




原著:MagedM. Michael
原名:Hazard Pointers: Safe Memory Reclamation for Lock-Free Objects
原文:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.130.8984&rep=rep1&type=pdf
翻译:CoryXie<cory.xie@gmail.com>
摘要:无锁(Lock-free)对象比传统的基于锁的对象提供了显著的性能和可靠性等优点。然而,由于缺乏一个有效可移植的无锁方法来回收这些对象中删除掉的动态节点所占用的内存,成为了在实践中广泛应用该方法的一个主要障碍。本文介绍了风险指针(Hazard Pointers),这是一种内存管理方法,允许内存被回收后任意重用。我们的实验结果证明,这是非常有效的。它适用于用户级应用程序,也适用于系统程序,不依赖于特殊的内核调度的支持。它是无等待的(wait-free)。其核心操作仅需要单字的内存读取和写入访问。它允许被回收的内存被返回给操作系统。此外,仅仅使用实际的单字指令,它还提供了ABA问题的一个无锁解决方案。除了其在内存回收和独立于特殊硬件支持这些质量优势之外,我们在多处理器系统中的实验结果还显示,相比其他内存管理方法,该新方法提供了同等的,在更多的时候,甚至明显更好的性能。我们还表明,使用风险指针(HazardPointers)的重要对象类型的无锁实现与高效的基于锁的实现相比,提供了在无争用无多道程序的情况下同等的性能,在中等多道程序和中等争用情况下显著超越他们,此外,甚至在存在的线程失败和任意延迟的情况下,也能保证持续前进和其可用性。
索引词:无锁(Lock-free),同步(synchronization),并行编程(concurrent programming),内存管理(memory management),多道程序设计(multi-programming),动态数据结构(dynamic data structures)。
1. 引言
共享对象是无锁的(lock-free)(也称为非阻塞的,nonblocking),如果它能保证当一个线程在对象上执行一些有限次数的操作步骤,在执行这些步骤期间,某个线程(可能是不同的线程),必须能朝着完成在该对象上的操作的方向上取得进展。因此,它不同于传统的基于锁的对象,在面临线程失败的时候,无锁对象是死锁免疫的;即使面对任意的线程延迟,也提供了稳健的性能。
已经开发出了许多无锁动态对象的算法,例如[11],[9], [23], [21], [4], [5], [16], [7], [25], [18]。但是,关于这些对象的一个主要关注的问题是,如何回收已经删除掉的节点所占用的内存。在基于锁的对象的情形下,当线程从对象中删除一个节点时,在它被重用或者重新分配之前,很容易保证没有其他线程会在此后访问该节点的内存。结果是,通常由删除线程来回收(例如使用free)被删除的节点占用的内存,用于将来被某些其他线程重用(例如使用malloc)是安全的。
对于典型的无锁动态对象,当在没有自动垃圾回收机制的环境中运行时,就不再是如此了。为了保证无锁的进展,每个线程必须要有无限制的机会在任意时间去操作该对象。当线程删除一个节点时,可能某个其他线程——在其无锁操作期间——已经在预先读取了该对象的一个引用,且正要访问其内容。如果删除线程真的回收了被删除节点的内存用以任意重用,那个争用线程就可能破坏该对象或者其他恰巧占据了该被释放掉的对象的空间的对象,从而会返回错误结构,或者因为解引用无效指针而遭受访问错误。进一步,如果被回收的内存被返回给了操作系统(例如使用munmap), 访问这样的内存位置就会导致致命的访问违例错误。简单点说,内存回收问题是如何允许被删除节点的内存被释放(也即,被任意重用或者返回给OS),同时还保证没有线程访问被释放的内存,以及如何以一种无锁的方式做到这一点。
之前的用以允许动态无锁对象的节点重用的方法主要可以分为3类。1)IBM 标签方法(更新计数)[11],这阻碍了内存被回收任意重用,且要求双字宽指令,而在64位处理器上不存在这种指令。2)无锁引用计数方法[29],[3],这种方法效率不佳,且为了允许内存回收还使用了根本不存在的强大的多地址原子原语。3)基于总体引用计数或者每个线程(per-thread)的时间戳的方法[13],[4], [5]。没有特殊的调度器支持,这些方法都是阻塞的。也就是说,甚至一个线程的失败或者延迟都会阻止总体引用计数到达零值,或者阻止时间戳被更新,从而阻止不定界的内存重用。
本论文介绍风险指针(hazard pointers),一种用以无锁动态对象的内存回收方法。它是高效的;它对每个退休节点(例如一个被删除的不再被删除线程需要的节点)的分摊时间是预期的常量。无论线程是失败还是延迟,它都能对不可重用的退休节点的总数保持一个上界。也就是说,任意数量的线程失败或者延迟都只能阻碍有限数量的退休节点不能被重用。该方法不要求使用双字或者更强大的多地址原子原语。在其核心操作中,它只使用单字内存读写访问。它是无等待的[8],即,能保证每个活跃线程的进展,而不仅仅是总体的进展。因此,它也适用于无等待算法,而不会减弱他们对进展的保证性。它运行被回收的内存被返回给操作系统。它不要求内核或者调度器提供任何特殊支持。
核心思想是,将一些(典型地是1或2个)被称为风险指针(hazard pointers)的单写者多读者(single-writer multi-reader)的共享指针,与每一个想要访问无锁对象的线程关联起来。一个风险指针要么是NULL,要么指向一个节点,该节点之后可能会被该线程访问,而不需要验证对该节点的这个引用是否有效。每个风险指针只能被其拥有者线程写入,但是可以被别的线程读取。
该方法要求无锁算法保证,当动态节点可能已经被从对象中删除掉的时候,没有任何线程可以访问该动态节点,除非该线程的至少一个关联的风险指针从该节点还可以保证能够从对象的根到达开始已经连续指向该节点。该方法防止释放任何已经在其被删除之前已经被一个或多个线程的一个或者多个风险指针指向的节点。
每当一个线程退休一个节点,它就将其保持在一个私有列表中。在累积了一定数量R个退休节点之后,该线程就扫描其它线程的风险指针,寻找与累积的节点地址的匹配。如果退休节点没有与任何风险指针匹配,那么释放该节点就是安全的。否则,该线程继续保持该节点,直到它下次扫描这些风险指针。
通过组织一个私有的非空风险指针的快照的的列表到一个可以以常量可预期时间搜索的哈希表中,且如果R设置为满足![]()
,其中H是风险指针的总数,那么该方法可以保证在每次扫描风险指针的过程中能识别
![]() 个节点可以用来做任意回收,且能够以
个节点可以用来做任意回收,且能够以![]() 可预期时间完成。因此,处理每个退休节点直到它可以被重用的期望分摊时间复杂度是一个常量。
可预期时间完成。因此,处理每个退休节点直到它可以被重用的期望分摊时间复杂度是一个常量。
注意,每个线程用很小数量的风险指针就可以用来支持任意数量的对象,只要该数量的风险指针足以能够单独支持每个对象。例如,在一个程序中每个线程可以在数百个共享对象上任意操作,每个对象要求每个线程有两个风险指针(例如,哈希表[25],FIFO队列[21],LIFO堆栈[11],链表[16],工作队列[7],以及优先级队列[9]),那么每个线程总共就只需要两个风险指针。
在IBM RS/6000多处理器上的实验结果显示,该新方法当被应用与重要的对象类型的无锁实现时,除了其在内存回收和独立于特殊硬件支持这些质量优势之外,相比于其他内存管理方法,还提供了等同的,或者在更多时候显著更好的性能。我们还表明,使用风险指针(Hazard Pointers)的重要对象类型的无锁实现与高效的基于锁的实现相比,提供了在无争用无多道程序的情况下同等的性能,在中等多道程序和中等争用情况下显著超越他们,此外,甚至在存在的线程失败和任意延迟的情况下,也能保证持续前进和其可用性。
本论文的其余部分组织如下:在第二节,我们讨论我们的方法的计算模型以及对于无锁对象的内存管理问题。在第三节,我们论述风险指针方法。在第四节,我们讨论应用风险指针到无锁算法上。在第五节,我们展示我们实验性的性能结果。在第六节,我们讨论相关的研究工作以及总结我们的结果。
