多从
哨兵之间会互相监测运行状态,并且会交换一下节点监测的状态,同时哨兵也会监测主从节点的状态。
如果检测到某一个节点没有正常回复,并且距离上次正常回复的时间超过了某个阈值,那么就认为该节点为主观下线。 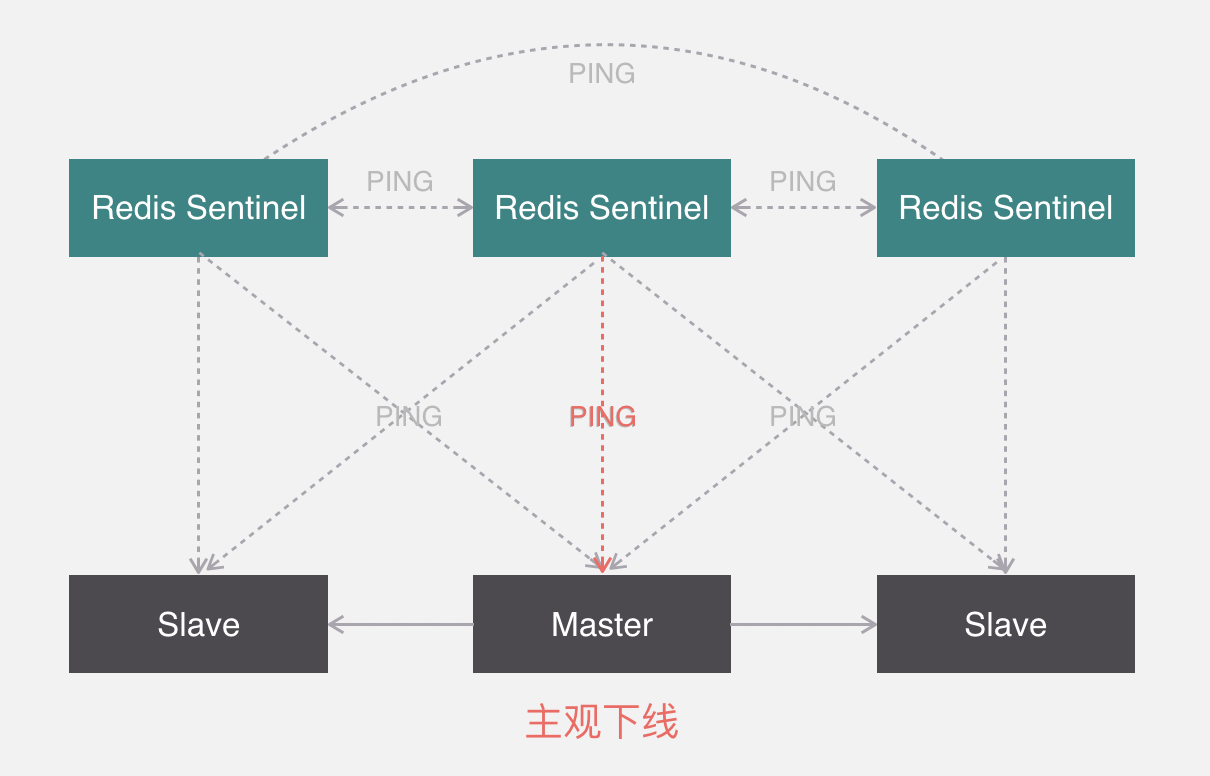
这个时候其他哨兵也会来监测该节点是不是真的主观下线,如果有足够多数量的哨兵都认为它确实主观下线了,那么它就会被标记为客观下线。
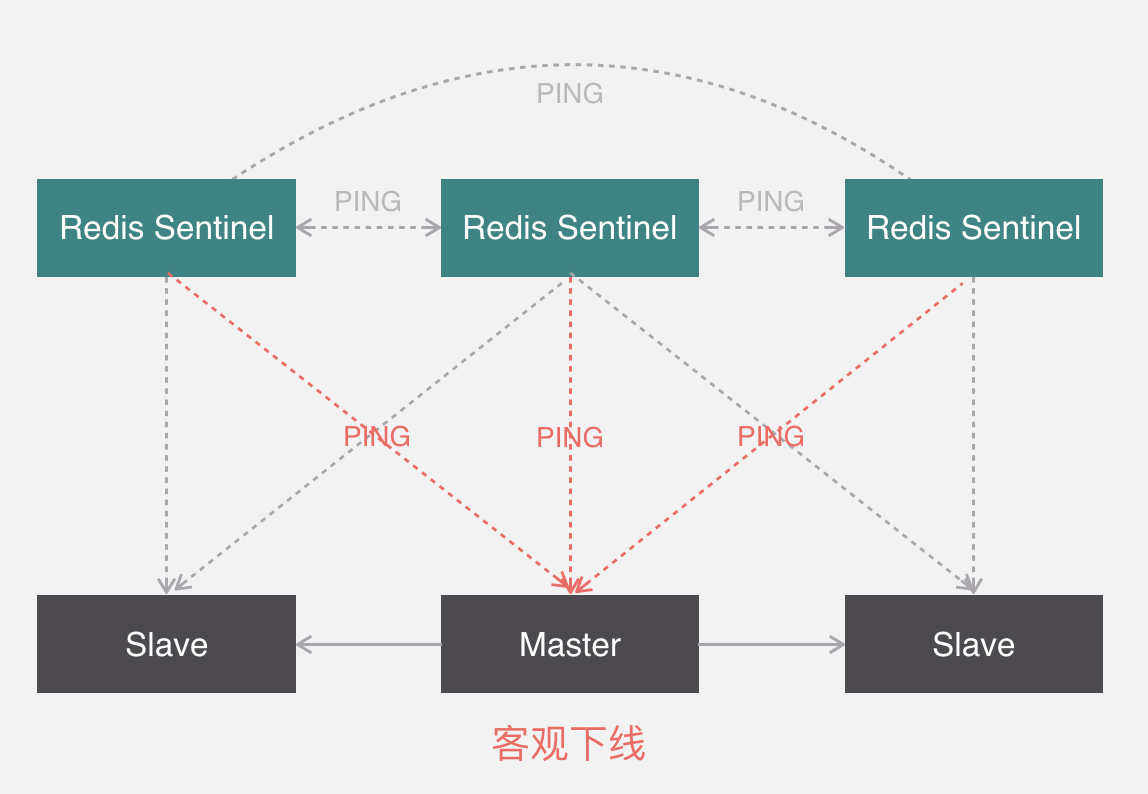
这个时候哨兵开始启动故障切换的流程。
关于主从节点的切换有两个环节,第一个是哨兵要选举出领头人Sentinel Leader来负责下线机器的故障转移,第二是从Slave中选出主节点,
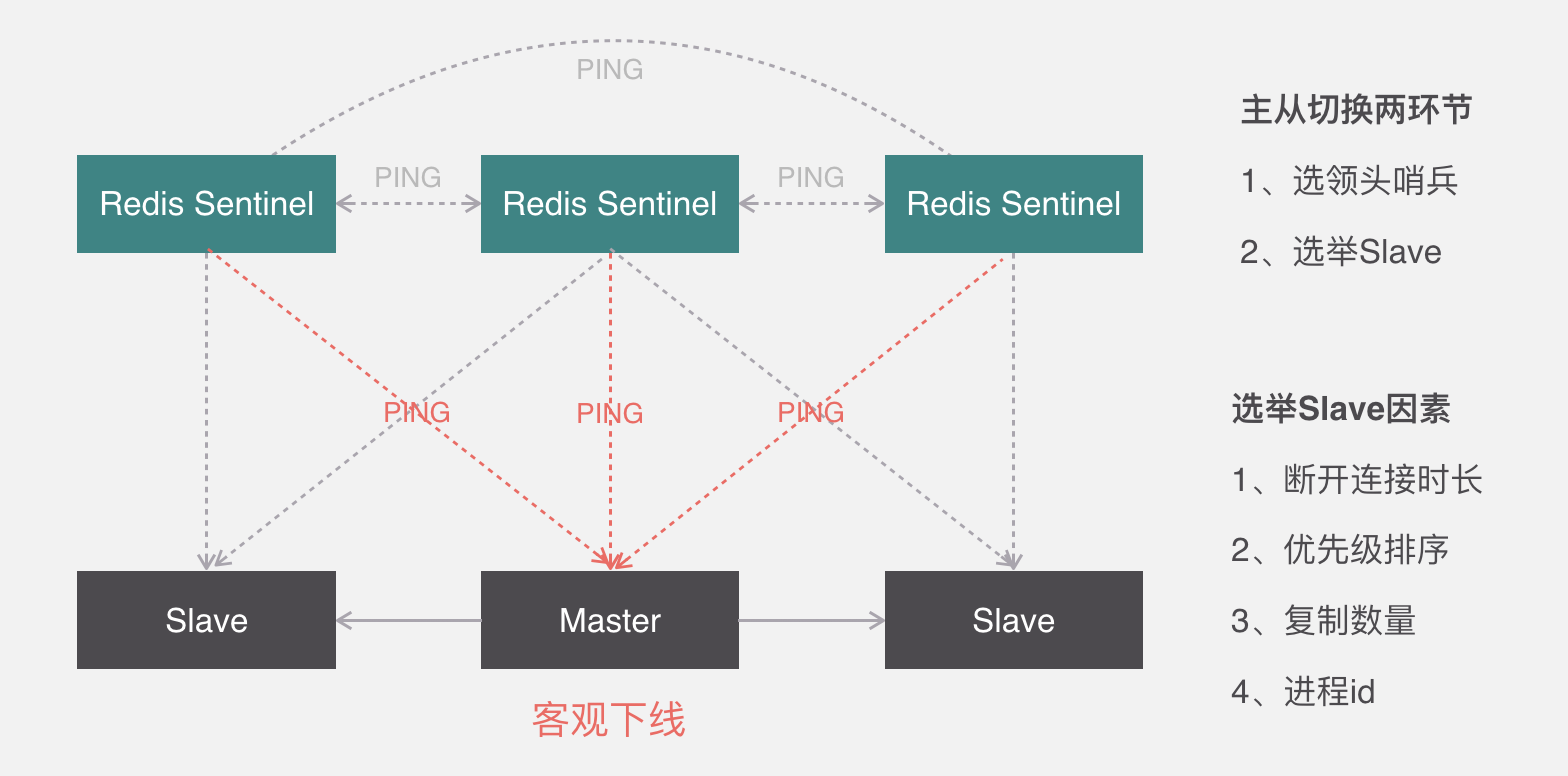
(2)选举Sentinel Leader
当一个Master服务器客观下线后,监控这个Master服务器的所有Sentinel将会选举出一个Sentinel Leader。并由Sentinel Leader对客观下线的Master进行故障转移。
每一个Sentinel节点都可以成为Leader,当一个Sentinel节点确认redis集群的主节点主观下线后,会请求其他Sentinel节点要求将自己选举为Leader。被请求的Sentinel节点如果没有同意过其他Sentinel节点的选举请求,则同意该请求(选举票数+1),否则不同意。
如果一个Sentinel节点获得的选举票数达到Leader最低票数(quorum/Sentinel节点数/2+1的最大值),则该Sentinel节点选举为Leader;否则重新进行选举。
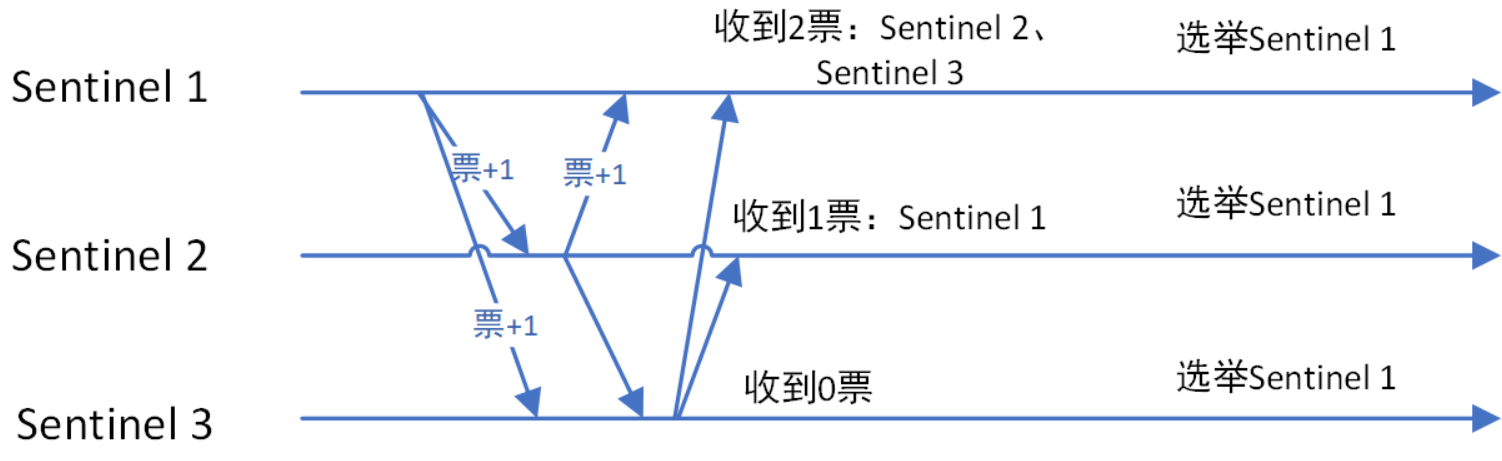
为什么Sentinel集群至少3节点
一个Sentinel节选举成为Leader的最低票数为quorum和Sentinel节点数/2+1的最大值,如果Sentinel集群只有2个Sentinel节点,则
Sentinel节点数/2 + 1
= 2/2 + 1
= 2
即Leader最低票数至少为2,当该Sentinel集群中由一个Sentinel节点故障后,仅剩的一个Sentinel节点是永远无法成为Leader。
也可以由此公式可以推导出,Sentinel集群允许1个Sentinel节点故障则需要3个节点的集群;允许2个节点故障则需要5个节点集
如果超过半数,则当前Sentinel就会被选为领头Sentinel并进行故障转移。
(3)故障转移
故障转移包括以下三步:
- 在已下线的Master主机下面挑选一个Slave将其转换为主服务器。
- 让其余所有Slave服务器复制新的Master服务器。
- 让已下线的Master服务器变成新的Master服务器的Slave。当已下线的服务器在此上线后将复新的Master的数据。
(4)选举新的主服务器
领头Sentinel会在所有Slave中选出新的Master,发送SLAVEOF no one命令,将这个服务器确定为主服务器。
领头Sentinel会将已下线Master的所有从服务器报错在一个列表中,按照规则进行挑选。
- 删除列表中所有处于下线或者短线状态的Slave。
- 删除列表中所有最近5s内没有回复过领头Sentinel的INFO命令的Slave。
- 删除所有与下线Master连接断开超过down-after-milliseconds * 10毫秒的Slave。
- 领头Sentinel将根据Slave优先级,对列表中剩余的Slave进行排序,并选出其中优先级最高的Slave。如果有多个具有相同优先级的Slave,那么领头Sentinel将按照Slave复制偏移量,选出其中偏移量最大的Slave。如果有多个优先级最高,偏移量最大的Slave,那么根据运行ID最小原则选出新的Master。
确定新的Master之后,领头Sentinel会以每秒一次的频率向新的Master发送SLAVEOF no one命令,当得到确切的回复role由slave变为master之后,当前服务器顺利升级为Master服务器。
(5)将旧的Master变成Slave
当已下线的Master重新上线后,领头Sentinel会向此服务器发送SLAVEOF命令,将当前服务器变成新的Master的Slave。
(6)原Master重新上线
当原Master节点重新上线后,自动转为当前Master节点的从节点。
故障切换的例子
1.Sentinel集群包括三个sentinel节点sentinel1、sentinel2、seninel3,sentinel集群各节点之间互相监控哨兵运行状态。
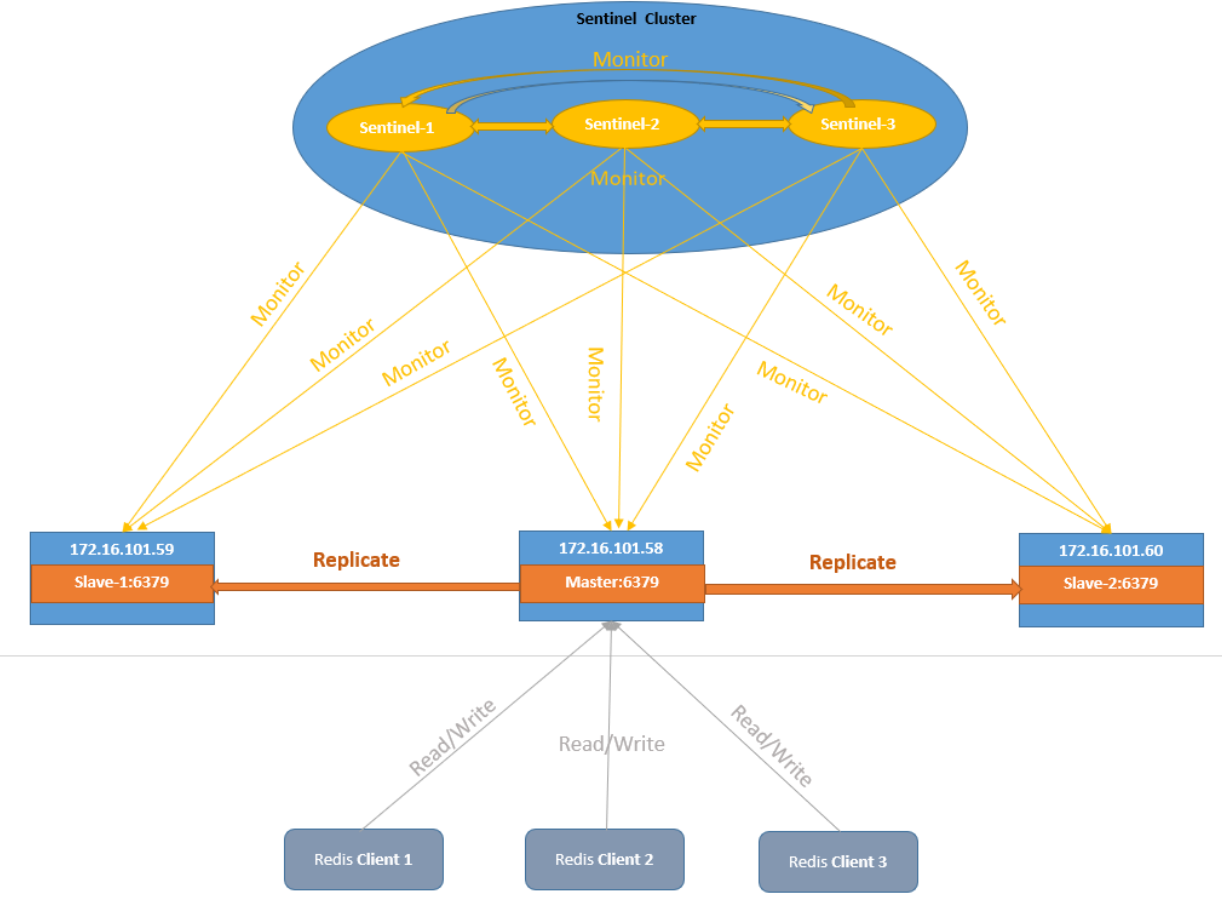
2.Sentinel集群各节点分别与Redis主节点进行ping命令,以检查Redis主节点的运行状态。
3.假设Sentinel集群检测到Redis主节点Master宕机,在指定时间内未恢复,Sentinel集群通过投票(半数原则),最终确定Sentinel leader。投票通过之后,Sentinel leader就会对Redis集群做故障转移操作。
3.1 首先,是Sentinel集群从各slave节点中挑选一台优先级最高的slave节点提升为Master节点。
3.2,其次,新的Master节点向原Master的所有从节点发送slaveof命令,让它们作为新Master的slave节点,并将新的Master节点数据复制数据各个slave节点上,故障转移完成。
3.3 最后,Sentinel集群会继续监视老的Master节点,老的Master恢复上线后,Sentinel会将它设置为新Master的slave节点。
3.4 故障转移后的拓扑图如下所示,在图中,slave节点slave-1被选举成为新的Master的节点。
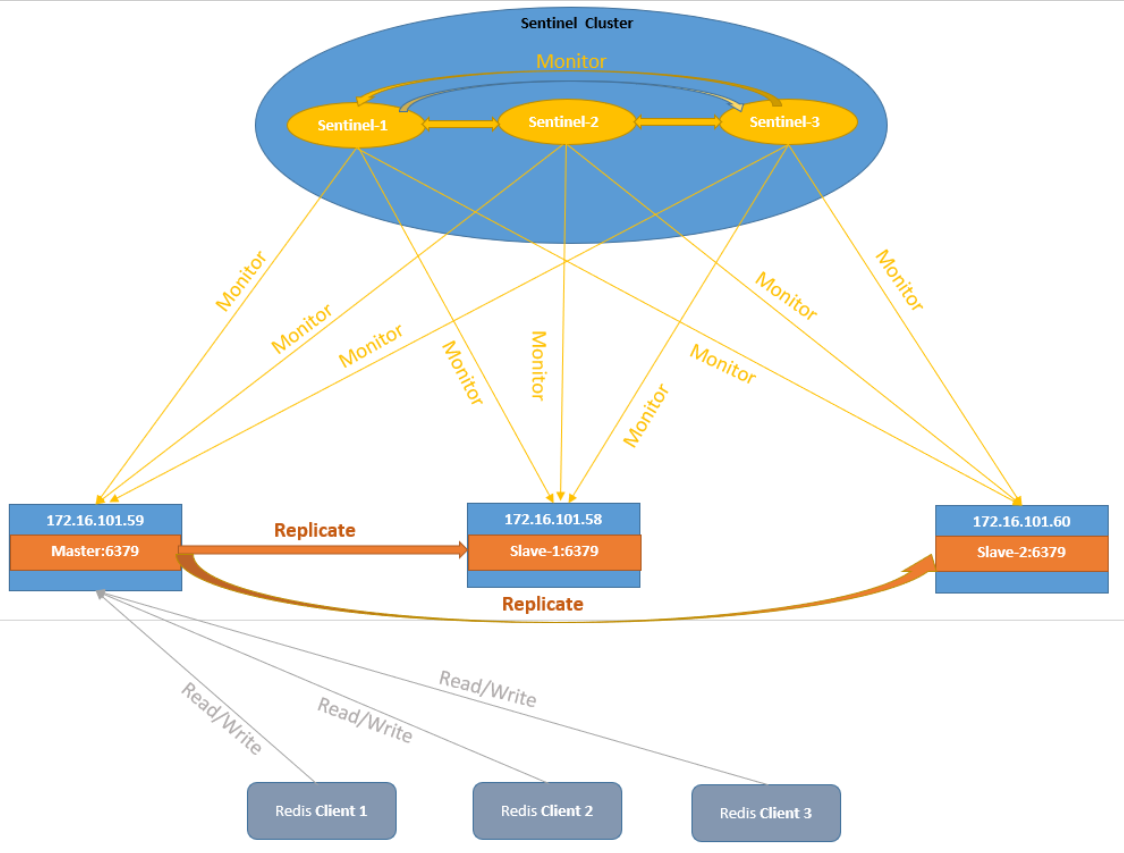
哨兵模式部署
需求
前提:已经存在一个正在运行的主从模式。另外,配置三个Sentinel实例,监控同一个Master节点。
配置Sentinel
(1)在/usr/local目录下,创建/redis/sentinels/目录
cd /usr/local/redis
mkdir sentinels
(2)在sentinels目录下,依次创建s1、s2、s3三个子目录中
cd sentinels
mkdir s1 s2 s3
(3)依次拷贝redis解压目录下的sentinel.conf文件,到这三个子目录中
cp /usr/local/src/redis-5.0.4/sentinel.conf s1/
cp /usr/local/src/redis-5.0.4/sentinel.conf s2/
cp /usr/local/src/redis-5.0.4/sentinel.conf s3/
(4)依次修改s1、s2、s3子目录中的sentinel.conf文件,修改端口,并指定要监控的主节点。(从节点不需要指定,sentinel会自动识别)
# s1 哨兵配置
port 26379
sentinel monitor mymaster 127.0.0.1 6380 2
# mymaster为主节点别名,127.0.0.1为主节点IP,6380为主节点端口,2为触发故障切换的最少哨兵数量
# s2 哨兵配置
port 26380
sentinel monitor mymaster 127.0.0.1 6380 2
# s3 哨兵配置
port 26381
sentinel monitor mymaster 127.0.0.1 6380 2
(5)再打开三个shell窗口,在每一个窗口中,启动一个哨兵实例,并观察日志输出
