游戏引擎客户端代码保护技术的软件系统设计方案
该工程实践项目主要是研究OLLVM的几种代码混淆技术,测试混淆性能,从而写出反混淆的算法。整个系统其实是建立在OLLVM的基础上,而
OLLVM也是在LLVM的基础上做一些可扩展的修改,所以整个系统结构与LLVM的结构是差不多的。
一. 软件系统设计方案
1.1 软件结构特点
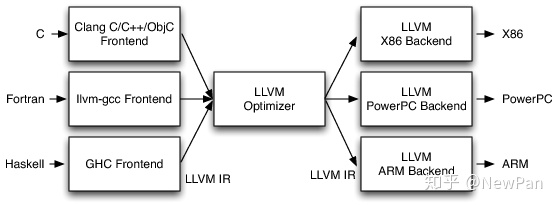
整个系统的架构如下:

前端负责解析源码,检查错误,生成指定语言的抽象语法树(Abstract Syntax Tree)后转换成LLVM IR 交给中间的优化器进行优化,优化后的结果再传给后端生成指定平台的机器码。
这种三段式设计的架构优势是在段落之间定义通用的接口和数据结构,那么就可以无缝地替换每个段。如编译器在优化时使用一种通用的中间码,那么前端可以用任意的可编译语言编写,
只要他们生成出规范地LLVM IR即可。而且后端可以编译成任何目标平台地机器码。如下图所示。
整个三段式架构可以分成下图6个阶段。
- 词法分析。 词法分析将字符序列转换为记号的序列。执行词法分析的程序包括了词法分析器、记号序列化生成器和扫描器,不过扫描器常常作为词法分析器的第一阶段。
- 语法分析。 分析符合一定语法规则的一串符号。它通常会生成一个语法树(或称为AST - Abstract Syntax tree),用于表示记号之间的语法关系。
- 语义分析。 通过语法分析的解析后,这个过程将从源代码中收集必要的语义信息。它通常包括类型检查,或者确保在使用之前声明了变量,这在EBNF范式中是不可能描述的,因此在语法分析阶段不容易检测到。
- 中间表达式(IR)生成。 代码在这个阶段会转换为中间表示式(IR),这是一种中立的语言,与源语言(前端)和机器(后端)无关。
- 优化中间表达式。 IR代码常常会有冗余和死代码的情况出现,而优化器可以处理这些问题以获得更优异的性能。
- 生成目标代码。 最后后端会生成在目标机器上运行的机器码,我们也将其称之为目标代码。
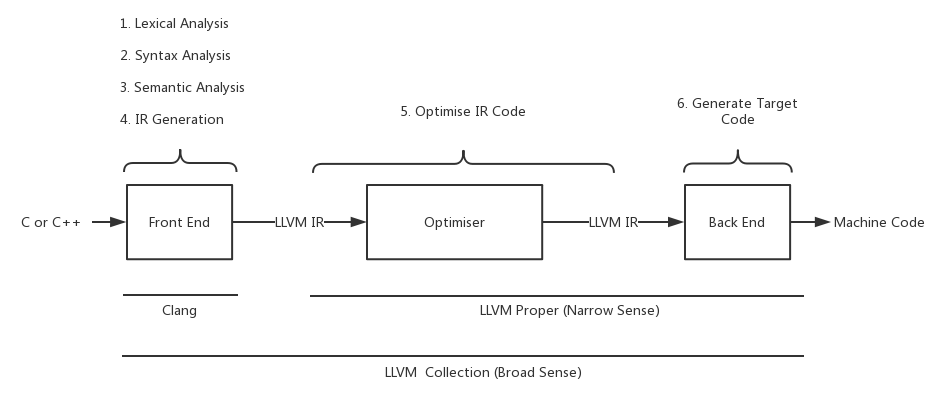
在这种架构设计下,要想把编译器移植到一种新的编程语言,那么只要实现一个新的编译前端即可,已有的优化器和后端可以直接复用。
1.2 接口API
整个LLVM中提供的接口非常之多,我们主要关注的是Pass相关的API接口,几种基本的Pass接口如下如下:
BasicBlockPass类。用于实现本地优化,优化通常每次针对一个基本块或指令运行FunctionPass类。用于全局优化,每次执行一个功能ModulePass类。用于执行任何非结构化的过程间优化RegionPass类。用于对区域地优化LoopPass类。用于执行对循环地优化CallGraphSCCPass类。用于自底向上地遍历函数调用图
我们要做的就是根据我们的需求,编写自己的继承自上面接口类的类。如我们想对函数优化,就可以写一个类,继承自
RegisterPass类模板进行Pass的注册即可。如我们想对函数进行优化,就可以自己写一个继承自FunctionPass的类,并
重写其中的runOnFunction的虚方法,最后用RegisterPass类模板注册我们自定义的Pass即可。
1.3 依赖试图
依赖视图展现了软件模块之间的依赖关系。比如一个软件模块A调用了另一个软件模块B,那么我们说软件模块A直
接依赖软件模块B。如果一个软件模块依赖另一个软件模块产生的数据,那么这两个软件模块也具有一定的依赖关
系。依赖视图在项目计划中有比较典型的应用。比如它能帮助我们找到没有依赖关系的软件模块或子系统,以便独
立开发和测试,同时进一步根据依赖关系确定开发和测试软件模块的先后次序。依赖视图在项目的变更和维护中也
