
一、官方文档参考路径:
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/operators/index.html
二、Map
输入一个元素,映射返回一个元素
public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<Integer> source = env.fromElements(1,2,3,4,5,6,7,8,9); //Transformation 功能:做映射 SingleOutputStreamOperator<Integer> res1 = source.map(new MapFunction<Integer, Integer>() { @Override public Integer map(Integer input) throws Exception { return input * 2; } }); //传入功能更加强大的RichMapFunction // source.map(new RichMapFunction<Integer, Integer>() { // //open,在构造方法之后,map方法执行之前,执行一次,Configuration可以拿到全局配置 // //用来初始化一下连接,或者初始化或恢复state // @Override // public void open(Configuration parameters) throws Exception { // super.open(parameters); // } // // //销毁之前,执行一次,通常是做资源释放 // @Override // public void close() throws Exception { // super.close(); // } // // @Override // public Integer map(Integer value) throws Exception { // return value * 10; // } // }); //Sink res1.print(); env.execute("SourceDemo"); }
RichMap功能更丰富
三、FlatMap
将一个元素打平成0个,1个或多个元素
DataStreamSource<String> source = env.fromElements("spring spark spring", "flink spring","spark");
//Transformation 功能:做映射
SingleOutputStreamOperator<String> res = source.flatMap(new FlatMapFunction<String, String>() {
private static final long serialVersionUID = 9033850264996321740L;
@Override
public void flatMap(String input, Collector<String> out)
throws Exception {
Arrays.stream(input.split(" ")).forEach(out::collect);
}
});
//Sink
res.print();
输出:
1> spark
4> flink
4> spring
3> spring
3> spark
3> spring
FlatMap也提供RichFlatMapFunction,原理同RichMap
四、Filter
提供一个boolean函数过滤原数据,返回true的保留,否则删去
DataStreamSource<Integer> source = env.fromElements(1,2,3,4,5,6,7,8,9); SingleOutputStreamOperator<Integer> res = source.filter(new FilterFunction<Integer>() { @Override public boolean filter(Integer value) throws Exception { return value > 6; } }); res.print();
程序运行返回:
1> 7
2> 8
3> 9
五、KeyBy
将记录按照相同的key进行分组
1、按元组分组
DataStreamSource<String> source = env.socketTextStream("192.168.87.130", 8888);
SingleOutputStreamOperator<Tuple2<String, Integer>> res = source.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
return Tuple2.of(value, 1);
}
});
//泛型的第二个参数Tuple是key by的条件
KeyedStream<Tuple2<String, Integer>, Tuple> keyed = res.keyBy(0);
keyed.print();
输入:
[root@xdsu0 flinktest1-1]# nc -lk 8888
spark
spark
hue
hue
hbase
flink
hadoop
运行结果:
1> (spark,1) 1> (spark,1) 3> (hue,1) 3> (hue,1) 2> (hbase,1) 4> (flink,1) 4> (hadoop,1)
分组架构图:
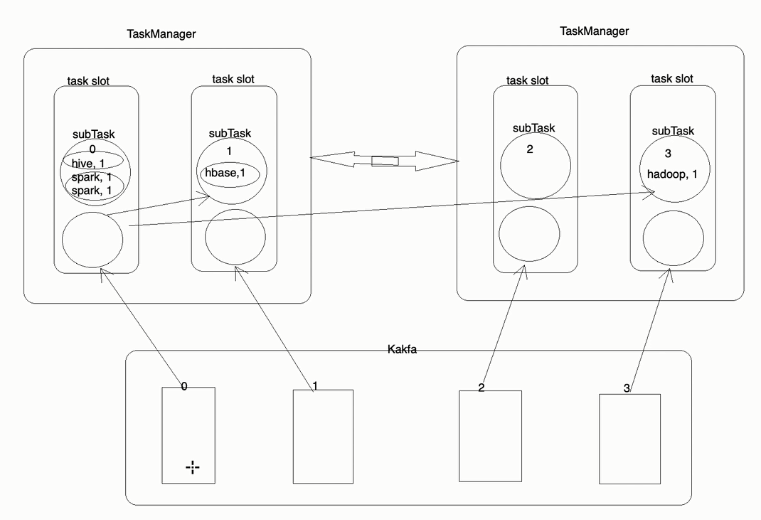
2、自定义分组
SingleOutputStreamOperator<WordCount> res = source.map(new MapFunction<String, WordCount>() { @Override public WordCount map(String value) throws Exception { return WordCount.of(value, 1L); } }); //自定义bean,keyby参数需指定字段名 KeyedStream<WordCount, Tuple> keyed = res.keyBy("word");
public class WordCount { public String word; public Long counts; @Override public String toString() { return "WordCount [word=" + word + ", counts=" + counts + "]"; } public WordCount(String word, Long counts) { super(); this.word = word; this.counts = counts; } public WordCount() { } public static WordCount of(String word, Long counts) { return new WordCount(word, counts); } }
输入:
hadoop
hadoop
hadoop
flink
spring
flink
打印:
4> WordCount [word=hadoop, counts=1]
4> WordCount [word=hadoop, counts=2]
4> WordCount [word=flink, counts=1]
3> WordCount [word=spring, counts=1]
4> WordCount [word=flink, counts=2]
3、多条件分组
//辽宁,沈阳,1000 //山东,青岛,2000 //山东,青岛,2000 //山东,烟台,1000 DataStreamSource<String> source = env.socketTextStream("192.168.87.130", 8888); SingleOutputStreamOperator<Tuple3<String, String, Integer>> res = source.map(new MapFunction<String, Tuple3<String, String, Integer>>() { @Override public Tuple3<String, String, Integer> map(String value) throws Exception { String[] word = value.split(","); return Tuple3.of(word[0], word[1], Integer.parseInt(word[2])); } }); //自定义bean,keyby参数需指定字段名 SingleOutputStreamOperator<Tuple3<String, String, Integer>> keyed = res.keyBy(0, 1).sum(2); keyed.print();
输入:
辽宁,沈阳,1000
辽宁,沈阳,1000
山东,烟台,1000
输出:
3> (辽宁,沈阳,1000)
3> (辽宁,沈阳,2000)
1> (山东,烟台,1000)