[root@node0719 sentinels]# redis-sentinel ./s1/sentinel.conf
[root@node0719 sentinels]# redis-sentinel ./s2/sentinel.conf
[root@node0719 sentinels]# redis-sentinel ./s3/sentinel.conf
哨兵模式测试
(1)先关闭6380节点。发现,确实重新指定了一个主节点
(2)再次上线6380节点。发现,6380节点成为了新的主节点的从节点。
哨兵模式建议:
1 如果监控同一业务,可以选择一套 Sentinel 集群监控多组 Redis 集群方案
2 sentinel monitor配置中的建议设置成 Sentinel 节点的一半加 1,当 Sentinel 部署在多个 IDC 的时候,单个 IDC 部署的 Sentinel 数量不建议超过(Sentinel 数量 – quorum)。
3 部署的各个节点服务器时间尽量要同步,否则日志的时序性会混乱。
4 Redis 建议使用 pipeline 和 multi-keys 操作,减少 RTT 次数,提高请求效率。
哨兵模式优点
Sentinel哨兵模式,确实能实现自动故障切换。提供稳定的服务
哨兵模式缺点:
是一种中心化的集群实现方案:
始终只有一个Redis主机来接收和处理写请求,写操作受单机瓶颈影响。
集群里所有节点保存的都是全量数据,浪费内存空间
没有真正实现分布式存储。数据量过大时,主从同步严重影响master的性能。
故障转移期间不能写
Redis主机宕机后,哨兵模式正在投票选举的情况之外,因为投票选举结束之前,谁也不知道主机和从机是谁,此时Redis也会开启保护机制,禁止写操作,直到选举出了新的Redis主机。
客户端分片的集群模式
客户端分片主要是说,我们只需要部署多个Redis节点,具体如何使用这些节点,主要工作在客户端。
客户端分片是把分片的逻辑放在Redis客户端实现,客户端通过固定的Hash算法,针对不同的key计算对应的Hash值,然后对不同的Redis节点进行读写。
比如:jedis已支持Redis Sharding功能,即ShardedJedis,通过Redis客户端预先定义好的路由规则(使用一致性哈希),把对Key的访问转发到不同的Redis实例中,查询数据时把返回结果汇集。这种方案的模式如图所示。
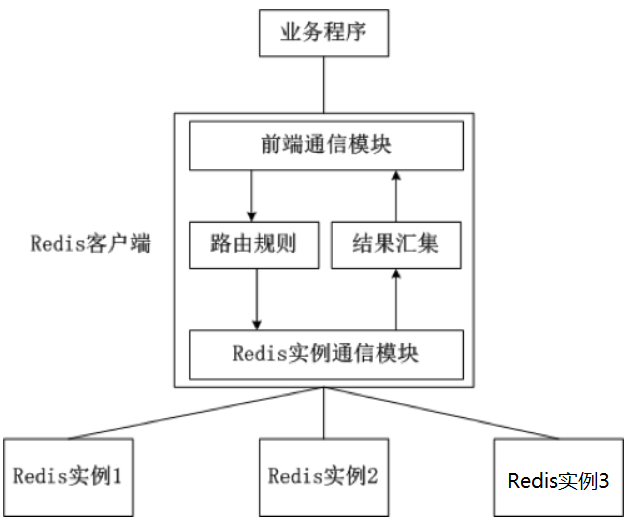
客户端分片集群模式 需要业务开发人员事先评估业务的请求量和数据量,然后让DBA部署足够的节点交给开发人员使用即可。
特点
这实际上是一种静态分片技术。Redis 实例的增减,都得手工调整分片程序。
基于此分片机制的开源产品,现在仍不多见。
优点
1 部署非常方便,业务需要多少个节点DBA直接部署交付即可,剩下的事情就需要业务开发人员根据节点数量来编写key的请求路由逻辑,制定一个规则,一般采用固定的Hash算法,把不同的key写入到不同的节点上,然后再根据这个规则进行数据读取。
2 性能较好。这种分片机制的性能比代理式更好(少了一个中间分发环节)。
3 解决了主从模式的分布式存储问题,数据不在集中在一个节点上。 通过分片的方式,存储在多个节点上。
缺点
1 业务开发人员使用Redis的成本较高,需要编写路由规则的代码来使用多个节点,而且如果事先对业务的数据量评估不准确,后期的扩容和迁移成本非常高,因为节点数量发生变更后,Hash算法对应的节点也就不再是之前的节点了。客户端代码升级麻烦,对研发人员的个人依赖性强——需要有较强的程序开发能力做后盾。如果主力程序员离职,可能新的负责人,会选择重写一遍。
所以后来又衍生出了一致性哈希算法,就是为了解决当节点数量变更时,尽量减少数据的迁移和性能问题。
2 对数据业务数据量比较稳定.。这种客户端分片的方案一般用于业务数据量比较稳定,后期不会有大幅度增长的业务场景下使用,只需要前期评估好业务数据量即可。
3 可运维性较差。出现故障,定位和解决都得研发和运维配合着解决,故障时间变长。这种方案,难以进行标准化运维,不太适合中小公司(除非有足够的 DevOPS)。
服务端分片模式(redis集群模式)
Redis 的哨兵模式虽然已经可以实现高可用,读写分离 ,但是存在几个方面的不足:
- 哨兵模式下每台 Redis 服务器都存储相同的数据,很浪费内存空间;数据量太大,主从同步时严重影响了master性能。
- 哨兵模式是中心化的集群实现方案,每个从机和主机的耦合度很高,master宕机到salve选举master恢复期间服务不可用。
- 哨兵模式始终只有一个Redis主机来接收和处理写请求,写操作还是受单机瓶颈影响,没有实现真正的分布式架构。
Redis Cluster(Redis集群)简介
RedisCluster 是 Redis 的亲儿子,它是 Redis 作者自己提供的 Redis 集群化方案。 相对于 Codis 的不同,它是去中心化的,如图所示,该集群有三个 Redis 节点组成, 每个节点负责整个集群的一部分数据,每个节点负责的数据多少可能不一样。这三个节点相 互连接组成一个对等的集群,它们之间通过一种特殊的二进制协议相互交互集群信息。
redis在3.0上加入了 Cluster 集群模式,实现了 Redis 的分布式存储,也就是说每台 Redis 节点上存储不同的数据。cluster模式为了解决单机Redis容量有限的问题,将数据按一定的规则分配到多台机器,内存/QPS不受限于单机,可受益于分布式集群高扩展性。
Redis Cluster 将所有数据划分为 16384 的 slots,它比 Codis 的 1024 个槽划分得更为精细,每个节点负责其中一部分槽位。槽位的信息存储于每个节点中,它不像 Codis,它不 需要另外的分布式存储来存储节点槽位信息。
Redis Cluster是一种服务器Sharding技术(分片和路由都是在服务端实现),采用多主多从,每一个分区都是由一个Redis主机和多个从机组成,片区和片区之间是相互平行的。
Redis Cluster集群采用了P2P的模式,完全去中心化。

如上图,官方推荐,集群部署至少要 3 台以上的master节点,最好使用 3 主 3 从六个节点的模式。
集群搭建需要的环境
Redis集群数据的分片
Redis集群不是使用一致性哈希,而是使用哈希槽。整个redis集群有16384个哈希槽,决定一个key应该分配到那个槽的算法是:计算该key的CRC16结果再模16834。
集群中的每个节点负责一部分哈希槽,比如集群中有3个节点,则:
- 节点A存储的哈希槽范围是:0 – 5500
- 节点B存储的哈希槽范围是:5501 – 11000
- 节点C存储的哈希槽范围是:11001 – 16384
这样的分布方式方便节点的添加和删除。比如,需要新增一个节点D,只需要把A、B、C中的部分哈希槽数据移到D节点。同样,如果希望在集群中删除A节点,只需要把A节点的哈希槽的数据移到B和C节点,当A节点的数据全部被移走后,A节点就可以完全从集群中删除。
因为把哈希槽从一个节点移到另一个节点是不需要停机的,所以,增加或删除节点,或更改节点上的哈希槽,也是不需要停机的。
如果多个key都属于一个哈希槽,集群支持通过一个命令(或事务, 或lua脚本)同时操作这些key。通过“哈希标签”的概念,用户可以让多个key分配到同一个哈希槽。哈希标签在集群详细文档中有描述,这里做个简单介绍:如果key含有大括号”{}”,则只有大括号中的字符串会参与哈希,比如”this{foo}”和”another{foo}”这2个key会分配到同一个哈希槽,所以可以在一个命令中同时操作他们。
槽位为什么是16384(2^14)个?
