实验二
作业一
(1)实验内容
o 要求:要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库
代码如下:
import urllib.request
import re
import pandas as pd
import pathlib
desktopDir = str(pathlib.Path.home()).replace('\\','\\\\') + '\\Desktop'
url = 'http://www.weather.com.cn/weather/101010100.shtml'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.47'
}
req = urllib.request.Request(url=url,headers=headers)
data = urllib.request.urlopen(req).read().decode()
s = '<li class="sky skyid.*?">.*?<h1>(.*?)</h1>.*?<p title=.*? class="wea">(.*?)</p>.*?<span>(.*?)</span>.*?<i>(.*?)</i>.*?</li>'
data = re.compile(s,re.S).findall(data)
count = 1
index_ls = ['序号','地区','日期','天气信息','温度']
dic = {i:[] for i in index_ls}
for d in data:
dic['序号'].append(count)
count += 1
dic['地区'].append('北京')
dic['日期'].append(d[0])
dic['天气信息'].append(d[1])
dic['温度'].append(d[2] + '/' + d[3])
df = pd.DataFrame(dic)
df.to_excel(desktopDir + '\\data1.xlsx',index=False)
结果如下:
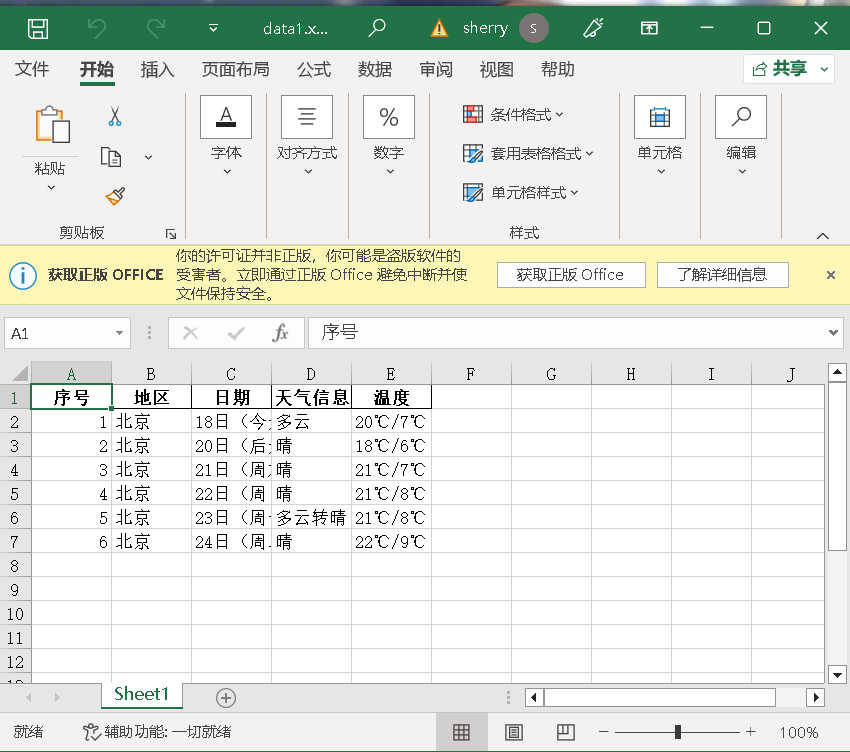
(2)心得体会
进一步的了解了如何用re库便捷的寻找标签,爬取数据,学习了re库的findall函数的基本用法
作业二
(1)实验内容
o 要求:用 requests 和 BeautifulSoup 库方法定向爬取股票相关信息,并存储在数据库中。
代码如下:
import urllib.request
import re
import json
import pandas as pd
import pathlib
desktopDir = str(pathlib.Path.home()).replace('\\','\\\\') + '\\Desktop'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.47'
}
data_ls = []
count_ls = []
count = 1
for i in range(1,6):
page_num = i
url = 'http://25.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124021313927342030325_1696658971596&pn=%d&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f2,f3,f4,f5,f6,f7,f12,f14,f15,f16,f17,f18&_=1696658971636'
url = url % page_num