2. 预备知识
2.1 模型
我们的方法的基本计算模型是异步共享内存模型。这个模型的正式描述出现在例如[8]的文献中。通俗地说,在这个模型中,一组线程通过在一组共享内存位置上的内存访问操作原语来沟通。线程运行在任意速度,可以有任意延迟。线程对任何其他线程的速度或状态不作任何假设。也就是说,它不做任何假设是否有另一个线程是活动的,被延迟,或崩溃,以及其暂停或恢复的时间和长短,亦或者是失败。如果一个线程崩溃,则它立即停止执行。
共享对象占有一组共享内存位置。对象是一个抽象的对象类型实现的实例,它定义了在对象上可以允许的操作的语义。
2.2 原子原语
除了原子读取和写入,共享内存位置上的基本操作可能包括更强的原子原语,比如compare-and-swap(CAS)以及load-linked/store-conditional(LL/ SC)。 CAS有三个参数:一个内存位置的地址,一个预期值,一个新值。当且仅当存储单元存储的是预期值时,新值才能原子地写入该存储单元。一个布尔返回值表示是否发生了写操作。也就是说,CAS(addr,exp,new) 以原子方式执行下列操作:
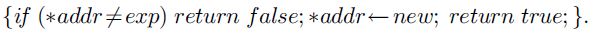
LL需要一个参数:一个内存位置的地址,并返回其内容。 SC有两个参数:一个内存位置的地址和一个新值。只有如果自从当前线程最后使用LL读取该位置之后,没有其他线程写入该内存位置,新值才会原子地写入到该内存位置。一个布尔返回值表示是否发生了写操作。一个与此相关的指令,验证(VL),它有一个参数:一个内存位置的地址,并返回一个布尔值,指示自从当前线程最后使用LL读取该位置之后是否有任何其他线程写入过该内存位置。
由于实际的体系结构的原因,支持LL / SC的架构(Alpha,MIPS,PowerPC)中没有一个支持VL,或者上述定义的LL / SC的理想语义。没有一个架构允许嵌套或交织LL / SC对,并且大部分都禁止在LL和SC之间有任何内存访问。此外,所有这样的架构中,偶尔,但不是无限经常,允许SC意外失败,也就是说,即使自从当前线程最后一次使用LL读取之后没有其他线程写入过该内存位置,该指令会返回false。在本文中,对于本论文中所展示的所有算法,CAS(addr,exp,new)都可以使用受限制的LL/ SC实现如下:
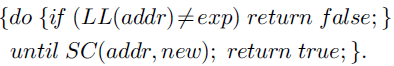
大多数目前主流的处理器架构上都支持CAS,或在对齐的单字上受限制的LL / SC。在大多数32位架构中都支持CAS和对齐双字上的LL/ SC(即支持64位指令),但在64位架构上不受支持(即不支持128位指令)。
2.3 ABA问题
与内存回收不同但相关的一个问题是所谓的ABA问题。它影响了几乎所有的无锁算法。它首次在IBM System 370的CAS文档中被报道[11]。它发生在当一个线程从共享位置读取值A,然后其他线程改变该位置为不同的值,例如B,然后再回到A这样的情况下。之后,当原来的线程再次检查位置,例如,使用读或CAS,比较结果会成功,线程假设该位置自从线程之前读取它以后并没有改变,从而错误地前进。因此,线程可能会破坏该对象,或返回一个错误的结果。
ABA问题是一个根本问题,必须被防止,而不论内存回收如何。它与内存回收的关系在于,后一个问题(指内存回收问题)的解决方案,如自动垃圾收集(GC)以及这里描述的新方法,通常会作为一种副作用只需很少或根本没有额外的开销,就能阻止ABA问题。
对大多数的无锁动态对象也是如此。但是,应该指出的是,一个常见的误解是,在所有情况下GC都能从本质上防止ABA问题。不过,考虑一个程序,在两个列表之间来回移动动态节点(例如,LIFO堆栈[11])。在这种情况下,ABA问题仍然是可能的,即使有完美的GC。
在无锁算法的ABA问题的防止方面,新方法与GC一样强大。也就是说,如果一个无锁算法在GC下是ABA安全的,那么在没有GC的情况下对该算法应用风险指针(hazard pointers)也会使它是ABA安全的。正如我们在最近的一份报告[19]中讨论的,在GC下,无锁算法总是可以被做成ABA安全的,同样在没有GC的情况下使用风险指针(hazard pointers)也行。在本论文的其余部分,当我们讨论在没有GC支持的情况下使用风险指针作为ABA防止措施的时候,我们假设该无锁算法在GC下已经是ABA安全的。
3. 方法及其证明
该新方法主要是根据观察发现,在绝大多数无锁动态对象算法中,线程只会持有少量的引用,以后可能会在没有进一步验证访问动态节点的内容的情况下使用,或者作为易于发生ABA问题(ABA-prone)的原子比较操作的目标或期望值。
新方法的核心思想是,将一些被称为风险指针(hazard pointers)的单写者多读者(single-writer multi-reader)的共享指针,与每一个想要访问相关对象的线程关联起来。每个线程的风险指针的数量取决于相关联的对象的算法,且根据他们打算访问的对象的类型不同可能会有所不同。通常情况下,这个数目是1个或2个。为简单演示起见,我们假定每个线程都具有相同的K个风险指针(hazard pointers)。
该方法只通过风险指针(hazard pointers)和一个被称为RetireNode的过程(线程通过它传递退休节点的地址)来与相关的算法沟通。该方法包括两个主要部分:处理退休节点的算法,以及无锁算法为了保证内存回收的安全性和防止ABA问题所必须满足的条件。
3.1 算法
图1显示出该算法所使用的共享和私有结构。主要的共享结构是风险指针(HP)记录的列表。该列表被初始化为给N个参与线程的每一个都包含一个HP记录。风险指针的总数是H=N*K(注1)。每个线程使用了两个静态的私有变量,rlist(退休列表)和rcount(退休计数),以保持私有的退休节点列表。
注1:正如在3.2节中讨论的,该算法可以被扩展,从而N和H的值并不需要事先知道,线程可以动态地加入和离开系统,且可以动态分配和释放风险指针。
图2所示的RetireNode例程,其中退休节点插入线程的退休节点的列表,并更新列表的长度。每当线程的退休的节点列表的大小达到阈值R,线程就使用Scan例程扫描风险指针(hazard pointers)列表。 R可以是任意选择的。然而,为了每个退休节点达到一个恒定的预期分摊处理时间,R必须满足![]() 。
。
图3示出了Scan例程。扫描分为两个阶段。第一阶段包括扫描HP列表获得所有非空值。每当遇到非空值时,它被插入在一个本地列表plist中,这可以被实现为一个哈希表。扫描的第二阶段涉及检查rlist中的每个节点对比plist中的指针。如果查找找不到匹配,该节点就被确定为可以任意重用。否则,它被保持在rlist中,直到当前线程下一次扫描。在plist中的插入和查询时间为常数。



或者,如果期望更低的最坏情况时间复杂度,而不是平均时间复杂度,plist可以被实现为一个平衡搜索树,这样插入和查找时间复杂度为![]() ,其中p是在阶段1扫描中所遇到的非空风险指针(hazard pointers)的数目。在这种情况下,每个退休节点的分摊时间复杂度是
,其中p是在阶段1扫描中所遇到的非空风险指针(hazard pointers)的数目。在这种情况下,每个退休节点的分摊时间复杂度是![]() 。
。
在实践中,为了简单性和速度,我们建议将plist实现为一个数组,且在扫描的第1阶段结束时排序,然后在第二阶段使用二进制搜索。在第5节中,我们使用后者来实现我们的实验。我们省略了哈希表,平衡查找树,排序,以及二进制搜索算法,因为它们是知名的顺序算法[2]。
在本论文的背景下,内存回收方法的任务是,在允许内存回收时,确定一个退休节点何时可以安全地被重用。因此,PrepareForReuse例程的定义是开放的,可以有几个备选实现方案,因此它就不是我们这里所提方法的一个不可分割的一部分。该例程的一个明显实现是立即使用标准库函数调用,例如free,来释放内存回收节点,以作任意重用。另一种可能性,为了减少每个节点分配和释放都调用malloc和free的开销,每个线程都可以维持一个大小有限的私有空闲节点列表。当线程用完了私有空闲节点,它就分配新节点,当它积累了太多的私有空闲节点时,它就释放多余的节点。
该算法是无等待的(wait-free),它需要的![]() 预期时间或
