【大数据】对于行动操作中 arggrrgate的理解
内容来源于: 知乎博主
后面两个图是我对博主所讲知识的理解 以及计算流程展示
-
首先,对于reduce和fold来说都有一个要求就是: 返回值的类型必须和rdd的数据类型相同。
- 比如数据的类型是int,那么返回的结果也要是int。
-
但是对于有些场景这个是不适用的,
-
比如我们想求平均,我们需要知道term的和,也需要知道term出现的次数,所以我们需要返回两个值。
-
这个时候我们初始化的值应该是0, 0,也就是对于加和与计数而言都是从0开始的,接着我们需要传入两个函数,比如写成这样:
-
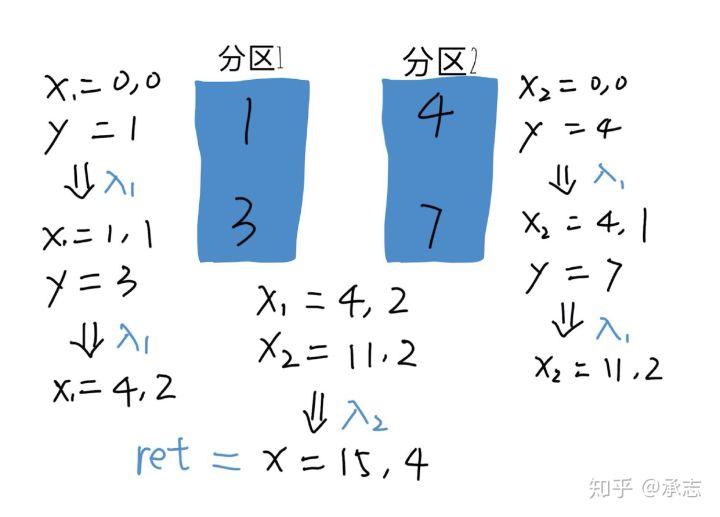
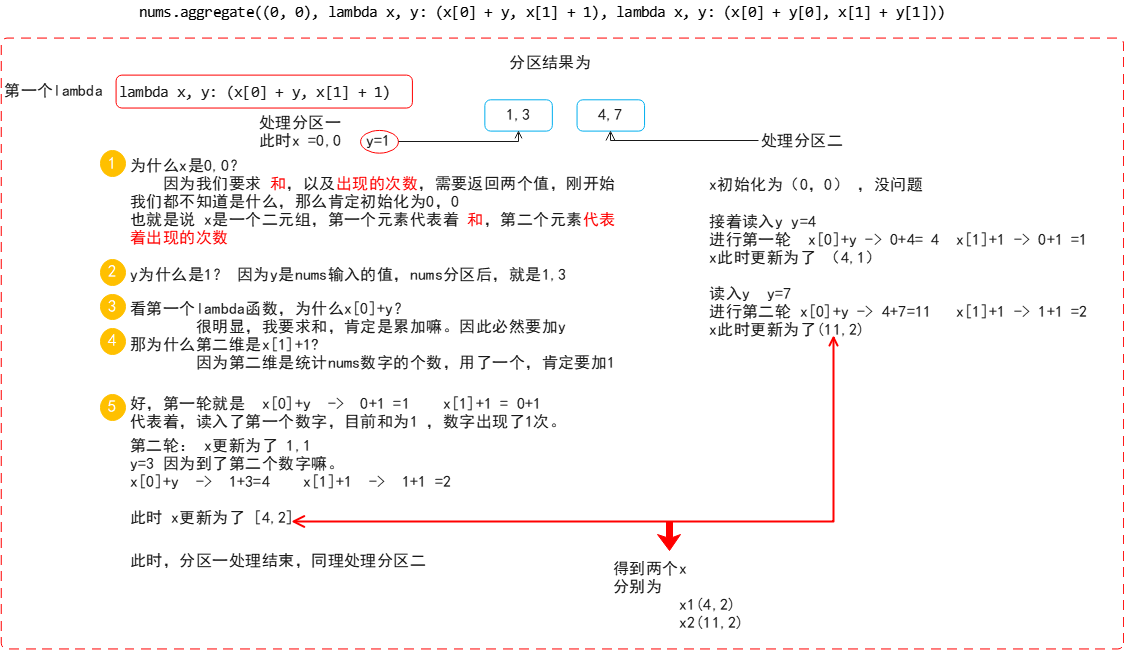
nums.aggregate((0, 0), lambda x, y: (x[0] + y, x[1] + 1), lambda x, y: (x[0] + y[0], x[1] + y[1])) -
首先是第一个lambda函数 (
lambda x, y: (x[0] + y, x[1] + 1)),-
这里的x不是一个值而是两个值 ,或者说是一个二元组,也就是我们最后返回的结果,即 (0,0)
- 在我们的返回预期里,第一个返回的数是nums的和,第二个返回的数是nums当中数的个数。
-
而这里的y则是nums输入的结果,显然nums输入的结果只有一个int,所以这里的y是一维的。 即1 和3
- 那么我们要求和当然是用x[0] + y,也就是说把y的值加在第一维上,第二维自然是加一,因为我们每读取一个数就应该加一。
-
-
第二个函数和第一个不同,它不是用在处理nums的数据的,而是 用来处理分区的 。
- 当我们执行aggregate的时候,spark并不是单线程执行的,
- 它会将nums中的数据拆分成许多分区,每个分区得到结果之后需要合并,合并的时候会调用这个函数。
- 和第一个函数类似,第一个x是最终结果,而y则是其他分区运算结束需要合并进来的值。
- 所以这里的y是二维的,第一维是某个分区的和,第二维是某个分区当中元素的数量,那么我们当然要把它都加在x上。
-

-
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号