
mysql
MYSQL
https://blog.csdn.net/justloveyou_/article/details/78308460
索引
哈希索引(哈希表):等值查询快、不支持模糊查询、范围查询、最左前缀匹配
B+树、B树区别:
-
B+树非叶子节点不存储数据,只是索引;B树则存储数据
-
B+树叶子节点存着链指针(方便范围查询)
-
一次IO,B+树能获取更多的索引
2、聚簇索引、非聚簇索引
聚簇索引:叶子节点存储key值、整行数据
非聚簇索引:叶子节点存储key值(如果索引不包含查询字段、需要回表查询)
3、联合索引
-
多个字段建立索引,按照查询频繁次数降序建索引
-
查询时严格按照联合索引建立的顺序查询
4、查看是否使用了索引
explain命令查询语句的执行计划
5、什么情况下无法使用索引
-
使用不等于
-
有数学运算或者函数
-
like通配在左边 like '%aaa'
-
mysql认为全表扫描更快
-
联合索引,前一个为范围查询
6、什么样的字段适合做索引
-
经常查询的
-
经常当做表连接用的
-
经常出现在order by, group by, distinct 后面的字段
7、创建索引应该注意什么
-
字段非null
-
差异值比较大
-
字段本身比较小
事务
ACID
原子性、一致性、隔离性、持久性
1、多事务同时进行有何问题?
读未提交-脏读:事务B读取到事务A未提交的内容,然后事务A回滚了
原理:写数据时加上X锁,直到事务结束, 读的时候不加锁。
读已提交-不可重复读:事务B读取到事务A提交的内容,但是前后不一致
原理:写数据的时候加上X锁, 直到事务结束, 读的时候加上S锁, 读完数据立刻释放。(共享锁规则1)
可重复读-幻读:事务A插入数据,事务B范围查询,前后不一致
原理:写数据的时候加上X锁, 直到事务结束, 读数据的时候加S锁, 也是直到事务结束。(共享锁规则2)
串行化:严格有序执行
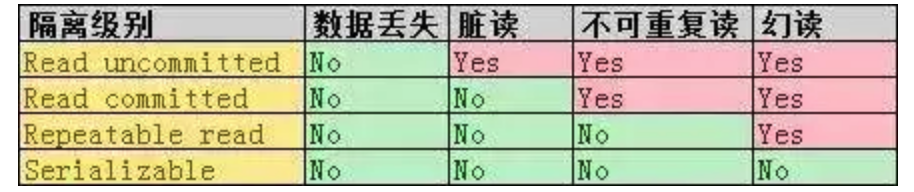
其中read committed 和 repeated read在mysql下可开启MVCC
分布式事务
https://blog.csdn.net/u010425776/article/details/79516298
https://www.dockone.io/article/9804
分布式系统CAP理论
-
一致性、可用性、分区容错性;不可兼得
-
一般保证AP、只要求最终一致性
分布式事务协议:
二阶段提交
一个协调者、三个参与者
1、第一阶段
-
协调者向所有参与者询问是否可操作,等待响应
-
参与者执行事务,并在log中写入undo与redo日志
-
发送响应,如果事务成功则同意、失败则不同意
2、第二阶段
-
协调者收到响应
-
若参与者都同意,协调者发送提交消息、参与者完成事务并发送响应给协调者、协调者收到反馈后完成事务
-
若参与者存在不同意、协调者发送回滚消息、参与者回滚事务并发送响应给协调者、协调者收到反馈后取消事务
存在的问题:
-
参与者参与过程是阻塞的、浪费资源
-
参与者宕机(协调者阻塞)、协调者宕机(参与者阻塞)都需要超时机制
-
如果协调者发送同意之后宕机、收到请求的唯一一个参与者也宕机、没人知道当前是什么状态
三阶段提交
1、canCommit阶段
-
协调者向参与者发送消息,是否可以执行事务
-
参与者返回YES or NO
2、preCommit阶段
-
如果全为YES、协调者发送preCommit请求、参与者执行事务并在log写入undo与redo日志、向协调者发送响应
-
如果存在NO、协调者发送abort请求、参与者取消事务、向协调者发送响应
3、doCommit阶段
-
如果是提交的、协调者发送提交请求、参与者提交事务、向协调者发送响应、协调者完成事务
-
如果是中断请求、协调者发送中断请求、参与者中断事务、向协调者发送响应、协调者取消事务
三阶段存在的问题:
-
在提交阶段如果发送的是中断事务请求,但是由于网络问题,导致部分参与者没有接到请求,那么参与者会在等待超时之后执行提交事务操作,这导致参与者数据不一致
分布式主键id获取
https://zhuanlan.zhihu.com/p/140078865
-
uuid
-
mysql自增(redis)
-
mysql多实例自增(redis)
-
雪花算法
-
mysql自增+双buffer方案
主从
https://zhuanlan.zhihu.com/p/96212530
-
主dump线程,从IO线程、sql线程
-
IO线程给dump线程binlog的名字、偏移量
-
dump线程发送数据给IO线程
-
IO线程写入relay log中
-
sql线程重放relay log更新
其他
1、字段为何要求定义为not null?
null会占用更多的字节、且容易造成与预期不符的情况
2、InnoDb与MyIsam的区别
-
innodb支持事务、行级锁、MVCC、外键、不支持全文索引、数据存储在一个文件中
-
myisam不支持事务、表级锁、不支持MVCC、不支持外键、支持全文索引、数据存储在三个文件(.frm、.MYD、.MYI,因而没有聚簇索引)、保存了表的行数
3、varchar、char
-
char定长,检索效率高
-
varchar变成,占用空间=实际字符长度+1(存储使用长度)
4、mysql binlog格式
-
statement:sql语句&上下文,日志小、但是某些函数无法被记录复制
-
row:记录每行数据修改、日志量大
-
mixed:根据sql语句区分使用上述哪种
5、超大分页处理:减少load的数据
select * from table where age > 20 limit 1000000,10这种查询其实也是有可以优化的余地的. 这条语句需要load1000000数据然后基本上全部丢弃,只取10条当然比较慢. 当时我们可以修改为select * from table where id in (select id from table where age > 20 limit 1000000,10).这样虽然也load了一百万的数据,但是由于索引覆盖,要查询的所有字段都在索引中,所以速度会很快.

