
神经网络与误差反向传播
1 神经网络
大量结构简单的、功能接近的神经元节点按一定体系架构连接成的模拟大脑结构的网状结构。用于分类、模式识别、连续值预测。建立输入与输出的映射关系.
1.1 神经元
生物神经元之间相互连接,传递信息。树突进行输入,细胞体处理,轴突进行输出到下一神经元。
人工神经元包含:输入\(x\)(考虑权重\(w\)),混合输入(线性混合 \(w_i x_i\)),之后判断是否达到阈值\(b\) 然后进行非线性映射\(f\)(激活函数, 仿生,达到阈值放电,低于阈值为0),输出一个值\(y\)到下一层。
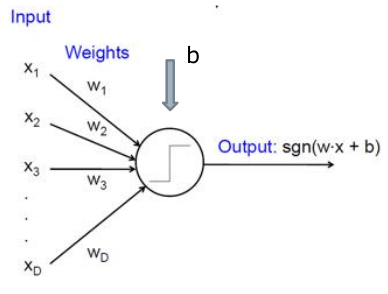
为了推导方便,把\(b\)当作权重的一部分,\(f\) 为激活函数,有式子:

常见传统神经网络激活函数
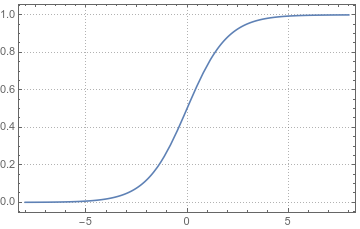
sigmod: \(f(z)=\frac{1}{1+e^{-z}}\),把\((-\infty, \infty)\)映射到\((0,1)\). 基本上函数的输入小于-5就非常接近0,大于5非常接近1
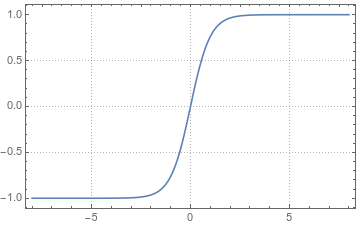
双曲正切函数: \(f(z)=tanh(z)=\frac{e^z-e^{-z}}{e^z+e^{-z}}\), 把\((-\infty, \infty)\)映射到\((-1,1)\)
数学基础: 链式求导\((f(g(x)))^\prime = f^\prime (g(x)) g^\prime(x)\); 或者\({\mathrm{d}y\over \mathrm{d}x}={\mathrm{d}y\over \mathrm{d}z}\bullet{\mathrm{d}z\over \mathrm{d}x}\)
对激活函数引入变量 \(y\)
\(f(z)=\frac{1}{1+e^{-z}}\) 令 \(f(z)=y\), 求导 \(f^\prime(z)= y(1-y)\)
\(f(z)=tanh(z)=\frac{e^z-e^{-z}}{e^z+e^{-z}}\), 令\(f(z)=y\), 求导 \(f^\prime (z) = 1-y^2\)
其它关键问题
层数:传统浅层网络一般3到5层。层起到了提取特征的效果。一般有输入层、隐含层和输出层。
优化方法:梯度下降;BP后向传播(链式规则)
1.2 前馈网络
单向多层。同一层的神经元之间没有相互连接,层间信息只沿一个方向进行。第一层为输入层,最后一层为输出层。
Delta学习规则 \(\Delta w_{ij} = a\cdot(d_i-y_i)x_j(t)\)
\(\Delta w_{ij}\) 是神经元 \(j\rightarrow i\)的连接权重增量; \(x_j\) 是输入,是神经元 \(j\) 的状态;\(d_i\) 是 \(i\) 的期望输出;\(y_i\) 是 \(i\) 的实际输出;\(a\) 是学习的步长,是学习速度的常数
神经网络调权重有点像多项式拟合?最终把系数拟合出来。多项式拟合?,是多组输入,多组输出,调整系数(输出与实际值接近)。神经网络是一组输入、多组输出,调整权重(要求实际输出与期望输出接近)。
目标函数 目标函数以\(\mathrm{w}\)为自变量,初始输入 \(\mathbf{x}\), 实际输出 \(\mathbf{z}=(z_1,\dots,z_c)\) 与 期望输出 \(\mathbf{t}=(t_1,\dots,t_c)\) 越接近越好,即:
目标要这个函数值尽量小,能够接近0更好。系数 \({1\over 2}\) 是为计算方便,为了求导时消掉幂2。函数为各输出误差的平方的累加和。
1.3 梯度下降
上面的式子求最小值不方便求导,也可以对二维的情形可视化看到比较复杂。可以用梯度下降方法求最小值,沿梯度方向往下,到目标函数变化很少,即达到局部最小值。思路:先确定一个初始点,将\(\mathbf{w}\)的值,按照梯度下降(负方向)的方向调整\(\Delta\mathrm{w}=-\eta\frac{\partial J}{\partial\mathrm{w}}\),就会使唤\(J(\mathbf{w})\) 往更低的方向变化,直到目标\(J(\mathbf{w})\) 变化较少。
