清晰架构(Clean Architecture)的Go微服务: 依赖注入(Dependency Injection)
在清晰架构(Clean Architecture)中,应用程序的每一层(用例,数据服务和域模型)仅依赖于其他层的接口而不是具体类型。 在运行时,程序容器¹负责创建具体类型并将它们注入到每个函数中,它使用的技术称为依赖注入²。 以下是要求。
容器包的依赖关系:
-
容器包是唯一依赖于具体类型和许多外部库的包,因为它需要创建具体类型。 本程序中的所有其他软件包主要仅依赖于接口。
-
外部库可以包括DB和DB连接,gRPC连接,HTTP连接,SMTP服务器,MQ等。
-
#2中提到的具体类型的资源链接只需要创建一次并放入注册表中,所有后来的请求都将从注册表中检索它们。
-
只有用例层需要访问并依赖于容器包。
依赖注入的核心是工厂方法模式(factory method pattern)。
工厂方法模式(Factory Method Pattern):
实现工厂方法模式并不困难,这里³描述了是如何在Go中实现它的。困难的部分是使其可扩展,即如何避免在添加新工厂时修改代码。
处理新工厂的方式有很多种,下面是常见的三种:
-
(1)使用if-else语句⁴
-
(2) 使用映射(map)保存不同的工厂⁵
-
(3) 使用反射生成新的具体类型。
#1不是一个好选择,因为你需要在添加新类型时修改现有代码。 #3是最好的,因为添加新工厂时现有代码不需更改。在Java中,我会使用#3,因为Java具有非常优雅的反射实现。你可以执行类似“(Animal)Class.forName(”className“)。newInstance()”的操作,即你可以将类的名称作为函数中的字符串参数传递进来,并通过反射从中创建一个类型的新实例,然后将结构转换为适当的类型(可能是它的一个超级类型(super type),这是非常强大的。由于Go的反射不如Java,#3不是一个好选择。在Go中,由反射创建的实例是反射类型而不是实际类型,并且你无法在反射类型和实际类型之间转换类型,它们处于两个不同的世界中,这使得Go中的反射难以使用。所以我选择#2,它比#1好,但是在添加新类型时需要更改少部分代码。
以下是数据存储工厂的代码。它有一个“dsFbInterface”,其中有一个“Build”函数需要由每个数据存储工厂实现。 “Build”是工厂的关键部分。 “dsFbMap”是每个数据库(或gRPC)的代码(code)与实际工厂之间的映射。这是添加数据库时需要更改的部分。
// To map "database code" to "database interface builder"
// Concreate builder is in corresponding factory file. For example, "sqlFactory" is in "sqlFactory".go
var dsFbMap = map[string]dsFbInterface{
config.SQLDB: &sqlFactory{},
config.COUCHDB: &couchdbFactory{},
config.CACHE_GRPC: &cacheGrpcFactory{},
}
// DataStoreInterface serve as a marker to indicate the return type for Build method
type DataStoreInterface interface{}
// The builder interface for factory method pattern
// Every factory needs to implement Build method
type dsFbInterface interface {
Build(container.Container, *config.DataStoreConfig) (DataStoreInterface, error)
}
//GetDataStoreFb is accessors for factoryBuilderMap
func GetDataStoreFb(key string) dsFbInterface {
return dsFbMap[key]
}
以下是“sqlFactory”的程序,它实现了上面的代码中定义的“dsFbInterface”。 它为MySql数据库创建数据存储。 在“Build”函数中,它首先从注册表中检索数据存储(MySql),如果找到,则返回,否则创建一个新的并将其放入注册表。
因为注册表可以存储任何类型的数据,所以我们需要在检索后将返回值转换为适当的类型(*sql.DB)。 “databasehandler.SqlDBTx”是实现“SqlGdbc”接口的具体类型。 它的创建是为了支持事务管理。 代码中调用“sql.Open()”来打开数据库连接,但它并没有真正执行任何连接数据库的操作。 因此,需调用“db.Ping()”去访问数据库以确保数据库正在运行。
// sqlFactory is receiver for Build method
type sqlFactory struct{}
// implement Build method for SQL database
func (sf *sqlFactory) Build(c container.Container, dsc *config.DataStoreConfig) (DataStoreInterface, error) {
key := dsc.Code
//if it is already in container, return
if value, found := c.Get(key); found {
sdb := value.(*sql.DB)
sdt := databasehandler.SqlDBTx{DB: sdb}
logger.Log.Debug("found db in container for key:", key)
return &sdt, nil
}
db, err := sql.Open(dsc.DriverName, dsc.UrlAddress)
