dp递推 口胡记录
[SHOI2013] 超级跳马
\(tag\):矩阵乘法,前缀和
暴力\(dp\)很显然,设\(f_{i,j}\)为从\((1,1)\)跳到\((i,j)\)的方案数,那么有$f_{i,j}= \sum \limits _{j-(2k+1)>0}f _{i/i+1/i-1,j-(2k+1)} $
发现这个东西其实是一直由前面奇偶性相同的一段转移过来的,因此考虑前缀和优化
设\(s_{i,j}=\sum \limits _{j-2k>0} f_{i,j-2k}\),那么由定义有\(s_{i,j}=s_{i,j-2}+f_{i,j}\),然后我们再考虑\(f\)怎么由\(s\)转移而来,不难发现\(f_{i,j}=s_{i-1,j-1}+s_{i,j-1}+s_{i+1,j-1}\),联立两式有\(s_{i,j}=s_{i,j-2}+s_{i,j-1}+s_{i-1,j}+s_{i+1,j-1}\)。
然后这个前缀和显然可以矩乘转移。
[JLOI2015] 有意义的字符串
不看题解连矩乘都想不到,/kk
发现\(\frac{b+ \sqrt{d}}{2}\)的形式和一元二次方程求根公式很像,进过构造可以发现它是方程\(x^2-bx+\frac{b^2-d}{4}=0\)的一个解。
移项后两边同时乘\(x^{n-2}\)有\(x^n=bx^{n-1}-\frac{b^2-d}{4}x^{n-2}\)。
发现这个已经形成了矩乘形式的递推关系,但是初始\(\frac{b+ \sqrt{d}}{2}\)是小数,不方便进行取模。
所以考虑构造\(f(x)=(\frac{b+ \sqrt{d}}{2})^x+(\frac{b- \sqrt{d}}{2})^x\),将两个根\(x1,x2\)带入后两式相加发现有\(f(i)=bf(i-1)-\frac{b^2-d}{4}f(i-2)\),并且有\(f(0),f(1),b,\frac{b^2-d}{4}\)都为整数。
因此可以直接矩乘计算出\(f(n)\),再考虑减去\((\frac{b- \sqrt{d}}{2})^n\)的贡献,发现这东西 \(\in \left\{-1,1 \right\}\)分类讨论\(n\)的奇偶性判断答案是否减一即可。
注意用__int128或者龟速乘。
[ABC219H] Candles
首先有经典的关灯模型,显然每次关灯都是在已选的区间向左或向右拓展一格。那么设\(dp_{l,r,t,0/1}\)为已选区间为\([l,r]\) ,时间为 \(t\) ,在 \([l,r]\) 的左/右端点的蜡烛长度最大值。
但是时间这一维很大,考虑优化,一种比较套路的想法是先将所有蜡烛熄灭,然后时间倒流点燃,对于每个时刻,答案会损失点燃的长度非负蜡烛数。
因此每个蜡烛的贡献为\(\max(0, a_i - t)\),这个式子不好维护。因为存在某些蜡烛最终贡献为0,考虑只记录有效的点。具体来说,设\(dp_{l,r,k,0/1}\),其中\(l,r,0/1\)与前文的定义相同,\(k\)表示\([l,r]\)区间外有\(k\)个点有效,会对答案造成贡献。然后就很好做了。
时间复杂度\(O(n^3)\)。
点击查看代码
#include <bits/stdc++.h>
#define ll long long
const int MAXN = 305;
ll dp[MAXN][MAXN][MAXN][2];
void solve() {
int n;
std::cin >> n;
std::vector <std::pair<int, int> > a(n + 1);
for (int i = 0; i < n; i++) {
std::cin >> a[i].first >> a[i].second;
}
a[n] = std::make_pair(0, 0);
std::sort(a.begin(), a.end());
int beg = -1;
for (int i = 0; i < a.size(); i++) {
if (a[i].second == 0) {
beg = i;
break;
}
}
const ll INF = 1e15;
for (int i = 0 ; i <= n; i++) {
for (int j = 0; j <= n; j++) {
for (int k = 0; k <= n; k++) {
dp[i][j][k][0] = dp[i][j][k][1] = -INF;
}
}
}
for (int i = 0; i <= n; i++) {
dp[beg][beg][i][0] = dp[beg][beg][i][1] = 0;
}
for (int len = 2; len <= n + 1; len++) {
for (int l = 0; l <= n; l++) {
int r = l + len - 1;
if (r > n) break;
for (int k = 0; k <= n; k++) {
ll x1 = -INF, x2 = -INF;
x1 = std::max(dp[l + 1][r][k][0] - 1ll * (a[l + 1].first - a[l].first) * k, dp[l + 1][r][k][1] - 1ll * (a[r].first - a[l].first) * k);
if (k != n) x2 = std::max(dp[l + 1][r][k + 1][0] - 1ll * (a[l + 1].first - a[l].first) * (k + 1) + a[l].second, dp[l + 1][r][k + 1][1] - 1ll * (a[r].first - a[l].first) * (k + 1) + a[l].second);