\(m+1\) 步的权重为:\(\mathrm{w}(m+1)=\mathrm{w}(m)+\Delta\mathrm{w}(m)=\mathrm{w}(m)-\eta\frac{\partial J}{\partial \mathrm{w}}\)
步骤: (1)计算梯度方向,(2)沿梯度方向下降 (3) 步长,学习速率
(4) 持续迭代。要求目标函数处处可导。
输出层的权重改变量\(\frac{\partial J}{\partial w_{kj}}\)
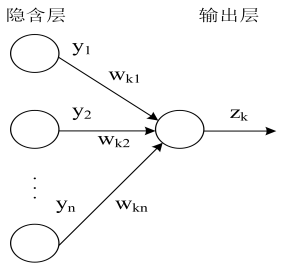
如图第\(k\)次迭代后,最后一个隐藏层\(H\)的结果,即对输出层的输入为\(\mathrm{y}\),对输出层的权重为\(\mathrm{w_k}\),\(k\in[1,c]\),输出层的对应这个输入的结果为\(z_k\)
输出层与之相对应的输出单元的总的输入(省略阈值\(b\),把\(b\) 看作权重的一部分,线性组合,该层输入的加权和):\(net_k=\sum\limits_{j=1}^{n_H}w_{kj}y_j\), \(\color{darkgray}{\frac{\partial net_k}{\partial w_{kj}}}=y_j\)
输出\(z_k\) 有:\(z_k\propto f(net_k)=f\left(\sum\limits_{j=1}^{n_H}w_{kj}y_j\right)\), \(f\) 为激活函数
寻找 \(J\) 与 \(w_{kj}\) 的函数关系:
\(\frac{\partial J}{\partial w_{kj}}=\color{green}{\frac{\partial J}{\partial net_k}}\color{darkgray}{\frac{\partial net_k}{\partial w_{kj}}}\)
\(\color{green}{\frac{\partial J}{\partial net_k}}=\color{red}{\frac{\partial J}{\partial z_k}}\color{darkorange}{\frac{\partial z_k}{\partial net_k}}=\color{red}{-(t_k-z_k)}\color{darkorange}{f^\prime (net_k)}\)
令: \(\delta_k = (t_k-z_k)f^\prime(net_k)\)(残差)
\(\frac{\partial J}{\partial w_{kj}}=\color{red}{-(t_k-z_k)\color{darkorange}{f^\prime(net_k)\color{darkgray}{y_j}}}=-\delta_k y_j\)
所以:\(J\longrightarrow z_k \longrightarrow net_k\longrightarrow w_{kj}\)
\(J(\mathbf{w})={1 \over 2}\parallel \mathbf{t-z}\parallel^2 = {1\over 2}\sum\limits_{k=1}^c(t_k-z_k)^2\)
\(\frac{\partial J}{\partial w_{kj}}=\color{red}{\frac{\partial J}{\partial z_k}}\color{darkorange}{\frac{\partial z_k}{\partial net_k}}\color{darkgray}{\frac{\partial net_k}{\partial w_{kj}}}=\color{red}{-(t_k-z_k)}\color{darkorange}{f^\prime (net_k)}\color{darkgray}{y_j}\)
隐藏层的权重改变量\(\frac{\partial J}{\partial w_{ji}}\)
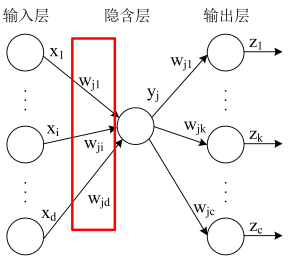
对于隐藏层的某一神经元 \(y_j\) 往输出层有输出\(\mathrm{z}\),也接收来自在输入层的输入\(\mathrm{x}\). 其中来自\(x_i\)的输入权重为\(w_{ji}\), 输出到 \(z_k\) 的权重为 \(w_{jk}\), \(i\in[1,d]\).
