python 实用编程技巧 —— 复杂场景下字符串处理相关问题与解决技巧
如何拆分含有多种分隔符的字符串
实际案例:
- 我们要把某个字符串依据分隔符号拆分不同的字段,该字符串包含多种不同的分隔符,例如: s=’ab;cd|efg|hi,jkl|mn\topq;rst,uvw\txyz’,其中<,>, <;>, <|>, <\t>都是分隔符号,如何处理?
解决方案:
- 1.连续使用str.split(),每一次处理一种分隔符号;
- 2.使用正则表达式的re.split(),一次性拆分字符串
map 函数的使用 (对指定的序列进行映射)
for z in map(lambda x: x.split(';'), ["ab;cd|efg|hi,jkl|mn\topq;rst,uvw\txyz"]):
print(z)

连续使用str.split
s = "ab;cd|efg|hi,jkl|mn\topq;rst,uvw\txyz"
def mySplit(s, ds):
res = [s]
for i in ds:
t = []
for z in map(lambda x: x.split(i), res):
t.extend(z)
res = t
return [x for x in res if x]
print(mySplit(s, ",;|\t"))

使用正则表达式的re.split(),一次性拆分字符串
import re s="ab;cd|efg|hi,jkl|mn\topq;rst,uvw\txyz" print(re.split(r'[,;|\t]+',s))

如何判断字符串a是否以字符串b开头或结尾
实际案例:
- 某文件系统中目录下有一系列文件,a.c,b.sh,d.py,e.java... 编写程序给其中所以的.sh文件和.py文件加上用户可执行权限
解决方案:
- 使用字符串的str.startwith()和str.endswith()方法, 注意:多个匹配时参数使用元组

如何调整字符串中文本的格式
案例:
- 把日期格式 'yyyy-mm-dd'改成'mm/dd/yyyy'
解决方案:
- 使用正则表达式re.sub()方法做字符串替换,利用正则表达式的捕获组,捕获每个部分内容,在替换字符串中调整各个捕获组的顺序
import re
log = "2016-05-21 10:39:26 statys unpacked python3-pip:all " \
"2016-05-23 10:49:26 status half-configured python3"
res = re.sub('(?P<d>\d{4})-(?P<m>\d{2})-(?P<y>\d{2})', r'\g<m>/\g<d>/\g<y>', log)
print(res)

如何将多个小字符串拼接成一个大的字符串
解决方案
- 迭代列表,连续使用'+'操作依次拼接每一个字符串
- 使用str.join()方法,更加快速的拼接列表中的所有字符串
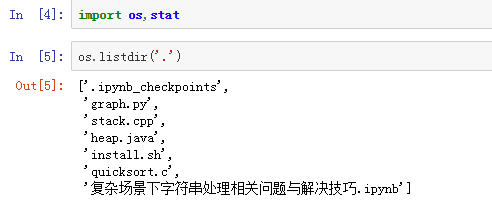
l = ["<0112>", "<32>", "<1024x768>", "<60>", "<1>", "<100.0>", "<500.0>"]
print(''.join(l))
如何对字符串进行左, 右, 居中对齐
案例:
- { "a":100, "as":0.01, "wer":500.0, "cc":12 } 处理成: "a" :100, "as" :0.01, "wer":500.0, "cc" :12
解决方案:
- 使用字符串的str.ljust(),str.rjust(),str.center()进行左右中对齐
- 使用format()方法,传递类似'<20','>20','^20'参数完成同样任务
s = 'abc' print(s.ljust(20)) print(s.ljust(20,'=')) print(s.rjust(20)) print(s.center(20)) print(format(s,'<20')) print(format(s,'>20')) print(format(s,'^20'))

实际案例
d = {
"a":100,
"as":0.01,
"wer":500.0,
"cc":12
}
# 通过map找出key的长度
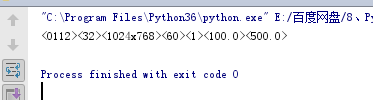
print(list(map(len,d.keys())))
w = max(list(map(len, d.keys())))
for k in d:
print(k.ljust(w),':',d[k])
如何去掉字符串中不需要的字符
案例:
- 1.过滤掉用户输入中前后多余的空白字符:' hello@qq.com '
- 2.过滤windows下编辑文本中的'\r':'hello world\r\n'
- 3.去掉文本中的unicode符号"āáǎà ōóǒò ēéěè īíǐì"
方案:
- 1.字符串strip(),lstrip(),rstip()去掉字符串两端字符
- 2.删除单个固定位置的字符,可以使用切片+拼接的方式
- 3.字符串的replace()方法或正则表达式re.sub()删除任意位置字符
- 4.字符串translate()方法,可以同时删除多种不同字符
去掉空白字符
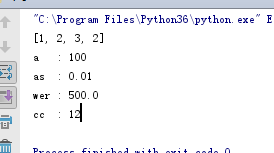
s = ' abc 123 ' # 去掉两边的空白字符 print(s.strip()) # 去掉左边的字符 print(s.lstrip()) # 去掉右边的字符 print(s.rstrip())
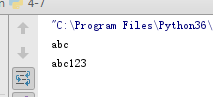
删除字符
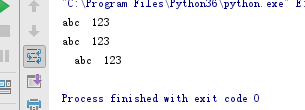
s = '+++abc---'
# 删除字符串中的多个字符
print(s.strip('+-'))
s = 'abc:123'
# 删除一个区间的字符
print(s[:3] + s[4:])
替换字符
s = '\tabc\t123\txyz'
# 替换单个字符
print(s.replace('\t',''))
# 替换多个不同字符
import re
s = '\tabc\t123\txyz\ropt\r'
print(re.sub('[\t\r]','',s))

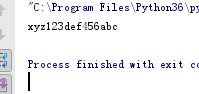
字符串值相互替换
s = 'abc123def456xyz'
a = s.maketrans('abcxyz','xyzabc')
print(s.translate(a))
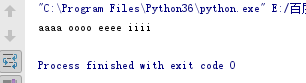
去除 unicode 中的特殊字符
import sys
import unicodedata
s = 'āáǎà ōóǒò ēéěè īíǐì'
remap = {
# ord返回ascii值
ord('\t'): '',
ord('\f'): '',
ord('\r'): None
}
# 去除\t, \f, \r
a = s.translate(remap)
'''
通过使用dict.fromkeys() 方法构造一个字典,每个Unicode 和音符作为键,对于的值全部为None
然后使用unicodedata.normalize() 将原始输入标准化为分解形式字符
sys.maxunicode : 给出最大Unicode代码点的值的整数,即1114111(十六进制的0x10FFFF)。
unicodedata.combining:将分配给字符chr的规范组合类作为整数返回。 如果未定义组合类,则返回0。
'''
cmb_chrs = dict.fromkeys(c for c in range(sys.maxunicode) if unicodedata.combining(chr(c))) #此部分建议拆分开来理解
b = unicodedata.normalize('NFD', a)
'''
调用translate 函数删除所有重音符
'''
print(b.translate(cmb_chrs))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号