Hive笔记
一、Hive是基于Hadoop的数据仓库。
1、计算
把HQL查询通过HQL解析引擎转换为一系列在Hadoop集群上运行的MapReduce作业,易于分析。
解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析,编译生成执行计划,优化查询计划的生成。生成的查询计划存储在HDFS中,并在随后由MapReduce执行。具体过程是:HQL->AST Tree->QueryBlock->OperatorTree->逻辑层优化->翻译成MR任务->物理层优化生成最终执行计划
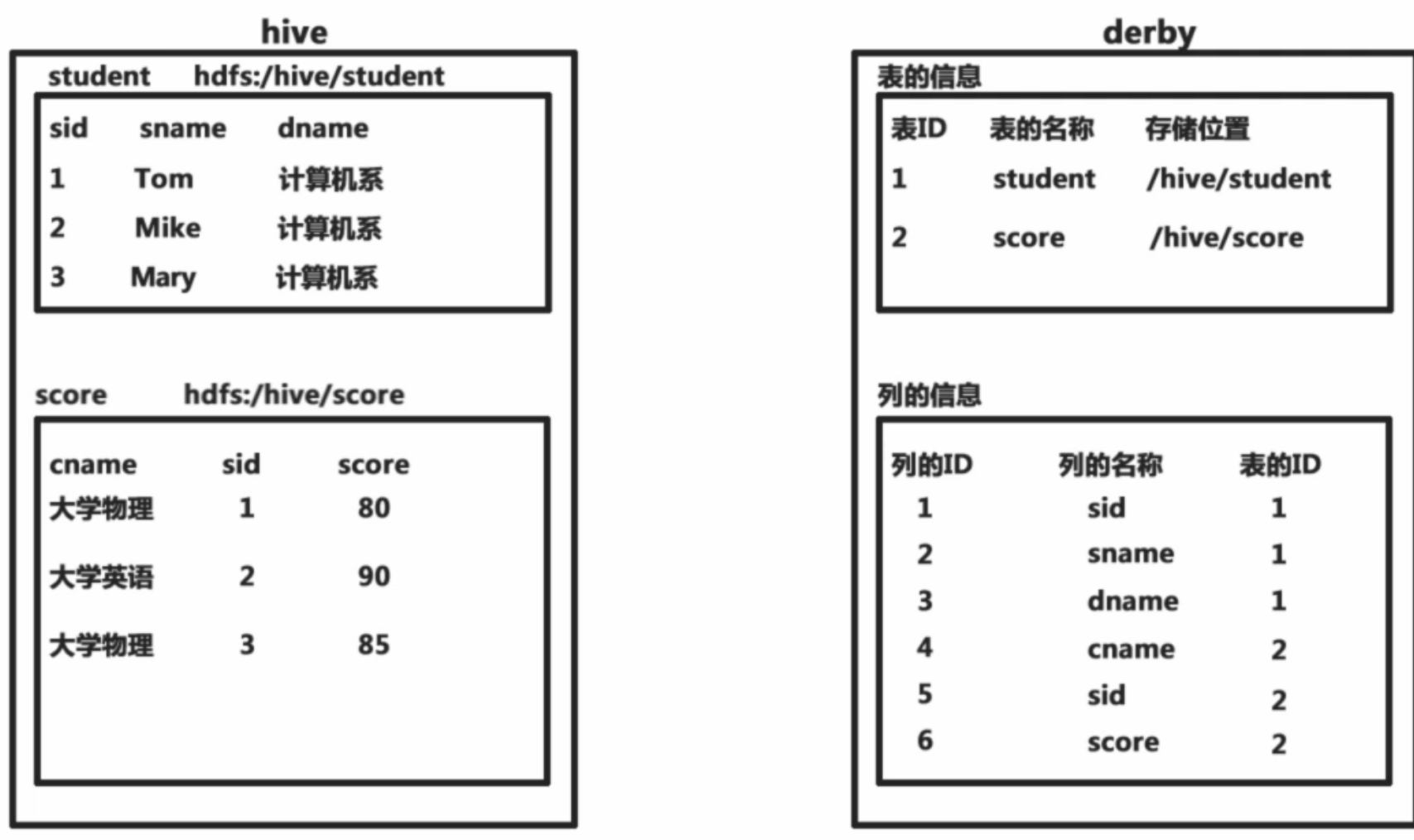
2、数据
把数据组织为表,通过这种方式为存储在HDFS的数据赋予结构,hive中一个表对应于hdfs上一个文件夹。默认在/user/hive/warehouse/下
元数据存储在metastore数据库(支持derby默认、mysql、oracle)中。元数据包括表名、列和分区及其属性、表属性、表数据的目录等
3、HQL转换成MR的过程
HQL->AST Tree->QueryBlock->OperatorTree->逻辑层优化->翻译成MR任务->物理层优化生成最终执行计划
- Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree
- 子查询或某表生成TOK_FROM节点
- 每个表生成TOK_TABREF节点
- join条件生成TOK_JOIN节点,并在 = 子节点处标记关联条件
- 遍历AST Tree,抽象出查询的基本组成单元QueryBlock
- 遍历QueryBlock,翻译为执行操作树OperatorTree
- 基本:SelectOperator,TableScanOperator,FilterOperator,JoinOperator,GroupByOperator,ReduceSinkOperator
- ReduceSinkOperator 在Map阶段将字段组合序列化为Reduce Key/value, Partition Key,同时也标志着Hive生成的MR程序中Map阶段的结束
- 逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量
- MapJoinProcessor 优化mapjoin
- BucketMapJoinOptimizer 优化bucket mapjoin
- GroupByOptimizer 优化map端聚合
- 遍历OperatorTree,翻译为MapReduce任务
- 物理层优化器进行MapReduce任务的变换,生成最终的执行计划
- CommonJoinResolver + MapJoinResolver mapjoin优化器
二、配置:
- Hive中,所有的默认配置都在${HIVE_HOME}/conf/hive-default.xml文件中,如果需要对默认的配置进行修改,可以创建一个hive-site.xml文件,放在${HIVE_HOME}/conf目录下。里面可以对一些配置进行个性化设定。永久有效
- hive -hiveconf 属性名=属性值,只对本次启动的会话有效(hive -hiveconf fs.default.name=localhost:9000 -hiveconf mapred.job.tracker=localhost:9001)
- hive>set 属性名=属性值; 只对本次会话有效
- hive>SET -v; 查看当前设定的所有信息
- ${HOME}/.hiverc 配置一系列的set语句,hive启动时会自动生效,注意要加;
hive>SET mapred.job.tracker=Hmaster:9001 设置参数
hive>SET mapred.job.tracker 显示参数值
SET命令设置的参数的作用域是Session级的,只对本次会话的操作有用。
优先级依次提高。
注意一定要在metastore同级目录下执行hive或beeline,否则会报未初始化metastore错误
设置最大内存:hive-config.sh export HADOOP_HEAPSIZE=${HADOOP_HEAPSIZE:-512} (默认是256M)即使调大机器内存也是无用的,必须在此处配置hive JVM最大内存值
(3)常用配置
|
属性名
|
默认值
|
|
|
hive.cli.print.header
|
false
|
显示列名
|
|
hive.cli.print.current.db
|
false
|
显示当前库名
|
|
hive.mappred.mode
|
nonstrict
|
是否严格模式(建议strict,这样对分区表查询时,必须在where条件里过滤分区)
|
|
hive.root.logger
|
日志级别(设置为INFO,console即在当前窗口显示,只能通过-hiveconf生效)
|
|
|
hive.enforce.bucketing
|
false
|
导入数据前设置使强制用桶对数据进行划分(2.x移除,总是true)
|
|
hive.optimize.bucketmapjoin
|
false
|
使用桶优化map join
|
|
hive.enforce.bucketmapjoin
|
false
|
启用分桶map-side join
|
|
hive.cbo.enable
|
false(0.x) true(1.1.0+)
|
启用cbo
|
|
mapred.child.java.opts
|
无
|
修改hive内存限制
|
|
hive.msck.path.validation
|
默认当发现分区目录有非法字符时会报错,skip自动跳过异常分区,ignore则尝试创建此分区
|
|
|
set mapred.job.queue.name=queue3;
set mapreduce.job.queuename=queue3;
set mapred.queue.names=queue3;
|
设置资源池
|
(4)常用命令
show functions; #查看函数
show functions 'xpath.*'; #正则查看函数名
describe function xpath; #查看具体函数内容
show partitions 表名; 显示这个表的分区情况
explain sql; 查看Hive的执行计划
explain extended sql; 查看Hive更详细的执行计划
desc t1; 查看表结构
describe extended t1; 显示一个表的详细情况
show tables; #查看所有表名
show tables 'ad*' #查看以'ad'开头的表名
set 命令 #设置变量与查看变量;
set-v #查看所有的变量
set hive.stats.atomic #查看hive.stats.atomic变量
set hive.stats.atomic=false #设置hive.stats.atomic变量
set hivevar:变量名=变量值 #设置自定义变量
dfs -ls #查看hadoop所有文件路径
dfs -ls /user/hive/warehouse/ #查看hive所有文件
dfs -ls /user/hive/warehouse/ptest #查看ptest文件
source file #在client里执行一个hive脚本文件
quit #退出交互式shell
exit #退出交互式shell
reset #重置配置为默认值
!ls #从Hive shell执行一个shell命令
(5)启动
- 命令行