隐藏层的某一神经元\(y_j\) 来自输入层的总的输入:
\(net_j=\sum\limits_{i=1}^{d}w_{ji}x_i\), \(\color{darkyellow}{\frac{\partial net_j}{\partial w_{ji}}}=x_i\)
寻找 \(J\) 与 \(w_{ji}\) 的关系:
首先\(J\) 与 隐藏层神经元的输出\(\color{darkorange}{y_j}\) 有关系,再看隐藏层的输出\(\color{darkorange}{y_j}\)与隐藏层的接收\(\color{darkgray}{\frac{\partial net_j}{\partial w_{ji}}}\)有关系
所以有:
\(\frac{J}{\partial w_{ji}}=\color{darkorange}{\frac{\partial J}{y_j}}\color{darkgreen}{\frac{\partial y_j}{\partial net_j}}\color{darkgray}{\frac{\partial net_j}{\partial w_{ji}}}\)
\(\color{darkgreen}{\frac{\partial y_j}{\partial net_j}}=g^\prime(net_j)\), \(g\) 为 \(y_j\) 神经元的激活函数,可以与 输出层的 \(f\) 相同,也可以不同
考察 \(\color{darkorange}{\frac{\partial J}{y_j}}\):
由 \(J(\mathbf{w})={1 \over 2}\parallel \mathbf{t-z}\parallel^2 = {1\over 2}\sum\limits_{k=1}^c(t_k-z_k)^2\):
\(\color{darkorange}{\frac{\partial J}{y_j}}=\frac{\partial \left[ {1\over 2}\sum\limits_{k=1}^c(t_k-z_k)^2\right] }{\partial y_j} = -\sum\limits_{k=1}^c(t_k-z_k) \frac{\partial z_k}{\partial y_j}\), \(\sum\) 表示 \(y_j\) 输出到的所有 \(\mathrm{z}\);
上式中 \(\frac{\partial z_k}{\partial y_j}=\frac{\partial z_k}{\partial net_k}\frac{\partial net_k}{\partial y_j}=f^\prime (net_k) w_{kj}\),其中 \(f\) 为输出层相应神经元的 激活函数,输出层的总输出 \(net_k=\sum\limits_{j=1}^{n_H}w_{kj}y_j\), \(\frac{\partial net_k}{\partial y_j}=w_{kj}\)
\(\color{darkorange}{\frac{\partial J}{\partial y_j}= -\sum\limits_{k=1}^c(t_k-z_k) f^\prime (net_k) w_{kj} = -\sum\limits_{k=1}^c \delta_k w_{kj}}\)
\(\frac{J}{\partial w_{ji}}=\color{darkorange}{\frac{\partial J}{\partial y_j}}\color{darkgreen}{\frac{\partial y_j}{\partial net_j}}\color{darkgray}{\frac{\partial net_j}{\partial w_{ji}}} = \color{darkorange}{-\sum\limits_{k=1}^c \delta_k w_{kj}} \color{darkgreen}{g^\prime(net_j)} \color{darkgray}{x_i}\)
令 \(\delta_j=\color{darkgreen}{g^\prime(net_j)} \color{darkorange}{\sum\limits_{k=1}^c \delta_k w_{kj}}\) (隐藏层的残差)
\(\frac{J}{\partial w_{ji}}=-\delta_j \color{darkgray}{x_i}\)
1.4 误差反向传播
误差传播迭代的形式化表达
输出层
