RabbitMQ集群搭建
RabbitMQ集群原理
多个RabbitMQ单节点,经过配置组成RabbitMQ集群;
集群节点之间共享元数据,比如有节点1,节点2,节点3,3个节点是普通集群,它们仅有相同的元数据,即交换机,队列的结构,不共享队列数据(默认);
RabbitMQ节点数据相互转发,客户端通过单一节点可以访问所有数据;
消息只存在其中的一个节点里面,假如消息A存储在节点1,消费者连接节点1消费消息时,可以直接取出来,但如果消费者连接的是其他节点,那RabbitMQ会把队列中的消息从存储它的节点中取出,并经过连接节点转发后再发送给消费者;
集群拓扑图
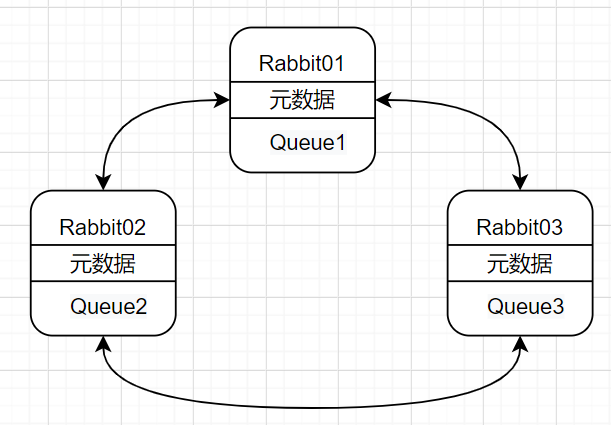
普通集群搭建步骤
设置主机名或host,使得节点之间可以通过名称访问;
安装RabbitMQ单节点;
复制Erlang cookie;集群需要保证各个节点有相同的token令牌,Erlang Cookie 值必须相同,也就是一个集群内 RABBITMQ_ERLANG_COOKIE 参数的值必须相同, 相当于不同节点之间通讯的密钥,erlang.cookie是erlang的分布式token文件,集群内各个节点的erlang.cookie需要相同,才可以互相通信;
启动RabbitMQ并组成集群;
docker-compose.yml如下
version: "3"
services:
rabbit1:
image: rabbitmq:3.8.12-management-alpine
hostname: rabbit_node1
ports:
- 6672:5672 #集群内部访问的端口
- 25672:15672 #外部访问的端口
environment:
- RABBITMQ_DEFAULT_USER=admin #用户名
- RABBITMQ_DEFAULT_PASS=dev #密码
- RABBITMQ_ERLANG_COOKIE='rabbitmq_cookie'
privileged: true
rabbit2:
image: rabbitmq:3.8.12-management-alpine
hostname: rabbit_node2
ports:
- 6673:5672
- 25673:15672 #外部访问的端口
environment:
- RABBITMQ_ERLANG_COOKIE='rabbitmq_cookie'
links:
- rabbit1
privileged: true
rabbit3:
image: rabbitmq:3.8.12-management-alpine
hostname: rabbit_node3
ports:
- 6674:5672
- 25674:15672 #外部访问的端口
environment:
- RABBITMQ_ERLANG_COOKIE='rabbitmq_cookie'
links:
- rabbit1
- rabbit2
privileged: true
privileged:true 使用该参数,container内的root拥有真正的root权限,否则容器出现permission denied;
hostname自定义Docker容器的 hostname;
节点2
# 进入2号节点 docker exec -it compose_rabbit2_1 bash # 停止2号节点的rabbitmq rabbitmqctl stop_app # 配置2号节点,加入集群,--ram是以内存方式加入,忽略该参数默认为磁盘节点,rabbit@后面接hostname rabbitmqctl join_cluster rabbit@rabbit_node1 # 启动2号节点的rabbitmq rabbitmqctl start_app # 退出 exit
节点3
# 进入3号节点 docker exec -it compose_rabbit3_1 bash # 停止3号节点的rabbitmq rabbitmqctl stop_app # 配置3号节点,加入集群,--ram是以内存方式加入,忽略该参数默认为磁盘节点,rabbit@后面接hostname rabbitmqctl join_cluster rabbit@rabbit_node1 # 启动3号节点的rabbitmq rabbitmqctl start_app # 退出 exit

