
libevent源码学习(7):event_io_map
以下源码均基于libevent-2.0.21-stable。
在libevent中,自定义了一个哈希表结构用于实现event_io_map,该哈希表相关代码在ht-internal.h中,从该头文件的名称也可以看出来,libevent中的哈希表是一个并不对用户开放的内部使用结构。哈希表用于实现event_io_map,因此先来看看event_io_map的定义。
event_io_map
在event_internal.h文件中,有如下定义:
-
-
/* If we're on win32, then file descriptors are not nice low densely packed
-
integers. Instead, they are pointer-like windows handles, and we want to
-
use a hashtable instead of an array to map fds to events.
-
*/
-
-
-
-
/* #define HT_CACHE_HASH_VALS */
-
-
-
-
struct event_map_entry;
-
HT_HEAD(event_io_map, event_map_entry); //定义一个结构体名为event_io_map,其中的哈希表元素类型为event_map_entry
-
-
-
根据上述定义可知,仅在Windows环境下,event_io_map会使用哈希结构,否则event_io_map直接按event_signal_map使用。
这里涉及到了一个宏定义HT_HEAD以及一个结构体event_map_entry,先来看看event_map_entry结构体的定义。
-
-
struct event_map_entry {
-
HT_ENTRY(event_map_entry) map_node; //构成哈希表中同一个桶下的链表
-
evutil_socket_t fd; //文件描述符
-
union { /* This is a union in case we need to make more things that can
-
be in the hashtable. */
-
struct evmap_io evmap_io; //存放同一个文件描述符/信号值下的所有event
-
} ent;
-
};
可以看到,在event_map_entry这一结构体中,还涉及到了一个HT_ENTRY宏定义,除此之外,其中包含了一个文件描述符/信号值成员fd,以及一个联合体中定义了一个evmap_io类型的结构体。对于这里的HT_ENTRY以及前面的HT_HEAD,各自的宏定义如下所示:
对于HT_HEAD宏定义,其中包含5个成员,各自的含义可参照注释。需要注意的是第一个成员struct type **hth_table,从成员名来看就是哈希表,这是一个二级指针,在C语言中规定,p[i]等价于*(p+i),换到这里来看,hth_table是一个指向type *类型的指针,因此(p+i)就是从首地址偏移了i个type *类型大小的地址,而*(p+i)自然也就是从首地址算起,第i个type *类型的元素了,因此,hth_table作为一个二级指针,那么hth_table[i]也就是第i个type*类型的元素,hth_table也就相当于一个type *类型的数组了。
再来看 HT_ENTRY这一宏定义,它定义了一个匿名结构体,该结构体的接个头由宏定义HT_CACHE_HASH_VALUES控制,在libevent中,我目前尚未找到HT_CACHE_HASH_VALUES的定义,也就是说,该宏定义默认为未定义的,可由用户自行选择是否定义。
接下来,替换以上两个宏定义,再回到event_map_entry和event_io_map中,得到各自定义如下:
-
struct event_map_entry
-
{
-
struct
-
{
-
struct event_map_entry *hte_next; //构成链表
-
-
unsigned hte_hash;
-
-
}map_node;
-
-
evutil_socket_t fd;
-
union
-
{
-
struct evmap_io evmap_io;
-
}ent;
-
};
-
-
-
struct event_io_map
-
{
-
//哈希表,连续地址分配
-
struct event_map_entry **hth_table;
-
//哈希表的长度
-
unsigned hth_table_length;
-
//哈希的元素个数
-
unsigned hth_n_entries;
-
//哈希表扩容阈值,当哈希表中元素数目达到这个值就需要进行扩容
-
unsigned hth_load_limit;
-
//哈希表的长度所对应素数数组中的索引
-
int hth_prime_idx;
-
};
在event_io_map中,二级指针hth_table刚刚说了,可以看做是一个数组,这个数组的各个元素类型为event_map_entry *类型,而在event_map_entry结构体的定义中,一个hte_next很明显表明了这里会存在一个event_map_entry的链表。在来看后面的evmap_io结构体定义,如下所示:
-
struct evmap_io
-
{
-
struct event_list events; //event双向链表
-
ev_uint16_t nread; //链表中读事件的个数
-
ev_uint16_t nwrite; //链表中写事件的个数
-
};
关于event_list类型,可以在event_struct.h中找到其相关语句:(关于TAILQ)
TAILQ_HEAD (event_list, event); //名为event_list的头结点,链表结点为event类型也就是说,在evmap_io中,定义了一个event的双向链表,以及一个nread变量和nwrite变量,而一个event_map_entry对应一个evmap_io,也就对应一个event的双向链表。
因此总结得出event_io_map的结构,如下所示:
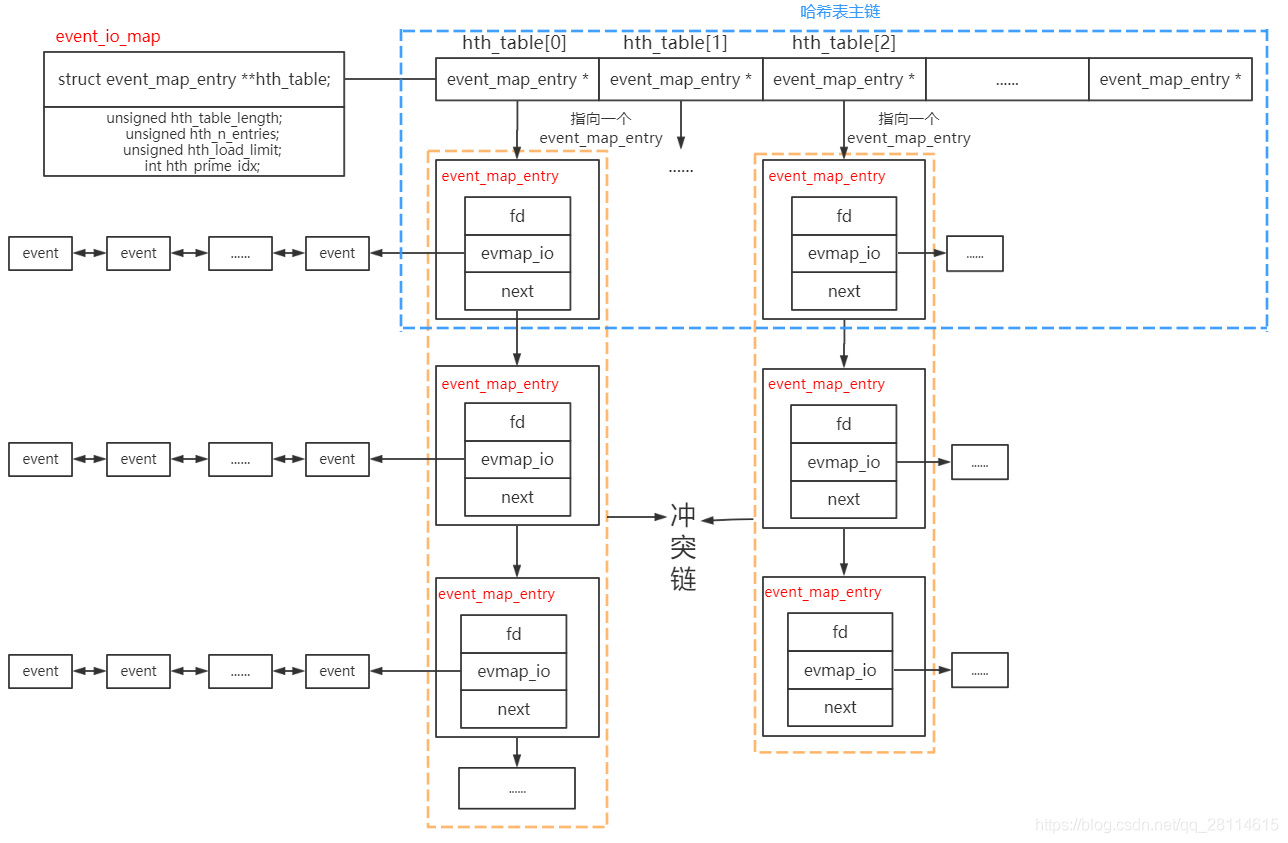
这样,我们就大概知道了libevent中哈希表的结构:
hth_table就是哈希表中的“桶数组”,它的每一个元素都是一个“桶”,这里将哈希表分为主链和冲突链,哈希表主链上的各个结点放置的是地址连续的event_map_entry指针,通过下标如hth_table[i]就可以直接访问第i个结点,它的底层就是*(hth_table+i),这是一个寻址的过程,时间复杂度为O(1)。主链上每一个这样的event_map_entry指针都指向一个event_map_entry实体。如果有多个event_map_entry实体对应同一个桶,这就引起了哈希冲突,从图中也可得知,libevent是采用拉链法来解决哈希冲突的,如图中褐色框中的内容所示。
每个event_map_entry都对应了一个fd,对于event这是一个文件描述符,对于signal这是一个信号值,也就对应了一个监听事件。如果多个事件对应同一个fd,那么这些事件就会被放到evmap_io所对应的event事件双向链表中,evmap_io中的nread和nwrite则分别记录了这个双向链表中读类型和写类型的event数量。
总之,event_io_map中会保存所有通过event_add添加的io event。
哈希表操作函数
在ht-internal.h中,哈希表相关的函数主要都是以宏函数来实现的,找到这些函数的宏定义如下所示:
-
-
-
-
/* How many elements in 'head'? */
-
-
-
-
-
-
-
-
-
-
-
-
这里只有两个函数直接给出了实现,而其他函数都是宏定义为name##_HT_XXX的宏函数上面,可以发现,这些宏函数对应了三个参数:name、head以及elm。宏定义中的“##”起的是连接作用。从函数名上大概能推断出函数的功能,不过如果直接去看这些宏函数的定义会非常懵的,在event_io_map中,这些宏定义中的name参数直接替换为"event_io_map"即可。
将这些宏定义全部替换(用gcc -E编译),然后就可以看到event_io_map中的这些函数的实现。
在分析函数实现之前,有必要先回过头再看一下event_io_map结构体:
-
struct event_io_map
-
{
-
//哈希表,连续地址分配
-
struct event_map_entry **hth_table;
-
//哈希表的长度
-
unsigned hth_table_length;
-
//哈希的元素个数
-
unsigned hth_n_entries;
-
//哈希表扩容阈值,当哈希表中元素数目达到这个值就需要进行扩容
-
unsigned hth_load_limit;
-
//哈希表的长度所对应素数数组中的索引
-
int hth_prime_idx;
-
};
hth_table:哈希表,hth_table[i]就是哈希表中的第i个桶;
hth_table_length:哈希表的长度。为了让元素散列更加均匀,哈希表的长度最好选为素数,libevent中提供了一个素数数组,哈希表的长度都是以该数组中的元素为准,即使是哈希表扩容,也是一样的,该素数数组定义如下:
-
static unsigned name##_PRIMES[] = { \
-
53, 97, 193, 389, \
-
769, 1543, 3079, 6151, \
-
12289, 24593, 49157, 98317, \
-
196613, 393241, 786433, 1572869, \
-
3145739, 6291469, 12582917, 25165843, \
-
50331653, 100663319, 201326611, 402653189, \
-
805306457, 1610612741 \
-
};
可以发现,素数数组中的每个元素都是素数,并且后一个元素近似为前一个元素两倍。而hth_table_length也只能取该数组中的某个值;
hth_n_entries:哈希表中的元素个数;
hth_load_limit:哈希表的扩容阈值。扩容阈值的含义是:当哈希表中的元素个数达到这个值后,哈希表就需要进行扩容;
hth_prime_idx:哈希表的长度对应素数数组中该元素的索引。比如说哈希表的长度为193,那么hth_prime_idx就为2。
hashcode与equals函数
在java的HashMap中,提供了一个hashcode方法以及equals方法,前者可以将不同类型参数转换为一个int型的散列值,而后再通过哈希算法找到对应的桶位置,而后者则是用于判断哈希表中两个元素是否相等。
在libevent中,也定义了这两个函数。
event_io_map中为event_map_entry类型的参数提供了一个取相应hashcode的函数hashsocket,根据英文注释可知,由于windows中socket的低2~3位是没有多大影响的,也就是可能会存在很多socket的低2~3位是相同的情况。如果两个socket只有低2~3位不同,那么说明这两个socket的值是非常接近的,而在哈希表中,对于非常接近的元素也希望把他们尽量的散列开,因此这里并没有直接使用event_map_entry的fd作为hashcode,而是先将fd的二进制位进行旋转,将其低2位放到高2位去,然后再与原来的fd进行求和,这样,即使值相近的两个socket的hashcode也会有很大的差别,更有利于散列。如下所示:(evmap.c)
-
static inline unsigned
-
hashsocket(struct event_map_entry *e)
-
{
-
/* On win32, in practice, the low 2-3 bits of a SOCKET seem not to
-
* matter. Our hashtable implementation really likes low-order bits,
-
* though, so let's do the rotate-and-add trick. */
-
unsigned h = (unsigned) e->fd;
-
h += (h >> 2) | (h << 30); // h>>2后只剩前面30位,h<<30后只有最后2位,相当于把最后2位放到了最前面,然后再与原数相加
-
return h;
-
}