\(\frac{\partial J}{\color{blue}{\partial w_{kj}}}=-\delta_k \color{purple}{y_j}\)
\(\color{blue}{w_{kj}: 隐含层 \longrightarrow 输出层的权重}\)
\(\color{purple}{y_j: 输出层单元的输入,也是隐藏层神经元的输出}\)
\(\delta_k=(t_k-z_k)\color{darkorange}{f^\prime(net_k)}\)
\((t_k-z_k): 人为定义的实际输出层误差\)
\(\color{darkorange}{f^\prime(net_k): 输出层激活函数的导数;net_k 各隐含层输出的加权和}\)
隐含层
\(\frac{J}{\color{blue}{\partial w_{ji}}}=-\delta_j \color{purple}{x_i}\)
\(\color{blue}{w_{ji}: 输入层 \longrightarrow 隐含层的权重}\)
\(\color{purple}{x_i: 最初的人为实际输入}\)
\(\delta_j=\color{darkgreen}{g^\prime(net_j)}\color{darkorange}{\sum\limits_{k=1}^c \delta_k w_{kj}}\)
\(\color{darkorange}{\sum\limits_{k=1}^c \delta_k w_{kj}}: 各输出层传播来的误差\)
\(\color{darkorange}{w_{kj}: 隐含层 \longrightarrow 输出层的权重}\)
\(\color{darkgreen}{g^\prime(net_j): 隐含层激活函数(可以与输出层相同,也可以不同)的导数;net_j 各输入的加权和}\)
总结
权重增量 = -1*学习步长*目标函数对权重的偏导数
\(\Delta\mathrm{w}(m)=-\eta\frac{\partial J}{\partial \mathrm{w}}\)
目标函数对权重的偏导数=-1*残差*当前层的输入
\(隐含层 \longrightarrow 输出层\)
\(\frac{\partial J}{\partial w_{kj}}=-\delta_k y_j\)
\(输入层 \longrightarrow 隐含层\)
\(\frac{J}{\partial w_{ji}}=-\delta_j x_i\)
残差=当前层激活函数的导数*上层反传来的误差
\(隐含层 \longrightarrow 输出层\)
\(\delta_k=\color{darkorange}{f^\prime(net_k)}(t_k-z_k)\)
\(输入层 \longrightarrow 隐含层\)
\(\delta_j=\color{darkgreen}{g^\prime(net_j)}\color{darkorange}{\sum\limits_{k=1}^c \delta_k w_{kj}}\)
上层反传来的误差=上层残差的加权和
\(隐含层 \longrightarrow 输出层\)
\((t_k-z_k): 人为定义的实际输出层误差\)
\(输入层 \longrightarrow 隐含层\)
\(\color{darkorange}{\sum\limits_{k=1}^c \delta_k w_{kj}}: 各输出层传播来的误差\) 误差反向传播BP
网络是前馈的(前向计算损失),由输入到输出层的最终输出,没有层内连接,没有自身连接,没有反馈连接;误差是反向传播,用于计算调整每一层的权重,使每一层的权重按梯度下降方法进行计算, 先得输出层的误差然后调整指向输出层的权重,依次从后传播即表现在调整权重。
网络的初始输入是人为的提取原始数据的特征,在算法执行过程中(隐藏层),对这些特征进行选择对分类有用的特征。
1.5 BP示例
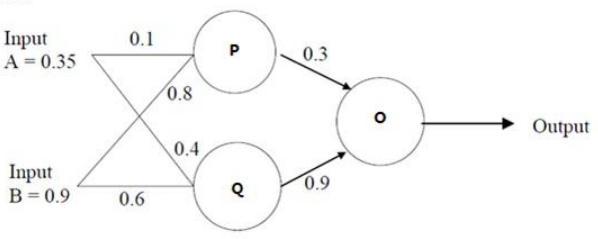
输入样本为 (A,B) 或者 \((x_1, x_2)\) 为 (0.35,0.9),因变量\(t\)为 0.5
初始权重:
\(w_{x_1y_1}=AP=0.1\), \(w_{x_1y_2}=AQ=0.4\), \(w_{y_1z}=PO=0.3\)
\(w_{x_2y_1}=BP=0.8\), \(w_{x_2y_2}=BQ=0.6\), \(w_{y_2z}=PO=0.9\)
三个神经元的激活函数均为\(f(net)=\frac{1}{1+e^{-net}}\), \(net\) 为该神经元的输入权重和.
