
常见CNN网络结构
图片分类,判断图片中是否有某个物体,一个图对应一个标签。性能指标:(1) Top1 error 第一次是否猜中,(2) Top5 error 猜5次其中有一次猜中。
很多出色的网络结构是从大赛中流行起来的。ImageNet Large Scale Visual Recognition Challenge ILSVRC 2017 年已经停止举办,因为涉及的方面的算法技术已经很成熟,没有什么提升空间了。涉及图像分类(1000个分类,训练集1.2M、验证集50K、测试集150K,使用WorkNet的词汇对图像打标签)、场景分类(MIT的Places2数据集,图片10M+、分类400+,365个场景分类,训练集8M、验证集36K、测试集328K)、物体检测、物体定位、场景解析等方面。在ILSCRC的 ImageNet Classification Top5 error 错误率2015年已经降到3.57%
网络进化过程中比较好的网络 AlexNet(深度8层)->VGG(19)->GoogleLeNet(22)->ResNet(152)
1. AlexNet(8)
原始论文 http://www.cs.toronto.edu/~fritz/absps/imagenet.pdf
2012年ImageNet 竞赛第一,远比第二名领先,标志着DNN深度学习革命的开始。
特点:5个卷积层+3个全连接层
60M个参数+650K个神经元
2个分组->2个GPU(3GB、2块GTX 580 训练5至6天)
引入的新技术 ReLU、Max polling、Dropout regularization
LRU 相邻通道kernel上同一位置的数值进行归一化(VGGNet的论文认为没什么用)
网络结构如图:
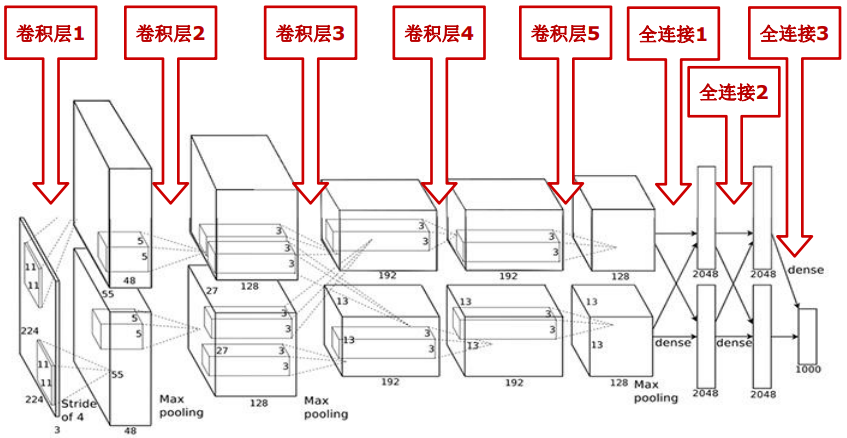
为了后面下采样除起来是个整数,前面做成 227*227
| 输~~~~~~~入 \(227\times 227\times 3\) |
GPU 1 | GPU 2 | 输~~~~~~~~~~~~出 |
|---|---|---|---|
| 卷积层 1 \(227\times 227\times 3\) |
