B-tree&B+tree
B-tree&B+tree
B-tree,B是balance,一般用于数据库的索引。使用B-tree结构可以显著减少定位记录时所经历的中间过程,从而加快存取速度。而B+tree是B-tree的一个变种,大名鼎鼎的MySQL就普遍使用B+tree实现其索引结构。
那数据库为什么使用这种结构?
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。
为了达到这个目的,磁盘按需读取,要求每次都会预读的长度一般为页的整数倍。而且数据库系统将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。并把B-tree中的m值设的非常大,就会让树的高度降低,有利于一次完全载入。
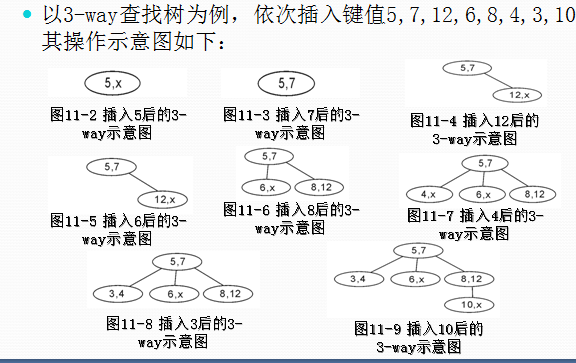
m-way查找树
首先介绍一下m-way查找树,顾名思义就是一棵树的每个节点的度小于等于m。
故,它的性质如下:
- 每个节点的键值数小于m
- 每个节点的度小于等于m
- 键值按顺序排列
- 子树的键值要完全小于或大于或介于父节点之间的键值
B-tree
B-tree是一种平衡的m-way查找树。
B-tree利用多个分支(称为子树)的结点,减少获取记录时所经历的结点数,从而达到节省存取时间的目的。
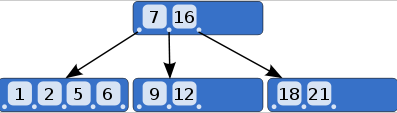
一棵度为m的B-tree应满足的性质:
- 每个结点的子结点个数≤m;
- 根结点若不是叶子结点,它至少有两个子结点
- 除根和叶子结点外,每个结点的子结点个数≥ [m/2]
- 所有的叶子结点都出现在同一层,而且不带有信息
- 非叶子结点若具有j+1个子结点,那么它包含j个关键字(其中,j≤m-1)
B-树的非叶子结点的结构形式:
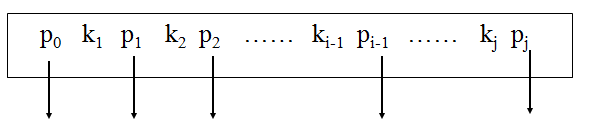
ki (1≤i≤j)是关键字,所有关键字的值是唯一的;pi (0≤i≤j)是指向该结点的子结点的指针
例如图中的P1,它指向的子树的关键字应该大于k1,小于k2
在给定的m阶B-树中查找一个给定值v相等的关键字,必须从根结点开始进行查找,一般采用二分查找
B-tree的插入
- 插入的节点少于M-1个键值,则直接插入。
- 插入的节点的键值已等于m-1,则将此节点分为二,因为一棵m的B-tree,最多只能有m-1个键值
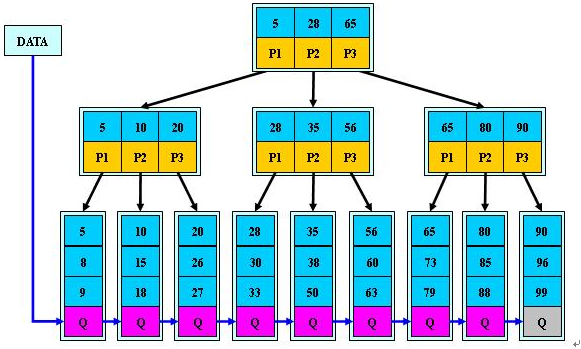
B+tree
B+树是B-树的变体。
有几点不同的地方:
- 非叶子结点的子树指针与关键字个数相同
- 为所有叶子结点增加一个链指针
- 所有关键字都在叶子结点出现
参考
http://blog.csdn.net/hguisu/article/details/7786014
http://blog.sina.com.cn/s/blog_6776884e0100ohvr.html
http://baike.baidu.com/link?url=8Au1iocebretZtJN2E6JcIolkM79PDwQ22dJEESfntDvYUXHKfZ45s4zcd4PoCjm
本文 由 cococo点点 创作,采用 知识共享 署名-非商业性使用-相同方式共享 3.0 中国大陆 许可协议进行许可。欢迎转载,请注明出处:
转载自:cococo点点 http://www.cnblogs.com/coder2012


 浙公网安备 33010602011771号
浙公网安备 33010602011771号