【raft协议-01】 从raft源码看选举
# 1. clone
git clone https://github.com/vision9527/raft-demo
# 2. build
cd raft-demo
go build
# 启动node1:
./raft-demo --http_addr=127.0.0.1:7001 --raft_addr=127.0.0.1:7000 --raft_id=1 --raft_cluster=1/127.0.0.1:7000,2/127.0.0.1:8000,3/127.0.0.1:9000raft_cluster:集群节点;
raft_id:标识这个节点的唯一id,字符串;
raft_addr:raft开启的tcp端口,用来跟其他的节点RPC通信;
http_addr:开启的http端口,非raft内容;
// raft-demo/main.go
func main() {
flag.Parse()
if httpAddr == "" || raftAddr == "" || raftId == "" || raftCluster == "" {
...
return
}
raftDir := "node/raft_" + raftId
os.MkdirAll(raftDir, 0700)
// 初始化raft
myRaft, fm, err := myraft.NewMyRaft(raftAddr, raftId, raftDir)
...
}前面简单,解析命令行参数,再调用myraft.NewMyRaft(raftAddr, raftId, raftDir)。
// raft-demo/myraft/my_raft.go
func NewMyRaft(raftAddr, raftId, raftDir string) (*raft.Raft, *fsm.Fsm, error) {
config := raft.DefaultConfig()
// raftId: "1"
config.LocalID = raft.ServerID(raftId)
// raftAddr: "127.0.0.1:7000"
addr, err := net.ResolveTCPAddr("tcp", raftAddr)
transport, err := raft.NewTCPTransport(raftAddr, addr, 2, 5*time.Second, os.Stderr)
...
}首先是调用raft.DefaultConfig()产生一个默认的配置,这个配置包括心跳超时时长、选举超时时长、节点ID等信息。
raft.NewTCPTransport()函数:
// raft@1.1.2/tcp_transport.go
func NewTCPTransport(
bindAddr string, // 127.0.0.1:7000
advertise net.Addr, // 127.0.0.1:7000 的 tcp地址对象
maxPool int, // 2
timeout time.Duration, // 5s
logOutput io.Writer, // os.Stderr
) (*NetworkTransport, error) {
return newTCPTransport(bindAddr, advertise, func(stream StreamLayer) *NetworkTransport {
return NewNetworkTransport(stream, maxPool, timeout, logOutput)
})
}
// raft@1.1.2/tcp_transport.go
func newTCPTransport(bindAddr string, advertise net.Addr,
transportCreator func(stream StreamLayer) *NetworkTransport) (*NetworkTransport, error) {
// Try to bind
list, err := net.Listen("tcp", bindAddr)
if err != nil {
return nil, err
}
// Create stream
stream := &TCPStreamLayer{
advertise: advertise,
listener: list.(*net.TCPListener),
}
// Verify that we have a usable advertise address
addr, ok := stream.Addr().(*net.TCPAddr)
if !ok {
list.Close()
return nil, errNotTCP
}
if addr.IP.IsUnspecified() {
list.Close()
return nil, errNotAdvertisable
}
// Create the network transport
trans := transportCreator(stream)
return trans, nil
}首先调用net.Listen("tcp", bindAddr)监听127.0.0.1:7000,返回一个Listener接口,用来后面调用Accept。
stream := &TCPStreamLayer{
advertise: advertise, // 127.0.0.1:7000 的 tcp地址对象
listener: list.(*net.TCPListener), // TCPListener是一个具体的接口, 语法:接口静态类型转动态类型
}然后检查两个事情:
-
-
绑定的地址我们没有指定一个具体的ip。没有指定ip就是形如"0.0.0.0" 或 "::",说明在这;
// stream.Addr()返回127.0.0.1:7000 的 tcp地址对象
// 1. 如果不是一个tcp地址,就不玩了
addr, ok := stream.Addr().(*net.TCPAddr)
if !ok {
list.Close()
return nil, errNotTCP
}
// 2. 如果没有指定一个具体的ip,就不玩了
if addr.IP.IsUnspecified() {
list.Close()
return nil, errNotAdvertisable
}然后再回到回调函数trans := transportCreator(stream),传入stream对象。这个时候应该在小本本上记一下stream对象的结构,有哪些字段。