当取得元素相应的hashcode值之后,就需要通过这个hashcode来找到它在哈希表中相应的桶的位置。这里采用的方法是直接让hashcode对哈希表长度取模%,得到的结果就是该元素在哈希表中桶的位置。 如果找到了桶的位置,并且桶是空的,那么直接将该元素放到桶中,如果桶中已经有元素了,说明此时产生了哈希冲突,如前所述,这里解决哈希冲突的方法是将冲突的元素组合成一个链表。举个例子,java中的HashMap或者是C++中的Map,存储的都是一个key-value键值对,当你通过key去寻找对应的value时,就会对value相应的hashcode先通过哈希算法(比如这里是hashcode取哈希表长度的模)求得key对应的桶的位置,然后再在桶中去看是否有元素与传入的元素"equals",如果没有那么就是查找失败,否则就返回equals成功的那个元素。
libevent中通过eqsocket函数来判断哈希表中的两个元素是否相同,判断的方法很简单,就是看二者的fd是否相等即可。
-
static inline int
-
eqsocket(struct event_map_entry *e1, struct event_map_entry *e2)
-
{
-
return e1->fd == e2->fd;
-
}
哈希表初始化
event_io_map哈希表初始化函数为event_io_map_HT_INIT,需要注意的是,这里只是让hth_table初始化为NULL,并没有为其分配实际的内存,哈希表此时也并不存在。如下所示:
-
static inline void event_io_map_HT_INIT(struct event_io_map *head) //哈希表初始化
-
{
-
head->hth_table_length = 0;
-
head->hth_table = NULL;
-
head->hth_n_entries = 0;
-
head->hth_load_limit = 0;
-
head->hth_prime_idx = -1;
-
}
哈希表元素查找
这里定义了两个哈希表元素查找函数,一个是_event_io_map_HT_FIND_P,一个则是_event_io_map_HT_FIND。二者都是在哈希表中去寻找与传入参数elm的fd相等的元素,不同的是前者返回的是哈希表中fd与elm相同的元素地址的指针,而后者则是返回该元素的地址。
-
static inline struct event_map_entry **
-
_event_io_map_HT_FIND_P(struct event_io_map *head,
-
struct event_map_entry *elm) //返回哈希表中,fd与elm相等的元素地址,如果哈希表不存在就返回NULL,如果哈希表中不存在该元素*p=NULL
-
{
-
struct event_map_entry **p;
-
if (!head->hth_table) //哈希表未分配
-
return NULL;
-
-
-
p = &((head)->hth_table[((elm)->map_node.hte_hash) //先将传入的elm进行哈希后取模,找到该元素在哈希表中的位置,然后找到哈希表中该位置上的元素,p为该元素地址
-
% head->hth_table_length]);
-
-
p = &((head)->hth_table[(hashsocket(*elm))%head->hth_table_length]);
-
-
-
while (*p) //从该位置开始遍历整个冲突链,查找冲突链上是否有与elm的fd相等的元素,如果有就返回该元素地址
-
{
-
//判断是否相等。在实现上,只是简单地根据fd来判断是否相等
-
if (eqsocket(*p, elm))
-
return p;
-
-
//p存放的是hte_next成员变量的地址
-
p = &(*p)->map_node.hte_next;
-
}
-
-
return p; //如果没找到,那么*p = NULL
-
}
-
static inline struct event_map_entry *
-
event_io_map_HT_FIND(const struct event_io_map *head,
-
struct event_map_entry *elm) //返回的是哈希表中该结点元素
-
{
-
struct event_map_entry **p;
-
struct event_io_map *h = (struct event_io_map *) head;
-
-
-
do
-
{ //计算哈希值
-
(elm)->map_node.hte_hash = hashsocket(elm);
-
} while(0);
-
-
-
p = _event_io_map_HT_FIND_P(h, elm); //p为NULL说明哈希表未分配,如果已分配,但是没找到,那么*p为NULL
-
return p ? *p : NULL; //返回NULL可能是哈希表本身未分配,也可能是哈希表中没有该元素
-
}
哈希表扩容
哈希表中每次扩容都是接近加倍,加倍扩容可以一次取得较大的容量,也就不用经常扩容了。不过对于哈希表扩容来说,它的作用不单单是为了增大空间,它也能降低哈希冲突发生的概率。
哈希表中通过HT_GENERATE宏设置了扩容因子,默认为0.5,而哈希表的扩容阈值,就是哈希表的长度乘以这个扩容因子得到的值,当哈希表中元素的个数超过扩容阈值,那么就说明需要进行扩容了。实际上扩容因子的设置并不固定,这里之所以将其设置为0.5,是为了降低哈希冲突概率的同时也避免频繁的扩容。
event_io_map的扩容函数为event_io_map_HT_GROW,其定义如下:
-
int event_io_map_HT_GROW(struct event_io_map *head, unsigned size) //哈希表扩容
-
{
-
unsigned new_len, new_load_limit;
-
int prime_idx;
-
-
struct event_map_entry **new_table;
-
//哈希表当前长度对应素数表中最后一个元素,此时不能再扩容了
-
if (head->hth_prime_idx == (int)event_io_map_N_PRIMES - 1)
-
return 0;
-
-
//还未达到哈希表扩充阈值,无需扩容
-