预期时间或![]() 的最坏情况下的时间(如果使用了对数搜索结构来鉴别
的最坏情况下的时间(如果使用了对数搜索结构来鉴别![]() 个可以任意重用的退休节点)。它仅使用单字内存读取和写入操作。它提供了一个还不能重用的退休节点的上限个数NR,即使部分或全部线程被延迟或已经崩溃。
个可以任意重用的退休节点)。它仅使用单字内存读取和写入操作。它提供了一个还不能重用的退休节点的上限个数NR,即使部分或全部线程被延迟或已经崩溃。
3.2 算法扩展
以下是核心算法的可选扩展,提高了该方法的灵活性。
如果参与线程的最大数N之前是未知的,我们可以使用一个简单的push例程来添加新的HP记录到HP列表[11]。需要注意的是,这样的程序是无等待的(wait-free),因为最大线程数是有限的。如果线程想要能够动态分配额外的风险指针(hazard pointers),这种方法也可能是有用的。
在某些应用中,线程动态创建和退休的。在这种情况下,我们期望可以允许HP记录被重用。为每个HP记录添加一个布尔型标志(Boolean flag),可以作为说明是否HP记录正在使用或可以重用的一个指示。线程退休之前,可以清除该标志,当创建一个新线程时,可以搜索HP记录列表,找到一个可用的HP记录,并test-and-set (TAS)获得它。如果没有HP记录是可用的,可以按如上所述的方法添加一个新的。
由于线程可能有剩余的退休节点尚未鉴定为可以被重用,可以添加两个字段到HP记录结构中,使得退休线程可以通过他们将rlist和rcount变量值传递给下一个继承该HP记录的线程。
此外,可能想要能够保证可以重用的每一个节点,最终能被释放,尽管有线程失败。要做到这一点,在执行Scan后,线程再执行一个HelpScan,它会检查每个HP记录。如果有HP记录是不活动的(inactive),线程将其使用TAS锁定,并从其rlist中弹出(pops)节点。每当线程积累到R个节点,就执行执行一次Scan。因此,即使一个线程退休时留下了一个具有非空rlist的HP记录,而其HP记录恰巧没有被重用,rlist中的节点仍然可以被其他执行HelpScan的线程处理。
图4中示出了包括上述这些扩展的算法的一个版本。该算法仍然是无等待的(wait-free),且只使用了单字指令。
3.3 条件
对于一个正确的算法,为了动态无锁对象能使用新的方法来做内存回收和ABA问题的防止,它必须满足一定的条件。当线程分配一个引用(即,一个节点的地址)到它的一个风险指针(hazard pointer)时,它基本上是在向其他线程宣布,它可能要以有风险的方式(hazardous manner)使用该引用(例如,访问节点的内容而没有进一步的验证该引用),这样,其他线程将避免回收或再利用该节点,直到该引用不再是有风险的(hazardous)。这一宣告(即设置风险指针,hazard pointer)必须在此节点退休之前,且风险指针(hazard pointer)必须持续持有该引用,直到引用不再是有风险的(hazardous)。
为正式描述该条件,我们先定义一些术语:
节点(Node):我们使用术语节点(node)来描述一个内存位置范围,这个内存位置范围在某些时候可以被看作是一个逻辑实体,要么通过其在使用了风险指针(hazard pointers)的对象中的实际使用,要么通过参与线程的视角。因此,可能会有多个节点物理上重叠,但仍然被看作是不同的逻辑实体。
在任一时刻t,每个节点n处在下列状态之一:
1. 已分配(Allocated): n已经被一个参与线程分配,但尚未插入一个相关联的对象。
2. 可到达(Reachable):n是可以通过从根部开始跟踪一个相关联的对象的有效指针是可达的。
3. 已删除(Removed):n不再可到达,但仍可能在删除线程(removing thread)中正被使用。
4. 已退休(Retired): n已经被删除并被删除线程用完,但尚未被释放。
5. 空闲(Free):n的内存可以被分配使用。
6. 不可用(Unavailable):n的部分或全部内存被一个不相干的对象在使用。
7. 未定义(Undefined):n的内存访问目前没有被当作一个节点看待。
拥有(Own):一个线程j在时刻t拥有一个节点,当且仅当在时刻t节点n对于线程j 属于allocated, removed, 或者retired状态。每个节点都可以有最多一个拥有者。被分配的(allocated)节点的拥有者(owner)是分配它的线程(例如,通过调用malloc)。被删除的(removed)节点的拥有者(owner)是执行将它从对象中删除步骤的线程(也即,从将其状态从可到达(reachable)改为已删除(removed))。已退休(retired)节点的拥有者(owner)与删除它的线程是同一个线程。
安全的(Safe):一个节点n对于线程j在时间t是安全的,当且仅当在时间t,要么n是可达的,要么j拥有n。
可能是不安全的(Possibly unsafe):一个节点从线程j的视角中在时间t可能是不安全的(possibly unsafe),如果不可能仅仅通过检查j的私有变量以及该算法的语义,就可以确定对于j在时间t该节点绝对肯定是安全的。
访问风险(Access hazard):在线程j的算法的一个步骤是一个访问风险(Access hazard),当且仅当它可能会导致访问到对于线程j在其执行的时间内可能是不安全的(possibly unsafe)节点。
ABA风险(ABA hazard):线程j的算法中的一个步骤s是一个ABA风险(ABA hazard),当且仅当线程j在执行s时在一个可能不安全的(possiblyunsafe)动态节点上包括了容易发生ABA问题的比较(ABA-prone comparison)操作,这样,1)节点的地址,或它的一个算术变体,是容易发生ABA问题的比较(ABA-prone comparison)操作的一个预期值,或2)包含在动态节点中的内存位置是容易发生ABA问题的比较(ABA-prone comparison)操作的目标。
有访问风险的引用(Access-hazardous reference):线程j在时刻t包含对节点n的一个有访问风险的引用(accesshazardous reference),当且仅当在时刻t,j的一个或者多个私有变量持有n的地址,或者其算数变体,并且j可以保证(除非它崩溃了)能够到达访问风险(access hazard)s,在那里有风险地使用n的地址,也即,在n对于j可能是不安全的(possibly unsafe)时候访问n。【译注:真TNND的绕啊,基本意思就是,存在一个引用,肯定能到达,但是一旦访问就有风险!】
有ABA风险的引用(ABA-hazardous reference):线程j在时刻t包含对节点n的一个有ABA风险的引用(ABA-hazardousreference),当且仅当在时刻t,j的一个或者多个私有变量持有n的地址,或者其算数变体,并且j可以保证(除非它崩溃了)能够到达ABA风险(ABA hazard)s,在那里有风险地使用n的地址。
有风险的引用(Hazardous reference):一个引用是有风险的,如果它有访问风险(access-hazardous),和/或者有ABA风险(ABA-hazardous)。
非正式地,有风险的引用是一个地址,不经进一步的安全性验证,之后会以存在风险的方式被使用,即,在容易发生ABA问题的比较(ABA-prone comparison)操作中访问可能不安全的存储器,和/或作为目标地址,或者预期值。
一个持有节点的引用的线程,使用风险指针(hazard pointers)来向其他线程宣告,之后在一个有风险的步骤中,它可以使用该引用,而不做进一步验证。然而,如果该宣告在该引用已经是有风险的之后发生,那么此宣告是无用的,或者换句话说,在节点可能是不安全的(possibly unsafe)之后,由于另一个线程可能已经删除了该节点,且接着扫描了HP列表,而没有找到与那个节点匹配的节点。因此,相关联的算法必须满足的条件是,每当线程持有到一个节点的存在风险的引用时,它的情况必须是,线程的风险指针中的至少一个,已经从该节点对线程绝对安全的时候开始,持续持有该引用。注意,这种情况意味着,没有任何线程能够在它退休后创建一个新的对一个节点的有风险的引用。
