MySQL训练营-DDL性能问题
DDL算法类型
copy/inplace/instant 复制、原地、即时
copy复制算法
原理
Copy 算法在执行 DDL 操作时,会创建一个新的临时表,该临时表具有修改后的表结构。然后将原表中的数据逐行复制到新的临时表中。复制完成后,删除原表,并将临时表重命名为原表的名称。
优点
兼容性好:几乎可以处理所有类型的 DDL 变更,不受存储引擎内部机制的限制。因为它是通过创建新表来实现结构变更,所以对各种复杂的变更场景都能很好地支持。
数据一致性高:在复制数据的过程中,可以保证数据的完整性和一致性。即使在复制过程中出现错误,也可以很方便地回滚操作,不会影响原表的数据。
缺点
性能开销大:需要额外的磁盘空间来存储临时表,并且数据复制过程会消耗大量的 I/O 和 CPU 资源。如果表的数据量非常大,复制操作可能会花费很长时间,导致数据库在操作期间性能严重下降。
锁表时间长:在复制过程中,通常需要对原表加锁,以防止数据的不一致。这会导致其他用户无法对原表进行读写操作,影响数据库的可用性。
适用场景
当需要进行复杂的表结构变更,而存储引擎不支持其他更高效的方式时,可以使用 Copy 算法。例如,在某些情况下需要修改表的字符集、添加或删除大字段等。
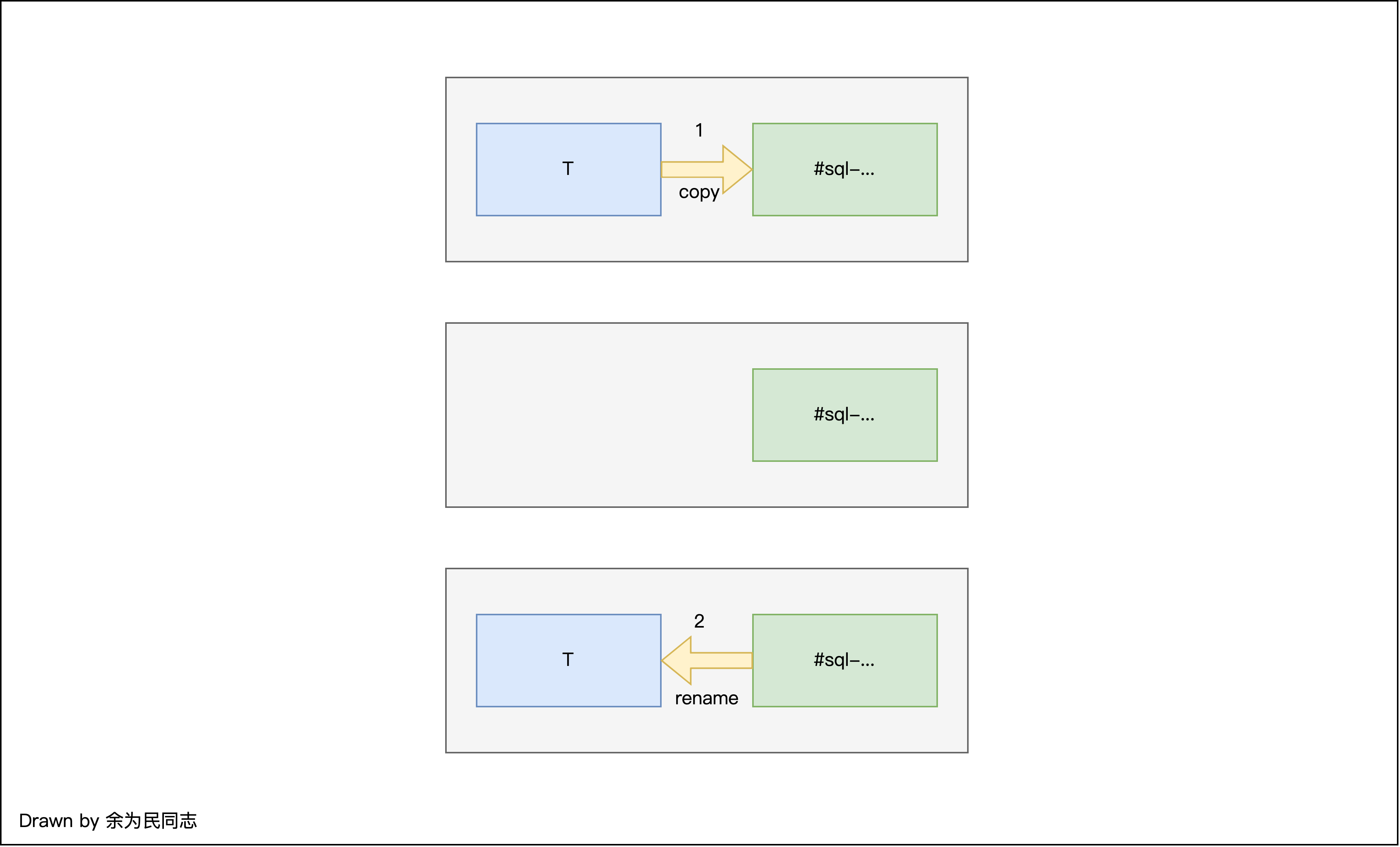
如要进行一个新增列操作,那么进行的流程为:
-
复制一个相同表结构的新表
#sql-...,对新表进行DDL操作,将原表中的数据复制过去 -
删除原表
-
将
#sql-...名字修改回T
use mysql;
drop table if exists users;
create table users(id int, age int);
insert into users(id,age) values(1,1),(2,2),(3,3);
修改DDL语句:ALTER TABLE users MODIFY COLUMN id INT PRIMARY KEY AUTO_INCREMENT;
课堂练习
space id会不会变?
在 InnoDB 存储引擎里,数据和索引存储在表空间中,每个表空间都有一个与之对应的 SPACE ID。表空间可以是共享的(多个表共享一个表空间),也可以是独立的(每个表有自己单独的表空间),SPACE ID 能帮助 MySQL 准确地定位和管理这些表空间。
会变
修改前SPACE为22:
mysql> SELECT * FROM INFORMATION_SCHEMA.innodb_tables WHERE NAME = 'mysql/users';
+----------+-------------+------+--------+-------+------------+---------------+------------+--------------+--------------------+