if (head->hth_load_limit > size)
-
return 0;
-
//执行到这里说明哈希表需要进行扩容了,下面开始扩容
-
prime_idx = head->hth_prime_idx; //保存当前哈希表长度对应的素数数组索引
-
-
do {
-
new_len = event_io_map_PRIMES[++prime_idx]; //从素数数组中得到扩容后的长度
-
-
new_load_limit = (unsigned)(0.5*new_len); //更新扩容阈值
-
} while (new_load_limit <= size
-
&& prime_idx < (int)event_io_map_N_PRIMES); //如果当前扩容后size依然超过了阈值,那么继续选取素数数组中下一个元素作为扩容大小
-
-
//执行到这里说明哈希表的扩容大小已经确定,现在分配实际空间
-
if ((new_table = mm_malloc(new_len*sizeof(struct event_map_entry*)))) //malloc分配扩容大小的空间 注意此时原来的哈希表依然存在
-
{
-
unsigned b;
-
memset(new_table, 0, new_len*sizeof(struct event_map_entry*)); //清空哈希表
-
-
//这里不能直接用realloc来扩容,因此哈希表长度变化后各个元素在哈希表中的位置也会改变,因此需要hash,将原哈希表上的每个元素重新放置到新的哈希表上,包括未冲突的
-
//实际上分配的只是一个新的哈希表的主链,新的哈希表和原来的哈希表对应同样的冲突链表
-
for (b = 0; b < head->hth_table_length; ++b) //遍历原来的哈希表
-
{
-
struct event_map_entry *elm, *next;
-
unsigned b2;
-
-
elm = head->hth_table[b]; //遍历哈希表上的主链的结点,然后再遍历主链结点所在的冲突链
-
while (elm) //从该元素开始,检查它的map_node链表,看是否有冲突
-
{
-
next = elm->map_node.hte_next; //取得所属链表的下一个元素
-
-
-
b2 = (elm)->map_node.hte_hash % new_len; //直接用缓存的哈希值取模得到元素在哈希表上的索引
-
-
b2 = (hashsocket(*elm)) % new_len;
-
-
//用头插法插入数据
-
//将该元素放到重新hash后的位置,这里相当于是头插法
-
elm->map_node.hte_next = new_table[b2]; //更新该元素所在的冲突链表位置
-
new_table[b2] = elm; //将该元素放到重新hash后的位置
-
-
elm = next; //冲突链下一个元素
-
}
-
}
-
-
if (head->hth_table) //释放原来的哈希表
-
mm_free(head->hth_table);
-
-
head->hth_table = new_table; //更新event_io_map中的哈希表
-
}
-
else //新哈希表malloc扩容失败,前面可以看到,malloc分配后新老哈希表都同时存在,因此分配失败的原因可能是空间不够装下两个哈希表
-
{ //尝试用realloc分配尝试是否能节约空间。realloc内部也会调用malloc分配一个新空间,然后将原空间中的数据复制过去后再释放原空间,
-
//因此在一般情况下即使使用realloc分配,在某一时刻内存中也会同时存在两个哈希表,内存不足的问题并不会得到解决
-
//这里之所以使用realloc,是为了尝试realloc的特殊情况,如果原空间的后面刚好有一段空闲内存,并且与原空间加起来刚好可以放下新空间,那么就会直接在原空间上进行“增长”,这样就节省了内存
-
//因此这里使用realloc并不一定就能改善空间状况,只是在malloc分配失败的情况下的一种尝试解决的办法,并不一定成功
-
unsigned b, b2;
-
-
-
new_table = mm_realloc(head->hth_table,
-
new_len*sizeof(struct event_map_entry*)); //用realloc进行重新分配,分配后直接将原哈希表上的主节点复制到新哈希表上,冲突链表还是原来的不变
-
-
if (!new_table) //如果realloc还是分配失败,就退出
-
return -1;
-
//执行到这里说明realloc分配成功,新分配的哈希表与原来的哈希表在原有位置上的延伸,延伸部分还需要初始化
-
memset(new_table + head->hth_table_length, 0,
-
(new_len - head->hth_table_length)*sizeof(struct event_map_entry*) //初始化延伸部分的空间
-
);
-
-
for (b=0; b < head->hth_table_length; ++b) //遍历哈希表上的主节点
-
{
-
struct event_map_entry *e, **pE;
-
-
for (pE = &new_table[b], e = *pE; e != NULL; e = *pE) //从主节点开始遍历冲突链表
-
{
-
//计算重新哈希后在新哈希表中的位置
-
-
b2 = (e)->map_node.hte_hash % new_len;
-
-
b2 = (hashsocket(*elm)) % new_len;
-
-
//对于冲突链A->B->C.
-
//pE是二级指针,存放的是A元素的hte_next指针的地址值
-
//e指向B元素。
-
-
//如果重新哈希取模后还是原来的位置
-
if (b2 == b)
-
{
-
//此时,无需修改。接着处理冲突链中的下一个元素即可
-
//pE向前移动,存放B元素的hte_next指针的地址值
-
pE = &e->map_node.hte_next; //就不用更改当前结点,直接到冲突链下一个结点
-
}
-
else//重新哈希取模后需要改变位置
-
{
-
