

静态库和动态库的制作与使用 & C程序常量变量的地址分配
GCC背后的故事 & C程序常量变量的地址分配
实验任务
- 静态库和动态库的制作和使用。
- Linux下GCC的常用命令和使用方法。
- C程序中的变量在Ubuntu和STM32中的区别。
实验准备
- Ubuntu 20.04
- Keil5
实验过程
1. 静态库和动态库的制作和使用
-
编辑生成示例程序 hello.h、hello.c 和 main.c
-
先创建一个作业目录,保存本次练习的文件。
mkdir test1 cd test1 -
使用vim编辑生成3个文件:hello.h、hello.c 和 main.c。
hello.h
#ifndef HELLO_H #define HELLO_H void hello(const char *name); #endif //HELLO_Hhello.c
#include <stdio.h> void hello(const char *name) { printf("Hello %s!\n", name); }main.c
#include "hello.h" int main() { hello("everyone"); return 0; }
-
-
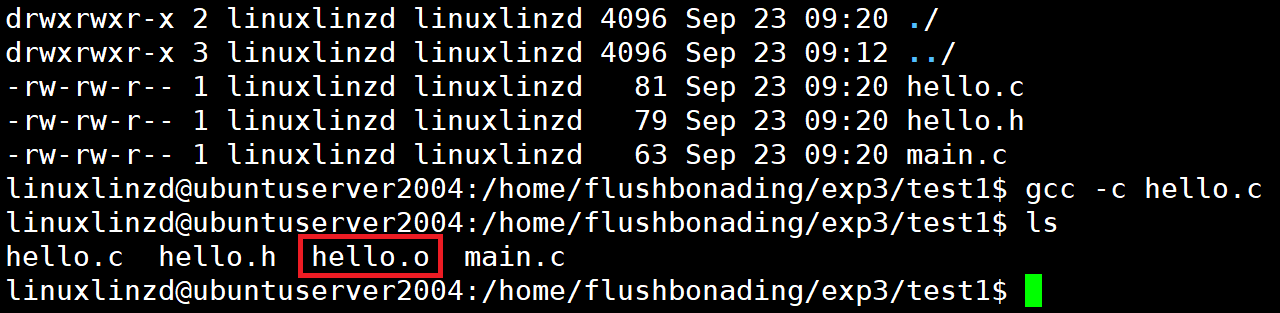
将 hello.c 编译成 .o 文件
-
在终端输入如下gcc命令,得到 hello.o 文件。
gcc -c hello.c -
运行 ls 命令查看是否生成了 hello.o 文件。
![]()
-
-
由 .o 文件创建静态库
-
静态库文件名的命名规范是以 lib 为前缀,紧接着跟静态库名,扩展名为 .a 。
例如:我们将创建的静态库命名为 myhello,则静态库文件名就是 libmyhello.a 。
创建静态库使用 ar 命令。
在终端下键入以下命令创建静态库文件 libmyhello.a 。
ar -crv libmyhello.a hello.o -
运行 ls 命令查看是否生成了 libmyhello.a 文件。
![]()
-
-
在程序中使用静态库
在程序 main.c 中,我们包含了静态库的头文件 hello.h,然后在主程序 main 中直接调用公用函数 hello。
下面先生成目标程序 hello,然后运行 hello 程序查看运行结果。
