
10 Spark安装以及命令使用方法介绍
1.下载压缩文件并解压

2.修改文件名,赋予权限


3.修改Spark的配置文件spark-env.sh
编辑spark-env.sh文件(vim ./conf/spark-env.sh),在第一行添加以下配置信息:


有了上面的配置信息以后,Spark就可以把数据存储到Hadoop分布式文件系统HDFS中,也可以从HDFS中读取数据。如果没有配置上面信息,Spark就只能读写本地数据,无法读写HDFS数据。
配置完成后就可以直接使用,不需要像Hadoop运行启动命令。
4.通过运行Spark自带的示例,验证Spark是否安装成功。
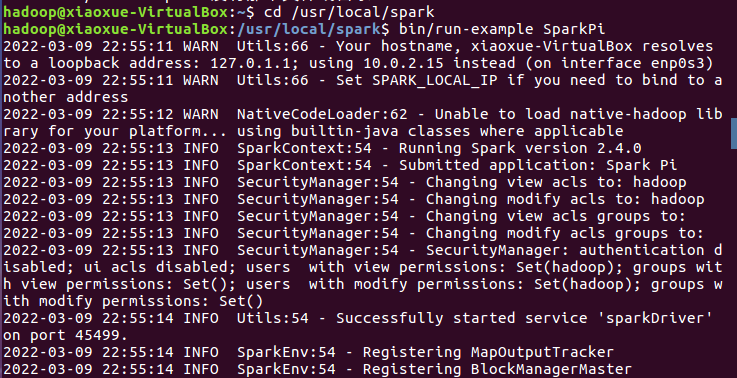
过滤后的运行结果如下图示,可以得到π 的 5 位小数近似值:

5.采用本地模式,在CPU核心上运行spark-shell:

或

也可以执行“spark-shell –help”命令,获取完整的选项列表。
输入scala代码进行调试
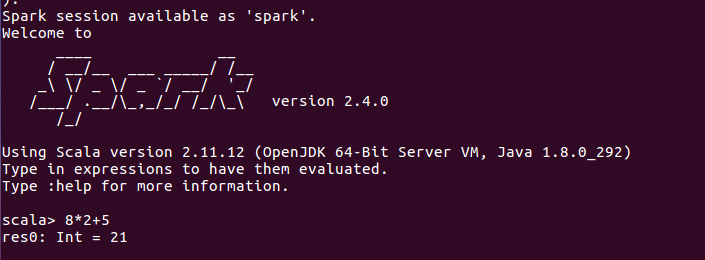
输入:quit 退出,也可以直接使用“Ctrl+D”组合键,退出Spark Shell。

6.编写Scala独立应用程序
- 安装sbt
“http://www.scala-sbt.org”下载安装文件sbt-1.3.8.tgz,保存到下载目录。
创建安装目录

解压
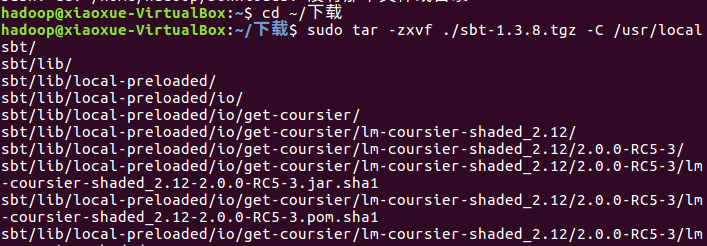
赋予权限并复制到创建的安装的目录下

在安装目录中使用下面命令创建一个Shell脚本文件,用于启动sbt


增加可执行权限

查看sbt版本
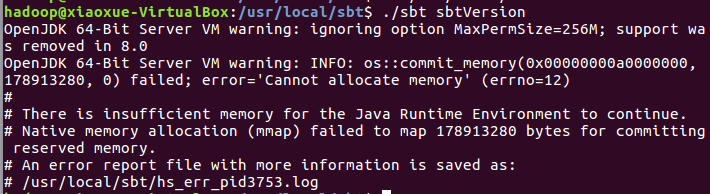
进入用户主文件夹,创建根目录和所需的文件夹结构

在 ./sparkapp/src/main/scala 下建立一个名为 SimpleApp.scala 的文件

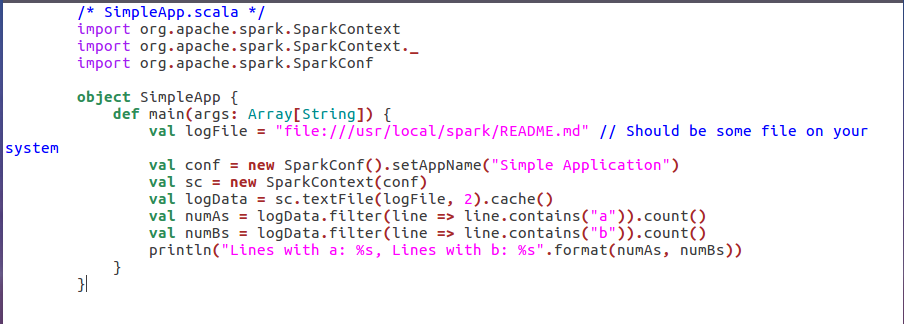
在./sparkapp 中新建文件 simple.sbt,声明该独立应用程序的信息以及与 Spark 的依赖关系


 浙公网安备 33010602011771号
浙公网安备 33010602011771号