网络库的编写
目前网络库根据公司需求已经完成基础框架,剩余的就是填空了
目前对于网络事件库编写注意事项有:
定时器
- tcp/udp/unix 等中需要有读写 event,每个event 都需要定时器,定时器一般使用最小堆实现,或者红黑树、
-
-
红黑树:
- 1、用于定时器时:增删时间复杂度为O(logn),查找最小节点的时间复杂度为O(h)
2、中序遍历为有序集合 -
存在问题与解决方法
问题:若存在多个定时时间相同的任务,红黑树要怎么操作。
解决方法:可以将节点插入到相同节点的右边(中序遍历可以得出:后面加入的定时任务,在后面执行)
- 1、用于定时器时:增删时间复杂度为O(logn),查找最小节点的时间复杂度为O(h)
-
最小堆:
- 时间复杂度:添加为O(logn),删除为O(1)
-
特点
1、最小值永远是根节点
2、增删的时间复杂度是O(logn)
3、查找最小节点的复杂度是O(1)
4、相较于红黑树更加稳定,因为是完全二叉树
-
时间轮
类似于时钟,秒针走一圈,分针前进一格
-
-
对于时间轮:
对于时间轮的实现,Timer依然是存放在链表上,但是借助了hash的思想,将相同间隔(或者相同周期的整数倍)的超时Timer放在同一个时间轮子上的槽(slot)上。时间轮上有一个指针,按照一个基准的频率(比如1ms,5ms,10ms等,libco中设置的是1ms)向前移动。这个基准的频率就是传递给epoll_wait()超时的值,也是定时器精度的基本单位;
时间轮实现
Linux定时器分为低精度定时器和高精度定时器两种类型,内核对其均有实现。本文讨论的是我们在应用程序开发中比较常见的低精度定时器。作为常用的基础组件,定时器常用的几种实现方法包括:基于排序链表实现、基于小根堆实现、基于红黑树实现、基于时间轮实现。本文讲解的是时间复杂度最优,也是linux内核采用的基于时间轮的实现方式。
采用有序链表实现的定时器,添加定时器的时间复杂度为O(n);采用小根堆或红黑树实现的定时器,添加定时器的时间复杂度为O(lgn)。之所以没法做到O(1)的复杂度,究其原因是所有定时器节点挂在一条链表(或一棵树)上。时间轮算法的核心思路是将定时器散列到多条链上,是典型的空间换时间的策略。下文从单个时间轮出发讲解,逐步扩展至linux实现定时器所采用的多级时间轮算法。
简单的单时间轮
单时间轮只有一个由bucket串起来的轮子,记时间轮的一个滴答时间为si(slot interval),即时间轮每转动一个槽的时间为si,如果有N个槽,那么时间轮转动一圈的时间为N * si如果时间轮开始转动的起始时间为ts,那么当有个定时器Timeout时间为t的定时器要加入到时间轮,那么应该将这个定时器放到哪个时间槽对应的链表呢?可以用下面的公式计算:
((t - ts)/ si) % N
下图所示的时间轮有8个bucket,每个bucket下链接着未来对应时刻到期的节点。假设图中相邻bucket到期时间的间隔为slot=1s,从当前时刻0s开始计时,1s时到期的定时器节点挂在bucket[1]下,2s时到期的定时器节点挂在bucket[2]下……当tick检查到时间过去了1s时,bucket[1]下所有节点执行超时动作,当时间到了2s时,bucket[2]下所有节点执行超时动作…….