-
方法一
gcc -o hello main.c -L. -lmyhello -
方法二
gcc main.c libmyhello.a -o hello -
方法三
先生成 main.o:
gcc -c main.c再生成可执行文件:
gcc -o hello main.o libmyhello.a -
运行可执行文件
./hello效果如下:
![]()
-
-
.o文件创建动态库文件
动态库文件名命名规范和静态库文件名命名规范类似,也是在动态库名增加前缀 lib,但其文件扩展名为 .so 。
例如:我们将创建的动态库名为 myhello,则动态库文件名就是 libmyhello.so 。
-
在终端输入以下命令得到动态库文件 libmyhello.so 。
gcc -shared -fPIC -o libmyhello.so hello.o -
使用 ls 命令看看动态库文件是否生成。
![]()
-
-
在程序中使用动态库
提示:程序在运行时, 会在/usr/lib 和/lib 等目录中查找需要的动态库文件。若找到,则载入动态库,否则将提示找不到动态库文件。
-
因此,在使用动态库之前,我们先将文件 libmyhello.so 复制到目录 /usr/lib 中(如果提示没有权限,改成root用户即可)。
mv libmyhello.so /usr/lib -
复制完成,再编译运行。
gcc -o hello main.c -L. -lmyhello ./hello -
运行结果如下。
![]()
-




2. 第一次作业改编
在第一次作业(点这里查看第一次作业)的基础上进行改编,引入静态库和动态库的操作,生成相关的可执行文件。
-
x2y函数实现
在x2x函数的基础上,再实现一个x2y函数,负责打印一句话:"Calculate complete!!!",在x2x函数执行完毕之后调用这个函数。
创建 sub2.h 和 sub2.c ,sub2.h 中负责声明 x2y 函数,sub2.c 中负责 该函数的具体实现。
sub2.h
#include<stdio.h> void x2y();sub2.c
#include"sub2.h" void x2y() { printf("%s\n", "Calculate complete!!!"); } -
生成 .o 目标文件
