数据产品-数据分析-统计模型分析-推荐算法
前言:
当掌握了大量数据时候,我们往往希望在数据中挖掘更多的信息,一般可以应用成熟模型进行比较深入的分析。
举个需求:我需要知道在一些用户购买了很多商品后,预估哪些商品同时被购买的概率大。目的是为了让用户对平台产生好的体验,更高的黏性,更高的订单量。
这种分析通常会被用到推荐模块里面,也可以计算出搭配的契合度,进行补货。
我们使用的是和hadoop搭配的基于Mahout的推荐算法,我个人越来越觉得Apache这家基金的牛逼,有着十分完事的大数据体系。
1.工作原理
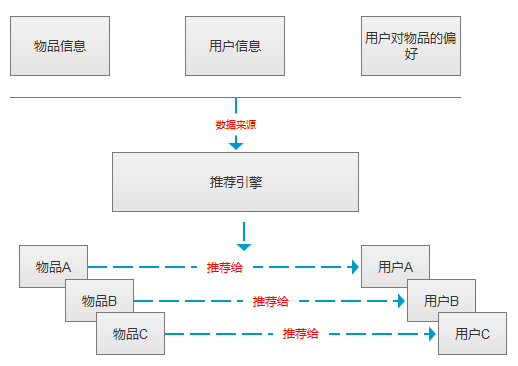
推荐系统主要向用户推荐可能感兴趣商品的系统。系统主要使用的数据是用户的历史商品购买记录,这部分数据存放在公司的数据库中。
2.Mahout的推荐系统整体架构:

3.这里介绍一种推荐系统中常用的算法:Apriori算法
3.1如何寻找相关联的物品?
在历史购物记录中,一些商品总是在一起购买。但人看上去不是那么的直观的,而是隐蔽的。让计算机做这事,设法计算法让计算机自动去找,找到这样的规律。
目标:寻找那些总是一起出现商品。
例如:苹果手机—>苹果手机壳
(整体):“苹果手机”与“苹果手机壳”一起购买的记录数占所有商品记录总数的比例——支持度
(局部):买了“苹果手机”与“苹果手机壳”一起购买的记录数占所有购买“苹果手机”记录数的比例——置信度
支持度、置信度越大,商品出现一起购买的次数就越多,可信度就越大。
支持度:假设在所有的商品记录中有2%量是同时购买苹果手机和苹果手机壳
置信度:假设买“苹果手机”的客户中有60%的客户购买了“苹果手机壳”
支持度、置信度进行计算(贝叶斯无处不在):
A表示苹果手机 B表示“苹果手机壳
支持度(A->B) = P(AB) (苹果手机和苹果手机壳一起买占总的购买记录的比例)
置信度(A->B) = P(B|A) (购买了苹果手机后,买苹果手机壳占的比例)
3.2明确问题
1、找出总出现在一起的商品组合
2、提出衡量标准支持度、置信度(需要达到阈值)
3、拿出支持度、置信度计算方法
4、得出在计算方法中起决定因素的是频繁项集(关键)
5、由频繁项集找到强关联规则
3.3相关概念
项集:项的集合称为项集,即商品的组合。
k项集:k种商品的组合,不关心商品件数,仅商品的种类。
项集频率:商品的购买记录数,简称为项集频率,支持度计数。
频繁项集:如果项集的相对支持度满足给定的最小支持度阈值,则该项集是频繁项集。
强关联规则:满足给定支持度和置信度阈值的关联规则。找关联规则--------->找频繁项集
步骤:
1. 找出所有的频繁项集;这个项集出现的次数至少与要求的最小计数一样。如在100次购买记录中,至少一起出现30次。
2. 由频繁项集产生强关联规则;这些关联规则满足最小支持度与最小置信度。
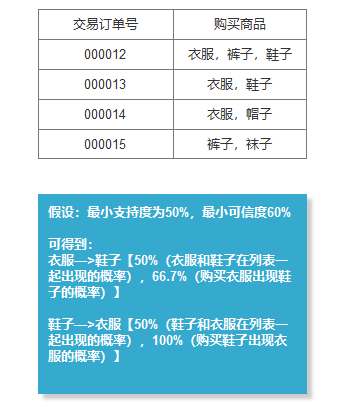
3.4支持度&可信度的计算方式:
3.5工作中的需求举例
假设我从数据库拿到以下的订单列表数据,我需要计算出“code04”订单号的用户推荐什么物品?

经过多次计算得出最后的频繁项集为{B,E},那么我需要给订单"code04"的用户推荐E商品。
4.总结
Apriori的难点
1.需要多次数据库扫描
2.巨大数量的候补项集
3.繁琐的支持度计算
改善Apriori的方法
1.减少扫描数据库的次数
2.减少候选项集的数量
3. 简化候选项集的支持度计算

 浙公网安备 33010602011771号
浙公网安备 33010602011771号