epollwait惊群回头看
可以看以前的epoll 分析
对于epoll_wait&& accept惊群问题:
static handler_t network_server_handle_fdevent(void *context, int revents) { const server_socket * const srv_socket = (server_socket *)context; server * const srv = srv_socket->srv; ----------------------------- /* accept()s at most 100 new connections before * jumping out to process events on other connections */ int loops = (int)srv->lim_conns; if (loops > 100) loops = 100; else if (loops <= 0) return HANDLER_GO_ON; -------------------------- sock_addr addr; size_t addrlen; /*(size_t intentional; not socklen_t)*/ do { addrlen = sizeof(addr); int fd = fdevent_accept_listenfd(srv_socket->fd, (struct sockaddr *)&addr, &addrlen); if (-1 == fd) break; --------------------------- #ifdef HAVE_SYS_UN_H /*(see sock_addr.h)*/ else if (addrlen <= 2) /*(AF_UNIX if !nagle_disable)*/ memcpy(addr.un.sun_path, srv_socket->addr.un.sun_path, srv_socket->srv_token_colon < sizeof(addr.un.sun_path) ? (size_t)srv_socket->srv_token_colon+1 /*(+1 for '\0')*/ : sizeof(addr.un.sun_path));/*(escaped len might be longer)*/ #endif connection *con = connection_accepted(srv, srv_socket, &addr, fd); if (__builtin_expect( (!con), 0)) return HANDLER_GO_ON; connection_state_machine(con); } while (--loops); ----------------- return HANDLER_GO_ON; }
内核原理
