

今日:我要猛猛科研!!
1.今天降温冻得不行。早上洗澡回学校,路上和亮聊硕博连读志愿者,形式大于过程。
2.早上中午下午读GAP这篇文章,总结笔记。中午去咖喱屋吃了饭,买了杯瑞幸的抹茶回来,半路上在湖边椅子坐了会儿拍拍照,被亲妈以为抑郁了,笑嘻了。和祥聊国际局势,不想聊了接着看文章。
3.下午三点多把文章看完了,录取结果还没出很忐忑,哎哟卧槽总想看手机。一直在配那个屌环境。
4.吃晚饭前以为配好了,满意地自己去吃了。回来发现还是不行,我草了,晚上继续配环境。而且志愿应该是寄了。配到十点多,我真草了。
GAP: Gaussianize Any Point Clouds with Text Guidance收获感悟
粗读:
1.总体工作是把输入的3d点云转化成3d高斯表示(Point-to-Gaussian Generation),输入3d点云和文字引导(几何先验+文生图diffusion大模型),在surface render上下了功夫(提出一种约束方法)。
2.三个贡献:①融合了几何先验+大模型的框架 ②高斯优化框架,表面锚定约束 ③实验表现牛逼
3.写作思路可以学一下,逻辑很清晰没废话,每句话干啥已标注在zotero中。
精读:
1.相关工作部分
①Texture Generation
早期用GAN,现在多用文生图diffusion作先验,也有用深度当先验的,还有用UV域的几何先验当先验的。


②Rendering-Driver 3D Representation
Mesh还是最主流,但是纹理分辨率和UV参数化有限制。NeRF可以体渲染性能挺牛的,但是计算开销巨大。相比而言3dgs省时又省力。(有夸大自己研究内容的嫌疑)
③3DGS Generation Methods
这段写作逻辑也不错。隐式表示的研究很多,推广到3dgs这种显式的上了。不用生成模型的重建方法生成不了多样的形状,条件生成能力弱。最近的3d点云到3d高斯表示方法太依赖点云的RGB值输入,反正也是不好。
2.方法部分
从点云P里重建高斯G,通过文本提示c约束。
①高斯初始化
基本:协方差矩阵定义高斯的形状、朝向和范围。球谐函数记录颜色、不透明度。
初始化:把高斯基元的中心位置σi映射到坐标里。UDF代表Unsigned Distance Field无符号距离场,用CAP-UDF方法找法向量。用2dgs取代3dgs,对几何表示更牛。


②多视角图像修复与更新 (Inpaint v.修复)
由一系列确定的视角,逐步生成有联系的高斯球,再结合深度图。渲染图象Ij+深度图Dj+掩码Mj+文本提示c一起被输入进哪个depth-aware inpainting model(深度感知修复模型)中。
深度感知修复模型:作为外观的生成模型。首先把输入的掩码图像I和深度图D编码到潜空间的z0中,每个timestep都要根据掩码再编一回。
更新修复:同样一块儿区域有可能被修复模型猜出来不同的外观,所以需要把掩码分成generate,keep和update三部分。generate负责之前没生成过的空白区域,keep负责之前已经处理过不能更好了的,update负责看看有没有基于观察方向和法线更新的区域。同时还定义了一个similarity,用来量化从不同角度视角看表面细节的可观测性。
③高斯优化
对于给定视角vj,可以用修复模型生成外观Ij,然后优化G。对每个视点只进行一次优化,且只修改表面能见的高斯球。
表面锚固(Surface-anchoring)机制:偏离表面位置的高斯球最难搞,会产生错误的遮挡关系。引入一种距离损失Ldistance = ∥fu(σi)∥2。
尺度限制:过大的高斯球会影响几何形状。引入尺度损失Lscale = (min(max(si), τ) − max(si))2 ,其中si是高斯球协方差矩阵里的那个尺度因子,τ是预先定义的阈值。
渲染限制:损失由L1损失+D-SSIM损失组成。Lrendering = 0.8L1(I′j , Ij) + 0.2LD−SSIM (I′j, Ij),其中0.8和0.2是自己填的超参数。
综上所述,总体损失为L = Lrendering + αLdistance + βLscale。