6、慢查询优化
-
分析语句:看看是否load了额外的数据,可能是查询了多余的行并且抛弃掉了,可能是加载了许多结果中并不需要的列
-
分析执行计划:查看索引使用情况
-
若语句无法优化,则进行分库分表
7、范式
-
第一范式:每列不可再分
-
第二范式:非主键列完全依赖主键、而不是主键的一部分
-
第三范式:非主键列只依赖主键
8、悲观锁与乐观锁
悲观锁:select… for update语句、获取行锁、执行中所有扫描过的行都会被锁上,因此,如果在mysql中用悲观锁务必要确定使用了索引,而不是全表扫描
乐观锁:乐观锁的特点先进行业务操作,只在最后实际更新数据时进行检查数据是否被更新过,若未被更新过,则更新成功;否则,失败重试。一般的做法是在需要锁的数据上增加一个版本号或者时间;在数据库内部update同一行的时候是不允许并发的
原理:先获取版本号、然后update的时候对比版本号
应用场景:读多写少更适合用乐观锁,读少写多更适合用悲观锁
Redis
https://blog.csdn.net/liqingtx/article/details/60330555
https://blog.csdn.net/qq_34337272/article/details/80012284
https://blog.csdn.net/itcats_cn/article/details/82391719
内存型、支持持久化的nosql数据库
-
单线程、IO多路复用、非阻塞IO
-
内存、速度快
-
支持丰富数据类型,支持string,list,set,sorted set,hash
-
支持事务、操作为原子性
持久化
持久化方式:RDB(快照)、AOF(指令)
-
RDB:bgsave指令,fork子进程生成快照、一般隔一段时间操作、因此优势:恢复快、缺点:数据缺失多、耗时长
-
AOF:将执行指令记录下来、一般每秒操作、优点:数据完整 缺点:文件大(重写机制)、恢复数据慢(appendfsync选项:always、everysec和no)
AOF重写过程:
-
fork重写子进程
-
子进程读取AOF文件到临时文件、主进程把接下来的指令一边追加到AOF文件、一般载入内存缓冲区
-
重写结束发信号给主进程、主进程将缓冲区指令写入新的AOF
-
新的AOF替换旧的
主从:
-
主服务器写、从服务器读
-
异步主从同步
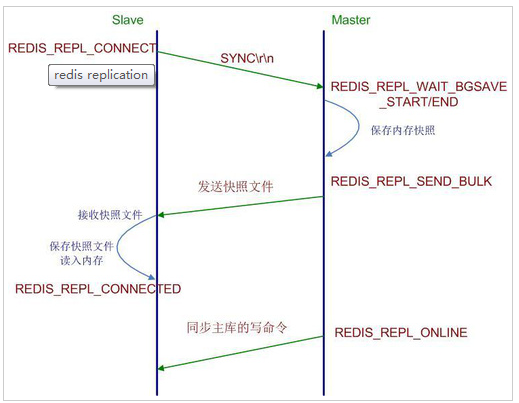
同步原理(全量同步):
-
从服务器发送sync指令、主服务器执行bgsave、子进程持久化RDB、新指令记录在缓存区
-
将缓存的RDB发送给从服务器、然后发送缓存指令(分开发送)
-
从服务器读取到内存。进行恢复
增量同步:
-
PSYNC指令、从服务器发送希望同步的主服务器id、数据偏移
-
主服务器验证id、将数据增量发送(主服务器也许也会缓存数据偏移)
Redis事务
multi、exec
-
语法错误、事务取消
-
运行时错误、忽略错误指令执行
1、为何不支持事务回滚?
-
语法错误程序员问题
-
保持redis简洁、高效
2、支持隔离性么
单线程、保证执行事务期间不中断、天然支持
缓存
缓存雪崩
-
同一时间缓存大面积失效、全部打到db上
-
解决方案:key的失效时间加上随机数
缓存穿透:
-
查询缓存、db中都没有的数据、每次都绕过缓存打到db上
-
解决方案:
-
缓存的key、value写null
-
布隆过滤器
-
增加校验、过滤掉恶意请求
-
缓存击穿
-
与雪崩类似、热门key失效瞬间、大量请求打到db上
-