分片SLOT的计算公式
SLOT=CRC16.crc16(key.getBytes()) % MAX_SLOT

但是可能这个槽并不归随机找的这个节点管,节点如果发现不归自己管,就会返回一个MOVED ERROR通知,引导客户端去正确的节点访问,这个时候客户端就会去正确的节点操作数据。
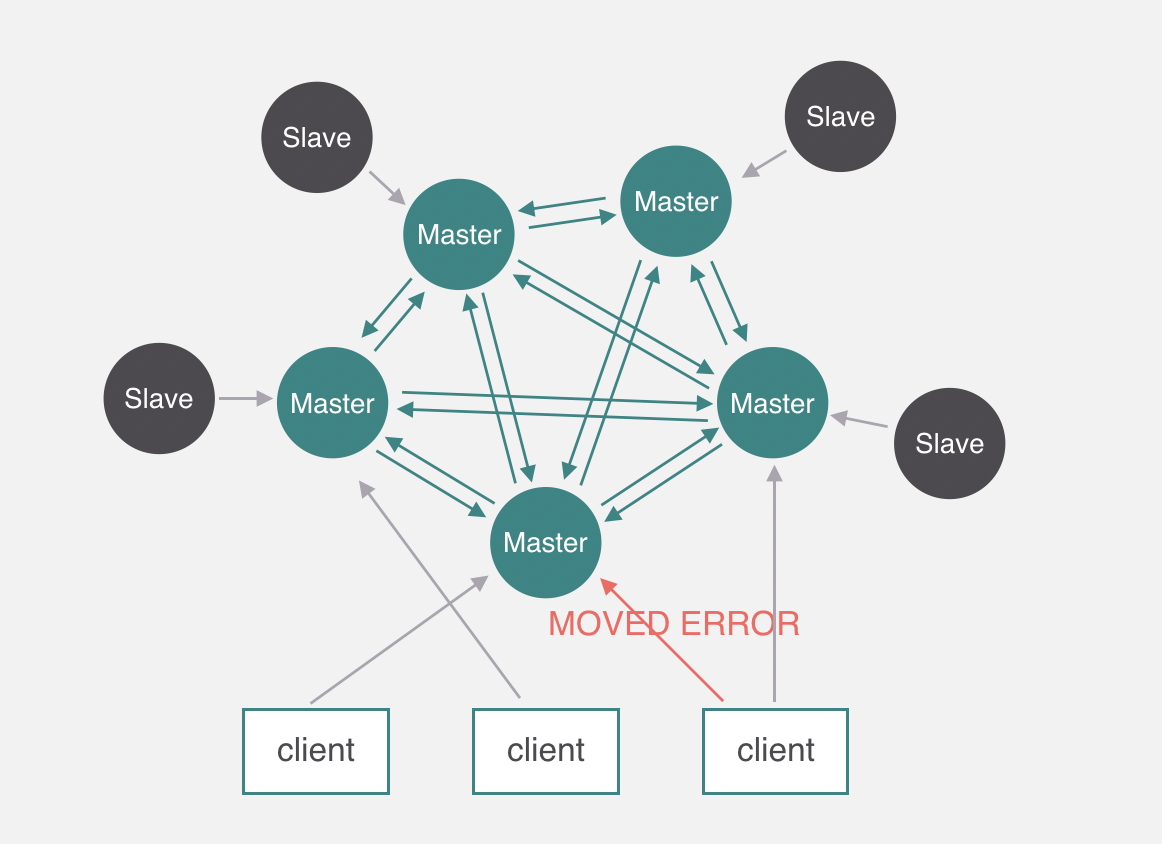
对于客户端请求的key,根据公式HASH_SLOT=CRC16(key) mod 16384,计算出映射到哪个分片上,然后Redis会去相应的节点进行操作!
CRC16算法产生的hash值有16bit,该算法可以产生2^16-=65536个值。换句话说,值是分布在0~65535之间。那作者在做mod运算的时候,为什么不mod 65536,而选择 mod 16384?
在redis节点发送心跳包时需要把所有的槽放到这个心跳包里,以便让节点知道当前集群信息,
交换的数据信息,由消息体和消息头组成。消息体无外乎是一些节点标识啊,IP啊,端口号啊,发送时间啊。这与本文关系不是太大,我不细说。我们来看消息头,结构如下
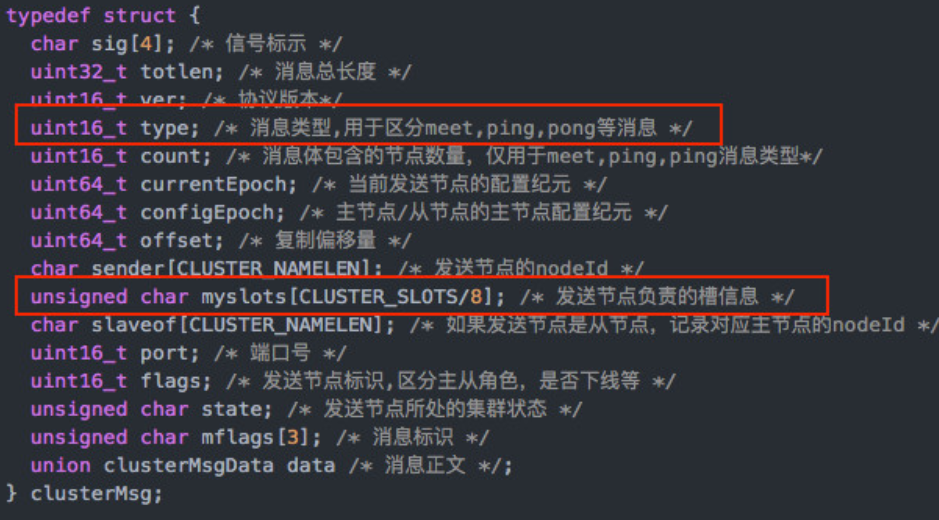
消息头里面有个myslots的char数组,长度为16383/8,这其实是一个bitmap,每一个位代表一个槽,如果该位为1,表示这个槽是属于这个节点的。在消息头中,最占空间的是myslots[CLUSTER_SLOTS/8]。
这块的大小是:
16384÷8÷1024=2kb
16384=16k,在发送心跳包时使用char进行bitmap压缩后是2k(2 * 8 (8 bit) * 1024(1k) = 16K)个char,也就是说使用2k个char的空间创建了16k的槽数。
虽然使用CRC16算法最多可以分配65535(2^16-1)个槽位,65535=65k,压缩后就是8k(8 * 8 (8 bit) * 1024(1k) =65K),也就是说需要需要8k的心跳包,作者认为这样做不太值得;
集群节点越多,心跳包的消息体内携带的数据越多。如果节点过1000个,也会导致网络拥堵。因此redis作者,不建议redis cluster节点数量超过1000个。
那么,对于节点数在1000以内的redis cluster集群,16384个槽位够用了。没有必要拓展到65536个。并且一般情况下一个redis集群不会有超过1000个master节点,所以16k的槽位是个比较合适的选择。
Redis集群的一致性保证
Redis集群不能保证强一致性。一些已经向客户端确认写成功的操作,会在某些不确定的情况下丢失。
产生写操作丢失的第一个原因,是因为主从节点之间使用了异步的方式来同步数据。
一个写操作是这样一个流程:
-
1)客户端向主节点B发起写的操作
-
2)主节点B回应客户端写操作成功
-
3)主节点B向它的从节点B1,B2,B3同步该写操作
从上面的流程可以看出来,主节点B并没有等从节点B1,B2,B3写完之后再回复客户端这次操作的结果。所以,如果主节点B在通知客户端写操作成功之后,但同步给从节点之前,主节点B故障了,其中一个没有收到该写操作的从节点会晋升成主节点,该写操作就这样永远丢失了。
就像传统的数据库,在不涉及到分布式的情况下,它每秒写回磁盘。为了提高一致性,可以在写盘完成之后再回复客户端,但这样就要损失性能。这种方式就等于Redis集群使用同步复制的方式。
基本上,在性能和一致性之间,需要一个权衡。
如果真的需要,Redis集群支持同步复制的方式,通过WAIT指令来实现,这可以让丢失写操作的可能性降到很低。但就算使用了同步复制的方式,Redis集群依然不是强一致性的,在某些复杂的情况下,比如从节点在与主节点失去连接之后被选为主节点,不一致性还是会发生。
这种不一致性发生的情况是这样的,当客户端与少数的节点(至少含有一个主节点)网络联通,但他们与其他大多数节点网络不通。比如6个节点,A,B,C是主节点,A1,B1,C1分别是他们的从节点,一个客户端称之为Z1。
当网络出问题时,他们被分成2组网络,组内网络联通,但2组之间的网络不通,假设A,C,A1,B1,C1彼此之间是联通的,另一边,B和Z1的网络是联通的。Z1可以继续往B发起写操作,B也接受Z1的写操作。当网络恢复时,如果这个时间间隔足够短,集群仍然能继续正常工作。如果时间比较长,以致B1在大多数的这边被选为主节点,那刚才Z1发给B的写操作都将丢失。
注意,Z1给B发送写操作是有一个限制的,如果时间长度达到了大多数节点那边可以选出一个新的主节点时,少数这边的所有主节点都不接受写操作。
这个时间的配置,称之为节点超时(node timeout),对集群来说非常重要,当达到了这个节点超时的时间之后,主节点被认为已经宕机,可以用它
服务端分片Redis 集群的缺点
另外,官方 Redis 集群方案将 Sentinel 功能内置到 Redis 内,这导致在节点数较多(大于 100)时在 Gossip 阶段会产生大量的 PING/INFO/CLUSTER INFO 流量,根据 issue 中提到的情况,200 个使用 3.2.8 版本节点搭建的 Redis 集群,在没有任何客户端请求的情况下,每个节点仍然会产生 40Mb/s 的流量,虽然到后期 Redis 官方尝试对其进行压缩修复,但按照 Redis 集群机制,节点较多的情况下无论如何都会产生这部分流量,对于使用大内存机器但是使用千兆网卡的用户这是一个值得注意的地方。
最后,每个 Key 对应的 Slot 的存储开销,在规模较大的时候会占用较多内存,4.x 版本以前甚至会达到实际使用内存的数倍,虽然 4.x 版本使用 rax 结构进行存储,但是仍然占据了大量内存,从非官方集群方案迁移到官方集群方案时,需要注意这部分多出来的内存。
还有,官方集群方案的高可用策略仅有主从一种,高可用级别跟 Slave 的数量成正相关,如果只有一个 Slave,则只能允许一台物理机器宕机, Redis 4.2 roadmap 提到了 cache-only mode,提供类似于 Twemproxy 的自动剔除后重分片策略,但是截至目前仍未实现。
Redis Cluster集群具有如下几个特点:
- 集群完全去中心化,采用多主多从;所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
- 客户端与 Redis 节点直连,不需要中间代理层。客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
- 每一个分区都是由一个Redis主机和多个从机组成,分片和分片之间是相互平行的。
- 每一个master节点负责维护一部分槽,以及槽所映射的键值数据;集群中每个节点都有全量的槽信息,通过槽每个node都知道具体数据存储到哪个node上。
redis cluster主要是针对海量数据+高并发+高可用的场景,海量数据,如果你的数据量很大,那么建议就用redis cluster,数据量不是很大时,使用sentinel就够了。redis cluster的性能和高可用性均优于哨兵模式。
Redis Cluster采用虚拟哈希槽分区而非一致性hash算法,预先分配一些卡槽,所有的键根据哈希函数映射到这些槽内,每一个分区内的master节点负责维护一部分槽以及槽所映射的键值数据。关于Redis Cluster的详细实现原理请参考:Redis Cluster数据分片实现原理。
优点:
- 无中心架构;
- 数据按照 slot 存储分布在多个节点,节点间数据共享,可动态调整数据分布;
- 可扩展性:可线性扩展到 1000 多个节点,节点可动态添加或删除;
- 高可用性:部分节点不可用时,集群仍可用。通过增加 Slave 做 standby 数据副本,能够实现故障自动 failover,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave 到 Master 的角色提升;
- 降低运维成本,提高系统的扩展性和可用性。
缺点:
- Client 实现复杂,驱动要求实现 Smart Client,缓存 slots mapping 信息并及时更新,提高了开发难度,客户端的不成熟影响业务的稳定性。目前仅 JedisCluster 相对成熟,异常处理部分还不完善,比如常见的“max redirect exception”。
- 节点会因为某些原因发生阻塞(阻塞时间大于 clutser-node-timeout),被判断下线,这种 failover 是没有必要的。
- 数据通过异步复制,不保证数据的强一致性。
- 多个业务使用同一套集群时,无法根据统计区分冷热数据,资源隔离性较差,容易出现相互影响的情况。
- Slave 在集群中充当“冷备”,不能缓解读压力,当然可以通过 SDK 的合理设计来提高 Slave 资源的利用率。
- Key 批量操作限制,如使用 mset、mget 目前只支持具有相同 slot 值的 Key 执行批量操作。对于映射为不同 slot 值的 Key 由于 Keys 不支持跨 slot 查询,所以执行 mset、mget、sunion 等操作支持不友好。
- Key 事务操作支持有限,只支持多 key 在同一节点上的事务操作,当多个 Key 分布于不同的节点上时无法使用事务功能。
- Key 作为数据分区的最小粒度,不能将一个很大的键值对象如 hash、list 等映射到不同的节点。
