
可伸缩架构简短系列
采取什么办法可以让一个Web服务可大规模可扩展?相信你会对这个问题感兴趣。
克隆
通常来说,公共服务器上的一个可伸缩的web服务总是隐藏在一个Load Balancer(负载均衡器)之后。这个负载均衡器会将负载(来自用户的请求)均匀的分配到一组服务器或者服务器集群。那意味着什么?举个例子:某个用户访问你的服务,他第一次的请求可能会由第二台服务器提供,第二次请求由第9台服务器提供,第3次请求又再次由第二台服务器提供。
对于该用户而言,他每次得到的结果应该是一样的,不依赖服务到底是哪台服务器提供的。这个正是可伸缩性的第一个黄金法则:每个服务器都包含完全相同的代码库,不在本地磁盘或内存存储任何与用户相关的数据,如session或用户信息。Session需要集中存储,使得每一台服务器都可以访问到它。它可以是一个外部数据库或外部持久缓存,比如Redis。相比外部数据库,在持久化的缓存中存放session将会有更好的性能。这里提到的“外部”指的是数据存储不放置在这些应用服务器上,而是在接近您的应用程序服务器的数据中心。
但是这要怎么部署呢?你如何确定当应用代码发生了改变能够发送到所有的服务器而没有一台服务器依旧使用之前的代码?幸运的是,这个棘手的问题已经被一个很好的工具capistrano解决了,你需要稍微学习了解下。
在解决了session和多台服务器上新版本的同步更新问题之后,你需要做的就是克隆你的机器镜像了,然后将你最新的代码部署上去。可以参考Amazon提供的AMI服务(Amazon Machine Image)
现在你的服务器可以水平扩展,并且处理成千上万的并发请求了。
数据库
但是你发现应用程序变得越来越来最终崩溃。问题的原因:是MySql,不是吗?
现在不是增加更多的机器可以解决的问题了,你有两种办法:
- 1,坚持使用MySql,并且让它运行良好。做主从复制(从服务器负责读取,主服务器负责写入),并且升级主服务器,不断加入更多的内存。随着不断优化,你会使用数据库分片、反规模化、SQL调优等常用手段。这时,对于数据库的任何一个操作成本都会变得相当昂贵。
- 2,切换到一个更加容易扩展的NoSQL数据库,比如 MongoDB或CouchDB,连接查询现在需要在应用代码层里去进行了。
现在,你的数据库有了一个可扩展的解决方案了,你再也不用担心存储TB级的数据,世界看起来那么的美好。
缓存
当大量的数据请求发往到数据库,你发现又变慢了,解决办法是增加缓存。
这里说的缓存指的是内存缓存,比如常见的内存数据库 Memcached 或者 Redis ,千万不要使用文件缓存,它会让你服务器的克隆和自动伸缩很痛苦。
但是回到内存缓存,缓存是一个简单的键值存储并且应该介于应用程序和数据存储。任何时候当你的应用程序需要去读取数据时,它首先应该尝试从缓存里面获取数据,只有无法从缓存中读取数据时,才会尝试从数据库中读到。为什么要这么做呢?因为缓存快如闪电,它将数据集存放在内存中,并且可以快速的被处理。举个例子:Redis没秒钟可以处理成千上万的读操作。
访问流程:第一次访问绿色,第二次和之后的蓝色:
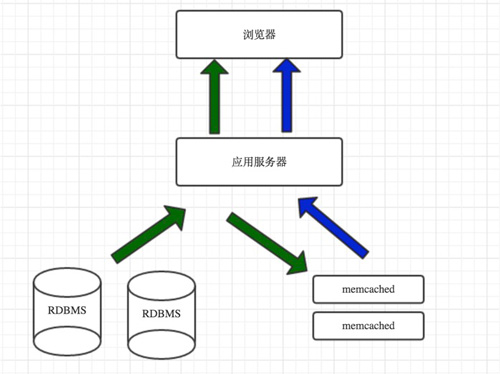
有两种缓存数据的模式,一种是老的方式,一种是新的方式:
- 1,缓存数据库查询,这个仍然是最普遍的缓存方式,当你做一次查询时,将数据集进行缓存,通过哈希后查询串作为键。下一次查询时,检查缓存中是否有结果。这种方式存在一些问题,最主要的问题就是过期。当数据表中的一块数据发生变化时,你需要删除所有包含这个数据块的查询串的缓存。
- 2,缓存对象,我强烈推荐使用这种方式,这也是我经常使用的。
一些适合缓存的对象:
- 用户Session(永远不存放在数据库中)
- 完全呈现的博客文章
- 活动流
- 用户<- -> 朋友 之类的关系
异步
请想象一下,你想在你最喜欢的面包店买面包,所以你走进面包店,向一个店员询问购买面包,但是面包都卖光了。你被告知2个小时之后你订的面包可以好,这个很恼人,不是吗?
为了避免这种“请等片刻”的场景,需要采取异步。比如什么时候有面包了,店员会将面包派送给你的家里。通常来说,有两种异步的范例:
- 1,让我们回到普通的买面包的场景,第一种异步处理流程是:“晚上把面包都烹制好,第二天早上卖”,这个对于顾客来说不需要等待。对于一个web应用程序,这意味着提前做耗时的工作,这样就可以在短时间处理完工作。通常这种模式用来将动态的内容转换为静态内容。比如提前渲染好CMS里面的一些网页,并且本地存储这些HTML文件。采用定时任务,可能是通过脚本叫做每小时的计划。这种对通用数据预先计算可以极大的提升网站和web app的可伸缩性和性能。可以通过脚本将这些预先渲染好的HTML页面发布至CDN。你的网站将能做到响应超快并且每小时可以处理成千上万的游客!
- 2,回到面包店,有的时候顾客可能会有一些特殊的需求,不然在面包上加上“生日快乐”等装饰。面包店并不能提前知道这种顾客类型的需求,所以当顾客来到店里后,必须马上开启一个任务并且告诉他:”你明天再来吧!“ 对于web而言,这意味着异步任务。这里有一个典型的工作流:一个用户来到你的网站,开始一项计算密集型任务,这个任务需要花费几分钟来完成,所以网站前端会往任务队列里面发送一个任务,并且告诉用户你的任务已经在处理中了,你可以继续浏览网页了。一个任务队列会不断的被处理任务的workers 检查处理。如果有一个新任务,work会处理这个任务,过了几分钟之后会发送一个处理完毕的消息信号。前端会不断的检查(比如轮询)这个任务是否已经处理完,一旦处理完则通知用户。如果你想更深入了解,推荐你去看看RabbmitMQ),Rabbit MQ是一个实现了异步消息队列的优秀中间件。你也可以使用ActiveMQ或者一个简单的Redis list,异步消息队列看起来很复杂,但是它值得你花时间去学习和实现。
如果你做一些耗时的操作,试着采用异步。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号