dp[l][r][k][0] = std::max(x1, x2);
x1 = std::max(dp[l][r - 1][k][0] - 1ll * (a[r].first - a[l].first) * k, dp[l][r - 1][k][1] - 1ll * (a[r].first - a[r - 1].first) * k);
if (k != n) x2 = std::max(dp[l][r - 1][k + 1][0] - 1ll * (a[r].first - a[l].first) * (k + 1) + a[r].second, dp[l][r - 1][k + 1][1] - 1ll * (a[r].first - a[r - 1].first) * (k + 1) + a[r].second);
dp[l][r][k][1] = std::max(x1, x2);
}
}
}
ll ans = -INF;
for (int l = 0; l <= n; l++) {
for (int r = l; r <= n; r++) {
for (int k = 0; k <= n; k++) {
ans = std::max(ans, std::max(dp[l][r][k][0], dp[l][r][k][1]));
}
}
}
std::cout << ans << "\n";
}
int main() {
std::ios::sync_with_stdio(0);
std::cin.tie(0);
std::cout.tie(0);
int t = 1;
while (t--) {
solve();
}
return 0;
}
[AGC012E] Camel and Oases
首先由于每次跳跃时\(v\)的值都会除以2,所以只有\(O(\log n)\)个\(v\)值,不难想到固定一个\(v\)的值,可以算出每个点能向左/右拓展到的最远点,分别记为\(l_i, r_i\)。
然后发现如果我们将每个固定的\(v\)形成的若干个区间的集合看成一层,那么原问题等价于对于每个\(i\)在除了\(v'=v\)这一层中之后的每一层都选恰好一个区间,能否使得它们的并集为\([1,n]\),简称能为可达
那么显然如果\(i\)可达\([1,n]\),就有从\(1\)开始的前缀和从\(n\)开始的后缀能够覆盖\(i\)所在区间。考虑设\(dpl_{mask}\)为在状态为\(mask\)的层中选择了点能覆盖前缀的最大值,\(dpr_{mask}\)同理,很好转移。
对于每个\(i\), 若\(dpl_{mask}\) 与 $ dpr_{mask2} $ 的交覆盖了\(i\)所在的区间 $ (mask1 | mask2 = all) $,则这个区间是可行的。
复杂度\(O(n \log v)\)
扩张
一类形如 \(dp_{mask} = (|mask| - |sub|) \times w(mask)\)的转移方程的优化,\(O(3 ^ n) -> O(2 ^ n \times n ^2)\)

[ARC101E] Ribbons on Tree
三个月前做过,现在不会了,不像某位神仙两年前做过现在一眼秒了😅
比较navie的想法是设\(dp{u,x}\)为\(u\)的子树中有\(x\)个点未被覆盖,需要子树外一个点向内某个点相连的方案数,直接类似树背包转移有 \(dp_{u,x + y - 2k} = \sum \limits_{v \in son(u), x +y > 0,k \leq min(x, y)} dp_{u, x} \times dp_{v,y} \times \binom{x}{k} \times \binom{y}{k} \times k!\)。
系数过于复杂,不便于优化。看到每条边至少被覆盖一次考虑容斥。
考虑边集\(S\)中的边一次都没被覆盖过,这等价于删去这些边。此时整张图被分成了若干个联通块,显然每个联通块内部匹配的方案数是 \(g(n) = \prod \limits _{2k \leq n, k \in N^*}{2k - 1}\),注意\(n\)为奇数时\(g(n) = 0\)。
数据范围无法枚举子集,考虑\(dp\),重定义\(dp_{u,x}\)为以\(u\)为根的子树联通块大小为\(x\)的方案数(考虑容斥系数)。那么有这条边断掉 \(dp_{u,x} \times dp_{v,y} \times{g(y)} \times -1 \rightarrow dp_{u,x}\) (断边集合大小加一),保留这条边 \(dp_{u,x} \times dp_{v,y} \rightarrow dp_{u, x +y}\)。
最后答案即为 \(\sum \limits_{i = 1} ^n dp_{1, i} \times g(i)\)。复杂度为树形背包的 \(O(n ^2)\)。
点击查看代码
#include <bits/stdc++.h>
void solve() {
int n;
std::cin >> n;
std::vector <std::vector<int> > adj(n + 1);
for (int i = 1; i < n; i++) {
int u, v;
std::cin >> u >> v;
adj[u].push_back(v);
adj[v].push_back(u);
}
const int MOD = 1e9 + 7;
std::vector <int> g(n + 1);
g[0] = 1;
for (int i = 2; i <= n; i += 2) g[i] = 1ll * g[i - 2] * (i - 1) % MOD;
std::vector <std::vector<int> > dp(n + 1);
std::vector <int> siz(n + 1);