NewNetworkTransport里去。
// stream
// maxPool: 2
// timeout: 5s
// logOutput: os.Stderr
return newTCPTransport(bindAddr, advertise, func(stream StreamLayer) *NetworkTransport {
return NewNetworkTransport(stream, maxPool, timeout, logOutput)
})
:
// raft@1.1.2/net_transport.go
func NewNetworkTransport(
stream StreamLayer, // stream对象
maxPool int, // 2
timeout time.Duration, // 5s
logOutput io.Writer, // os.Stderr
) *NetworkTransport {
logger := hclog.New(&hclog.LoggerOptions{
Name: "raft-net",
Output: logOutput,
Level: hclog.DefaultLevel,
})
config := &NetworkTransportConfig{Stream: stream, MaxPool: maxPool, Timeout: timeout, Logger: logger}
return NewNetworkTransportWithConfig(config)
}先搞一个logger出来,再搞一个看起来是配置的config出来,包含传进来的所有的参数,再调用NewNetworkTransportWithConfig(config),继续跳吧。
NewNetworkTransportWithConfig():
// raft@1.1.2/net_transport.go
func NewNetworkTransportWithConfig(config *NetworkTransportConfig) *NetworkTransport {
...
trans := &NetworkTransport{
connPool: make(map[ServerAddress][]*netConn),
consumeCh: make(chan RPC),
logger: config.Logger, // 名为"raft-net"的logger对象
maxPool: config.MaxPool, // 2
shutdownCh: make(chan struct{}),
stream: config.Stream, // stream对象
timeout: config.Timeout, // 5s
TimeoutScale: DefaultTimeoutScale, // 256 * 1024 256KB 不明白啥意思, 暂时放过
serverAddressProvider: config.ServerAddressProvider, // 没配置过, 默认值, 接口类型, nil
}
// Create the connection context and then start our listener.
trans.setupStreamContext()
go trans.listen()
return trans
}搞一个NetworkTransport对象,这应该就是最终返回的transport对象了。需要注意的是,接收stream是用一个interface接收。这在后面调用listen时会有用。
trans.setupStreamContext(),这个比较简单,就是设置一个基类Context,和一个cancel方法。
func (n *NetworkTransport) setupStreamContext() {
ctx, cancel := context.WithCancel(context.Background())
n.streamCtx = ctx
n.streamCancel = cancel
}trans.listen():
// raft@1.1.2/net_transport.go
func (n *NetworkTransport) listen() {
const baseDelay = 5 * time.Millisecond
const maxDelay = 1 * time.Second
var loopDelay time.Duration
for {
// Accept incoming connections
conn, err := n.stream.Accept() // tcp连接进来
if err != nil {
// 发生错误情况下, sleep一段时间
...
}
// No error, reset loop delay
loopDelay = 0
n.logger.Debug("accepted connection", "local-address", n.LocalAddr(), "remote-address", conn.RemoteAddr().String())
// Handle the connection in dedicated routine
go n.handleConn(n.getStreamContext(), conn)
}
}listen()方法调用了stream.Accept()方法,stream是一个静态类型StreamLayer的interface,内嵌了net.Listener接口,动态类型是TCPStreamLayer的结构体,实现了StreamLayer
// raft@v1.1.2/net_trasport.go
type StreamLayer interface {
net.Listener
// Dial is used to create a new outgoing connection
Dial(address ServerAddress, timeout time.Duration) (net.Conn, error)
}
// raft@v1.1.2/tcp_transport.go
type TCPStreamLayer struct {
advertise net.Addr
listener *net.TCPListener
}
// Dial implements the StreamLayer interface.
