python 实用编程技巧 —— 数据解析与构建相关问题与解决技巧
如何读写csv数据
csv 模块 reader 和 writer 对象读取和写入序列。程序员还可以使用 DictReader 和 DictWriter 类以字典形式读写数据。
该 csv 模块定义了以下功能
csv.reader(csvfile,dialect ='excel',** fmtparams )
- 返回一个读取器对象,它将迭代 csvfile 中的每行,以列表的形式呈现(里面的每个元素为字符串)
一个简单的用法案例:
import csv
with open('eggs.csv', 'r') as csvfile:
spamreader = csv.reader(csvfile, delimiter=' ', quotechar='|')
for row in spamreader:
print(', '.join(row))
csv.writer(csvfile,dialect ='excel',** fmtparams )
- 返回一个writer对象,负责将用户的数据转换为给定的类文件对象上的分隔字符串。
一个简单的用法案例
import csv
with open('eggs.csv', 'wb') as csvfile:
spamwriter = csv.writer(csvfile, delimiter=' ',
quotechar='|', quoting=csv.QUOTE_MINIMAL)
spamwriter.writerow(['Spam'] * 5 + ['Baked Beans'])
spamwriter.writerow(['Spam', 'Lovely Spam', 'Wonderful Spam'])
csv.DictReader(f,fieldnames = None,restkey = None,restval = None,dialect ='excel',* args,** kwds )
- 创建一个像常规阅读器一样操作的对象,但将读取的信息映射到一个dict
简单用法实例
import csv
with open('ceshi.csv') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
print(row['name'], row['age'])
csv.DictWriter(f,fieldnames,restval ='',extrasaction ='raise',dialect ='excel',* args,** kwds )
- 创建一个像常规编写器一样操作的对象,但将字典映射到输出行。如果字典缺少字段名中的键,则可选的restval参数指定要写入的值
- fieldnames 起到约束的作用,指定 csv 的头
一个简短的用法实例
import csv
with open('names.csv', 'w') as csvfile:
fieldnames = ['first_name1', 'last_name']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'first_name': 'Baked', 'last_name': 'Beans'})
writer.writerow({'first_name': 'Lovely', 'last_name': 'Spam'})
writer.writerow({'first_name': 'Wonderful', 'last_name': 'Spam'})
支持以下属性
Dialect.delimiter:用于分隔字段的单字符字符串。它默认为','- Dialect.lineterminator: 用于终止由生成的行的字符串 wrinter, 它默认为
'\r\n' Dialect.skipinitialspace:True,忽略分隔符后面的空格。默认是False
公共方法:
csvwriter.writerow(行)
- 将row参数写入writer的文件对象,根据当前方言进行格式化
csvwriter.writerows(行)
- 将行中的所有元素(如上所述的行对象的可迭代)写入编写器的文件对象,根据当前方言进行格式化
读写csv文件
import csv
headers = ['name', 'age', 'six']
data = [
('张三', '21', '男'),
('张四', '22', '男')
]
with open('ceshi.csv', 'w', encoding='gbk') as f:
writer = csv.writer(f, delimiter=',')
writer.writerow(headers)
for i in data:
writer.writerow(i)
with open('ceshi.csv','r', encoding='gbk') as f:
reader = csv.reader(f)
next(reader)
for book in reader:
print(book)
如何解析简单的xml文档
from xml.etree import ElementTree
# 从字符串中解析
ElementTree.fromstring('相应字符串')
# 从文件中解析
et = ElementTree.parse('demo.xml')
root = et.getroot() # 获取根元素 data
root.tag # 当前tag data
c1 = list(root)[0] # 获取子元素列表 c1为列表中第一个 country
c1.attrib # {'name': "Liechtenstein"} attrib获取属性字典
c1.get('name') # Liechtenstein
year = list(c1)[1]
year.text # 得到year标签里的 2008
year.tail # '\n\t\t' 即 year标签与下一个标签 之间的 字符
c1.find('neighbor') # 在子元素中 找到 第一个neighbor标签
c1.findall('neighbor') # 在子元素中 找到 所有neighbor标签 得到 列表