*pE = e->map_node.hte_next; //直接把当前结点的下一个结点放到当前结点的位置上,相当于从冲突链表中删除当前结点
-
-
e->map_node.hte_next = new_table[b2]; //再将当前结点以头插形式放到新的位置上去
-
new_table[b2] = e;
-
}
-
-
//这种再次哈希的方式,很有可能会对某些元素操作两次。
-
//当某个元素第一次在else中处理,那么它就会被哈希到正确的节点
-
//的冲突链上。随着外循环的进行,处理到正确的节点时。在遍历该节点
-
//的冲突链时,又会再次处理该元素。此时,就会在if中处理。而不会
-
//进入到else中。
-
}
-
}
-
-
head->hth_table = new_table; //更新哈希表
-
}
-
//更新event_io_map中的相关信息
-
head->hth_table_length = new_len;
-
head->hth_prime_idx = prime_idx;
-
head->hth_load_limit = new_load_limit;
-
-
return 0;
-
}
哈希表元素插入
向哈希表中插入一个元素,就是先求得插入元素elm在哈希表中的位置,不管这个位置是否有元素,都直接以头插法的形式将新元素插在最前面。之所以采用头插法,是按照“最近新插入的元素可能在未来会被经常使用”的原则,插在链表头部这样即使发生了冲突,访问起来效率也更高。
-
static inline void
-
event_io_map_HT_INSERT(struct event_io_map *head,
-
struct event_map_entry *elm) //哈希表插入一个元素
-
{
-
struct event_map_entry **p;
-
if (!head->hth_table || head->hth_n_entries >= head->hth_load_limit)
-
event_io_map_HT_GROW(head, head->hth_n_entries+1); //如果哈希表未分配,或者哈希表超到或者达到扩容阈值(表明不能再插入新元素),就需要扩容
-
-
++head->hth_n_entries; //哈希表元素加1
-
-
-
do
-
{ //计算哈希值并进行缓存,后面获取哈希值时就不需要再调用哈希函数了
-
(elm)->map_node.hte_hash = hashsocket(elm);
-
} while (0);
-
-
p = &((head)->hth_table[((elm)->map_node.hte_hash)
-
% head->hth_table_length]); //找到哈希表上该哈希值取模后的位置
-
-
p = &((head)->hth_table[(hashsocket(*elm))%head->hth_table_length]);
-
-
-
-
//使用头插法,即后面才插入的链表,反而会在冲突链表头。
-
elm->map_node.hte_next = *p;
-
*p = elm;
-
}
哈希表元素替换
哈希表元素替换,实际上是替换元素的地址,先传入一个元素elm,然后寻找哈希表中与该元素fd相同的元素,然后将该元素的地址替换为新元素的地址,并将该元素的冲突链接在新元素的后面,从而完成替换。
-
static inline struct event_map_entry *
-
event_io_map_HT_REPLACE(struct event_io_map *head,
-
struct event_map_entry *elm) //替换哈希表中的结点元素
-
{
-
struct event_map_entry **p, *r;
-
-
if (!head->hth_table || head->hth_n_entries >= head->hth_load_limit) //如果哈希表未分配或者元素个数达到扩容阈值,那么就进行扩容
-
event_io_map_HT_GROW(head, head->hth_n_entries+1);
-
-
-
do
-
{
-
(elm)->map_node.hte_hash = hashsocket(elm); //缓存哈希值
-
} while(0);
-
-
-
p = _event_io_map_HT_FIND_P(head, elm); //p为哈希表中fd与elm相同的结点元素的地址
-
-
r = *p; //保存原结点元素地址
-
*p = elm; //给结点元素赋新值,这里是让哈希表上原来元素的地址换成了新元素的地址,完成了替换
-
-
if (r && (r!=elm)) //如果原结点元素与新元素不同
-
{
-
elm->map_node.hte_next = r->map_node.hte_next; //把原结点元素后面的冲突链接上去
-
-
r->map_node.hte_next = NULL;
-
return r; //返回被替换掉的元素
-
}
-
else //到这里说明哈希表在新元素对应的地方没有元素,或者原结点元素与新结点元素就是同一个
-
{
-
++head->hth_n_entries; //为什么元素个数加1? 不明白
-
return NULL; //返回NULL,表示哈希表中对应位置没有元素,无法完成替换,或者新老元素本身就相同,无需替换
-
}
-
}
哈希表元素删除
哈希表元素删除就是找到哈希表中某一个元素fd与传入参数elm的fd相同的元素并删除该元素。不过需要注意的是,这里并没有对被删除的元素进行释放,因此调用该函数后应当对返回值指针进行释放。
-
static inline struct event_map_entry *
-
event_io_map_HT_REMOVE(struct event_io_map *head,
-
struct event_map_entry *elm) //哈希表元素删除
-
{
-
struct event_map_entry **p, *r;
-
-
-
do
-
{
-
(elm)->map_node.hte_hash = hashsocket(elm);
-
} while (0);
-
-
-
p = _event_io_map_HT_FIND_P(head,elm); //p是找到的哈希表上元素的地址
-
