DPVS架构
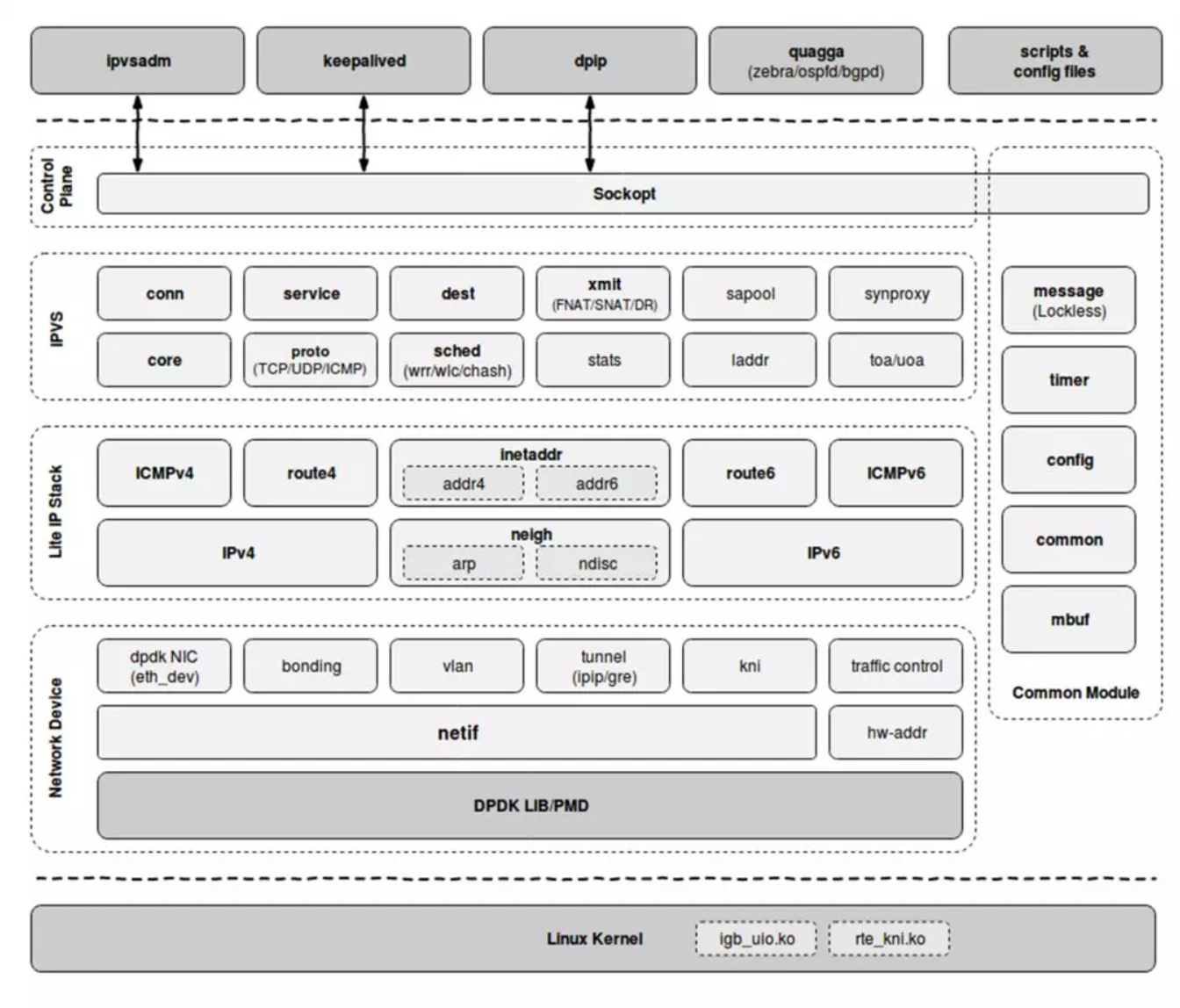
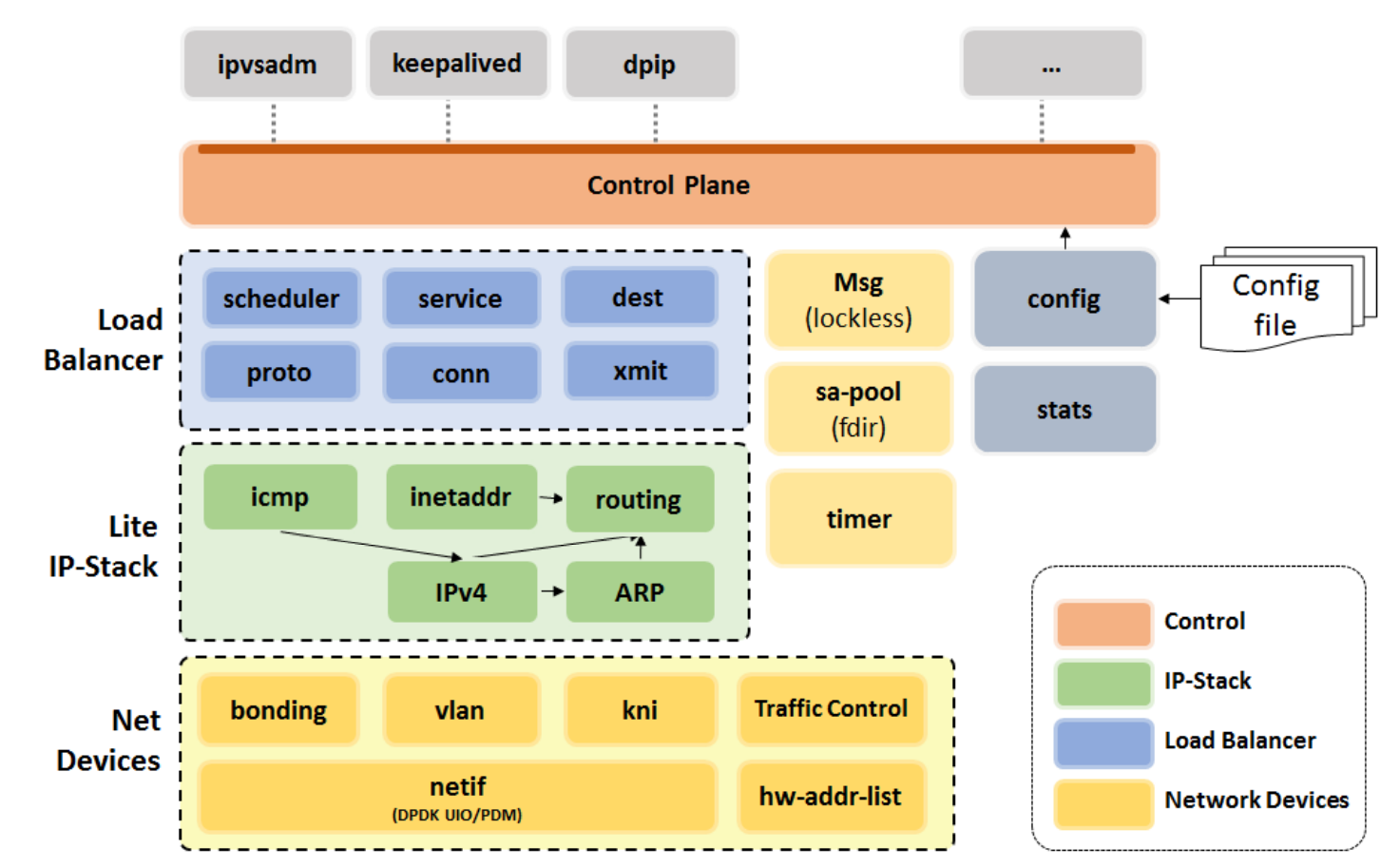
DPVS 是一个基于DPDK 的高性能四层负载均衡器(Layer-4 load balancer) ,DPVS的名字来源于DP DK+LVS ,注意这里的LVS是阿里巴巴改进版的LVS 。下图是爱奇艺官方给出的一个DPVS架构以及主要特点:
用户态实现
DPVS主要的任务都是在用户态完成的,可以极大地提高效率。官方声称DPVS的包处理速度,1个工作线程可以达到 2.3Mpps,6个工作线程可以达到万兆网卡小包的转发线速(约 12Mpps)。 这主要是因为DPVS绕过了内核复杂的协议栈 ,并采用轮询的方式收发数据包,避免了锁、内核中断、上下文切换、内核态和用户态数据拷贝产生的性能开销。
实际上四层负载均衡并不需要完整的协议栈,但是需要基本的网络组件 ,以便完成和周围设备的交互(ARP/NS/NA)、确定分组走向 (Route)、回应 Ping 请求、健全性检查(分组完整性,Checksum校验)、以及 IP 地址管理等基本工作。使用 DPDK 提高了收发包性能,但也绕过了内核协议栈,DPVS 依赖的协议栈需要自己实现。
Master/Worker模型
这一点和nginx一样,使用M/S模型,Master 处理控制平面,比如参数配置、统计获取等;Worker 实现核心负载均衡、调度、数据转发功能。
另外,DPVS 使用多线程模型,每个线程绑定到一个 CPU 物理核心上,并且禁止这些 CPU 被调度。这些 CPU 只运行 DPVS 的 Master 或者某个 Worker,以此避免上下文切换,别的进程不会被调度到这些 CPU,Worker 也不会迁移到其他 CPU 造成缓存失效。
网卡队列/CPU绑定
现在的服务器网卡绝大多数都是多队列网卡 ,支持多个队列同时收发数据,让不同的 CPU 处理不同的网卡队列的流量,分摊工作量,DPVS将其和CPU进行绑定,利用DPDK 的 API 实现一个网卡的一个收发队列对应一个CPU核心和一个Worker进程 ,实现一一对应和绑定,从而实现了处理能力随CPU核心、网卡队列数的增加而线性增长,并且很好地实现了并行处理 和线性扩展。
关键数据无锁化
内核性能问题的一大原因就是资源共享和锁。 所以,被频繁访问的关键数据需要尽可能的实现无锁化,其中一个方法是将数据做到 per-cpu 化,即每个CPU核心只处理自己本地的数据,不需要访问其他CPU的数据,这样就可以避免加锁 。对于DPVS而言,连接表,邻居表,路由表等频繁修改或者频繁查找的数据,都做到了 per-cpu 化。但是在具体 per-cpu 的实现上,连接表和邻居表、路由表两者的实现方式并不相同。
连接表在高并发的情况下会被频繁的CRUD 。DPVS中每个CPU核心维护的是不相同的连接表,不同的网络数据流(TCP/UDP/ICMP)按照 N 元组被定向到不同的CPU核心,在此特定的CPU核心上创建、查找、转发、销毁。同一个数据流的包,只会出现在某个CPU核心上,不会落到其他的CPU核心上。这样就可以做到不同的CPU核心只维护自己本地的表,无需加锁。