func (t *TCPStreamLayer) Dial(address ServerAddress, timeout time.Duration) (net.Conn, error) { ... }
// Accept implements the net.Listener interface.
func (t *TCPStreamLayer) Accept() (c net.Conn, err error) {
return t.listener.Accept()
}
// Close implements the net.Listener interface.
func (t *TCPStreamLayer) Close() (err error) { ... }
// Addr implements the net.Listener interface.
func (t *TCPStreamLayer) Addr() net.Addr { ... }所以调用最终就是调用 t.listener.Accept()。
每当有连接进来,就开一条狗处理与这个连接相关的通信消息:
conn, err := n.stream.Accept() // tcp连接进来
// Handle the connection in dedicated routine
go n.handleConn(n.getStreamContext(), conn)回到最初的调用,这个时候可以画出transport, err := raft.NewTCPTransport(raftAddr, addr, 2, 5*time.Second, os.Stderr) transport的画像了:
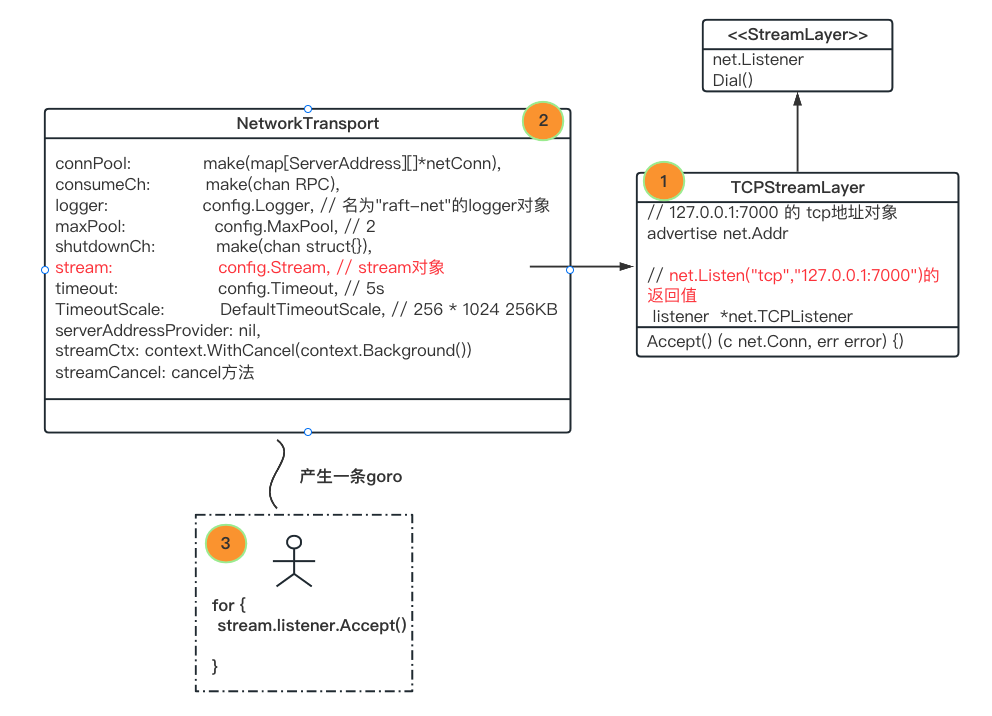
网络连接部分先到此为止。
// raft-demo/myraft/my_raft.go
func NewMyRaft(raftAddr, raftId, raftDir string) (*raft.Raft, *fsm.Fsm, error) {
...
// "node/raft_1"
snapshots, err := raft.NewFileSnapshotStore(raftDir, 2, os.Stderr)
...
}看名字就是快照的意思,没怎么看懂,暂时略过。
// raft-demo/myraft/my_raft.go
func NewMyRaft(raftAddr, raftId, raftDir string) (*raft.Raft, *fsm.Fsm, error) {
...