- hive 或 hive --service cli
- -e: 命令行sql语句
-f: SQL文件
-h, --help: 帮助
--hiveconf: 指定配置文件-i: 初始化文件
-S, --silent: 静态模式(不将错误输出)-v,--verbose: 详细模式
- beeline(推荐)
- 连接:(注意这个连的是metastore,无论是存在于derby还是mysql,metastore服务的端口都是10000,此处的数据库是填的hive库,第一次只能填default)
- !connect jdbc:hive2:// 默认连localhost的10000端口的default库
- !connect jdbc:hive2://namenode-ip:10000/dbName dbName若不写则默认是default库
- beeline -u jdbc:hive2://localhost:10000 -n root
- hive.server2.enable.doAs设为true后,自动模拟当前用户的kerberos cache认证的用户
- beeline -u "jdbc:hive2://host:10000/default;principal=hive/host@REALM"
- 指定用户模拟
- beeline -u 'jdbc:hive2://fuxi-luoge-76:36003/default;principal=hive/_HOST@FUXI-LUOGE-79;hive.server2.proxy.user=XXXXXXX'
(连接后需要输入用户名和密码,在hive-site中的javax.jdo.option.ConnectionUserName、javax.jdo.option.ConnectionPassword有设置)
(连接后若报User root is not allowed to impersonate anonymous,在core-site.xml中配置hadoop.proxyuser.root.hosts的value为*,hadoop.proxyuser.root.groups的value为*)
- web界面 hive --service hwi &
- metastore服务 nohup hive --service metastore > metastore.log 2>&1 &
- hive作为后台服务供远程使用(端口号10000)
- hive --service hiveserver2 &
- nohup hiveserver2 > hiveserver2.log 2>&1 &
- 可通过配置hive-stie.xml实现高可用
- hive.server2.support.dynamic.service.discovery true
- hive.server2.zookeeper.namespace hiveserver2_zk
- hive.zookeeper.quorum zkNode1:2181,zkNode2:2181,zkNode3:2181
- hive.zookeeper.client.port 2181
- hive.server2.thrift.bind.host 0.0.0.0
- hive.server2.thrift.port 10001
三、本地模式
set mapred.job.tracker=local; 若设置成local,则会在本地执行mapreduce任务,对小数据集查询的运行非常有用。小任务在集群运行时反而效率会低
set hive.exec.mode.local.auto=enable; 设置本地自动执行mapreduce,默认为关闭。若设为enable,则Hive会先分析查询中的每个任务,当任务的输入规模小于hive.exec.mode.local.auto.inputbytes.max属性值(默认为128MB),并且全部的map数少于hive.exec.mode.local.auto.task.max值(默认为4),全部的reduce数为1或0时,则任务自动在本地模式执行
四、错误日志
Hive使用Log4j记录日志。默认情况下,记录级别是WARN,存储在HDFS:/tmp/hive/安装hive的用户名/hive.log。
若要在终端看到日志内容,可用(只能用-hiveconf配置):
hive -hiveconf hive.root.logger=INFO,console
五、Metastore
是Hive元数据的集中存放地。包括两部分:服务和后台数据的存储。
默认情况:内嵌metastore配置,metastore与hive运行在同一个JVM中,包含一个内嵌的以本地磁盘为存储的Derby数据库实例。比较简单,但缺点是不支持多会话。多用于测试环境
本地metastore:虽然metastore与hive在同一个进程中,但连接的却是在另一个进程中运行的数据库(如Mysql),支持多会话
远程metastore:metastore与hive运行在不同的进程,数据库层可以完全置于防火墙后,更加安全和可管理。多用于生产环境
六、HiveQL 对象、DDL
HiveQL是一种类似SQL的语言, 它与大部分的SQL语法兼容, 但是并不完全支持SQL标准, 如HiveQL不支持更新操作, 这是因其底层依赖于Hadoop云平台这一特性决定的, 但其有些特点是SQL所无法企及的。例如多表查询、支持CTAS和集成MapReduce脚本等
1、类型
- 基本类型
整数(有符号):TINYINT(1) SMALLINT(2) INT(4) BIGINT(8)
浮点数:FLOAT(4) DOUBLE(8) DECIMAL
BOOLEAN:TRUE FALSE
文本:STRING(变长) VARCHAR(0.12.0开始支持) CHAR(0.13.0开始)
二进制:BINARY(变长)
时间:TIMESTAMP(精度为纳秒,自1970年以来的偏移量)、DATE(0.12.0开始支持)
- 复杂类型
|
类型
|
含义
|
定义
|
使用
|
显示
|
|
ARRAY
|
数组,一组相同类型的元素
|
array
|
字段名[0]
|
["a","b","c"]
|
|
MAP
|
字典,由键值对组成
|
map<string,int>
|
字段名[key]
|
{"a":1,"b":2,"c":3}
|
|
STRUCT
|
结构,包含不同类型的元素
|
struct<fa:string,fb:int>
|
字段名.fa
|
{"fa":1}
|
|
数组字典
|
字典的value是数组
|
map<int,array>
|
{1:["a","b"],2:["c","d"]}
|
- 类型转换
所有整数类型、FLOAT、STRING都能隐式转换为DOUBLE,TIMESTAMP可以被隐式转换为STRING,BOOLEAN不能转换为其他任何数据类型。显式类型转换得用CAST,若强制转换失败后会返回NULL,如SELECT CAST('1' AS INT);
- 注意
- 当int型溢出时,插入到parquet表里是空值,需要设成bigint型。建议能用bigint就别用int
2、函数
SHOW FUNCTIONS; 获取函数列表
DESCRIBE FUNCTION 函数名; 获取某个特定函数的帮助
create function 创建函数
3、表
加载数据到托管表时,hive并不判断数据是否满足表的模式,只是单纯的文件移动,因此很快。只有在查询的时候才会检查模式。即读模式。
hive只能读取hdfs的数据,但本地数据可以load进hdfs
(1)表类型
- 托管/内部表(创建时会将数据移到数据仓库指向的路径,若local load则保留原文件,若hdfs load则不保留原文件;删除时删元数据、数据)