for (int i = 0; i <= n; i++) dp[i].resize(n + 1);
auto dfs = [&](auto self, int u, int fa) -> void {
siz[u] = 1;
dp[u][1] = 1;
for (const auto &v : adj[u]) {
if (v == fa) continue;
self(self, v, u);
std::vector <int> tmp(siz[u] + siz[v] + 1);
for (int j = 1; j <= siz[u]; j++) {
for (int k = 1; k <= siz[v]; k++) {
tmp[j] += -1ll * dp[u][j] * dp[v][k] % MOD * g[k] % MOD;
tmp[j] %= MOD; tmp[j] += MOD; tmp[j] %= MOD;
tmp[j + k] += 1ll * dp[u][j] * dp[v][k] % MOD;
tmp[j + k] %= MOD;
}
}
siz[u] += siz[v];
for (int i = 1; i <= siz[u]; i++) dp[u][i] = tmp[i];
}
};
dfs(dfs, 1, 0);
int ans = 0;
for (int i = 1; i <= n; i++) {
ans += 1ll * dp[1][i] * g[i] % MOD;
ans %= MOD;
}
std::cout << ans << "\n";
}
int main() {
std::ios::sync_with_stdio(0);
std::cin.tie(0);
std::cout.tie(0);
int t = 1;
while (t--) {
solve();
}
return 0;
}
「GLR-R3」惊蛰
tag:\(dp\)优化,线段树
暴力\(dp\)很显然,状态为设\(dp_{i,j}\)前\(i\)个\(b\),其中最后一个数为\(j\)的最小答案,可以暴力 \(O(nV^2)\)转移。
发现可以前缀最小值优化,并且第二维的取值只可能是\(a_i\),于是可以离散化优化到\(O(n ^ 2)\)。
设离散化后数组为\(a'\),离散化数组为\(lsh\),考虑变换\(dp\)状态,重定义\(dp_{i,j}\)为\(lsh_j \leq b_i\)时最小值(即原dp的后缀和),那么\(dp\)转移过程为
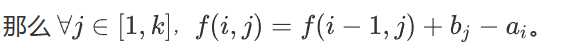
发现这种形式可以用线段树维护。
具体来说,第一种转移直接区间加。第二种主要是区间加\(lsh_j\)打标记即可。主要难在保持\(dp_i\)的单调性。
但是又发现\(lsh\)与\(dp_i\)两个数组都是单调的,加完后\(dp_{i,1} \rightarrow dp_{i,k}\),\(dp_{i,k+1} \rightarrow dp_{i,n}\)都是单调的。为了维护整个\(dp_i\)单调性,用第一部分的最小值,在线段树上二分出取\(min\)的影响区间,然后区间覆盖即可。
复杂度\(O(n \log n)\)。
点击查看代码
#include <bits/stdc++.h>
const int MAXN = 1e6 + 5;
template <class T>
void read(T &x) {
x = 0; char c = getchar(); bool f = 0;
while (!isdigit(c)) f = c == '-', c = getchar();
while (isdigit(c)) x = x * 10 + c - '0', c = getchar();
x = f ? (-x) : x;
}
#define ll long long
int lsh[MAXN];
struct Sgt {
struct Node {
int l, r;
ll mx;
ll add, tag, addb;
}t[MAXN * 8];
void pushup(int p) {
t[p].mx = std::max(t[p << 1].mx, t[p << 1 | 1].mx);
}
void pushadd(int p, ll tg) {
t[p].mx += tg; t[p].add += tg;
}
void pushaddb(int p, ll tg) {
t[p].mx += 1ll * lsh[t[p].l] * tg; t[p].addb += tg;
}
void pushtag(int p, ll tg) {
t[p].mx = t[p].tag = tg;
t[p].add = t[p].addb = 0;
}
void pushdown(int p) {
if (t[p].tag != -1) {
pushtag(p << 1, t[p].tag); pushtag(p << 1 | 1, t[p].tag);
t[p].tag = -1;
}
if (t[p].add) {
pushadd(p << 1, t[p].add); pushadd(p << 1 | 1, t[p].add);
t[p].add = 0;
}
if (t[p].addb) {
pushaddb(p << 1, t[p].addb); pushaddb(p << 1 | 1, t[p].addb);
t[p].addb = 0;
}
}
void build(int p, int l, int r) {
t[p].l = l; t[p].r = r;
t[p].tag = -1;
if (l == r) return;
int mid = (l + r) >> 1;