- 不支持多数据库空间,单机下的 redis 可以支持到 16 个数据库,集群模式下只能使用 1 个数据库空间,即 db 0。
- 复制结构只支持一层,从节点只能复制主节点,不支持嵌套树状复制结构。
- 避免产生 hot-key,导致主库节点成为系统的短板。
- 避免产生 big-key,导致网卡撑爆、慢查询等。
- 重试时间应该大于 cluster-node-time 时间。
- Redis Cluster 不建议使用 pipeline 和 multi-keys 操作,减少 max redirect 产生的场景。
代理分片 集群模式
这种方案,将分片工作交给专门的代理程序来做。代理程序接收到来自业务程序的数据请求,根据路由规则,将这些请求分发给正确的 Redis 实例并返回给业务程序。
其基本原理是:通过中间件的形式,Redis客户端把请求发送到代理 proxy,代理 proxy 根据路由规则发送到正确的Redis实例,最后 代理 proxy 把结果汇集返回给客户端。
redis代理分片用得最多的就是Twemproxy,由Twitter开源的Redis代理,其基本原理是:通过中间件的形式,Redis客户端把请求发送到Twemproxy,Twemproxy根据路由规则发送到正确的Redis实例,最后Twemproxy把结果汇集返回给客户端。
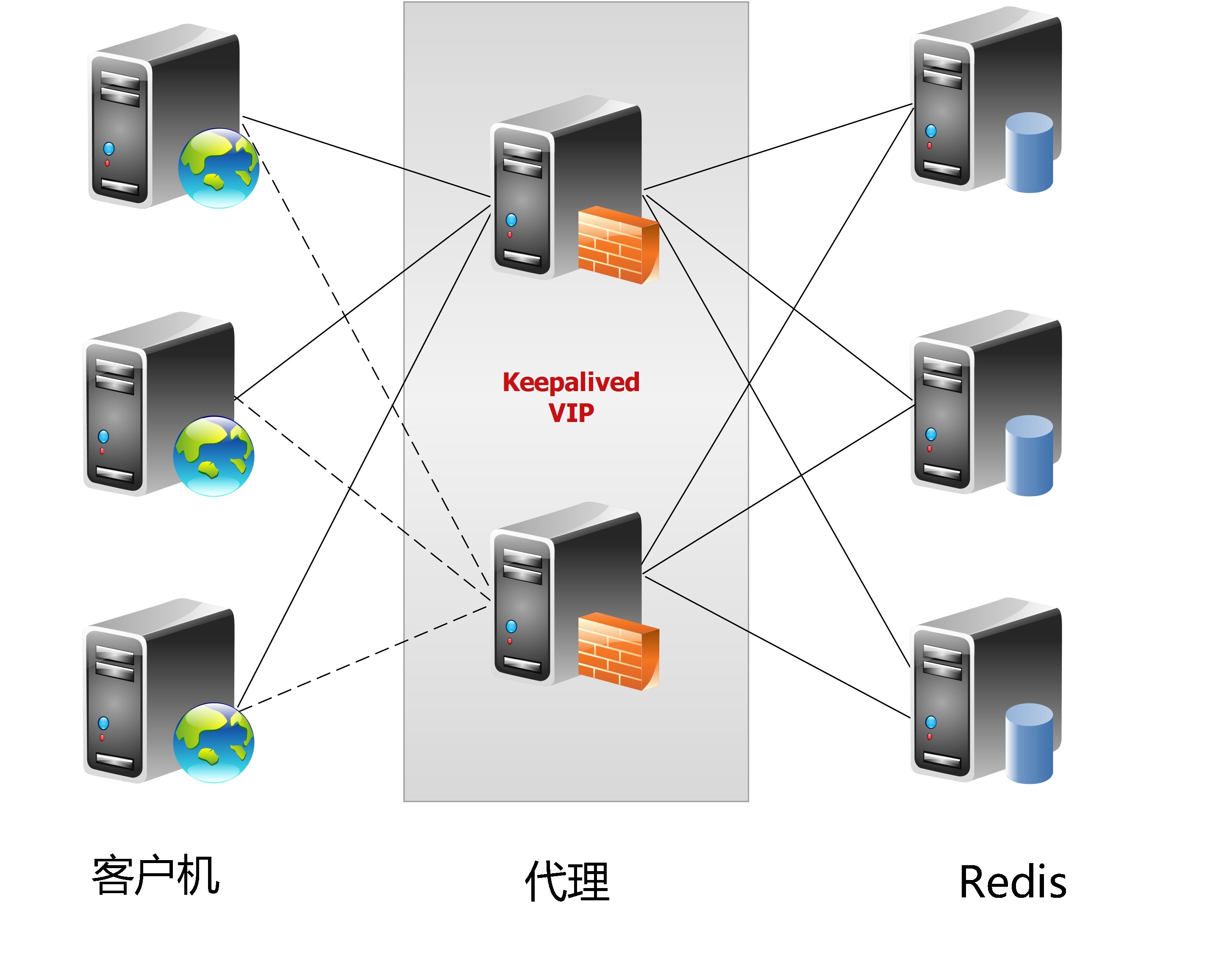
这种机制下,一般会选用第三方代理程序(而不是自己研发),因为后端有多个 Redis 实例,所以这类程序又称为分布式中间件。
这样的好处是,业务程序不用关心后端 Redis 实例,运维起来也方便。虽然会因此带来些性能损耗,但对于 Redis 这种内存读写型应用,相对而言是能容忍的。
Twemproxy 代理分片
Twemproxy 是一个 Twitter 开源的一个 redis 和 memcache 快速/轻量级代理服务器; Twemproxy 是一个快速的单线程代理程序,支持 Memcached ASCII 协议和 redis 协议。
Twemproxy是由Twitter开源的集群化方案,它既可以做Redis Proxy,还可以做Memcached Proxy。
它的功能比较单一,只实现了请求路由转发,没有像Codis那么全面有在线扩容的功能,它解决的重点就是把客户端分片的逻辑统一放到了Proxy层而已,其他功能没有做任何处理。
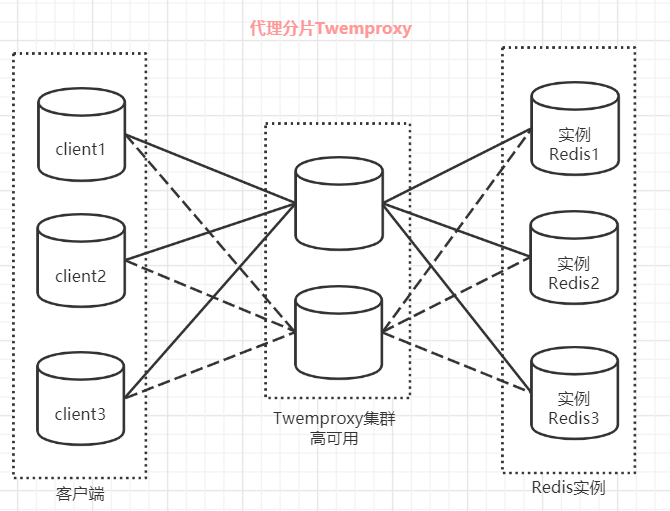
Tweproxy推出的时间最久,在早期没有好的服务端分片集群方案时,应用范围很广,而且性能也极其稳定。
但它的痛点就是无法在线扩容、缩容,这就导致运维非常不方便,而且也没有友好的运维UI可以使用。
Twemproxy的优点:
- 客户端像连接Redis实例一样连接Twemproxy,不需要改任何的代码逻辑。
- 支持无效Redis实例的自动删除。
- Twemproxy与Redis实例保持连接,减少了客户端与Redis实例的连接数。
- 后端 Sharding 分片逻辑对业务透明,业务方的读写方式和操作单个 Redis 一致
- 多种 hash 算法:MD5、CRC16、CRC32、CRC32a、hsieh、murmur
Twemproxy的不足:
由于Redis客户端的每个请求都经过Twemproxy代理才能到达Redis服务器,这个过程中会产生性能损失。
没有友好的监控管理后台界面,不利于运维监控。
Twemproxy最大的痛点在于,无法平滑地扩容/缩容。对于运维人员来说,当因为业务需要增加Redis实例时工作量非常大。
增加了新的 proxy,需要维护其高可用。
Twemproxy作为最被广泛使用、最久经考验、稳定性最高的Redis代理,在业界被广泛使用。
知乎的redis集群
知乎存储平台团队基于开源Redis 组件打造的知乎 Redis 平台,经过不断的研发迭代,目前已经形成了一整套完整自动化运维服务体系,提供很多强大的功能。
- 1)机器内存总量约 70TB,实际使用内存约 40TB;
- 2)平均每秒处理约 1500 万次请求,峰值每秒约 2000 万次请求;
- 3)每天处理约 1 万亿余次请求;
- 4)单集群每秒处理最高每秒约 400 万次请求;
- 5)集群实例与单机实例总共约 800 个;
- 6)实际运行约 16000 个 Redis 实例;
- 7)Redis 使用官方 3.0.7 版本,少部分实例采用 4.0.11 版本。
知乎的Redis应用类型
根据业务的需求,我们将Redis实例区分为单机(Standalone)和集群(Cluster)两种类型,
-
单机实例通常用于容量与性能要求不高的小型存储,
-
集群则用来应对对性能和容量要求较高的场景。
这里仅仅介绍知乎的Twemproxy 代理Redis集群实践情况。
知乎的Twemproxy 代理Redis集群
由 Twitter 开源的 Twemproxy 具有如下特点:
- 1)单核模型造成性能瓶颈;
- 2)传统扩容模式仅支持停机扩容。
知乎的Twemproxy 代理Redis集群
知乎对Twemproxy 进行了局部的定制。其总体方案如下:
在方案早期使用数量固定的物理机部署 Twemproxy,通过物理机上的 Agent 启动实例(对 Twemproxy 进行健康检查与故障恢复),由于 Twemproxy 仅提供全量的使用计数,所以 Agent 运行时还会进行定时的差值计算来计算 Twemproxy 的 requests_per_second 等指标。
后来为了更好地故障检测和资源调度,知乎的Twemproxy 引入了 Kubernetes,将 Twemproxy 和 Agent 放入同一个 Pod 的两个容器内,底层 Docker 网段的配置使每个 Pod 都能获得独立的 IP,方便管理。
早期使用dns进行负载均衡
我们使用 DNS A Record 来进行客户端的资源发现,每个 Twemproxy 采用相同的端口号,一个 DNS A Record 后面挂接多个 IP 地址对应多个 Twemproxy 实例。 初期,这种方案简单易用,但是到了后期流量日益上涨,单集群 Twemproxy 实例个数很快就超过了 20 个。
由于 DNS 采用的 UDP 协议有 512 字节的包大小限制,单个 A Record 只能挂接 20 个左右的 IP 地址,超过这个数字就会转换为 TCP 协议,客户端不做处理就会报错,导致客户端启动失败。
知乎的端口复用的Twemproxy 部署
之后知乎修改了 Twemproxy 源码, 加入 SO_REUSEPORT 支持。
通过端口复用,实现同一个容器内由 Starter 启动多个 Twemproxy 实例并绑定到同一个端口,由操作系统进行负载均衡,对外仍然暴露一个端口,但是内部已经由操作系统将访问均摊到了多个 Twemproxy 上。
Twemproxy with SO_REUSEPORT on Kubernetes:
同一个容器内由 Starter 启动多个 Twemproxy 实例并绑定到同一个端口,由操作系统进行负载均衡,对外仍然暴露一个端口,但是内部已经由系统均摊到了多个 Twemproxy 上。
同时 Starter 会定时去每个 Twemproxy 的 stats 端口获取 Twemproxy 运行状态进行聚合,此外 Starter 还承载了信号转发的职责。
原有的 Agent 不需要用来启动 Twemproxy 实例,所以 Monitor 调用 Starter 获取聚合后的 stats 信息进行差值计算,最终对外界暴露出实时的运行状态信息。
Linux的SO_REUSEPORT特性
1、前言
昨天总结了一下Linux下网络编程“惊群”现象,给出Nginx处理惊群的方法,使用互斥锁。为例发挥多核的优势,目前常见的网络编程模型就是多进程或多线程,根据accpet的位置,分为如下场景:
(1)单进程或线程创建socket,并进行listen和accept,接收到连接后创建进程和线程处理连接
(2)单进程或线程创建socket,并进行listen,预先创建好多个工作进程或线程accept()在同一个服务器套接字、
在多核时代,一般主流的web服务器都使用 SO_REUSEADDR模式。 以下是比较典型的多进程/多线程服务器模型。
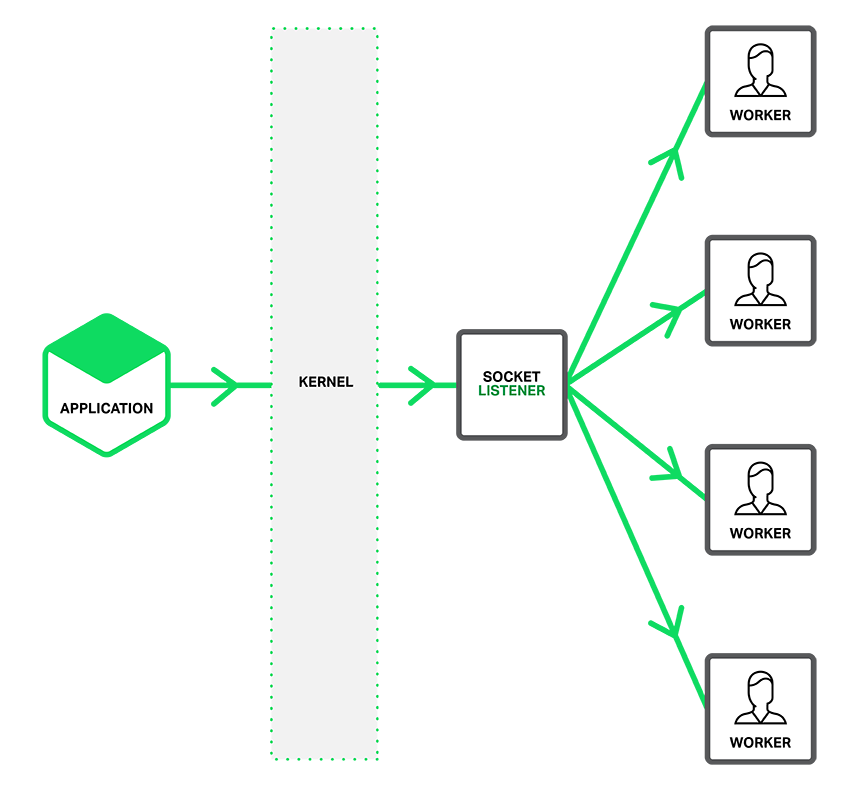
这两种模型解充分发挥了多核CPU的优势,虽然可以做到线程和CPU核绑定,但都会存在:
- 单一listener工作进程胡线程在高速的连接接入处理时会成为瓶颈
- 多个线程之间竞争获取服务套接字
- 缓存行跳跃
- 很难做到CPU之间的负载均衡
- 随着核数的扩展,性能并没有随着提升
Linux kernel 3.9带来了SO_REUSEPORT特性
Linux kernel 3.9带来了SO_REUSEPORT特性,可以解决以上大部分问题。
首先需要单线程listen一个端口上,然后由多个工作进程/线程去accept()在同一个服务器套接字上。
第一个性能瓶颈,单线程listener,在处理高速率海量连接时,一样会成为瓶颈
第二个性能瓶颈,多线程访问server socket锁竞争严重。
那么怎么解决? 这里先别扯什么分布式调度,集群xxx的 , 就拿单机来说问题。在Linux kernel 3.9带来了SO_REUSEPORT特性,她可以解决上面(单进程listen,多工作进程accept() )的问题.