create table managed_table(dummy STRING);
load data inpath '/user/tom/data.txt' into table managed_table; --加载hdfs文件追加到原表
load data local inpath '/home/hadoop/test_data/temper.dat' overwrite into table testsort; --加载本地文件覆盖原表
- 外部表(创建时仅在hdfs location创建空目录,location只能指定hdfs文件,不需要load)
- 创建
- create external table external_table(dummy STRING) row format delimited fields terminated by ',' location '/user/tom/external_table';
然后直接就可以查了,至于能否查出来得看数据是否匹配模式(location后面跟的必须是数据所在目录)
修改location
alter table external1 set location '...';
- 情况
- 删除外部表时只删元数据,外部数据没有任何变化
- 无论是内部表还是外部表,无非就是往对应的hdfs目录复制文件,再以定义的表结构来读取数据
- 重命名时只改表名,外部数据目录名、内容没有任何变化
- 建同构表create table like时,仍然建的是内部表
- 分区外部表
- create EXTERNAL table IF NOT EXISTS outer_table (userid string) partitioned by (ptDate string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' location '/user/tom/outer_table';
- alter table test add partition (ptDate=20121214) location '/user/tom/outer_table/20121214'; (必须加分区,才能传文件到hdfs)
- 分区表(注意分区列是排在其他列后面的。且overwrite是分分区的)
create table logs (ts BIGINT,line STRING) partitioned by (dt STRING,country STRING) row format delimited fields terminated by ' ';
- 加载数据到数据表时,要显式指定分区值
load data local inpath '/home/hadoop/test_data/stu.dat' into table logs partition (dt='2016-08-15',country='CN');
insert into part_stu partition(sex='M') select name,id from stu where sex='M';
- 查询,使用where分区列,注意:查询出来的分区列数据是从hdfs目录获得的
select * from part_stu where sex='M';
- 当hdfs上有分区数据时,若未add partition,分区外部表也无法识别,必须add partition,且分区目录在表的location后,可不用指定location
alter table t1 add partition (ds='2019-01-09');
- 动态分区(自动根据数据创建分区,注意load不支持动态分区装载,只能用insert)
set hive.exec.dynamic.partition=true; --启用动态分区
insert into part_stu2 partition(sex='M',id) select name,id from stu where sex='M';(sex静态分区,id动态分区)
set hive.exec.dynamic.partition.mode=nonstrict;
--启用非严格动态分区,即允许所有分区列都是动态分区。默认主分区不能是动态分区
insert into part_stu partition(id,sex) select name,id,sex from stu;
- 桶表(类似于Oracle的聚簇表,大表化多个小表,方便map-side join)
create table bucketed_users (id INT,name STRING) clustered by (id) sorted by (name asc) into 4 buckets;
set hive.enforce.bucketing=true;(除2.x之外都必须设置,否则按桶分数据无效)
insert overwrite table bucketed_users select * from t2; (若使用load导入数据,桶分数据也是无效的)
set hive.optimize.bucketmapjoin=true;(启用按桶map join)
select /*+mapjoin(a)*/ count(*) from bucketed_users a join bucketed_users b on a.id = b.id;
物理上,每个桶就是一个文件,桶数和reduce任务个数相同(可强制指定)。Hive对值进行哈希并将结果除以桶的个数取余数来划分桶。防止热块
取样:select * from bucketed_users tablesample(bucket 1 out of 4 on id); 将所有桶分成4份,取1份
TABLESAMPLE(BUCKET x OUT OF y on col)
y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。例如,table总共分了64份,当y=32时,抽取(64/32=)2个bucket的数据,当y=128时,抽取(64/128=)1/2个bucket的数据。x表示从哪个bucket开始抽取。例如,table总bucket数为32,tablesample(bucket 3 out of 16),表示总共抽取(32/16=)2个bucket的数据,分别为第3个bucket和第(3+16=)19个bucket的数据。
随机采样:select * from t1 where rand()<=0.001 distribute by rand() sort by rand() limit 1000; (0.001是采样数占总数的比例*100)
(2)修改表
由于hive是读时模式,只有在读取数据的时候才会检查表结构是否满足数据需要,因此可以非常灵活地变更元数据以符合新数据的结构
- 重命名 alter table t32 rename to t;
- 保留表结构,删除数据 dfs -rmr 表数据文件目录 或 create table t2 like t;
- 增加分区:alter table tp2 add partition(dt='2016-07-04',country='cn'); alter table tp1 add partition(ds='N') location '/tp1/ds=N'; (注意ds必须是分区列)
- 删除分区:alter table tp2 drop partition(dt='2016-07-04',country='cn'); alter table tp1 drop partition (ds='N');