// "node/raft_1/raft-log.db"
logStore, err := raftboltdb.NewBoltStore(filepath.Join(raftDir, "raft-log.db"))
// "node/raft_1/raft-stable.db"
stableStore, err := raftboltdb.NewBoltStore(filepath.Join(raftDir, "raft-stable.db"))
...
}现在只需要知道,这两个用来做持久化存储。
log用来存日志,stable用来存任期term,后面分析选举流程时会分清。
这里创建了(不存在时创建,存在时打开)两个持久化的文件,一个叫log,一个叫stable。
bolt是一个key-value的单机文件数据库,把文件分成一个个与操作系统页大小相同的page,一般是4kb,再把这个文件mmap到内存,采用了B+树索引,且支持事务。raft在它上面进行了封装,成了另一个库raft-boltdb。为了分类数据,bolt分为了bucket(桶),存取key的时候必须指定是在哪个bucket名下存取。
// raft-demo/myraft/my_raft.go
func NewMyRaft(raftAddr, raftId, raftDir string) (*raft.Raft, *fsm.Fsm, error) {
...
fm := fsm.NewFsm()
...
}目前这个小例子只是实现了Apply()方法,简单的设置值。还不清楚流程是啥样的。
需要自己实现的有限状态机:finite-state machine https://pkg.go.dev/github.com/hashicorp/raft#FSM
// raft-demo/myraft/my_raft.go
func NewMyRaft(raftAddr, raftId, raftDir string) (*raft.Raft, *fsm.Fsm, error) {
...
rf, err := raft.NewRaft(config, fm, logStore, stableStore, snapshots, transport)
...
}传入前面创建的对象,进入raft.NewRaft()。
raft.NewRaft()
1) logs、stable
// raft@v1.1.2/api.go
func NewRaft(conf *Config, fsm FSM, logs LogStore, stable StableStore, snaps SnapshotStore, trans Transport) (*Raft, error) {
...
// keyCurrentTerm: []byte("CurrentTerm")
currentTerm, err := stable.GetUint64(keyCurrentTerm)
lastIndex, err := logs.LastIndex()
...
}接着在logs里取,logs不一样,用cursor移到bucket下的最后一行,取最后一行数据。这里一开始是空,当然是取不到,lastIndex = 0。之后,会往stable里写一次CurrentTerm,值为0。
首先从stable里取一下CurrentTerm的值,如果没有这个key,则返回0。一开始肯定是没有的,返回0。前面说了,存取bolt的时候必须指定buckt名,这里没有指定,看来是raft帮我们指定了,stable里所有的key操作都是在名为conf这个bucket下。
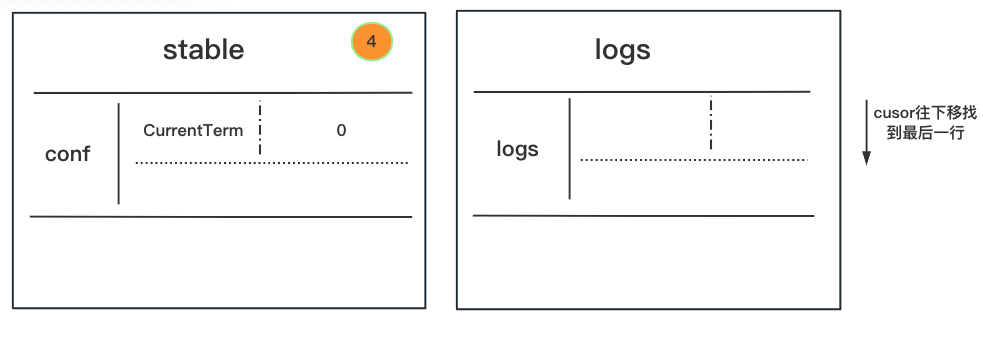
2) 设置当前状态为Follower
r.setState(Follower)
r.goFunc(r.run)
r.goFunc(r.runFSM)
r.goFunc(r.runSnapshots)开三个goro,节点状态变更在r.run goro,因为当前状态是Follower,执行runFollower函数。
4) runFollower()
// raft@v1.1.2/raft.go
func (r *Raft) runFollower() {
didWarn := false
for r.getState() == Follower {
select {
...
case b := <-r.bootstrapCh:
b.respond(r.liveBootstrap(b.configuration))
case <-heartbeatTimer:
// 1. 当前有无其他节点配置, 没有, continue
// 2. 状态变为Candidate, return
...