正式地,条件如下,其中HPj是线程j的一组风险指针(hazard pointers):

【译注:我靠,这真是《藏地密码》的精简版啊!】
3.4 正确性
以下的引理(lemmas)和定理(theorem)取决于第3.3节中条件的满足。
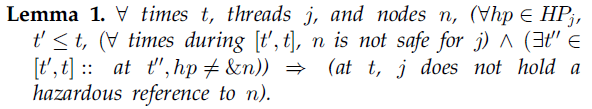
通俗地说,如果扫描线程j的风险指针没有找到匹配退休节点n的,那么必然是这样的,即线程j在扫描结束时没有持有对n的有风险的引用。
论证(Proof sketch):采用反证法,假设引理是假,即先行词的含义是真,而随之而来的结果是假。那么,在时刻t,线程j持有到节点n的有风险的引用。进而,由第3.3节中的条件,必然有一个时刻t0对于线程j而言节点n是安全的,但t0必然是在t’时刻之前,因为我们已经假设节点n在时间[t’,t]之间是不安全的。另外,由于在3.3节中的条件,线程j必然有至少一个风险指针在[t0,t]期间连续指向节点n。但是,这违背了最初的假设,对线程j的每个风险指针,存在一段时间[t’,t]期间(从而也在[t0,t]期间),风险指针不指向节点n。因此,最初的假设是假的,从而引理是真实的。

通俗地说,退休的节点只有在Scan的第2阶段扫描了所有参与线程的风险指针都没有找到匹配后,才能被确定为可以被重用。
论证(Proof sketch):采用反证法,假设引理是假的。那么,线程j的危险指针中至少有一个从t0时刻起开始连续地指向节点n。然后,由于控制流(第1阶段),在第1阶段的末尾,plist中必然包含一个到节点n的指针。然后,由于控制流(第2阶段),节点n没有被确定为可重用。这就是一个与最先假设的矛盾。
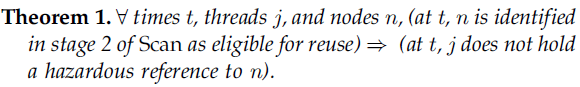
通俗地说,如果Scan识别出一个可以重用的节点,那么必然的情况是,没有任何线程持有它的具有风险的引用(hazardous reference)。
论证:如果j是执行Scan的线程,该定理是平凡真实的。考虑j是一个不同线程的情况。假设在时刻t,节点n在Scan的第2阶段被识别为可重用。那么,根据安全(safe)的定义,对于线程j而言节点n自从Scan开始就是不安全的,由引理2,对于每一个风险指针,当前Scan的执行中有一个时间段,该风险指针并没有指向节点n。那么,由引理1,在时刻t,j就不持有一个到节点n的有风险的引用(hazardous reference)。
根据有访问风险的引用(access-hazardous reference)的定义和定理1,风险指针的方法(hazardpointer methodology)(即算法和条件)保证了节点是空闲的(free)或不可用的(unavailable),没有线程访问它的内容,即,风险指针的方法(hazard pointer methodology),能保证安全内存回收。
根据有ABA风险的引用的定义和定理1,风险险指针的方法(hazard pointer methodology)能保证,当节点空闲(free)或者不可用(unavailable)时,没有线程可以持有它的引用,没有进一步的验证,意图使用该引用作为容易发生ABA问题的比较(ABA-prone comparison)的目标或预期值。这是与由GC所提供的对ABA问题的保证一样的。
4. 应用风险指针(Hazard Pointers)
本节讨论将现有的无锁算法适配到在3.3节中所列条件的方法。下面是一个纲要:
1. 按如下所示检查目标算法
A. 识别他们涉及的风险(hazards)以及存在风险的引用(hazardous references)。
B. 对于每一个不同的存在风险的引用(hazardous reference),确定它是在何时被创建的,以及使用该引用的最后风险(last hazard)是在何时。这两点之间的间隔就是需要为该引用设定专用的风险指针(hazard pointer)的时间。
C. 对所有存在风险的引用(hazardous references),对比在前面的步骤中得到的间隔,并确定对相同线程同一时间可能有风险(hazardous)的不同引用的最大数目。这就是每个线程需要的风险指针(hazard pointers)的最大数目。
对于每个有风险的引用(hazardous reference),将下面的步骤插入到目标算法中,位于创建引用之后,并在任何使用到该引用的风险之前:
A. 将引用目标节点的地址写入一个可用的风险指针中。
B. 验证该节点是安全的。如果验证成功,按照目标算法的正常控制流程继续。否则,跳过风险(hazards),并按照目标算法在检测到冲突时的路径继续,即,重试,后退,退出循环,等等。这一步是必要的,因为节点可能在执行前一步之前已经删除。
我们应用了风险指针到很多算法中,例如,[11],[10],[23],[28],[21],[26],[4],[16],[7],[6],[18],用以允许内存回收和防止ABA问题。我们使用了几个重要的对象类型的算法,来展示上述步骤的应用。
请注意,对于算法设计者而言,尽管应用这些步骤是很容易的,这些步骤并不是很容易自动地适用(例如,编译器)。例如,目前尚不清楚,是否编译器可以判断是否一个节点不再可达。确定ABA风险对于编译器更具挑战性,因为ABA问题是一个微妙的问题,涉及算法设计者的隐含意图。
4.1 FIFO队列
图5显示了Michael 和Scott的无锁FIFO队列算法[21]的一个版本中剥离的内存管理代码。该算法演示了风险指针的典型使用。我们使用它作为主要的案例研究。
简单地说,该算法将队列作为一个单向链表,在其头部有一个虚(dummy)节点。如果一个enqueue操作发现Tail指针指向最后一个节点,它就连接新节点到列表末尾,然后更新Tail。否则,就先更新Tail,然后尝试enqueue新节点。Dequeue操作在从列表中的第二个节点读取数据后摆动Head指针,同时确保Tail不会落后于Head。正如其他任何无锁对象一样,如果一个线程当在对象上操作时在任何时候被延迟,并使其处于不稳定的状态,任何其他线程都可以将对象搬到一个稳定的状态,然后继续进行其自身的操作。

首先,我们检查图5来识别风险(hazards)和存在风险的引用(hazardous references),从enqueue函数开始:
1. 在行2和行3中的节点访问不存在风险(not hazardous),因为在那时候,节点*node可以保证处于被分配(allocated)状态,也因此是被当前线程所拥有的(owned)。
2. 在行5的节点访问是一个访问风险(access hazard),因为在当前线程执行完行4之后,节点*t可能已经被另一个线程删除,且被回收掉了。
3. 在行6中我们所说的验证条件的功能是,要保证该线程能运行到行7,只有当在行5中读取t^:Next的时候,Tail还等于t才行。如果没有这个保证,队列就可能被破坏。这很容易产生ABA问题,因此,这就是一个ABA风险(ABA hazard)。
4. 在行7的CAS是一个ABA风险(ABA hazard)。
5. 在行8的CAS既是一个访问风险(access hazard),也是一个ABA风险(ABA hazard)。
6. 在行9的CAS是一个ABA风险(ABA hazard)。
因此,在行4到行9直接对t的引用是存在风险的(hazardous)。只需一个风险指针(hazard pointer)已经足够,因此在这个函数中任何时间只有一个存在风险的引用(hazardous reference)。
图6显示了被使用风险指针增强后的enqueue函数,以及保证安全内存回收和防止ABA问题的代码。在4a 和 4b中的技术是应用风险指针(hazard pointers)到目标算法的基本机制,正如本节剩下部分要显示的。

当该无视内存管理的算法(memory-management-oblivious algorithm)(在第4行)创建一个被识别为存在风险的引用之后,线程采取以下步骤:1)它将被引用的节点地址指派给一个风险指针(行4a)。 2)然后,验证该节点是安全的(行4b)。如果不安全,那么它就跳过该风险,并再次尝试。