通过下图,了解一下服务端 tcp 的第三次握手和 epoll 内核的等待唤醒工作流程。
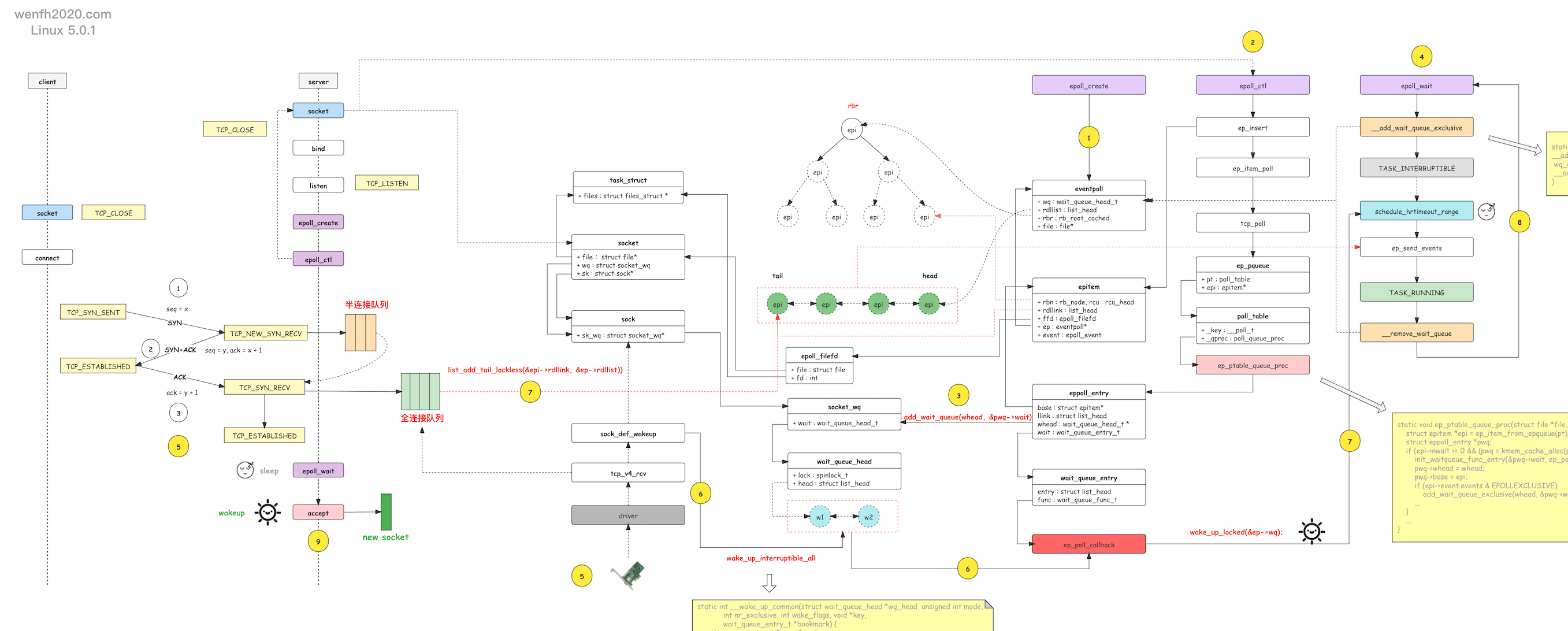
- 进程通过 epoll_create 创建 eventpoll 对象。
- 进程通过 epoll_ctl 添加关注 listen socket 的 EPOLLIN 可读事件。
- 接步骤 2,epoll_ctl 还将 epoll 的 socket 唤醒等待事件(唤醒函数:ep_poll_callback)通过 add_wait_queue 函数添加到 socket.wq 等待队列。
当 listen socket 有链接资源时,内核通过 __wake_up_common 调用 epoll 的 ep_poll_callback 唤醒函数,唤醒进程。
- 进程通过 epoll_wait 等待就绪事件,往 eventpoll.wq 等待队列中添加当前进程的等待事件,当 epoll_ctl 监控的 socket 产生对应的事件时,被唤醒返回。
- 客户端通过 tcp connect 链接服务端,三次握手成功,第三次握手在服务端进程产生新的链接资源。
- 服务端进程根据 socket.wq 等待队列,唤醒正在等待资源的进程处理。例如 nginx 的惊群现象,__wake_up_common 唤醒等待队列上的两个等待进程,调用 ep_poll_callback 去唤醒 epoll_wait 阻塞等待的进程。
- ep_poll_callback 唤醒回调会检查 listen socket 的完全队列是否为空,如果不为空,那么就将 epoll_ctl 监控的 listen socket 的节点 epi 添加到
就绪队列:eventpoll.rdllist,然后唤醒 eventpoll.wq 里通过 epoll_wait 等待的进程,处理 eventpoll.rdllist 上的事件数据。 - 睡眠在内核的 epoll_wait 被唤醒后,内核通过 ep_send_events 将就绪事件数据,从内核空间拷贝到用户空间,然后进程从内核空间返回到用户空间。
- epoll_wait 被唤醒,返回用户空间,读取 listen socket 返回的 EPOLLIN 事件,然后 accept listen socket 完全队列上的链接资源。
【注意】 有了 socket.wq 为啥还要有 eventpoll.wq 啊?因为 listen socket 能被多个进程共享,epoll 实例也能被多个进程共享!
-
添加等待事件流程:
epoll_ctl -> listen socket -> add_wait_queue <+ep_poll_callback+> -> socket.wq ==> epoll_wait -> eventpoll.wq
-
唤醒流程:
tcp_v4_rcv -> socket.wq -> __wake_up_common -> ep_poll_callback -> eventpoll.wq -> wake_up_locked -> epoll_wait -> accept