| TABLE_ID | NAME | FLAG | N_COLS | SPACE | ROW_FORMAT | ZIP_PAGE_SIZE | SPACE_TYPE | INSTANT_COLS | TOTAL_ROW_VERSIONS |
+----------+-------------+------+--------+-------+------------+---------------+------------+--------------+--------------------+
| 1095 | mysql/users | 33 | 5 | 22 | Dynamic | 0 | Single | 0 | 0 |
+----------+-------------+------+--------+-------+------------+---------------+------------+--------------+--------------------+
1 row in set (0.00 sec)
修改后SPACE为23:
mysql> SELECT * FROM INFORMATION_SCHEMA.innodb_tables WHERE NAME = 'mysql/users';
+----------+-------------+------+--------+-------+------------+---------------+------------+--------------+--------------------+
| TABLE_ID | NAME | FLAG | N_COLS | SPACE | ROW_FORMAT | ZIP_PAGE_SIZE | SPACE_TYPE | INSTANT_COLS | TOTAL_ROW_VERSIONS |
+----------+-------------+------+--------+-------+------------+---------------+------------+--------------+--------------------+
| 1089 | mysql/users | 33 | 6 | 23 | Dynamic | 0 | Single | 0 | 0 |
+----------+-------------+------+--------+-------+------------+---------------+------------+--------------+--------------------+
1 row in set (0.00 sec)
rows_examined是多少?