很有价值。比如它能有效帮助我们理清一个软件模块的变更对其他软件模块带来影响范围。

从上图可以看出,由于我们要写的代码位于优化器中,主要就是一个一个的Pass,所以主要依赖于Front End。
1.4 泛化试图
泛化视图展现了软件模块之间的一般化或具体化的关系,典型的例子就是面向对象分析和设计方法中类之间的继承
关系。值得注意的是,采用对象组合替代继承关系,并不会改变类之间的泛化特征。因此泛化是指软件模块之间的一
般化或具体化的关系,不能局限于继承概念的应用。
泛化视图有助于描述软件的抽象层次,从而便于软件的扩展和维护。比如通过对象组合或继承很容易形成新的软件
模块与原有的软件架构兼容
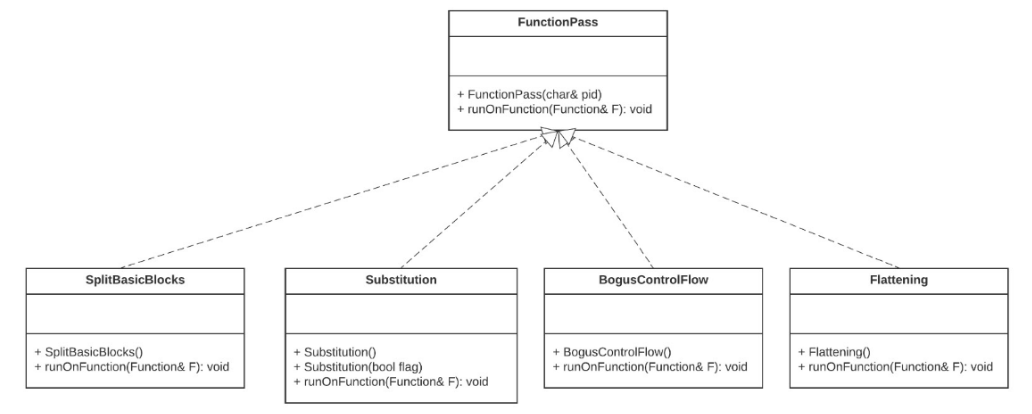
我们要实现的一些功能都要继承自LLVM自身提供的一些Pass接口,上图反映了几个典型的功能都继承自FunctionPass类。我们自己要实现的代码也需要参考这个架构。
1.5 实现视图
实现视图是描述软件架构与源文件之间的映射关系。比如软件架构的静态结构以包图或设计类图的方式来描述,
但是这些包和类都是在哪些目录的哪些源文件中具体实现的呢?一般我们通过目录和源文件的命名来对应软件架构
中的包、类等静态结构单元,这样典型的实现视图就可以由软件项目的源文件目录树来呈现。
实现视图有助于码农在海量源代码文件中找到具体的某个软件单元的实现。实现视图与软件架构的静态结构之间映
射关系越是对应的一致性高,越有利于软件的维护,因此实现视图是一种非常关键的架构视图。
总体的目录文件结构如下:
└── llvm
├── examples 使用LLVM IR和JIT的简单示例
├── include LLVM的lib的公共头文件。其中有三个子目录
├── llvm 所有LLVM特定的头文件和头文件子目录。子目录对应LLVM各个部分:Analysis,CodeGe,Transforms,etc...
├── Support LLVM提供的通用支持工具的lib头文件目录。
├── Config 由cmake配置的头文件。他们包括标准UNIX和C的头文件。源码可以引入这些自动处理的头文件。
├── lib 大部分源文件都在这里。LLVM使得各个tools之间共享源码非常容易。
├── IR 核心LLVM源文件,实现了核心的类如:Instruction和BasicBlock
├── AsmParser 解释汇编语言的源码
├── Bitcode 读写字节码的源码
├── Analysis 各种分析程序的源码,例如:Call-Graphs,Induction-Variables,Natural-Loop-Identification,etc
├── Transforms IR-to-IR 程序转换,例如:主动死代码消除,稀疏有条件常量传播,内联,循环不变码变化,死全局消除...
├── Target 描述目标架构的代码生成。例如:llvm/lib/Target/X86 中存放X86机器的描述
├── CodeGen 代码生成的主要部分:指令选择器,指令调度以及寄存器分配。
├── MC 未知
├── ExecutionEngine 用于直接在JIT解释器中执行字节码的库
├── Support 对应于llvm/include/ADT和llvm/include/Support的头文件
├── projects 这个目录可以存放用户自己用llvm构建的系统
├── test 特征和回归测试,以及其他LLVM基础设施的完整性检查。力求快速并广覆盖的检查环境,并不是面面俱到的。
├── test-suite 一个全面正确性,性能,及基准测试套件,包含大量的不同许可的三方代码.