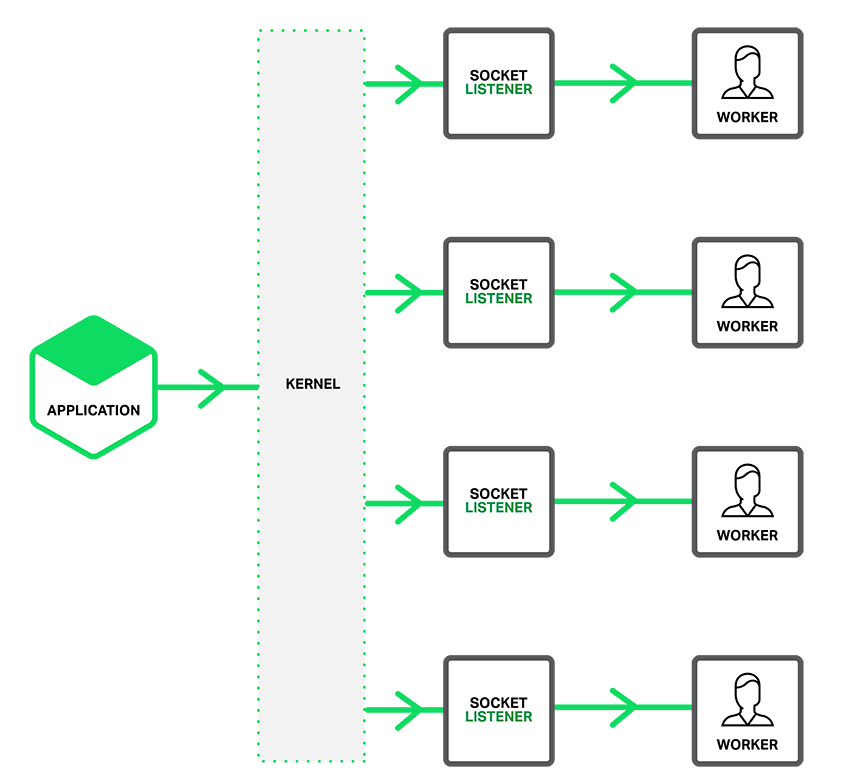
看图说话,对比SO_REUSADDR的模型,我想你应该看懂SO_REUSEPORT是个什么东西了。 SO_REUSEPORT是支持多个进程或者线程绑定到同一端口,提高服务器程序的吞吐性能,具体来说解决了下面的几个问题:
允许多个套接字 bind()/listen() 同一个TCP/UDP端口
每一个线程拥有自己的服务器套接字
在服务器套接字上没有了锁的竞争,因为每个进程一个服务器套接字
内核层面实现负载均衡
安全层面,监听同一个端口的套接字只能位于同一个用户下面
SO_REUSEADDR和SO_REUSEPORT的区别。
SO_REUSEADDR提供如下四个功能:
SO_REUSEADDR允许启动一个监听服务器并捆绑其众所周知端口,即使以前建立的将此端口用做他们的本地端口的连接仍存在。这通常是重启监听服务器时出现,若不设置此选项,则bind时将出错。
SO_REUSEADDR允许在同一端口上启动同一服务器的多个实例,只要每个实例捆绑一个不同的本地IP地址即可。对于TCP,我们根本不可能启动捆绑相同IP地址和相同端口号的多个服务器。
SO_REUSEADDR允许单个进程捆绑同一端口到多个套接口上,只要每个捆绑指定不同的本地IP地址即可。这一般不用于TCP服务器。
SO_REUSEADDR允许完全重复的捆绑:当一个IP地址和端口绑定到某个套接口上时,还允许此IP地址和端口捆绑到另一个套接口上。一般来说,这个特性仅在支持多播的系统上才有,而且只对UDP套接口而言(TCP不支持多播)。
SO_REUSEPORT选项有如下语义:
此选项允许完全重复捆绑,但仅在想捆绑相同IP地址和端口的套接口都指定了此套接口选项才行。
如果被捆绑的IP地址是一个多播地址,则SO_REUSEADDR和SO_REUSEPORT等效。
SO_REUSEPORT解决了什么问题
SO_REUSEPORT支持多个进程或者线程绑定到同一端口,提高服务器程序的性能,解决的问题:
- 允许多个套接字 bind()/listen() 同一个TCP/UDP端口
- 每一个线程拥有自己的服务器套接字
- 在服务器套接字上没有了锁的竞争
- 内核层面实现负载均衡
- 安全层面,监听同一个端口的套接字只能位于同一个用户下面
其核心的实现主要有三点:
- 扩展 socket option,增加 SO_REUSEPORT 选项,用来设置 reuseport。
- 修改 bind 系统调用实现,以便支持可以绑定到相同的 IP 和端口
- 修改处理新建连接的实现,查找 listener 的时候,能够支持在监听相同 IP 和端口的多个 sock 之间均衡选择。
有了SO_RESUEPORT后,每个进程可以自己创建socket、bind、listen、accept相同的地址和端口,各自是独立平等的。让多进程监听同一个端口,各个进程中accept socket fd不一样,有新连接建立时,内核只会唤醒一个进程来accept,并且保证唤醒的均衡性。
原有的 Agent 不需要用来启动 Twemproxy 实例,所以 Monitor 调用 Starter 获取聚合后的 stats 信息进行差值计算,最终对外界暴露出实时的运行状态信息。
1)MIGRATE 造成的阻塞问题:
MIGRATE
调研后发现,MIGRATE 命令实现分为三个阶段:
对于小 Key,该时间可以忽略不计,但如果一旦 Key 的内存使用过大,一个 MIGRATE 命令轻则导致P95 尖刺,重则直接触发集群内的 Failover,造成不必要的切换
同样,方案初期时的 Codis 采用的是相同的 MIGRATE 方案,但是使用 Proxy 控制 Redis 进行迁移操作而非第三方脚本(如 redis-trib.rb),基于同步的类似 MIGRATE 的命令,实际跟 Redis 官方集群方案存在同样的问题。
对此,Redis 作者在 Redis 4.2 的 中提到了 Non blocking MIGRATE 但是截至目前,Redis 5.0 即将正式发布,仍未看到有关改动,社区中已经有相关的 ,该功能可能会在 5.2 或者 6.0 之后并入 master 分支,对此我们将持续观望。
什么是P95 尖刺
假设有100个请求,按照响应时间从小到大排列,位置为X的值,即为PX值。
P1就是响应时间最小的请求,P10就是排名第十的请求,P100就是响应时间最长的请求。
在真正使用过程中,最常用的主要有P50(中位数)、P95、P99。
P50: 即中位数值。100个请求按照响应时间从小到大排列,位置为50的值,即为P50值。如果响应时间的P50值为200ms,代表我们有半数的用户响应耗时在200ms之内,有半数的用户响应耗时大于200ms。如果你觉得中位数值不够精确,那么可以使用P95和P99.9
P95:响应耗时从小到大排列,顺序处于95%位置的值即为P95值。
P99.9:许多大型的互联网公司会采用P99.9值,也就是99.9%用户耗时作为指标,意思就是1000个用户里面,999个用户的耗时上限,通过测量与优化该值,就可保证绝大多数用户的使用体验。 至于P99.99值,优化成本过高,而且服务响应由于网络波动、系统抖动等不能解决之情况,因此大多数时候都不考虑该指标。
P95、P99.9百分位数值——服务响应时间的重要衡量指标
平均值之所以会成为大多数人使用衡量指标,其原因主要在于他的计算非常简单。请求的总耗时/请求总数量就可以得到平均值。而P值的计算则相对麻烦一些。
按照传统的方式,计算P值需要将响应耗时从小到大排序,然后取得对应百分位之值。
下面是一个供参考的:响应延迟折线图
需要客户端自己完成读写分离
由于 Twemproxy 仅进行高性能的命令转发,不进行读写分离,所以默认没有读写分离功能,而在实际使用过程中,知乎团队也没有遇到集群读写分离的需求。
如果要进行读写分离,也有解决放哪,可以使用资源发现策略,在 Slave 节点上架设 Twemproxy 集群,由客户端进行读写分离的路由。
知乎Redis实例的扩容实践
静态扩容
对于单机实例,如果通过调度器观察到对应的机器仍然有空闲的内存,仅需直接调整实例的 maxmemory 配置与报警即可。同样,对于集群实例, 通过调度器观察每个节点所在的机器,如果所有节点所在机器均有空闲内存,像扩容单机实例一样直接更新 maxmemory 与报警。
动态扩容
但是当机器空闲内存不够,或单机实例与集群的后端实例过大时,无法直接扩容,需要进行动态扩容:
1)对于单机实例,如果单实例超过 30GB 且没有如 sinterstore 之类的多 Key 操作, 会将其扩容为集群实例;
2)对于集群实例,会进行横向的重分片,称之为 Resharding 过程。
Resharding 过程:
原生 Twemproxy 集群方案并不支持扩容,知乎团队开发了数据迁移工具来进行 Twemproxy 的扩容,迁移工具本质上是一个上下游之间的代理,将数据从上游按照新的分片方式搬运到下游。
原生 Redis 主从同步使用 SYNC/PSYNC 命令建立主从连接,收到 SYNC 命令的 Master 会 fork 出一个进程遍历内存空间生成 RDB 文件并发送给 Slave,期间所有发送至 Master 的写命令在执行的同时都会被缓存到内存的缓冲区内,当 RDB 发送完成后,Master 会将缓冲区内的命令及之后的写命令转发给 Slave 节点。
开发的迁移代理会向上游发送 SYNC 命令模拟上游实例的 Slave,代理收到 RDB 后进行解析,由于 RDB 中每个 Key 的格式与 RESTORE 命令的格式相同,所以我们使用生成 RESTORE 命令按照下游的 Key 重新计算哈希并使用 Pipeline 批量发送给下游。
等待 RDB 转发完成后,我们按照新的后端生成新的 Twemproxy 配置,并按照新的 Twemproxy 配置建立 Canary 实例,从上游的 Redis 后端中取 Key 进行测试,测试 Resharding 过程是否正确,测试过程中的 Key 按照大小,类型,TTL 进行比较。
测试通过后,对于集群实例,使用生成好的配置替代原有 Twemproxy 配置并 restart/reload Twemproxy 代理,知乎团队修改了 Twemproxy 代码,加入了 config reload 功能,但是实际使用中发现直接重启实例更加可控。而对于单机实例,由于单机实例和集群实例对于命令的支持不同,通常需要和业务方确定后手动重启切换。
由于 Twemproxy 部署于 Kubernetes ,可以实现细粒度的灰度,如果客户端接入了读写分离,可以先将读流量接入新集群,最终接入全部流量。
这样相对于 Redis 官方集群方案,除在上游进行 BGSAVE 时的 fork 复制页表时造成的尖刺以及重启时造成的连接闪断,其余对于 Redis 上游造成的影响微乎其微。
这样扩容存在的问题:
1)对上游发送 SYNC 后,上游 fork 时会造成尖刺:
-
对于存储实例,使用 Slave 进行数据同步,不会影响到接收请求的 Master 节点;
-
对于缓存实例,由于没有 Slave 实例,该尖刺无法避免,如果对于尖刺过于敏感,可以跳过 RDB 阶段,直接通过 PSYNC 使用最新的 SET 消息建立下游的缓存。
2)切换过程中有可能写到下游,而读在上游:
- 对于接入了读写分离的客户端,会先切换读流量到下游实例,再切换写流量。
3)一致性问题,两条具有先后顺序的写同一个 Key 命令在切换代理后端时会通过 1)写上游同步到下游 2)直接写到下游两种方式写到下游,此时,可能存在应先执行的命令却通过 1)执行落后于通过 2)执行,导致命令先后顺序倒置:
-
这个问题在切换过程中无法避免,好在绝大部分应用没有这种问题,如果无法接受,只能通过上游停写排空 Resharding 代理保证先后顺序;
-
官方 Redis 集群方案和 Codis 会通过 blocking 的 migrate 命令来保证一致性,不存在这种问题。
实际使用过程中,如果上游分片安排合理,可实现数千万次每秒的迁移速度,1TB 的实例 Resharding 只需要半小时左右。另外,对于实际生产环境来说,提前做好预期规划比遇到问题紧急扩容要快且安全得多。
知乎为什么没有使用官方 Redis 集群方案
在 2015 年调研过多种集群方案,综合评估多种方案后,最终选择了看起来较为陈旧的 Twemproxy 而不是官方 Redis 集群方案与 Codis,具体原因如下:
1)MIGRATE 造成的阻塞问题:
Redis 官方集群方案使用 CRC16 算法计算哈希值并将 Key 分散到 16384 个 Slot 中,由使用方自行分配 Slot 对应到每个分片中,扩容时由使用方自行选择 Slot 并对其进行遍历,对 Slot 中每一个 Key 执行 MIGRATE 命令进行迁移。
调研后发现,MIGRATE 命令实现分为三个阶段:
a)DUMP 阶段:由源实例遍历对应 Key 的内存空间,将 Key 对应的 Redis Object 序列化,序列化协议跟 Redis RDB 过程一致;
b)RESTORE 阶段:由源实例建立 TCP 连接到对端实例,并将 DUMP 出来的内容使用 RESTORE 命令到对端进行重建,新版本的 Redis 会缓存对端实例的连接;
c)DEL 阶段(可选):如果发生迁移失败,可能会造成同名的 Key 同时存在于两个节点,此时 MIGRATE 的 REPLACE 参数决定是是否覆盖对端的同名 Key,如果覆盖,对端的 Key 会进行一次删除操作,4.0 版本之后删除可以异步进行,不会阻塞主进程。
经过调研,认为这种模式MIGRATE 并不适合知乎的生产环境。
Redis 为了保证迁移的一致性, MIGRATE 所有操作都是同步操作,执行 MIGRATE 时,两端的 Redis 均会进入时长不等的 BLOCK 状态。对于小 Key,该时间可以忽略不计,但如果一旦 Key 的内存使用过大,一个 MIGRATE 命令轻则导致尖刺,重则直接触发集群内的 Failover,造成不必要的切换
同时,迁移过程中访问到处于迁移中间状态的 Slot 的 Key 时,根据进度可能会产生 ASK 转向,此时需要客户端发送 ASKING 命令到 Slot 所在的另一个分片重新请求,请求时延则会变为原来的两倍。
同样,方案调研期间的 Codis 采用的是相同的 MIGRATE 方案,但是使用 Proxy 控制 Redis 进行迁移操作而非第三方脚本(如 redis-trib.rb),基于同步的类似 MIGRATE 的命令,实际跟 Redis 官方集群方案存在同样的问题。
2)缓存模式下高可用方案不够灵活:
还有,官方集群方案的高可用策略仅有主从一种,高可用级别跟 Slave 的数量成正相关,如果只有一个 Slave,则只能允许一台物理机器宕机, Redis 4.2 roadmap 提到了 cache-only mode,提供类似于 Twemproxy 的自动剔除后重分片策略,但是截至目前仍未实现。
3)内置 Sentinel 造成额外流量负载:
另外,官方 Redis 集群方案将 Sentinel 功能内置到 Redis 内,这导致在节点数较多(大于 100)时在 Gossip 阶段会产生大量的 PING/INFO/CLUSTER INFO 流量,根据 issue 中提到的情况,200 个使用 3.2.8 版本节点搭建的 Redis 集群,在没有任何客户端请求的情况下,每个节点仍然会产生 40Mb/s 的流量,虽然到后期 Redis 官方尝试对其进行压缩修复,但按照 Redis 集群机制,节点较多的情况下无论如何都会产生这部分流量,对于使用大内存机器但是使用千兆网卡的用户这是一个值得注意的地方。
4)slot 存储开销:
最后,每个 Key 对应的 Slot 的存储开销,在规模较大的时候会占用较多内存,4.x 版本以前甚至会达到实际使用内存的数倍,虽然 4.x 版本使用 rax 结构进行存储,但是仍然占据了大量内存,从非官方集群方案迁移到官方集群方案时,需要注意这部分多出来的内存。
总之,官方 Redis 集群方案与 Codis 方案对于绝大多数场景来说都是非常优秀的解决方案,但是仔细调研发现并不是很适合集群数量较多且使用方式多样化的知乎,
总之,场景不同侧重点也会不一样,方案也需要调整,没有最有,只有最适合。
Codis代理分片
Codis 是一个分布式 Redis 解决方案, 对于上层的应用来说, 连接到 Codis Proxy 和连接原生的 Redis Server 没有明显的区别 (有一些命令不支持), 上层应用可以像使用单机的 Redis 一样使用, Codis 底层会处理请求的转发, 不停机的数据迁移等工作, 所有后边的一切事情, 对于前面的客户端来说是透明的, 可以简单的认为后边连接的是一个内存无限大的 Redis 服务,
现在美团、阿里等大厂已经开始用codis的集群功能了,
什么是Codis?