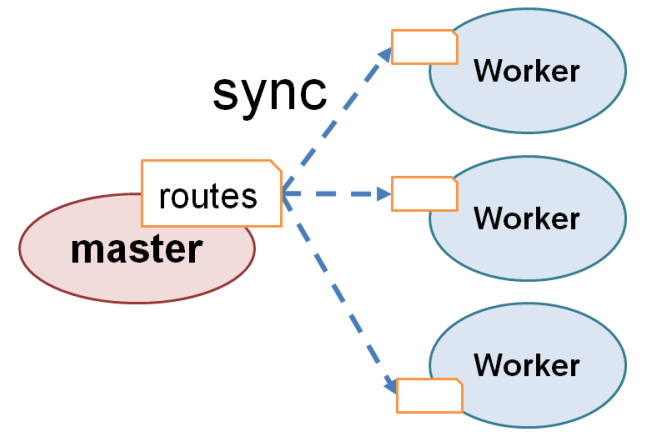
对于邻居表和路由表这种每个CPU核心都要使用的全局级别的操作系统数据,默认情况下是使用”全局表+锁保护“的方式。DPVS通过让每个CPU核心有同样的视图,也就是每个CPU核心需要维护同样的表,从而做到了per-cpu。 对于这两个表,虽然在具体实现上有小的差别(路由表是直接传递信息,邻居是克隆数据并传递分组给别的 CPU),但是本质上都是通过跨CPU通信来实现的跨CPU无锁同步 ,从而将表的变化同步到每个CPU,最后实现了无锁化。
跨CPU无锁通信
上面的关键数据无锁化和这一点实际上是殊途同归的。首先,虽然采用了关键数据 per-cpu等优化,但跨CPU还是需要通信的,比如:
Master 获取各个 Worker 的各种统计信息
Master 将路由、黑名单等配置同步到各个 Worker
Master 将来自DPVS的KNI网卡的数据发送到 Worker(只有 Worker 能操作DPDK网卡接口来发送数据)
既然需要通信,就不能存在互相影响、相互等待的情况,因为那会影响性能。DPVS的无锁通信还是主要依靠DPDK提供的无锁rte_ring库实现的 ,从底层保证通信是无锁的,并且我们在此之上封装一层消息机制来支持一对一,一对多,同步或异步的消息。
丰富的功能
从转发模式上看 :DPVS 支持 DirectRouting(DR)、NAT、Tunnel、Full-NAT、SNAT五种转发模式,可以灵活适配各种网络应用场景
从协议支持上看 :DPVS 支持 IPv4和 IPv6 协议、且最新版本增加了 NAT64的转发功能,实现了用户从 IPv6网络访问 IPv4服务
从设备支持上看 :DPVS支持主流的硬件网卡设备,同时还支持了Bonding(mode 0 and 4 ), VLAN, kni, ipip/GRE等虚拟设备
从管理工具上看 :可以使用包括 ipvsadm、keepalived、dpip等工具对DPVS进行配置和管理,也支持使用进行 quagga 集群化部署
小结
从上面列出的几个DPVS的主要特点我们不难发现,DPVS的主要设计思路就是通过减少各种切换和避免加锁来提高性能 ,具体的实现上则主要依赖了DPDK的许多功能特性以及使用了常用的几个开源负载均衡软件(ipvsadm、keepalived、dpip等),结合用户态的轻量级网络协议栈(只保留了四层负载均衡所必须的),就实现了超强性能的四层负载均衡系统。
1、机器配置
DPVS由于引入了DPDK套件作为底层的支撑,因此想要最大化发挥它的性能,需要对硬件有一定的要求,dpdk官方给出了一份支持列表 ,虽然支持性列表上面的平台支持得很广泛,但是实际上兼容性和表现最好的似乎还是要Intel的硬件平台。网卡的兼容性方面,主流的Intel网卡几乎都支持,需要注意的是不同型号的网卡在flow-director功能和网卡的收发数据包支持的队列数可能会有不同。
机器参数
CPU:两颗 Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz
内存:16G*8 DDR4-2400 MT/s,每个CPU64G,共计128G
网卡:两张双口的Intel Corporation 82599ES 10-Gigabit SFI/SFP+ Network Connection (rev 01)
系统:Red Hat Enterprise Linux Server release 7.6 (Maipo)
内核:3.10.0-1127.19.1.el7.x86_64
关闭超线程和启用NUMA策略
关闭超线程最好的办法是在BIOS中找到相关的超线程设置并且将其禁用,而NUMA策略也是一样,最好在BIOS中直接打开。
打开超线程技术的时候我们可以看到Thread(s) per core是2,也就是每个物理核心对应有2个逻辑核心,而Core(s) per socket表示每个socket有10个物理核心(一般一个CPU对应一个socket),Socket(s)表示当前服务器有两个CPU,也就是常说的双路。
1234567891011121314151617181920212223242526272829303132
$ lscpuArchitecture: x86_64CPU op-mode(s): 32-bit, 64-bitByte Order: Little EndianCPU(s): 40On-line CPU(s) list: 0-39Thread(s) per core: 2Core(s) per socket: 10Socket(s): 2NUMA node(s): 2Vendor ID: GenuineIntelCPU family: 6Model: 79Model name: Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHzStepping: 1CPU MHz: 2669.567CPU max MHz: 3100.0000CPU min MHz: 1200.0000BogoMIPS: 4399.75Virtualization: VT-xL1d cache: 32KL1i cache: 32KL2 cache: 256KL3 cache: 25600KNUMA node0 CPU(s): 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38NUMA node1 CPU(s): 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39 Copy
关闭超线程技术之后的时候我们可以看到Thread(s) per core是1,也就是每个物理核心对应有1个逻辑核心。这时候CPU(s)的数值和CPU的物理核心数值应该相等。
12345678910111213141516171819202122232425262728