解决方案:
-
热门key不失效
-
同一个key用方式(加锁)顺序执行、避免同一时间全部查询
-
缓存数据库一致性:
-
先更新数据库、再删除缓存
-
删除失败则重试(利用消息队列等重试)
淘汰策略
1、过期删除?
定时删除+惰性删除
-
定期删除:每隔100ms 随机抽取一批设置了过期时间的key、查看是否过期
-
惰性删除:查询时先判断是否过期、过期删除
2、内存淘汰
-
noeviction(不淘汰)
-
allkeys-lru
-
allkeys-random
-
Volatile-lru
-
Volatile-random
-
Volatile-ttl(最早过期时间)
集群
主负责写、从负责读
主从复制原理:
-
从服务器发送sync指令
-
主服务器收到,执行bgsave指令、生成RDB快照、并且缓存执行指令
-
将RDB快照和缓存指令发送给从服务器
-
从服务器load到内存并执行指令
1、哨兵机制
哨兵也是集群、至少一主一从
-
监控主节点、从节点的状态
-
通知:服务器发生问题时、进行通知
-
故障转移:当主服务器出现问题、从从服务器中选举出新的主节点
故障转移:主观下线+客观下线、
-
主观下线:每秒ping一次、ping不通则认为故障
-
客观下线:若认为主节点故障、则询问从节点、如果一定数量从节点认为主节点不可达、则认为客观下线、进行故障转移
数据分区:
| 分区方式 | 特点 | 相关产品 |
|---|---|---|
| 哈希分区 | 离散程度好,数据分布与业务无关,无法顺序访问 | Redis Cluster,Cassandra,Dynamo |
| 顺序分区 | 离散程度易倾斜,数据分布与业务相关,可以顺序访问 | BigTable,HBase,Hypertable |
哈希分区分为两种:
-
Hash(key) % N
缺点:扩容、缩容数据分布变化很大、迁移麻烦
-
一致性哈希:key做哈希、服务节点做哈希(都是int32整数范围)、然后看key分布在哪个服务节点
优点:扩容&缩容只影响相邻节点
缺点:负载不均衡
解决方案:虚拟槽位、每个节点负责一批虚拟槽位、然后计算一致性哈希使用虚拟槽位、根据虚拟槽位找到真实的节点
3、key竞争并发
-
不要求顺序:分布式锁
-
要求顺序:时间戳(或者队列)
4、集群搭建方案
-
客户端分区:redis sharding
-
中间件分区:Twemproxy 、codis
-
服务器转发(查询路由):客户端随意发、服务器路由到正确节点、redis cluster
数据底层实现
https://www.cnblogs.com/ysocean/category/1221478.html
所有的object基类
typedef struct redisObject{
//类型
unsigned type:4;
//编码
unsigned encoding:4;
//指向底层数据结构的指针
void *ptr;
//引用计数
int refcount;
//记录最后一次被程序访问的时间
unsigned lru:22;
}robj
1、String
使用场景:
-
计数
-
限制次数:如五分钟内超过三次验证没过等待
数据结构:简单动态字符串SDS
struct sdshdr{
//记录buf数组中已使用字节的数量
//等于 SDS 保存字符串的长度
int len;
//记录 buf 数组中未使用字节的数量
int free;
//字节数组,用于保存字符串
char buf[];
}
编码:int、raw(长度>44)、embstr(长度<44)