隐藏层神经元的输入 \(net_{y_j}=\sum\limits_{i=1}^d w_{y_jx_i} x_i\)。
输出层神经元的输入 \(net_{z_k}=\sum\limits_{j=1}^n w_{z_ky_j} y_j\)。
前馈到输出层 O:
P 处理来自 AB的输入 \(p(A,B)=f(net_{y_1})=f(\sum\limits_{i=1}^2 w_{y_1x_i} x_i)=\frac{1}{1+e^{-(0.1\times 0.35+0.8\times 0.9)}}=0.68\)
Q 处理来自 AB的输入 \(q(A,B)=f(net_{y_2})=f(\sum\limits_{i=1}^2 w_{y_2x_i} x_i)=\frac{1}{1+e^{-(0.4\times 0.35+0.6\times 0.9)}}=0.6637\)
O 处理来自 PQ的输入 \(o(P,Q)=f(net_{z_1})=f(\sum\limits_{j=1}^2 w_{z_1y_j} y_j)=\frac{1}{1+e^{-(0.3\times 0.68+0.9\times 0.6637)}}=0.69\)
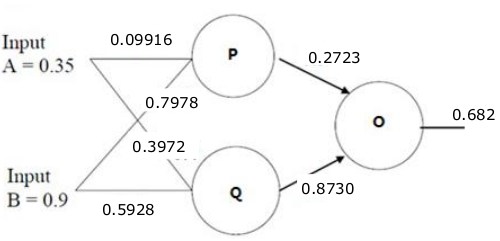
误差反向传播调整权重
先从输出层的实际误差开始中 \(t=0.5\), \(z=0.69\):
梯度下降法使\(J(\mathrm{w})={1\over 2}(t-z)^2\) 得到最小值
先看隐含层到输出层权重:
\(\frac{\partial J}{\partial PO}=\frac{\partial J}{\partial error}\frac{\partial error}{\partial o}\frac{\partial o}{\partial PO} = \color{red}{\frac{\partial J}{\partial z_1}}\color{darkorange}{\frac{\partial z_1}{\partial net_{z_1}}}\color{darkgray}{\frac{\partial net_{z_1}}{\partial w_{z_1y_1}}}=\color{red}{-(t-z)}\color{darkorange}{f^\prime (net_{z_1})}\color{darkgray}{y_1}=-(0.5-0.69)\times[0.69\times(1-0.69)]\times0.68=0.02763\)
这里 \(\color{darkorange}{f (net_{z_1})}=z_1\), 导数可以用输出计算 \(\color{darkorange}{f^\prime (net_{z_1})}=z_1 (1-z_1)\).
