



1.早上吃了昨晚买的糕点和俩鸡蛋,收拾收拾回学校。看见俞奶奶陪姥姥去外面溜达,和姥爷打完招呼回学校实验室。
2.整理了昨天DDPM模型学习过程。中午买了个馅饼肉夹馍坐湖边吃了,挺惬意。下午去做实验,回来跑会儿diffusion代码,在MNIST上敲出来了。不开会了很爽。
3.晚上和师兄们吃饭,吃完饭溜达溜达。继续回来改CIFAR10数据集,太费劲了得换不想改了。学学VAE。
以下内容均来自油管上的deepia老师,已关注并点赞。
Autoencoder自编码器 学习笔记
1.结构:
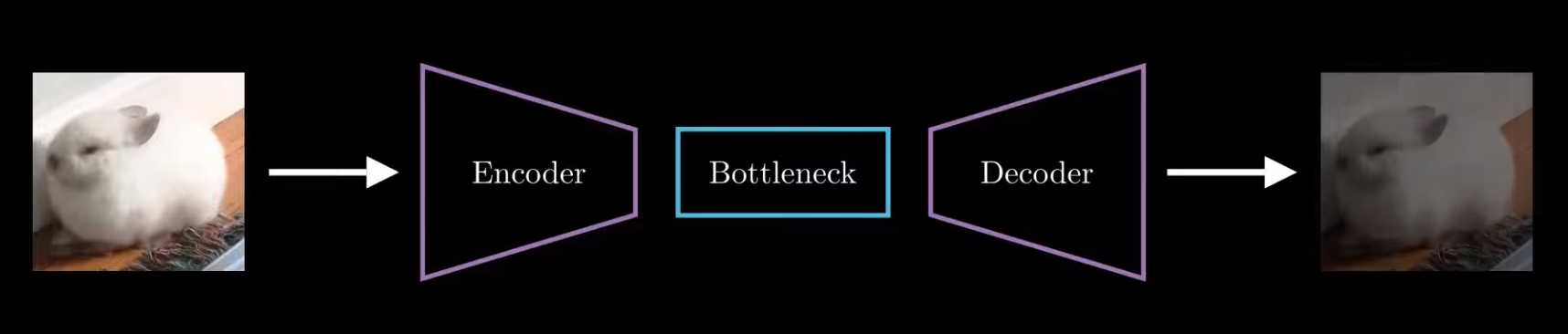
2.encoder学习输入图像/文本/音频等模态的特征,提取特征信息(可看作编码)。
decoder从接收到的特征信息中还原输入。
通过把输入和输出图像/文本/音频等的距离当损失函数,规范解码出来的输出跟输入越来越像。
其中提取的特征域称作潜空间(Latent space)
3.简单的栗子:(encoder)只描述一个人性别+肤色+身高+体重(4 dimensions),脑子(decoder)里根据这些特征想到一个形象。
特征压缩提取 学习笔记
需要强大的降维技术
1.PCA(Principal Component Analysis主成分分析)
只能处理线性问题,因为用到的是线性代数知识所以好用。求协方差矩阵,投影到主成分上。
2.t-SNE
能解决非线性问题,可视化很慢,基本不用。
KL散度衡量两个分布的相似度。
3.UMAP(推荐)