Twemproxy不能平滑增加Redis实例的问题带来了很大的不便,于是豌豆荚自主研发了Codis,一个支持平滑增加Redis实例的Redis代理软件,其基于Go和C语言开发,并于2014年11月在GitHub上开源 codis开源地址 。
Codis的架构图:
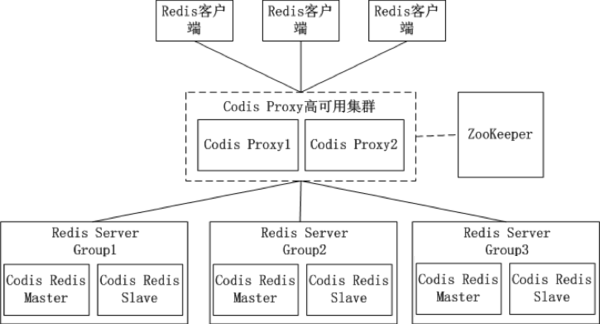
在Codis的架构图中,Codis引入了Redis Server Group,其通过指定一个主CodisRedis和一个或多个从CodisRedis,实现了Redis集群的高可用。当一个主CodisRedis挂掉时,Codis不会自动把一个从CodisRedis提升为主CodisRedis,这涉及数据的一致性问题(Redis本身的数据同步是采用主从异步复制,当数据在主CodisRedis写入成功时,从CodisRedis是否已读入这个数据是没法保证的),需要管理员在管理界面上手动把从CodisRedis提升为主CodisRedis。
如果手动处理觉得麻烦,豌豆荚也提供了一个工具Codis-ha,这个工具会在检测到主CodisRedis挂掉的时候将其下线并提升一个从CodisRedis为主CodisRedis。
Codis的预分片
Codis中采用预分片的形式,启动的时候就创建了1024个slot,1个slot相当于1个箱子,每个箱子有固定的编号,范围是1~1024。
Codis的分片算法
Codis proxy 代理通过一种算法把要操作的key经过计算后分配到各个组中,这个过程叫做分片。
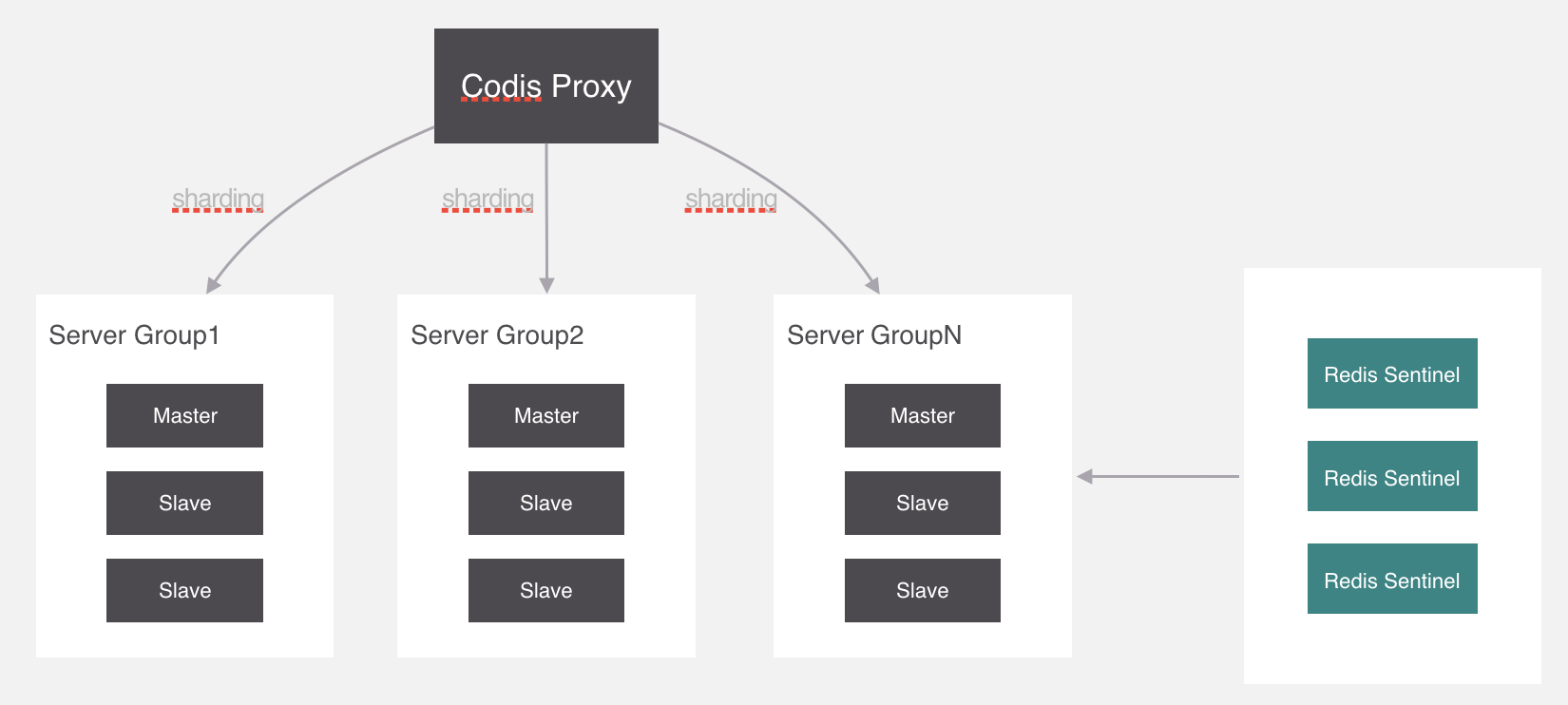
在Codis里面,它把所有的key分为1024个槽,每一个槽位都对应了一个分组,具体槽位的分配,可以进行自定义,现在如果有一个key进来,首先要根据CRC32算法,针对key算出32位的哈希值,然后除以1024取余,然后就能算出这个KEY属于哪个槽,然后根据槽与分组的映射关系,就能去对应的分组当中处理数据了。
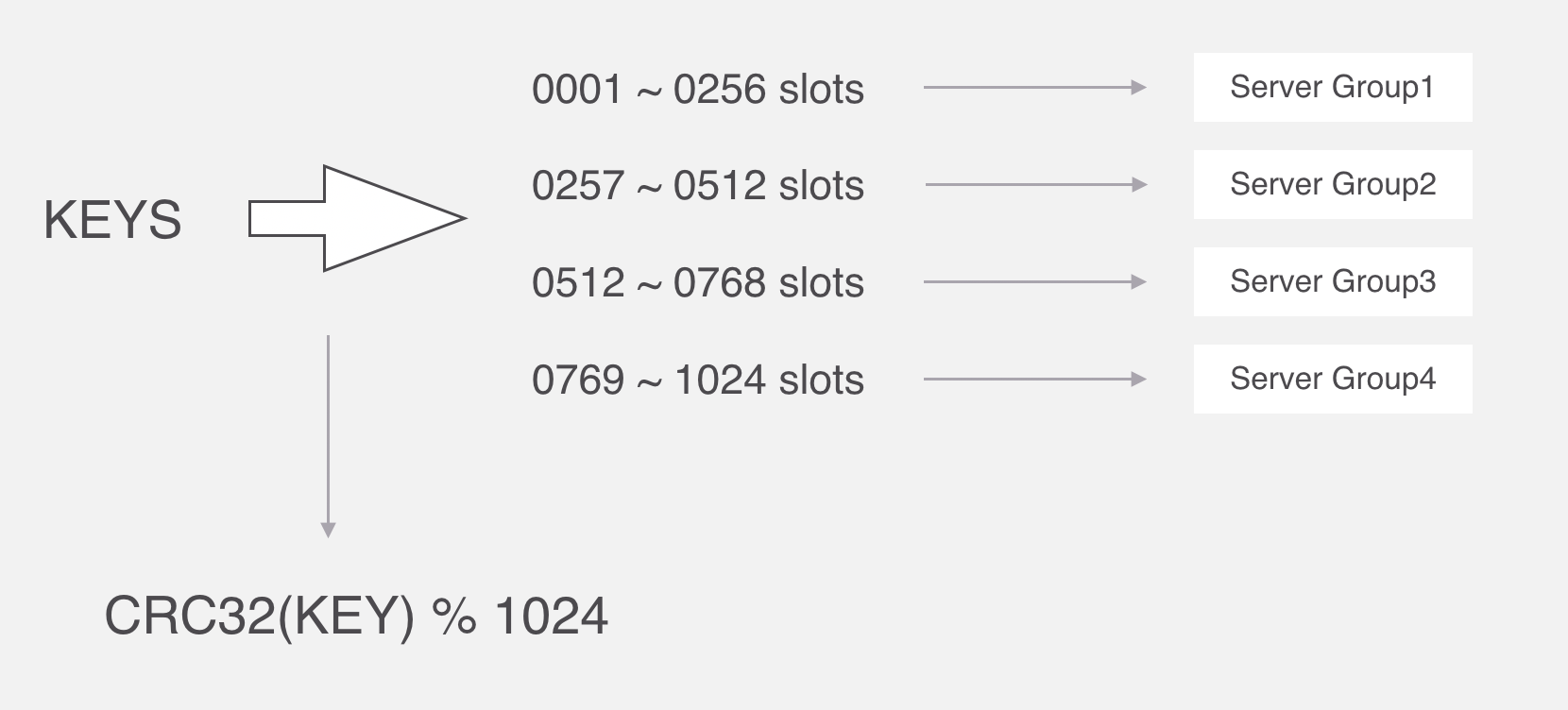
CRC全称是循环冗余校验,主要在数据存储和通信领域保证数据正确性的校验手段,CRC校验(循环冗余校验)是数据通讯中最常采用的校验方式。
我们继续回过来,slot这个箱子用作存放Key,至于Key存放到哪个箱子,可以通过算法“crc32(key)%1024”获得一个数字,这个数字的范围一定是1~1024之间,Key就放到这个数字对应的slot。
例如,如果某个Key通过算法“crc32(key)%1024”得到的数字是5,就放到编码为5的slot(箱子)。
slot和Server Group的关系
1个slot只能放1个Redis Server Group,不能把1个slot放到多个Redis Server Group中。1个Redis Server Group最少可以存放1个slot,最大可以存放1024个slot。因此,Codis中最多可以指定1024个Redis Server Group。
槽位和分组的映射关系就保存在codis proxy当中
codis-ha 高可用
槽位和分组的映射关系就保存在codis proxy当中,但是codis proxy它本身也存在单点问题,所以需要对proxy做一个集群。
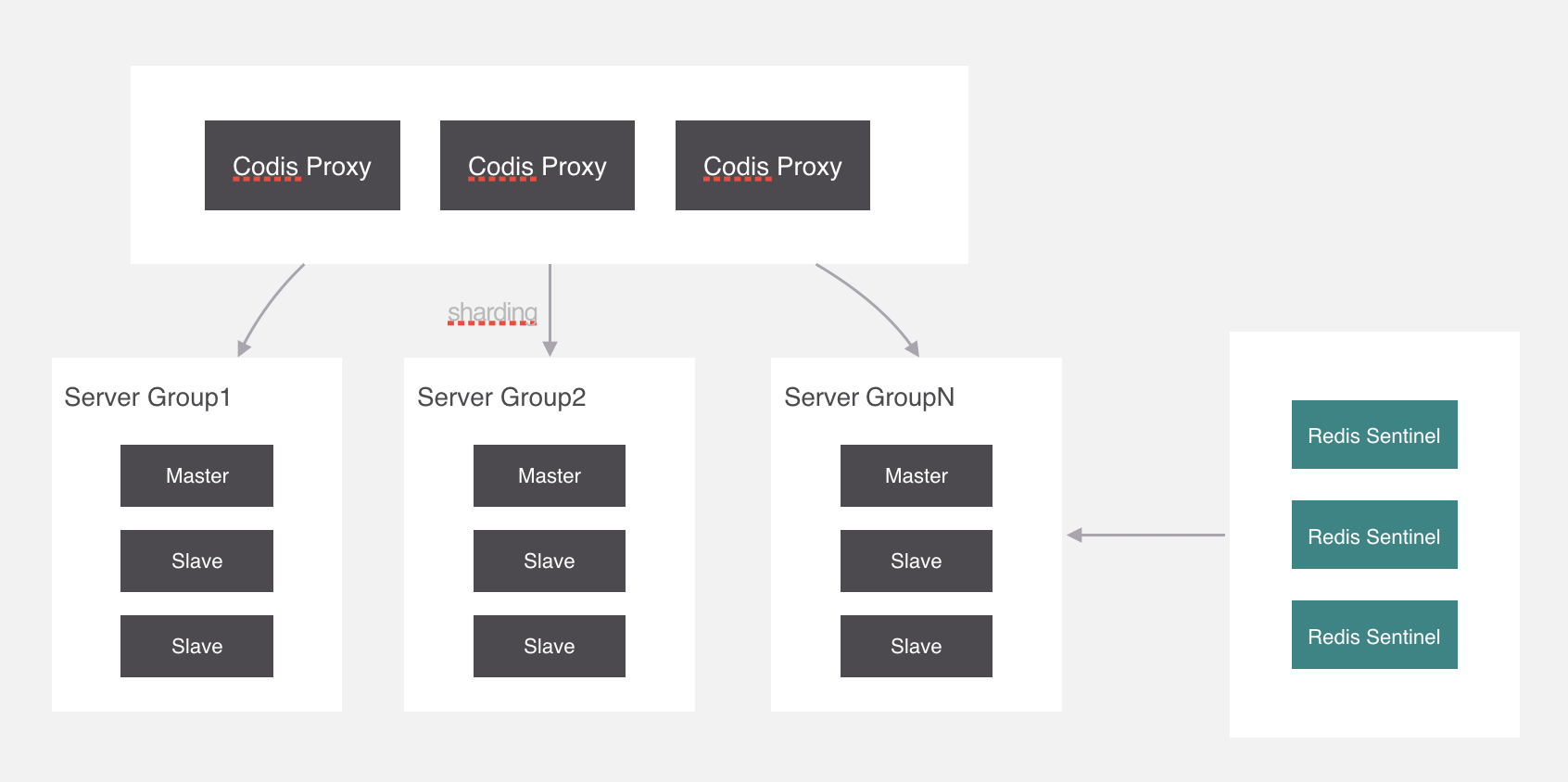
部署好集群之后,有一个问题,就是槽位的映射关系是保存在proxy里面的,不同proxy之间怎么同步映射关系?