- 修改分区路径 alter table tp1 partition(ds='M') set location '/tp1/ds=M';(不会删旧目录和数据,也不移动数据)
- 重命名表:alter table tp2 rename to tp3;
- 改变列名、类型、注释、位置:alter table tp2 change column ip ipv4 string comment 'comment1:ipv4' after userid; (after userid可以换成first,即放在首列)
- 增加/替换列:alter table tp2 add/replace columns (列名 列类型, ...) add columns允许在当前列的末尾、分区列之前增加新的列,replace columns删除当前列,加入新列。
alter table tp2 add columns (ipv6 string);
- 删除列: alter table tp2 replace columns (新schema);
- 增加表属性:alter table tp2 set TBLPROPERTIES table_properties
table_properties:{property_name=property_value,property_name=property_value,...}
- desc extended tp2; 获得表的metadata信息
- 改变文件格式和组织:alter table tp2 set FILEFORMAT ... alter table tp2 clustered by (col1,col2...) [sorted by (col1,...)] into buckets数 buckets;
读时模式(hive):
只有在读的时候hive才检查、解析具体的 数据字段、schema。
优势是load data 非常迅速,因为它不需要读取数据进行解析,仅仅进行文件的复制或者移动。
写时模式(传统数据库):
优势是提升了查询性能,因为预先解析之后可以对列建立索引,并压缩,但这样也会花费要多的加载时间。
4、视图(只有元数据,在hdfs上无对应目录。视图是只读的。若基本表被删除或无效,则视图的查询也将无效)
类似rdbms的view,不存储实际数据
create view v1 as select * from t4 where t4.id=1;
create view v_mapcity(icity,iprovince) as select cols['city'],cols['province'] from ext_mapcity where cols['city']='hangzhou';
5、数据库
hive中的数据库含义类似于mysql,是命名空间或表的集合。初始化元数据后自动产生一个默认的数据库default
- 创建数据库:CREATE DATABASE|SCHEMA [IF NOT EXISTS] dbName
- create database test location '/tmp/dir'; 使用特定目录,而非/user/hive/warehouse子目录
- 列出数据库:SHOW DATABASES;
- 切换数据库:USE dbName;
- 删除数据库:DROP (DATABASE|SCHEMA) [IF EXISTS] dbName [RESTRICT|CASCADE];
- cascade:删除数据库先把其中的表删掉
七、存储格式
行格式:行和一行中的字段如何存储,由SerDe定义(序列化和反序列化工具) row format
文件格式:一行中字段容器的格式,最简单的格式是纯文本文件 file format
(1)行格式 ROW FORMAT
- DELIMITED(使用分隔符)
行内分隔符fields:Ctrl+A
集合元素分隔符collection items:Ctrl+B
键值分隔符map keys:Ctrl+C
行间分隔符lines:换行符
create table testsort(year int,temper int) row format delimited
fields terminated by '\001'
collection items terminated by '\002'
map keys terminated by '\003'
lines terminated by '\n';
- SERDE(使用SerDe)
csv文件,文件字段用引号括住,字段间用逗号分隔,不支持字段内有换行符的情况
CREATE external TABLE default.pyq_message (
`ID` string ,
`RoleId` string ,
`TargetId` string COMMENT '留言对象ID',
`ReplyId` string COMMENT '回复对象ID',
`OwnerId` string COMMENT '空间主人ID',
`Text` string COMMENT '留言内容',
`CreateTime` string ,
`Status` string COMMENT '留言状态:0 未读 1 已读 -1已删除'
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
"separatorChar" = ",",
"quoteChar" = "\"",
"escapeChar" = "\\"
)
location '/user/liyubin/pyq_message';
(2)二进制存储格式 STORED AS
Textfile、Sequencefile、Avro、RCFile
- Sequencefile 可分割(文件可划分成块)、可压缩、面向行。
- 提供了三种压缩方式:NONE、RECORD、BLOCK(BLOCK方式可分割且压缩性能最好),配置方式:set mapred.output.compression.type=BLOCK
- Avro 可分割、可压缩、面向行、支持模式演化及多种编程语言的绑定。Hive可以使用avroSerDe读取或写入Avro文件
- RCFile Parquet 可分割、可压缩、面向列。按列记录文件,表的每个行分片依次存表的每一列数据(推荐)
- 适合场景:列很多且一般只用到某些列;列有很多重复数据
create table compressed_users(id INT,name STRING) stored as sequencefile;
(3)压缩(hive会自动根据文件后缀名进行解压缩)
压缩率:Bzip2>Gzip>LZO/Snappy
Bzip2和LZO提供块级压缩,可分割。Gzip和Snappy不提供块级压缩,不可分割
可在hadoop或hive中配置,只需要配置一个
- hadoop
- 压缩器 set io.compression.codecs="org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.LzoCodec";
- 中间压缩(DefaultCodec、GzipCodec、Bzip2Codec、SnappyCodec、LzoCodec)
- 开启 set mapred.compress.map.output=true
- 指定 set mapred.map.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
- 结果压缩
- 开启 set mapred.output.compress=true;
- 指定 set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
- hive