用 gcc 分别将 sub1.c,sub2.c,main1.c 编译为3个 .o 目标文件。
gcc -c sub1.c gcc -c sub2.c gcc -c main1.c -
生成静态库文件并运行
-
将x2x、x2y目标文件用 ar工具生成 libmysub.a 静态库文件。
ar -crv libmysub.a sub1.o sub2.o![]()
-
gcc 编译生成可执行文件。
用 gcc 将 main1 函数的目标文件与 libmysub.a 静态库文件进行链接,生成最终的可执行程序。
gcc main1.c libmysub.a -o main1![]()
-
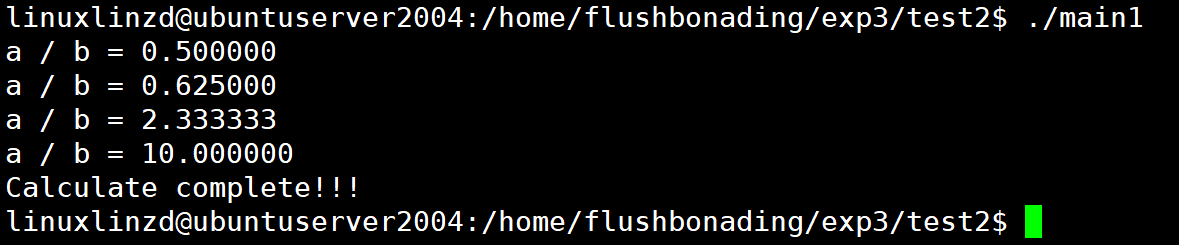
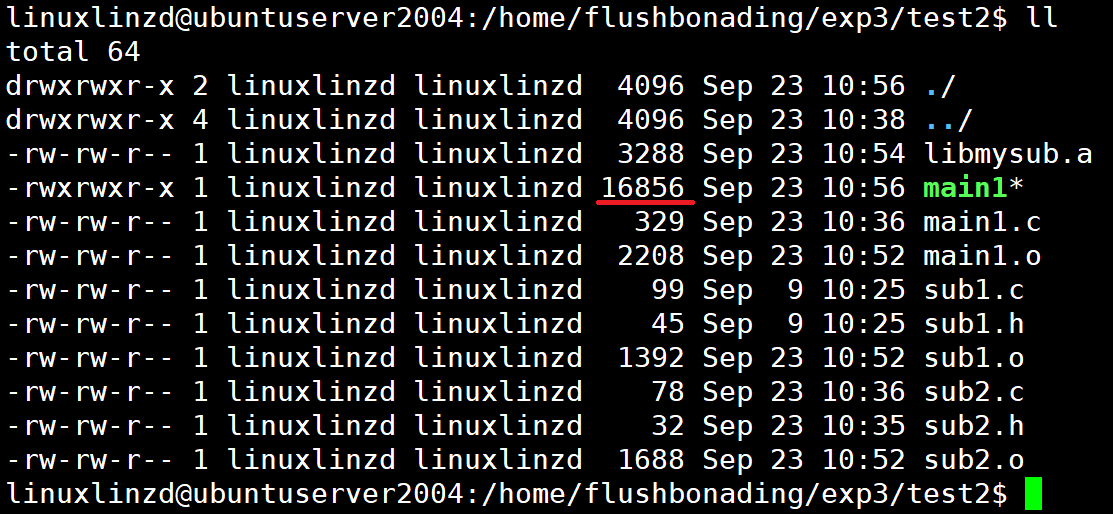
运行并记录文件大小。
-
运行 main1 可执行文件
./main1![]()
-
查看可执行文件大小:16856字节,指令:
ll![]()
-
-
-
生成动态库文件并运行
-
将 sub1.o 和 sub2.o 用 ar 工具生成 libmysub.so 动态库文件。
gcc -shared -fPIC -o libmysub.so sub1.o sub2.o![]()
-
gcc 编译生成可执行文件。
同样,在编译之前,先将生成的动态库复制到目录 /usr/lib 中。
mv libmysub.so /usr/lib -
复制完成,编译运行。
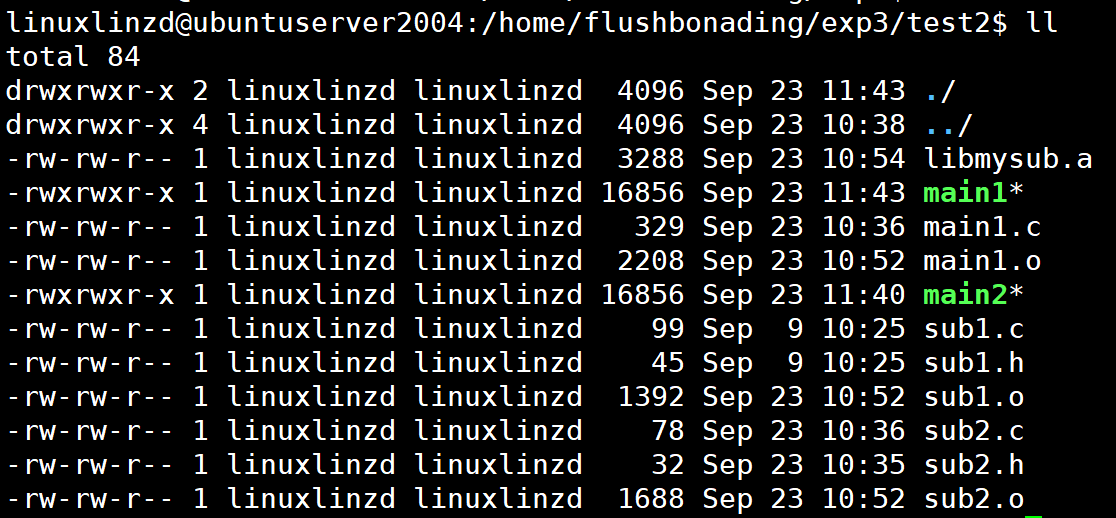
gcc -o main2 main1.c -L. -lmysub ./main2![]()
-
记录文件大小:16856字节。
![]()
-




3. GCC的常用命令和使用方法
-
简单编译
编写示例程序 test.c 。
#include <stdio.h> int main(void) { printf("Hello World!\n"); return 0; }该程序一步到位的编译指令是:
gcc test.c -o test实质上,上述编译过程是分为四个阶段进行的,即预处理(也称预编译,Preprocessing)、编译 (Compilation)、汇编 (Assembly)和连接(Linking)。
-
预处理
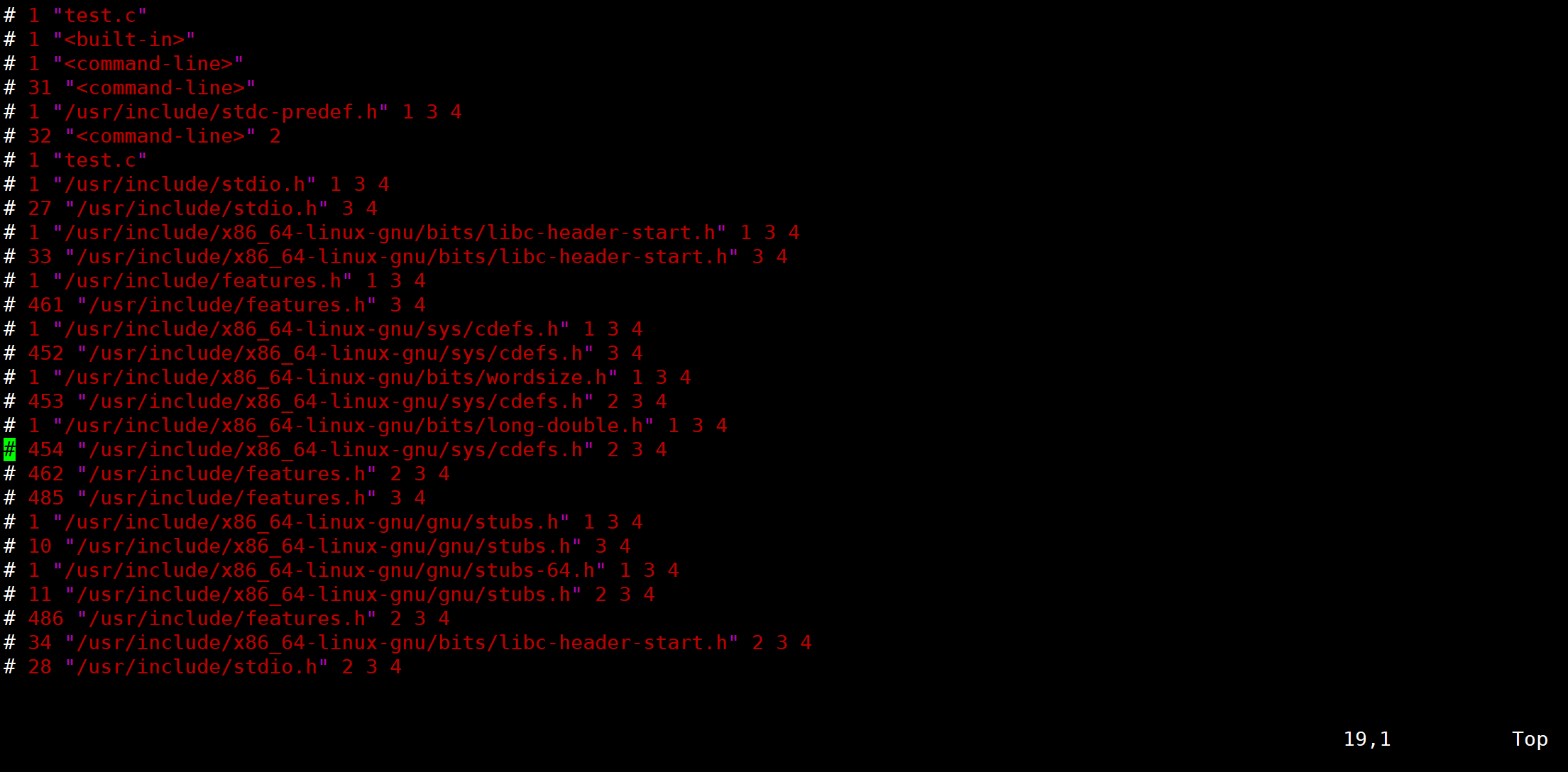