在Codis中使用的是Zookeeper来保存映射关系,给 proxy 来同步配置信息,其实codis 支持的不止zookeeper,还有etcd和本地文件。
在zookeeper中保存的数据格式就是这个样子。
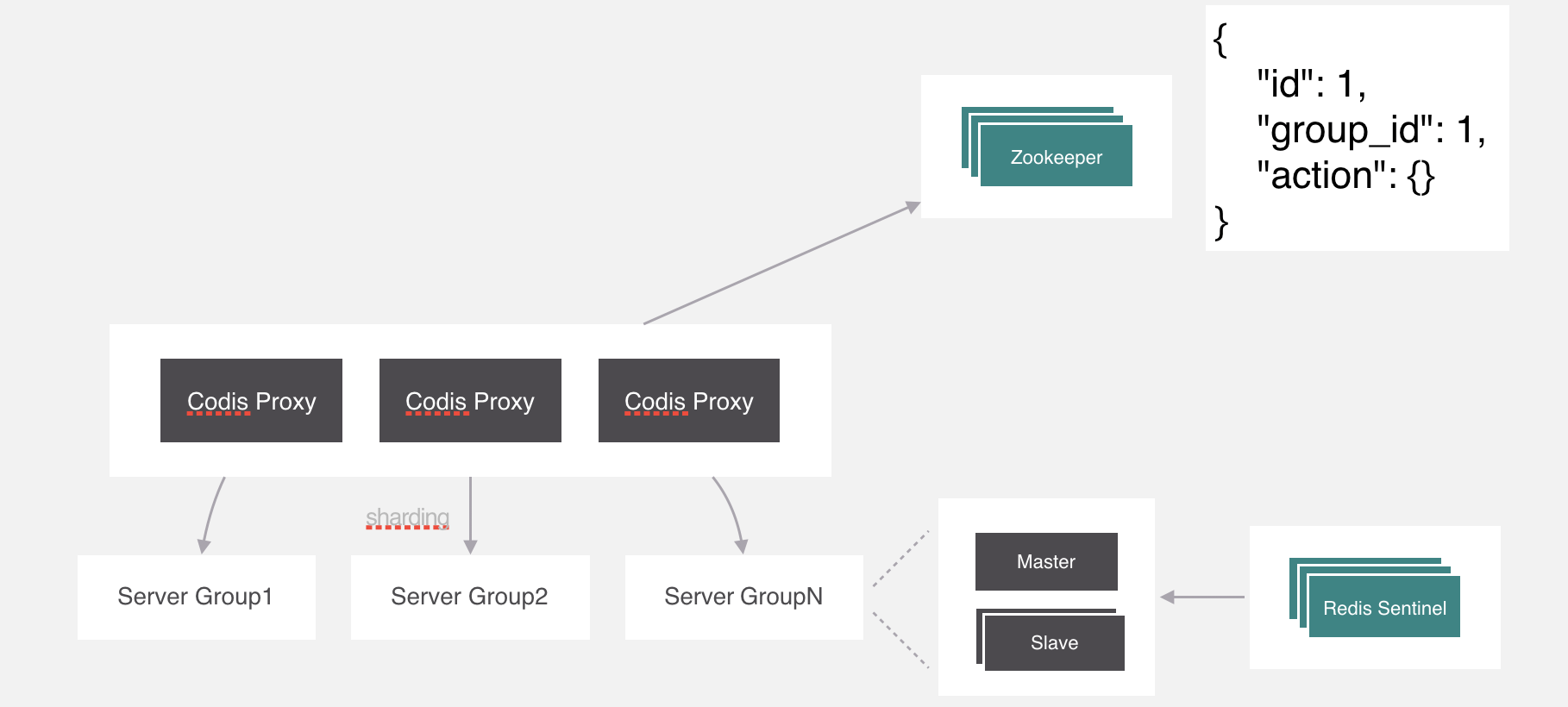
除了这个slot id, group_id 还会存储一些其他的信息,比如分组信息、代理信息等。
如果codis proxy如果出现异常怎么处理,这个可能要利用一下k8s中pod的特性,在k8s里面可以设置pod冗余的数量,k8s会严格保证启动的数量与设置一致,所以只需要一个进程监测Proxy的异常,并且把它干掉就可以了,k8s会自动拉起来一个新的proxy。
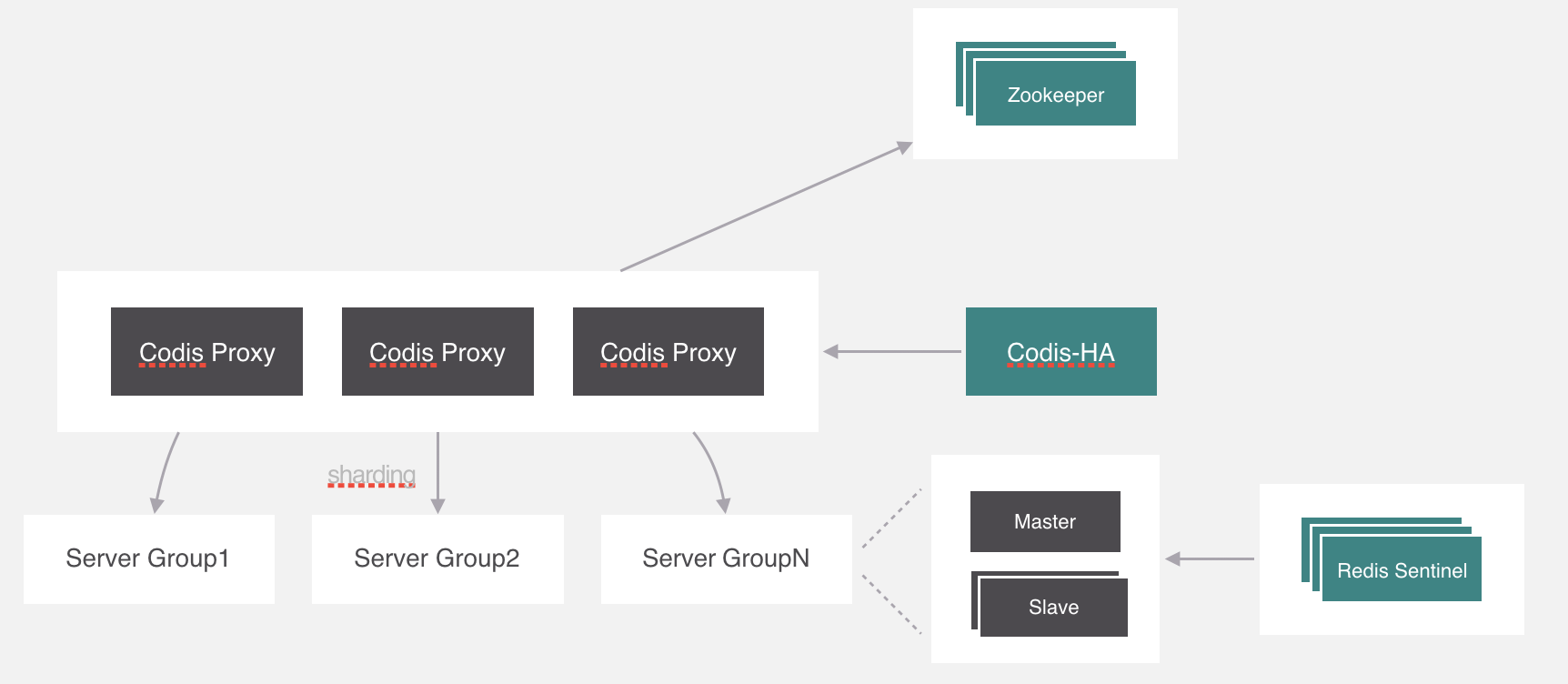
codis给这个进程起名叫codis-ha,codis-ha实时监测codis proxy的运行状态,如果有异常就会干掉,它包含了哨兵的功能,所以豌豆荚直接把哨兵去掉了。
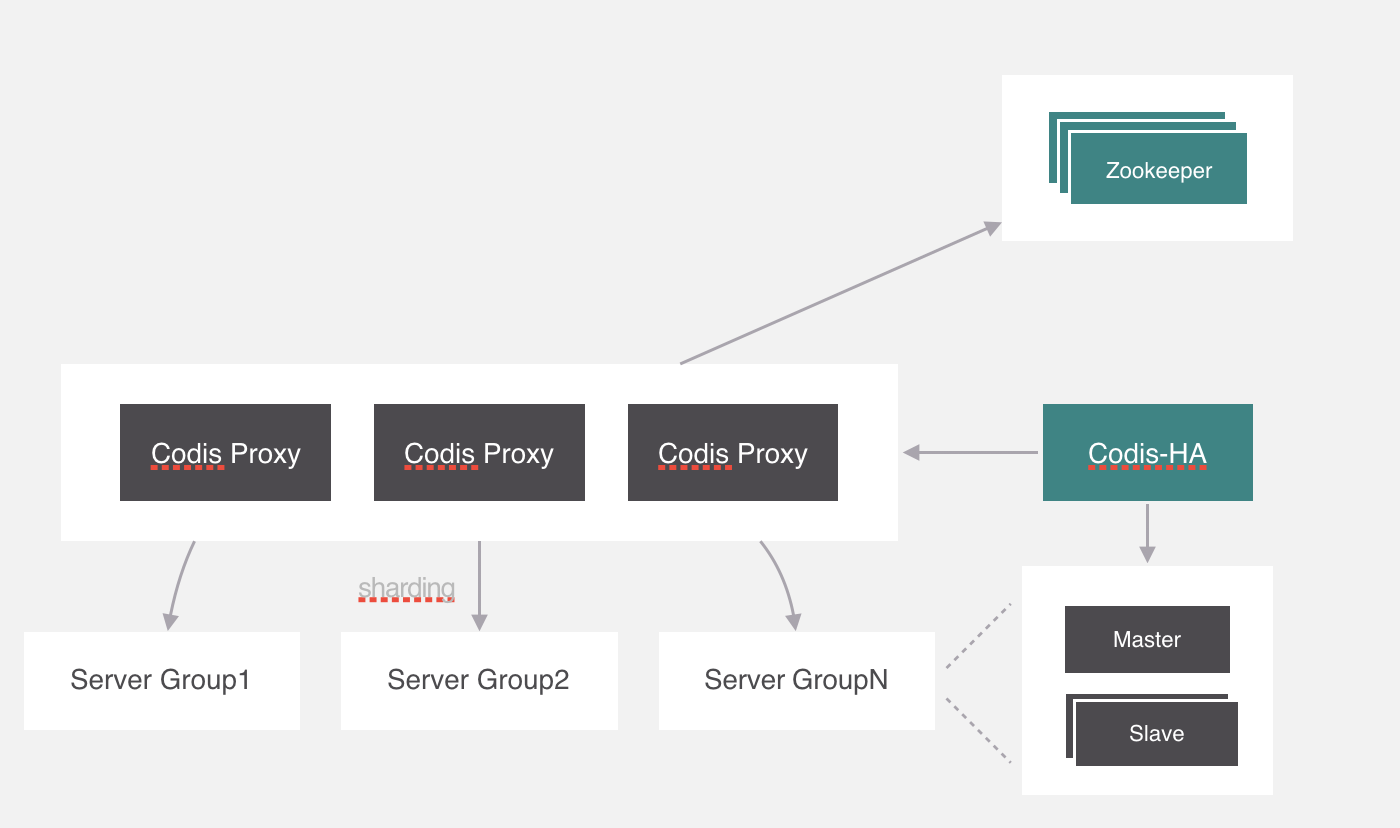
dashboard
但是codis-ha在Codis整个架构中是没有办法直接操作代理和服务,因为所有的代理和服务的操作都要经过dashboard处理。所以部署的时候会利用k8s的亲和性将codis-ha与dashboard部署在同一个节点上。
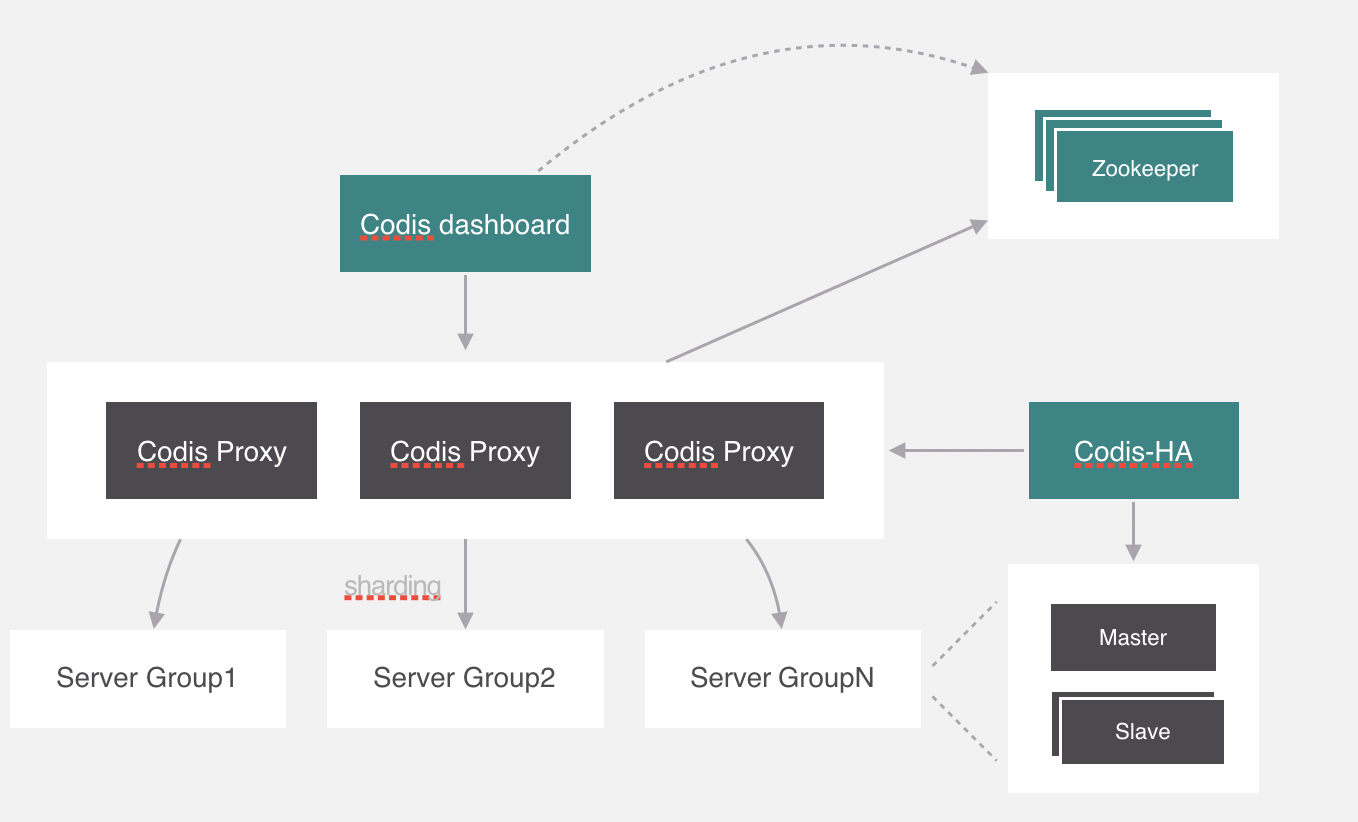
除了这些,codis自己开发了集群管理界面,集群管理可以通过界面化的方式更方便的管理集群,这个模块叫codis-fe,我们可以看一下这个界面。
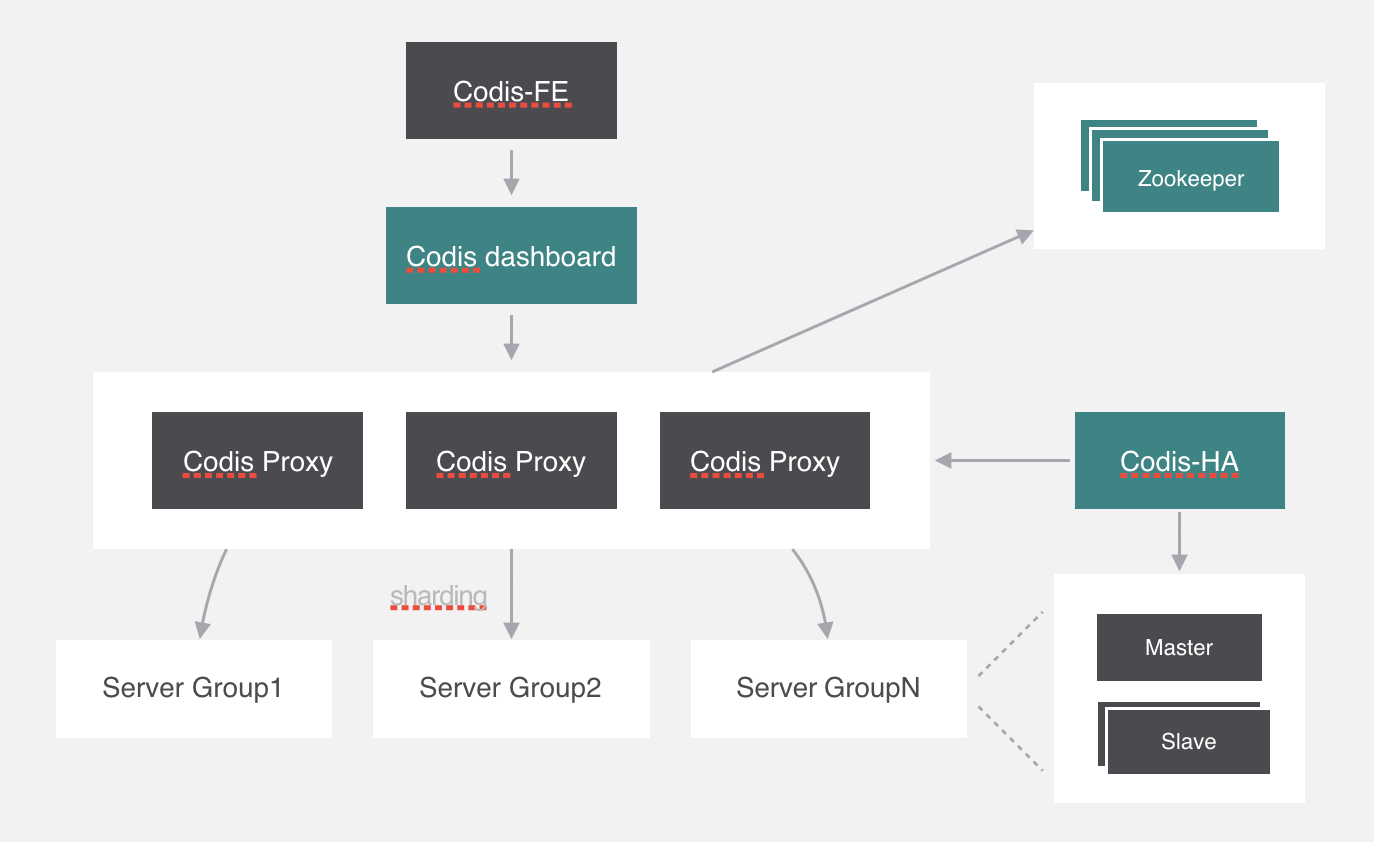
最后就是redis客户端了,客户端是直接通过代理来访问后端服务的。

Codis的架构
Codis是一个分布式Redis解决方案,对于上层的应用来说,连接到Codis Proxy和连接原生的RedisServer没有明显的区别,有部分命令不支持。
Codis底层会处理请求的转发,不停机的数据迁移等工作,所有后边的一切事情,
对于前面的客户端来说是透明的,可以简单的认为后边连接的是一个内存无限大的Redis服务.