if err != nil {
return nil, errors.Wrap(err, "")
}
// check the connection
err = db.Ping()
if err != nil {
return nil, errors.Wrap(err, "")
}
dt := databasehandler.SqlDBTx{DB: db}
c.Put(key, db)
return &dt, nil
}
数据服务工厂(Data service factory)
数据服务层使用工厂方法模式来创建数据服务类型。 可以有不同的策略来应用此模式。 在构建数据服务工厂时,我使用了三种不同的策略,每种策略都有其优缺点。 我将详细解释它们,以便你可以决定在那种情况下使用哪一个。
基础工厂(Basic factory)
最简单的是“cacheGrpcFactory”,因为数据存储只有一个底层实现(即gRPC),所以只创建一个工厂就行了。
二级工厂(Second level factory)
对于数据库工厂,情况并非如此。 因为我们需要每个数据服务同时支持多个数据库,所以需要二级工厂,这意味着对于每种数据服务类型,例如“UserDataService”,我们需要为每个支持的数据库使用单独的工厂。 现在,由于有两个数据库,我们需要两个工厂。
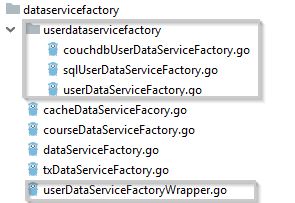
你可以从上面的图像中看到,我们需要四个文件来完成“UserDataService”,其中“userDataServiceFactoryWrapper.go”是在“userdataservicefactory”文件夹中调用实际工厂的封装器(wrapper)。 “couchdbUserDataServiceFactory.go”和“sqlUserDataServiceFactory.go”是CouchDB和MySql数据库的真正工厂。 “userDataServiceFactory.go”定义了接口。 如果你有许多数据服务,那么你将创建许多类似代码。
简化工厂(Simplified factory)
有没有办法简化它? 有的,这是第三种方式,但也带来一些问题。 以下是“courseDataServiceFactory.go”的代码。 你可以看到只需一个文件而不是之前的四个文件。 代码类似于我们刚才谈到的“userDataServiceFactory”。那么它是如何如何简化代码的呢?
关键是为底层数据库链接创建统一的接口。 在“courseDataServiceFactory.go”中,可以在调用“dataStoreFactory”之后获得底层数据库链接统一接口,并将“CourseDataServiceInterface”的DB设置为正确的“gdbc”(只要它实现“gdbc”接口,它可以是任何数据库链接)。
var courseDataServiceMap = map[string]dataservice.CourseDataInterface{
config.COUCHDB: &couchdb.CourseDataCouchdb{},
config.SQLDB: &sqldb.CourseDataSql{},
}
// courseDataServiceFactory is an empty receiver for Build method
type courseDataServiceFactory struct{}
// GetCourseDataServiceInterface is an accessor for factoryBuilderMap
func GetCourseDataServiceInterface(key string) dataservice.CourseDataInterface {
return courseDataServiceMap[key]
}
func (tdsf *courseDataServiceFactory) Build(c container.Container, dataConfig *config.DataConfig) (DataServiceInterface, error) {
dsc := dataConfig.DataStoreConfig
dsi, err := datastorefactory.GetDataStoreFb(dsc.Code).Build(c, &dsc)
if err != nil {
return nil, errors.Wrap(err, "")
}
gdbc := dsi.(gdbc.Gdbc)
gdi := GetCourseDataServiceInterface(dsc.Code)
gdi.SetDB(gdbc)
return gdi, nil
}
它的缺点是,对于任何支持的数据库,需要实现以下代码中“SqlGdbc”和“NoSqlGdbc”接口,即使它只使用其中一个,另一个只是空实现(以满足接口要求)并没有被使用。 如果你只有少数几个数据库需要支持,这可能是一个可行的解决方案,否则它将变得越来越难以管理。
// SqlGdbc (SQL Go database connection) is a wrapper for SQL database handler
type SqlGdbc interface {
Exec(query string, args ...interface{}) (sql.Result, error)
Prepare(query string) (*sql.Stmt, error)
Query(query string, args ...interface{}) (*sql.Rows, error)
QueryRow(query string, args ...interface{}) *sql.Row
// If need transaction support, add this interface
Transactioner
}
// NoSqlGdbc (NoSQL Go database connection) is a wrapper for NoSql database handler.