}
}
}监听了很多的通道,与启动相关的目前就两个:
-
bootstrapCh,这是main goro调用r.BootstrapCluster(configuration)放进来的,包含其他节点的配置信息,这里是参数raft_cluster的配置:1/127.0.0.1:7000,2/127.0.0.1:8000,3/127.0.0.1:9000,三个server。
-
heartbeatTimer,Follower状态超时后(与Leader心跳超时、或者启动时初始状态超时),状态转换为Candidate状态。
这个也比较关键,值得好好看,传入的b.configuratoin是这样一个结构:
Configuration{
Servers: [
{
Suffrage: Voter,
ID: "1",
Address: "127.0.0.1:7000",
},
{
Suffrage: Voter,
ID: "2",
Address: "127.0.0.1:8000",
},
{
Suffrage: Voter,
ID: "3",
Address: "127.0.0.1:9000",
},
]
}
// raft@v1.1.2/future.go
// b
type bootstrapFuture struct {
deferError
configuration Configuration
}
// raft@v1.1.2/configuration.go
type Configuration struct {
Servers []Server
}
// raft@v1.1.2/raft.go
func (r *Raft) liveBootstrap(configuration Configuration) error {
// Use the pre-init API to make the static updates.
err := BootstrapCluster(&r.conf, r.logs, r.stable, r.snapshots,
r.trans, configuration)
if err != nil {
return err
}
...BootstrapCluster()函数做了以下事情:
-
stable里取一下当前任期CurrentTerm的值,如果 >0,返回ErrCantBootstrap错误。前面分析过,stable存的CurrentTerm值为0,所以继续往下走;
-
logs里取一下最后一条记录,如果有,返回ErrCantBootstrap错误。现在是没有,继续往下走;
-
snaps里取一下,如果有,返回ErrCantBootstrap错误。现在是没有,继续往下走;
-
stable写入当前任期CurrentTerm,值为1;
-
logs写入日志:
entry := &Log{ Index: 1, Term: 1, Type: LogConfiguration Data: 编码了的,其他节点配置信息 }现在, stable、logs里有初始值了,从这里也知道,初始term值是1,与文档对得上。
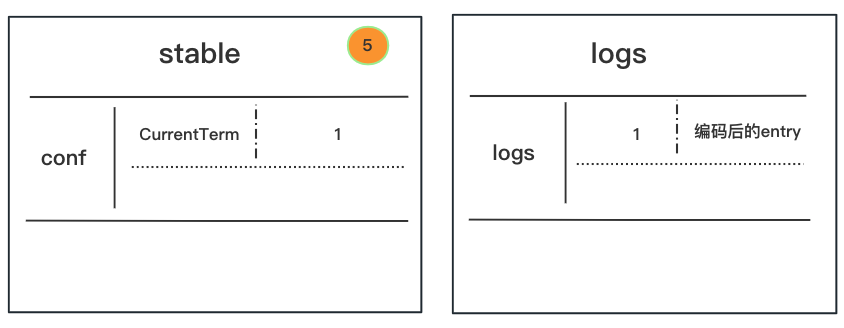
// raft@v1.1.2/raft.go
func (r *Raft) liveBootstrap(configuration Configuration) error {
// Use the pre-init API to make the static updates.
err := BootstrapCluster(&r.conf, r.logs, r.stable, r.snapshots,
r.trans, configuration)
if err != nil {
return err
}
// Make the configuration live.