卷积核\(11\times 11\) 数量48 步长 4 | 卷积核\(11\times 11\) 数量48 步长 4 | |
| 激活函数 relu | 激活函数 relu | 特征图: \((227-11)/4+1=55\) 即 \(55\times 55\times 96\) |
|
| 池化Max pooling, kernel size 3, stride 2 | 池化Max pooling, kernel size 3, stride 2 | 特征图:\((55-3)/2+1=27\) 即 \(27\times 27\times 96\) |
|
| 标准化 Local Response Normalization | |||
| 卷积层 2 \(27\times 27\times 96\) 通道独立 |
卷积核\(5\times 5\) 数量128 步长 1 | 卷积核\(5\times 5\) 数量128 步长 1 | 输入特征图先扩展padding2个像素 即\(31\times 31\) |
| 激活函数 relu | 激活函数 relu | 特征图:\((31-5)/1+1=27\) 即 \(27\times 27\times 256\) |
|
| 池化Max pooling, kernel size 3, stride 2 | 池化Max pooling, kernel size 3, stride 2 | 特征图:\((27-3)/2+1=13\) 即 \(13\times 13\times 256\) |
|
| 标准化 Local Response Normalization | |||
| 卷积层 3 \(13\times 13\times 256\) 通道合并 双GPU交互 |
卷积核\(3\times 3\) 数量192 步长 1 | 卷积核\(3\times 3\) 数量192 步长 1 | 输入特征图先扩展padding1个像素 即\(15\times 15\) |
| 激活函数 relu | 激活函数 relu | 特征图:\((15-3)/1+1=13\) 即 \(13\times 13\times 384\) |
|
| 卷积层 4 \(13\times 13\times 384\) 通道独立 |