第二步是必要的,因为可能在第4行之后,4a行之前,某些其他线程已经删除了节点*t并检查了*hp0,并得出结论说当前线程没有持有存在风险的引用(hazardous references)*t。行4b就被用于保证在那个时间点,还处于任何风险之前,*hp0已经指向*t,而且*t是安全的。
在当前线程执行行4和行4b之间,可能节点*t已经被其他线程删除并被重新插入。然而,这是可以接受的,因为这并没有违背地3.3节的条件。在执行行4之后,在执行4b之前,引用t还不存在风险,因为线程并不能保证能到达风险(第5, 6, 7, 8, 或 9行)。在行4b的验证条件成功的时候,该引用就开始存在风险了(hazardous)。但是,在那个时刻点,*hp0已经能保护到t,且它继续如此,直到t不再存在风险(在行9之后)。
下面,我们检查图5的dequeue函数。
1. 在行13的节点访问是一个使用引用h的访问风险(access hazard)。
2. 在行14的验证条件是一个使用引用h的ABA风险(ABA hazard)。
3. 在行16的CAS是一个使用t的ABA风险(ABA hazard)。然而,由于在那个时刻t可以保证等于h,如果h已经被保护(covered),那么它就已经被保护(covered)。
4. 在行17的节点访问是一个使用next的访问风险(access hazard)。
5. 在行18的CAS是一个使用引用h的ABA风险(ABA hazard)。
因此,h在行11到行18之间是存在风险的(hazardous),且next在行13和行17之间是存在风险的(hazardous)。由于这两个期间重叠,就需要两个风险指针(hazard pointers)。
图7显示了使用风险指针增强的dequeue函数。对于引用h,行11a和11b采用了与图6中的行4a和4b相同的技术。对于引用next,不需要附加的验证。在行14的验证条件(来自于原有算法)保证了*hp1等于next,从*next还安全的一个时间点开始。该算法的语义保证了节点*next 不能再行14被删除,除非其前驱(predecessor)*h已经首先被删除,然后在行13之后行14之前重新被插入。但是,这是不可能的,因为从行11b之前直到行18之后*hp0已经保护(covers)了h。
需要注意的是,风险指针允许对原有的算法[21]的一些优化,只用IBM标记方法[11] 来防止ABA问题是不安全的。行6可以从enqueue函数中删除,且第17行可以被从dequeue函数的主循环中移出来。
如果只有安全所需的内存回收和ABA的问题是不是一个问题,例如,假设理想的LL / SC /支持VL那么只有一个危险的指针是足够的保护* h和*下的“出列”常规。我们离开这个作为一个练习留给读者。
如果只需要安全内存回收,而ABA问题不是一个问题,例如,加入支持了理想的LL/SC/VL——那么在Dequeue函数中只需要一个风险指针来保护*h和*next。我们将这一点留给读者作为练习。
4.2 LIFO堆栈
图8显示了一个使用风险指针(hazard pointers)增强了的基于IBM freelist算法[11]的无锁堆栈。在push函数中,在行2和行4的节点访问不存在风险(因为*node在那时候被该线程拥有),且在第5行中的CAS不是ABA易发的(ABA-prone)(因为在第3行和第5行之间改变Top永远不会导致破坏堆栈或任何其它对象)。因此,对于push函数不需要风险指针(hazard pointers)。

在pop函数中,在行10的节点访问是存在风险的(hazardous),且在第11行的CAS是ABA易发的(ABA-prone)。所有的风险都使用引用t。用于转化pop函数所采用的技术与图6的enqueue函数中使用的技术是相同的。
4.3 基于列表的集合和哈希表
图9显示了一个使用风险指针(hazard pointers)的改进版本的无锁的基于列表的集合的实现(list-based set implementation)[16]。 [16]的算法通过允许有效的内存管理提高了Harris 的算法[5]。它可以用来作为实现无锁链式哈希表(lock-free chaining hash tables)的构建块。

节点插入很简单直接。删除一个节点需要首先在它的Next指针的低位作标记,然后将其从列表中删除,来防止其他线程将新插入的节点链接到已删除的节点[23],[5]。当一个运行线程遇到一个标记为删除的节点,它就删除节点,然后再继续,以避免在节点被删除后再创建到节点的引用。
遍历该链表任何时候都最多要求保护2个节点:一个当前节点*cur,如果有的话,以及其前驱(predecessor),如果存在的话。两个风险指针,*hp0 和 *hp1,分别被用于保护这两个节点。遍历线程开始主循环(行 12-25),其中*prev已经被保护。在第一次迭代中,*prev是root,因此这是安全的。风险指针(hazard pointer)*hp0被通过指定有风险的引用(hazardous reference)cur而被设置(行13),接着验证节点*cur在设置改风险指针之后已经处于链表中。该验证是通过验证指针*prev仍然具有值cur完成的。该验证是足够的,因为该算法的语义保证了,如果包含了*prev或其后继(successor)的节点,或者*cur节点被删除的话,则*prev的值必须改变。对*prev自身的保护是有保证的,要么它是root(在第一次迭代),或者(如下所述)保证包含它的节点被*hp1所保护。
为了在之后的迭代中保护*prev指针,由于prev是cur值的算术变体(行13),算法就交换*hp0 和 *hp1的私有标签(行24)。这里没有脆弱窗口(windows of vulnerability),因为在行21之后的步骤知道循环结束都不保护任何风险。同样,由于*hp0再行11a已经保护了cur引用,那么就没有必要进一步验证之前由cur指向而现在包含了*prev的节点还处于链表中。
因此,按照第3.3节中的条件,所有的风险(行4,6,7,15,17,20,和21)都由风险指针(hazard pointers)保护。
该算法演示了一个有趣的情况,风险指针(hazard pointers)被用来保护与对象的根节点不相邻的节点,不同于队列和堆栈算法的情况。
4.4 单写者多读者动态数据结构
Tang等人[27]采用无锁单写者多读者双链表实现点至点的发送和接收队列,以提高多道程序共享存储系统中线程化MPI的性能。该实现面临的主要挑战是内存管理。也就是说,拥有者(即,单写者)如何保证在重用或释放节点之前没有读者仍然持有已删除的节点?为了避免低效的每一个节点的引用计数,他们改而使用总体引用计数(perlist)。然而,一个读者线程的延误或者失败,可以无限期地阻止重复使用无限数量的已删除节点。正如第6.1节中所讨论的,这种类型的聚合方法不是无锁的,因为它是线程延迟和失败敏感的。此外,即使没有任何线程延迟,在该实现中,如果读者持续访问列表,总的引用计数可能永远达不到零,从而拥有者无限保持下去,不能重用删除的节点。此外,引用计数的操作需要诸如CAS或原子加这样的原子操作。
我们使用风险指针来提供一个高效的单写者多读者双向链表(single-writer multi-reader doubly-linked list)实现,它允许无锁内存回收。图 10显示了读者的检索程序的代码,以及拥有者的插入和删除程序。与使用锁或引用计数不同,除了写自己的风险指针以外,读线程不写任何共享变量,但是(风险指针)很少被写线程访问,从而减少了高速缓存一致性的通信量。此外,每个读者线程只需要两个风险指针(hazard pointers),用于支持任意数量的列表,而不是使用基于每个列表的锁或引用计数。

该算法只使用单字的读取和写入来做内存访问。因此,它表明了风险指针(hazard pointer)方法的可行性,在硬件支持的内存访问仅限于这些指令的系统上的重要性。
该算法大部分是简单直接的。然而,值得注意的是,如果*node不是列表中的最后一个节点,那么在SingleWriterDelete函数中的行10改变node^:Next是必要的。否则,由读者线程并发执行ReaderSearch函数中的第23行的验证条件可能会成功,即使在拥有者线程退休了包含*prev的节点。如果是这样的话,并且如果拥有者还删除了后续节点,那么读者可能继续设置了一个风险指针用于后续节点,但在其已经被移除和再利用之后为时已晚。