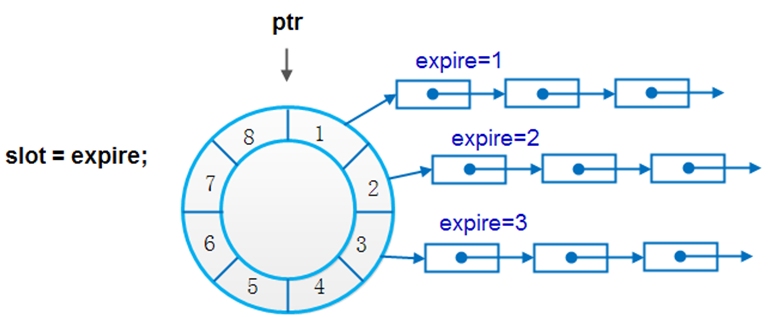
由于bucket是一个数组,能直接根据下标定位到具体定时器节点链,因此添加删除节点、定时器到期执行的时间复杂度均为O(1)。
但使用这个定时器所受的限制也显而易见:待添加的timer到期时间必须在8s以内。这显然不能满足实际需求。当然要扩展也很容易,直接增加bucket的个数就可以了。在 Linux 系统中,我们可以设置slot为1个jiffy(1/HZ)的定时器,假设最大的到期时间范围要达到 2^32个 jiffies,如果采用上面这样的单时间轮,我们就需要2^32个 bucket,这会带来巨大的内存消耗,显然是需要优化改进的。
改进的单时间轮
改进的单时间轮其实是一个对时间和空间折中的思路,即不会像单时间轮那样有O(1)的时间复杂度,但也不会像单时间轮那样对bucket个数有巨大的需求。其原理也很简单,就是每个bucket不单可以挂接到期时间expire=slot的定时器,还可挂接expire%N=slot的定时器(N为bucket个数)。这也正好顺应时间轮的轮回作用。如图2所示,定时器中expire表示到期时间,rotation表示节点在时间轮转了几圈后才到期。当当前时间指针指向某个bucket时,不能像简单时间轮那样直接对bucket下的所有节点执行超时动作,而是需要对链表中节点遍历一遍,判断轮子转动的次数是否等于节点中的rotation值,当两者相等时,方可执行超时操作。
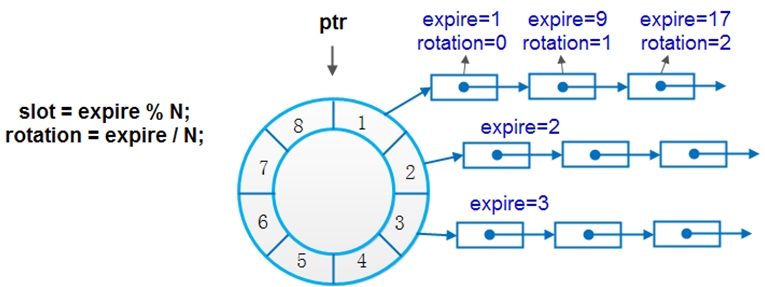
多时间轮
上面所述的时间轮都是单枪匹马战斗的,因此很难在时间和空间上都达到理想效果。Linux所实现的多时间轮算法,借鉴了日常生活中水表的度量方法,通过低刻度走得快的轮子带动高一级刻度轮子走动的方法,达到了仅使用较少刻度即可表示很大范围度量值的效果。
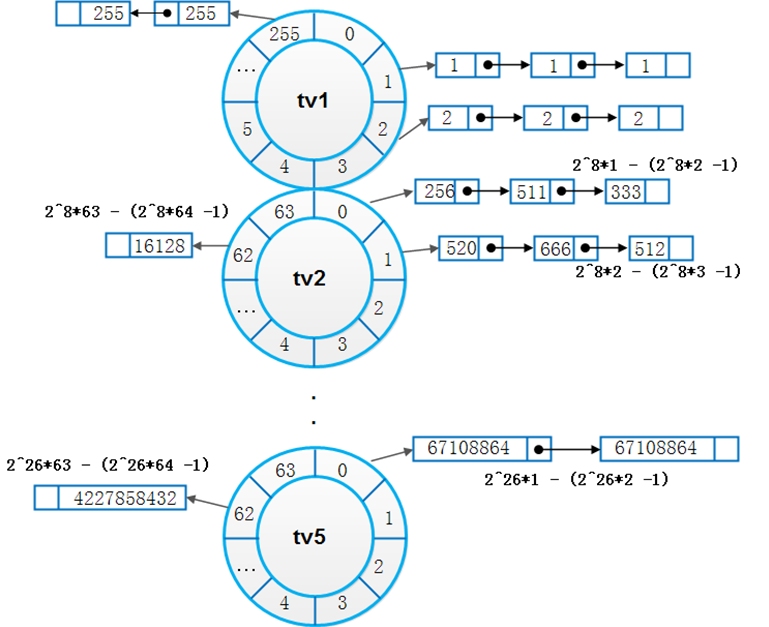
Linux定时器时间轮分为5个级别的轮子(tv1 ~ tv5),如图3所示。每个级别的轮子的刻度值(slot)不同,规律是次级轮子的slot等于上级轮子的slot之和。Linux定时器slot单位为1jiffy,tv1轮子分256个刻度,每个刻度大小为1jiffy。tv2轮子分64个刻度,每个刻度大小为256个jiffy,即tv1整个轮子所能表达的范围。相邻轮子也只有满足这个规律,才能达到“低刻度轮子转一圈,高刻度轮子走一格”的效果。tv3,tv4,tv5也都是分为64个刻度,因此容易算出,最高一级轮子tv5所能表达的slot范围达到了25664646464 = 2^32 jiffies。
