Mysql读写分离+防止sql注入攻击
Reference
[1] https://zhuanlan.zhihu.com/p/111682902
一、读写分离和防止sql注入的必要性(foreword)
1、 读写分离:
- 一句话定义:读写分离,基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
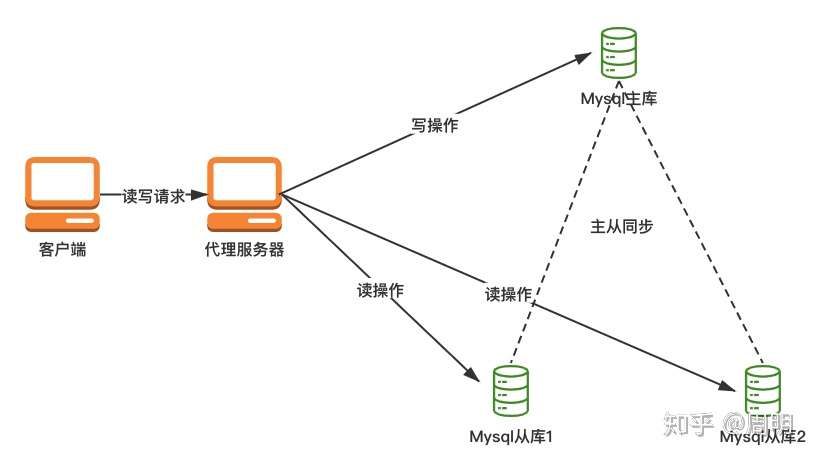 图1-1 主从读写分离示意图
图1-1 主从读写分离示意图
- 读写分离的好处:
(1) 增加冗余
(2) 增加了机器的处理能力
(3) 对于读操作为主的应用,使用读写分离是最好的场景,因为可以确保写的服务器压力更小,而读又可以接受点时间上的延迟。
2、 防止sql注入攻击:
一句话定义:SQL注入攻击(SQL Injection),简称注入攻击,是Web开发中最常见的一种安全漏洞。可以用它来从数据库获取敏感信息,或者利用数据库的特性执行添加用户,导出文件等一系列恶意操作,甚至有可能获取数据库乃至系统用户最高权限。
二、最佳解决方案(what)
主库用读写账户,从库用只读账户,建立mysql链接时使用参数interpolateParams=true
package main
import (
"database/sql"
"fmt"
_ "github.com/go-sql-driver/mysql"
)
func main() {
//主库用读写账户 建立mysql链接时使用参数interpolateParams=true
db_master, err := sql.Open("mysql", "master:@tcp(127.0.0.1:3306)/db_test?charset=utf8&interpolateParams=true")
if err != nil {
panic(err.Error()) //只是举例,真实使用中需要对错误进行处理和返回
}
defer db_master.Close()
//从库用只读账户 建立mysql链接时使用参数interpolateParams=true
db_slave, err := sql.Open("mysql", "slave:@tcp(127.0.0.1:3306)/db_test?charset=utf8&interpolateParams=true")
if err != nil {
panic(err.Error())
}
defer db_slave.Close()
rows, err := db_slave.Query("SELECT * FROM tbl_user WHERE user_id = ?", 1)
if err != nil {
panic(err.Error())
}
}
三、 几种方案对比(why)
1、主从都使用读写账户,sql语句采用字符串拼接方式(废弃)
既不能实现主从读写分离,也不能防止sql注入攻击。
2、主从都使用读写账户,sql采用prepare+execute的方式(存在风险)
可以防止sql注入攻击,但不能实现主从读写分离,当并发量上来后主库压力会很大,存在风险。
3、主采用读写账户,从采用只读账户,sql采用prepare+execute的方式(会报错)
(1)首先抛出报错:

(2)报错原因分析:
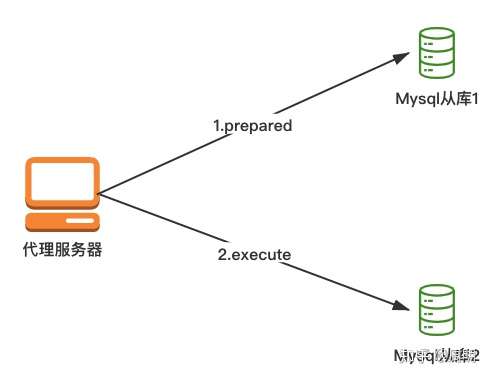 图1-2 报错原因分析
图1-2 报错原因分析
错误原因:如果prepare的时候sql发给了从库1,但是execute的时候因为从库1延时较大,sql命令发给了从库2,就会报上面这个错误(除此之外,默认proxy会隔断时间切换备机,保证备机都能用到)。
4、主采用读写账户,从采用只读账户,建立mysql链接时使用参数interpolateParams=true
针对方案4,我们需要来看下底层源码:
这里我们需要关注两部分源码:database/sql和go-sql-driver/mysql,其中database/sql是golang针对数据库抽象出来的一个标准库,go-sql-driver/mysql是实现database/sql驱动接口的mysql驱动。
(1)我们一般写查询语句是这样的(举个栗子)
rows, err := db_slave.Query("SELECT * FROM tbl_user WHERE user_id = ?", 1)
if err != nil {
panic(err.Error()) //只是举例,真实使用中需要对错误进行处理和返回
}我们知道prepared statement可以防止sql注入攻击,上图这样的写法看上去是使用的prepared statement方式,但到底是不是呢?我们继续往底层走。
(2)database/sql中查询接口是下面两个方法(即Query和QueryRow)
// Query executes a query that returns rows, typically a SELECT.
// The args are for any placeholder parameters in the query.