卷积核\(3\times 3\) 数量192 步长 1 | 卷积核\(3\times 3\) 数量192 步长 1 | 输入特征图先扩展padding1个像素 即\(15\times 15\) |
| 激活函数 relu | 激活函数 relu | 特征图:\((15-3)/1+1=13\) 即 \(13\times 13\times 384\) |
|
| 卷积层 5 \(13\times 13\times 384\) 通道独立 |
卷积核\(3\times 3\) 数量128 步长 1 | 输入特征图先扩展padding1个像素 即\(15\times 15\) |
|
| 激活函数 relu | 激活函数 relu | 特征图:\((15-3)/1+1=13\) 即 \(13\times 13\times 256\) |
|
| 池化Max pooling, kernel size 3, stride 2 | 池化Max pooling, kernel size 3, stride 2 | 特征图:\((13-3)/2+1=6\) 即 \(6\times 6\times 256\) |
|
| 全连接 6 \(6\times 6\times 256\) |
2048个神经元 | 2048个神经元 | |
| dropout | dropout | \(4096\times 1\)的向量 | |
| 全连接 7 \(4096\times 1\) |
2048个神经元 | 2048个神经元 | |
| dropout | dropout | \(4096\times 1\)的向量 | |
| 全连接 8 \(4096\times 1\) |
1000个神经元 | \(1000\times 1\)的向量 |
2. Network in Network
论文 Network in Network
一个 \(28\times 28\times 192\) 的特征图 被 32 个 \(1\times1\times 192\)的卷积核进行卷积。这样最终是 \(28\times 28\times 32\).
假设输入特征图的某像素的\(c\)个通道值 \((x_1, x_2, \cdots, x_c)\)