5. 实验性能结果
本节介绍了新方法的实验性能结果相比于其他无锁内存管理方法性能。我们使用风险指针(hazard pointers),ABA预防标签(ABA-prevention tags)[11],以及无锁引用计数[29]实现了无锁FIFO队列算法[21],LIFO堆栈[11],以及链式哈希表[16]。 6.1节中详细讨论了后面几种内存管理方法。
此外,我们在实验中对这些对象类型包括了有效的常用的基于锁的实现。对于FIFO队列和LIFO堆栈,我们使用的是普遍存在的具有有界指数退避(bounded exponential backoff)的test-and-test-and-set[24]锁。对于哈希表中,我们使用了100个独立的锁保护100个不相交的桶(buckets)的实现,从而使不同的桶上的操作之间完全并发。对于这些锁,我们使用Mellor-Crummey 和 Scott 的[15]简单公平的读写锁,允许桶内部(intrabucket)只读操作之间组并发(group concurrency)。
实验是在具有4个频率为375MHz的POWER3-II处理器IBM RS/6000多处理器上进行的。我们在没有其他用户使用该系统时运行该实验。所有实现的数据结构都是高速缓存行边界对齐,并在适当时做填充,以消除伪共享。在所有的实验中,所有需要的内存都在物理内存中。在需要保证内存序(memory ordering)的地方,所有代码实现中都插入了内存屏障指令(Fence instructions)。锁,以及单字和双字CAS都使用POWER3架构在32位模式下支持的单字和双字LL/ SC指令来实现。所有的实现都是在最高优化级别编译。
我们每个实验跑了五次,并取中间三个的平均值做报告。在所有的实验中,差异是可以忽略不计。报告的时间不包括初始化。对于每一个实现,我们将使用的处理器数目从一至四改变,并且每个处理器从一个到四个线程数改变。在初始化时,每个线程都被绑定到特定的处理器。在初始化时分配所有需要的节点。时间测量过程中,删除的节点被准备好重用,但并没有释放。在每个实验中用于产生不同的线程中的键和操作的伪随机序列,是不重叠的,但是在每一个实验中是可重复的(为公平比较不同实现)。
对于风险指针(hazard pointer)实现,我们的线程数N保守到64,虽然使用过较小数量的线程。对于使用引用计数的实现,我们仔细考虑了目标算法的语义,以尽量减少引用计数更新的次数。
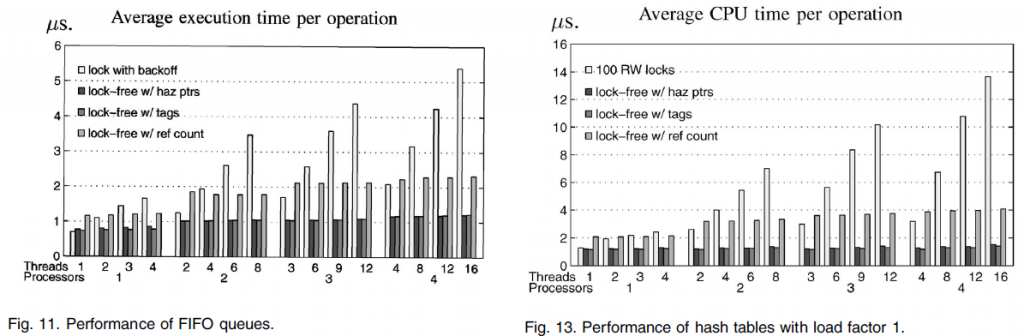
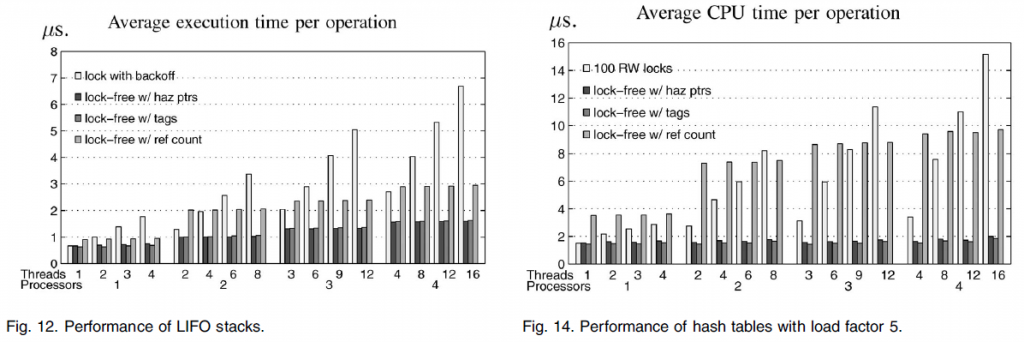
图11和图12分别显示了在共享FIFO队列和LIFO堆栈实现中每个操作的平均执行时间。在每次实验中,每个线程执行100万次操作,即队列的enqueue和dequeue操作,以及堆栈的push和pop操作。缩写标签“haz ptrs”是指风险指针,“tags”是指ABA预防标签(ABA-prevention tags),而“ref count”指的是无锁引用计数。
图13和图14分别显示负载因子分别为1和5,在具有100个桶(buckets)的共享链式哈希表上的平均CPU时间(执行时间和使用的处理器数量的乘积)。哈希表的负载因子是平均每个桶的项数。在每个实验中,每个线程执行200万次操作(插入,删除和搜索)。
在所有的图表中,一个共同的现象是,在几乎所有的情况下,使用风险指针(hazard pointers)的无锁实现,与其它实现表现一样好,或者往往显著优于其它的实现。由于是无锁的,无锁对象的性能是不受抢占影响的,而锁在抢占下表现不佳。例如,当分别有4,8,12,和16个线程分别运行在四个处理器上时,使用风险指针(hazard pointers)的无锁哈希表达到的吞吐量是基于锁的实现的251%,496%,792%和905%(图13)。
在所有的实验中,风险指针的性能与ABA预防标签(ABA-prevention tags)的性能相当。然而,不像风险指针(hazard pointers),标签要求双倍宽度的指令,并阻碍而不是帮助内存回收。
使用风险指针的无锁对象处理争用(图11和图12)显著优于用锁(即使在没有抢占的情况下)。例如,在被四个处理器争用时,甚至没有抢占,他们实现的吞吐量也是用锁在队列上操作时的178%。需要注意的是,使用无回退锁(locks without backoff)(未显示)的实验中,在四个处理器争用的情况下,执行时间还要增加一倍以上。在使用风险指针的无锁实现中使用回退,导致中等程度的性能改善(在四个处理器争用的情况下)(在队列中提升25%,在堆栈中提升44%)。然而,我们保守的报告不使用回退的结果。
使用风险指针的无锁实现,优于基于锁的实现,以及引用计数的实现(没有或者忽略争用但有共享的情况下),正如哈希表的情况(图13和图14)。这是因为他们不写除了风险指针以外的任何共享位置,在只读搜索操作过程中以及遍历过程中,从而最大限度地减少高速缓存一致性的通信量【注2】。另一方面,锁获取和释放,即使是只读事务,也要导致写入锁变量。至于引用计数,情况更糟,即使在只读事务中,每一个被遍历的节点的引用计数都需要先递增然后递减。在哈希表的情况下负载系数为5时,其效果是最明显的(图14)。在四个处理器上,使用风险指针的实现相比于使用引用计数的实现的吞吐量为573%。
注2:典型地,处理器写被缓存在cache中的具有只读权限的位置,会导致无效其他处理器中该位置对应的所有缓存副本,且在其他处理器需要访问相同的高速缓存行时,导致额外的通信流量。然而,读具有只读权限的缓存副本不会导致任何一致性通信流量。
对于哈希表,我们对整个哈希表使用一个锁来运行实验(图中未示出)。正如预期的那样,这些实现的性能是非常差的(与100互不相交锁的并发实现相比,在四个处理器上的执行时间有超过10倍的增长)。我们也使用100个test-and-test-and-set互斥锁,而不是100读写锁来运行实验。前者的性能(图中未示出)略差于后者(如图所示),因为它们不允许只读操作在桶内并发(intrabucket concurrency)。因此,我们相信,我们已经选择了非常的有效的基于锁的实现作为基准,来评估无锁实现,以及风险指针(hazard pointers)的使用。
此外,我们保守地选择了把重点放在低级别的争用和多道程序上,这往往会限制无锁同步的性能优势。对非常规同步技术的一种常见批评是:他们只有在不寻常的高争用情况下才能实现自己的优势,而在通常的低争用情况下,相比于比较简单的互斥机制,他们的表现往往非常差。我们的实验结果表明,使用风险指针(hazard pointers)的无锁对象,除了其在更高级别的争用和抢占情况下显著的性能优势外,与最简单最有效的基于锁的实现在无争用无抢占的情况下相比,仍然提供了相当的性能。
使用风险指针(hazard pointers)的无锁实现相比于基于锁的实现的卓越性能,归因于几个因素。与锁不同:
1. 他们在共享对象上直接操作,而不需要管理额外的锁变量。
2. 只读操作不会导致任何共享变量的写入(除了大多算是私有的风险指针以外)。
3. 没有无用的旋转(spin),因为在启动后每次尝试都有机会成功,这使他们更能容忍争用。
4. 并且在有抢占时也能保证进展。
需要注意的是,前两个因素的影响,即使在无争用也无抢占的情况下也适用。
值得注意的是,尽管可扩展的基于队列的锁[14],[15] 在高争用下超越能我们在这项研究中使用的简单锁,他们在通常的没有或低争用情况下却表现不佳。此外,这些锁甚至对低抢占也是极为敏感的,因为抢占在等待队列中的任何线程——不仅仅锁的持有者——都可导致阻塞。
克服锁抢占的影响,可以部分地实现,但是,只能通过使用更复杂和更昂贵的技术,如握手,超时以及与内核通信[1],[12],[22],[30],这进一步降低了常见情况下的性能。另一方面,在图中所示的使用风险指针(hazard pointers)的无锁实现天生就是线程延迟免疫的,在没有争用没有抢占的情况下几乎不损失性能,并在有争用和抢占的情况下超越基于锁的实现。
6. 讨论
6.1 相关研究工作
6.1.1 IBM ABA预防标签(ABA-Prevention Tags)