可以看到执行sql后的提示显示,影响了3行。
mysql> ALTER TABLE users MODIFY COLUMN id INT PRIMARY KEY AUTO_INCREMENT;
Query OK, 3 rows affected (0.07 sec)
Records: 3 Duplicates: 0 Warnings: 0
- 中间删除表后,
select语句是否会报表不存在的错?
不会,会给DML元数据加写锁。select语句需要获取到读锁才能执行,所以select不会报错。
inplace原地算法
静态添加索引c,加索引过程中不进行业务的DML。

课堂练习
space id会不会变?
不会
rows_examined是多少?
N,需要读取数据
全程
a.ibd需要加锁,只能读不能写
动态添加索引c,加索引过程中同步进行业务的DML。
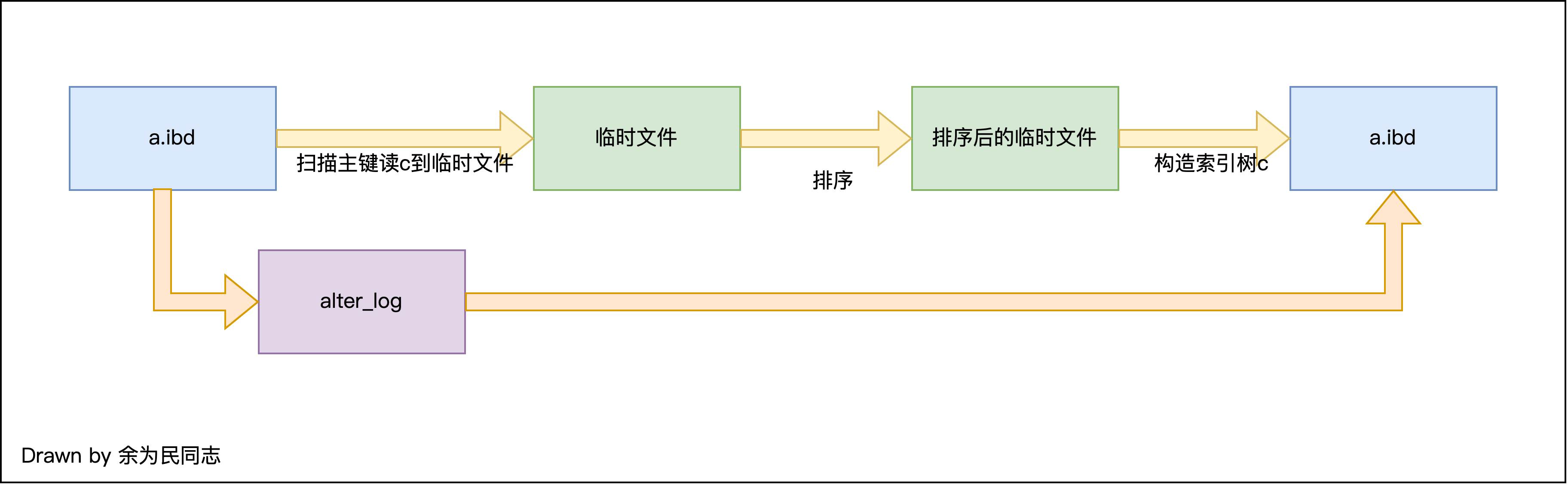
在
alter_log应用到构建后的a.ibd需要加锁,只能读不能写。其他时间不加
与之相关存在系统参数:innodb_online_alter_log_max_size。若达到最大值,会发生回滚。
新索引紧凑吗?