\(k\) 个 \(1\times 1\times c\) 的卷积核,\((a_{11}, \cdots, a_{1c}), \cdots, (a_{k1}, \cdots, a_{kc})\)
\((x_1, x_2, \cdots, x_c)\otimes \begin{pmatrix}a_{11} & \cdots & a_{1c}\\ \vdots & \ddots &\vdots\\a_{k1}&\cdots & a_{kc}\end{pmatrix}=(y_1, y_2, \cdots, y_k)\)
\(f(a_{11}x_1+a_{12}x_2+\cdots+a_{1c}x_c)=y_1\cdots\cdots\)
实现跨通道的交互和信息整合,能够对通道数进行降维和升维
3. VGG(19)
ImageNet-2014 竞赛第二,网络改造的首选基础网络,典型的层数是19层
提出目的是为了探究在大规模图像识别任务中,卷积网络深度对模型精确度的影响
一个大卷积核分解成连续多个小卷核
例如 \(7\times7\) 分解成 3个 \(3\times 3\) 核 由ReLU连接,参数数量由\(49C^2\) 降至 \(27C^2\)
VGG可以减少参数,降低计算,增加深度
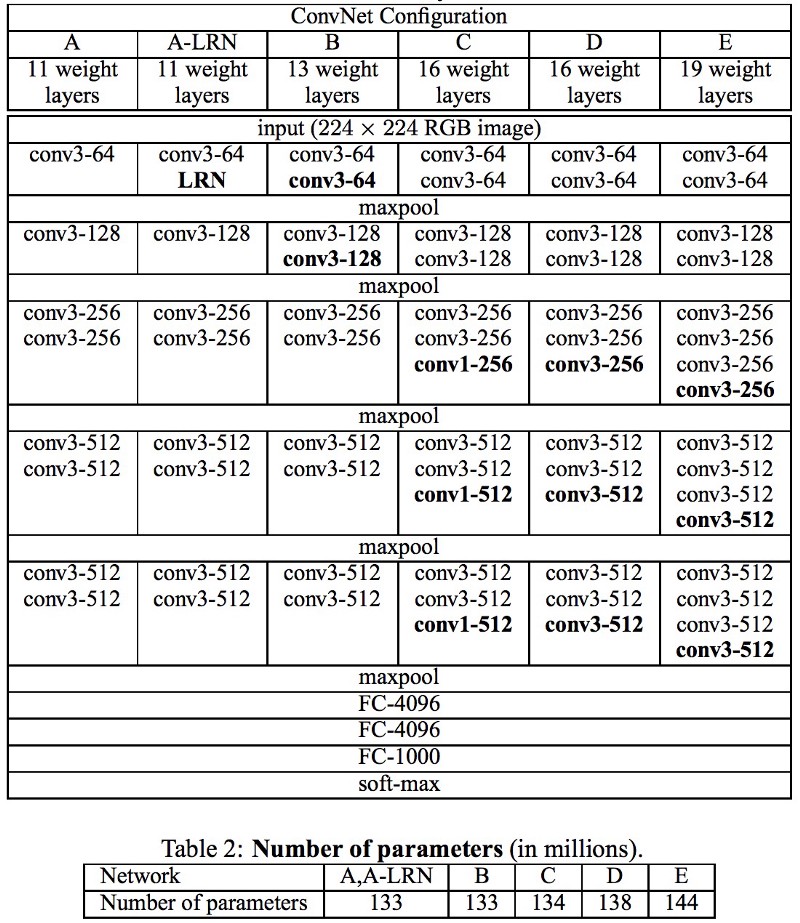
从A至E随着层数的增加,参数增加的并不多
4. GoogleLeNet(22)
在此之前,网络结构的突破是更深的层数更宽的神经元数。
GoogleLeNet网络ImageNet-2014竞赛第一
模型是不是试出来的?是不是要穷举验证各方面的网络结构? GoogleLeNet解决这个问题,把所有的可能性排出来,让模型去决定。
Inception V1网络
核心组件Inception Architecture
Split-Merge 试了 \(1\times 1\)卷积, \(3\times 3\)卷积, \(5\times 5\)卷积, \(3\times 3\)池化
使用了NiN的\(1\times 1\)卷积进行特征降维
为了减负取消了全连接,因为全连接参数量大
由于层数深(一般22层),使用辅助分类器解决前几层的梯度消失问题