├── tools 由以上文件构建出来的执行文件,其包含了用户主界面的大部分。
├── bugpoint bugpoint用于优化passes和backends,定位passes或者指令的问题,无论是奔溃还是错误编译。
├── llvm-ar 归档器,对LLVM字节码文件进行归档,可选使用索引来快速查找
├── llvm-as 转换器,从LLVM的IR转换到LLVM字节码
├── llvm-dis 转换器,从LLVM字节码转换到LLVM的IR
├── llvm-link 连接器,将多个LLVM模块链接到单个程序
├── lli LLVM解释器,用于直接执行LLVM字节码(执行速度比较慢)。
├── llc LLVM后端编译器,将LLVM字节码编译成本机汇编代码。
├── opt 将LLVM字节码,应用LLVM一些列转换(命令行定义),并输出结果的字节码。
├── utils LLVM源码的实用程序。有些是构建器的一部分,应为它们是代码生成的一部分。
├── codegen-diff codegen-diff找出LLC和LLI生成代码的不同之处。
├── emacs LLVM汇编文件和TableGen描述文件的Emacs和XEmacs语法高亮。
├── llvmgrep 一个非常高效的基于正则表达式的源文件搜索工具。
├── TableGen 用于生成寄存器信息,指令集描述,以及其他普通的编译器描述文件
├── vim vim高亮语法文件
其中我们重点关注的是我们添加混淆部分的目录文件的结构,,其中头文件位于/include/llvm/Transforms/Obfuscation/, 源代码文件位于/lib/Transforms/Obfuscation/,结构如下
└── Obfuscation
├── BogusControlFlow.cpp 实现虚假控制流pass
├── CMakeLists.txt CMakeList文件
├── CryptoUtils.cpp 实现字符串混淆
├── Flattening.cpp 实现控制流展平
├── SplitBasicBlocks.cpp 实现代码基本块的划分
├── Substitution.cpp 实现指令替换
├── Utils.cpp 一些工具类函数的集合
1.6 核心数据结构设计
整个系统中使用的数据结构相当之多,不仅大量使用了STL,而且自己定义了一堆专门的数据结构,在这无法一一列举。
这里就介绍相对比较核心的CFG(Control Flow Graph)的设计。CFG就是一种表明程序各个块之间跳转关系的一种图,
先用算法将代码分成一个个块,分割的要求如下:
1. Basic blocks are maximal sequences of consecutive instructions with the following properties:
- The flow of control can only enter the basic block through the first instruction in the block
- There are no jumps into the middle of the block
2. Control will leave the block without halting or branching, except possibly at the last instruction in the block.
分割完之后再用线来表示跳转关系,即用图结构表示,如下

这里我简单用C++表示下数据结构
struct CFGNode {
int inc_start; // 指令开始编号
int inc_end; // 指令结束编号
bool exit; // 是否退出
CFGNode * fp; // 可能跳转的第一个块
CFGNode * sp; // 可能跳转的第二个块
}
struct CFG {
int num; // 总代码块数量
CFGNode* Blocks; // 代码块数组指针
int start_no; // 开始代码块的编号
}
二. 软件系统运行环境和技术选型说明
2.1 运行环境
从技术上来说没有运行环境限制,可以移植到多平台使用,
推荐硬件:
- 操作系统: Windows10 64位操作系统
- 处理器:Inter(R) Core(TM) i5-8250U CPU @1.60G Hz
- 内存: 8GB
- 显卡:NVIDIA GeForce MX150
- 固态硬盘: 512G
开发所需软件:
- visual studio 2017 v15.6以上
- CMake
- IDA Pro v7.0
开发所需软件(移动端游戏代码混淆):
- visual studio 2017 v15.6以上
- visual studio 2019 (安装时选择c++游戏开发,c++桌面开发,Unreal Engine安装程序)
- CMake
- Unreal Engine v25.4往上
- Android SDK
- Android NDK r21b
- JDK
- IDA Pro v7.0
2.2 技术选型说明
对于本系统来说,目标是代码混淆,之所以选择OLLVM,是因为它是一个2010年就开源的一个混淆库,网上的资料分析等相对较多,易于上手且做起来相对容易。
因为LLVM和OLLVM使用的都是C++,所以本项目也使用C++进行开发。
三. 系统概念原型的核心工作机制
概念原型就是用例+数据模型。具体在本工程实践项目中就是编译器接受用户的代码,中间调用代码混淆的函数去混淆代码,最后输出混淆后的代码。
具体点来说,就是在优化器中插入我们自己写的混淆pass,这些pass必须继承自LLVM提供的Pass接口类,通过它们对代码进行混淆,最后输出混淆后的代码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号