// 1. 从logs取第一条日志, 也就是刚刚写入的
var entry Log
if err := r.logs.GetLog(1, &entry); err != nil {
panic(err)
}
// 2. 再写一下任期1
r.setCurrentTerm(1) // 内存与持久化
r.setLastLog(entry.Index, entry.Term)
// 3.
r.processConfigurationLogEntry(&entry)
return nil
}
-
存一下最近的节点配置,主要是设置一下:
r.configurations.latest = 其他节点信息配置
r.configurations.latestIndex = 1 // 在logs的Index
至此,配置有了,可以进入Candidate状态了。

// raft@v1.1.2/raft.go
func (r *Raft) runCandidate() {
r.logger.Info("entering candidate state", "node", r, "term", r.getCurrentTerm()+1)
// 1. 异步广播其他节点, 让他们投票给我
voteCh := r.electSelf()
// 2. 启动计时器
electionTimer := randomTimeout(r.conf.ElectionTimeout) // 1s
...
}
// raft@v1.1.2/raft.go
func (r *Raft) electSelf() <-chan *voteResult {
// 1. 搞个chan
respCh := make(chan *voteResult, len(r.configurations.latest.Servers))
// 2. 任期+1, 且持久化写入stable, 当前任期 = 2
r.setCurrentTerm(r.getCurrentTerm() + 1)
// 3. 从内存取最新log的Index、Term, 现在的Index = 1, Term = 1
lastIdx, lastTerm := r.getLastEntry()
// 4. 构造请求数据
req := &RequestVoteRequest{
RPCHeader: r.getRPCHeader(),
Term: r.getCurrentTerm(), // 当前term
Candidate: r.trans.EncodePeer(r.localID, r.localAddr),
LastLogIndex: lastIdx, // 最新的log index
LastLogTerm: lastTerm, // 最新的log term
LeadershipTransfer: r.candidateFromLeadershipTransfer,
}
// 5. 遍历节点, 发送rpc投票消息
// For each peer, request a vote
for _, server := range r.configurations.latest.Servers {
if server.Suffrage == Voter {
// 给自己投赞成票
if server.ID == r.localID {
// Persist a vote for ourselves
r.persistVote(req.Term, req.Candidate)
// Include our own vote
respCh <- &voteResult{
RequestVoteResponse: RequestVoteResponse{
RPCHeader: r.getRPCHeader(),
Term: req.Term,
Granted: true,
},
voterID: r.localID,
}
} else {
askPeer(server)
}
}
}
return respCh
}需要注意的点:
-
每次请求他人投票前,增加自己的当前任期CurrentTerm,并持久化到stable。如果一直在选举阶段,任期值就会一直加。
-
发送RPC消息是通过transport,transport里有个map,映射地址 ---> 连接对象Conn,用来缓存。
-
因为每个节点只能投一票,要记录下投出的票,包括自己投给自己的票也要记录下来。通过持久化到stable的LastVoteTerm、LastVoteCand两个key实现。
// raft@v1.1.2/raft.go
func (r *Raft) runCandidate() {
...
// Tally the votes, need a simple majority
grantedVotes := 0
votesNeeded := r.quorumSize() // 法定人数
r.logger.Debug("votes", "needed", votesNeeded)
for r.getState() == Candidate {
select {
// rpc消息
case rpc := <-r.rpcCh:
r.processRPC(rpc)
// 收到其他节点投票结果
case vote := <-voteCh:
// Check if the term is greater than ours, bail
if vote.Term > r.getCurrentTerm() {
r.logger.Debug("newer term discovered, fallback to follower")
r.setState(Follower)
r.setCurrentTerm(vote.Term)
return
}
// Check if the vote is granted
if vote.Granted {
grantedVotes++
r.logger.Debug("vote granted", "from", vote.voterID, "term", vote.Term, "tally", grantedVotes)
}
// Check if we've become the leader
if grantedVotes >= votesNeeded {
r.logger.Info("election won", "tally", grantedVotes)
r.setState(Leader)
r.setLeader(r.localAddr)
return
}
}
}
}判断是否赢得大多数人的选票,是就成为Leader。
这里有个问题,什么情况下投票结果的Term会 > 当前节点的Term?