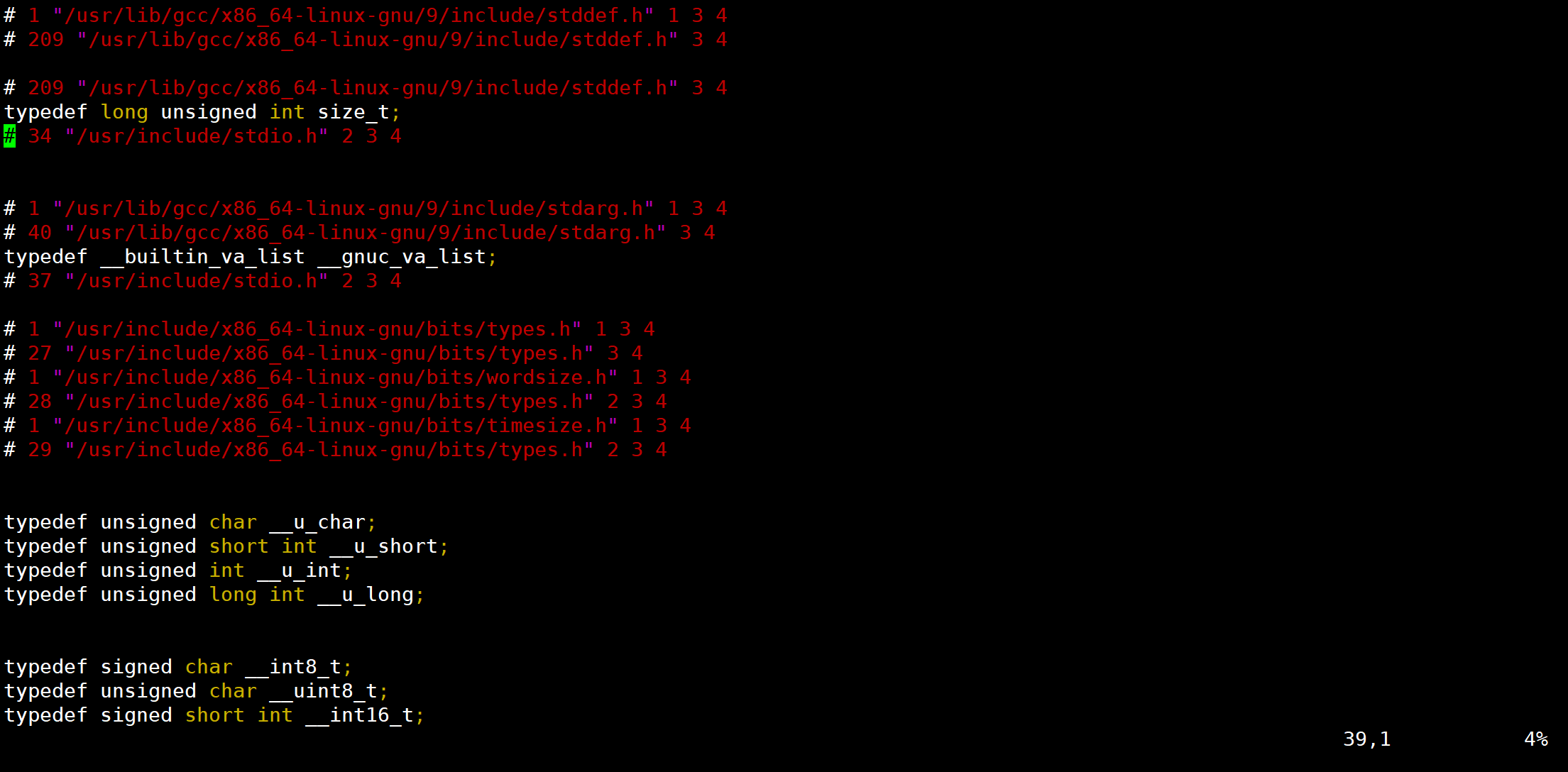
gcc -E test.c -o test.i 或 gcc -E test.ctest.i 文件中存放着 test.c 经预处理之后的代码。
gcc 的-E 选项,可以让编译器在预处理后停止,并输出预处理结果。在本例中,预处理结果就是将 stdio.h 文件中的内容插入到 test.c 中了。
![]()
![]()
-
编译为汇编代码
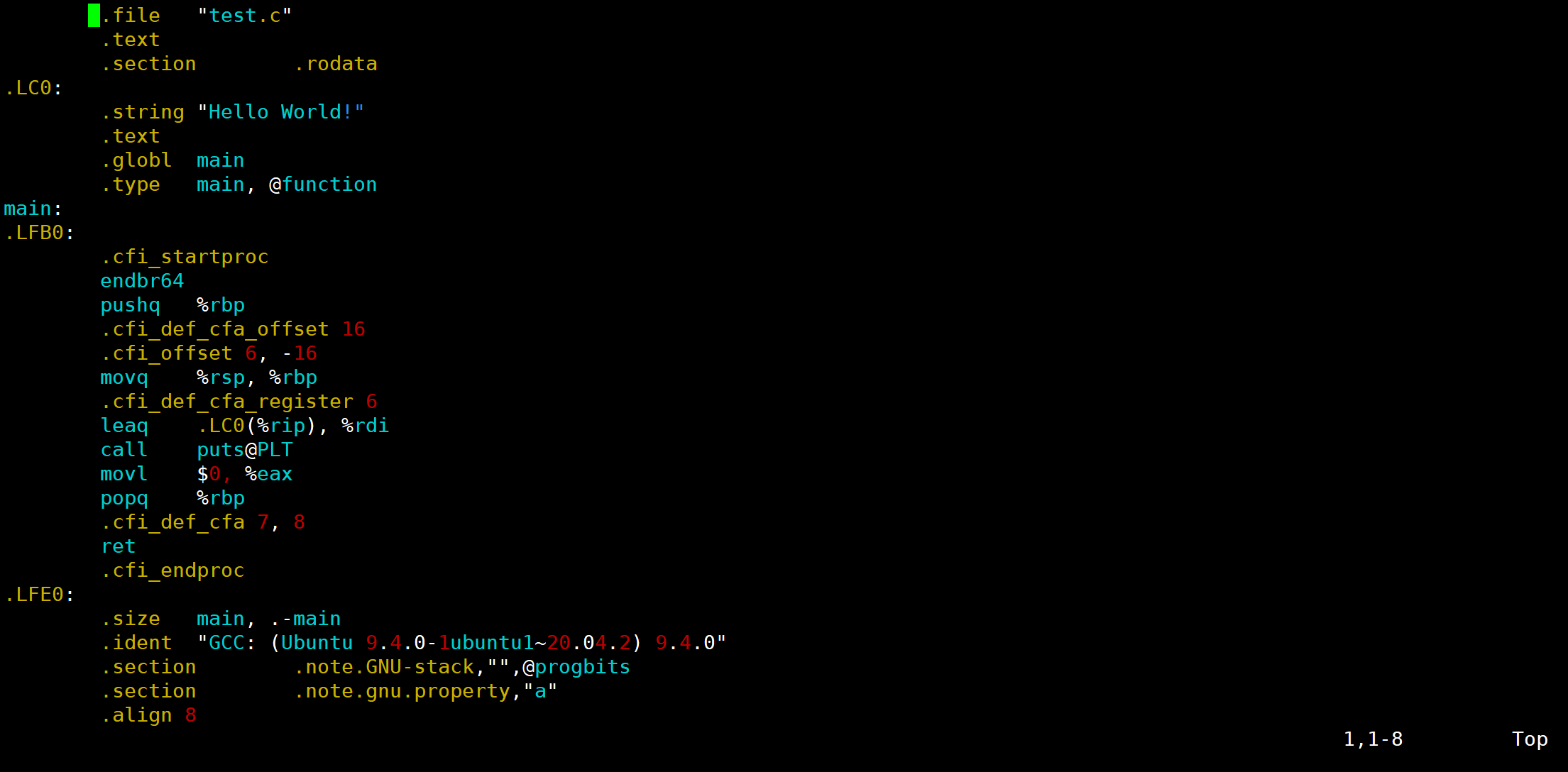
预处理之后,可直接对生成的 test.i 文件编译,生成汇编代码:
gcc -S test.i -o test.sgcc 的 -S 选项,表示在程序编译期间,在生成汇编代码后,停止,-o 输出汇编代码文件。
![]()
gcc 的 -S 选项,表示在程序编译期间,在生成汇编代码后,停止,-o 输出汇编代码文件。
-
汇编
对于上一小节中生成的汇编代码文件 test.s,gas 汇编器负责将其编译为目标文件,如下:
gcc -c test.s -o test.o -
连接
gcc 连接器是 gas 提供的,负责将程序的目标文件与所需的所有附加的目标文件连接起来,最终生成可执行文件。
附加的目标文件包括静态连接库和动态连接库。
对于上一步生成的 test.o,将其与C标准输入输出库进行连接,最终生成程序 test。
gcc test.o -o test最后,在终端执行
./test,即可打印 “Hello World!” 。
-
-
多文件的编译
假设有一个由 test1.c 和 test2.c 两个源文件组成的程序,为了对它们进行编译,并最终生成可执行程序 test,可以使用下面这条命令:
gcc test1.c test2.c -o test -
检错
-
-pedantic 选项能够帮助程序员发现一些不符合 ANSI/ISO C 标准的代码,但不是全部,事实上只有 ANSI/ISO C 语言标准中要求进行编译器诊断的 那些情况,才有可能被 GCC 发现并提出警告。
gcc -pedantic illcode.c -o illcode -
使用 -Wall 能够使 GCC 产生尽可能多的警告信息。
gcc -Wall illcode.c -o illcode -
