

一、explain各字段含义:
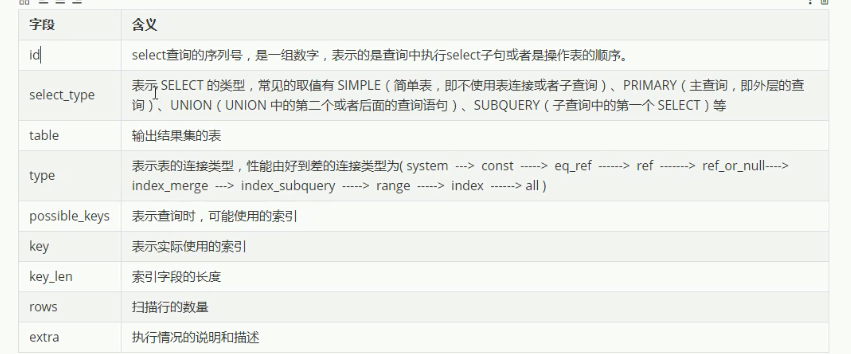
二、explain之id控制表结构执行顺序
id字段是select查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺序。id情况有三种:
(1)id相同表示加载表的顺序是从上到下。

上图表查询顺序依次appapi,api,app
(2)id不同id值越大,优先级越高,越先被执行。

上图查询顺序依次ag_appication,ag_application_api,api表
(3)id有相同,也有不同,同时存在。id相同的可以认为是一组,从上往下顺序执行;在所有的组中,id值越大,优先级越高,越先执行
三、explain之select_type

查询类型从上到下效率越来越低
例:

四、explain之type
type显示的是访问类型,是较为重要的一个指标,可取值为:

查询效率从上到下依次降低,一般来说我们需要保证查询至少达到range级别,最好达到ref
五、expliain 之 key
possible_keys:显示可能应用在这张表的索引,一个或多个
key:实际使用的索引,如果为null,则没有使用索引
key_len:表示索引中使用的字节数,该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前提下,长度越短越好
六、expliain 之 rows
扫描行的数量
七、explain之extra
其它额外的信息

前两个性能较差,出现需考虑优化
八、索引失效情况:
举例:已建好name+status+address联合索引
1)最左前缀法则(复合索引):索引从最左边字段开始匹配,即必须带name字段才会走索引,否则不会
2)范围查询右边的列不会使用索引:如:where name='' and status > '1' and address='fsdfd' 只会走name和status索引,address不会走索引
3)不要在索引列上进行运算操作,否则索引失效: 如:where substring (name,3,2)='科技'; 不会走索引
4)字符串不加单引号,索引失效
5)尽量使用覆盖索引(只访问索引的查询(索引列完全包含查询列)),减少select *。
6)用or分隔开的条件,如果or前的条件中的列有索引,而后面的列中没有索引,那么设计的索引都不会被用到。
如:where name='123' or createtime='xxx' name有索引而createtime没索引,索引都不会被用到
7)以%开头的like模糊查询,索引失效。如果仅仅是尾部模糊匹配,索引不会失效。头部模糊匹配,索引会失效
解决方法是使用覆盖索引
8)如果MYSQL评估使用索引比全表更慢,则不适用索引
9)is NULL,is NOT NULL有时索引失效(取决于表记录null值是否过多,mysql内部执行器自行决定是否走索引)
10)in 走索引, not in索引失效
11)尽量使用复合索引,而少使用单列索引(多个条件查询时,单列索引不会全部使用,数据库会选择一个最优的单列索引)