func (db *DB) Query(query string, args ...interface{}) (*Rows, error) {
return db.QueryContext(context.Background(), query, args...)
}注:Query执行查询并返回多个数据行,这个查询通常是一个select,方法中args参数用于填写查询语句中包含的占位符的实际参数。
// QueryRow executes a query that is expected to return at most one row.
// QueryRow always returns a non-nil value. Errors are deferred until
// Row's Scan method is called.
// If the query selects no rows, the *Row's Scan will return ErrNoRows.
// Otherwise, the *Row's Scan scans the first selected row and discards
// the rest.
func (db *DB) QueryRow(query string, args ...interface{}) *Row {
return db.QueryRowContext(context.Background(), query, args...)
}注:QueryRow与Query方法不同点是,执行一条查询最多只会返回一个数据行。
(3)发现宝藏:Query底层执行查询的策略
从queryDC方法来看Query默认是不使用prepared statement方式的,只有在查询时发生driver.ErrSkip错误才会启用prepared statement继续查询。
注:从Query到queryDC方法经过的连接获取和错误处理等逻辑不影响我们分析问题,可以忽略。
// queryDC executes a query on the given connection.
// The connection gets released by the releaseConn function.
// The ctx context is from a query method and the txctx context is from an
// optional transaction context.
func (db *DB) queryDC(ctx, txctx context.Context, dc *driverConn, releaseConn func(error), query string, args []interface{}) (*Rows, error) {
queryerCtx, ok := dc.ci.(driver.QueryerContext)
var queryer driver.Queryer
if !ok {
queryer, ok = dc.ci.(driver.Queryer)
}
if ok {
var nvdargs []driver.NamedValue
var rowsi driver.Rows
var err error
withLock(dc, func() {
nvdargs, err = driverArgsConnLocked(dc.ci, nil, args)
if err != nil {
return
}
//核心查询 不使用‘prepared Statement‘来执行
rowsi, err = ctxDriverQuery(ctx, queryerCtx, queryer, query, nvdargs)
})
if err != driver.ErrSkip {//发生错误driver.ErrSkip才使用‘prepared Statement‘方式去查询
if err != nil {//其他错误,关闭链接并报错返回
releaseConn(err)
return nil, err
}
// Note: ownership of dc passes to the *Rows, to be freed
// with releaseConn.
rows := &Rows{
dc: dc,
releaseConn: releaseConn,
rowsi: rowsi,
}
rows.initContextClose(ctx, txctx)
return rows, nil
}
}
//发生错误driver.ErrSkip时,才会使用‘Prepared Statement‘方式再次执行查询
var si driver.Stmt
var err error
withLock(dc, func() {
si, err = ctxDriverPrepare(ctx, dc.ci, query)//prepare
})
if err != nil {
releaseConn