req = urllib.request.Request(url=url,headers=headers)
data = urllib.request.urlopen(req).read().decode()
data = re.compile('"diff":\[(.*?)\]',re.S).findall(data)
for one_data in re.compile('\{(.*?)\}',re.S).findall(data[0]):
data_dic = json.loads('{' + one_data + '}')
data_ls.append(data_dic)
count_ls.append(count)
count += 1
columns={'f2':'最新价','f3':'涨跌幅(%)','f4':'涨跌额','f5':'成交量','f6':'成交额','f7':'振幅(%)','f12':'代码','f14':'名称','f15':'最高',
'f16':'最低','f17':'今开','f18':'昨收'}
num = pd.DataFrame(count_ls)
# print(num)
df = pd.DataFrame(data_ls)
df.rename(columns=columns,inplace=True)
df.insert(0,column='序号',value=num)
df.to_excel(desktopDir + '\\data2.xlsx',index=False)
结果如下:
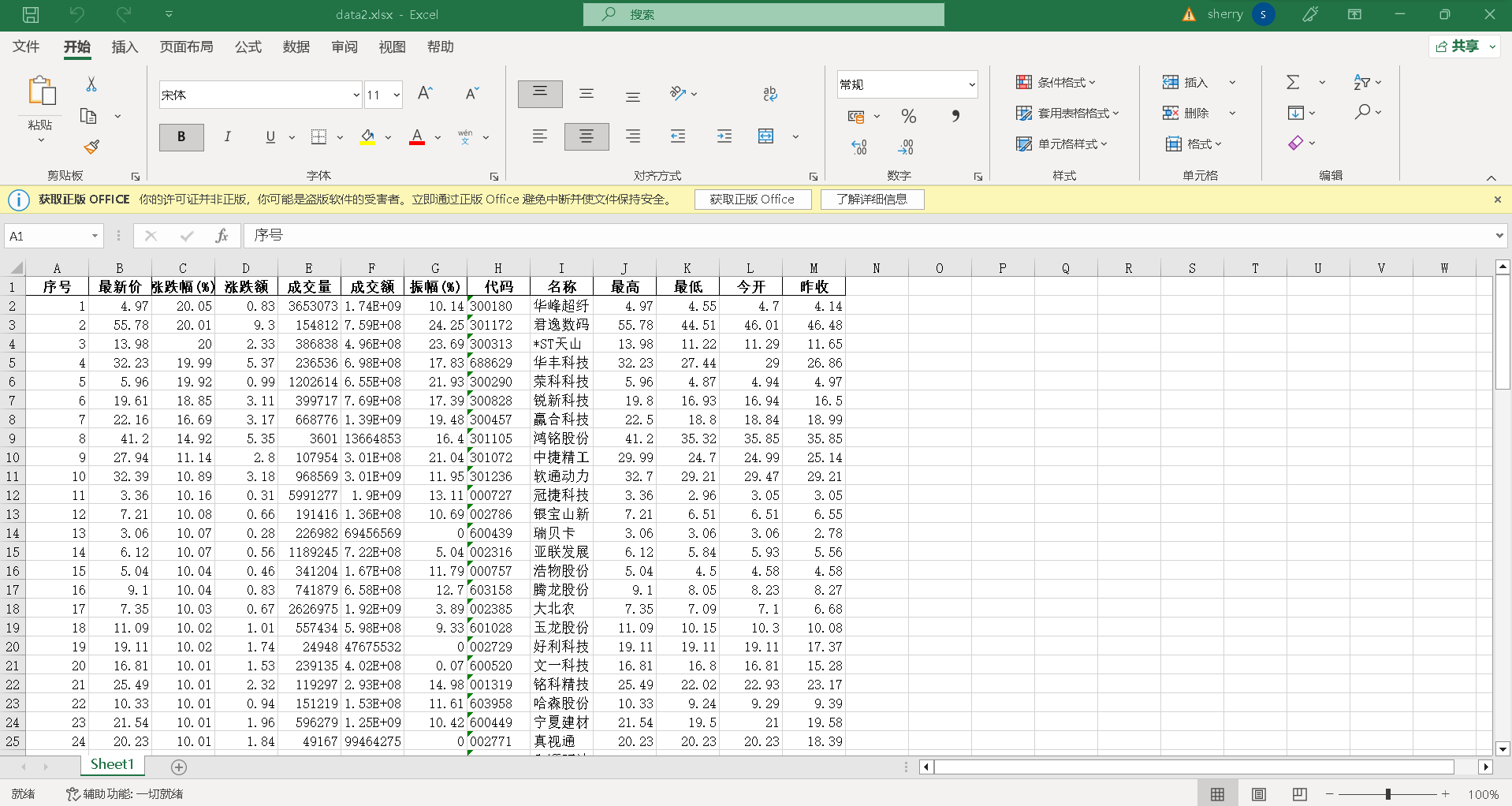
(2)心得体会
了解的如何通过抓包获取网页数据,学习了json库的基本用法
作业三
(1)实验内容
o 要求:爬取中国大学 2021 主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器 F12 调试分析的过程录制 Gif 加入至博客中。
代码如下:
import urllib.request
import re
import pathlib
import pandas as pd
import pathlib
desktopDir = str(pathlib.Path.home()).replace('\\','\\\\') + '\\Desktop'
desktopDir = str(pathlib.Path.home()).replace('\\','\\\\') + '\\Desktop'
url = 'https://www.shanghairanking.cn/_nuxt/static/1697106492/rankings/bcur/2021/payload.js'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.47'
}
req = urllib.request.Request(url=url,headers=headers)
data = urllib.request.urlopen(req).read().decode()
names = re.findall("univNameCn:(.*?),univNameEn",data)
Category = re.findall("univCategory:(.*?),province",data)
province = re.findall("province:(.*?),",data)
scores = re.findall("score:(.*?),ranking",data)
res = r'function\((.*?)\).*?\{.*?indList.*?\}.*?\((.*?)\).*?'