-
if (!p || !*p)//没有找到 //p为NULL说明哈希表未分配,*p为NULL说明没有找到elm
-
return NULL;
-
-
r = *p; //r指向要被删除的元素
-
*p = r->map_node.hte_next; //把该元素的地址换为它在冲突链上下一个元素的地址 实现删除
-
r->map_node.hte_next = NULL;
-
-
--head->hth_n_entries; //元素数目减1
-
-
return r;
-
}
自定义条件删除元素
如前面的删除元素函数,是删除fd相同的那个元素,删除的依据就是fd相同。这里还提供了一种自己定义删除依据的删除方式:先自定义一个函数fn,在遍历哈希表元素的时候,将各个元素与传入的elm作为参数调用fn,如果fn返回true,那么就将哈希表中该元素删除,如下所示:(可以看到,在该函数中对于删除的元素并没有进行释放,并且也没有返回被删除元素的地址,这样也无法从外部对删除的元素进行释放)
-
static inline void
-
event_io_map_HT_FOREACH_FN(struct event_io_map *head,
-
int (*fn)(struct event_map_entry *, void *),
-
void *data) //遍历哈希表上所有元素,以各个元素去调用fn,如果fn返回true则删除该元素
-
{
-
unsigned idx;
-
struct event_map_entry **p, **nextp, *next;
-
-
if (!head->hth_table)
-
return;
-
-
for (idx=0; idx < head->hth_table_length; ++idx) //遍历哈希表主链
-
{
-
p = &head->hth_table[idx]; //取哈希表主链上元素的地址
-
-
while (*p) //如果在该处有元素
-
{
-
nextp = &(*p)->map_node.hte_next; //nextp保存哈希表上该元素在冲突链上下一个元素的地址
-
next = *nextp; //next保存该元素在冲突链上的下一个元素
-
-
//对B元素进行检查
-
if (fn(*p, data))
-
{
-
--head->hth_n_entries;
-
-
*p = next; //直接将该元素的地址替换为下一个元素的地址,相当于删除该元素
-
}
-
else
-
{
-
p = nextp; //冲突链上下一个元素地址
-
}
-
}
-
}
-
}
哈希表第一个非空元素
哈希表第一个非空元素一定是在主链上,因此直接遍历哈希表的主链,不用去管冲突链,找到主链上第一个非空的元素返回其地址即可。由于主链上的元素都是event_map_entry *类型,因此这里返回的地址是event_map_entry **类型。
-
static inline struct event_map_entry **
-
event_io_map_HT_START(struct event_io_map *head) //返回哈希表主链上第一个非空元素的地址
-
{
-
unsigned b = 0;
-
-
while (b < head->hth_table_length)
-
{
-
if (head->hth_table[b])
-
return &head->hth_table[b];
-
-
++b;
-
}
-
-
return NULL;
-
}
哈希表下一个元素
这里提供了两个取下一个元素地址的函数event_io_map_HT_NEXT和event_io_map_HT_NEXT_RMV。前者是直接查找传入的elm所在冲突链上的下一个元素并返回其地址的指针,如果该元素是冲突链上最后一个元素,那么就从主链上找到下一个非空的元素,返回其地址的指针;后者则是返回下一个元素地址的指针,并且将elm从哈希表中删除。
-
static inline struct event_map_entry **
-
event_io_map_HT_NEXT(struct event_io_map *head,
-
struct event_map_entry **elm) //返回elm在哈希表中下一个元素的地址的指针,先从elm所在冲突链中找到下一个元素,如果没有就从主链上下一个位置开始找
-
{
-
if ((*elm)->map_node.hte_next) //返回elm的下一个结点的地址
-
{
-
return &(*elm)->map_node.hte_next;
-
}
-
else //如果elm是其所在冲突链的最后一个结点,那么就找到下一条冲突链的第一个结点
-
{
-
#ifdef HT_CACHE_HASH_VALUES
-
unsigned b = (((*elm)->map_node.hte_hash)
-
% head->hth_table_length) + 1; //从elm所在冲突链在主链上位置的后一个开始
-
-
unsigned b = ( (hashsocket(*elm)) % head->hth_table_length) + 1;
-
-
-
while (b < head->hth_table_length)
-
{
-
//找到了第一个非空的结点,就返回该结点地址
-
if (head->hth_table[b])
-
return &head->hth_table[b];
-
++b;
-
}
-
-
return NULL; //返回NULL说明elm所在冲突链包括主链后面都没有非空结点了
-
}
-
}
-
static inline struct event_map_entry **
-
event_io_map_HT_NEXT_RMV(struct event_io_map *head,
-
struct event_map_entry **elm) //返回哈希表上elm的下一个元素的地址,如果是在elm的冲突链上,那么就把elm删除
-
{
-
-
unsigned h = ((*elm)->map_node.hte_hash);
-
-
unsigned h = (hashsocket(*elm));
-
-
//h中保存elm对应的哈希值
-
-