在编译程序时带上 -Werror 选项,那 么 GCC 会在所有产生警告的地方停止编译,迫使程序员对自己的代码进行修改。
gcc -Werror test.c -o test
-
-
库文件连接
开发软件时,都需要借助许多函数库的支持才能够完成相应的功能。
Linux 下的大多数函数都默认将头文件放到 /usr/include/ 目录下,而库文件则放到 /usr/lib/ 目录下。
但也有的时候,我们要用的库不在这些目录下,所以 GCC 在编译时必须用自己 的办法来查找所需要的头文件和库文件。
例如:
我们的程序 test.c 是在 linux 上使用 c 连接 mysql,这个时候我们需要去 mysql 官网下载 MySQL Connectors 的 C 库,下载下来解压之后,有一个 include 文件夹,里面包含 mysql connectors 的头 文件,还有一个 lib 文件夹,里面包含二进制 so 文件 libmysqlclient.so 。
其中 inclulde 文件夹的路径是 /usr/dev/mysql/include ,lib 文件夹是 /usr/dev/mysql/lib 。
-
编译成可执行文件
先我们要进行编译 test.c 为目标文件,这个时候需要执行如下指令:
gcc –c –I /usr/dev/mysql/include test.c –o test.o -
链接
把所有目标文件链接成可执行文件:
gcc –L /usr/dev/mysql/lib –lmysqlclient test.o –o test -
强制链接时使用静态链接库
默认情况下, GCC 在链接时优先使用动态链接库,只有当动态链接库不存在时才考虑使用静态链接库,如果需要的话可以在编译时加上 -static 选项,强制使用静态链接库。 在/usr/dev/mysql/lib 目录下有链接时所需要的库文件 libmysqlclient.so 和 libmysqlclient.a,为了让 GCC 在链接时只用到静态链接库,可以使用下面的命令:
gcc –L /usr/dev/mysql/lib –static –lmysqlclient test.o –o test
-
-
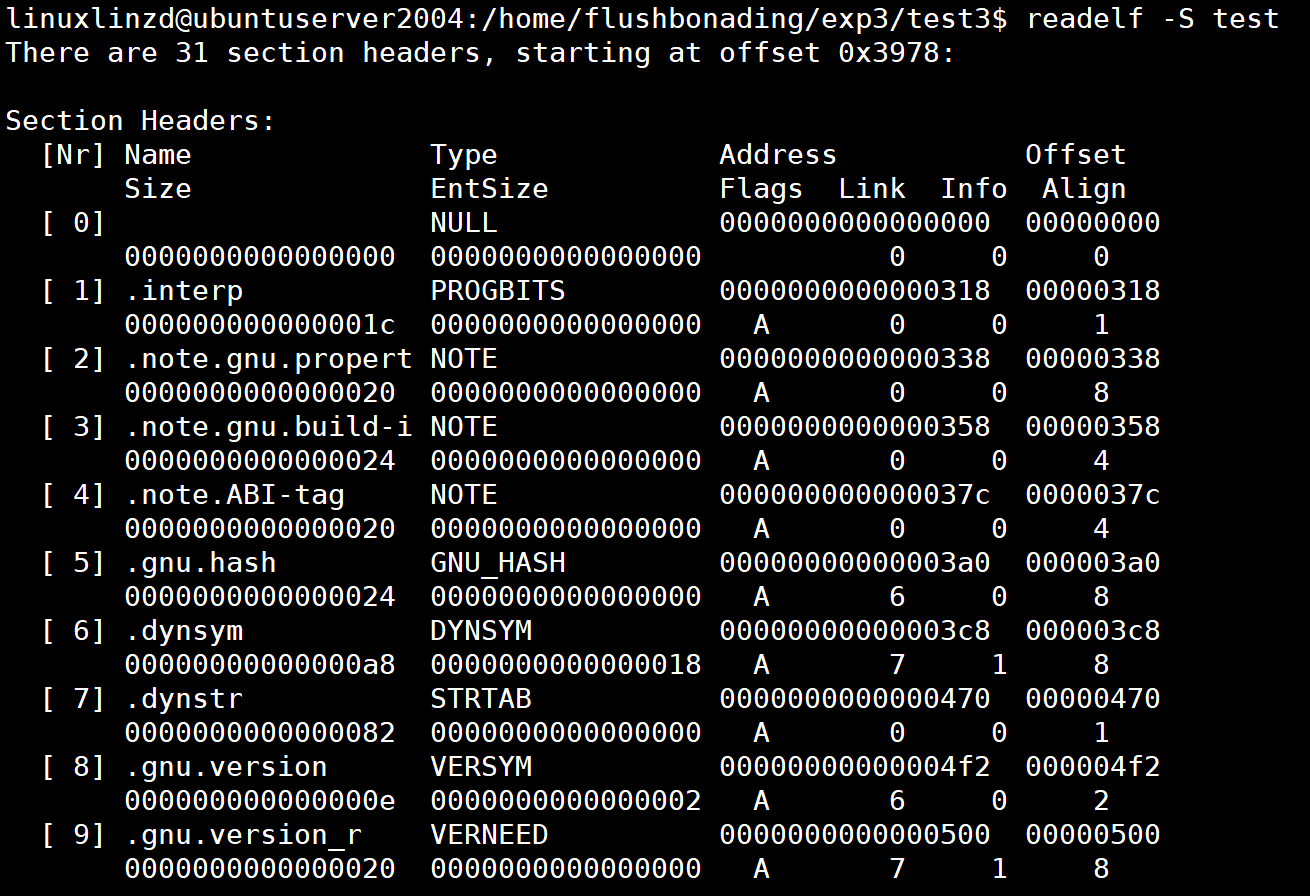
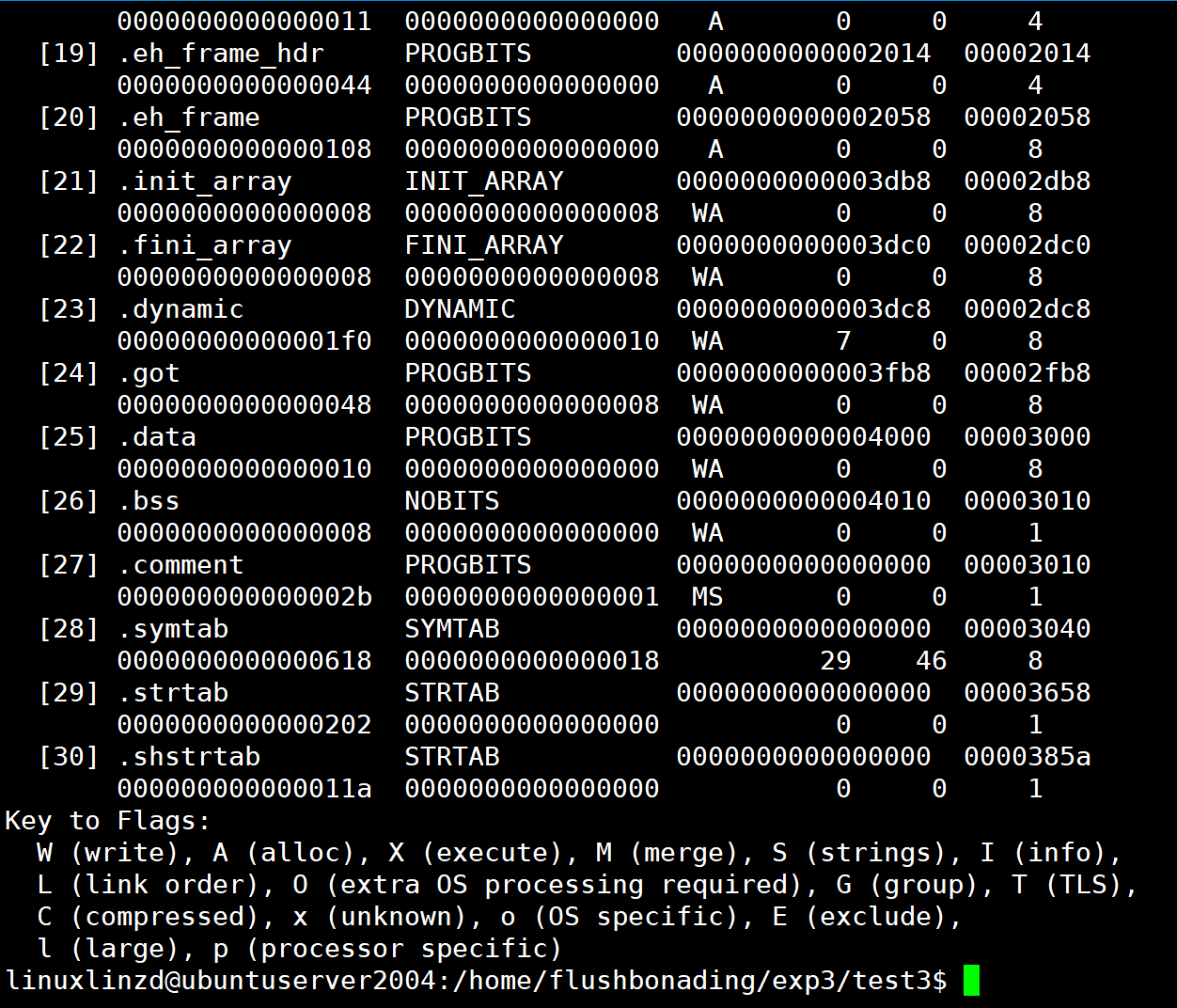
分析 ELF 文件
指令:
readelf -S test![]()
![]()
-
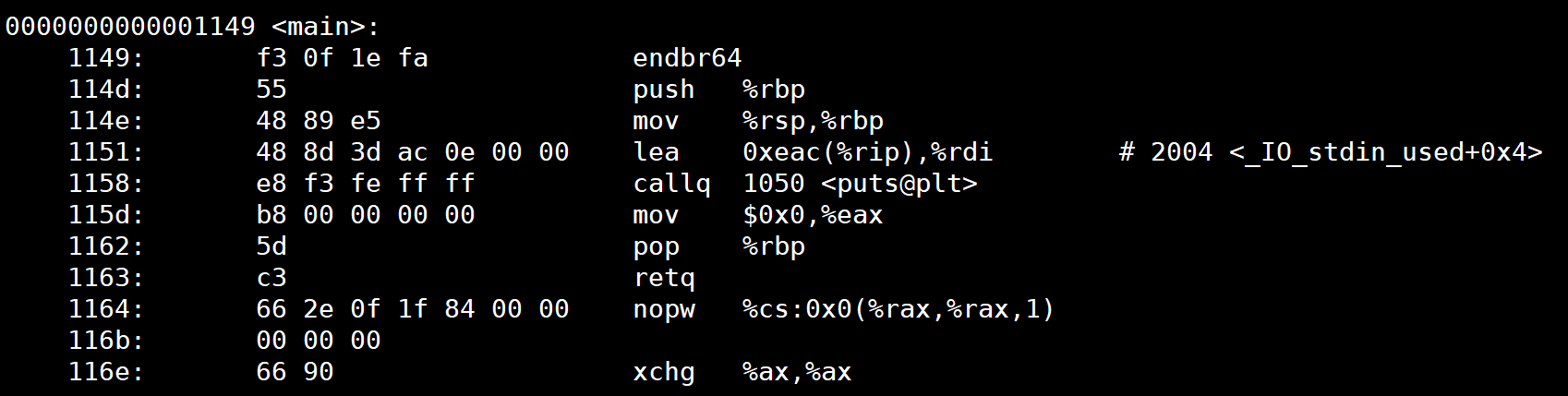
反汇编 ELF
由于 ELF 文件无法被当做普通文本文件打开,如果希望直接查看一个 ELF 文件包 含的指令和数据,需要使用反汇编的方法。
-
使用 objdump -D 对其进行反汇编如下:
objdump -D test![]()
-
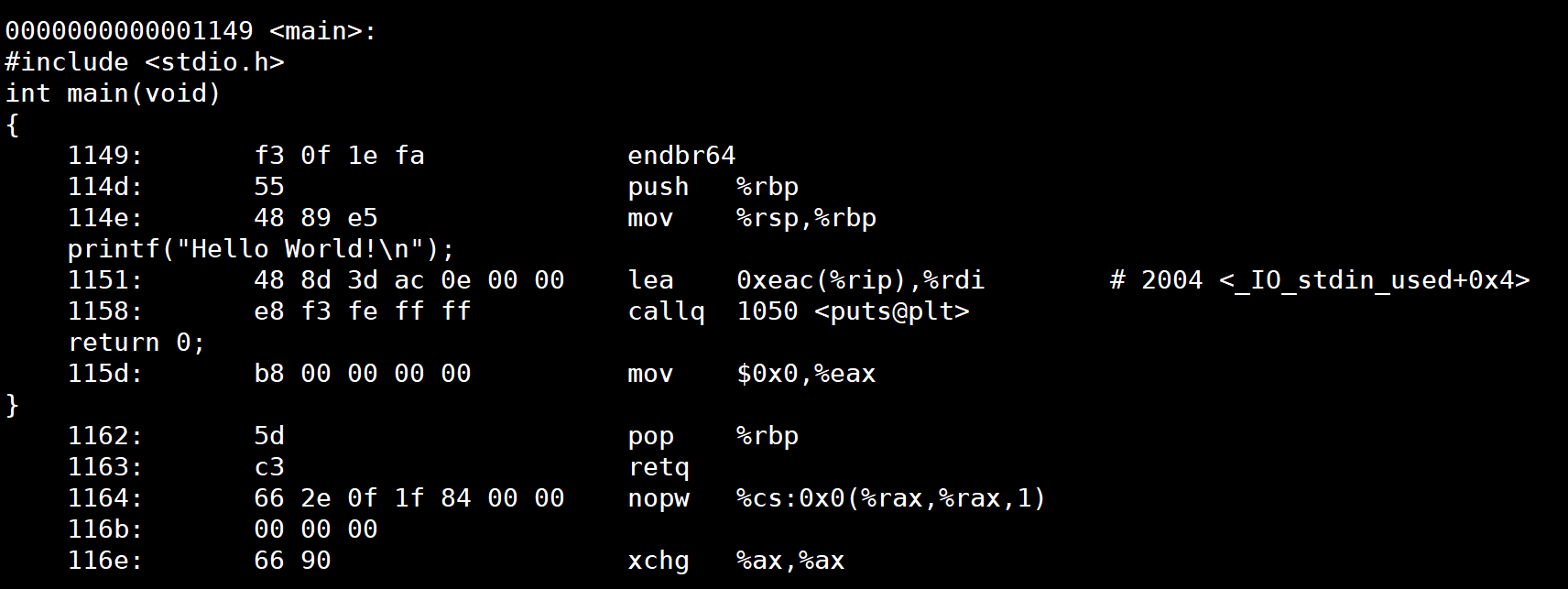
使用 objdump -S 将其反汇编并且将其 C 语言源代码混合显示出来
gcc -o test -g test.c //要加上-g 选项 objdump -S test![]()
-
4. 基于Ubuntu和STM32的C程序的内存分配问题
-
C程序的内存分配问题
C语言中的不同内存区域(或内存段)用于存储不同类型的数据和程序代码,每个区域都具有不同的特性和用途。以下是对C语言中的栈区、堆区、全局区、文字常量区和程序代码区的介绍:
-
栈区(Stack):
-
特性: 栈区是用于存储函数调用的局部变量和函数调用的上下文信息的内存区域。它采用后进先出(LIFO)的方式组织数据。
-
生命周期: 局部变量的生命周期与函数调用的生命周期相对应。当函数被调用时,局部变量被分配到栈上;当函数返回时,局部变量被销毁。
-
内存管理: 栈内存的分配和释放是自动进行的,由编译器生成的代码负责管理。不需要程序员显式地分配或释放栈内存。
-
-
堆区(Heap):
-
特性: 堆区是用于存储动态分配的内存的内存区域。它的大小通常比栈大得多,且更灵活。
-
生命周期: 动态分配的内存在程序员显式释放之前一直存在。如果不释放,可能会导致内存泄漏。
-
内存管理: 堆内存的分配和释放需要程序员显式调用函数,如
malloc()、free()或calloc()来进行。程序员负责管理堆内存的分配和释放。
-
-
全局区(Global Area):
-
特性: 全局区用于存储全局变量和静态变量。这些变量通常具有全局作用域,可以在程序的任何地方访问。
-
生命周期: 全局变量和静态变量的生命周期从程序的启动到终止,它们在整个程序执行期间都存在。
-
内存管理: 全局变量和静态变量的内存分配由程序的内存管理系统负责,在程序启动时分配,在程序结束时释放。
-
-
文字常量区(Text Constants):