③基于扩散的高斯修补
对于看不见的区域修补还是很难。运用跨多视角的高斯选择策略,可以认出没被任何视角渲染图优化过的高斯球。对于位置和法线方向已被预测、但仍未见的高斯球,就要多关注其其余属性,比如颜色、尺寸、不透明度等。
颜色:用一种从附近的高斯球中传播的扩散方法。引入加权算法,同时规范空间接近性、几何一致性和不透明度可靠性。权重是由这仨东西的算式乘起来的,有权重就可以计算颜色属性了。

尺寸:由高斯球最近的邻居(包括已优化过的和不可见的)决定,规范邻居的空间接近性。是一个用距离算出来求和的式子。

不透明度:基于密度控制,半径ρ内的不透明度与局部高斯密度成反比。P代表半径ρ内相邻的高斯球数量,P0是参考阈值。
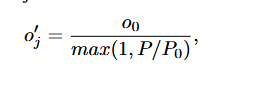
3.实验部分
分别比较说明:文字驱动的外观生成能力、3d点云到3d高斯表示能力、在真实世界扫描点云上的能力、场景点云表示的能力、消融实验。
①文本驱动的外观生成
数据集:Objaverse,225种有纹理的mesh网格共410个。只从3D mesh模型里采样100K个点作为点云输入(老方法需要输入mesh文件)。
三个评价指标:FID+KID(前面笔记里有)用来评估图像画质,CLIP分数用来测量图文对齐程度。
所有方法都使用相同的文本prompt来描述每个对象,从固定视点以1024×1024像素的高分辨率渲染所有对象。为了公平对比,把生成的也转化成UV贴图了,GAP的细节比起传统的方法更牛逼。图文对齐是找志愿者打主官分的,也更牛逼。
②点云到高斯球生成
数据集:DeepFashion3D和ShapeNet椅子类(DiffGS老朋友),同样只从3D mesh模型里采样100K个点作为点云输入(这里的对比方法也是输入100K个点)。
评价指标:没列表,只有视觉效果。
喷了老方法,第一个颜色浮夸,后两个受限于有限分辨率,细节很差(对自己的老作品DiffGS不舍得喷)。
③扫描输入(真实世界)的高斯球生成
数据集:SRB(Scan-to-Reality Benchmark)和DeepFashion3D,这俩都包括直接拿深度传感器捕获的点云,直接输入。
评价指标:又没列表,只有视觉效果。
甚至没跟别人比,只是拿两个生活里的东西重建展示了一下,确实纹理效果不错。
④场景级别(尺度)的高斯球生成
数据集:3D-FRONT(合成的多样室内环境数据集),从3D mesh模型里采样500K个点作为点云输入。3D Scene(真实世界,复杂的拓扑、点云密度、扫描伪影),直接把点云导入。
评价指标:没列表,只有视觉效果。
喷了老方法,一个到大场景直接寄了,另一个得优化+LoRA微调,本方法在大场景很牛。真实世界的在补充材料里,还没看。
⑤消融实验
数据集:没说。
评价指标:FID+KID、CLIP Score,这些指标是在从多个视点捕获的渲染图像上计算的。
分别对尺度损失Lscale、距离损失Ldistance和高斯修补模型进行消融。证明了尺度损失能规范高斯球别变老大导致畸变,距离损失能规范高斯球别从表面偏离走从而保持几何一致性,基于扩散的高斯修复模型确保在难以观察到的区域也能被高斯球覆盖。
关于CUDA版本的问题收获感悟
pip install -r requirements.txt --no-build-isolation ...这个指令有点牛逼,解除环境隔离
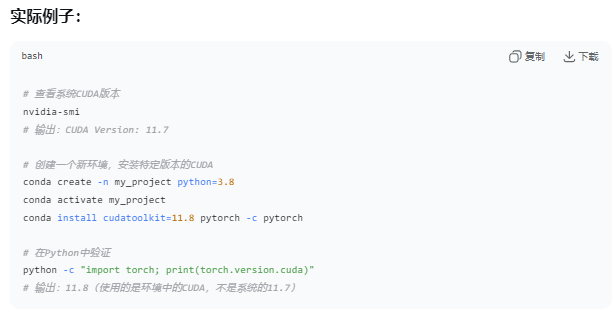
conda install cuda-nvcc=11.6 -c nvidia ...强制安装所需的CUDA版本,省得一直被服务器那个12.2的搞


 浙公网安备 33010602011771号
浙公网安备 33010602011771号