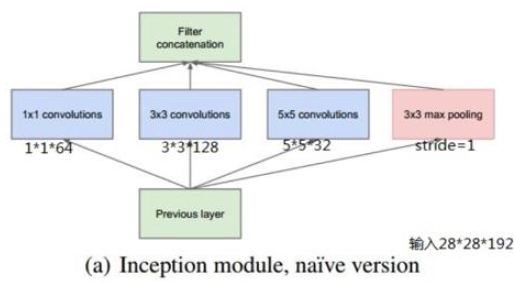
从下往上看,对几种情况分别做卷积后叠在一起(不做和,只是叠在一起,保持层数不变),另外不同的卷积操作使用padding等方法使图像尺度不变,这样才能叠加
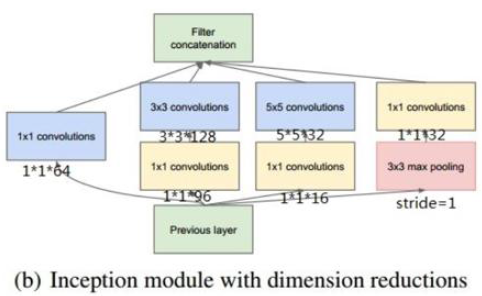
通过加入\(1\times 1\)卷积降低通道数,保持图像尺度不变的情况下,叠在一起
全局平均池化 Global average pooling
取消占用大量参数的全连接层。全局平均池化,对每个特征图求平均值
输入\(7\times7\times1024\)变成\(1\times1\times1024\)
辅助分类器
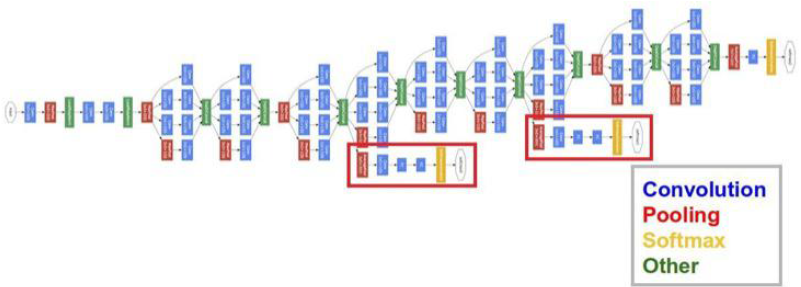
避免梯度消失。训练阶段,在认为梯度有可能消失的地方,让结果重新参与调整误差。
Inception V2网络
提出Batch Normalization2018年有论文认为这一操作使“解空间”更加平滑。
在这个网络中使用批归一化代替部分Dropout。
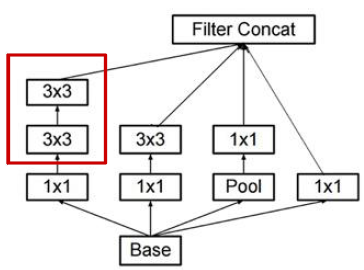
将\(5\times 5\) 变成两个\(3\times3\)卷积核堆叠。
每个特征通道分别进行归一化。通道数不做归一化。
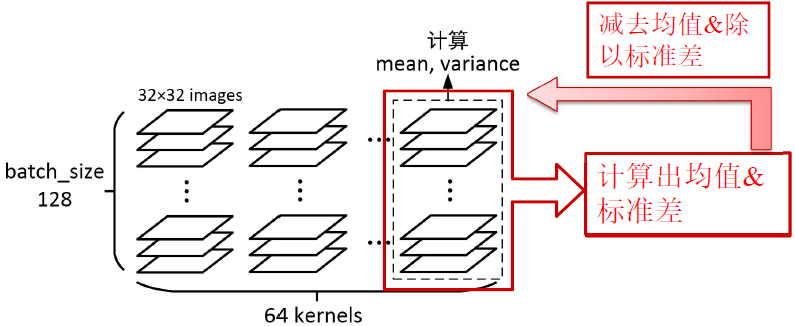
在测试阶段使用的是训练阶段所有Batch的均值、方差的平均值。
原论文把Batch归一化放(包含scale & shift)在卷积与ReLU之间。
Inception V3网络
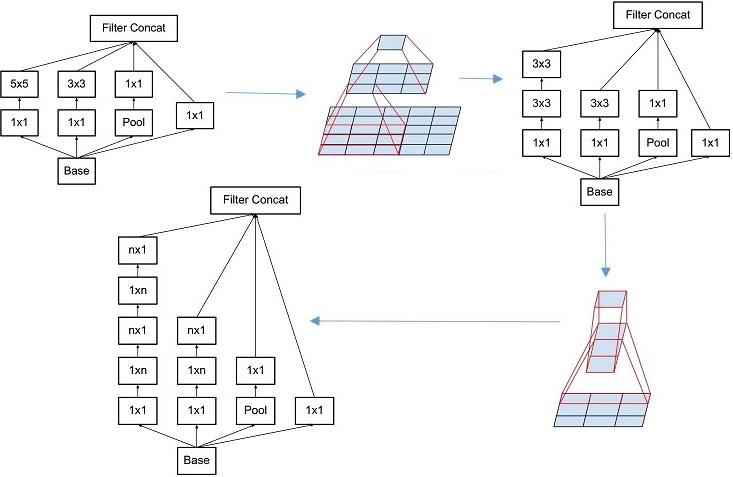
将\(N\times N\)分解成\(1\times N\), \(N\times 1\), 能够降低参数和计算量
经验:在中度大小的feature map上使用效果好,建议m*m 里m取12到20之间。

前面的层先做卷积和pooling(相当于v4里的主干 stem),将特征提取足够多。后面用Inception。Inception 包含了不同的可能性,如果有的情况对分类影响不大,则后面卷积时权重会很小接近于0。这样Inception就实现了选择不同的可能性