$ lscpuArchitecture: x86_64CPU op-mode(s): 32-bit, 64-bitByte Order: Little EndianCPU(s): 20On-line CPU(s) list: 0-19Thread(s) per core: 1Core(s) per socket: 10Socket(s): 2NUMA node(s): 2Vendor ID: GenuineIntelCPU family: 6Model: 79Model name: Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHzStepping: 1CPU MHz: 1200.036CPU max MHz: 3100.0000CPU min MHz: 1200.0000BogoMIPS: 4400.07Virtualization: VT-xL1d cache: 32KL1i cache: 32KL2 cache: 256KL3 cache: 25600KNUMA node0 CPU(s): 0,2,4,6,8,10,12,14,16,18NUMA node1 CPU(s): 1,3,5,7,9,11,13,15,17,190 Copy
使用numastat命令可以看到有两个node,表明已经打开NUMA策略,同样的还可以使用lscpu命令查看NUMA node(s)的数量。
$ numastat 654623151 11334196 0 0 0 0 34599 34359 654619810 11281809 3341 52387 Copy
2、安装
开始之前我们需要使用yum安装一些编译安装的时候需要使用的工具和软件
123456789101112131415161718
$ yum group install "Development Tools" Copy
这时候需要机器能够连接外网(互联网),直接从github将dpvs项目clone下来,同时还需要下载特定版本的dpdk,无法联网的机器也可以直接下载之后传输到服务器中,后续的安装过程并不需要联网
接下来需要对dpdk进行打补丁,注意这里的补丁并不是必须的 。
$ cd /home/dpvscd dpdk-stable-17.11.2/ Copy
编译dpdk
$ cd /home/dpvs/dpdk-stable-17.11.2 Copy
如果出现下面的问题
我们需要手动更改文件,解决方案参考这里 :
用find / -name netdevice.h 查找内核中的头文件,找到struct net_device_ops 中的 ndo_change_mtu,
会看到ndo_change_mtu被替换成对应版本的ndo_change_mtu_rhXX,比如 ndo_change_mtu_rh75 将 /kni_net.c:704:2 中 ndo_change_mtu 用 ndo_change_mtu_rh75 替换试试?
查看对应内核中的文件
$ find / -name netdevice.hCopy
或者对于CentOS7.5之后的版本可以直接执行
sed -i 's/ndo_change_mtu/ndo_change_mtu_rh74/g' /home/dpvs/dpdk-stable-17.11.2/lib/librte_eal/linuxapp/kni/kni_net.c Copy