- 中间压缩 (推荐LZO)
- 开启 set hive.exec.compress.intermediate=true;
- 指定 set hive.intermediate.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
- 结果压缩
- 开启 set hive.exec.compress.output=true;
- 指定 set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
普遍案例:
create table t1_compress (...) stored as XXX; (XXX有TEXTFILE、SEQUENCEFILE、RCFILE、AVRO)
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.XXXCodec; (XXX有Default、Bzip2、Gzip、Lzo2、Snappy)
insert overwrite into table t1_compress select * from t1;
create table t1_compress (...) stored as ORCFILE TBLPROPERTIES ("orc.compress"="XXX") (XXX有ZLIB、SNAPPY)
查看.gz文件:/bin/zcat /user/hive/warehouse/final_comp_on_gzip/000000_0.gz
查看sequencefile文件:hadoop fs -text /user/hive/warehouse/final_comp_on_gz_seq/000000_0
一般使用方法:中间压缩使用SnappyCodec,结果压缩使用Bzip2,文件格式用sequencefile
效果:
[numFiles=1, numRows=4312, totalSize=420, rawDataSize=21564]
(4)存档
配置:
set hive.archive.enabled=true;
set hive.archive.har.parentdir.settable=true;
set har.partfile.size=1099511627776;
命令:
alter table t1 archive partition (p1='v1');
alter table t1 unarchive partition (p1='v1');
八、导入数据
(1)INSERT
不支持行级DML数据
- 写入表
- 覆盖表 insert overwrite table target select c1,c2 from source;
- 增量添加 insert into table target select c1,c2 from source;
- 覆盖分区 insert overwrite table target partition(dt='2001-01-01' ) select c1,c2 from source;
- 动态分区插入 insert overwrite table target partition(dt) select c1,c2,dt from source;
- 写入文件系统
- INSERT [OVERWRITE] [LOCAL] DIRECTORY d1 select ... from ...
- 写入文件系统时,每列用^A区分,换行表示一行数据结束。如果任何一列不是原始类型,则这些列被序列化为JSON格式。
- 多表插入
- from source insert overwrite table t1 select year,count(distinct station) group by year insert into t2 select year,count(1) group by year;
(2)CTAS(不支持外部表)
create table t32 as select * from t3;
(3)Load (路径是文件时只加载此文件,是目录时加载目录下的所有文件。且加载时文件会移动到hadoop默认表目录下)
load data [local] inpath 'filepath' [overwrite] into table tablename [partition (partcol1=val1,partcol2=val2 ...)]
LOCAL关键字:在本地文件系统查找filepath
OVERWRITE关键字:删除目标表的内容,再添加filepath新内容
注意partition子句指定了分区列的值,而不会对源数据有任何筛选,且会改变导入后分区列的值
(4)Sqoop
注意:hive将数据写入hdfs时,会自动把字符集转为utf-8,若源数据不是utf-8会出现乱码,因此要先将源数据转为utf-8字符集再加载
十、查询数据
(1)排序
order by(全局排序,单机执行从而效率低,在严格模式下需要加limit):
select * from students order by id desc;
select * from testsort distribute by year sort by year asc,temper desc;
distribute by key sort by col(distribute对key hash分组到reducer,sort局部排序,按组有序而全局无效)
cluster by key(相当于distribute by key sort by key asc)
(2)连接
内连接 select t4.*,t5.* from t4 join t5 on (t4.id=t5.id);
外连接(left outer join/right outer join/full outer join) select t4.*,t5.* from t4 left outer join t5 on (t4.id=t5.id);
半连接(类似于IN) select * from t4 left semi join t5 on (t4.id=t5.id);
map连接(把指定的表放入mapper内存中执行连接操作,小表放入内存) select /*+mapjoin(t4)*/ t4.*,t5.* from t4 join t5 on (t4.id=t5.id);
(3)子查询
Hive只允许子查询出现在select语句的from子句或in子句中。
- from子句。要加别名
- in子句。不支持嵌套in子查询
(4)限制返回结果数
select * from stu limit 5;
(5)合并结果集
union all
(6)显式类型转换
cast(col as FLOAT)
转换BINARY:Hive只支持BINARY转换成String,若要转换成其他类型需要通过嵌套cast()的方式
(7)抽样查询
tablesample(bucket x out of y on col) 数据值抽样。将数据按col的hash值分成y个桶,再抽样其中的x个(也适用于非分桶表。但在分桶表中抽样查询时,只会扫描涉及到的桶下的数据,提高了效率)
tablesample(x percent) 数据块抽样。抽样的最小样本单元是一个HDFS数据块,若表的数据大小小于128M,则不管x是多少,都会返回所有结果
(8)判断
case ... when ... then ... end
(9)streaming(可用shell、python,类比java开发UDF,但要简单得多)
transform(col1,col2...) using '/bin/ | python ...' as (col3,col4...)