build(p << 1, l, mid); build(p << 1 | 1, mid + 1, r);
}
void add(int p, int l, int r, ll delta) {
if (l <= t[p].l && t[p].r <= r) {
pushadd(p, delta);
return;
}
if (t[p].l != t[p].r) pushdown(p);
int mid = (t[p].l + t[p].r) >> 1;
if (l <= mid) add(p << 1, l, r, delta);
if (r > mid) add(p << 1 | 1, l, r, delta);
pushup(p);
}
void addb(int p, int l, int r, ll delta) {
if (l <= t[p].l && t[p].r <= r) {
pushaddb(p, delta);
return;
}
if (t[p].l != t[p].r) pushdown(p);
int mid = (t[p].l + t[p].r) >> 1;
if (l <= mid) addb(p << 1, l, r, delta);
if (r > mid) addb(p << 1 | 1, l, r, delta);
pushup(p);
}
void assign(int p, int l, int r, ll v) {
if (l <= t[p].l && t[p].r <= r) {
pushtag(p, v);
return;
}
if (t[p].l != t[p].r) pushdown(p);
int mid = (t[p].l + t[p].r) >> 1;
if (l <= mid) assign(p << 1, l, r, v);
if (r > mid) assign(p << 1 | 1, l, r, v);
pushup(p);
}
ll query(int p, int pos) {
if (t[p].l == t[p].r) {
return t[p].mx;
}
if (t[p].l != t[p].r) pushdown(p);
int mid = (t[p].l + t[p].r) >> 1;
if (pos <= mid) return query(p << 1, pos);
return query(p << 1 | 1, pos);
}
int binary(int p, ll x) {
if (t[p].l != t[p].r) pushdown(p);
if (t[p].mx < x) return -1;
else if (t[p].l == t[p].r) return t[p].l;
int mid = (t[p].l + t[p].r) >> 1;
int ret = binary(p << 1 | 1, x);
if (ret != -1) return ret;
return binary(p << 1, x);
}
//last position i where dp[i] >= x
};
void solve() {
int n, c;
std::cin >> n >> c;
std::vector <int> a(n + 1);
for (int i = 1; i <= n; i++) {
read(a[i]);
lsh[i] = a[i];
}
std::sort(lsh + 1, lsh + 1 + n);
int tot = std::unique(lsh + 1, lsh + 1 + n) - lsh - 1;
for (int i = 1; i <= n; i++) {
a[i] = std::lower_bound(lsh + 1, lsh + 1 + tot, a[i]) - lsh;
a[i] = tot - a[i] + 1;
// std::cerr << a[i] << " ";
}
// std::cerr << "\n";
std::reverse(lsh + 1, lsh + 1 + tot);
static Sgt t;
t.build(1, 1, tot);
for (int i = 1; i <= n; i++) {
if (a[i] + 1 <= tot) t.add(1, a[i] + 1, tot, c);
t.add(1, 1, a[i], -lsh[a[i]]);
t.addb(1, 1, a[i], 1);
ll val = t.query(1, a[i]);
// std::cerr << "qwq" << "\n";
int pos = t.binary(1, val);
// int pos = tot;
// std::cerr << "qaq" << "\n";
if (pos != -1 && a[i] + 1 <= pos) t.assign(1, a[i] + 1, pos, val);
}
ll ans = 1e18;
for (int i = 1; i <= tot; i++) ans = std::min(ans, t.query(1, i));
std::cout << ans << "\n";
}
int main() {
// freopen("wave.in", "r", stdin);
// freopen("wave.out", "w", stdout);
// std::ios::sync_with_stdio(0);
// std::cin.tie(0);
// std::cout.tie(0);
int t = 1;
while (t--) {
solve();
}
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号