
关于深度学习中的一些疑惑
本文主要是在深度学习中自己的一些疑惑,从这些问题中从而更好理解其中的原理。学习的过程就是提出问题,然后解决问题,而交互式大模型正好很适合自我驱动的学习。
- 为何需要卷积网络
答:传统神经网络中每个神经元都要进行全连接,从而大量权重。而卷积神经网络利用局部感知概念,即图像中邻近区域的相关性,参数量小很多。为了解决神经网络层数增加梯度消失的问题,就有了ResNet。
- 为何要引入Attention机制
Attention是为了解决长序列转化到定长向量时信息损失问题,特别是在Seq2Seq网络结构中。由于编码后送入解码器的定长向量会遗忘之前信息,而Attention可以让其更注意一些词汇。
- TextBoxes有什么改进
Textbox对SSD的改进有卷积核从3x3变为1x5,更适合捕捉文本的横向特征。Textboxes++在TextBoxes基础上改进,支持检测任意角度的文本。而卷积核从1x5->3x5。
- 什么是感受野
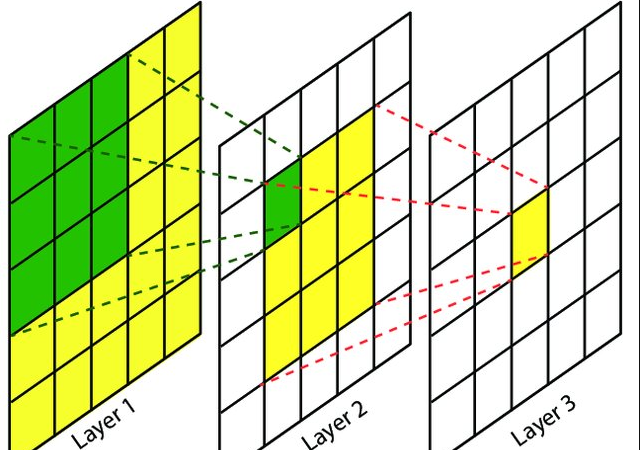
如上图所示,第1层的感受野为1,而第2层的感受野为3,第3层的感受野为5。后面层的感受野可以看成是图像经过前面卷积层处理后的汇聚的一种表现。比如第2层中绿色的一格可以看成是前面3x3处理后得到的,是一种浓缩。而第3层的黄色一格等同于第1层5x5的浓缩。因为第3层中1个单元等于第2层与3x3卷积后才得到的,而第2层的1个单元有等价于第1层与3x3卷积得到的,因此第3层的1个单元等同于第1层与5x5卷积得到的结果。
- 输入特征图经过1x1卷积处理,通道数为何被压缩一半
实际上通道数减少一半不是因为1x1卷积引起的,而是设定的通道数减半了,1x1卷积只是参与其运算。例如YOLOv5的Bottleneck模块输入特征图为HxWx256,此时使用128个1x1卷积核,其中128个是输出通道,1x1是参与计算,输入通道是256,每个通道结果为HxW,因此通道数被压缩一半。