type NoSqlGdbc interface {
// The method name of underline database was Query(), but since it conflicts with the name with Query() in SqlGdbc,
// so have to change to a different name
QueryNoSql(ctx context.Context, ddoc string, view string) (*kivik.Rows, error)
Put(ctx context.Context, docID string, doc interface{}, options ...kivik.Options) (rev string, err error)
Get(ctx context.Context, docID string, options ...kivik.Options) (*kivik.Row, error)
Find(ctx context.Context, query interface{}) (*kivik.Rows, error)
AllDocs(ctx context.Context, options ...kivik.Options) (*kivik.Rows, error)
}
// gdbc is an unified way to handle database connections.
type Gdbc interface {
SqlGdbc
NoSqlGdbc
}
除了上面谈到的那个之外,还有另一个副作用。 在下面的代码中,“CourseDataInterface”中的“SetDB”函数打破了依赖关系。 因为“CourseDataInterface”是数据服务层接口,所以它不应该依赖于“gdbc”接口,这是下面一层的接口。 这是本程序的依赖关系中的第二个缺陷,第一个是在事物管理⁶模块。 目前对它没有好的解决方法,如果你不喜欢它,就不要使用它。 可以创建类似于“userFataServiceFactory”的二级工厂,只是程序较长而已。
import (
"github.com/jfeng45/servicetmpl/model"
"github.com/jfeng45/servicetmpl/tool/gdbc"
)
// CourseDataInterface represents interface for persistence service for course data
// It is created for POC of courseDataServiceFactory, no real use.
type CourseDataInterface interface {
FindAll() ([]model.Course, error)
SetDB(gdbc gdbc.Gdbc)
}
怎样选择?
怎样选择是用简化工厂还是二级工厂?这取决于变化的方向。如果你需要支持大量新数据库,但新的数据服务不多(由新的域模型类型决定),那么选二级工厂,因为大多数更改都会发生在数据存储工厂中。但是如果支持的数据库不会发生太大变化,并且数据服务的数量可能会增加很多,那么选择简化工厂。如果两者都可能增加很多呢?那么只能使用二级工厂,只是程序会比较长。
怎样选择使用基本工厂还是二级工厂?实际上,即使你需要支持多个数据库,但不需同时支持多个数据库,你仍然可以使用基本工厂。例如,你需要从MySQL切换到MongoDB,即使有两个不同的数据库,但在切换后,你只使用MongoDB,那么你仍然可以使用基本工厂。对于基本工厂,当有多种类型时,你需要更改代码以进行切换(但对于二级工厂,你只需更改配置文件),因此如果你不经常更改代码,这是可以忍受的。
备注:上面是我在写这段代码时的想法。但如果现在让我选择,我可能不会使用简化工厂。因为我对程序复杂度有了不同的认识。我依据的原则并没有变,都是要降低代码复杂度。但我以前认为代码越长越复杂,但现在我会加上另外一个维度,就是代码的结构复杂度。二级工厂虽然代码长了很多,但结构简单,只要完成了一个,就可以拷贝出许多,结构几乎一模一样,这样不论读写都非常容易。它的复杂度是线性增加的,而且不会有其他副作用。另外,你可以使用代码生成器等工具来自动生成,以提高效率。而“简化工厂”虽然代码量少了,但结构复杂,它的复杂度增加很快,而且副作用太大,很难管理。
依赖注入(Dependency Injection)库
Go中已经有几个依赖注入库,为什么我不使用它们?我有意在项目初期时不使用任何库,所以我可以更好地控制程序结构,只有在完成整个程序结构布局之后,我才会考虑用外部库替换本程序的某些组件。
我简要地看了几个流行的依赖注入库,一个是来自优步⁷的Dig⁸,另一个是来自谷歌¹⁰的Wire⁹ 。 Dig使用反射,Wire使用代码生成。这两种方法我都不喜欢,但由于Go目前不支持泛型,因此这些是唯一可用的选项。虽然我不喜欢他们的方法,但我不得不承认这两个库的依赖注入功能更全。