注意出现transform时,select不能有别的列,只能有transform
脚本执行: source HQL脚本文件;
- shell
- cat命令 from invites a insert overwrite table events select transform(a.foo,a.bar) using '/bin/cat' as (oof,rab) where a.ds>'2010-08-09';
- python
- SELECT TRANSFORM(pv) USING 'python /root/script/sum.py' AS total FROM tsum;
(10)分区列
当分区列的值是1、2、3时,不要用'1'、'2'、'3'查
SELECT [ALL | DISTINCT] select_expr,select_expr,...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list] ]
[LIMIT number];
- Top-k select * from t1 sort by amount desc limit 5;
- HAVING(Hive使用子查询实现) select col1 from (select col1,sum(col2) as col2sum from t1 group by col1) t2 where t2.col2sum>10; (sql形式为:select col1 from t1 group by col1 having count(1)>10)
(11)去重计数
count(distinct xxx)
若要符合某些条件才计入总数,则要将不符合条件的设置为null,再进行count distinct
count(distinct case when xxx then yyy else null end)
(12)count
count(*):所有行进行统计,包括NULL行 count(1):所有行进行统计,包括NULL行 count(column):对column中非NULL进行统计 count(distinct column):对column中非NULL进行去重统计 count(distinct col1,col2,...):对col1、col2,...多个字段同时去重并统计。 count(CASE WHEN plat=1 THEN u ELSE NULL END), count(DISTINCT CASE WHEN plat=1 THEN u ELSE NULL END), count(CASE WHEN (type=2 OR type=6) THEN u ELSE NULL END), count(DISTINCT CASE WHEN (type=2 OR type=6) THEN u ELSE NULL END)
十二、UDF(用户自定义函数)
(1)UDF必须用Java语言编写
UDF:作用于单个数据行,且产生一个数据行作为输出。如数学函数、字符串函数
UDAF:接受多个输入数据行,且产生一个输出数据行。如count、max
UDTF:作用于单个数据行,且产生多个输出数据行。如表
(2)Hive UDF必须满足下面两个条件:
必须是org.apache.hadoop.hive.ql.exec.UDF的子类
必须至少实现了evaluate()方法
(3)在hive中使用UDF:
两种方法:
会话设置:
注册:add jar /home/hadoop/jar/Strip.jar
建函数:create temporary function Strip as 'com.lyb.hive.Strip'; (temporary表示此UDF只是为这个Hive会话定义的,as后需要跟包名.类名,UDF名不是大小写敏感的)
全局设置:
hive --auxpath jar包路径
或者hive运行前在hive-env.sh 设置HIVE_AUX_JARS_PATH
十四、索引
1、Hive的2维坐标结构:定位行键->列修饰符
对比:HBase的4维坐标结构:定位行键->列簇->列修饰符->时间戳
2、创建索引
- 创建普通索引
create index idx_sogou_content on table sogou(content)
as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler'
with deferred rebuild
in table sogou_idx_table;
- 创建BITMAP索引
3、删除索引(会自动删掉索引表)
drop index idx_sogou_content on sogou;
4、重建索引
alter index idx_sogou_content on sogou rebuild;
5、查看索引
show index on sogou;
6、优化参数
set hive.optimize.index.filter=true;
set hive.optimize.index.groupby=true;
必须开启这两个参数,索引才能起作用
十五、Hive优化
- 列裁剪 只读取查询中需要用到的列
- set hive.optimize.cp=true; (默认true,0.13.0移除)
- 分区裁剪 查询过程中只读取涉及到的分区,where。
- Join操作
- 将条目少的表/子查询放在join左边(在Join操作的Reduce阶段,位于 Join 操作符左边的表的内容会被加载进内存,将条目少的表放在左边,可以有效减少发生 OOM 错误的几率)
- MR任务数量和join的连接条件数目是一样的(即使有多个join,但连接条件都是id,也只有一个MR任务)
- map-join操作
- 无须shuffle、reduce操作join就可以在map阶段全部完成。
- insert overwrite table t1 select /*+mapjoin(pv)*/ pv.pageid,u.age from page_view pv join user u on (pv.userid=u.userid);
- 适用场景:指定进行mapjoin的表能一次加载进内存
- 参数
- hive.join.emit.interval = 1000
- hive.mapjoin.size.key = 10000
- hive.mapjoin.cache.numrows = 10000
- 自动优化:Hive版本0.11之后,Hive默认启动该优化,也就是不再需要显式的使用MAPJOIN标记,其会在必要的时候触发该优化操作将普通JOIN转换成MapJoin
- hive.auto.convert.join 开启自动map-join优化
- hive.mapjoin.smalltable.filesize 单位是字节,默认25M,指定使用该优化的表的最大大小,小于此值的表会被加载进内存
- 不支持场景:右外连接、全外连接
- 分桶表自动优化
- 适用条件:数据按连接键分桶,其中一张表的分桶个数必须是另一张表的若干倍
- hive.optimize.bucketmapjoin=true 开启分桶map-join优化
- sort-merge-join优化:效率更高,要求也更高
- 适用条件:数据按连接键分桶并排序,涉及所有表具有相同的分桶数
- hive.input.format = org.apache.hive.ql.io.bucketizedhiveinputformat;
- hive.optimize.bucketmapjoin.sortedmerge = true
- hive.optimize.bucketmapjoin = true
- group by 操作
- map 端部分聚合: 并不是所有的聚合操作都需要在 Reduce 端完成,很多聚合操作都可以先在 Map 端进行部分聚合,最后在 Reduce 端得出最终结果(是基于hash进行聚合的)
- hive.map.aggr = true 是否在map 端进行聚合,默认为 True
- hive.groupby.mapaggr.checkinterval = 100000 在map 端进行聚合操作的条目数目
- 数据倾斜时进行负载均衡