不紧凑,因为应用
alter_log顺序是不固定的。为了避免该场景,mysql会为每个page页面预留空间。
继续使用刚刚的例子举例
use mysql;
drop table if exists users;
create table users(id int, age int);
insert into users(id,age) values(1,1),(2,2),(3,3);
修改DDL语句:ALTER TABLE users ADD INDEX(id);,执行前后space id不会变:
mysql> SELECT * FROM INFORMATION_SCHEMA.innodb_tables WHERE NAME = 'mysql/users';
+----------+-------------+------+--------+-------+------------+---------------+------------+--------------+--------------------+
| TABLE_ID | NAME | FLAG | N_COLS | SPACE | ROW_FORMAT | ZIP_PAGE_SIZE | SPACE_TYPE | INSTANT_COLS | TOTAL_ROW_VERSIONS |
+----------+-------------+------+--------+-------+------------+---------------+------------+--------------+--------------------+
| 1118 | mysql/users | 33 | 5 | 52 | Dynamic | 0 | Single | 0 | 0 |
+----------+-------------+------+--------+-------+------------+---------------+------------+--------------+--------------------+
1 row in set (0.00 sec)
instant即时算法
相关资料:https://www.cnblogs.com/huaweiyun/p/18464467
直接修改元数据,如添加一列:alter table users add x int;
修改前:
mysql> SELECT * FROM INFORMATION_SCHEMA.innodb_tables WHERE NAME = 'mysql/users';
+----------+-------------+------+--------+-------+------------+---------------+------------+--------------+--------------------+
| TABLE_ID | NAME | FLAG | N_COLS | SPACE | ROW_FORMAT | ZIP_PAGE_SIZE | SPACE_TYPE | INSTANT_COLS | TOTAL_ROW_VERSIONS |
+----------+-------------+------+--------+-------+------------+---------------+------------+--------------+--------------------+
| 1099 | mysql/users | 33 | 5 | 33 | Dynamic | 0 | Single | 0 | 0 |
+----------+-------------+------+--------+-------+------------+---------------+------------+--------------+--------------------+
1 row in set (0.01 sec)
修改后:
mysql> alter table users add x int DEFAULT 0,ALGORITHM=INSTANT;
Query OK, 0 rows affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM INFORMATION_SCHEMA.innodb_tables WHERE NAME = 'mysql/users';
+----------+-------------+------+--------+-------+------------+---------------+------------+--------------+--------------------+
| TABLE_ID | NAME | FLAG | N_COLS | SPACE | ROW_FORMAT | ZIP_PAGE_SIZE | SPACE_TYPE | INSTANT_COLS | TOTAL_ROW_VERSIONS |
+----------+-------------+------+--------+-------+------------+---------------+------------+--------------+--------------------+
| 1100 | mysql/users | 33 | 6 | 34 | Dynamic | 0 | Single | 0 | 0 |
+----------+-------------+------+--------+-------+------------+---------------+------------+--------------+--------------------+
1 row in set (0.00 sec)
怀疑是小表数据量不够,改用大表做测试,参考《MySQL训练营-准备阶段》的内容,导入tpch的数据进行测试。可以对其中的lineitem表进行加列测试:alter table lineitem add x int;
即使这样还是走不了instant算法,即使指定算法也不行,不知道是不是mysql的bug:
mysql> alter table lineitem add x int DEFAULT 0,ALGORITHM=INSTANT;
ERROR 1845 (0A000): ALGORITHM=INSTANT is not supported for this operation. Try ALGORITHM=COPY/INPLACE.
instant DDL语句有没有可能执行时间很长(比如超过1分)?