认为浅层辅助分类器无用,取消浅层辅助分类器。在训练后期使用深层辅助分类器,比如用在最后一层后。加上BatchNormalization和Dropout
Inception V4网络
论文https://arxiv.org/abs/1602.07261v2
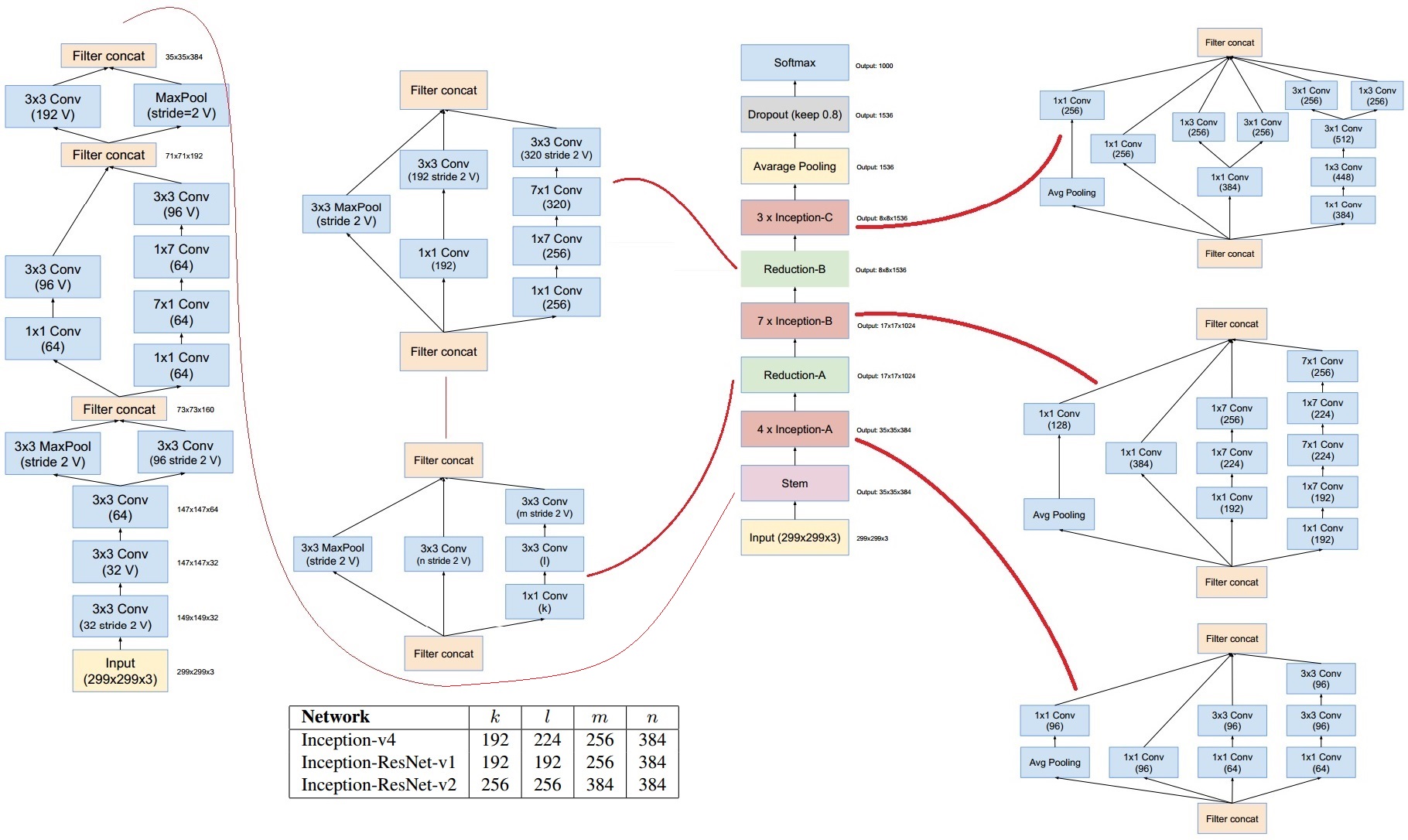
Reduction 能够比较Maxpooling 与卷积两种把尺度变小的方法哪个更好。
整个网络结构包含了很多种组合,包含了很多种情况。训练的结果决定哪些情况起的作用大。
Inception 小结
不像VGG那样人工去试。该类网络结构代替人工确定卷积层中的过滤器类型或者确定卷积层和池化层的组合方式,即预先给网络添加尽可能多的可能性组合,将输出连接起来,让网络自己学习决定。
缺点:由于添加了尽可能多的可能性,所以训练出来的参数和网络结构更贴近该样本,造成不利于扩展。扩展性不如VGG。
5. ResNet(152)
论文https://arxiv.org/abs/1512.03385v1
提出背景:网络的层数不能通过一直堆叠来获得好的学习效果。过多的层数会导致梯度消失、梯度爆炸、网络退化(误差增大、效果不好、过适应等问题)。
ResNet主要思路:
残差映射 \(F(x)=H(x)-x\),\(x\)是卷积之前,\(H(x)\)是卷积之后。\(F(x)=H(x)-x\) 相当于学到的东西与原始的东西的差距,相当于卷积没有获取的特征,或者相当于没有学到的内容。
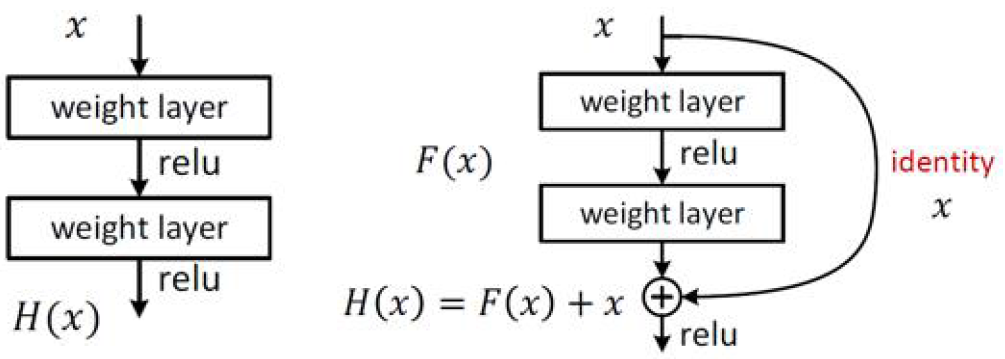
ResNet特点:
(1) 残差映射(主要贡献)
(2) 全是\(3\times 3\)卷积核(应该是为了操作残差映射)
(3) 卷积步长2取代池化, 没有池化(应该是为了操作残差映射)
(4) 使用Batch Normalization
(5) 取消Max池化,取消全连接层(参数多计算量大,取消掉是趋势,有其它方法替换),取消Dropout(应该是为了操作残差映射)
优化点:
通过\(1\times 1\) 卷积降低计算量,在两头加,前面降维,后面升维,使其与之前维数相同以便于操作\(H(x)=F(x)+x\)