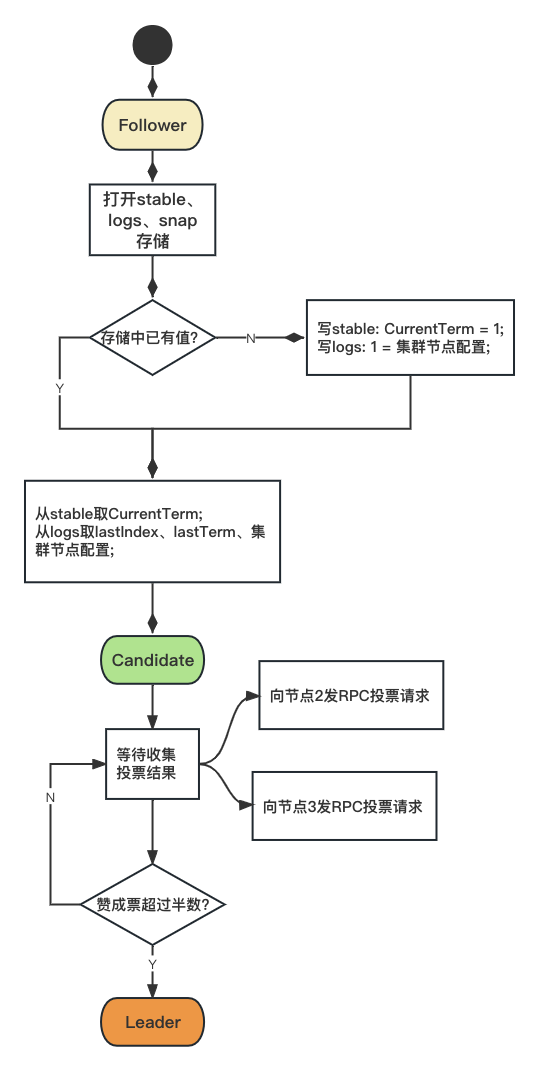
到此为止,从Candidate视角来看,Candidate节点成为了Leader。
// raft@v1.1.2/net_transport.go
func (n *NetworkTransport) listen() {
for {
// Accept incoming connections
conn, err := n.stream.Accept() // tcp连接进来, 返回原生的Conn
n.logger.Debug("accepted connection", "local-address", n.LocalAddr(), "remote-address", conn.RemoteAddr().String())
// Handle the connection in dedicated routine
go n.handleConn(n.getStreamContext(), conn)
}
}
// raft@v1.1.2/net_transport.go
func (n *NetworkTransport) handleCommand(r *bufio.Reader, dec *codec.Decoder, enc *codec.Encoder) error {
// 1. 先读一个字节, 消息类型
rpcType, err := r.ReadByte()
if err != nil {
return err
}
// Create the RPC object
respCh := make(chan RPCResponse, 1)
rpc := RPC{
RespChan: respCh,
}
isHeartbeat := false
switch rpcType {
case rpcRequestVote:
var req RequestVoteRequest
// 2. 解码剩下的字节流数据
if err := dec.Decode(&req); err != nil {
return err
}
rpc.Command = &req
...