最早的也是最简单的用于节点重用的无锁方法是标签(tag)(更新计数器)方法,是跟随IBM370系统中CAS的文档介绍的[11]。它需要将每个ABA易发的(ABA-prone)比较操作的目标位置与一个标记相关联。当相关联的位置被写入时通过增加标签值,比较操作(例如,CAS)可确定该位置在最后一次被相同线程访问后是否被写过,从而防止ABA问题。该方法要求在标签中包含足够多的位,从而使得在任何一个无锁尝试的执行过程中不可能完全回绕。此方法是非常有效的,并允许退休节点立即重用。
在不利的一面,当被适用于任意的指针,正如动态大小的对象的情况下,它需要双宽度的指令,以允许原子操作该指针以及与其相关的标签。这些指令不被64位架构支持。另外,在大多数情况下,必须无限期保留标记字段的语义。因此,如果该标记是一个动态节点结构的一部分时,这些节点永远不能被回收。他们的内存不能分割或聚结,因为这可能会导致改变该字段的语义。也就是说,一旦一个存储器位置的范围用于一定的节点类型,它们就不能被重用为不能保留标记字段的语义的其他节点类型。
6.1.2 无锁引用计数(Lock-FreeReference Counting)
Valois [29]提出了一种无锁引用计数方法,要求在每个动态节点包含一个引用计数,反映对象中引用该节点以及操作该对象的线程的局部变量的最大数量。每当一个动态节点的一个新的引用被创建/销毁,引用计数就递增/递减,使用fetch-and-add和CAS。只有当引用计数器变为零之后,一个节点才可以被重用。然而,由于非原子地使用单地址CAS操纵指针以及独立定位引用计数,结果的时间窗口(timing windows)决定了必须永久保留节点的类型,以及引用计数字段的语义,因而阻碍了内存回收。
Detlefs等[3]提出了无锁引用计数的方法,使用的大多体系结构都不支持的DCAS原语(即CAS两个独立的位置)来原子地操作指针和引用计数两者,以保证引用计数永远不会小于实际引用数量。当一个节点的引用计数达到零,它就可以安全地回收再利用。但是,可用内存不能返回给操作系统。
每个节点的引用计数最重要的缺点是高昂的性能代价,不必要的更新被引用节点的引用计数,即使是只读访问,从而导致高速缓存一致性通信流量的显著增加。
6.1.3 依赖于调度器的和阻塞式的方法
这一类方法要么是线程失败或延迟敏感的,即一个单独的线程的延迟可能,且很可能会,无限期地阻止无界的内存重用(prevent the reuse of unbounded memory indefinitely);或者依赖于特殊的内核或调度器,来支持这样的延迟和失败的恢复。
McKenney和Slingwine[13]提出了读-拷贝-更新(Read-Copy-Update),在此框架下,在退休节点被删除后,只有确定其他每一个线程都已经达到了一个静止点(quiescence point),退休的节点才可以被回收。静止点的定义,取决于编程环境。通常情况下,读-拷贝-更新的实现使用时间戳或集体的引用计数。并非所有的环境都适合于静止点(quiescence points)的概念,并且如果没有特殊的调度器支持该方法是阻塞的,甚至一个线程的延迟都能阻止无界的内存重用。
Greenwald [4]提出了类型稳定内存(type stablememory)实现的简要轮廓,依赖于内核的特别支持,用以访问线程私有变量以及检测线程的延迟和失败。其核心思想是,当线程到达安全点,如内核的顶层循环,它们就设置时间戳,在这里,进程保证不会持有陈旧引用。最早的时间戳就代表一个高水位(high water mark),所有那个时间点之前退休的节点就可以安全地被回收。
Harris [5]给出了一个延后释放(deferredfreeing)方法的简要介绍,要求每个线程记录没有持有动态节点引用的最后时间的时间戳(timestamp of the latest time it held no references),并保持两个退休节点的to-be-freed列表:一个old列表,一个new列表。退休的节点先被放置在new列表上,当old列表中的最新插入的时间先于(precedes)每线程的最早时间戳时,old列表的节点都被释放,old和new列表交换标签。该方法是阻塞的,因为一个线程如果没有更新其时间戳,就会导致无限期阻碍无限数量的退休节点被重用。这甚至可能在没有线程的延迟时也会发生。如果一个线程根本不在目标对象上操作,则该线程的时间戳就会保持不被更新。
风险指针(hazard pointers)与这些方法[13],[4],[5]的一个关键区别是,前者不使用引用计数或时间戳。为无界数量的节点使用总体引用计数,和/或对每线程时间戳的依赖,使得存储器管理方法从本质上更加脆弱于甚至一个线程的故障或延迟。
6.1.4 最近的研究工作
这项研究工作的初步版本[17]发表于2002年1月。Herlihy等人 [10]独立开发了一个内存回收方法。他们的方法的基本思想与我们的相同。所不同的是在Liberate例程,对应于我们的Scan例程。Liberate比Scan更复杂,并使用双字CAS。我们的方法具有超过他们的重要优势,在如实验证明的性能方面,以及在不依赖于特殊的硬件支持方面。我们的方法,甚至在3.2节中的扩展算法,只使用单字指令,而他们的核心操作需要双字CAS,这在64位处理器架构上是不支持的。此外,我们的方法只使用读取和写入其核心业务,而他们使用CAS在其核心业务。这就阻碍了他们的方法支持要求只有读写操作的算法(例如,图10),在没有硬件支持CAS或LL/ SC的系统上,而其他方法是可行的。
6.2 结论
动态无锁对象的内存回收问题,长期打消广泛使用无锁对象的积极性,尽管比传统的基于锁的同步有其固有的性能和可靠性的优点。
在本文中,我们提出了风险指针方法(hazard pointer methodology),一种动态无锁对象的内存回收的实用,有效的解决方案。它允许无限制的内存回收,它具有每退休节点常量预期分摊时间复杂度,它不需要特殊的硬件支持,它仅使用单字指令,它不需要特殊的内核支持,它在任何时候对退休节点尚不可重用的数量保证了一个上限,它是无等待的,它提供了ABA问题的一个无锁解决方案,它对每个指针,每个节点,或每个对象不需要任何额外的共享空间。
我们的实验结果表明,风险指针的整体性能优良。这些都显示出风险指针方法(hazard pointer methodology)比其他内存管理方法,除了其在内存回收和独立于特殊的硬件支持质量优势之外,还提供了相当的性能,更多的时候甚至更好的性能。
我们的研究结果也显示使用风险指针(Hazard Pointers)的重要对象类型的无锁实现与高效的基于锁的实现相比,提供了在无争用无多道程序的情况下同等的性能,在中等多道程序和中等争用情况下显著超越他们,此外,甚至在存在的线程失败和任意延迟的情况下,也能保证持续前进和其可用性。
已经有越来越多的无锁动态对象的有效算法可用。风险指针方法通过实现内存回收,提高了其实用性,同时使他们能够实现出色的强劲性能。结合最近的完全无锁的动态内存分配算法[20],风险指针方法最终使得这些对象完全动态,且同时还是完全无锁的,不管是否有自动垃圾收集支持。
7. 致谢
作者感谢编辑和审阅者对本文给出的有价值的评论。感谢Marc Auslander, Maurice Herlihy, Victor Luchangco, Paul McKenney,Mark Moir, Bryan Rosenburg, Michael Scott, Ori Shalev, Nir Shavit, Yefim Shuf, 和 RobertWisniewski在本工作的不同阶段给出的有用讨论和评论,以及Victor Luchangco建议将指针重命名(pointer renaming)作为指针序(pointer ordering)的替代。
8. 参考资料
[1] T.E. Anderson, B.N. Bershad, E.D.Lazowska, and H.M. Levy,“Scheduler Activations: Effective Kernel Support forthe User-Level Management of Parallelism,” ACM Trans. Computer Systems,vol. 10,no. 1, pp. 53-79, Feb. 1992.