*elm = (*elm)->map_node.hte_next; //elm冲突链上下一个元素的地址,这里也相当于直接用elm下一个元素的地址替换elm的地址,删除了哈希表上elm的地址
-
-
--head->hth_n_entries; //哈希表元素个数减1
-
-
if (*elm) //返回elm所在冲突链上下一个元素的地址
-
{
-
return elm;
-
}
-
else //如果elm在其冲突链上是最后一个元素,那么就从后面的主链上找第一个非空的元素
-
{
-
unsigned b = (h % head->hth_table_length)+1;
-
-
while (b < head->hth_table_length)
-
{
-
if (head->hth_table[b])
-
return &head->hth_table[b];
-
-
++b;
-
}
-
-
return NULL;
-
}
-
}
释放哈希表
-
void event_io_map_HT_CLEAR(struct event_io_map *head)
-
{
-
if (head->hth_table) //释放哈希表
-
mm_free(head->hth_table);
-
-
head->hth_table_length = 0;
-
-
event_io_map_HT_INIT(head); //重新初始化event_io_map
-
}
向event_io_map中添加event
如前所述,当对一个io event调用event_add时,Libevent就会把这个io event添加到event_io_map中,添加到event_io_map所调用的函数是evmap_io_add,其定义如下所示:
-
int
-
evmap_io_add(struct event_base *base, evutil_socket_t fd, struct event *ev)
-
{
-
const struct eventop *evsel = base->evsel; //得到event所绑定的base对应的后端方法
-
struct event_io_map *io = &base->io; //得到base对应的iomap
-
struct evmap_io *ctx = NULL; //指向fd所对应的那个evmap_io,evmap_io中又含有一个event双向链表
-
int nread, nwrite, retval = 0;
-
short res = 0, old = 0; //old用于记录下fd所对应的事件链表中在ev未插入前的所有事件对应了哪几种类型(write/read)
-
struct event *old_ev;
-
-
EVUTIL_ASSERT(fd == ev->ev_fd); //确保传入的fd等于event的fd
-
-
if (fd < 0)
-
return 0;
-
-
-
if (fd >= io->nentries) { //如果fd大于当前哈希表中的元素数目就重新分配
-
if (evmap_make_space(io, fd, sizeof(struct evmap_io *)) == -1)
-
return (-1);
-
}
-
-
GET_IO_SLOT_AND_CTOR(ctx, io, fd, evmap_io, evmap_io_init,
-
evsel->fdinfo_len);
-
//ctx就成为了fd对应的那个evmap_io的指针
-
nread = ctx->nread; //记录下fd所有event中读事件实木
-
nwrite = ctx->nwrite;//记录下fd所有event中写事件数目
-
-
if (nread) //如果fd对应的事件链表中有读类型事件
-
old |= EV_READ; //表明在ev插入之前fd对应的event链表中就已经存在读类型事件了
-
if (nwrite) //如果fd对应的事件链表中有写类型事件
-
old |= EV_WRITE; //表明在ev插入之前fd对应的event链表中就已经存在写类型事件了
-
-
if (ev->ev_events & EV_READ) { //如果添加的ev为读类型
-
if (++nread == 1) //读事件数目加1
-
res |= EV_READ;
-
}
-
if (ev->ev_events & EV_WRITE) { //如果添加的ev为写类型
-
if (++nwrite == 1) //写事件数目加1
-
res |= EV_WRITE;
-
}
-
if (EVUTIL_UNLIKELY(nread > 0xffff || nwrite > 0xffff)) {
-
event_warnx("Too many events reading or writing on fd %d",
-
(int)fd);
-
return -1;
-
}
-
//此时还没有将ev插入到fd下的那个链表中,遍历整个链表,需要保证fd下的链表中所有event要么都是ET要么都不是ET,不能混合使用
-
if (EVENT_DEBUG_MODE_IS_ON() &&
-
(old_ev = TAILQ_FIRST(&ctx->events)) &&
-
(old_ev->ev_events&EV_ET) != (ev->ev_events&EV_ET)) {
-
event_warnx("Tried to mix edge-triggered and non-edge-triggered"
-
" events on fd %d", (int)fd);
-
return -1;
-
}
-
-
if (res) {//如果有读或写事件,就将event添加到base中
-
void *extra = ((char*)ctx) + sizeof(struct evmap_io);
-
/* XXX(niels): we cannot mix edge-triggered and
-
* level-triggered, we should probably assert on
-
* this. */
-
if (evsel->add(base, ev->ev_fd,
-
old, (ev->ev_events & EV_ET) | res, extra) == -1) //调用对应后端的add函数进行添加
-
return (-1);
-