参考:[https://www.rabbitmq.com/rabbitmqctl.8.html#join_cluster]

参考:[https://www.rabbitmq.com/configure.html]

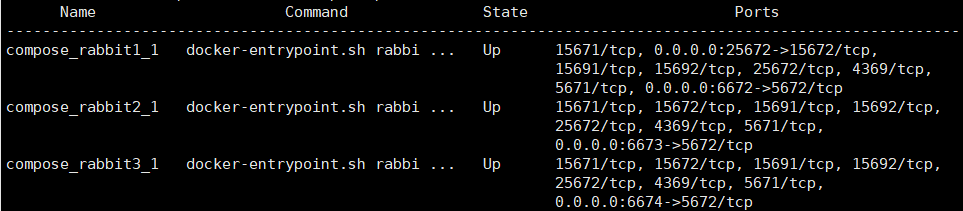
访问节点一的web管控台,可以看到多个节点

在节点1创建队列(持久化的),发送消息,测试节点2,节点3是否创建队列,接收到消息;
![]()
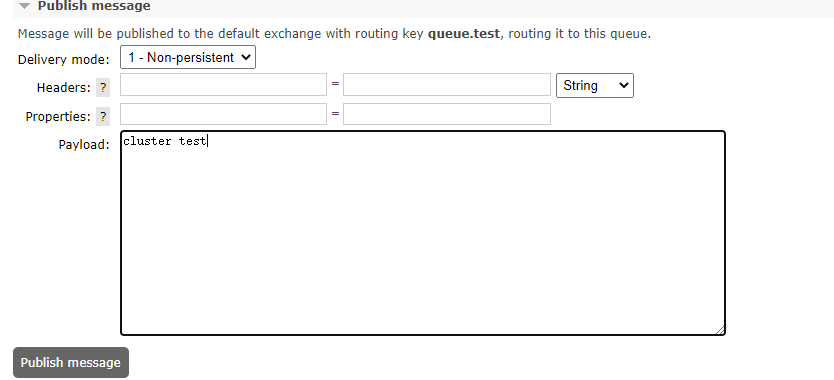
节点2通过节点自身的web管控台可以看到队列和消息

节点3通过节点自身的web管控台可以看到队列和消息

测试如果把节点1停止,节点2和节点3是否会收不到消息
节点2通过节点自身的web管控台可以看到节点1停止,该队列状态显示down;
![]()
节点3通过节点自身的web管控台可以看到节点1停止,该队列状态显示down;
![]()
节点1重新启动
节点2,节点3该队列的状态恢复;
![]()
如果磁盘节点挂掉后,如果没开启持久化数据就丢失了,其他节点也无法获取消息;
集群镜像队列原理
多个RabbitMQ单节点,经过配置组成RabbitMQ集群;
集群节点之间共享元数据,且共享队列数据;
RabbitMQ节点数据互相转发,客户端通过单一节点可以访问所有数据;
集群+镜像队列拓扑图