[2] T.H. Cormen, C.E. Leiserson, and R.L.Rivest, Introduction to Algorithms. MIT Press, 1990.
[3] D.L. Detlefs, P.A. Martin, M. Moir, andG.L. Steele Jr., “Lock-Free Reference Counting,” Proc. 20th Ann. ACM Symp. Principlesof Distributed Computing, pp. 190-199, Aug. 2001.
[4] M.B. Greenwald, “Non-BlockingSynchronization and System Design,” PhD thesis, Stanford Univ., Aug. 1999.
[5] T.L. Harris, “A PragmaticImplementation of Non-Blocking Linked Lists,” Proc. 15th Int’l Symp.Distributed Computing, pp.*nbsp;300-314, Oct. 2001.
[6] T.L. Harris, K. Fraser, and I.A. Pratt,“A Practical Multi-Word Compare-and-Swap Operation,” Proc. 16th Int’l Symp.Distributed Computing, pp. 265-279, Oct. 2002.
[7] D. Hendler and N. Shavit, “WorkDealing,” Proc. 14th Ann. ACM Symp. Parallel Algorithms and Architectures, pp.164-172, Aug. 2002.
[8] M.P. Herlihy, “Wait-FreeSynchronization,” ACM Trans. Programming Languages and Systems, vol. 13, no. 1,pp. 124-149, Jan. 1991.
[9] M.P. Herlihy, “A Methodology forImplementing Highly Concurrent Objects,” ACM Trans. Programming Languages andSystems, vol. 15, no. 5, pp. 745-770, Nov. 1993.
[10] M.P. Herlihy, V. Luchangco, and M.Moir, “The Repeat Offender Problem: A Mechanism for Supporting Dynamic-SizedLock-Free Data Structures,” Proc. 16th Int’l Symp. Distributed Computing, pp.339-353, Oct. 2002.
[11] IBM, IBM System/370 ExtendedArchitecture, Principles of Operation, publication no. SA22-7085, 1983.
[12] L.I. Kontothanassis, R.W. Wisniewski,and M.L. Scott, “Scheduler-Conscious Synchronization,” ACM Trans. ComputerSystems, vol. 15, no. 1, pp. 3-40, Feb. 1997.
[13] P.E. McKenney and J.D. Slingwine, “Read-CopyUpdate: Using Execution History to Solve Concurrency Problems,” Proc. 10thIASTED Int’l Conf. Parallel and Distributed Computing and Systems, Oct. 1998.
[14] J.M. Mellor-Crummey and M.L. Scott, “Algorithmsfor Scalable Synchronization on Shared-Memory Multiprocessors,” ACM Trans.Computer Systems, vol. 9, no. 1, pp. 21-65, Feb. 1991.
[15] J.M. Mellor-Crummey and M.L. Scott, “ScalableReader-Writer Synchronization for Shared-Memory Multiprocessors,” Proc. Third ACMSymp. Principles and Practice of Parallel Programming, pp. 106-113, Apr. 1991.
[16] M.M. Michael, “High PerformanceDynamic Lock-Free Hash Tables and List-Based Sets,” Proc. 14th Ann. ACM Symp.Parallel Algorithms and Architectures, pp. 73-82, Aug. 2002.
[17] M.M. Michael, “Safe Memory Reclamationfor Dynamic Lock-Free Objects Using Atomic Reads and Writes,” Proc. 21st Ann.ACM Symp. Principles of Distributed Computing, pp. 21-30, July 2002. earlierversion in Research Report RC 22317, IBM T.J. Watson Research Center, Jan.2002.
[18] M.M. Michael, “CAS-Based Lock-FreeAlgorithm for Shared Deques,” Proc. Ninth Euro-Par Conf. Parallel Processing, pp.651-660, Aug. 2003.
[19] M.M. Michael, “ABA Prevention UsingSingle-Word Instructions,” Technical Report RC 23089, IBM T.J. Watson Research Center,Jan. 2004.
[20] M.M. Michael, “Scalable Lock-FreeDynamic Memory Allocation,” Proc. 2004 ACM SIGPLAN Conf. Programming LanguageDesign and Implementation, June 2004.
[21] M.M. Michael and M.L. Scott, “Simple,Fast, and Practical Non-Blocking and Blocking Concurrent Queue Algorithms,” Proc.15th Ann. ACM Symp. Principles of Distributed Computing, pp. 267-275, May 1996.
[22] M.M. Michael and M.L. Scott, “NonblockingAlgorithms and Preemption-Safe Locking on Multiprogrammed Shared Memory Multiprocessors,”J. Parallel and Distributed Computing, vol. 51, no. 1, pp. 1-26, May 1998.
[23] S. Prakash, Y.-H. Lee, and T. Johnson,“A Nonblocking Algorithm for Shared Queues Using Compare-and-Swap,” IEEE Trans.Computers, vol. 43, no. 5, pp. 548-559, May 1994.
[24] L. Rudolph and Z. Segall, “DynamicDecentralized Cache Schemes for MIMD Parallel Processors,” Proc. 11th Int’lSymp. Computer Architecture, pp. 340-347, June 1984.
[25] O. Shalev and N. Shavit, “Split-OrderedLists: Lock-Free Extensible Hash Tables,” Proc. 22nd Ann. ACM Symp. Principlesof Distributed Computing, pp. 102-111, July 2003.
[26] N. Shavit and D. Touitou, “SoftwareTransactional Memory,” Distributed Computing, vol. 10, no. 2, pp. 99-116, 1997.
[27] H. Tang, K. Shen, and T. Yang, “ProgramTransformation and Runtime Support for Threaded MPI Execution on Shared Memory Machines,”ACM Trans. Programming Languages and Systems, vol. 22, no. 4, pp. 673-700, July2000.
[28] J. Turek, D. Shasha, and S. Prakash, “LockingWithout Blocking: Making Lock Based Concurrent Data Structure Algorithms Nonblocking,”Proc. 11th ACM Symp. Principles of Database Systems, pp. 212-222, June 1992.
[29] J.D. Valois, “Lock-Free Linked ListsUsing Compare-and-Swap,” Proc. 14th Ann. ACM Symp. Principles of DistributedComputing, pp. 214-222, Aug. 1995.
[30] J. Zahorjan, E.D. Lazowska, and D.L.Eager, “The Effect of Scheduling Discipline on Spin Overhead in Shared Memory ParallelSystems,” IEEE Trans. Parallel and Distributed Systems, vol. 2, no. 2, pp.180-198, Apr. 1991.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号