Linux时间轮定时器算法的关键在于添加定时器操作和时间轮进位迁移链表操作。先来说添加定时器。添加定时器的关键又在于知道每个时间轮每一个刻度所能表示的到期时间的范围。图4列出了每一级时间轮能度量的jiffies的大小。假设有一个定时器在1000个jiffies后到期,根据图4容易看出其应该挂在tv2轮上。tv2轮每个刻度表示的大小为256个jiffies,则其应该挂在(1000/256)=3即第三个bucket上。
Linux在定时器到期检查上的操作也实现得很巧妙。假设curr_time=0x12345678,那么下一个检查的时刻为0x12345679。如果tv1.bucket[0x79]上链表非空,则下一个检查时刻tv1.bucket[0x79]上的定时器节点超时。如果curr_time到了0x12345700,低8位为空,说明有进位产生,这时移出8~13位对应的定时器链表(即正好对应着tv2轮),重新加入定时器系统,这就完成了一次进位迁移操作。同样地,当curr_time的第8-13位为0时,这表明tv2轮对tv3轮有进位发生,将curr_time第14-19位的值作为下标,移出tv3中对应的定时器链表,然后将它们重新加入到定时器系统中来。tv4,tv5依次类推。之所以能够根据curr_time来检查超时链,是因为tv1~tv5轮的度量范围正好依次覆盖了整型的32位:tv1(1-8位),tv2(9-14位),tv3(15-20位),tv4(21-26位),tv5(27-32位);而curr_time计数的递增中,低位向高位的进位正是低级时间轮转圈带动高级时间轮走动的过程。
对比
最后比较一下多级时间轮和单个简单时间轮的时间复杂度及空间复杂度:linux使用了总计256+64+64+64+64=512个bucket,即可实现[0,2^32) jiffies的超时范围。相比简单的单时间轮,时间上仅仅多了1/256次(为约等于值,忽略了tv2以上产生的进位操作)的链表迁移操作耗时。可以认为其添加、删除定时器节点及到期check的操作时间复杂度均为O(1)。
-
单层级的时间轮
用于实现时间窗口(如tcp滑动窗口)的限流与熔断
假设检测5秒内是否有100次操作
限流: 每秒都查看最近五秒是否有100次操作
熔断:每过五秒查看这五秒有没有100次操作
显而易见的,限流更加准确,但是很耗费时间,熔断没那么准确,但是相对来说没那么耗时间
熔断的应用:
DDos攻击:
客户端不断发送大量数据给服务器的过程为DDos攻击
解决办法:
在网络底层用DPDK判断
在应用层用熔断机制判断规定时间内客户端发送的数据包是否大于最大上限
读事件
- fd 可读时处理: 比如读取tcp数据时,tcp被reset 的情况 被fin的情况,会触发ev_mask什么标志;比如数据读取完了遇到eof怎么处理,读取数据时缓存buff读取完成, 填满了,也就是buff的len是n, recv 结果返回n, 怎么处理?对于recv 返回数值的处理?