\(\frac{\partial J}{\partial QO}=\frac{\partial J}{\partial error}\frac{\partial error}{\partial o}\frac{\partial o}{\partial QO} = \color{red}{\frac{\partial J}{\partial z_1}}\color{darkorange}{\frac{\partial z_1}{\partial net_{z_1}}}\color{darkgray}{\frac{\partial net_{z_1}}{\partial w_{z_1y_2}}}=\color{red}{-(t-z)}\color{darkorange}{f^\prime (net_{z_1})}\color{darkgray}{y_2}=-(0.5-0.69)\times[0.69\times(1-0.69)]\times0.6673=0.02711\)
调整权重
\(\mathrm{w}(m+1)=\mathrm{w}(m)+\Delta \mathrm{w} = \mathrm{w}(m)-\eta\frac{\partial J}{\partial \mathrm{w}}\)
\(PO^* = PO-\frac{\partial J}{\partial PO} = 0.2723\)
\(QO^* = QO-\frac{\partial J}{\partial QO} = 0.8730\)
输入层到隐藏层的权重
\(\frac{\partial J}{\partial AP}= \frac{\partial J}{\partial error}\frac{\partial error}{\partial o}\frac{\partial o}{\partial p}\frac{\partial p}{\partial AP}=\color{darkorange}{\frac{\partial J}{y_1}}\color{darkgreen}{\frac{\partial y_1}{\partial net_{y_1}}}\color{darkgray}{\frac{\partial net_{y_1}}{\partial w_{y_1x_1}}}=\color{darkorange}{\left[ -\sum\limits_{k=1}^1(t_k-z_k) \frac{\partial z_k}{y_1}\right]}\color{darkgreen}{\frac{\partial y_1}{\partial net_{y_1}}}\color{darkgray}{\frac{\partial net_{y_1}}{\partial w_{y_1x_1}}} =\color{darkorange}{\left[ -(t_1-z_1) \frac{\partial z_1}{\partial net_{z_1}}\frac{\partial net_{z_1}}{\partial y_1}\right]}\color{darkgreen}{\frac{\partial y_1}{\partial net_{y_1}}}\color{darkgray}{\frac{\partial net_{y_1}}{\partial w_{y_1x_1}}} =\color{darkorange}{-(t_1-z_1) \frac{\partial z_1}{\partial net_{z_1}}\frac{\partial net_{z_1}}{\partial y_1}}\color{darkgreen}{\frac{\partial y_1}{\partial net_{y_1}}}\color{darkgray}{\frac{\partial net_{y_1}}{\partial w_{y_1x_1}}} =\color{darkorange}{-(t_1-z_1) f^\prime(net_{z_1})w_{z_1y_1}^*}\color{darkgreen}{f^\prime(net_{y_1})}\color{darkgray}{x_1}=\color{darkorange}{-(t_1-z_1) (z_1 (1-z_1))w_{z_1y_1}^*}\color{darkgreen}{(y_1(1-y_1))}\color{darkgray}{x_1}=-(0.5-0.69)\times[0.69\times(1-0.69)]\times0.2723\times[0.68\times(1-0.68)]\times0.35=0.00084\)
类似可以计算 \(\frac{\partial J}{\partial BP}\), \(\frac{\partial J}{\partial AQ}\), \(\frac{\partial J}{\partial BQ}\)
调整权重
\(AP^* = AP-\frac{\partial J}{\partial AP} = 0.09916\)
\(BP^* = BP-\frac{\partial J}{\partial BP} = 0.7978\)
\(AQ^* = AQ-\frac{\partial J}{\partial AQ} = 0.3972\)
\(BQ^* = BQ-\frac{\partial J}{\partial BQ} = 0.5928\)
2 多样本
批量梯度下降(BGD),对所有样本进行处理, 得到全局最优解,样本数很大时计算量很大。
目标函数为: \(J(w) = {1\over 2}\sum_\limits{所有样本}\sum\limits_{k=1}^c (t_k-z_k)^2\)
随机梯度下降(SGD)
只用其中一部分样本,就有可能已经迭代到最优解了。SGD不是每次迭代都向着整体最优化方向,但是整体上是趋于整体最优化方向。
Mini-batch Gradient Descent(Mini-BGD), 在批量梯度下降和随机梯度下降之间折衷。每次从所有数据中取一个子集(mini-batch)。 可以是退化成SGD,也可以是所有样本BGD。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号