一、Flink是什么
apache flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,提供支持流处理和批处理两种类型应用的功能
二、Flink特点
- 现有的开源计算方案,会把流处理和批处理作为两种不同的应用类型:流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞吐、高效处理
- Flink是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是他的输入流被定义为有界的
三、Flink组件栈
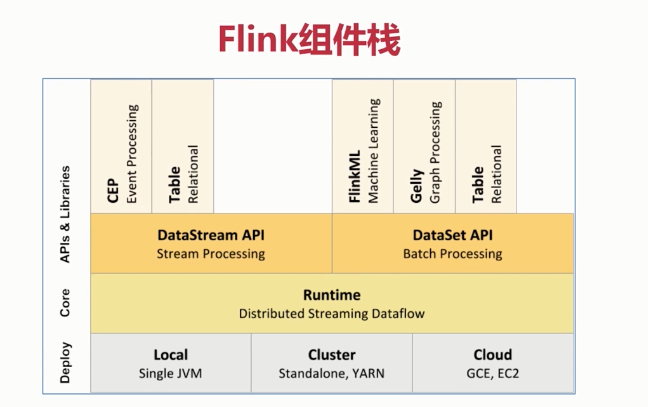
Deployment层
主要涉及了Flink的部署模式,Flink支持多种部署模式:本地、集群(Standalone/YARN)、云(GCE/EC2)。
Runtime层
Runtime层提供了支持Flink计算的全部核心实现,比如:支持分布式Stream处理、JobGraph到ExecutionGraph的映射、调度等等,为上层API层提供基础服务
API层
API层主要实现了面向无界Stream的流处理和面向Batch的批处理API,其中面向流处理对应DataStream API,面向批处理对应DataSet API
Libaries层
在API层之上构建的满足特定应用的实现计算框架,也分别对应与面向流处理和面向批处理两类
Flink自身优势
- 支持高吞吐、低延迟、高性能的流处理
- 支持高度灵活的窗口(Window)操作
- 支持有状态计算的Exactly-once语义
- 提供DataStream API和DataSet API
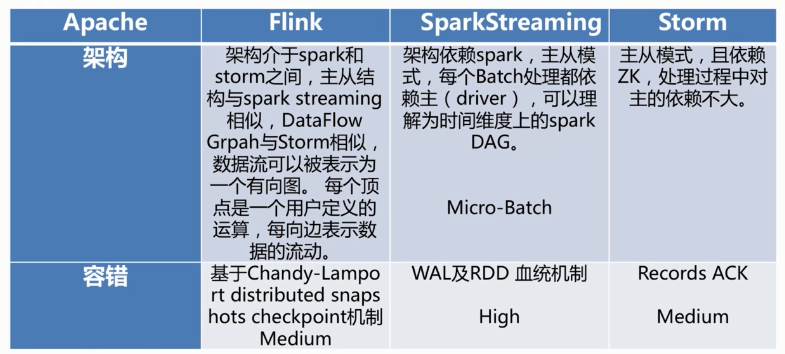
Flink与其它框架比较

Flink基本概念