- socket层读取数据后怎样回调到业务层,业务层处理时怎样使用状态机维护此时读取数据不足问题or数据还没有收完问题?也就是 event->tcp -->tcp_client/tcp_server的问题
-
typedef struct _ae_event_t { ae_event_loop_t *base; void *data; int32_t fd; int32_t mask; ae_event_cb *cb; uint64_t diff_msec; struct heap_node timer; ae_timer_cb timer_cb; list_head_t list; }ae_event_t; typedef struct _ae_tcp_t{ ae_handle_type type; ae_event_t read_watcher; ae_event_t write_watcher; int32_t fd; int32_t sys_errrno; int32_t err_code; int32_t alloc_size; ae_alloc_cb alloc_cb; ae_recv_msg_cb recv_fd_cb; ae_write_msg_cb write_fd_cb; ae_read_cb read_proc; ae_close_cb close_cb; ae_connection_cb accept_cb; ae_connect_t *connect_req; nsev_queue_t write_queue; nsev_queue_t write_completed_queue; int32_t write_queue_size; uint32_t flags; }ae_tcp_t;
static void ae_tcp_read(ae_event_loop_t * loop, ae_tcp_t *stream) { ae_buf_t buf; int nread = 0; int count = 0; ae_event_t *pev = NULL; count = 10; pev = &stream->read_watcher; while (stream->read_proc && stream->recv_fd_cb && && (pev->mask & AE_READABLE) && (count > 0)) { count--; assert(stream->alloc_cb); stream->alloc_cb(stream, 2048, &buf); assert(buf.len > 0); assert(buf.base); assert(stream->fd >= 0); if (stream->recv_fd_cb) { do { nread = stream->recv_fd_cb(stream->fd, buf.base, buf.len, (void *)stream); }while (nread < 0 && errno == EINTR); } if (nread < 0) { /* Error */ if (errno == EAGAIN || errno == EWOULDBLOCK) { /* Wait for the next one. */ if (pev->mask & AE_READABLE) { ae_add_event_active(loop, &stream->read_watcher); } stream->sys_errrno = EAGAIN; stream->err_code = AE_ERROR_TCP_READ_AGAIN; if (stream->read_proc) { stream->read_proc(stream, 0, buf); } return; } else { stream->sys_errrno = errno; stream->err_code = AE_ERROR_TCP_READ_FAILED; if (stream->read_proc) { stream->read_proc(stream, -1, buf); } return; } } else if (nread == 0) {/* EOF */ stream->flags |= AE_STREAM_EOF; stream->sys_errrno = 0; stream->err_code = AE_ERROR_TCP_READ_EOF; ae_del_event_disable(&stream->read_watcher); if (stream->read_proc) { stream->read_proc(stream, -1, buf); } return; } else { /* Successful read */ int32_t buflen = buf.len; if (stream->read_proc) { stream->read_proc(stream, nread, buf); } if (nread < buflen) { return; } } } if(0 == count && (stream->read_watcher.mask & AE_READABLE)) { ae_move_event_2_base_list(loop, &stream->read_watcher); } }
写事件
- write的时候怎样处理write的异常, 怎样使用epoll+write完成数据的写,缓存的释放什么完成。
- tcp 写回调怎样设置 ,tcp socket层的写怎样设置, event怎样处理写,回调怎样处理。
struct uv_write_t { void* data; ae_tcp_t* handle; nsev_queue_t queue; ae_write_cb cb; int write_index; ae_buf_t bufs[MAX_REQ_BUF]; int nbufs; int sys_error; int error; }uv_write_t;
对于最底层事件回调的处理!