-
特性: 文字常量区用于存储字符串文字常量,例如
"Hello, World!"。这些文字常量是不可修改的。 -
生命周期: 文字常量在程序的整个生命周期内都存在,因为它们通常嵌入在可执行程序的代码中。
-
内存管理: 文字常量通常是只读的,不允许修改。程序中的文字常量会被存储在该区域。
-
-
程序代码区(Code Section):
-
特性: 程序代码区包含了程序的机器指令和可执行代码。这些指令被CPU执行以执行程序的功能。
-
生命周期: 程序代码在程序运行时加载到内存中,并在程序结束时卸载。它的生命周期与程序的执行周期相关。
-
内存管理: 程序代码区的内容由编译器生成,通常是只读的,不允许修改。
-
这些不同的内存区域在C语言中有不同的用途和生命周期,了解它们有助于编写高效、可维护和安全的C代码。根据变量的生命周期和作用域,程序员可以选择在栈区、堆区或全局区中存储数据。程序代码区和文字常量区通常由编译器和操作系统管理,程序员不需要显式干预。
-
-
Ubuntu,STM32开发板编程,输出信息进行验证
编写如下c语言代码:
#include <stdio.h> #include <stdlib.h> //定义全局变量 int init_global_a = 1; int uninit_global_a; static int inits_global_b = 2; static int uninits_global_b; void output(int a) { printf("hello"); printf("%d",a); printf("\n"); } int main( ) { //定义局部变量 int a=2; static int inits_local_c=2, uninits_local_c; int init_local_d = 1; output(a); char *p; char str[10] = "lyy"; //定义常量字符串 char *var1 = "1234567890"; char *var2 = "qwertyuiop"; //动态分配 int *p1=malloc(4); int *p2=malloc(4); //释放 