kvdata = re.compile(res).search(data)
keys = kvdata.group(1).split(',')
values = kvdata.group(2)
values = values.replace('"2023,2022,2021,2020"','""')
values = values.split(",")
values = values[:-3]
dic = dict(zip(keys,values))
for i in range(len(names)):
names[i] = names[i].replace('"','')
for i in range(len(scores)):
score = dic.get(scores[i],-1)
scores[i] = scores[i] if score == -1 else score
for i in range(len(province)):
province[i] = dic.get(province[i],"").replace('"',"")
for i in range(len(Category)):
Category[i] = dic.get(Category[i],"").replace('"',"")
dic = {'排名':list(range(1,len(names)+1)),
'学校':names,
'省市':province,
'类型':Category,
'总分':scores}
df = pd.DataFrame(dic)
df.to_excel(desktopDir + '\\data3.xlsx',index=False)
结果如下:
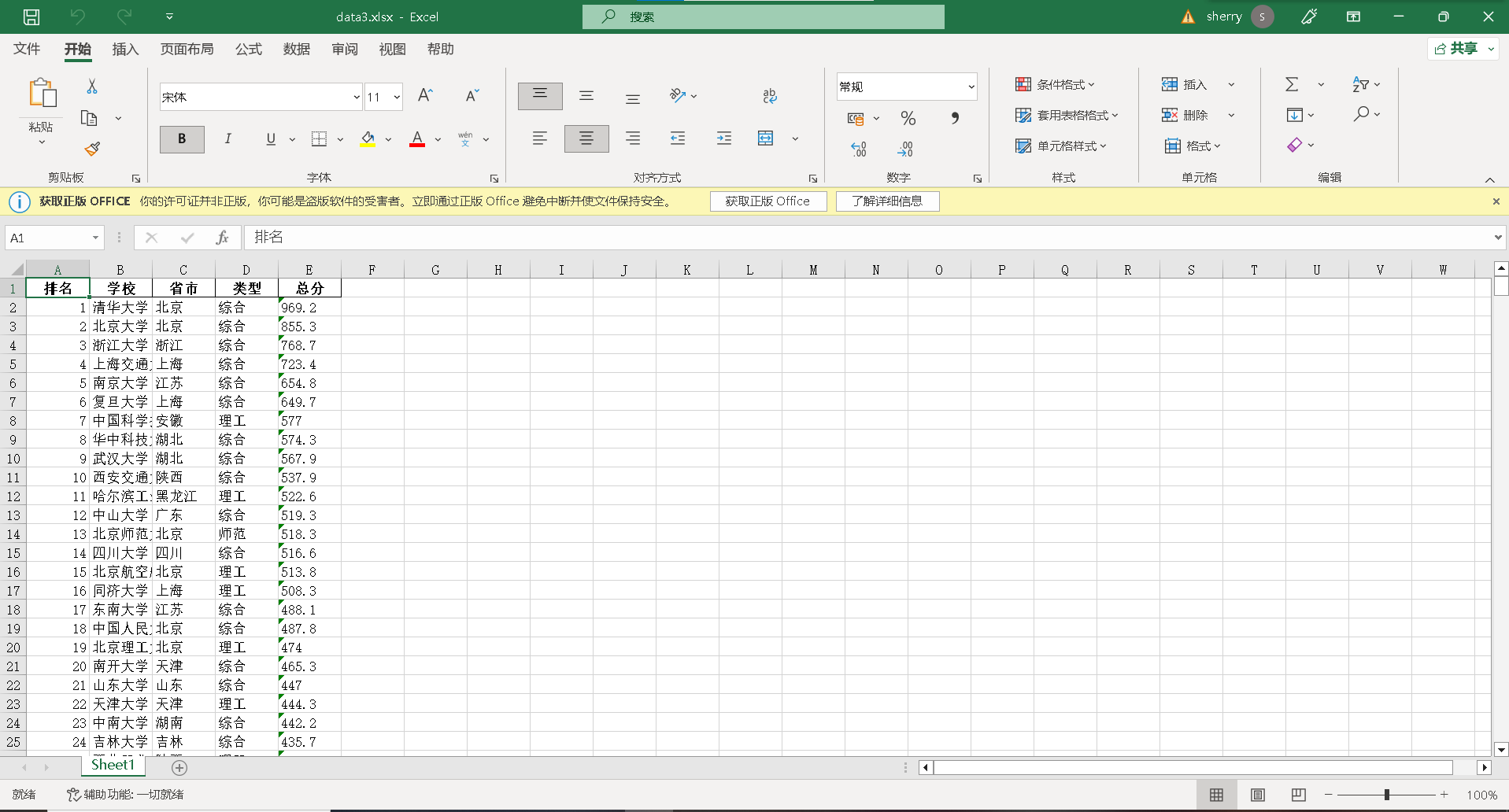
F12调试分析的过程Gif 如下
(2)心得体会
此题与第二题做法类似,不同的是,该题使用字典映射对数据进行了简单的加密,需要对爬取到的数据做进一步处理才能得到正确的结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号