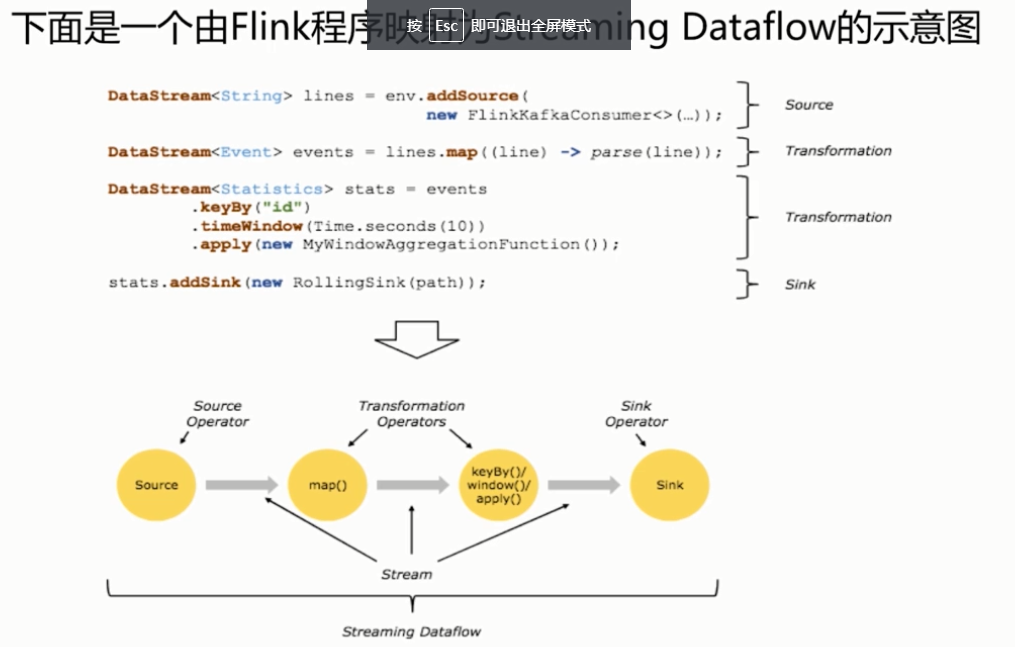
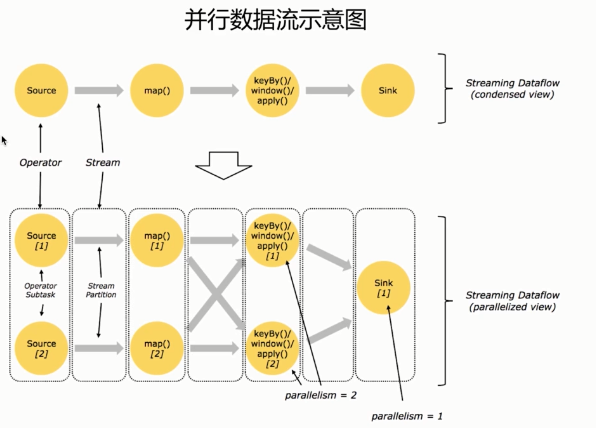
- Flink程序的基础构建模块是流(streams)与转换(transformations)
- 每一个数据流起始于一个或多个source,并终止于一个或多个sink
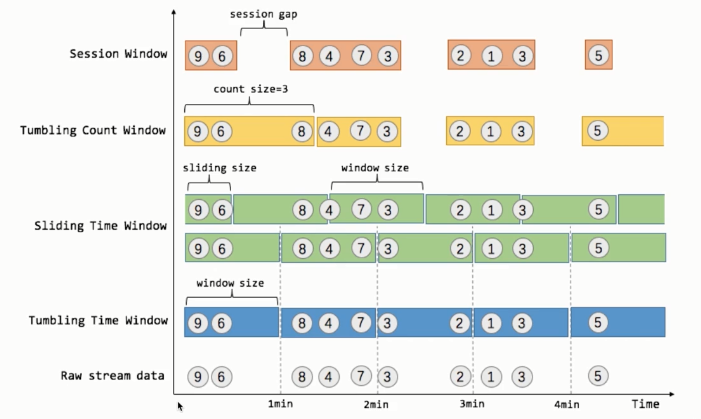
时间窗口
流上的聚合需要由窗口来划定范围,比如“计算过去的5分钟”或者“最后100个元素的和”
窗口通常被区分为不同的类型,比如滚动窗口(没有重叠),滑动窗口(有重叠),以及会话窗口(由不活动的间隙所打断)
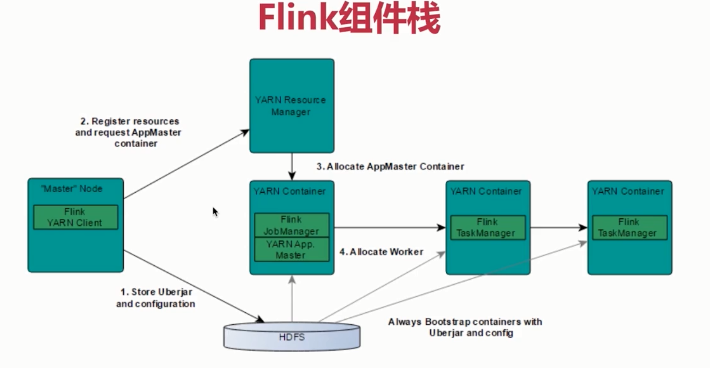
FLINK分布式运行环境
基本架构
Flink是基于Master-Slave风格的架构
Flink集群启动时,会启动一个JobManager进程、至少一个TaskManager进程
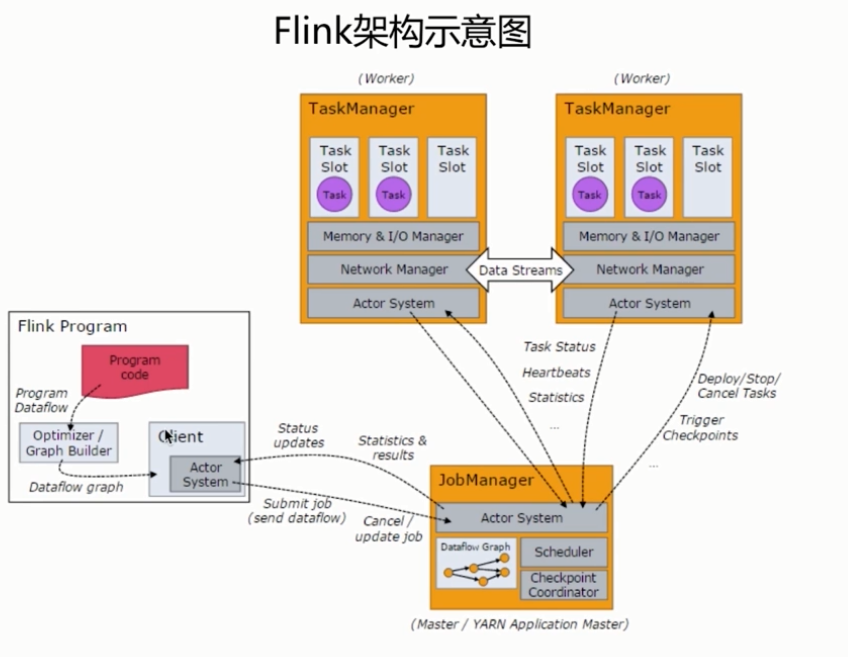
JobManager
- Flink系统的协调者,它负责接收Flink Job,调度组成Job的多个Task的执行
- 收集Job的状态信息,并管理Flink集群中从节点TaskManager
TaskManager
- 实际负责执行计算的Worker,在其上执行Flink Job的一组Task
- TaskManager负责管理其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候将资源的状态向JobManager汇报
Client
- 用户提交一个Flink程序时,会首先创建一个Client,该Client首先会对用户提交的Flink程序进行预处理,并提交到Flink集群
- Client会将用户提交的Flink程序组装一个JobGraph,并且是以JobGraph的形式提交的