| session1 | session2 | session3 |
|---|---|---|
| begin; select * from t limit 1; |
||
| alter table t add g int; //现象? | ||
| select * from t limit 1; //现象? |
1、session2执行alter table t add g int;语句会被堵住,因为session1会获取MDL锁
2、select * from t limit 1;也会被堵住,它需要获取表 t 的 MDL 读锁。然而,由于第二个会话正在等待获取 MDL 写锁,MySQL 为了保证操作的顺序和一致性,不会让第三个会话获取 MDL 读锁,因此第三个会话也会被阻塞,直到第二个会话获取到 MDL 写锁并完成操作,或者第一个会话释放 MDL 读锁。
instant DDL中使用MDL流程
MDL(Metadata Locking,元数据锁)是 MySQL 从 5.5 版本开始引入的一种锁机制,用于保护数据库对象的元数据(如表结构)免受并发操作的影响。MDL 主要确保在执行诸如 ALTER TABLE、DROP TABLE 等 DDL(数据定义语言)操作时,不会有其他会话同时对同一表进行可能导致冲突的 DML(数据操作语言)操作,如 INSERT、UPDATE、DELETE 等。这种机制有助于维护数据库的一致性和完整性,防止因并发操作导致的数据损坏或不一致。
- 获取MDL写锁
- MDL降级为S锁
- 执行DDL过程
- MDL升级为X锁
- 释放MDL的X锁
课堂练习
- copy 算法过程中,最高时需要占用 2 倍的原表空间。
对。中间需要复制一个临时表
- 同一个表,加索引和删除索引最好分成两个语句。
建议分开,不确定会先执行完删除还是先执行完添加,可能出现没有索引用的情况。对与修改索引的场景,也是建议先添加新的索引,再删除历史索引。
- 同一个表, 加两个索引最好分成两个语句。
错,解释同下
- add index(a), add index(b) 比分成两个语句执行来得快。
对,扫描主键只扫描一次。
- add unique index,使用 copy 算法比使用 inplace 算法的快。
错,COPY算法需要重建整个表。创建具有新索引结构的空表副本,逐行读取原表数据并插入新表(此时会构建所有索引),原子性地切换新旧表。
- add unique index,使用 copy 算法比使用 inplace 算法的更容易成功。
对,INPLACE算法不加写锁,可能在执行阶段插入了重复数据。COPY算法中,不允许插入新的数据。
optimize table
作用
- 空间回收与整理
在数据库中,当对表进行大量的插入、更新和删除操作后,数据文件可能会产生碎片。这些碎片会导致数据文件占用更多的磁盘空间,并且可能会影响查询性能。“OPTIMIZE TABLE”命令可以重新组织表数据和索引的物理存储,回收未使用的空间,从而减少磁盘空间的占用。
- 性能优化
它有助于提高查询性能。通过整理数据文件的存储结构,使得数据的读取更加连续,减少了磁盘I/O操作。对于频繁查询的表,执行“OPTIMIZE TABLE”后,查询速度可能会得到明显提升,因为数据库引擎可以更高效地定位和读取数据。
相关问题
- 能不能用instant算法操作
不能,需要重新整理存储结构。不能仅仅通过修改元数据实现。
- 能不能用inplace
不能,因为需要重建主键索引。只能使用copy算法。
- 得到的普通索引紧凑吗?
也是紧凑的。执行逻辑为:先创建表结构只包括主键索引,再导入数据,最后创建普通索引。创建普通索引时,数据都存在所以为紧凑的。
现在有以下场景,先数据构造:
drop table if exists t;
drop procedure if exists idata1;
create table t(id int primary key)engine=innodb;
delimiter ;;
create procedure idata1()
begin
DECLARE i INT DEFAULT 1;
WHILE i <= 100000 DO
insert into t(id) values(i);
set i=i+1;
END WHILE;
end;;
delimiter ;
call idata1();
创建数据表t,并向其中插入10000条数据。
create table a(id int primary key, c int , d int,
index(c), index(d))engine=innodb;
insert into a select id, id, id from t;
//ls -al a.ibd 大小 S1
S1是紧凑的
optimize table a ;
//ls -al a.ibd 大小 S2
问 :S1 S2 的大小关系?