Codis 由四部分组成:
- Codis Proxy (codis-proxy),处理客户端请求,支持Redis协议,因此客户端访问Codis Proxy跟访问原生Redis没有什么区别;
- Codis Dashboard (codis-config),Codis 的管理工具,支持添加/删除 Redis 节点、添加/删除 Proxy 节点,发起数据迁移等操作。codis-config 本身还自带了一个 http server,会启动一个 dashboard,用户可以直接在浏览器上观察 Codis 集群的运行状态;
- Codis Redis (codis-server),Codis 项目维护的一个 Redis 分支,基于 2.8.21 开发,加入了 slot 的支持和原子的数据迁移指令;
- ZooKeeper/Etcd,Codis 依赖 ZooKeeper 来存放数据路由表和 codis-proxy 节点的元信息,codis-config 发起的命令都会通过 ZooKeeper 同步到各个存活的 codis-proxy;
Codis 支持按照 Namespace 区分不同的产品,拥有不同的 product name 的产品,各项配置都不会冲突。
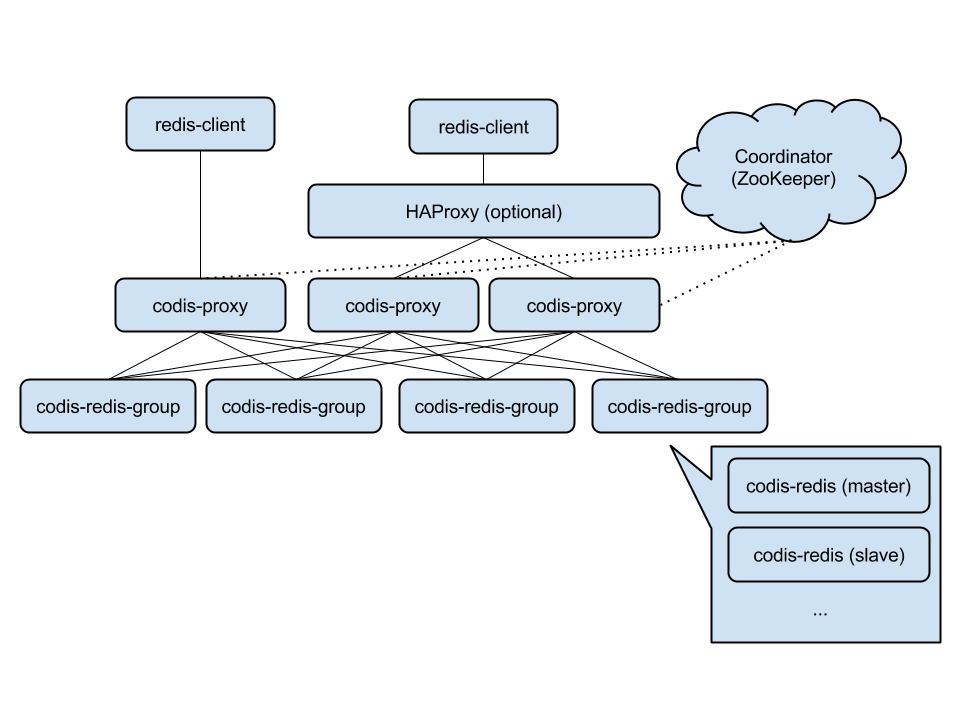
安装与部署
-
安装go;
-
安装codis
go get -u -d github.com/CodisLabs/codis cd $GOPATH/src/github.com/CodisLabs/codis make -
安装zookeeper;
-
启动dashboard
bin/codis-config dashboard -
初始化slots,在zk上创建slot相关信息
bin/codis-config slot init -
启动codis-redis,跟官方redis server方法一样;
-
添加redis server group,每个 Group 作为一个 Redis 服务器组存在,只允许有一个 master, 可以有多个 slave,group id 仅支持大于等于1的整数。如: 添加两个 server group, 每个 group 有两个 redis 实例,group的id分别为1和2, redis实例为一主一从。
-
bin/codis-config server add 1 localhost:6379 master bin/codis-config server add 1 localhost:6380 slave bin/codis-config server add 2 localhost:6479 master bin/codis-config server add 2 localhost:6480 slave -
设置server group 服务的 slot 范围,如设置编号为[0, 511]的 slot 由 server group 1 提供服务, 编号 [512, 1023] 的 slot 由 server group 2 提供服务
bin/codis-config slot range-set 0 511 1 online bin/codis-config slot range-set 512 1023 2 online -
启动codis-proxy,
bin/codis-proxy -c config.ini -L ./log/proxy.log --cpu=8 --addr=0.0.0.0:19000 --http-addr=0.0.0.0:11000刚启动的 codis-proxy 默认是处于 offline状态的, 然后设置 proxy 为 online 状态, 只有处于 online 状态的 proxy 才会对外提供服务
bin/codis-config -c config.ini proxy online <proxy_name> <---- proxy的id, 如 proxy_1
Codis的优缺点
(1)优点
对客户端透明,与codis交互方式和redis本身交互一样
支持在线数据迁移,迁移过程对客户端透明有简单的管理和监控界面
支持高可用,无论是redis数据存储还是代理节点
自动进行数据的均衡分配
最大支持1024个redis实例,存储容量海量
高性能
(2)缺点
采用自有的redis分支,不能与原版的redis保持同步
如果codis的proxy只有一个的情况下, redis的性能会下降20%左右
某些命令不支持,比如事务命令muti
国内开源产品,活跃度相对弱一些
数据迁移(migrate)
安全和透明的数据迁移是 Codis 提供的一个重要的功能,也是 Codis 区别于 Twemproxy 等静态的分布式 Redis 解决方案的地方。
数据迁移的最小单位是 key,我们在 codis redis 中添加了一些指令,实现基于key的迁移,如 SLOTSMGRT等 (命令列表),每次会将特定 slot 一个随机的 key 发送给另外一个 codis redis 实例,这个命令会确认对方已经接收,同时删除本地的这个 k-v 键值,返回这个 slot 的剩余 key 的数量,整个操作是原子的。
在 codis-config 管理工具中,每次迁移任务的最小单位是 slot。如: 将slot id 为 [0-511] 的slot的数据,迁移到 server group 2上,--delay 参数表示每迁移一个 key 后 sleep 的毫秒数,默认是 0,用于限速。
bin/codis-config slot migrate 0 511 2 --delay=10
迁移的过程对于上层业务来说是安全且透明的,数据不会丢失,上层不会中止服务。
注意,迁移的过程中打断是可以的,但是如果中断了一个正在迁移某个slot的任务,下次需要先迁移掉正处于迁移状态的 slot,否则无法继续 (即迁移程序会检查同一时刻只能有一个 slot 处于迁移状态)。
自动再平衡(auto rebalance)
Codis 支持动态的根据实例内存,自动对slot进行迁移,以均衡数据分布
bin/codis-config slot rebalance
要求:
- 所有的codis-server都必须设置了maxmemory参数;
- 所有的 slots 都应该处于 online 状态, 即没有迁移任务正在执行;
- 所有 server group 都必须有 Master;
高可用(HA)
因为codis的proxy是无状态的,可以比较容易的搭多个proxy来实现高可用性并横向扩容。
应用层的HA
对Java用户来说,可以使用经过一些开源的组件,来实现客户端的在多个proxy直接进行HA。
也可以通过监控zk上的注册信息来实时获得当前可用的proxy列表,既可以保证高可用性,
也可以通过轮流请求所有的proxy实现负载均衡。
后端redis 主备ha
对后端的redis实例来说,当一个group的master挂掉的时候,应该让管理员清楚,并手动的操作,因为这涉及到了数据一致性等问题(redis的主从同步是最终一致性的)。
因此codis不会自动的将某个slave升级成master。 不过也提供一种解决方案:codis-ha。这是一个通过codis开放的api实现自动切换主从的工具。该工具会在检测到master挂掉的时候将其下线并选择其中一个slave提升为master继续提供服务。
需要注意,codis将其中一个slave升级为master时,该组内其他slave实例是不会自动改变状态的,这些slave仍将试图从旧的master上同步数据,因而会导致组内新的master和其他slave之间的数据不一致。
因为redis的slave of命令切换master时会丢弃slave上的全部数据,从新master完整同步,会消耗master资源。
因此建议在知情的情况下手动操作。
使用
codis-config server add <group_id> <redis_addr> slave命令刷新这些节点的状态即可。codis-ha不会自动刷新其他slave的状态。
大厂使用什么样的redis集群:
redis 集群方案主要有3类,一是使用类 codis 的代理模式架构,按组划分,实例之间互相独立;另一套是基于官方的 redis cluster 的服务端分片方案;代理模式和服务端分片相结合的模式
- 基于官方 redis cluster 的服务端分片方案
- 类 codis 的代理模式架构
- 代理模式和服务端分片相结合的模式
类 codis 的代理模式架构

这套架构的特点:
- 分片算法:基于 slot hash桶;
- 分片实例之间相互独立,每组 一个master 实例和多个slave;
- 路由信息存放到第三方存储组件,如 zookeeper 或etcd
- 旁路组件探活
使用这套方案的公司:
阿里云: ApsaraCache, RedisLabs、京东、百度等
阿里云
AparaCache 的单机版已开源(开源版本中不包含slot等实现),集群方案细节未知;ApsaraCache
百度 BDRP 2.0
主要组件:
proxy,基于twemproxy 改造,实现了动态路由表;
redis内核: 基于2.x 实现的slots 方案;
metaserver:基于redis实现,包含的功能:拓扑信息的存储 & 探活;
最多支持1000个节点;
slot 方案:
redis 内核中对db划分,做了16384个db; 每个请求到来,首先做db选择;
数据迁移实现:
数据迁移的时候,最小迁移单位是slot,迁移中整个slot 处于阻塞状态,只支持读请求,不支持写请求;
对比 官方 redis cluster/ codis 的按key粒度进行迁移的方案:按key迁移对用户请求更为友好,但迁移速度较慢;这个按slot进行迁移的方案速度更快;
京东proxy
主要组件:
proxy: 自主实现,基于 golang 开发;
redis内核:基于 redis 2.8
configServer(cfs)组件:配置信息存放;
scala组件:用于触发部署、新建、扩容等请求;
mysql:最终所有的元信息及配置的存储;
sentinal(golang实现):哨兵,用于监控proxy和redis实例,redis实例失败后触发切换;
slot 方案实现:
在内存中维护了slots的map映射表;
数据迁移:
基于 slots 粒度进行迁移;
scala组件向dst实例发送命令告知会接受某个slot;
dst 向 src 发送命令请求迁移,src开启一个线程来做数据的dump,将这个slot的数据整块dump发送到dst(未加锁,只读操作)
写请求会开辟一块缓冲区,所有的写请求除了写原有数据区域,同时双写到缓冲区中。
当一个slot迁移完成后,把这个缓冲区的数据都传到dst,当缓冲区为空时,更改本分片slot规则,不再拥有该slot,后续再请求这个slot的key返回moved;
上层proxy会保存两份路由表,当该slot 请求目标实例得到 move 结果后,更新拓扑;
跨机房:跨机房使用主从部署结构;没有多活,异地机房作为slave;
基于官方 redis cluster 的服务端分片方案

和上一套方案比,所有功能都集成在 redis cluster 中,路由分片、拓扑信息的存储、探活都在redis cluster中实现;各实例间通过 gossip 通信;这样的好处是简单,依赖的组件少,应对400个节点以内的场景没有问题(按单实例8w read qps来计算,能够支持 200 * 8 = 1600w 的读多写少的场景);但当需要支持更大的规模时,由于使用 gossip协议导致协议之间的通信消耗太大,redis cluster 不再合适;
使用这套方案的有:AWS, 百度贴吧
官方 redis cluster
数据迁移过程:
基于 key粒度的数据迁移;
迁移过程的读写冲突处理:
从A 迁移到 B;
- 访问的 key 所属slot 不在节点 A 上时,返回 MOVED 转向,client 再次请求B;
- 访问的 key 所属 slot 在节点 A 上,但 key 不在 A上, 返回 ASK 转向,client再次请求B;
- 访问的 key 所属slot 在A上,且key在 A上,直接处理;(同步迁移场景:该 key正在迁移,则阻塞)
AWS ElasticCache
ElasticCache 支持主从和集群版、支持读写分离;
集群版用的是开源的Redis Cluster,未做深度定制;
代理模式和服务端分片相结合的模式
p2p和代理的混合模式: 基于redis cluster + twemproxy混合模式
百度贴吧的ksarch-saas:
基于redis cluster + twemproxy 实现;后被 BDRP 吞并;
twemproxy 实现了 smart client 功能;
使用 redis cluster后还加一层 proxy的好处:
- 对client友好,不需要client都升级为smart client;(否则,所有语言client 都需要支持一遍)
- 加一层proxy可以做更多平台策略;比如在proxy可做 大key、热key的监控、慢查询的请求监控、以及接入控制、请求过滤等;
即将发布的 redis 5.0 中有个 feature,作者计划给 redis cluster加一个proxy。
ksarch-saas 对 twemproxy的改造已开源:
https://github.com/ksarch-saas/r3proxy
面试题
请介绍一下你使用过的Redis集群的架构和原理?
看完本文,涉及到Redis集群的架构类面试题目,按照本文的思路去回答,一定是120分。
如果还有疑问,请来疯狂创客圈社群交流。
Redis集群的架构和原理问题交流:
高并发Java发烧友社群 - 疯狂创客圈 总入口 点击了解详情:

参考文档:
https://blog.csdn.net/ranrancc_/article/details/104283802
https://www.ipcpu.com/2019/01/redis-sentinel/
http://t.zoukankan.com/ilifeilong-p-12632231.html
https://zhuanlan.zhihu.com/p/60632927
https://blog.csdn.net/clapAlong/article/details/115493537
https://blog.csdn.net/justlpf/article/details/115908335
https://www.cnblogs.com/jebysun/p/9698554.html
https://www.cnblogs.com/Anker/p/7076537.html
https://www.cnblogs.com/rjzheng/p/11430592.html
https://blog.csdn.net/qq_24365213/article/details/73504091
https://www.cnblogs.com/me115/p/9043420.html
https://www.cnblogs.com/kismetv/p/9236731.html
https://www.cnblogs.com/kismetv/p/9236731.html
https://zhuanlan.zhihu.com/p/101172874
https://www.jianshu.com/p/b46cb093a083
https://zhuanlan.zhihu.com/p/89248752

 浙公网安备 33010602011771号
浙公网安备 33010602011771号