我试了一下Dig,发现它没有使代码更简单,所以我决定继续使用当前的解决方案。在Dig中,你为每个具体类型创建“(build)”函数,然后将其注册到容器,最后容器将它们自动连接在一起以创建顶级类型。本程序的复杂性是因为我们需要支持两个数据库实现,因此每个域模型有两个不同的数据库链接和两组不同的数据服务实现。在Dig中没有办法使这部分更简单,你仍然需要创建所有工厂然后把它们注册到容器。当然,你可以使用“if-else”方法来实现工厂,这将使代码更简单,但你以后需要付出更多努力来维护代码。
我的方法简单易用,并且还支持从文件加载配置,但是你需要了解它的原理以扩展它。 Dig提供的附加功能是自动加载依赖关系。如果你的应用程序有很多类型并且类型之间有很多复杂的依赖关系,那么你可能需要切换到Dig或Wire,否则请继续使用当前的解决方案
接口设计
下面是 “userDataServiceFactoryWrapper”的代码.
// DataServiceInterface serves as a marker to indicate the return type for Build method
type DataServiceInterface interface{}
// userDataServiceFactory is a empty receiver for Build method
type userDataServiceFactoryWrapper struct{}
func (udsfw *userDataServiceFactoryWrapper) Build(c container.Container, dataConfig *config.DataConfig)
(DataServiceInterface, error) {
key := dataConfig.DataStoreConfig.Code
udsi, err := userdataservicefactory.GetUserDataServiceFb(key).Build(c, dataConfig)
if err != nil {
return nil, errors.Wrap(err, "")
}
return udsi, nil
}
你可能注意到了“Build()”函数的返回类型是“DataServiceInterface”,这是一个空接口,为什么我们需要一个空接口? 我们可以用“interface {}”替换“DataServiceInterface”吗?
// userDataServiceFactory is a empty receiver for Build method
type userDataServiceFactoryWrapper struct{}
func (udsfw *userDataServiceFactoryWrapper) Build(c container.Container, dataConfig *config.DataConfig)
(interface{}, error) {
...
}
如果将返回类型从“DataServiceInterface”替换为“interface {}”,结果是相同的。 “DataServiceInterface”的好处是它可以告诉我函数的返回类型,即数据服务接口; 实际上,真正的返回类型是“dataservice.UserDataInterface”,但是“DataStoreInterface”现在已经足够好了,一个小诀窍让生活变得轻松一点。
结论:
程序容器使用依赖注入创建具体类型并将它们注入每个函数。 它的核心是工厂方法模式。 在Go中有三种方法可以实现它,最好的方法是在映射(map)中保存不同的工厂。 将工厂方法模式应用于数据服务层也有不同的方法,它们各自都有利有弊。 你需要根据应用程序的更改方向选择正确的方法。
源程序:
完整的源程序链接 github: https://github.com/jfeng45/servicetmpl
索引:
[1]Go Microservice with Clean Architecture: Application Container
[2] Inversion of Control Containers and the Dependency Injection pattern
[4]Creating a factory method in Java that doesn’t rely on if-else
[6]Go Microservice with Clean Architecture: Transaction Support
[8]Uber’s dig

 浙公网安备 33010602011771号
浙公网安备 33010602011771号