S2更大
S1 = 14680064
S2 = 15728640
多了1M。预分配机制会,多预留一个区。
相关知识:
InnoDB 使用 表空间(Tablespace) 来存储数据和索引。从 MySQL 5.6 开始,引入了 独立表空间(File-Per-Table Tablespace),每个表都有自己的 .ibd 文件,用于存储该表的数据和索引。此外,还有 系统表空间(System Tablespace) 、 通用表空间(General Tablespace) 等。
表空间的组成:
- 段(Segment) :表空间由多个段组成,每个段管理一组 区(Extent)。
- 区(Extent) :一个区由连续的 64 个页(Page)组成,默认页大小为 16KB,因此一个区大约为 1MB。
- 页(Page) :InnoDB 存储数据的最小单位,用于存放实际的数据记录和索引。
预分配是指 InnoDB 在需要更多空间来存储数据时,提前分配一定数量的区(Extent),而不是按需逐个分配。这种机制有助于减少频繁的空间分配操作,提高性能和减少碎片。
生产上如何做DDL
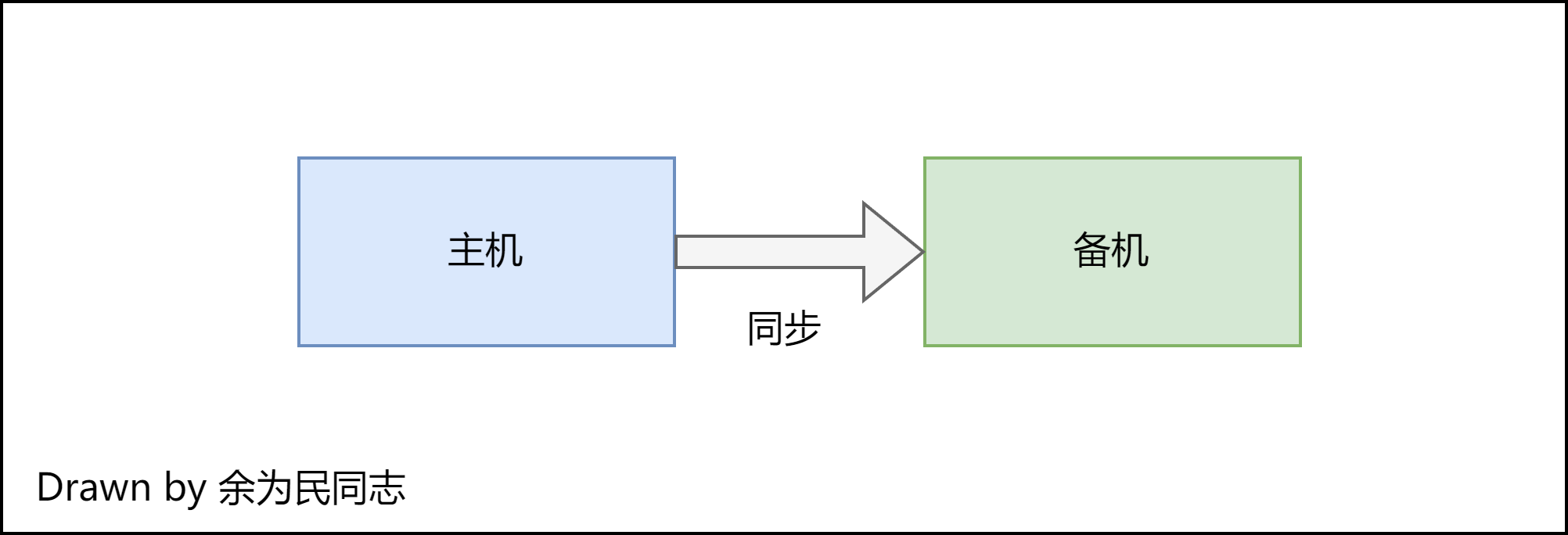
前提:存在主备数据库单向备份。
- 加索引
在备机上先加索引。再做主备切换,通过
binlog同步在新备机上加索引。
- optimize table
同上
- var(20) ->var(100)
业务需要在,新的从库也执行完后再进行业务操作。否则会存在数据丢失的情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号