- hive.groupby.skewindata = true 有数据倾斜的时候进行负载均衡,默认false。当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中(不按key分布到reduce),每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
- 合并小文件
- 文件数目过多,会给 HDFS 带来压力,并且会影响处理效率,可以通过合并 Map 和 Reduce 的结果文件来消除这样的影响
- 参数:
- hive.merge.mapfiles = true 是否合并 Map 输出文件,默认为 True(当只有select或mapjoin时,设为false可避免对map输出的文件的扫描,提高效率)
- hive.merge.mapredfiles = false 是否合并 Reduce 输出文件,默认为 False
- hive.merge.size.per.task = 256*1000*1000 合并文件的大小
- map阶段优化(确定合适的map任务数)
- map任务数=总数据量/每个map任务的数据量,注意,直接设置mapred.map.tasks是无效的
- 每个map任务的数据量=[$(mapred.min.split.size),min($(dfs.block.size),$(mapred.max.split.size))]
- mapred.min.split.size: 指的是数据的最小分割单元大小;min的默认值是1B
- mapred.max.split.size: 指的是数据的最大分割单元大小;max的默认值是256MB
- dfs.block.size: 指的是HDFS设置的数据块大小。已经指定好的值,而且这个参数默认情况下hive是识别不到的
- reduce阶段优化(确定合适的reduce任务数)
- 可直接设置mapred.reduce.tasks,有效,默认-1,即不限制
- min(${hive.exec.reducers.max},(${input.size}/${hive.exec.reducers.bytes.per.reducer}))
- hive.exec.reducers.max:此参数从Hive 0.2.0开始引入。在Hive 0.14.0版本之前默认值是999;而从Hive 0.14.0开始,默认值变成了1009,这个参数的含义是最多启动的Reduce个数
- hive.exec.reducers.bytes.per.reducer:此参数从Hive 0.2.0开始引入。在Hive 0.14.0版本之前默认值是1G(1,000,000,000);而从Hive 0.14.0开始,默认值变成了256M(256,000,000),可以参见HIVE-7158和HIVE-7917。这个参数的含义是每个Reduce处理的字节数。比如输入文件的大小是1GB,那么会启动4个Reduce来处理数据。
- order by limit优化
- sort by limit 外面套一层 order by limit (局部排序后再取多个前N,整体排序)
- 随机采样
- select * from t1 where rand()<=0.001 distribute by rand() sort by rand() limit 1000; (0.001是采样数占总数的比例*100)
- sql角度优化
- 无效ID在关联时的数据倾斜
- 两种解决方法:
- 空数据不参与关联 union all 空数据
- left outer join关联条件:case when a.id is null then concat('dp_hive',rand()) else a.id end = b.id(更好)
- t1(key数据倾斜) join t2
- t1每个key都加上随机前缀(如不大于N的整数1,2,...,N),t2每条数据扩容N倍,扩容出来的数据每条都加上1,2,...,N前缀,再进行join关联,关联后再去掉前缀
十六、常用函数
1、时间(以下string型日期必须满足格式才行)
符合日期格式要求的字符串可以直接比较,不需要转换格式
|
string to_date(arg)
|
日期时间转成时间(arg的格式必须是xxxx-x(x)-x(x) xx:xx:xx,结果是xxxx-xx-xx)
|
|
bigint unix_timestamp()
|
获取当前unix时间戳
|
|
bigint unix_timestamp(string date,string pattern)
|
将pattern格式的date转换为unix时间戳
|
|
string from_unixtime(bigint arg,string pattern)
|
将arg时间戳转换为pattern形式的时间
|
|
int datediff(string enddate, string startdate)
|
结束日期减去开始日期的天数(和时间部分没有关系,只是日期相减,如10.22-9.29是23天)
|
|
string date_add(string startdate, int days)
|
开始日期startdate增加days天后的日期,date格式是xxxx-xx-xx
|
|
string date_sub (string startdate, int days)
|
开始日期startdate减去days天后的日期,date格式是xxxx-xx-xx
|
|
int year(string date)
|
年份
|
|
int month(string date)
|
月份
|
|
int day(string date)
|
天
|
|
int hour(string date)
|
时
|
|
int minute(string date)
|
分
|
|
int second(string date)
|
秒
|
|
int weekofyear (string date)
|
周
|
2、窗口分析函数
可以不和group by合用,但注意在和group by合用时,分析函数里只能出现group by的字段;在和distinct合用时,分析函数只能出现group by的字段
|
NTILE(num) over
([partition_clause] order_by_clause)
|
把有序的数据集合 平均分配 到 指定的数量(num)个桶中, 将桶号分配给每一行。如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1。然后可以根据桶号,选取前或后 n分之几的数据。
|
用于等级、百分点、n分片等
|
|
RANK/DENSE_RANK/ROW_NUMBER() over (partion by col1... order by col2... desc/asc)
|
rank 会对相同数值,输出相同的序号,而且下一个序号不间断;
dense_rank 会对相同数值,输出相同的序号,但下一个序号,间断
row_number 会对所有数值输出不同的序号,序号唯一连续;
|
用于组内排序编号
|
|
LAG/LEAD(col,n,DEFAULT) over
(partion by col1... order by col2... desc/asc)
|
lag 返回窗口内往上第n行值,若null则default
lead 返回窗口内往下第n行值,若null则default
|
用于组内排序后,取当前行的值前第n个或后第n个值
|
|
FIRST_VALUE/LAST_VALUE(col) over ([partition_clause] order_by_clause)
|
first_value: 取分组内排序后,截止到当前行,第一个值
last_value: 取分组内排序后,截止到当前行,最后一个值
|
用于组内排序后,取第一个或最后一个值
|
|
SUM/AVG/MIN/MAX(col) over
(partition_clause [ order_by_clause [rows between xxx and xxx] ])
|
分组内求和/平均/最小/最大
若有order by而无window子句则相当于(分组内截止到当前行,且显示出的结果是分组内最后一种排序的)order by col rows between unbounded preceding and current row
xxx(rows between子句即window子句):
3 preceding 往前3行
2 following 往后2行