list(root.iter('neighbor')) # 找到所有neighbor
# root.iter() 没有传入参数 则返回所有 元素
list[root.iterfind('./*/*[@name]')] # 使用xpath 表达式 查找
list(c1.itertext()) # 获取所有 text文本 包括 \n\t
# 过滤掉\n\t
' '.join(t for t in c1.itertext() if not t.isspace())
如何构建xml文档
Element 是节点元素
ElementTree是由 Element 组成
创建一个元素
from xml.etree.ElementTree import Element,ElementTree
e = Element("Data") #创建一个元素,传入一个字符串 <Data>是head的名字
e.set('name','abc') #设备这个元素的属性,get获取属性,set设置属性。属性为’name’值 是abc
from xml.etree.ElementTree import tostring #显示成为XML元素后转成了字符串
e.text = '123'
print(tostring(e))

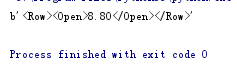
给一个元素添加子元素
from xml.etree.ElementTree import Element,ElementTree
e2 = Element('Row')
e3 = Element('Open')
e3.text = '8.80'
e2.append(e3)
from xml.etree.ElementTree import tostring #显示成为XML元素后转成了字符串
print(tostring(e2))
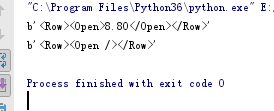
将一个已赋值的元素属性删除的方法
from xml.etree.ElementTree import Element,ElementTree
e2 = Element('Row')
e3 = Element('Open')
e3.text = '8.80'
e2.append(e3)
from xml.etree.ElementTree import tostring #显示成为XML元素后转成了字符串
print(tostring(e2))
e3.text = None # 删除 e3 中的内容
print(tostring(e2))
将XML格式的字符串写入文件中
from xml.etree.ElementTree import Element,ElementTree
e2 = Element('Row')
e3 = Element('Open')
e3.text = '8.80'
e2.append(e3)
e3.text = None # 删除 e3 中的内容
et = ElementTree(e2)
et.write('ha.xml')
如何读写excel文件
打开一个excel(读模式)
import xlrd, xlwt
rbook = xlrd.open_workbook('demo.xlsx') # 打开excel文件
# 获取所有的 表 rbook.sheets() 一个excel文件 是有多个表构成的 即sheet 可以在文件底边看到当前是哪张表
rsheet = rbook.sheet_by_index(0) # 第一张表
k = rsheet.ncols # ncols 列 nrows 行
# 常用用法
c00 = rsheet.cell(0,0) 获取0行 0列的 数据 是cell对象
c00.ctype 得到1 即xlrd.XL_CELL_TEXT 文本类型 还有其他的类型 如数字 type为 2 xlrd.XL_CELL_NUMBER
c00.value 得到内容 ‘姓名’
# rsheet.cell_value(0,0) 直接取到值
# 取整行
rsheet.row(0) 得到 [text:'姓名', text:'语文 , text:'数学', text:'英语']
rsheet.row_values(0) 得到 ['姓名', '语文 , '数学', '英语']
#第一个参数:第几行 第二个参数:从该行第几列开始取 第三个参数: 结束列,默认为 直到结束,
# 取列的方法 与取行 类似
rsheet.row_values(1, 1) 得到 [95, 99, 96]
往 excel 中写入数据
import xlrd, xlwt
rbook = xlrd.open_workbook('demo.xlsx') # 打开excel文件
# 获取所有的 表 rbook.sheets() 一个excel文件 是有多个表构成的 即sheet 可以在文件底边看到当前是哪张表
rsheet = rbook.sheet_by_index(0) # 第一张表
k = rsheet.ncols # ncols 列 nrows 行
rsheet.put_cell(0, k, xlrd.XL_CELL_TEXT, '总分', None) # 放置一个单元格,内容格式是文本,内容是总分
for i in range(1, rsheet.nrows):
t = sum(rsheet.row_values(i, 1)) # 算总分
rsheet.put_cell(i, k, xlrd.XL_CELL_NUMBER, t, None)
wbook = xlwt.Workbook()
wsheet = wbook.add_sheet(rsheet.name) # 表名不变
# 将原来的分数 和新添加的 总分 保存在新的excel文件中
for i in range(rsheet.nrows):
for j in range(rsheet.ncols):
wsheet.write(i, j, rsheet.cell_value(i, j))
wbook.save('out.xlsx')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号