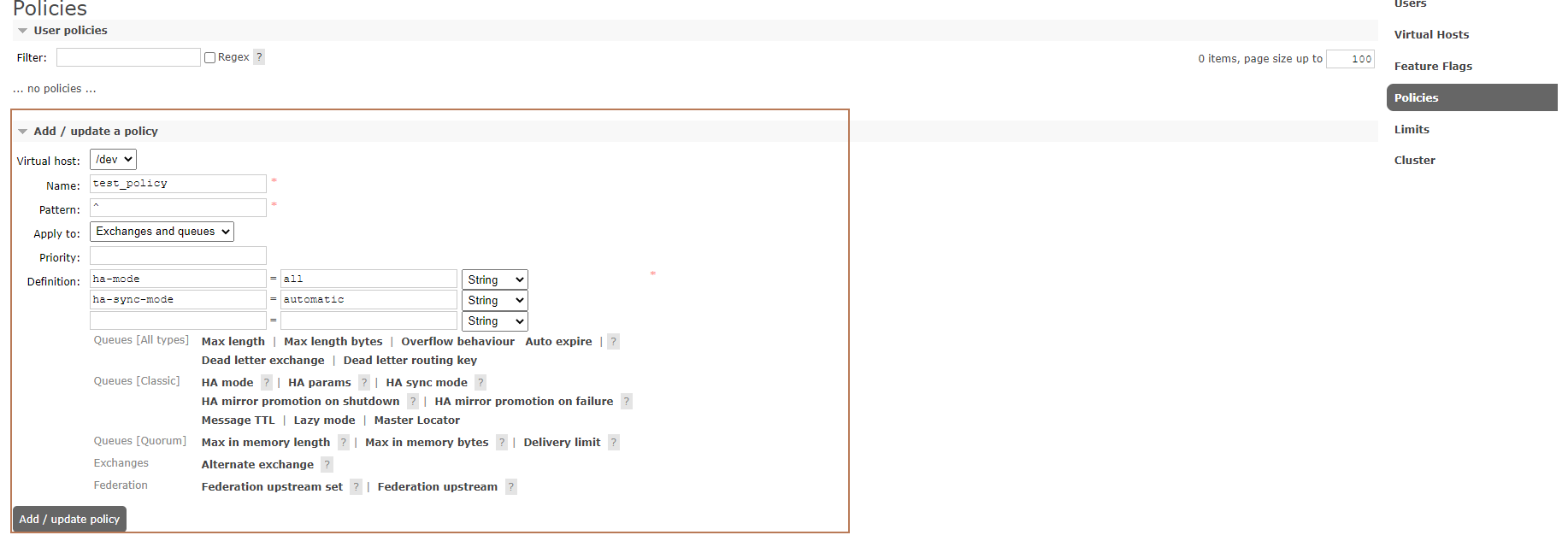
rabbitmq的策略policy是用来控制和修改集群的vhost队列和Exchange复制行为,即设置哪些Exchange或者queue的数据需要复制、同步,以及如何复制同步;
创建一个策略来匹配队列
-
路径:rabbitmq管理页面 —> Admin —> Policies —> Add / update a policy
-
参数: 策略会同步同一个VirtualHost中的交换器和队列数据
- name:自定义策略名称
- Pattern:^ 匹配符,代表匹配所有
- Definition:ha-mode=all 为匹配类型,分为3种模式:all(表示所有的queue)
ha-mode: 指明镜像队列的模式,可选下面的其中一个 all:表示在集群中所有的节点上进行镜像同步(一般都用这个参数) exactly:表示在指定个数的节点上进行镜像同步,节点的个数由ha-params指定 nodes:表示在指定的节点上进行镜像同步,节点名称通过ha-params指定 ha-sync-mode:镜像消息同步方式 automatic(自动),manually(手动)
也可以使用命令操作:
rabbitmqctl set_policy
配置好后,+2的意思是有三个节点,一个节点本身和两个镜像节点, 且可以看到策略名称;

集群重启的顺序是固定的,并且是相反的,最后关闭必须是磁盘节点,否则容易造成集群启动失败、数据丢失等异常情况;
集群+镜像队列只是实现了数据冗余和可扩展,并没有做到高可用;
实现高可用方式:
客户端负载均衡,直接在SpringBoot配置中设置多个地址,如下:
spring.rabbitmq.addresses=127.0.0.1,127.0.0.2,127.0.0.3
服务端负载均衡
配置HAProxy+Keepalived;
HAProxy一款高可用,负载均衡以及基于TCP和HTTP应用的代理软件,可以代理4层和7层,适合负载较大的web站点,可以支持数以万计的并发连接;
Keepalived用于做热备,主要来防止服务器单点故障的发生(如HAProxy宕机,使用Virtual IP解决),以VRRP协议为实现;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号