用图论的思想表示高维度和低维度特征,用损失函数规范。
变分自编码器学习笔记https://mbernste.github.io/posts/vae/
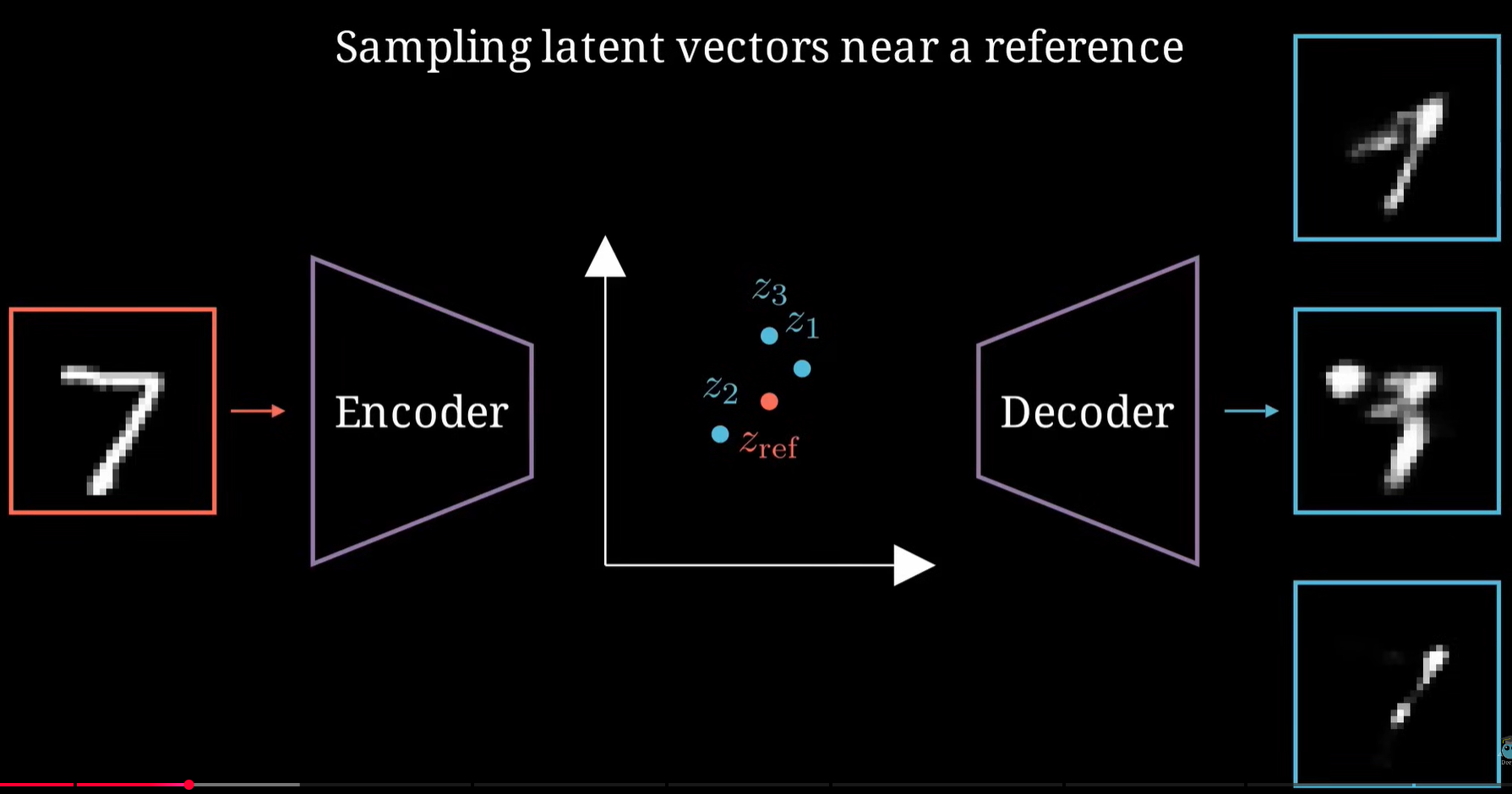
真正意义上生成式AI是不用有input的。传统的Autoencoder因为decoder读潜空间里大量的采样点都是无意义输出,就算在encoder输出的参考点附近也有可能输出一坨。
↑在此基础上,VAE横空出世
VAEs are a class of probabilistic models that find latent, low-dimensional representations of data. VAEs can be veiwed as probabilistic rather than deterministic.
·诶呦我草,数学推导真看不懂啊。可以看上面那个GitHub网页介绍。
·总之比起传统的自编码器,它是encoder传递一个分布而非一个低维度的数据点。数学推导都是推它为啥能反向梯度更新训练和损失函数的几个部分咋确定。
总结:怪不得VAE之类的总计算KL散度,人家本来就是要编码成一个分布来去操作的。弄不懂数学就算了,记住(找到)哪几个量是可以修改优化适配的。我们要做的generative model就是要把它训练成不用input(除了prompt需求)就能输出东西的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号