current row 当前行
unbounded preceding/following 起点/终点
|
用于组内求值
|
|
CUME_DIST/PERCENT_RANK() over
([partition_clause] order_by_clause)
|
CUME_DIST 小于等于当前值的行数/分组内总行数
PERCENT_RANK 分组内当前行的RANK值-1/分组内总行数-1
|
用于序列分析
|
|
group by col1,col2 GROUPING SETS(col1,col2,(col1,col2)) order by GROUPING__ID
|
根据不同的维度组合进行聚合,等价于将不同维度的group by结合集进行union all
GROUPING__ID 表示结果属于哪一个group by结合集
|
用于上卷和下钻维度的指标统计
|
|
group by col1,col2 with CUBE order by GROUPING__ID
|
根据GROUP BY的维度的所有组合进行聚合
(左例相当于不分组、对col1分组、对col2分组、对col1、col2分组 union all)
|
|
|
group by col1,col2 with ROLLUP order by GROUPING__ID
|
CUBE的子集,以最左侧维度为主,从该维度进行层级聚合。
首先是总体聚合、然后是按col1聚合、最后是按col1、col2聚合
|
3、合并记录函数(行列转换)
(1)行转列
- 多行转多列
col1 col2 col3 a c 1 a d 2 a e 3 b c 4 b d 5 b e 6 转换成 col1 c d e a 1 2 3 b 4 5 6
此时需要使用到max(case … when … then … else 0 end),仅限于转化的字段为数值类型,且为正值的情况
select col1, max(case col2 when 'c' then col3 else 0 end) as c, max(case col2 when 'd' then col3 else 0 end) as d, max(case col2 when 'e' then col3 else 0 end) as e from row2col group by col1;
- 多行转单列
col1 col2 col3 a b 1 a b 2 a b 3 c d 4 c d 5 c d 6 转换成 col1 col2 col3 a b 1,2,3 c d 4,5,6
a)cocat_ws(参数1,参数2),用于进行字符的拼接
必须要与group by合用,col必须是string或array,可以用cast(col as string)转换类型。col可以是非group by字段。oncat_ws(',', collect_list(col3))在impala里得用group_concat(),可以在group_concat()第二个参数指定分隔符,默认是逗号
参数1—指定分隔符
参数2—拼接的内容
b)collect_set(),它的主要作用是将某字段的值进行去重汇总,产生array类型字段
c) collect_list(), 不去重汇总
select col1, col2, concat_ws(',', collect_set(col3)) as col3 from row2col group by col1, col2;
(2)列转行
- 多列转多行
col1 c d e a 1 2 3 b 4 5 6 转换成 col1 col2 col3 a c 1 a d 2 a e 3 b c 4 b d 5 b e 6
这里需要使用union进行拼接
select col1, 'c' as col2, c as col3 from col2row UNION select col1, 'd' as col2, d as col3 from col2row UNION select col1, 'e' as col2, e as col3 from col2row order by col1, col2;
- 单列转多行
col1 col2 col3 a b 1,2,3 c d 4,5,6 转换成 col1 col2 col3 a b 1 a b 2 a b 3 c d 4 c d 5 c d 6
需要使用UDTF(表生成函数)explode(),该函数接受array类型的参数,其作用恰好与collect_set相反,实现将array类型数据行转列。explode配合lateral view实现将某列数据拆分成多行
select col1, col2, lv.col3 as col3 from col2row lateral view explode(split(col3, ',')) lv as col3;
4、字符串函数
|
nvl(col,val)
|
若col为空,则为val,否则为col
|
|
|
nvl2(col,val1, val2)
|
若col为空,则为val1,否则为val2
|
|
|
nullif(col1,col2)
|
若col1与col2相等,则返回空,否则返回col1
|
|
|
coalesce(...)
|
返回第一个非空值。可以包含任意多个参数,但类型必须相同,或可隐式转换为同类型
|
|
|
regexp_replace(str,oldstr,newstr)
|
||
|
split(str,regexp)
|
根据regexp分割字符串,返回一个数组。当regexp是特殊字符时,要在前面加\\,当split在""中时,\\要改为\\\\
|
split('192.168.0.1','\\.') hive -e ".... split('192.168.0.1','\\\\.') ... "
|
5、判断函数
if(boolean testCondition, T valueTrue, T valueFalseOrNull)
CASE a WHEN b THEN c [WHEN d THEN e]... [ELSE f] END
6、数字函数
|
ceil()
|
往上取整
|
|
floor()
|
往下取整
|
|
pmod(int a,int b)
pmod(double a,double b)
|
a的绝对值除以b的余数
|
7、json解析函数
get_json_object(string json_string, string path)
第一个参数填写json对象变量,第二个参数使用$表示json变量标识,然后用 . 读取对象,[] 读取数组;如果输入的json字符串无效,返回NULL
单层值 get_json_object(data, '$.owner')
多层值 get_json_object(data, '$.store.bicycle.price')
数组值 get_json_object(data, '$.store.fruit[0]')
十七、语句顺序
- FROM
- join
- WHERE
- GROUP BY
- HAVING
- SELECT
- OVER
- DISTINCE
- TOP
- ORDER BY
十八、实现exist/in以及not exists/not in子句
exist/in、not exists/not in在hive中不支持,需要改写:
1、in:
SELECT a.key, a.value FROM a WHERE a.key in (SELECT b.key FROM B);
改成:
SELECT a.key, a.value FROM a LEFT OUTER JOIN b ON (a.key = b.key) WHERE b.key <> NULL;
2、not exists:
select a, b from table1 t1 where not exists (select 1 from table2 t where t1.a = t2.a and t1.b = t2.b)
改成:
select t1.a, t2.b from table1 t1 left join table2 t2 on (t1.a = t2.a and t1.b = t2.b) where t2.a is null
十九、锁
1、解锁表
unlock table t1;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号