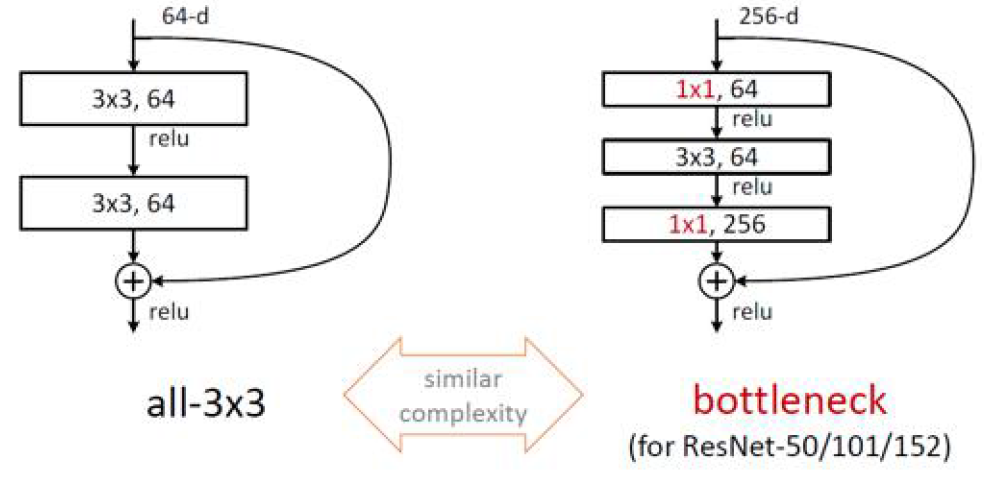
101层比较常见。另外GoogleLeNet中Inception层可以结合resnet的残差映射.
ResNeXt
ILSVRC-2016竞赛第二。提出“深”(如 GoogLeNet、ResNet等)和“宽”(如 GooglLeNet等)之外的第3个角度。
相当于将AlexNet里的group convolution引进ResNet中,将卷积核按通道分组,形成32个并行分支(cardinality(基数)),低维度卷积进行特征变换,然后加法合并
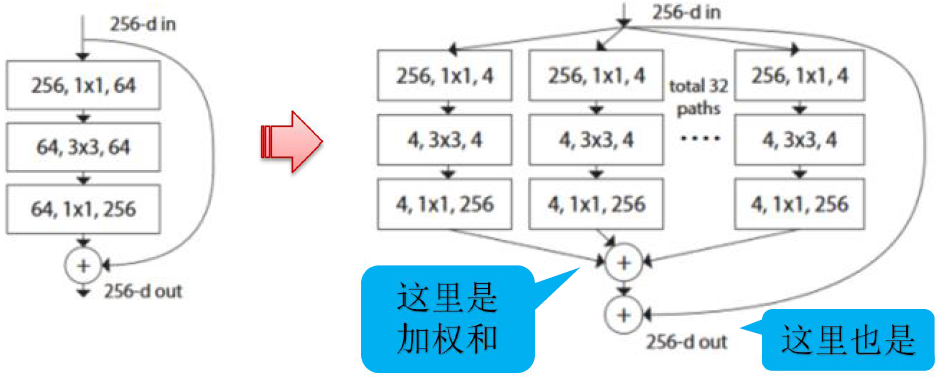
参数规模:
左边ResNet: \(256\times64+3\times3\times64\times64+64\times256=70\mathrm{k}\)
右边ResNeXt: \(32\times(256\times 4+3\times3\times 4\times 4+4\times 256)=70\mathrm{k}\)
同参数规模下,增加结构,提高模型表达力
效果:100层ResNeXt相当于200层ResNet
6. 典型的CNN对比
| 模型 | AlexNet | VGG | GoogLeNet v1 | ResNet |
|---|---|---|---|---|
| 时间 | 2012 | 2014 | 2014 | 2015 |
| 层数 | 8 | 19 | 22 | 152 |
| Top-5错误 | 16.4% | 7.3% | 6.7% | 3.57% |
| Data Augmentation | + | + | + | + |
| Inception(NIN) | - | - | + | - |
| 卷积层数 | 5 | 16 | 21 | 151 |
| 卷积核大小 | 11,5,3 | 3 | 7,1,3,5 | 7,1,3,5 |
| 全连接层数 | 3 | 3 | 1 | 1 |
| 全连接层大小 | 4096,4096,1000 | 4096,4096,1000 | 1000 | 1000 |
| Dropout | + | + | + | + |