static void ae_tcp_stream_io(ae_event_loop_t * loop, ae_event_t *ev, int events) { ae_tcp_t *stream = NULL; int *a = NULL; /* either UV__IO_READ or UV__IO_WRITE but not both */ assert(!!(events & AE_READABLE ) ^ !!(events & AE_WRITABLE)); if (events & AE_READABLE) stream = container_of(ev, ae_tcp_t, read_watcher); else stream = container_of(ev, ae_tcp_t, write_watcher); assert(stream->type == AE_TCP); assert(!(stream->flags | AE_CLOSING)); if(stream->connect_req) { ae_stream_connect(stream); }else if (events & AE_READABLE) { assert(stream->fd >= 0); ae_tcp_read(loop, stream); //cl_tcp_read_start } else { assert(stream->fd >= 0); ae_tcp_write_cb1(loop, stream); ae_tcp_write_callbacks(loop, stream); } }
int ae_write_req(uv_write_t* req, cl_tcp_t *tcp, ae_buf_t bufs[], int bufcnt, ae_write_cb cb) { int empty_queue; ae_tcp_t *stream = NULL; assert(bufcnt > 0 && bufcnt < MAX_REQ_BUF); stream = &tcp->ev_tcp; if (stream->fd < 0) { stream->sys_errrno = EBADF; stream->err_code = AE_ERROR_TCP_WRITE_SOCKFD_BAD; return -1; } empty_queue = (stream->write_queue_size == 0); req->cb = cb; req->handle = stream; req->error = 0; nsev_queue_init(&req->queue); memcpy(req->bufs, bufs, bufcnt * sizeof(ae_buf_t)); req->nbufs = bufcnt; req->write_index = 0; stream->write_queue_size += ae_buf_count(bufs, bufcnt); nsev_queue_insert_tail(&stream->write_queue, &req->queue); /* If the queue was empty when this function began, we should attempt to * do the write immediately. Otherwise start the write_watcher and wait * for the fd to become writable. */ if (stream->connect_req) { /* Still connecting, do nothing. */ }else if (empty_queue && stream->write_queue_size > 0) { // 以前没有数据要发送, 所以此次直接write ae_tcp_write_cb1(tcp->base, stream); ae_tcp_write_callbacks(tcp->base, stream); }else { /* *以前 还有数据没有发送完, 说明此时正在等待可写 */ assert(!(stream->flags & AE_STREAM_WRITEABLE)); ae_add_event_active(stream->loop, &stream->write_watcher); } return 0; }
static void ae_tcp_write_callbacks(ae_event_loop_t * loop, ae_tcp_t* stream) { uv_write_t* req; nsev_queue_t* q; ae_tcp_t* stream = req->handle; while (!nsev_queue_empty(&stream->write_completed_queue)) { /* Pop a req off write_completed_queue. */ q = nsev_queue_head(&stream->write_completed_queue); req = nsev_queue_data(q, uv_write_t, queue); nsev_queue_remove(q); /*即使写失败了。这部分数据被丢弃,所以相当于写成功,更新write_queue_size*/ stream->write_queue_size -= ae_write_req_size(req); /* NOTE: call callback AFTER freeing the request data. */ if (req->cb) { req->cb(req, req->error); } } /* Write queue drained. */ if (!ae_write_queue_head(stream)) { // is empty ae_del_event_disable(loop, &stream->write_watcher); } } #define MAX_IOV_COUNT 64 static void ae_tcp_write_cb1(ae_event_loop_t * baseloop, ae_tcp_t* stream) { uv_write_t* req; struct iovec* iov; ae_buf_t bufpool[MAX_IOV_COUNT]; int iovcnt; ssize_t n = -2; int write_over = 0; if (stream->flags | AE_CLOSING) { return; } start: assert(stream->fd >= 0); /* Get the request at the head of the queue. */ req = ae_write_queue_head(stream); if (!req) { assert(stream->write_queue_size == 0); return; } assert(req->handle == stream); iov = (struct iovec*) &(req->bufs[req->write_index]); // 