Embstr: 一次性申请/释放空间、不可变的,只要修改了就成raw格式
raw:两次申请释放空间
二进制安全
2、Hash(key、value对)
使用场景
-
缓存信息
数据结构
typedef struct dictEntry{
//键
void *key;
//值
union{
void *val;
uint64_tu64;
int64_ts64;
}v;
//指向下一个哈希表节点,形成链表
struct dictEntry *next;
}dictEntry
typedef struct dictht{
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
//总是等于 size-1
unsigned long sizemask;
//该哈希表已有节点的数量
unsigned long used;
}dictht

扩容条件:
负载因子 = 哈希表已保存节点数量 / 哈希表大小。
-
服务器目前没有执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且负载因子大于等于1。
-
服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且负载因子大于等于5。
-
渐近式哈希
编码:ziplist、hashtable


ziplist:个数<512&每个长度<64字节(可修改)
3、list
使用场景:
-
栈(lpush+lpop)
-
队列(lpush+rpop)
typedef struct listNode{
//前置节点
struct listNode *prev;
//后置节点
struct listNode *next;
//节点的值
void *value;
}listNode
typedef struct list{
//表头节点
listNode *head;
//表尾节点
listNode *tail;
//链表所包含的节点数量
unsigned long len;
//节点值复制函数
void (*free) (void *ptr);
//节点值释放函数
void (*free) (void *ptr);
//节点值对比函数
int (*match) (void *ptr,void *key);
}list;


编码:ziplist、linkedlist
ziplist:个数<512&每个长度<64字节(可修改)
4、set
使用场景:
-
利用集合的交并集特性,用户的共同好友,共同兴趣等
数据结构:


编码:intset、hashtable
intset:都是整数&个数<512
5、zset
使用场景:
-
排行榜
数据结构:跳表
typedef struct zskiplistNode {
//层
struct zskiplistLevel{
//前进指针
struct zskiplistNode *forward;
//跨度
unsigned int span;
}level[];
//后退指针
struct zskiplistNode *backward;
//分值
double score;
//成员对象
robj *obj;
} zskiplistNode
typedef struct zskiplist{
//表头节点和表尾节点
structz skiplistNode *header, *tail;
//表中节点的数量
unsigned long length;
//表中层数最大的节点的层数
int level;
}zskiplist;
编码:ziplist、skiplist
ziplist:个数小于128&长度小于64

 浙公网安备 33010602011771号
浙公网安备 33010602011771号