然后我们重新执行make操作
配置hugepage
和其他的一般程序不同,dpvs使用的dpdk并不是从操作系统中索要内存,而是直接使用大页内存(hugepage),极大地提高了内存分配的效率。
官方的配置过程中使用的是2MB的大页内存,这里的8192指的是分配了8192个2MB的大页内存,也就是一个node对应16GB的内存,一共分配了32GB的内存,这里的内存可以根据机器的大小来自行调整。但是如果小于1GB可能会导致启动报错。
挂载驱动模块
$ modprobe uiocd /home/dpvs/dpdk-stable-17.11.2 Copy
使用脚本查看目前机器和dpvs兼容的设备,这里我们只截取部分重点内容
1234567891011121314151617181920212223242526272829303132333435
$ ./usertools/dpdk-devbind.py --status'82599ES 10-Gigabit SFI/SFP+ Network Connection 10fb' if=eth0 drv=ixgbe unused=igb_uio'82599ES 10-Gigabit SFI/SFP+ Network Connection 10fb' if=eth1 drv=ixgbe unused=igb_uio'82599ES 10-Gigabit SFI/SFP+ Network Connection 10fb' if=eth4 drv=ixgbe unused=igb_uio *Active*'82599ES 10-Gigabit SFI/SFP+ Network Connection 10fb' if=eth5 drv=ixgbe unused=igb_uio *Active*'I350 Gigabit Network Connection 1521' if=eth2 drv=igb unused=igb_uio'I350 Gigabit Network Connection 1521' if=eth3 drv=igb unused=igb_uio Copy
编译安装dpvs
123456789101112131415161718
$ cd /home/dpvs/dpdk-stable-17.11.2/export RTE_SDK=$PWDcd /home/dpvs/cd bin/cd /home/dpvs/bin/ Copy
为了方便管理可以将相关的操作命令软链接到/sbin下方便全局执行
ln -s /home/dpvs/bin/dpvs /sbin/dpvs
http代理服务器(3-4-7层代理)-网络事件库公共组件、内核kernel驱动 摄像头驱动 tcpip网络协议栈、netfilter、bridge 好像看过!!!!
但行好事 莫问前程
--身高体重180的胖子





 浙公网安备 33010602011771号
浙公网安备 33010602011771号