| Local Response Normalization | + | - | + | - |
| Batch Normalization | - | - | - | + |
7. 如何设计CNN网络
-
避免信息瓶颈
- 卷积过程中
- 多个小尺寸卷积核 vs 一个大尺寸卷积核
- 尺度\(H\times W\)逐渐变小
- 输出通道数\(Cw\)逐渐变多
- \(H\times W\times C\)要缓慢变小
-
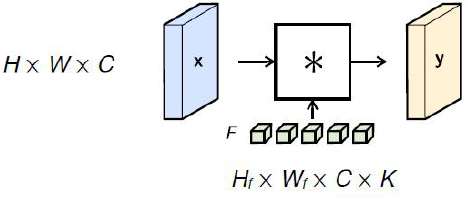
通道(卷积核)数量保持在可控范围内, 计算量 \(complexity\propto C\times K\) (可以通过如前面的 \(1\times 1\), \(3\times 3\), \(1\times N\)等方法叠在一起)
- 输入通道数量 \(C\)
- 输出通道数量 \(K\)
- 参数数量 \(H_f\times W_f\times C\times K\)
- 操作数量 \(\frac{H\times H_f}{stride}\times\frac{W\times W_f}{stride}\times C\times K\)
-
感受野要足够大(为了计算量,卷积核又不能太大,可以通过如前面\(5\times 5\) 使用 2个\(3\times 3\)叠在一起使用,后面的\(3\times 3\)能够达到\(5\times 5\)的感受野)
- 卷积是基于局部图片的操作
- 要捕捉大尺寸的内容
- 多个小尺寸卷积核 vs 一个大尺寸卷积核
- 参数少,计算快
- 多个非线性激活(增强网络的表现能力)

-
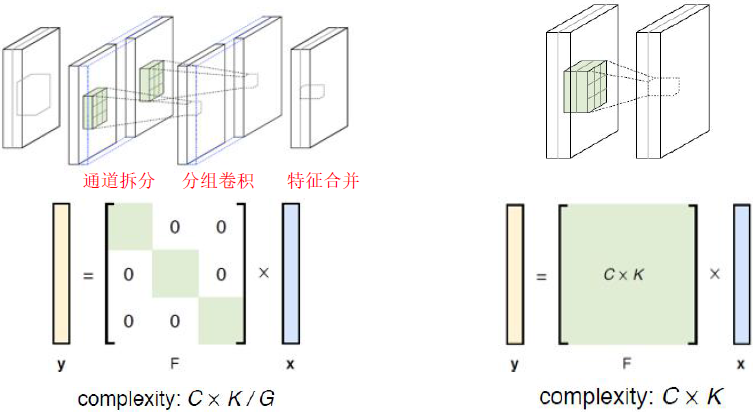
分组策略,降低计算量
- 分G组, M/G 个滤波器 vs M 个滤波器
[1] https://zhuanlan.zhihu.com/p/251068800
[2] https://paperswithcode.com/methods/category/convolutional-neural-networks

 浙公网安备 33010602011771号
浙公网安备 33010602011771号