问题:为什么epoll_wait在fork后面还存在惊群
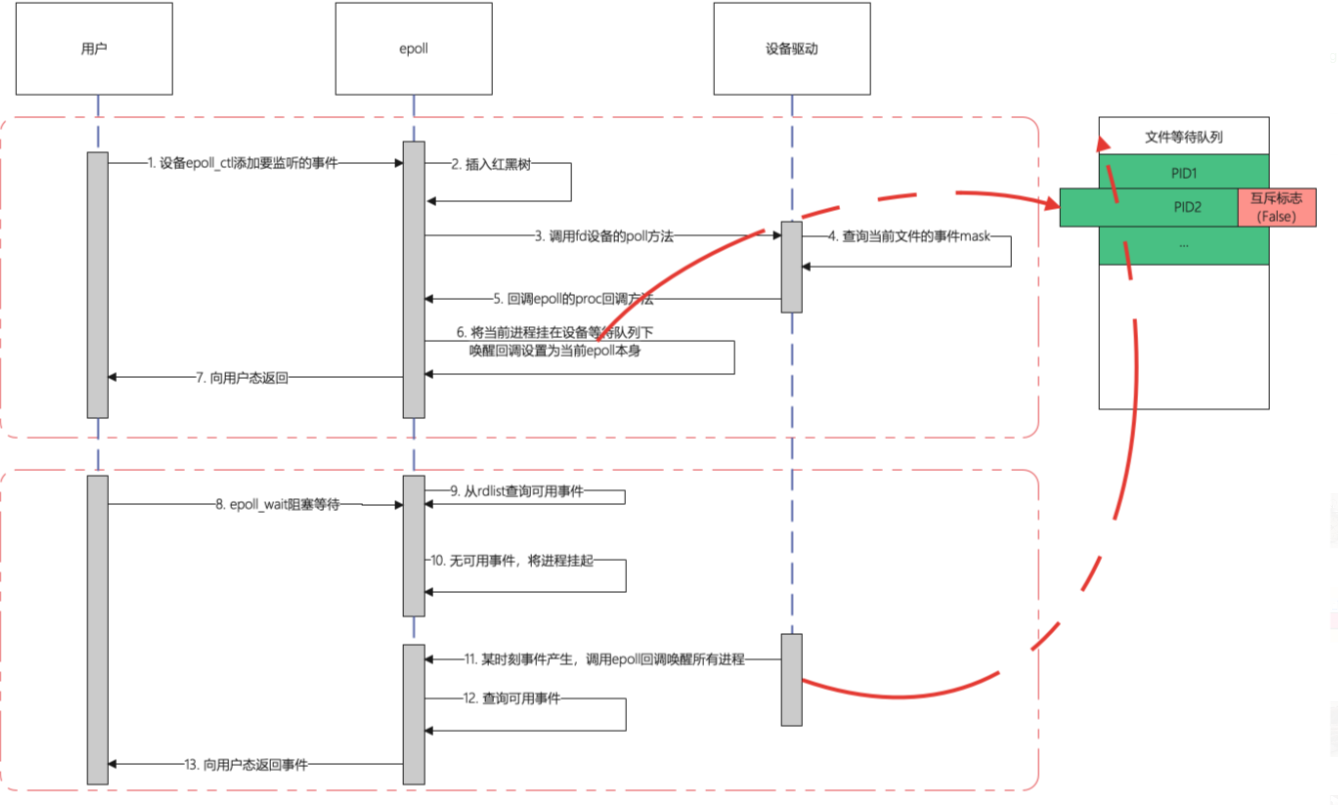
如上图,当用户调用epoll_ctl的添加事件的时候,在第6步中,epoll会把当前进程挂在fd的等待队列下,但是默认情况下这种挂载不会设置互斥标志,意思着当设备有事情产生进行等待队列唤醒的时候,如果当前队列有多个进程在等待,则会全部唤醒
可想而知,在下面的epoll_wait调用中,如果多个进程将同一个fd添加到epoll中进行监听,当事件到达的时候,这些进程将被一起唤醒;当有新的sock时执行如下代码唤醒队列上所有的进程
/* * Default Socket Callbacks */ static void sock_def_wakeup(struct sock *sk) { struct socket_wq *wq; rcu_read_lock(); wq = rcu_dereference(sk->sk_wq); if (wq_has_sleeper(wq)) wake_up_interruptible_all(&wq->wait); rcu_read_unlock(); }
但是唤醒并不一定会向用户态返回,因为唤醒之后epoll还要遍历一次就绪列表,确认有至少一个事件发生才会向用户态返回
到此,我们可以想象出epoll是如何造成accept惊群的:
- 当多个进程共享同一个监听端口并且都使用epoll进行多路复用的监听时,epoll将这些进程都挂在同一个等待队列下
- 当事件产生时,socket的设备驱动都会尝试将等待队列的进行唤醒,但是由于挂载队列的时候使用的是epoll的挂载方式,没有设置互斥标志(取代了accept自己挂载队列的方式,如第一节所述),所以这个队列下的所有进程将全部被唤醒
- 唤醒之后此时这些进程还处于内核态,他们都会立刻检查事件就绪列表,确认是否有事件发生,对accept而言,accept->poll方法将会检查在当前的socket的tcp全连接列表中是否有可用连接,如果是则返回可用事件标志
- 当所有进程都被唤醒,但是还没有进行去真正做accept动作的时候,所有进行的事件检查都认为accept事件可用,所以这些进行都向用户态返回
- 用户态检查到有accept事件可用,这时他们将会真正调用accept函数进行连接的获取
- 此时只会有一个进行能真正获取连接,其他进行都会返回EAGAIN错误,使用strace -p PID命令可以跟踪到这种错误
- 并不是所有进行都会返回用户态,关键点在于这些被唤醒的进行在检查事件的过程中,如果已经有进程成功accept到连接了,这时别的事情将不会检查到这个事情,从而他们会继续休眠,不会返回用户态
- 虽然不一定会返回用户态,但也造成了内核上下文切换的发生,其实也是惊群效应的表现

 浙公网安备 33010602011771号
浙公网安备 33010602011771号