retval = 1;
-
}
-
//记录fd下的读写event数量
-
ctx->nread = (ev_uint16_t) nread;
-
ctx->nwrite = (ev_uint16_t) nwrite;
-
TAILQ_INSERT_TAIL(&ctx->events, ev, ev_io_next); //将event插入到fd对应的事件链表中
-
-
return (retval);
-
}
这里如果不是使用哈希结构的话,event_io_map实际上就相当于一个数组,数组的元素索引就对应了一个fd值,因此当fd大于或等于该数组的元素个数,说明此时该数组就需要扩容了,就调用evmap_make_space函数进行扩容,可以参考非windows下的event_io_map实现。
需要注意的是,这里的evmap_add函数只是将event添加到Libevent自定义的数据结构evmap_io中,而真正添加到内核事件监听集合中的操作实际上是通过event_base所绑定的后端方法的add函数来实现的。可以参考libevent对epoll的封装。
激活event_io_map中的event
激活event_io_map中的event使用的是evmap_io_active函数,不过这并不是一个对用户开放的接口。实现原理就是将fd对应的双向链表中发生了感兴趣事件的event通过event_active_nolock函数添加到激活队列中。其定义如下:
-
void
-
evmap_io_active(struct event_base *base, evutil_socket_t fd, short events)//将event_io_map中fd对应的event双向链表中关注事件类型与events有共同部分的事件添加到激活队列中
-
{
-
struct event_io_map *io = &base->io;
-
struct evmap_io *ctx;
-
struct event *ev;
-
-
-
EVUTIL_ASSERT(fd < io->nentries);
-
-
GET_IO_SLOT(ctx, io, fd, evmap_io); //找到fd对应的event_io_map中的event双向链表
-
-
EVUTIL_ASSERT(ctx);
-
TAILQ_FOREACH(ev, &ctx->events, ev_io_next) { //遍历该链表
-
if (ev->ev_events & events) //如果event的关注事件类型与发生的事件类型有共同部分
-
event_active_nolock(ev, ev->ev_events & events, 1); //插入到激活队列中
-
}
-
}
event_active_nolock函数可以参考事件的激活。
删除event_io_map中的event
evmap_io_del函数实际上就是evmap_io_add的逆操作,即是将event从event_io_map中删除,定义如下所示:
-
int
-
evmap_io_del(struct event_base *base, evutil_socket_t fd, struct event *ev)
-
{
-
const struct eventop *evsel = base->evsel;
-
struct event_io_map *io = &base->io;
-
struct evmap_io *ctx;
-
int nread, nwrite, retval = 0;
-
short res = 0, old = 0;
-
-
if (fd < 0)
-
return 0;
-
-
EVUTIL_ASSERT(fd == ev->ev_fd);
-
-
-
if (fd >= io->nentries)
-
return (-1);
-
-
-
GET_IO_SLOT(ctx, io, fd, evmap_io); //ctx指向fd对应的那个evmap_io
-
-
nread = ctx->nread; //evmap_io中读事件数目
-
nwrite = ctx->nwrite;//evmap_io中写事件数目
-
//old保存删除前evmap_io中所有event的事件类型有哪些种类(读或写)
-
if (nread)
-
old |= EV_READ;
-
if (nwrite)
-
old |= EV_WRITE;
-
-
if (ev->ev_events & EV_READ) {//如果需要被删除的事件对读事件感兴趣
-
if (--nread == 0) //读事件数目减1
-
res |= EV_READ;
-
EVUTIL_ASSERT(nread >= 0);
-
}
-
if (ev->ev_events & EV_WRITE) {//如果需要被删除的时间对写事件感兴趣
-
if (--nwrite == 0) //写事件数目减1
-
res |= EV_WRITE;
-
EVUTIL_ASSERT(nwrite >= 0);
-
}
-
-
if (res) {
-
void *extra = ((char*)ctx) + sizeof(struct evmap_io);
-
if (evsel->del(base, ev->ev_fd, old, res, extra) == -1) //调用后端的del函数
-
return (-1);
-
retval = 1;
-
}
-
-
ctx->nread = nread;
-
ctx->nwrite = nwrite;
-
TAILQ_REMOVE(&ctx->events, ev, ev_io_next); //从evmap_io的双向链表中删除event
-
-
return (retval);
-
}
对于evmap_io_event函数本身来说,只是将这个event从Libevent自定义数据结构event_io_map中删除,而实际上将该事件从内核监听事件集合中删除的函数还是通过event_base所绑定的后端方法中的del函数实现的。可以参考libevent对epoll的封装
转载自:https://blog.csdn.net/qq_28114615/article/details/95887231

 浙公网安备 33010602011771号
浙公网安备 33010602011771号