}
// Dispatch the RPC
select {
// 放进无缓冲通道
case n.consumeCh <- rpc:
}
// Wait for response
RESP:
select {
case resp := <-respCh:
// Send the error first
respErr := ""
if resp.Error != nil {
respErr = resp.Error.Error()
}
if err := enc.Encode(respErr); err != nil {
return err
}
// Send the response
if err := enc.Encode(resp.Response); err != nil {
return err
}
case <-n.shutdownCh:
return ErrTransportShutdown
}
return nil
}
-
先从流读一个字节,标识RPC消息类型,这里是投票请求消息rpcRequestVote;
-
解码数据;
-
放进通道,阻塞等待取走。
// raft@v1.1.2/raft.go
func (r *Raft) runFollower() {
...
for r.getState() == Follower {
select {
case rpc := <-r.rpcCh:
r.processRPC(rpc)
最终是调用requestVote()函数:
// requestVote is invoked when we get an request vote RPC call.
func (r *Raft) requestVote(rpc RPC, req *RequestVoteRequest) {
// Setup a response
resp := &RequestVoteResponse{
RPCHeader: r.getRPCHeader(),
Term: r.getCurrentTerm(), // 回应的是节点的当前Term
Granted: false,
}
var rpcErr error
defer func() {
rpc.Respond(resp, rpcErr)
}()
// Check if we have an existing leader [who's not the candidate] and also
// check the LeadershipTransfer flag is set. Usually votes are rejected if
// there is a known leader. But if the leader initiated a leadership transfer,
// vote!
candidate := r.trans.DecodePeer(req.Candidate)
// 1. 检测当前是否已经有了Leader
// 如果有, 且我们没有明确指定当前新节点是用来替换已有的Leader, 那应该维持现有的Leader, 投反对票
if leader := r.Leader(); leader != "" && leader != candidate && !req.LeadershipTransfer {
r.logger.Warn("rejecting vote request since we have a leader",
"from", candidate,
"leader", leader)
return
}
// 2. 我的Term比你大, 投反对票
if req.Term < r.getCurrentTerm() {
return
}
// 3. 我的Term没你大, 那我把自己的Term改成跟你一样大
if req.Term > r.getCurrentTerm() {
// Ensure transition to follower
r.logger.Debug("lost leadership because received a requestVote with a newer term")
r.setState(Follower)
r.setCurrentTerm(req.Term)
resp.Term = req.Term
}
// Check if we have voted yet
lastVoteTerm, err := r.stable.GetUint64(keyLastVoteTerm)
if err != nil && err.Error() != "not found" {
r.logger.Error("failed to get last vote term", "error", err)
return
}
lastVoteCandBytes, err := r.stable.Get(keyLastVoteCand)
if err != nil && err.Error() != "not found" {
r.logger.Error("failed to get last vote candidate", "error", err)
return
}
// Check if we've voted in this election before
// 4. 我上次也是投针对这个Term投的票
if lastVoteTerm == req.Term && lastVoteCandBytes != nil {
r.logger.Info("duplicate requestVote for same term", "term", req.Term)
// 投给的是同一个人, 再投你赞成票, 反正是幂等的
if bytes.Compare(lastVoteCandBytes, req.Candidate) == 0 {
r.logger.Warn("duplicate requestVote from", "candidate", req.Candidate)
resp.Granted = true
}
// 我投的不是同一个人, 我投过了, 不能再投, 默认投反对
return
}
// Reject if their term is older
lastIdx, lastTerm := r.getLastEntry()
// 5. 我的日志上记录的我上次的Term 比你的大, 反对
if lastTerm > req.LastLogTerm {
r.logger.Warn("rejecting vote request since our last term is greater",
"candidate", candidate,
"last-term", lastTerm,
"last-candidate-term", req.LastLogTerm)
return
}
// 6. 我的日志上记录我们的Term一样, 但我的内容比你多, 反对
if lastTerm == req.LastLogTerm && lastIdx > req.LastLogIndex {
r.logger.Warn("rejecting vote request since our last index is greater",
"candidate", candidate,
"last-index", lastIdx,
"last-candidate-index", req.LastLogIndex)
return
}
// Persist a vote for safety
// 7. 记录下我是对哪个Term投票, 投给的谁
if err := r.persistVote(req.Term, req.Candidate); err != nil {
r.logger.Error("failed to persist vote", "error", err)
return
}
resp.Granted = true
r.setLastContact()
return
}组装投票结果后,返回给Candiate节点。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号