free(p1); free(p2); printf("栈区-变量地址\n"); printf(" a:%p\n", &a); printf(" init_local_d:%p\n", &init_local_d); printf(" p:%p\n", &p); printf(" str:%p\n", str); printf("\n堆区-动态申请地址\n"); printf(" %p\n", p1); printf(" %p\n", p2); printf("\n全局区-全局变量和静态变量\n"); printf("\n.bss段\n"); printf("全局外部无初值 uninit_global_a:%p\n", &uninit_global_a); printf("静态外部无初值 uninits_global_b:%p\n", &uninits_global_b); printf("静态内部无初值 uninits_local_c:%p\n", &uninits_local_c); printf("\n.data段\n"); printf("全局外部有初值 init_global_a:%p\n", &init_global_a); printf("静态外部有初值 inits_global_b:%p\n", &inits_global_b); printf("静态内部有初值 inits_local_c:%p\n", &inits_local_c); printf("\n文字常量区\n"); printf("文字常量地址 :%p\n",var1); printf("文字常量地址 :%p\n",var2); printf("\n代码区\n"); printf("程序区地址 :%p\n",&main); printf("函数地址 :%p\n",&output); return 0; }-
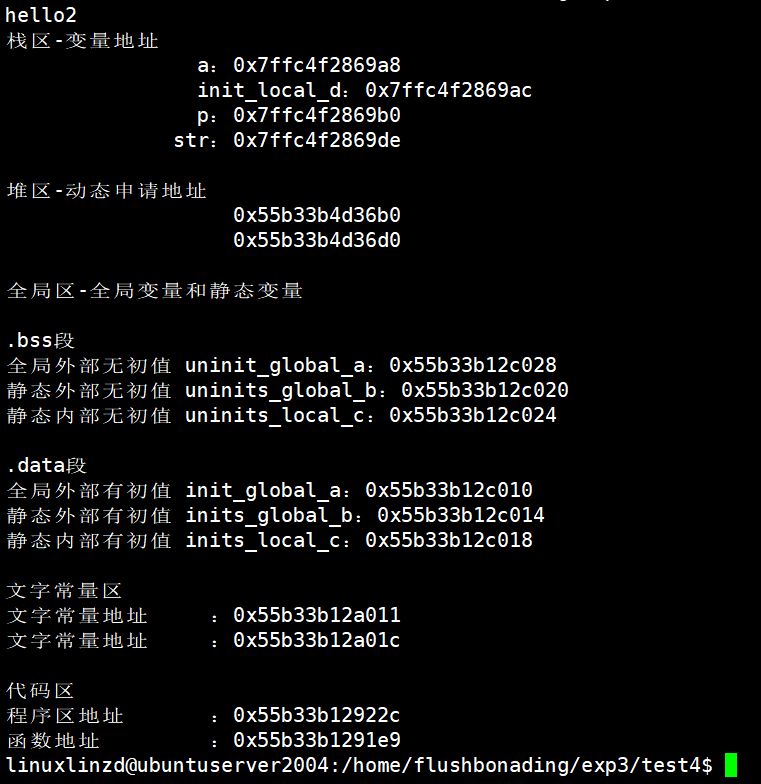
Ubuntu上运行
![]()
-
STM32上运行
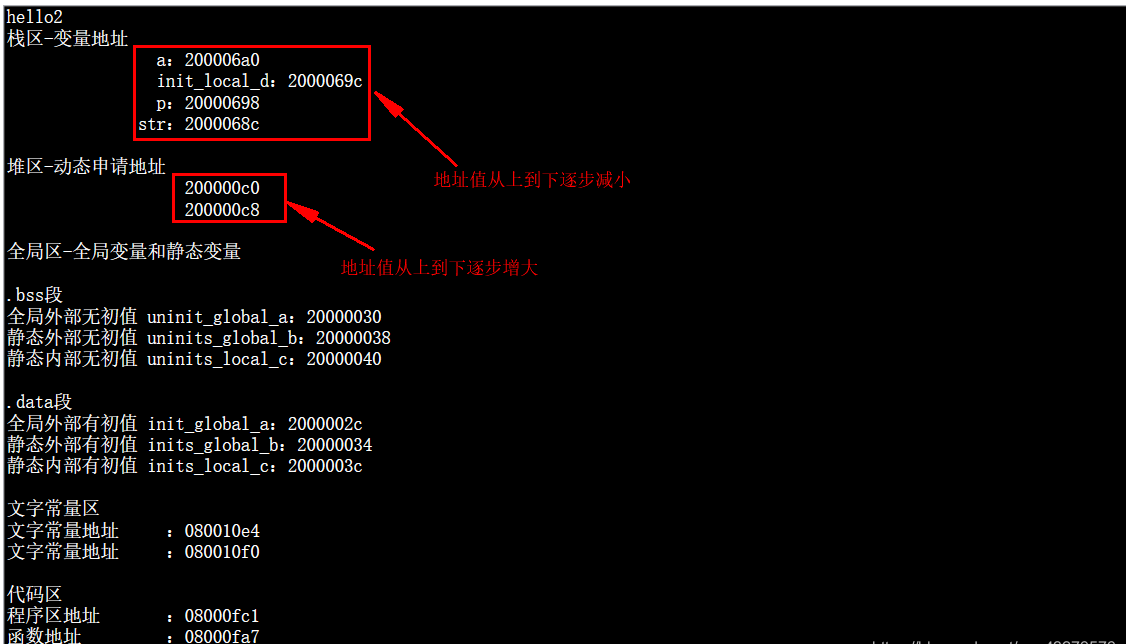
![]()
-
总结
通过运行结果可以发现,Ubuntu在栈区和堆区的地址值都是从上到下增长的,树莓派和stm32的栈区的地址值是从上到下减小的,堆区则是从上到下增长的。从每个区来看,地址值是从上到下逐步减小的,即栈区的地址是高地址,代码区的地址是处于低地址。
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号