待写的buf个数,nbufs是总数,write_index是当前已写的个数 iovcnt = req->nbufs - req->write_index; if (iovcnt > MAX_IOV_COUNT) { iovcnt = MAX_IOV_COUNT; } if (iovcnt == 1) { n = stream->write_fd_cb(stream->fd, iov[0].iov_base, iov[0].iov_len, (void *)stream); } else { do { n = writev(stream->fd, iov, iovcnt); }while (n == -1 && errno == EINTR); } if (n < 0) { if (errno != EAGAIN && errno != EWOULDBLOCK && errno != ENOBUFS) { req->sys_error = errno; req->error = AE_ERROR_TCP_WRITE_FAILED; ae_write_req_finish(req); ae_del_event_disable(baseloop, stream->write_watcher) return; } } else { /* Successful write */ while (n >= 0) { ae_buf_t* buf = &(req->bufs[req->write_index]); size_t len = buf->len; assert(req->write_index < req->nbufs); if ((size_t)n < len) { buf->base += n; buf->len -= n; stream->write_queue_size -= n; n = 0; write_over = 1; break; } else { req->write_index++; assert((size_t)n >= len); n -= len; assert(stream->write_queue_size >= len); stream->write_queue_size -= len; if (req->write_index == req->nbufs) { assert(n == 0); ae_write_req_finish(req); /* TODO: start trying to write the next request. */ return; } } } } /* Either we've counted n down to zero or we've got EAGAIN. */ assert(n == 0 || n == -1); ae_add_event_active(baseloop, &stream->write_watcher); }
c/s结构
typedef struct ae_connect_t { ae_event_loop_t *base_loop; void *data; ae_connect_cb cb; ae_tcp_t* stream; }ae_connect_t; typedef struct cl_tcp_connect_req { ae_event_t timer; void *cb; void *data; ae_connect_t req_conn; cl_tcp_t *tcp; } cl_tcp_connect_req; typedef struct cl_tcp_server{ ae_tcp_t ev_tcp; ae_event_loop_t *base; cl_ae_handle_type_t type; void *data; cl_tcp_server_cb server_cb; void *stop_cb; }cl_tcp_server;
- 对于 cl_tcp server的 start_open_listen的处理 ;cl_tcp_server 在 connect_cb close_cb 上的处理
- cl_tcp_client 在connect peer 上的处理, cl_tcp_client connect在connect 超时以及出错的处理
信号处理
怎样完成sigpipe 等处理。 同时管道pipe socketpair 对于多进程的使用
异常处理
- tcp udp 等错误如何设置 并返回到err_code 系统的sys_errno怎样发挥便于定位
日志的处理
- 日志的分级, debug error warn notice 等,其中对debug级别的 细分,可以分为多少个等级? 比如deng-evnet 、debug-timer、debug-ssl、debug-server 等的划分
内存的处理
参考redis的slab处理or 参考memcache nginx等的处理
socket 地址的处理
typedef struct cl_sockaddr{ union { unsigned short type; struct sockaddr addr; struct sockaddr_in v4; struct sockaddr_in6 v6; struct sockaddr_un un; struct sockaddr_tipc tipc; struct sockaddr_nl netlink; struct sockaddr_ll ll; } u; } cl_sockaddr;
IO复用
- 抽象出接口, 根据需求选择 epoll or select 去init
- 抽象出dispatch的接口, 根据初始化结果去执行epoll_wait or poll
- 抽象出 loop的接口
const struct eventop epoll_ops = { "epoll", epoll_init, epoll_add, epoll_del, epoll_dispatch, epoll_resize, epoll_done, };
基本数据结构
- hash的处理, resize的时候怎样处理,是直接全部 copy到new_table呢, 还是old_table new_table都保持,将old_tablemanman同步到new_table;如何设计rehash 也就是如何遍历hash表
- hash遍历 支持分层遍历 or 支持每次遍历部分?
- 参考之前的文章
- list 数据结构以及hlist 数据结构
- heap 数据结构
- hmap结构
- bitmap数据结构
- 红黑树
- str相关安全处理
- 随机数random rand
- 跳表 skiplist
- signale 处理 SIGSEGV、SIGABRT SIGFPE SIGILL SIGBUS SIGINT SIGQUIT SIGTERM 以及coredump生成 以及bugdump文件生成
- ini文件处理库 protobuf xml json 格式文件相互转换库
- crc、 MD5 、arc4 、jhash等算法
- daemon进程接口封装
- atomic的实现、cas的实现
- 32 位 64位 等夸平台问题
- lockfree 中的 无锁队列实现ring 等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号